基于GPS的出行者停止语义推断模型
2015-12-16刘春,曹凯
刘 春,曹 凯
(山东理工大学 交通与车辆工程学院,山东 淄博255049)
基于GPS的出行者停止语义推断模型
刘春,曹凯
(山东理工大学 交通与车辆工程学院,山东 淄博255049)
摘要:传统的车辆运动轨迹特性分析通常采用对其停止点加注语义的方法,该方法存在信息采集繁杂、信息遗漏以及实时处理不方便等问题.为此,提出以GPS轨迹数据中的语义信息为直接挖掘对象,运用马尔可夫链方法推断车辆运动下一停止点的方法.该方法通过辨识车辆停留中的子停留,利用车辆运动轨迹点特征参数(即时速度、停留时长等)进行信息量化,并与构建的判别信息库进行比对,从而挖掘车辆停留中的子停留语义信息.此外,通过划分车辆运行状态层次,统计每个子停留在每个状态层次的出现频率,以此推断车辆的未来停止点.实车测试结果表明,采集数据量越大,状态层次划分的越细,计算结果越稳定;预测范围越小,按照比例还原的电子地图产生的误差越小,所得的预测越准确.
关键词:车辆运动轨迹分析;语义注释;子停留;马尔可夫链
近年来,GPS被广泛使用,从而产生了大量的轨迹数据.轨迹数据分析研究的趋势已从轨迹几何特性和模式类型分析发展到轨迹数据的语义挖掘,从而实现对轨迹的分析更加深入和全面,也为从GPS轨迹数据中提取人们出行活动信息的研究提供了理论基础[1].2008年,Spaccapietra[2]提出了第一个GPS轨迹语义分析模型SMoT(StopsandMovesofTrajectories),该模型中轨迹由移动和停留组成,其中停留是轨迹具有标志性的部分.此外,一些典型的研究成果有:Wolf[3]提出了推断出行者出行目的的两个重要思路:其一,以出行者出行起讫点的土地利用性质为重要依据推断其出行目的;其二,利用采集到的出行者个人出行信息改善推断出行者出行目的的效果.Griffin[4]使用C4.5决策树算法简单判别规则,建立起出行特性与出行目的的关系.我国学者主要从理论角度归纳和定义与出行目的识别相关的语义信息类型,如华东师范大学的邓中伟等[5]对相关背景信息类型进行了归纳和定义,利用机器学习数据挖掘技术(主要为C5.0算法),依托经验建模的思路,建立了出行目的与多属性变量的关系,进行出行目的的智能化提取;山东理工大学的窦丽莎等[6]提出利用模糊识别算法来推断出行者出行目的.
本文着眼于出行者的微观活动分析与出行目的挖掘研究.以SMoT模型为基础,利用出行者的GPS轨迹信息(考虑到GPS轨迹数据中随机不确定性,以出行者的停留点为观察点),研究推断出行者进一步移动的停止点及相关语义的挖掘方法.为此,提出基于马尔可夫链的推断出行者停止点的新算法,即,通过划分出行者移动状态层次,统计GPS轨迹中出行者在停留点处的状态层次概率分布,计算下一停留点的状态转移概率,以推断出行的下一停留点.
1 出行者出行轨迹数据
1.1出行原始数据的获取
为获得车辆GPS轨迹数据,为试验车辆设计安装了特定的GPS数据采集模块,使其能够进行数据存储和传输.为此,实验数据采集选用GeoLogger和NEVEStepLogger进行试验.对安装了特定GPS设备的试验车进行多轨迹数据采集,并以此作为实验数据.输出的ExcelFile(.csv)格式的GPS轨迹数据包含了轨迹的日期、时间、经纬度、海拔高以及车辆在各个时刻的运动速度等信息.
1.2 数据预处理
目前全球定位系统使用的是WGS-84坐标系,它是一种国际地心坐标系,为方便后期数据处理,需要进行坐标系转换,以WGS84的参考椭圆体为基准进行高斯投影,利用EXCEL简易的进行GPS坐标转换.
对GPS轨迹数据进行语义挖掘,获取出行者信息的过程中,用到一些基本的数据计算,其中比较基本的两个量值是点间距和转向角,它们能够表征轨迹的基本信息.GPS点间距离使用如下公式进行计算[7]:
Δlat=lat2-lat1
(1)
Δlong=long2-long1
(2)
a=sin2(lat/2)+cos(lat1)*
cos(lat2)*sin2(Δlong/2)
(3)
a=sin2(Δlat/2)+cos(lat1)*
cos(Δlat2)*sin2(Δlong/2)
(4)
(5)
D=R*C
(6)
其中R=6 371km.相邻轨迹段的转向角反映了轨迹运动的趋势,连续轨迹段在轨迹点处的夹角表示为α,轨迹的转角表示为θ,夹角α和转角θ关系如图1所示,计算公式如下:

(7)

(8)

图1 轨迹转角示意图
2 判别信息库的建立及停留点的辨识算法
2.1判别信息库构建
GPS记录的轨迹数据中必然有明确的起迄点,其中迄点即为停留.如果为多目的出行,那么在整个行程中的GPS轨迹数据中必然会有多个起迄点,整个行程中的这些迄点即为子停留.无论停留还是子停留都隐含着出行者的某种目的,因此必然对应与目的相关的地理位置.通过将停留或子停留与GIS相匹配,以停留或子停留点为中心,以适当的步行距离(如5~10m)为半径,寻找停留或子停留附近的实际地理环境,以此将没有语境意义的GPS数据点语义化,并根据子停留语义信息,获得子停留的活动类型.
判别信息库是停留与子停留语义活动类型的集合.为此,根据GPS数据特征,选取Time(时长)、Speed(平均速度)、Direction(平均转角)3项作为子停留活动点的特征参数来构建判别信息库.通过进行大量的出行调查和分析,获取居民出行的各种出行目的类型和与之对应的特征参数值,从而确定判别信息库的特征参数阀值.再利用子停留的特征参数值与确立的特征参数阀值进行对比,获知子停留活动类型.例如对办公大厦进行信息库构建时,通过调查可得主要的子停留活动类型为上班、临时办公.通过GPS和室内定位系统获取的数据可得一系列的子停留,将子停留的特征参数与之前调查所得的特征参数阀值相对比可得:停留时长大于8h,平均速度为0,平均转角为0,则可判断为上班;停留时长大于0.5h,平均速度小于1.5km/h,平均转角小于45°,可以判断为临时办公(路过)(见表1).
表1办公大厦判别信息库

活动点特征参数活动类型Min-Time/hMax-Speed/km·h-1Max-Direction/(°)0.581.50450路过上班
2.2算法
利用IB-SMoT算法得到轨迹中的停留后,与电子地图相结合选择合适的判别信息库k-base,然后运用DBSCAN和CB-SMoT算法确定子停留后,将子停留特征参数与给定的特征参数阀值进行对比获知出行目的,算法具体过程见表2.
3 下一停留点推断
通过以上算法,可以从已有轨迹数据中提取出行者的出行目的.由于出行者的出行目的有较大的随机性,为此运用马尔科夫模型对出行者未来活动进行预测与推断,即对出行者下一停留地进行推断.
3.1模型条件
系统在每一时刻(或每一步)上的状态,仅仅取决于前一时刻(或前一步)的状态.这个性质称为无后效性,即所谓的马尔可夫假设.具备这个性质的离散型随机过程,称为马尔可夫链[8]. 用数学语言来
表2子停留辨识及目的推断算法伪代码

PUT: T //一条GPS轨迹数据 k-base //判别信息库OUTPUT: Goal //子停留目的METHOD:Stops->IB-Cluster //运用IB-SMOT算法得出轨迹T的停留subStops->CB-SMOT //运用CB-SMOT算法得出停留中的子停留FOReachsubStopDO //对于每个子停留如下计算timesubStop=endTime-startTime;//停留时长directionsubStop=getDirectionVariation;//停留的平均转角speedsubStop=getSpeedVariation;//停留平均速度FOReachrulerinkBaseDO //对于每条规则r如下运算maxDirectionOfRule=getMaxDirection;maxSpeedOfRule=getMaxSpeed;minTimeOfRule=getMinTime;//获取规则最小时长、最大速度、最大转角的量值IF(timeStop≤minTimeOfRuleANDspeedStop≤maxSpeedOfRuleANDdirectionStop≤maxDirectionOfRule) s.addGoal(r.getGoal);//规则r对应的目的就是子停留s的目的 ENDIFENDFORENDFORENDMETHOD
描述即
如果对任一n>1,任意i1,i2,…,in-1,j∈S恒有
P{Xn=j|X1=i1,X2=i2,…,Xn-1=in-1}=
P{Xn=j|Xn-1=in-1}
(9)
则称离散型随机过程Xt,t∈T为马尔可夫链.
3.2数据处理
原始的车辆GPS轨迹输出如图2所示,根据前面所述可以判断轨迹点密集区域为停留和子停留,在进行模型构建时,将停留与子停留区域简化为点集.由于新的点集轨迹高程坐标波动范围大,因此轨迹跨越区域大.在进行活动状态层次划分时,如此大区域跨度,如若划分较少的状态层次,则预测精确度会降低;如若划分较多状态层次,则计算量会大大增加,给预测带来不便.针对上述问题,需要对原始GPS轨迹数据进行预处理.这里利用前后两点位置高程坐标取平均值法,使得轨迹的跨度范围缩小,方便进行层次划分,具体方法如图3所示.
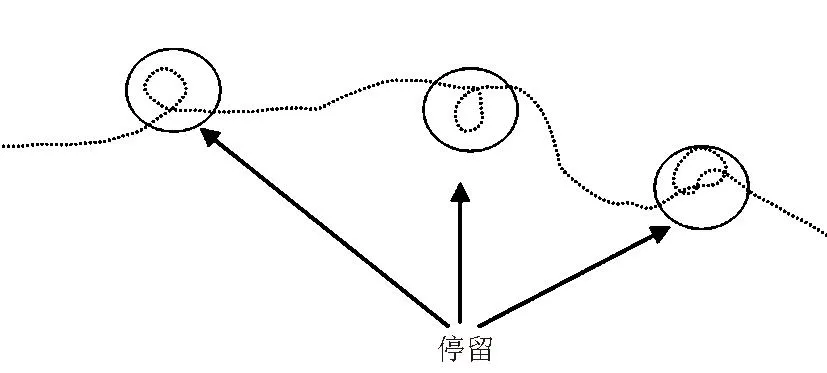
图2 原始车辆轨迹图

图3 模型数据处理图
3.3模型应用
选定同一经度的4个点作为实验的坐标原点,令安装有特定GPS设备的试验车从距离坐标原点一定距离的起点出发,然后到达某一终止点(本文选取山东理工大学西校区某3处建筑作为试验起点,另选取淄博人民公园附近3处建筑物作为终点),反复测试,获得大量运动轨迹.然后对运动轨迹数据进行预处理,从中找出运动轨迹数据中最大值与最小值.以最大值和最小值作水平线,并以此为界线将轨迹数据区域划分为4个状态层次:状态1、状态2、状态3和状态4.通过选取一个小时的实验时间段,以10min为间隔阀值,将实验时间段划分为6个运动周期进行分析,如图4所示.
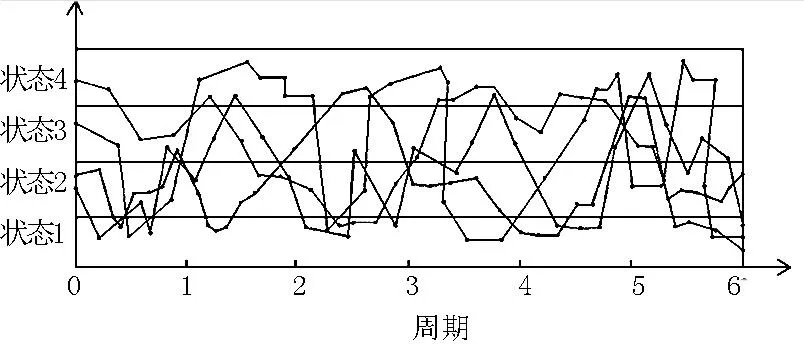
图4 状态层次图
在进行系统预测时,首先假定:
(1)预测期内系统状态数保持不变.
(2)系统的状态转移概率矩阵不随时间而变化.
轨迹在t=0时处于4个状态的概率是相同的,即起点的选取是随机的.因此,初始状态概率向量可定义为
P(0)= (p1(0),p2(0),p3(0),p4(0)=
(0.25,0.25,0.25,0.25)
设轨迹在ti时刻处于状态层次j(j=1,2,3,4),在ti+1时刻处于层次kj+1,就说明轨迹进行了状态转移,记状态转移概率为pij,则
pij≥0,i,j,=1,2,3,4

(10)
各个状态转移概率矩阵P为
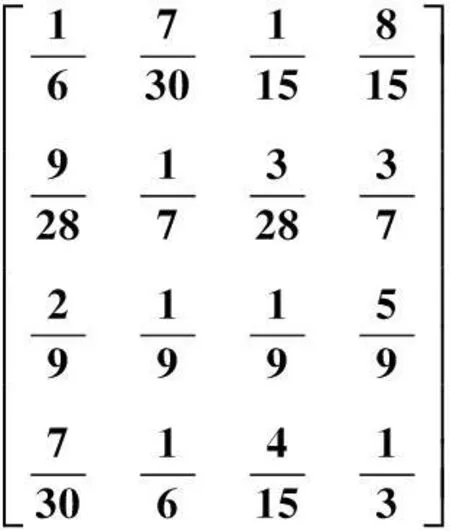
(11)



转化为矩阵形式为
P(k)=Pk,k≥1
在进行7步预测时可具体为P(7)=P7.如果已知转移矩阵以及初始状态概率向量,则任意时刻的状态概率分布可以确定为
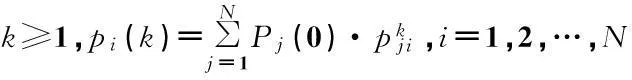
若记向量P(k)=(p1(k),p2(k),…,pN(k)),
则上式可写为
P(k)=P(0)P(k)=P(0)P(k).此时,进行第7步的状态预测,即对模型进行7步状态转移,得到
P(7)=P(0)P(7)
将P(0)和P(7)代入,可得
[0.230 9 0.168 7 0.167 5 0.432 8]
(12)
由上述计算结果可知,实验进行至第7步时,第1层系统状态概率为0.230 9,第2层系统状态概率为0.168 7,第3层状态概率为0.167 5,第4层状态概率为0.432 8.第4层次的概率明显高于前3个层次,因此可以推断实验在第7步时处于第4个层次的可能性最大.通过计算各层次的概率,在电子地图上按比例将各层次所表示区域范围表示出来,找到该范围内实际语义的地理环境,即车辆可能的下一目的地.
如图5所示,根据上述状态层次概率计算结果,结合校园电子地图可推断实验在第8步时,可能由山东理工大学东校移动到淄博人民公园西侧的猪龙河.

图5 试验车在第8个周期时的停留地
4 结束语
本文提出的推断出行目的方法,打破了通常使用轨迹宏观背景信息的惯例,从轨迹数据的语义挖掘中吸取精华,在出行起讫点(停留)基础上更进一步挖掘子停留语义信息,并用活动点特征参数对信
息进行量化,利用子停留语义这一微观信息推断出行目的,并结合马尔科夫链的相关研究,对轨迹数据进行状态层次划分,推断出行下一停留点.该方法与传统算法相比,对轨迹的研究更加深入细致,但其也有局限性:(1)要想获得较为理想的结果,应在海量数据支撑的条件下构建判别信息库,这是一项长期而又浩繁的工作,而且实现难度较大;(2)准确性不够高,因为一个子停留也可能符合判别信息库中的多条规则,使得出行目的的推断有时显得有些模棱两可.
充分利用现有空间轨迹数据资源,智能化的提取出行信息,是一个前沿的研究领域.出行信息包括大量内容,又因从枯燥的轨迹活动点数据中挖掘语义信息本身就是复杂的系统问题,因此有效利用空间轨迹数据推动交通调查的智能化任重而道远.
参考文献:
[1]陈锦阳,刘良旭,宋加涛,等. 基于R-tree的高效异常轨迹检测算法[J].计算机应用与软件,2011, 28(10): 34-37.
[2]Spaccapietra S, Parent C, Damiani M L,etal. A conceptual view on trajectories[J]. Data and Knowledge Engineering,2008, 65(1):126-146.
[3]Wolf J L. Using GPS data loggers to replace travel diaries in the collection of travel data[D]. Atlanta: Georgia Institute of Technology, 2000.
[4] Griffin T, Huang Y, Halverson R. Computerized trip classification of GPS data[C]//2006-3rd International Conference on Cybernetics and Information Technology Systems and Applications. Orlando:CITSA,2006:20-23.
[5] 邓中伟,季民河. GPS轨迹中出行目的提取的一种智能算法[J].中国科技论文在线,2011, 4(12):1 064-1 070.
[6]窦丽莎,曹凯. 出行者子停留语义推断模型框架[J].山东理工大学学报:自然科学版,2012, 26(6): 17-22.
[7]窦丽莎. GPS轨迹信息的语义挖掘[D]. 淄博:山东理工大学, 2013.
[8]张衡. 马尔科夫链的一个应用[J].长春光学精密机械学院学报,1994,17(3):44-49.
(编辑:郝秀清)

AsemanticinferencemodelforstopoftravelerbasedonGPS
LIUChun,CAOKai
(SchoolofTransportationandVehicleEngineering,ShandongUniversityofTechnology,Zibo255049,China)
Abstract:Traditional methods for vehicle trajectory characteristic analysis usually adopt filling the semantic information for the stop point. In this way, many problems have been caused such as making information collection complicate, leaving out information and making inconvenience in real-time processing. Aiming at this problem, on the basis of the above method, this paper puts forward the method of using Markov chain to infer the next stop point of the moving vehicle, based on mining the semantic information hiding in the GPS trajectory data directly. In this method, sub-stops are identified. The characteristic parameters (instant speed, the stay time, etc.) of the points in the vehicle moving trajectory are analyzed. Then, the above information is compared with the k-base to dig the semantic information of the sub-stops. In addition, the next stop point of the moving vehicle is inferred by dividing the vehicle running state level and counting the frequency of the sub-stops in each state level. Real vehicle test results show that the stability of the calculation results is improved by collecting more test data and dicing more state levels. The smaller the predicted range is, the less errors are produced when restoring the electronic map according to the percentage.
Key words:vehicle trajectory characteristic analysis; semantic information; sub-stops; Markov chain
中图分类号:
文献标志码:A
文章编号:1672-6197(2015)04-0048-05
通信作者:
作者简介:刘春,女,liuchun891229@126.com; 曹凯,男,caokailiu@sdut.edu.cn
基金项目:国家自然科学基金资助项目(61074140);山东省自然科学基金资助项目(ZR2010FM007)
收稿日期:2014-10-23
