基于GARCH族模型对我国沪深股市在险价值(VaR)的实证分析
2015-10-11智毓贤陈作章
智毓贤,姚 舜,陈作章
(1.苏州大学 东吴商学院,江苏 苏州215000;2.南京大学 经济学院,南京210000)
【经济与管理研究】
基于GARCH族模型对我国沪深股市在险价值(VaR)的实证分析
智毓贤1,姚舜2,陈作章1
(1.苏州大学 东吴商学院,江苏 苏州215000;2.南京大学 经济学院,南京210000)
近30多年来我国金融市场发展迅猛,金融机构面临的风险主要由信用风险向市场风险。如何构建合适的模型以恰当的方法对市场风险进行测量,是当今金融研究领域的一个热门的话题。在险价值(VaR)方法作为当前比较流行的测量金融风险的方法,具有简单明了的特点。文章运用GARCH族模型对我国沪深两市的VaR值进行实证分析,得出结论:相较于其他的GARCH族模型,TARCH模型拥有最高的准确度;上证综指的VaR值要小于深证成指的VaR值;我国沪深两市都存在一定的波动率非对称效应。
金融风险管理;在险价值VaR;GARCH模型
一、研究背景
金融风险是指金融市场各个构成要素的变动(如金融变量、制度因素、市场主体等)对金融活动的最终结果产生不确定性影响,从而使经济主体遭受亏损的可能性。自上世纪90年代以来,国际金融界经历了许许多多影响巨大的金融灾难。美国奥兰治县政府破产、英国国民西敏寺银行巨额亏损、巴林银行倒闭案件等都说明了市场风险发生频繁。市场风险又称价格风险,是由于金融资产的市场价格变化或波动而引起的未来损失的可能性。如何对市场风险进行精确的测量和评估,如何运用各种金融工具进行风险的规避与转移,成为金融机构风险管理工作的中心。
VaR的直译为“在险价值”,它是指在正常的市场条件和给定的置信水平 (通常为95%或99%)上,某种投资组合在未来特定的一段预期内可能发生的最大损失。相较于传统CAPM模型中使用β系数度量系统性风险,使用σ度量非系统性风险,VaR给出了预期风险的绝对值,具有CAPM模型中方差法所不具有的直观性、简洁性。
VaR在动态监管和量化风险方面的自身优点使得该方法受到各大金融机构的欢迎,目前已被广泛采用。巴塞尔协议(Basel Accord)和欧盟资本充足率指导(EU Capital Adequacy Directive)都已使用VaR作为其监督标准。在中国加入WTO之后,根据巴塞尔协议,国内银行业必须使用VaR框架监控风险。
二、文献综述
自20世纪90年代开始,国外的学者就针对VaR方法自身的评价以及VaR方法的应用效果两个方面进行探讨。对于VaR计算本身,Philippe Jorion对比了假定资产在不同的分布下对VaR值的计算所产生的差别,发现金融资产收益存在着一定的尖峰厚尾分布,需要对传统的正态分布假设做出改进[1]。Hull、White提出了一种新的历史模型法,通过计算当前的波动率与历史波动率的比值,然后再对历史数据进行调整[2]。Guermat、Harris将指数加权移动平均法(EWMA法)引入VaR的计量,从而提出了一种更加稳健型的VaR模型。针对VaR的应用效果,Kupiec通过引入失败天数与失败率,构造出LR统计量的方法来评定VaR模型估计的精确程度。Engle和Bredinctal分别采用了Hendricks1996年提出的均值相对偏差和均方根相对偏差来比较VaR模型。由于不同的市场以及建模的方式不同,各类方法得出的结果也存在着一定的差异,因此没有哪一种VaR模型可以被称为最优模型。
国内对VaR模型的研究始于上世纪90年代末。郑文通、姚刚等首次引入VaR,介绍了VaR方法的研究背景、定义、计算方法、应用领域以及引入国内的必要性。戴国强、徐龙炳、陆蓉运用VaR方法计算了投资组合潜在市场风险的具体方法,介绍了在我国金融市场中VaR模型适用的领域[3]。这时的实证分起步较早,国内的学者们大多使用静态模型计算VaR,即假设资产收益服从某种分布,并有独立同分布的特征,运用静态方差值计算VaR。但随着研究的进一步深入,许多学者发现金融资产收益并不服从正态分布,进而对VaR的计算多从条件方差的角度刻画。范英[4]、张宗益等人,在假定残差服从正态分布假设下,分别采用EWMA法与GARCH模型等来刻画条件方差,并计算了中国股市上证综指与深证综指的VaR值。此后,又有学者对GARCH模型和资产收益分布加以修正,在假定资产收益服从t-分布、广义误差分布假设下,运用GARCH族衍生模型,对中国股市的VaR进行研究。陆蓉、徐龙炳运用EGARCH模型分别对我国股票市场“牛熊市”阶段对波动的非对称性反应特征进行研究,结果发现我国股票市场波动存在着显著的非对称性[5]。闫志刚对上证指数的每日收盘价进行了GARCH-M建模,在GARCH模型均值方程中加入了方差项,结果显示加入的方差项并不能够很好地刻画我国股票收益和风险之间的紧密联系[6]。因此,GARCH-M模型在我国股票市场并不适用。
本文将综合前人的研究观点将GARCH模型、EGARCH模型和TARCH模型以及相应的均值方程,在正态分布的假设下对沪深两市指数进行建模分析,计算出相应的VaR值,并采用返回检验的方法检验各模型的精确度。
三、模型设定
(一)VaR方法的定义
在金融风险管理领域的权威著作 《风险管理与金融机构》中,Hull是这样定义VaR的:“VaR指在T的时间段,有X%的把握某金融资产的损失不会大于VaR。”这句话表明了VaR是两个变量的函数:时间展望期(T)以及置信度(X%),而VaR对应了在今后T天以及在X%的把握下,交易损失的最大值。用数学表达式表达为(1)式。
Prob(△p>VaR)=1-c(1)
(1)式中,ΔP是指金融资产在未来发生的损失,VaR为在置信度为c水平下的在险价值,c为置信水平。通过对VaR定义的描述可以发现,影响VaR数值大小的因素有:资产持有期、置信度和资产收益分布状况。
(二)计算VaR的参数选择
1.资产持有期选择
资产持有期指未来持有时金融资产的间跨度。一般而言,持有期越长,金融资产的风险越大,从而VaR值也就越大。在假定资产的回报是独立同分布之后,多日VaR可以通过单日VaR乘以持有天数的平方根得出,如(2)式。
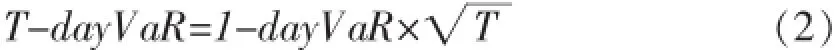
本文计算单日VaR,相应T取1。
2.置信度的选择
由VaR的定义可知,置信水平越高,相应得出的VaR值也就越大。金融机构会根据自身的风险偏好、信用评级等级以及其他的因素来确定适用于自身的置信水平。此外,金融机构还会考虑到不同的通途来选择不同的置信水平。当考虑到外部监管要求时,则选择较高的置信水平;考虑到VaR的有效性时,则选择较低的置信水平。本文计算VaR时,采用95%的置信度。
3.资产收益分布
资产收益分布是投资组合在既定的持有期内回报的概率分布,即概率密度函数。由于正态分布在统计上具有诸多良好的特性,所以在实际中通常假定金融资产收益服从对数正态分布的形式。应用正态分布假设对各种金融风险进行建模估计和计算方法都很简单,且行之有效。但这种方法的缺陷在于实际的金融资产分布往往是尖峰后尾,这样就会造成正态分布对极端事件VaR值的低估。为了克服正态分布这一缺点,当前对VaR的研究多假定资产收益服从于t分布或者广义误差分布(GED),但是计算过程却大大繁琐。为了简化起见,本文假定的资产收益服从标准正态分布。
4.VaR的计算方法
(1)一般分布计算法
在不对资产收益分布做出任何假设、最一般的情况下,根据VaR的定义,计算VaR的方法如(3)式。

(3)式中,W0为资产或价值的初始值,E(r)为资产预期收益率,r*为一定置信水平c下的最低收益率。计算VaR相当于计算最低的收益率r*。假定资产未来的收益概率密度函数为f(p),则其在某一置信水平c下的资产收益率最低值r*如(4)式。

(2)正态分布下的VaR计算法
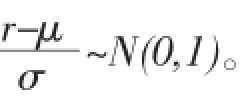

(5)式中,N-1表示累积正态分布的反函数。
考虑到资产的持有期,以及资产的原始价格,可以得到更一般的资产收益的VaR计算公式,如(6)式。
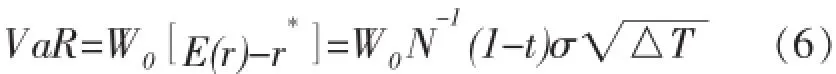
(6)式中,W0是资产的初始价格,△T是资产的持有期。
本文中假定资产持有期为1天,设定t为95%置信度下的股指收益率VaR值为(7)式。

从而将计算股指收益率VaR值转化为股指收益的标准差σ的计算。
(三)VaR的参数估计
以下对本文使用的参数估计模型进行介绍。
1.GARCH模型
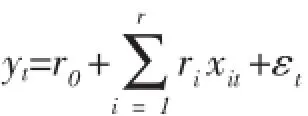
t,ARCH(p)模型
包含了以下两个方程,如(8)式和(9)式所示。
模型通过对历史收益率平方的移动平均,把金融资产收益率的条件异方差纳入分析,如果在前期市场发生了很大的波动,无论朝哪个方向,误差的平方值将变大并且导致当期的条件方差也变大。可见,ARCH模型较好地刻画金融资产收益率的丛集性效应。
在Engle的基础之上,Bollerslev T.对ARCH模型进行改良,在ARCH(p)模型中加入了q个自回归项,推广成为广义ARCH模型(Generalized ARCH,简称GARCH(p,q)模型)[8]。可以使用较为简单的GARCH模型来代表一个高阶ARCH模型,使待估参数大为减少,从而使模型的识别和估计都变得较为容易,解决了ARCH模型的固有缺点。GARCH(p,q)模型的条件方差方程如 (10)式。
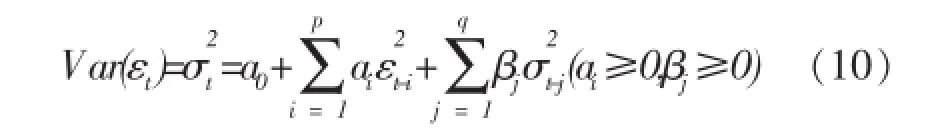
2.EGARCH模型
GARCH模型在金融领域的运用中,依旧存在一定的缺陷。第一,GARCH模型的条件方差方程要求估计参数非负,过度的限制了条件方差的动态性;第二GARCH模型中σ2t是εt-i的对称函数,即条件方差σ2t取决于εt-i的大小,而与其符号无关。实际意义指金融资产收益的正向收益和负向收益对条件方差的冲击都是一样的,这显然与现实不同。现实的金融市场上存在着杠杆效应,在牛市的时候,投资者普遍投资热情高涨,对资产收益的风险视而不见,因此正向收益的冲击要高于负向收益;在熊市的时候,投资者普遍情绪低落,投资的热情不高,对市场不具有信心,因此负向收益带来的冲击要高于正向收益。为了解决以上正负两类残差的非对称反应,Nelson提出了指数GARCH模 型(ExponentialGARCH,简 称EGARCH)[9],以更准确地刻画现实股票的波动性。其方差方程如(11)式。
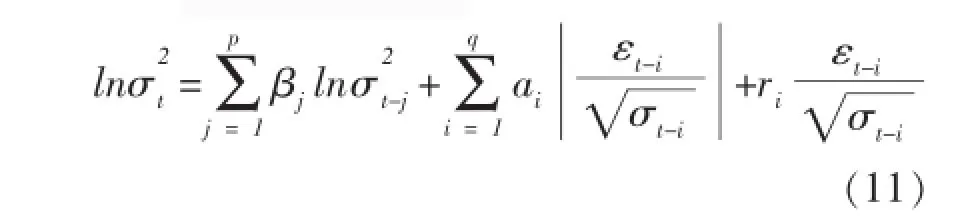
EGARCH模型中条件方差采用了自然对数,意味着σt,正负两类残差的非对称性反应体现在参数ri上,若ri≠0,则说明信息作用非对称。当ri<0时,说明股市的负收益对条件方差的冲击要比正收益大;当ri>0时,则说明股市的正收益对条件方差的冲击要比负收益大。
3.TARCH模型
与 EGARCH模型类似,Zakoian和 Glosten、Jafanatan、Runkle独立提出的另一种反应条件方差非对称模型为门限GARCH模型(Threshold ARCH,简称TARCH模型)[10]。TARCH模型的条件方差方程如(12)式。
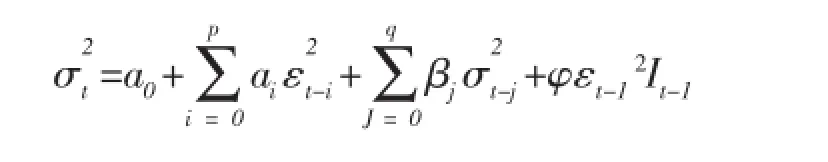

(四)VaR模型的准确性检验
VaR模型的准确性检验是指VaR模型的测量结果对实际损失的覆盖程度。若计算出的VaR值小于实际的发生的损失,则会降低金融机构资产的安全性;若计算出的VaR值大于实际发生的损失值,则会导致金融机构资产的收益性降低。常用的衡量VaR模型准确性的检验方法之一Kupiec提出的失败频率检验法[4]。他假定VaR具有时间独立性,实际损失超过VaR记为失败,实际损失低于VaR记为成功。失败的期望概率P*= 1-c(c为置信度),实际考察天数为T,失败天数为N,则失败频率为P=N/T。零假设为P=P*。因此对VaR模型的准确性的评估就转化为检验失败频率P是否显著不同于P*。Kupiec构造的统计量LR值可以对零假设进行检验,如(13)式。
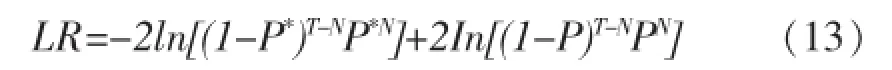
零假设条件下,LR统计量服从自由度为1的卡方分布。
四、实证分析
(一)数据选取与时段选取
1.样本数据来源选取
由于中国的股市并不存在单一的权威市场指数数据,上海证券交易所和深圳证券交易所分别根据本身的上市股票建立起了一套指数体系。根据研究需要,顾及到我国股市发展的代表性,本文选取上证综合指数(证券代码000001,记为SHZ)和深证综合指数(证券代码399001,记为SZZ)。从样本的选择范围考虑,样本既能考虑上海证券交易所交易情况,又能反应深圳证券交易所情况;从指数编算角度考虑,既能够反应所有股权,包括流通股与非流通股计算的综合指数(上证指数),又包括仅以流通股计算的成分指数(深证成分指数),从而覆盖面广,代表性强,可以作为我国股市的代表。
2.分析时段选取
最近一轮的牛市始于2014年11月21日,结合样本数据研究的实际意义以及研究的时间跨度,本文选取2013年5月20日至2015年5月20日之间488个交易日的收盘价格作为研究样本。
本文的数据来源于“国泰安”中国股票研究市场交易数据库(CSMAR),统计软件选择eviews7.0进行。
(二)数据基本分析
1.各股的收益率形式。
本文的指数收益率选择对数收益率形式,如(14)式。

(14)式中,rt表示在第T天的指数收益率,Pt表示第t天的指数收盘价,Pt-1第t-1天的指数收盘价。将上证指数对数收益记为RSHZ,深证成指对数收益记为RSZZ,运用eviews软件对样本对数收益率进行处理,得到样本收益率波动图,如图1、图2。
由图1和图2的对数收益率可以看出,上证综指和深证成指的对数收益波动性比较平稳,一次大的波动之后往往伴随着较大的波动,一次小的波动之后也往往伴随着较小的波动,因此可以说明上证综指和深证成指的收益率存在着丛集性效应。
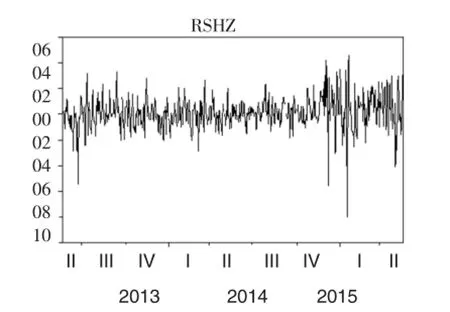
图1 上证综指对数收益率波动图
2.各股指对数收益率的描述性统计特征
根据表1各股指描述性统计量可知,上证综指收益率的偏度为-0.58170,深证成指的偏度为-0.27610,两者偏度均小于0,这说明两者收益率均存在左拖尾现象,即两个市场低于平均收益率的天数要比高于收益率的天数多。上证综指的峰度为7.82027,深证成指的峰度为5.38624,两者峰度都大于3,这说明两个市场的收益率都比正态分布更集中,分布呈尖峰分布的形状。上证综指的J-B检测值为498.942,深证成指的J-B检测值为121.731,两者的伴随概率都为0.00000,都小于5%的置信度,从而说明沪深市场的收益率都不是呈正态分布。
3.各股指对数收益率平稳性检验
在对时间序列进行分析之前,应该确定所使用的时间序列是否是平稳的。如果一个时间序列的均值或者协方差函数随着时间而改变,那么这个系列就是非平稳的,分析就存在“伪回归”现象。对上述沪深两市指数进行ADF检验,其检验结果如表2所示。
由表2可知上证综指和深证成指的ADF统计量均远小于1%标准下的t值,拒绝序列随机游走的原假设,因此可知对数收益率时间序列在1%的标准下是十分显著平稳的。
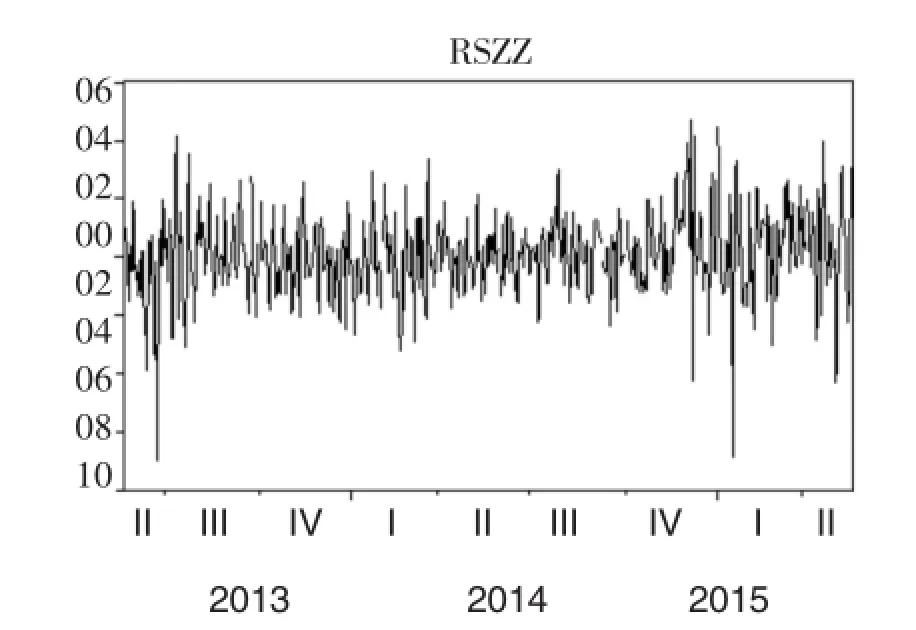
图2 深证成指对数收益率波动图

表1 各股指对数收益率的描述性统计量

表2 各股指收益率ADF检验结果
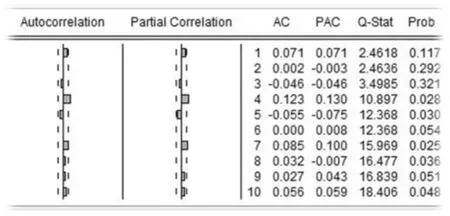
图3 上证综指对数收益率自相关图
4.各股指对数收益率的自相关性分析
对各股指对数收益率的10阶滞后量求自相关函数和偏自相关函数,结果如图3和图4所示。
由图3可知上证综指在低阶自相关性不显著,但是在高阶后呈若自相关性;深证成指的无自相关性较好,高阶低阶都可视为不存在自相关。总体而言,沪深两市对数收益率都可视为不存在自相关。
5.各股指对数收益率异方差检验
根据以上分析可知,沪深两市对数收益率为平稳序列,且不存在自相关,所以收益为一般均值回归方程,如(15)式。

(15)式中,εt为白噪声。
从直观上看,沪深两市对数日收益存在丛集性效应。因此,对沪深两市对数收益率进行10阶LM异方差检验,检验结果表3、表4所示。
上证综指收益序列和深证成指收益序列的TR2值分别为51.94339和23.38968,伴随概率分别为0.0000和0.0093,均小于0.05的置信度,因此这两个序列都拒绝了不存在ARCH效应的原假设,说明这两个序列的残差都是存在ARCH效应的。
(三)GARCH模型建立
1.GARCH(p,q)参数选择
分别将GARCH(1,1)、GARCH(1,2)、GARCH (2,1)、GARCH(2,2)代入模型建模,相应AIC与SIC信息准则如表5所示。
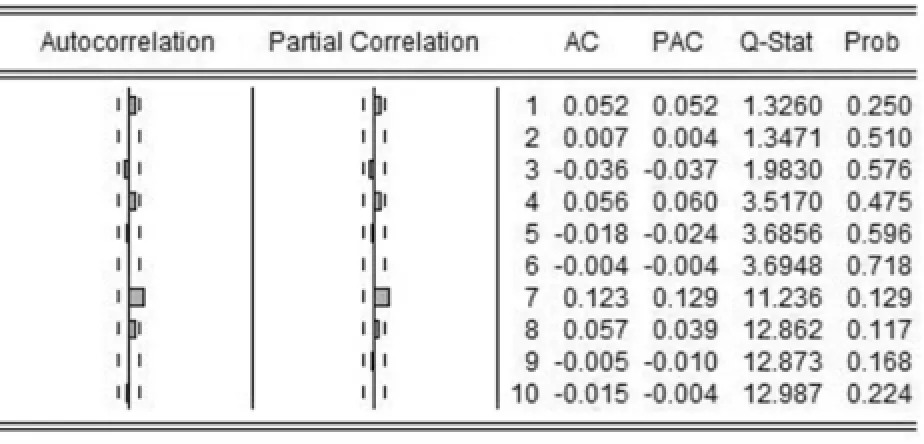
图4 深证成指对数收益率自相关图
综合考虑四种模型的AIC、SIC信息准则 (越小越好),以及模型回归相应系数的显著性,判断GARCH(1,1)比较合适,因此以下所有GARCH及其衍生类模型均选择GARCH(1,1)类模型。
2.GARCH族模型回归结果
在GARCH(1,1)的模型设定下,各模型的条件方差方程如(16)式、(17)式和(18)式。
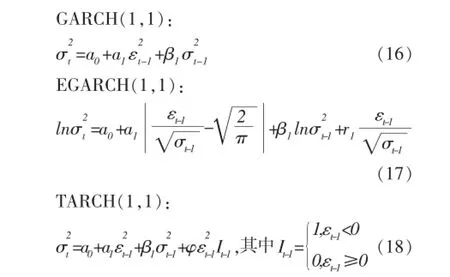
在正态分布假设下,各指数GARCH族模型回归结果如表6所示。
以下是上证综指各个模型的估计结果,如(19)、(20)、(21)、(22)、(23)和(24)所示。
GARCH(1,1)
均值方程:
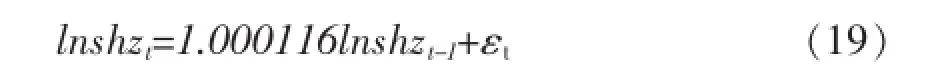
条件方差方程:
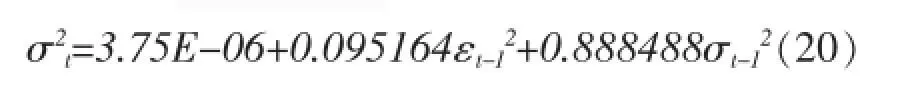
EGARCH(1,1)
均值方程:
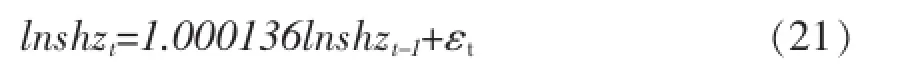
条件方差方程:

表3 LNSHZ ARCHLM检验

表4 LNSZZ ARCHLM检验
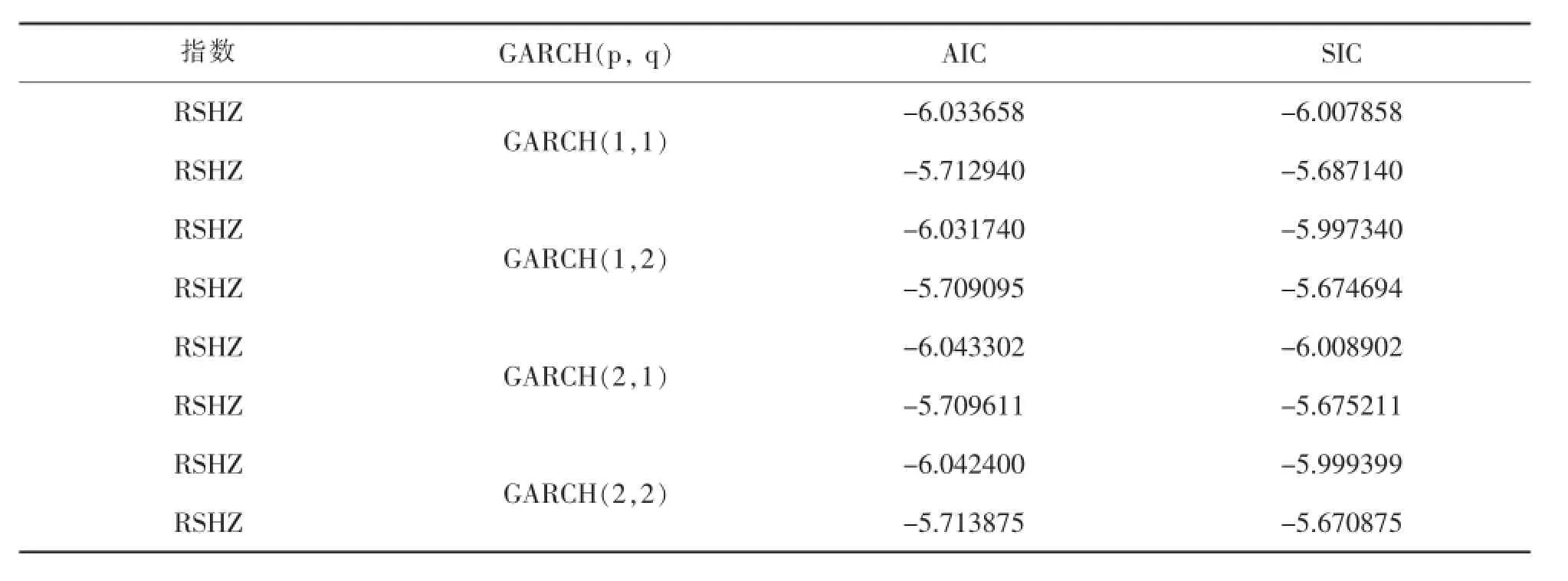
表5 RSHZ和RSZZ信息准则
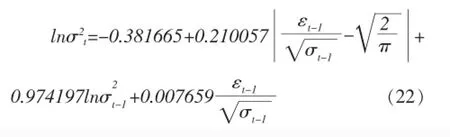
在EGARCH模型中,当出现一个利好消息时,会对条件方差对数带来0.217716(0.210057+0.007659)倍的冲击;而出现利空消息,则会带来0.202398 (0.210057-0.007659)倍的冲击。说明在上证市场上,利好消息带来的冲击要比利空消息大。
TARCH(1,1)
均值方程:
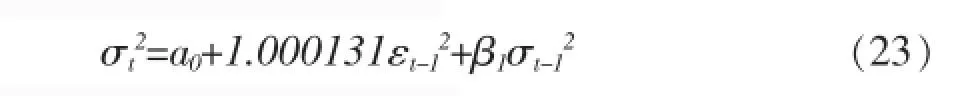
条件方差方程:
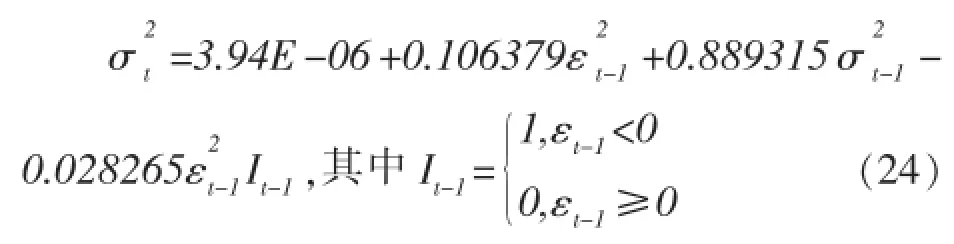
在TGARCH模型中,当出现一个利好消息时,会对条件方差对数带来0.106379倍的冲击;而出现利空消息,则会带来0.078114(0.106379-0.028265)倍的冲击。同样也说明了在上证市场上,利好消息带来的冲击要比利空消息大。
(2)以下是深证成指指各个模型的估计结果,如(25)、(26)、(27)、(28)、(29)和(30)所示。
GARCH(1,1):
均值方程:
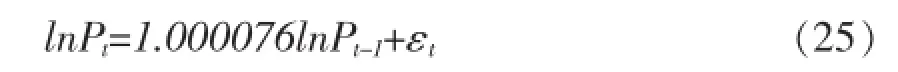
条件方差方程:
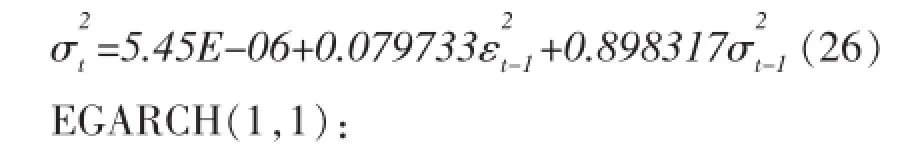
均值方程:
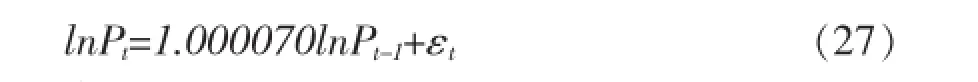
条件方差方程:
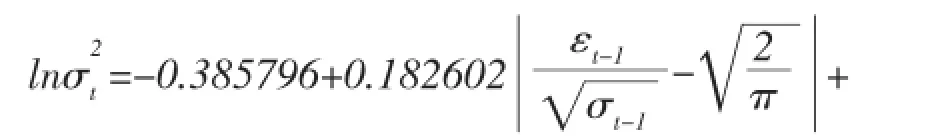
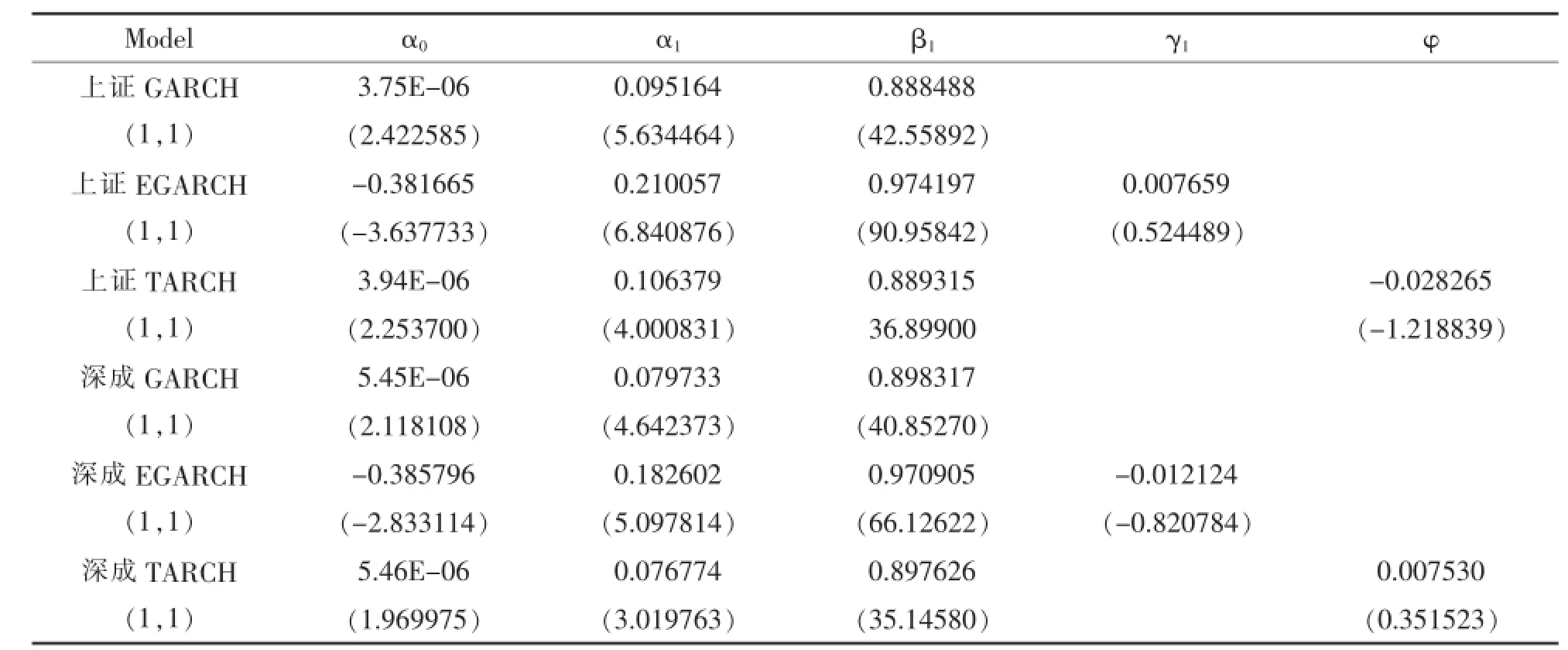
表6 正态分布假设下各指数GARCH族模型回归结果
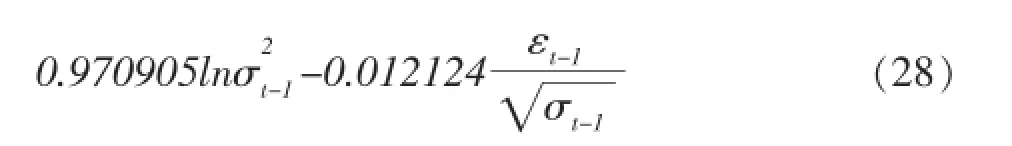
在EGARCH模型中,当出现一个利好消息时,会对条件方差对数带来0.170478(0.182602-0.012124)倍的冲击;而出现利空消息,则会带来0.194726(0.182602+0.012124)倍的冲击。说明在深成市场上,利空消息带来的冲击要比利好消息大。
TARCH(1,1):
均值方程:
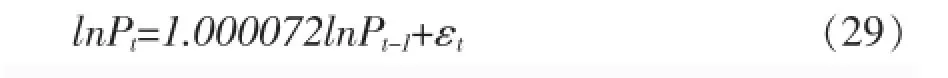
条件方差方程:
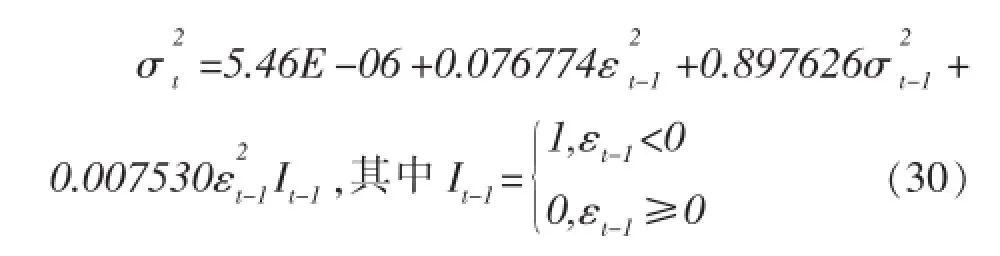
在TGARCH模型中,当出现一个利好消息时,会对条件方差对数带来0.076774倍的冲击;而出现利空消息,则会带来0.084304(0.076774+ 0.007530)倍的冲击。同样说明了在深成市场上,利空消息带来的冲击要比利好消息大。
3.ARCH LM检验
将以上两个模型的GARCH族模型分别进行10阶ARCHLM检验,将所得结果与原方程和临界值比较如表7所示。
从表7可以看出上证综指和深证成指的GARCH、EGARCH、TARCH模型的LM检验的TR2都小于临界点,因此方程不接受存在ARCH效应的原假设,这说明经过GARCH族建模后,原方程中的条件异方差现象基本消除,达到了建模的目的。
4.VaR计算结果与分析
本文选取2013年5月20日至2015年5月20日之间488个交易日的收盘价格来计算VaR值,为了简化计算,本文假定上证指数和深证成指的收益率分布呈正态分布,因此,应用GARCH族模型计算VaR的公式如(31)式。

(31)式中VaRt表示某个特定交易日的在险价值,表示在置信水平为(1-α)正态分布分位数,本文选取95%的置信区间,则为持有期的平方根,则日在险价值的△T=1。
各股指的VaR计算结果描述性统计量如表8所示。分析表8可知,在上证指数方面,GARCH模型算出的每日VaR值要高于其他两个模型,其标准差也是最大的;在深证成指方面,TARCH模型算出的每日VaR值高于其他的两个模型,标准差也是最大的。而从上证指数个深证成指两个指数的比较可知,无论是哪种计算方法,深证成指的VaR值都要高于上证指数,这说明了深证市场的波动性要比上证市场强,相应的风险也就更高。
5.模型的准确性检验
运用Kupiec提出的失败频率检验法,检验结果如表9所示。
由表9可以看出所有指数使用GARCH类模型计算出的VaR值相应的LR值均小于临界值,说明这些模型都通过了模型的准确性检验。在上证指数中,GARCH和TARCH模型计算出的VaR实际失败率高于期望失败率,因此低估了风险;EARCH模型计算出的VaR实际失败率低于期望失败率,因此高估了风险。在深证成指中,所有的模型均计算出的VaR均低于理论中,说明所有模型均低估了风险。
对比每种模型的LR值发现,对于上证指数,精确度最高的模型是GARCH和TARCH模型,而对于深证成指而言,精确度最高的模型是TARCH模型。
五、结论分析
根据以上实证分析的结果,通过比较同一证券指数不同GARCH类模型计算出的VaR结果,对比同一GARCH类模型不同证券指数,可以得出以下结论。
第一,综合上证指数和深证成指来看,TARCH模型的模拟准确度要优于其他的GARCH族模型。TARCH刻画了上一期市场的利好消息(εt-1>0)和利空消息(εt-1<0))给本期的方差带来的非对称性影响,这说明了我国沪深两市市场存在着一定的消息非对称性。
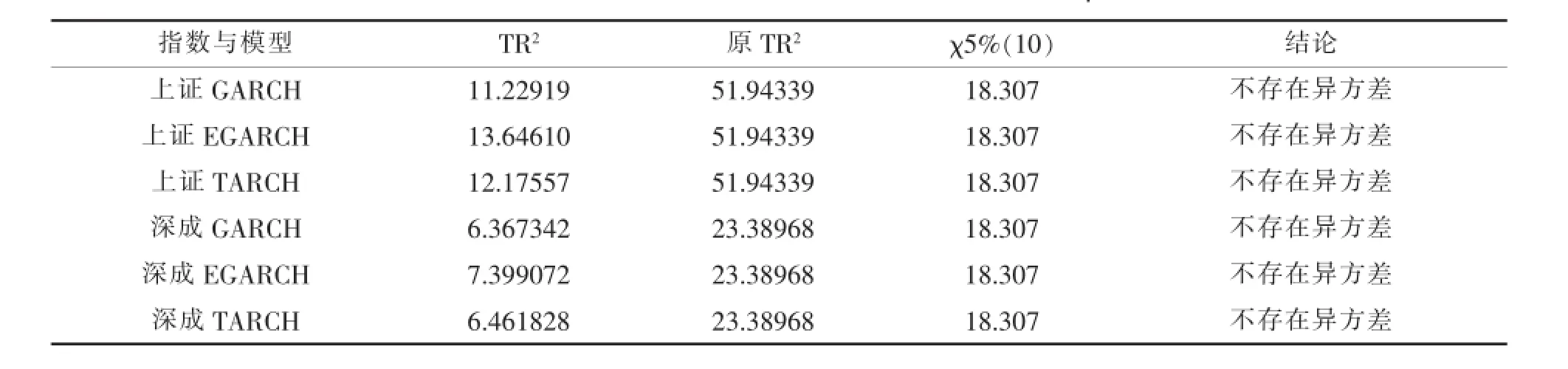
表7 GARCH族模型回归LM检验结果指数与模型q
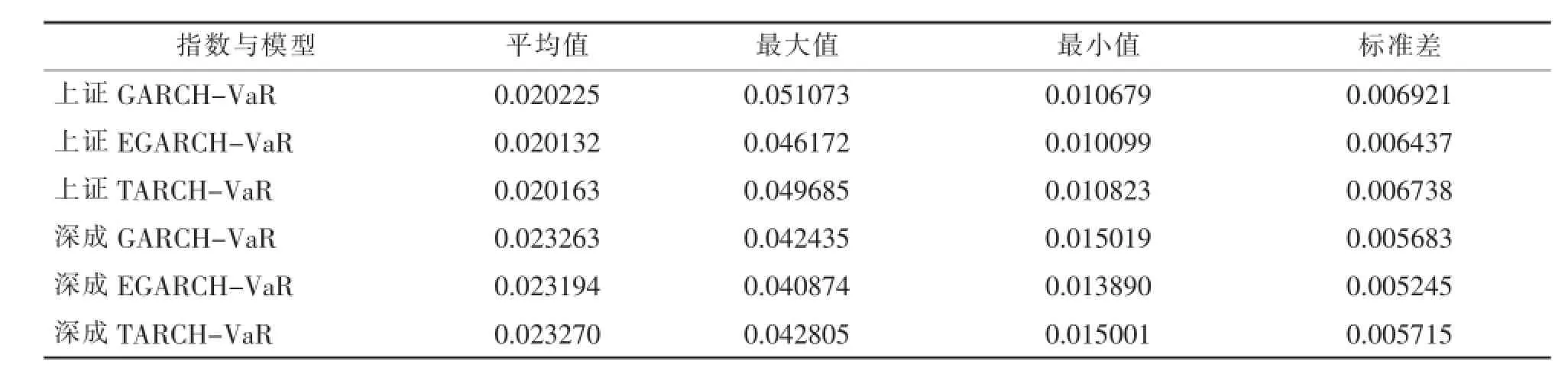
表8 各股指VaR描述性统计量

表9 各股指Kupiec检验结果
第二,综合各种模型所求出的VaR来看,上证综指的VaR要小于深证成指的VaR。本文中的VaR指在95%的置信区间内,投资者日损失要小于VaR值。这说明了上证市场的波动率要小于深证市场的波动率,因此投资于深证市场的投资者承担的风险要比上证市场投资者承担的风险大。
第三,从上证指数EGARCH和TARCH模型来看,上期利好消息带来的对本期条件方差的冲击要比利空消息的冲击大;从深成指数EGARCH 和TARCH模型来看,上期利好消息带来的冲击要比利空消息带来的冲击小。合理的解释是由于上证指数的波动率小于深证成指的波动率,每当利好消息来临时,因为上证市场风险较小,投资者情绪比较乐观,对市场出现的利好效益反应强烈,而由于深证市场的风险较大,但投资者却相当谨慎,对市场的反应不如上证市场强烈。相反,当利空消息来临时,深证市场的高风险增加了投资者的恐惧,市场抛售压力增大,股价迅速下跌,波动加剧,而由于上证市场的风险较小,投资者对股价下跌的反应却不如深证市场强烈。
[1]Jorion P.Risk:Measuring the risk in value at risk[J]. Financial Analysis Journal,1996(12):57-56.
[2]Hull,White.Incorporating volatility up datinginto the historical simulation method of value at risk[J].Journal of Risk,1998.
[3]戴国强,徐龙炳,陆蓉.VaR方法对过金融风险管理的借鉴及应用[J].金融研究,2000(7):45-51.
[4]范英,VaR方法在股市风险分析中的运用初探[J].中国管理科学,2000(3):26-32.
[5]陆蓉,徐龙炳.中国股票市场对政策信息的不平衡性反应研究[J].经济学,2004(2):319-330.
[6]闫志刚.上海证券市场GARCH效应检验和模型选择[J].统计与信息论,2005(1):66-69.
[7]Engle R F.Autoregression conditional heteroskedasticity with estimates of the variance of united kingdom inflation [J].Econometrica,1982:478-485.
[8]BollerslevT.Generalizedautoregressiveconditional heteroskedasticity[J].Journal of Eeonometries,1986(31):307-327.
[9]Ne1son D B.Conditional heteroskedastieity in asset returns :A new approach[J].Econometrica,1991,59(2):347-470.
[10]Zakoian J M.Threshold heteroscedastic models[J]. Journal of Economic Dynamics and control 1994(18):931-944.
(编辑:张薛梅 徐永生)
AnEmpiricalAnalysisoftheVaRofChina’sShanghai&ShenzhenStock MarketsinTermsofGARCHFamilyModel
ZHI Yu-xian1,YAO Shun2,CHEN Zuo-zhang1
(1.Dongwu Business School,Soochow University,Suzhou 215000,China;2.School of Economics,Nanjing University,Nanjing 210000,China)
China’s financial market has been developing at a high speed in the last 30 years,and the major risks that financial institutions are faced with are shifting from credit risks to market risks.As a result,constructing a proper model to measure the risks of the financial market has become a hot topic in the researches into finance.As a popular method adopted for the measurement of financial risks,VaR is both simple to handle and easy to understand.Based on an analysis of the VaR of China’s Shanghai&Shenzhen Stock Markets in Terms of GARCH Family Model,this paper concludes that,compared with other GARCH family models,TARCH model bears the highest accuracy,that the VaR of the composite index of Shanghai Stock Market is lower than the VaR of finite index of Shenzhen Stock Market,and that both Shanghai and Shenzhen Stock Markets bear a certain asymmetric effects in terms of fluctuation ratio.
Financial risk management;VaR;GARCH model
F 830.91
A
1671-4806(2015)05-0001-09
2015-07-05
智毓贤(1994— ),男,江苏泰州人,助理会计师,研究方向为证券投资;姚舜(1994— ),女,江苏泰州人,研究方向为理论经济学、服务经济学;陈作章(1959— ),男,陕西西安人,副教授,硕士研究生导师,研究方向为金融理论与货币政策、区域融资。
