大量网络游记文本中热度地名提取方法与实证研究
2015-06-07李照航,郭风华,李仁杰,3*,傅学庆,3,严正峰,3
李 照 航,郭 风 华,李 仁 杰,3*,傅 学 庆,3,严 正 峰,3
(1.河北师范大学资源与环境科学学院,河北 石家庄 050024;2.河北省科学院地理科学研究所,河北 石家庄 050021;3.河北省环境演变与生态建设实验室,河北 石家庄 050024)
大量网络游记文本中热度地名提取方法与实证研究
李 照 航1,郭 风 华2,李 仁 杰1,3*,傅 学 庆1,3,严 正 峰1,3
(1.河北师范大学资源与环境科学学院,河北 石家庄 050024;2.河北省科学院地理科学研究所,河北 石家庄 050021;3.河北省环境演变与生态建设实验室,河北 石家庄 050024)
探讨网络游记文本中的地名使用特征及其研究意义,地名使用状态的定量特征能够反映游客对旅游地景观的认知结构与旅游行为的一般过程。在现有中文分词技术基础上,结合游记文本中的地名使用特点,选用ATF*PDF方法计算特征词汇在整个旅游文本集中使用状态的综合权重,设计了一种基于大量网络游记文本的热度地名自动提取方法,为不使用自定义地名库的旅游地理研究奠定了基础。以游客点评网游记为样本的实验证明,该方法能够实现旅游相关地名的快速提取,地名使用热度越高,提取准确率越高;对地名提取结果的类型结构分析发现了自然和人文旅游地游记在词汇使用方面的共性和差异,指示了旅游文本地名的分布意义及其对旅行过程其他信息解读的潜在价值,预示了网络游记文本在进一步解析旅游者的旅游地认知特征和旅游行为过程方面的科学意义。
网络游记文本;热度地名;ATF*PDF模型;多样本集合共现
0 引言
网络游记是旅游者基于自身旅游体验主动发表在互联网中主要描述旅行过程和感受的文本,其相比问卷调查和访谈更能够代表游客的真实态度[1],可以作为旅游地研究的重要数据来源[2]。目前,国内外以互联网游记文本为数据源的旅游地研究越来越多,主要关注旅游者行为及其对旅游地整体的认知和情感特征[3]。例如,选择互联网内容分析方法,通过旅游文本中的高频特征词研究旅游者行为特征[4]和旅游地整体形象认知[5-7];深入分析旅游文本在游客地方感构建中的作用[8]及其对旅游目的地形象形成过程的影响[9,10]。总体看,现有研究主要关注大中尺度的区域旅游,或从整体、全局视角对特定旅游地开展研究,缺少对旅游地内部景观尺度及其与外部旅游空间关系的关注。
地名(本文中既包括旅游地及相关地名,还包括旅游地内部景观名称)在游记文本描述中起主线作用,游记中的地名可用于区分旅游者对旅游地不同区域和景观的认知评价单元,对旅游地内部小尺度景观认知与旅游行为的空间分异研究具有重要意义。不同作者撰写的同一旅游地游记文本的集合具有相同的描述对象,可以作为地名使用特征挖掘的重要数据来源。近年来,从自然语言中解析地名及相关空间信息成为地理信息科学的重要研究内容[11],但从大量旅游者自由撰写的文本中快速提取使用热度较高的特定旅游地相关地名,目前还缺少有效的方法。
本文在现有中文分词方法基础上,结合游记文本中的地名使用特点,尝试设计一种基于大量网络游记文本集合的热度地名提取方法:在有效分词基础上,设计游记文本中地名使用情况的综合权重值计算模型,并构建一种非地名词汇的排除词集合,进而通过热度排序提取出旅游者对某一旅游地关注度较高的景观或旅游地相关地名,即本文中的“热度地名”。通过此方法提取出的旅游景观与相关旅游地名可用于旅游地名数据库的自动构建[12]。大量网络游记文本中共同表征的定量化地名使用状态也是旅游者对旅游地认知状态的重要表征,可以为旅游地形象认知度及其内部分异等研究提供方法与数据来源。
1 游记文本中的地名
地名是为了达到表达与沟通目的,对旅游地附近和旅游地内部重要、典型的地形地物或景观等进行的命名[13]。景观与旅游地名是具有不固定、形式多样等特点的临时耦合广义地名[14],一般由旅游规划设计者在规划思想指导下命名,在旅游地发展的过程中逐渐被旅游者所熟悉,如黄山的光明顶、九寨沟的五花海等。互联网游记一般记录了出行的时间和目的地,并比较完整地记录旅行过程中的认知与感受,对旅行过程的描述往往通过地名串联起来。对互联网游记初步分析后发现其中的地名使用存在以下特点:1)相关地名数量大,由于旅游地周边及其内部的地物、景观数量众多,游记文本中也大量出现旅游地相关的地名;2)地名的使用既有共性也有差异,核心、标志性景观与旅游地名称在多数游记中被描述,同时由于旅游者审美视角差异,对旅游地景观的描述有明显个性化特征;3)同一旅游地相关的地名处于动态变化中,随着旅游地不断发展演化,新的旅游景观不断被规划设计者和旅游者发现、命名,并出现在后续旅游者的游记文本中,而缺乏活力的旅游地景观会逐渐被淘汰,失去旅游者的关注;4)地名的使用比较自由,简称、昵称较多,如“布宫”、“九寨”等。网络游记文本中使用地名的上述特点,使得许多旅游地名(尤其是景观名称)在常规的文本分词过程中往往被识别为地名之外的其他词汇。但由于旅游地名在旅游文本中出现的频率非常高,常规分词系统虽然未能将其识别为地名,却能够将其识别为新词,这就为基于大量游记文本的词汇统计特征提取旅游地名提供了可行性。
2 地名提取方法
2.1 方法设计
国内外对于地名提取方法的研究主要集中在规范化地名的自动识别,已达到较高的识别准确率。主要有基于统计模型的地名识别方法,如隐马尔可夫模型[15]、条件随机场等[16],以及在这些模型基础上加以的改进的最大间隔隐马尔可夫模型[17]、篇章关系引入条件随机场的地名识别方法等[18];此外还有结合地名特征词统计特征[19]进行地名识别等方法。上述方法主要针对规范化地名的识别,对于旅游地名和景观名称关注较少,地名时效性较低,简称、别名等非标准地名信息缺失[20]。上述分词方法的分词结果中,人名、地名、机构名等命名实体占文本中未登录词(没有收录在分词词表中但必须切分出来的词)的很大比重[21]。
采用上述分词方法对网络游记文本分词后,大量旅游地名也会归入未登录词。虽然从未登录词汇中难以直接判断哪些属于旅游地名,但从游记文本中的地名使用特点看,如果将同一旅游地的大量游记文本作为一个文本集合,文本分词后未登录词汇中的高频词汇属于该旅游地相关地名的概率较高。综合上述分析和假设,本文提出了基于大量互联网游记文本统计特征的旅游地名提取方法,具体流程如图1所示。首先采集同一旅游地的网络游记形成游记文本集合,并利用现有分词方法对每一篇游记进行分词,对分词结果按照词性进行初步筛选;第二,统计每篇文本中各词汇的频次及总词汇数,选择合适的权重分配模型计算各词汇在整个文本集合中的综合权重值;第三,按照同样方法选择3个以上的旅游地样本进行前两步处理,建立基于多个旅游地文本集合共现的排除词集合;最后,利用排除词集合分别将各样本游记文本词汇集的高频词中包含的少量非地名词汇剔除,就得到了使用热度较高的词汇,后续实验证明该部分词汇以旅游地相关的地名为主。
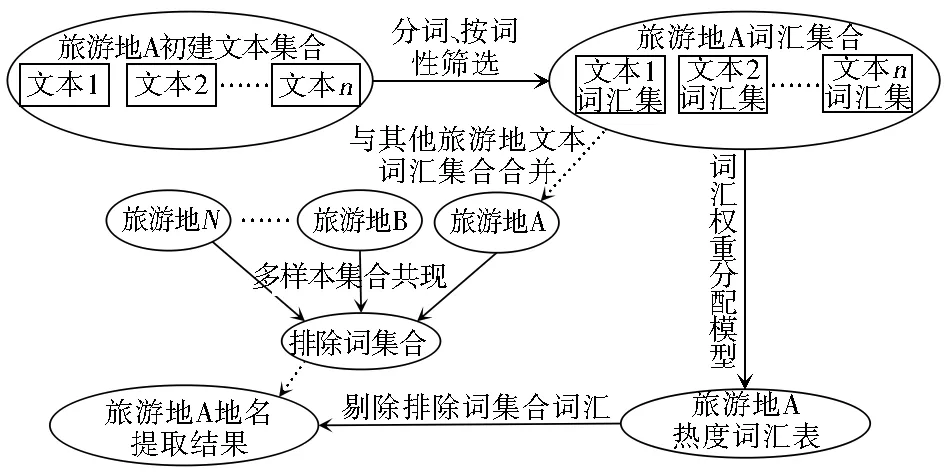
图1 地名提取方法流程
Fig.1 Toponym extraction flow
2.2 基于隐马尔可夫模型的分词方法
分词工具选用NLPIR汉语分词系统(ICTCLAS2013),该系统具有中文分词、词性标注和新词发现功能,并能够将未登录词识别为新词。NLPIR分词工具采用层叠隐马尔可夫模型对未登录词汇进行识别[22]。首先将要进行分词的原始字符串切分为分词原子序列;将一个给定的分词原子序列S的某个分词结果记为W=(w1,w2,…,wn),W对应的类别序列记为C=(c1,c2,…,cn),同时取概率最大的分词结果W#作为最终的分词结果,则:
(1)
如果wi未在核心词典收录,即为未登录词。其详细识别与标注过程本文不再阐述。本文利用JNI(JavaNativeInterface,Java本地接口)实现对NLPIR系统的Java调用。对初始文本进行分词,并对分词结果根据词性标注进行筛选,只保留词性标注为地名和新词的词汇,将每篇文本处理后的词汇集作为下一步处理的数据源。
2.3 基于ATF*PDF模型的词汇权重分配方法
描述同一旅游地的游记文本集合中,每篇游记可以看做一名游客在该旅游地旅行的认知与感受表述。因此,某个景观或旅游地名在越多的游记中出现,说明游客对其认知度越高。文本集中每个文本的大小不同,文本越大词表越大,词语在文本中出现的次数可能就越多。为了降低文本大小对词频的影响,应该对词语在每个文本中的词频进行归一化,然后取词语在文本集中词频的平均值作为词语在文本集中的词频。同时词语存在的文本数不同,词语的文本频率越大,其重要性就越大,相应的景观名称关注度也就越高。因此,权重模型需要赋予在文本集众多文本中均高频出现的词汇更高的权重。
针对以上需求,本文选用ATF*PDF(AverageTermFrequency*ProportionalDocumentFrequency)方法[23]计算词汇在整个文本集中的综合权重,以综合权重的大小反映词语的热度。ATF*PDF是在TF*PDF(TermFrequency*ProportionalDocumentFrequency)方法[24]基础上的改进,目前主要用于对多文档关键词的提取[25]。ATF*PDF方法在体现词语频率和文本频率对权重值的共同作用的同时弱化了单篇文本长度对词汇权重的影响。该方法应用于游记文本中的地名权重计算,既能反映地名在单篇游记中的认知深度,又能体现在游记集合中的认知广度,权重值大小更符合游记文本中地名热度特点。根据综合权重的大小,将词语i的权重wi定义为:
(2)
其中:N为整个文本集包含的文本数量;ni为文本集中包含词语i的文本数;|tfji|为词语i在文本j中的标准化词频,它的计算方法为:
(3)
其中:mj为第j个文本的词表大小,tfji为词语i在文本j中的词频。

2.4 基于多样本集合共现的排除词集构建方法
通过上述方法开展分词和计算权重之后,得到的仅是某旅游地系列游记文本中整体权重值较高的已识别地名及热度新词的集合,其中除地名外还可能包括一些用于描述旅行过程的常用词汇,如“退房”、 “订票”、“指示牌”等。当仅关注旅游地名研究时,如何快速有效地剔除其他词汇,就成为地名提取效率与精度的一个重要环节。
根据游记文本描述方式的共性和现代旅游者行为特征分析,本文提出了基于多样本集合共现的排除词集合构建方法。描述不同旅游地的系列游记文本集合间共同出现的词汇一般有两类:客源地名称和分词结果中未登录词汇构成的新词。客源地名称本质是地名(且一般都是标准化地名),在分词过程中能被直接识别并标注为地名;共同出现的未登录词汇主要是描述“吃、住、行、游、购、娱”等旅游过程的常用词汇,这些词汇不属于任意一个旅游地相关地名,应该在各个旅游地保留的高频词汇集合中剔除。基于多样本集合共现的排除词集合构建过程:首先,对分词和加权统计提取的不同旅游地的地名词汇集合进行筛选,仅保留未登录新词集合,并将不同旅游地的提取结果词汇合并;第二,统计各词汇在合并后的词汇集合中的出现频次(即样本旅游地文本中的出现频次);第三,选取出现频次大于等于样本旅游地总数量一半的词汇作为排除词集。
排除词集合构建时需要具备两个基本条件:首先,样本旅游地数量应该大于等于4个,以保证能够识别在不同旅游地游记中共同出现的非地名等旅行描述词汇;其次,样本旅游地相互独立,一般旅游者不会安排在同一次旅行过程中,以保证文本中的旅游地名使用具有相对独立性。排除词集合对于提高旅游地名自动提取的精度和效率具有重要意义,但并非说明这些词汇在开展旅游学其他相关研究时都需要被剔除。例如,基于多样本共现的排除词集合在用于研究旅游者行为或旅游地之间的对比分析时,有可能成为重要的核心指示词汇,具有很好的应用价值,本文不再深入探讨。
3 实验与分析
3.1 关键技术
3.1.1 数据源选取与处理 本研究以专业游客点评网站携程网(www.ctrip.com)上旅游者自由发布的网络游记文本为数据源。为了充分证明提取方法的可行性、科学性和潜在应用价值,研究挑选了在国内具有较高影响力、游记文本数量较充足的黄山、九寨沟、故宫、布达拉宫4个旅游地作为研究样本。其中黄山是世界文化与自然双遗产旅游地,自然与文化景观内涵都比较丰富,九寨沟则是以自然景观为主的世界遗产地,兼有特色的藏文化景观,故宫和布达拉宫则为世界著名的人文景观旅游地。利用火车采集器(LocoySpider)并编写采集规则,采集了携程网上4个样本旅游地的所有游记文本共13 410篇。为保证样本游记质量,提高研究效率和准确性,对所采集的游记样本进行了预处理:1)对于旅游者把同一次旅游经历分成若干游记发表的系列游记进行合并处理;2)删除字数较少缺少实质性旅游过程描述的游记,确保样本游记信息量的规模。每个旅游地分别保留2 000篇旅游游记作为实验文本。
3.1.2 地名提取 实验文本处理完毕后,使用NLPIR开源分词工具的JNI接口,编写Java程序实现4个旅游地样本共计8 000篇游记文本批量分词;根据分词结果的词性标注,只保留词性为地名和新词的分词结果,将其余词性的词汇、标点符号等全部删除。统计每篇文本中各词汇的频次与总词汇数,并统计每个词汇出现的文本频次。各旅游地样本选取预处理与相关频次统计完成后,基于ATF*PDF模型进行词汇的综合权重计算,并利用多样本集合共现方法构建排除词集合,对提取结果词汇集合进行非旅游地名词汇排除,最终得到各旅游地相关地名提取结果。选取权重排序前50位的词汇(表略)初步观察发现,本方法的提取结果以旅游地相关地名为主,既包括旅游地景观与旅游地名称,也包括重要的客源地名称,还包括少量未被过滤的非地名词汇。
3.2 提取结果分析
3.2.1 地名提取准确率 为了清晰表述和分析地名提取结果,本文提出了“地名提取准确率”的概念,指通过文本分词、词汇权重和排除词集合筛选后的提取结果对旅游地相关地名的识别率,以结果中属于本文界定的地名词汇的数量占提取结果总数量的比例表示。研究者对4个样本旅游地游记文本的地名提取准确率进行了逐一人工判别,以25个结果词汇为累计统计单元,按照词汇权重排序后的前200个结果词汇的提取准确率分布情况如表1所示。总体看,4个样本旅游地文本的前200个结果词汇中地名提取准确率都较高,但准确率的分布整体随词汇权重值下降而降低,其中,综合权重值前50的词汇中,地名提取准确率均达到了90%以上,前100的地名提取准确率也达到了80%以上。准确率分析初步表明,基于大量网络游记文本的地名提取方法适用于提取旅游者使用热度较高的地名,该方法对自然和人文景观旅游地的游记文本地名提取均具有较高准确率。随着旅游文本中使用的词汇热度降低,提取结果词汇中包含的地名逐渐减少,地名提取准确率降低。
表1 样本旅游地游记文本中的地名提取准确率
Table 1 The accuracy of toponyms extracted from sample travel blog texts

权重排序黄山九寨沟故宫布达拉宫地名数准确率(%)地名数准确率(%)地名数准确率(%)地名数准确率(%)前252496.0025100.002392.002392.00前504590.004794.004590.004590.00前756586.676688.006586.676688.00前1008484.008484.008888.008787.00前20014673.0015276.0015979.5016582.50
3.2.2 提取结果的类型结构 提取准确率评价为后续基于游记文本等旅游者自由发布信息的旅游学应用奠定了基础。由于提取结果中不同类型的地名分布特征和结构对于解析旅游者对旅游目的地的认知特征和旅游行为过程具有重要意义,研究中将旅游目的地自身名称以外的结果词汇进一步划分为5种类型:目的地内部景观名称、周边旅游地名称、政区与城市名称、重要地理要素名称、其他词汇。其中,前4种类型都属于广义的地名范畴,最后一种类型“其他词汇”是提取结果中不属于地名的词汇,这些词汇的热度较高,对于解释旅游文本中的地名分布意义或解读旅游过程的其他信息具有潜在价值。在类型结构描述中采用3种数量分布指标:不同类型词汇的数量、最大权重值和累积权重值。4个样本旅游地提取结果中综合权重值排序前100的词汇类型分布结构如图2所示。
从词汇数量(图2a)和累积权重值分布(图2b)可以看出,两种指标可以较好地反映不同旅游地游记文本在词汇使用类型方面的共性和差异。以自然景观为主导的黄山、九寨沟旅游地和以人文景观为主导的故宫、布达拉宫旅游地表现出了明显的自然和人文类型差异。自然景观主导的游记中表现出“旅游目的地景观名称主导型”地名使用特征,游记作者使用了丰富的景观名称描述旅行过程;人文景观主导的游记中则表现出“政区与城市名称主导型”地名使用特征,结果词汇中的旅游地内部景观名称较少,但包含大量周边其他旅游地名称。最大权重值分布(图2c)可以反映不同类型单个词汇在游记文本中的主导性状态,4个旅游地的总体结构具有一定的相似度,政区与城市名称整体上主导性明显,周边旅游地名称的主导性位于其次,重要地理要素名称的主导性在不同旅游地之间差异较大,而旅游地内部景观名称的主导性整体较弱。
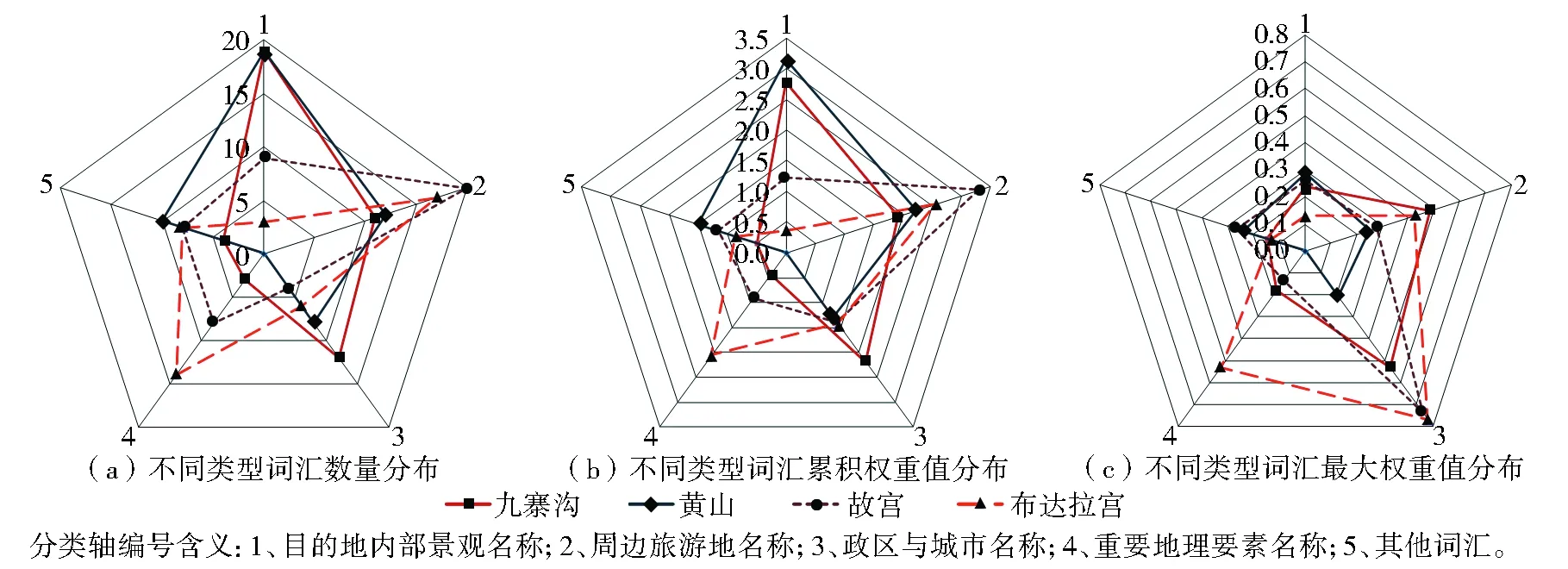
图2 不同样本旅游地游记文本中权重值前100位的词汇类型结构对比
Fig.2 Comparison of top 100 words of different sample travel blog texts
分析结果直接体现了游客在描述不同类型旅游地时记述方式的差异。由于自由撰写的旅行游记是旅游者记录旅行过程中的所见、所闻、所感的真实体现,因此,游记热度词汇的应用模式和类型结构也能间接反映旅游者对不同旅游目的地的认知差异。
4 结论与讨论
不同于已有基于文本的地名提取方法,本文基于大量网络游记文本提取热度旅游地名的思路充分利用了地名在旅游者自由撰写的游记文本中的重要地位,同时利用同一旅游地和不同旅游地游记文本集合在地名与其他词汇使用上的共性和差异特征进行提取方法设计。以黄山、九寨沟、故宫和布达拉宫4个旅游地为样本的实验结果显示,每个旅游地统计结果加权排序前200位的热度词汇均以该旅游地相关的地名为主,充分证明该方法能够较好地实现热度较高的旅游地和景观名称提取。
本文提取方法能够一定程度上解决基于大量自由描述文本开展旅游地理学研究的难点,使研究视角进入旅游地内部的较小空间尺度,并能够有效与更大空间尺度整合研究,也可以作为旅游地非标准化地名库建设的技术支撑。结果分析初步证明了地名与景观名称在旅游者自由撰写的旅游文本中的核心地位和研究价值,同时也为基于其他热度词汇的旅游学提供了空间研究视角和思路。ATF*PDF方法获得的综合权重值反映了地名及其相关词汇在游记文本集合中的整体重要程度,能够指示旅游者对旅游景观关注程度的高低,可以为后续旅游地景观关注度、景观认知与评价和旅游者行为的时空特征等研究提供参考,也能够通过旅游地相关地名的热度演变及时追踪旅游者的景观认知演化过程,对于准确把握和解释旅游目的地形象演化过程和机理,适时调整不同类型旅游目的地管理制度和政策也具有参考意义。本文提取方法还为不使用自定义地名库的旅游地理研究提供了可能,在一定程度上避免了自定义词库方式带来的主观性影响。但本文方法对文本规模具有一定要求,适合提取关注度较高的热度地名,对旅游者使用热度较低的词汇则不适用。
[1] 王佳果,王尧.基于NVivo软件的互联网旅游文本的质性研究——以贵州黔东南肇兴的旅游者文本为例[J].旅游论坛,2009,2(1):30-34.
[2] 苗学玲,保继刚.“众乐乐”:旅游虚拟社区“结伴旅行”之质性研究[J].旅游学刊,2007,22(8):48-54.
[3] BANYAI M,GLOVER T D.Evaluating research methods on travel blogs[J].Journal of Travel Research,2012,51(3):267-277.
[4] 赵振斌,党娇.基于网络文本内容分析的太白山背包旅游行为研究[J].人文地理,2011,26(1):134-139.
[5] 肖亮,赵黎明.互联网传播的台湾旅游目的地形象——基于两岸相关网站的内容分析[J].旅游学刊,2009,24(3):75-81.
[6] CHOI S,LEHTO X Y,MORRISON A M.Destination image representation on the web:Content analysis of Macau travel related Websites[J].Tourism Management,2007,28(1):118-129.
[7] LI X,WANG Y C.China in the eyes of western travelers as represented in travel blogs[J].Journal of Travel and Tourism Marketing,2011,28(7):689-719.
[8] 唐顺英,周尚意.文本在游客地方感建构中的作用研究——基于曲阜游记的分析[J].地理与地理信息科学,2013,29(2):100-104.
[9] GOVERS R,GO F M.Projected destination image online:Website content analysis of pictures and text[J].Information Technology &Tourism,2004,7(2):73-89.
[10] WANG H Y.Investigating the determinants of travel blogs influencing readers′ intention to travel[J].The Service Industries Journal,2012,32(2):231-255.
[11] GOODCHILD M F.Citizens as voluntary sensors:Spatial data infrastructure in the world of Web 2.0[J].International Journal of Spatial Data Infrastructures Research,2007(2):24-32.
[12] GOLDBERG D W,WILSON J P,KNOBLOCK C A.Extracting geographic features from the Internet to automatically build detailed regional gazetteers[J].International Journal of Geographical Information Science,2009(1):93-128.
[13] 张雪英,张春菊,闾国年.地理命名实体分类体系的设计与应用分析[J].地球信息科学学报,2010,12(2):220-227.
[14] 刘瑜,张毅,田原,等.广义地名及其本体研究[J].地理与地理信息科学,2007,23(6):1-7.
[15] 俞鸿魁,张华平,刘群,等.基于层叠隐马尔可夫模型的中文命名实体识别[J].通信学报,2006,27(2):87-94.
[16] 唐旭日,陈小荷,张雪英.中文文本的地名解析方法研究[J].武汉大学学报(信息科学版),2010,35(8):930-935.
[17] LI L,DING Z,HUANG D.Recognizing location names from Chinese texts based on max-margin network[A].International Conference on Natural Language Processing and Knowledge Engineering[C].2008.19-22.
[18] 唐旭日,陈小荷,许超,等.基于篇章的中文地名识别研究[J].中文信息学报,2010,24(2):24-32.
[19] 黄德根,岳广玲,杨元生.基于统计的中文地名识别[J].中文信息学报,2003,17(2):36-41.
[20] 张春菊,张雪英,朱少楠,等.基于网络爬虫的地名数据库维护方法[J].地球信息科学学报,2011,13(4):492-499.
[21] 黄昌宁,赵海.中文分词十年回顾[J].中文信息学报,2007,21(3):8-19.
[22] 刘群,张华平,俞鸿魁,等.基于层叠隐马模型的汉语词法分析[J].计算机研究与发展,2004,41(8):1421-1429.
[23] 杨洁,季铎,蔡东风,等.基于联合权重的多文档关键词抽取技术[J].中文信息学报,2008,22(6):75-79.
[24] BUN K K,ISHIZUKA M.Topic extraction from news archive using TF*PDF algorithm[A].Proceedings of the 3rd International Conference on Web Information Systems Engineering[C].Singapore:IEEE CS Press,2002.73-82.
[25] 胡志敏.基于综合权重的多文档关键词抽取算法[J].计算机与数字工程,2010,38(6):45-48.
Method and Case Study of Hot-Toponym Extraction from Mass Amount of Internet Travel Blog Text
LI Zhao-hang1,GUO Feng-hua2,LI Ren-jie1,3,FU Xue-qing1,3,YAN Zheng-feng1,3
(1.CollegeofResourceandEnvironmentScience,HebeiNormalUniversity,Shijiazhuang050024; 2.InstituteofGeographicalSciences,HebeiAcademyofSciences,Shijiazhuang050021; 3.HebeiKeyLaboratoryofEnvironmentalChangeandEcologicalConstruction,Shijiazhuang050024,China)
This paper discusses the characteristics of toponyms being used in text of Internet travel blog and the significance of this research.The toponyms in Internet travel blog refer to place names or landscape names in tourism.The quantitatively characteristics of toponyms used in travel blog can reflect the cognition structure and the common process of tourists.Depending on the existing Chinese Word Segmentation foundation and the characteristics of toponym in travel blog,this paper selects and uses the ATF*PDF method to calculate the joint weight of characteristic words in the whole travel blog collection.Design an automatic method of hot-toponym extraction from mass amount of text of Internet travel blog,laid the foundation of tourism geography research without manually defined gazetteer.The result of case study indicates that the method can extract tourism related toponym from text quickly.The hotter toponym has higher accuracy.The paper finds out the commonalities and differences in toponyms when being used in natural and cultural travel blog.This could help us find the meaning and potential value of toponyms in travel process by data interpretation.
text of Internet travel blog;hot-toponym;ATF*PDF model;multiple sample collection co-occurrence
2014-07-01
国家自然科学基金项目(41101105、41171105);河北省软科学研究计划项目(13406002D);河北省高校重点学科建设项目
李照航(1989-),男,硕士研究生,研究方向为地理信息可视化。*通讯作者E-mail:lrjgis@163.com
10.3969/j.issn.1672-0504.2015.01.015
F590
A
1672-0504(2015)01-0068-06
