基于BP算法的含沙量预测模型研究
2015-06-07温宗周刘现华
温宗周,刘现华
(西安工程大学电子信息学院,陕西西安 710048)
基于BP算法的含沙量预测模型研究
温宗周,刘现华
(西安工程大学电子信息学院,陕西西安 710048)
为提高水库泥沙含量预测的精度,综合考虑水温、水深、流速等因素对预测精度的影响,构建基于BP算法的含沙量预测模型.首先,选用实测的水温、水深、流速数据作为样本数据进行BP神经网络的训练,通过设置预测误差实现对预测模型的约束,完成了含沙量预测模型的构建.当需要进行含沙量预测时,则将测试数据导入到训练好的预测模型中得到含沙量的预测值.仿真结果表明,此含沙量预测模型获得的含沙量值与实测值之间的误差小,预测精度达到了预期目标.
库区泥沙;BP算法;含沙量预测
0 引 言
水库具有防洪、蓄水、养殖、供水、发电和调沙等重要功能.水库库容的大小是水库的重要指标,保证水库库容是水库正常有效运行的关键.我国是一个沙河流众多的国家,泥沙问题比较突出,在洪水期,挟带泥沙的上游河流到达库区时,泥沙会沉降到库底,出现不同程度的淤积,尤其是在我国北方地区泥沙问题更加严重[1-3].水库的泥沙淤积极大地损失了库容,降低了水库防洪、兴利的综合效益[4-5].因此适时有效地泄洪排沙对保证库容、提高水库的利用率有着至关重要的意义.这就需要实时动态监测水库的泥沙含量,在泥沙含量超过设定的阀值时进行预警,为泄洪排沙、水沙调度提供科学依据,对保证库容、提高水库利用率有较好的实用价值.文献[6]结合黑河流域的特点针对水库的入库洪水预报进行研究,同时探讨了泥沙淤积较为严重的冯家山水库的出库含沙量预测问题,力求能够根据现有实测数据对水库的入库洪水过程和出库含沙量过程进行较为可靠的预测.在此基础上,针对含沙量预测的研究越来越多[7-10],并有学者开始将神经网络和智能控制等相关理论引入到含沙量预测的研究中[11-15],文中在上述研究的基础上,提出了基于BP算法的含沙量预测模型.
1 BP算法概述
同传统含沙量预测-回归模型相比,BP网络的数据输入是拓扑有序的,因此利用BP神经网络可以在学习过程中将悬浮泥沙垂向分布对声波衰减的影响考虑在内,克服了回归模型各样本之间没有联系的缺点,提高传感器与背向散射源距离补偿的精度.利用BP神经网络进行库区洪水入库时的含沙量监测是符合洪水入库过程特性的.图1为一个基本的BP神经元,其功能为:输入量先乘上连接权值并与bj做加权处理,然后通过激励函数f(·)做转移处理.其中,x1,x2,…,xn代表输入量,yj表示输出量,bj代表阈值,wj1,wj2,…,wjn代表连接权值,f(·)为激励函数,净输入值sj为
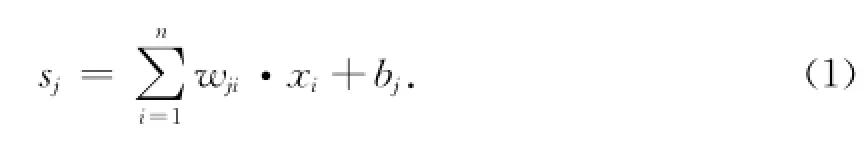
在将净输入sj通过激励函数f(·)转移处理之后,得到输出yj=f(sj).式中,f(·)是单调上升函数且为有界函数.
采用Delta学习规则进行网络训练,其数学表达式为

图1 基本BP神经元结构Fig.1 The basic structure of BP neurons

式中,wij表示神经元的连接权值,di为神经元的期望输出值,yi是神经元的实际输出值,xj表示神经元的状态值,α表示学习速度.对于输出层,权值的调整公式为
式中,f(·)为神经元的激励函数,f′(·)为其一阶导数,Neti表示为第i个神经元的输入.对隐含层来说,权值的调整公式为j
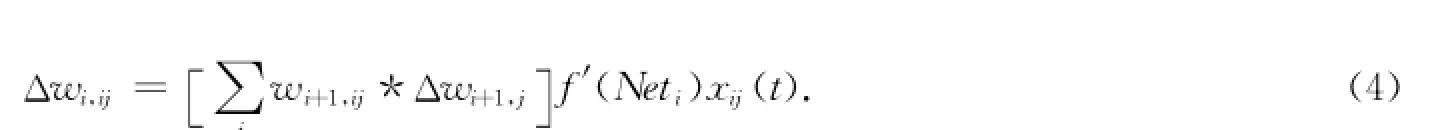
式中,∑为全体与隐含层的单元j相连的各项连接权值变化总和.
假设输入为P,输入神经元有n1个,隐含层有n2个,输出层有n3个,激励函数为f(·),输出为Y,阈值分别为b1和b2,神经元的连接权值分别为w1和w2信息在正向传递中所涉及的参数值计算:
(1)隐含层第i个神经元输出为

(2)输出层第j个函数为
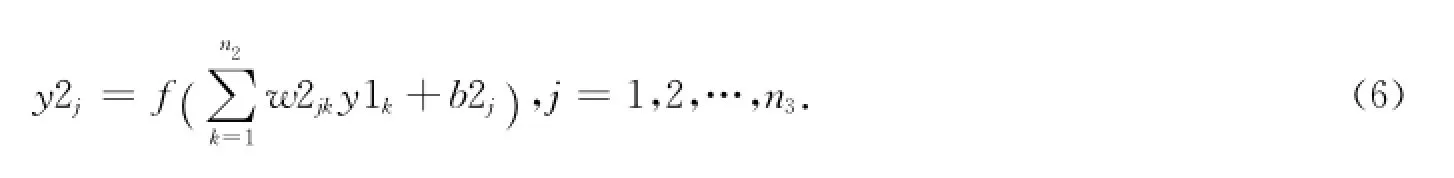
(3)误差函数的定义为

式中,tj为神经元的期望输出值.采用梯度下降的方法求相应权值:
(1)输出层权值的变化:

BP算法实现的步骤如下:
(1)初始化连接阈值与权值,数值设置为比较小的随机数;
(2)导入输入矢量X=[x1,x2,…,xn]以及期望输出Y=[y1,y2,…,yn];
(3)从第一个隐含层开始逐步计算出每个单元的净输入值sj;
(4)再将sj代入到激励函数,得到激励值yj=f(sj);
(5)由yj来得出输出值Oj=H(yj),式中,H代表输出函数;
(6)计算连接权的矫正值Δwij;
(7)再一次执行步骤(3)~(6),直至均方差达到预期目标.
2 含沙量预测模型
基于传感器断面优化布控的原则,以实时测得的超声波回波强度、水温、水深、流速作为样本,将其导入到基于BP神经网络的泥沙含量监测系统模型中进行参数训练,完成监测系统BP模型构建.通过测点测得的回波强度、水深、水温、流速导入到构建好的BP模型中完成对库区含沙量的实时预测,并与取样法测得的水库排沙后的下泄含沙量作对比.如果预测误差在可接受误差范围之外,则将本次含沙量的预测值以及测点实时测得的回波强度、水温、水深、流速作为样本数据,再次导入到已建好的BP神经网络中进行网络参数训练,通过这样多轮反复的训练—预测—再训练的过程,最终将监测误差控制在一定的范围之内,得到一个特定区域的BP神经网络模型.
2.1 网络中输入、输出因子选择
输入因子的选择依据:(1)首先输入量信息能够被检测,并且跟输出量之间的相关性比较大;(2)如果有多个输入量,它们之间是互不相干的.输出量表示本系统所要实现的功能目标,即含沙量.
2.2 网络层数的选择
三层前馈网络ANN可以满足一般函数的拟合逼近问题.隐含层数的增加可以提高模型精度,但过多隐含层会提高网络复杂程度.为了在库区泥沙含量的预报中达到较好的效果,选取一个隐含层,也就是建立一个三层网络.
2.3 输入层、输出层神经元数目以及隐含层节点数目的确定
输入层、输出层的神经元数目是根据系统研究因子决定的.文中的输入层数选择为4个变量,即回波强度、水温、水深、流速.输出层为库区含沙量.选择一个数目较少的情况,构建BP网络,如果不能满足收敛条件,则增加节点数目.经多次实验后,最终将隐含层节点数设置为11个.构建的BP模型如图2所示.

图2 基于BP算法的含沙量预测模型Fig.2 Prediction model of sediment concentration based on BP algorithm
2.4 激励函数的选择以及连接权的初始值确定
选择S型函数作为激励函数,由于S型函数对逼近非线性曲线的效果较好,同时网络的输出也集中在一个较小的范围内.连接权的初始值对网络训练时间和达到的期望精度都是至关重要的.一般原则是让每个输入量经过加权之后其值都接近于零,因此可将连接权的初始值选为小于0.1的随机数.
2.5 学习速率以及目标误差的确定
一般情况下,学习速率在0.01~0.9之间进行选择.文中经过多次的实验,最后将学习速率定为0.05.目标误差的选择是要根据水文预报规则以及实际网络训练难易度来决定的,经过反复实验后,将最后的目标误差定为0.000 1.
3 实验验证
3.1 样本数据的选择
选取2001年4月长江口北槽一个测点的测量数据,整理得到20组回波强度、平均水深、平均流速、平均水温以及实测的含沙量.其中的14组数据作为样本数据进行BP网络训练,另外6组数据作为测试数据.
3.2 数据归一化处理

归一化方法:将输入与输出数据变换到[0,1]区间以内,采用以下变换式:其中,xi为输入或输出数据,xmin是数据最小值,xmax为数据最大值.
3.3 样本训练
样本数据以及预测数据进行归一化处理后,如表1所示,其中的1~14组数据用于训练BP神经网络,15~20组数据用于检测预效果.

表1 归一化后的样本数据及预测数据Table 1 Sample data and predicted data after normalization
将归一化后的14组的数据导入BP预测模型中进行训练.最小训练的速率是0.1,动态参数设置为0.6,sigmoid参数设置为0.9,允许的最大误差为0.000 1,最大训练次数为20 000.使用MATLAB软件进行BP网络模型的训练,图3所示为当选择隐含层节点数为11个,激励函数为S型函数时的MATLAB训练结果.
如图3所示,训练最大迭代次数设置为20 000次,在训练13 511次后停止训练.模型的初始均方差为0.001 9,目标均方差为0.000 1,误差达到9.999 86×10-5时模型停止训练,因此该模型的最终训练误差为9.999 86×10-5,训练结果如表2所示.BP神经网络训练模型所形成的拟合曲线,如图4所示.
3.4 预测结果
通过对样本数据归一化后进行BP网络训练,并将测试数据输入到训练好的模型中进行测试,得到的测试结果如表3所示.根据数据的处理结果,基于BP神经网络模型的含沙量预测曲线如图5所示.

图3 Matlab软件训练界面Fig.3 Software training interface of matlab

表2 基于BP神经网络模型的训练结果Table 2 Training result based on BP neural network

表3 含沙量预测结果Table 3 Prediction result based on BP neural network
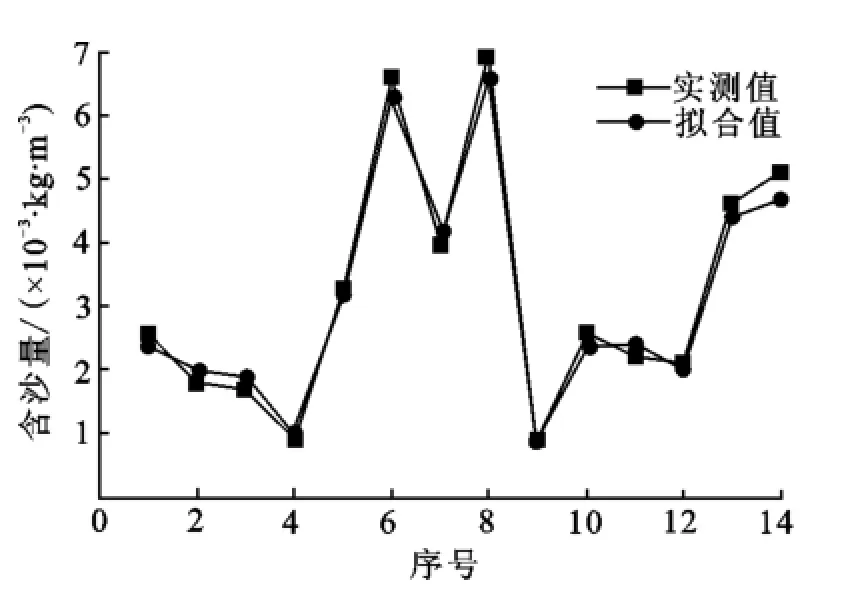
图4 实测值与拟合值曲线Fig.4Curves of measured value and fitting value

图5 预测含沙量与实际含沙量曲线Fig.5 Curces of predicted sediment concentration and practical sediment concentration
综上所述,基于BP神经网络的含沙量预测模型能够较好地预测水库的含沙量,与实测值之间的误差不大,最大相对误差为11.11%,最小相对误差为2.08%,平均相对误差为6.985%,达到了预期目标.
4 结束语
在国内外对水库含沙量预测的研究现状的基础上,提出了基于BP算法的含沙量预测模型,充分考虑了水温、水深、流速等因素对预测精度的影响,构建了基于BP算法的含沙量预测模型.通过实验验证,表明本文算法能够实现水库含沙量的预测,而且精度满足要求.
[1] 张瑞,汪亚平,潘少明.近50年来长江入河口区含沙量和输沙量的变化趋势[J].海洋通报,2008,27(2):1-9.ZHANG Rui,WANG Yaping,PAN Shaoming.Variations of suspended sediment concentrations and loads into the estuary area from Yangtze river in recent 50years[J].Marine Science Bulletin,2008,27(2):1-9.
[2] 许炯心,孙季.长江上游干支流悬移质含沙量的变化及其原因[J].地理研究,2008,27(2):332-342.XU Jiongxin,SUN Ji.Temporal variation in suspended sediment concentration of the upper Changjiang river and its tributaries[J].Geographical Research,2008,27(2):332-342.
[3] 孔亚珍,丁平兴,贺松林,等.长江口外及其邻近海域含沙量时空变化特征分析[J].海洋科学进展,2006,24(4):446-454.
KONG Yazhen,DING Pingxing,HE Songlin,et al.Analysis of spatial and temporal variation characteristics of suspended sediment oncentration in the Changjiang river eatuary and adjacent sea area[J].Advances in Marine Science,2006,24(4):446-454.
[4] 胡江,杨胜发,王兴奎.三峡水库2003年蓄水以来库区干流泥沙淤积初步分析[J].泥沙研究,2013(1):39-44.
HU Jiang,YANG Shengfa,WANG Xingkui.Sedimentation in Yangtze river above three gorges project since 2003[J].Journal of Sediment Research,2013(1):39-44.
[5] 谢金明.水库泥沙淤积管理评价研究[D].北京:清华大学,2012:10-12.
XIE Jinming.Studies on the evaluation of reservoir sedimentation management[D].Beijing:Tsinghua University,2012:10-12.
[6] 李亚娇.水库入库洪水预报与出库含沙量预测[D].西安:西安理工大学,2003:88-98.
LI Yajiao.Forecast of inflow hydrograph and out flow sediment concentration of reservoir[D].Xi′an:Xi′an University of Technology,2003:88-98.
[7] 张袁,付强,王斌.基于自由搜索的水库入库含沙量预测模型[J].南水北调与水利科技,2012,10(3):40-43.
ZHANG Yuan,FU Qiang,WANG Bin.Prediction model of reservoir inflow sediment concentration based on free search[J].South-to-north Water Diversion and Water Science &Technology,2012,10(3):40-43.
[8] 李亚娇,李怀恩,沈冰.基于RBF网络的冯家山水库出库含沙量预测研究[J].西北农林科技大学学报:自然科学版,2005,33(10):134-138.
LI Yajiao,LI Huaien,SHEN Bing.The application of RBF neural network in forecast of out flow sediment concentration of Feng jiashan Reservoir[J].Journal of Northwest A&F University:Natural Science Edition,2005,33(10):134-138.
[9] 黄启厅,史舟,潘桂颖.沙质土壤热红外高光谱特征及其含沙量预测研究[J].光谱学与光谱分析,2011,31(8):2195-2199.
HUANG Qiting,SHI Zhou,PAN Guiying.Charateristics of thermal infrared hyperspectra and prediction of sand content of sandy soil[J].Spectroscopy and Spectral Analysis,2011,31(8):2195-2199.
[10] 万新宇,包为民,王光谦.基于相似性的多沙水库坝址含沙量预测[J].水科学进展,2010,21(1):36-42.
WAN Xinyu,BAO Weimin,WANG Guangqian.Similarity-based prediction of sediment concentrations for reservoir dam-sites in sediment-laden rivers[J].Advanced in Water Science,2010,21(1):36-42.
[11] 陈海洋,聂弘颖,潘金波.基于动态贝叶斯网络的交通灯自助智能决策[J].西安工程大学学报,2014,28(4):474-479.
CHEN Haiyang,NIE Hongying,PAN Jinbo.Traffic lights intelligent decision independently based on dynamic bayesian network[J].Journal of Xi′an Polytechnic University,2014,28(4):474-479.
[12] 田景环,王文君,徐建华.基于BP算法的龙门站含沙量预报模型[J].人民黄河,2008,30(3):26-27.
TIAN Jinghuan,WANG Wenjun,XU Jianhua.Longmen station sediment concentration prediction model based on BP algorithm[J].Yellow River,2008,30(3):26-27.
[13] 于东生,严以新,田淳.基于BP算法的泥沙含量预测研究[J].三峡大学学报:自然科学版,2003,25(1):47-51.
YU Dongsheng,YAN Yixin,TIAN Chun.Research on forecast of sediment concentration based on BP Algorithm[J].Journal of China Three Gorges University:Natural Science Edition,2003,25(1):47-51.
[14] 石宝.多沙河流河段悬移质含沙量过程预报方法的再探讨[D].西安:西安理工大学,2008:1-20.
SHI Bao.Further studies on methods of hydrograph forecasting of sendiment concentration for sediment-laden river[D].Xi′an:Xi′an University of Technology,2008:1-20.
[15] 孔德星,杨红.长江口区基于BP算法的表层悬沙浓度计算模型[J].海洋技术.2009,28(2):18-20.
KONG Dexing,YANG Hong.Surface layer suspended particle matter concentration calculation model based on BP algorithm in Yangtze estuary[J].Ocean Technology,2009,28(2):18-20.
编辑、校对:孟 超
Study on prediction model of sediment concentration based on BP algorithm
WEN Zongzhou,LIU Xianhua
(School of Electronics and Information,Xi′an Polytechnic University,Xi′an 710048,China)
In order to improve precision of sediment concentration prediction,taking into account water temperature,water depth,velocity and other factors on the prediction accuracy,the sediment concentration prediction model based on BP algorithm was constructed.Firstly,water temperature,water depth and velocity data were chosen as training sample.By setting prediction error as constraint condition,the sediment concentration prediction model was completed.When predicting sediment concentration,the data was input into the trained prediction model to obtain the predicted result.The simulation results obtained that the sediment concentration prediction model reaches the expected goal.
reservoir sediment;BP algorithm;sediment concentration prediction
TP 29
A
1674-649X(2015)05-0600-06
10.13338/j.issn.1674-649x.2015.05.015
2015-07-02
陕西省工业科技攻关资助项目(2015GY065)
温宗周(1962—),男,陕西省宝鸡市人,西安工程大学副教授,研究方向为嵌入式系统开发与应用.E-mail:xgkwen@163.com
