一种基于图模型的Web数据库采样方法研究
2015-06-01何康乐
何康乐
摘要:在Web数据库中,有着大量丰富的信息数据,这些信息并不能直接看到,只有进行特定的查询才能看到。由于这一特点,对Web数据库的实时更新及其分布特征的了解成了一个问题,进而也会阻碍到Deep Web数据库的进一步集成。针对这一困难,本文提出了一种新型的采样方法,在查询时能够从Web数据库获取近似随机的增量样本并记录,并在此基础上进行下一次查询,并不会受到查询接口的属性限制,能够在获取高质量样本的同时降低代价。
关键词:Web数据库;采样;图模型
中图分类号:G434 文献标识码:A 论文编号:1674-2117(2015)09-0076-02
伴随着Web的飞速发展,其作为一个信息源覆盖了越来越多的信息,根据其所蕴含的具体信息深度,我们可以将整个Web分为两大部分,包括Deep Web以及Surface Web。[1]所谓的Surface Web指的是能够采用传统的普通搜索引擎就能直接索引出的信息内容。相对地,不能直接采用搜索引擎搜索到的信息数据内容就被放在Deep Web中,其具体内容被存储在能够进行在线访问的Web数据库之中。由于Deep Web数据库中存在着海量的信息,可以达到Surface Web的550倍[2],想要从中快速获取想要的信息也成了一个问题。
● Deep Web概述
网络中诸多能够进行在线访问的数据库,统称为Web数据库,将全部Web数据库整合到一起,就统一成了Deep Web,也被称作是Hidden Web。[3]想要访问Deep Web,就必须从查询接口进行访问,在网页上查询接口是通过表单表现出来的,用户具体需要做的就是输入一定的条件在表单中,进而便可以查询相关信息。[4]
● Web数据库采样
Web数据库中信息的质量参差不齐,想要对其进行有效研究,传统做法通常是将全部数据库进行完全的统计分析。但,由于Web数据库中的数据类型颇为广泛,本地研究并不需要完整的数据库,只需要构建出一个具有针对性的本地数据库即可。然而,本地数据库构建出来以后,由于网络信息一直在实时更新,相应地,本地数据库中的信息也需要实时更新,同时,这会为本地储存增加相当大的负担,进而付出更多的代价。[5]针对这一问题,我们可以不将所有的信息都从Web数据库中提取出来,仅从中抽取想要的数据样本,通过具有代表性的样本进行数据库研究。
传统的采样方法采集数据是通过数据库直接获取信息,进行随机采样。随机采样技术有直方图法和近似查询法,但是这类方法都要求数据库具备无限制访问接口。所以,在Web数据库采样中,这种方法并不适用。参考搜索引擎,也有专家学者提出可以通过文档进行随机采样,可以从搜索引擎中随机抽取样本。但是,由于文档并不能代替查询表单,所以该方法也不适用于Web数据库。综合考虑Deep Web的特点,笔者提出了一种基于图模型的数据采样方法,该方法摒弃了查询接口属性的限制,能够通过关键词进行快速查询。
● 基于图模型的Web数据库采样
1.基本思想
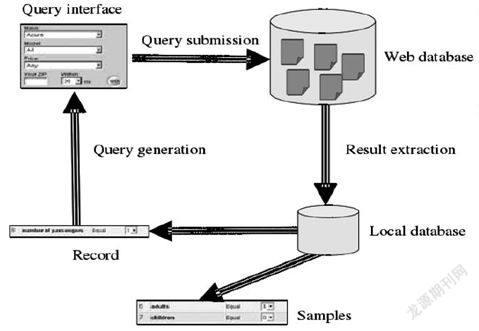
基于图模型的Web数据库采样的基本思想主要可以分成四个环节,首先,从任意的有效查询中查询;其次,根据查询到的结果抽取一些进行记录;再次,将记录好的内容放置到本地的样本数据库中;最后,根据样本库的信息,抽取一个记录进行下一次查询,达成循环(如下页图)。
想要完成Web数据库采样,需要解决两个问题。第一,采集到的样本存在一定的偏差,必须进行修正,保证数据分布能够和Web数据库相同;第二,获取样本相应地需要付出一定的代价,要降低代价,可以通过减少查询次数来达成这一目的。
2.图模型WG概述
根据Web数据库特征建立的一种全新模型,图模型可以借由图游历的形式进行采样。在改样过程中,模型中的各个顶点和边都被定义了唯一的特征查询,同时,查询后的记录集合中每个顶点都有其专门的对应记录,对于各个边来说,也有着边上自带两点的对应集合记录。WG能够提供的具体能力与WDB中的具体查询接口有关,因为只要是查询,就必须有查询接口。所以,要想判断WG中的边上两个顶点是否存在两个记录,就要确定是否存在某个查询接口能够满足边上两点的查询记录要求。
3.WG采样方法
由图可知,Web数据库采样需要解决的主要问题是:获取样本、选择查询以及终止条件。由于我们并不能调出所有的WDB记录,那么也很难构建出一个真正意义上的WG,所以,可以根据当前的WG,随机抽取一个点开始游历,进行采样,基本过程为:①随机抽取一个Q0,将其递交给WDB;②将查询后所得的具体结果记录到RL中,并根据已有的RL建立起对应的WGL;③判断是否终止,若满足终止条件,则终止,若不满足,则继续进行下一步骤;④对构建出WGL的进行分析,然后在RL中找出合适的记录继续进行查询,回到第①步骤进行。
(1)WDB-Sampler算法
WDB-Sampler算法主要对采样的整体过程进行具体的形式化描述。
(2)记录选择
想要进行持续查询,完成实时更新,必须在已经基本形成的本地记录合集中选出合适的某个记录进行下一步查询,这就是记录选择这一环节需要完成的内容。采样WG进行具体解释,就是根据目前的WGL选出一个顶点v,根据v查询之前没有查询到的其他顶点,丰富WGL。
(3)查询生成
选择好顶点以后,可以选出具体的某个记录,然后完成下一环节的查询。一个记录可以获得多个查询,所以,针对每个RL中的记录都要构建出对应的统计信息。
(4)采样终止
图模型若是没有设计终止程序,可想而知,数据采样将会持续进行下去,虽然在理论上这样做可以得到所有想要的记录,但是我们事实上并不需要所有的信息,只是需要其中某些样本。所以,应该设计出常量nq>1、0<<1表示若是查询中连续nq次的结果都超出了的重复记录,就代表采样结束。通常我们将nq值设计在5~10之间,设在5%~15%之间。
(5)偏差修正
因为查询中我们是将RL当做样本进行采样的,那么采样结束后往往会造成较大的偏差。针对这一问题,可以通过采样中的查询记录数量和过程中的Q{}进行样本偏差修正。
● 结语
笔者提出的基于图模型的WDB-Sample采样方法,能够将Web数据库转变为图形进行增量采样,该方法能够脱离属性限制,保证高质量采集样本的同时降低代价,在教育领域中的应用应该有无限广阔的前景。
参考文献:
[1]刘伟,孟小峰,凌妍妍.一种基于图模型的Web数据库采样方法[J].软件学报,2008(02).
[2]吴雨.基于图模型的Web数据库取样方法的解析[J].科技创新与应用,2013(20).
[3]王晓玲.一种基于图模型的Web数据库采样方法分析[J].计算机光盘软件与应用,2013(13).
[4]赵琳.Web数据库特征表示和抽取方法的研究[D].济南:山东财经大学,2012.
[5]董永权.Deep Web数据集成关键问题研究[D].济南:山东大学,2010.
