基于CFIO的参数自动选择研究
2015-04-14孙新华杨广文
孙新华 ,张 程 ,杨广文
1.清华大学 计算机科学与技术系,北京 100084
2.清华大学 地球系统科学研究中心 地球系统数值模拟教育部重点实验室,北京 100084
1 引言
近年来,全球气候正在经历一场显著的变化,其以全球变暖为主要特征,伴随着冰川融化退缩、海平面上升、土地沙漠化不断加剧,对地球的生态和环境产生了严重的影响。随之而来的各种极端天气与气候事件诸如暴雨、干旱、高温天气的频发也社会各界的广泛关注。如何有效地对气候进行预测分析成为摆在地球系统科学研究人员的难题,而地球系统模式作为地球系统科学走向定量化的标志得到了越来越多研究人员的青睐,成为研究气候变化的重要科学工具之一[1]。由于在低分辨率下地球系统模式无法模拟中小尺度下的过程,比如海洋模式中尺度漩涡过程,大气模式中的云演变过程,并且在面对复杂地形时难以达到精度要求,研究者越来越倾向于使用高分辨率格点网络进行数值模拟,高分辨率成为了地球系统模式发展的一个显著趋势。
随着分辨率的提高,模式程序需要对更多格点网格进行计算,在需要更多计算资源的同时也对运行平台的I/O能力提出了更高的要求。有数据显示,因为模式分辨率的提高,模式程序输出数据的规模呈现出几何级的增长速度[2]。然而高性能计算机的I/O能力与计算能力的差距却在逐渐拉大,这一方面是由于单机计算能力的增长速度遵循摩尔定律,远远高于磁盘带宽的增长速度;另一方面是由于并行计算技术的发展和异构加速器的引入,例如在科学应用程序中广泛使用的MPI和OpenMP技术,可以让科学计算程序运行在成千乃至上万个计算节点上,充分释放了高性能计算集群的计算能力;同时GPGPU和FPGA的引入为科学计算提供了更广阔的平台。I/O能力的相对不足严重影响了地球系统模式在高性能计算平台上的运行效率,地球系统模式的运行过程可以分为两个阶段,即计算阶段和I/O阶段,在传统的I/O方法下等待数据输出的过程中,模式无法继续进行计算只能等待I/O过程完成,因此模式的总体运行时间为I/O时间与计算时间之和。随着高分辨率地球系统模式输出数据规模的增大,I/O过程的时间越来越长,I/O问题愈发成为模式运行中的性能瓶颈。
为了解决这一问题,研究人员结合地球系统模式的I/O特征并基于I/O转发技术开发了一个面向地球系统模式的应用层并行I/O库CFIO(Climate Fast I/O Library)[3],利用I/O过程和计算过程的重叠来减少I/O过程对于模式整体运行性能的影响。CFIO将运行模式的进程划分为计算进程和I/O进程两类,计算进程只负责模式的计算过程,它将程序的I/O请求转发到I/O进程并缓存在I/O进程的缓冲区中,而由I/O过程负责完成模式数据的实际输出,这样就将I/O进程与计算进程自动重叠从而实现对程序整体的加速。在实际的使用过程中发现,在给定进程数的情况下,如何划分计算进程与I/O进程的比例以及I/O进程中内存缓冲区的大小会对模式程序整体运行产生极大的影响:若I/O进程过少,由于I/O能力不足会造成I/O进程缓冲区堵塞,计算进程被迫停下等待缓冲区的部分I/O请求完成才能继续,这样就会拉长模式程序整体运行时间;若I/O进程过多,将会造成I/O能力过剩,会浪费有限的计算资源。地学研究人员作为CFIO库的使用者,并不一定具备底层系统层面的知识帮助他们完成CFIO库相关参数的设置,所以现有的经验式的参数指定方式使得CFIO库在面对不同平台不同地球系统模式时并不能发挥最好的效能。
现有的与CFIO库设计思路类似的并行I/O库PIO[4]和DART[5]均没有解决这一问题。PIO是CESM(Community Earth System Model)[6]的开发者结合地球系统模式中I/O特征专门为CESM开发的应用层并行I/O库,其并行I/O功能由更底层的并行I/O库支持。目前PIO底层使用的 I/O 库有 MPI-IO[7]、netCDF[8]和 PnetCDF[9],用户可以根据自己的需要灵活选择底层的I/O库。PIO定义了两种数据在进程间的划分方式即计算划分和I/O划分并提供了一个数据重划分的功能接口。所谓计算划分是指针对计算网格进行的划分,数据的产生是随着计算任务按照计算划分分布在进程间的,但是这样的分布方式并不一定适合底层I/O库的I/O任务。用户可以使用PIO提供的接口重新定义数据在进程间的划分方式即I/O划分,经过通信数据会在进程间按I/O划分重新分布以获得更好的性能。与CFIO不同,PIO并没有采取计算阶段和通信阶段重叠的方法,而是按照传统的方式将计算与通信串联进行,数据按照计算划分产生后先缓存,然后再按照I/O划分的方式进行通信、写入。在重划分过程中,用户可以指定参与I/O划分的进程数以适应不同的I/O需求,其进程数指定方式主要依靠用户的经验式指定。DART是由美国橡树岭国家实验室开发的利用RDMA[10]作为通信方式的并行I/O转发架构,与CFIO类似,DART系统中也存在DARTClient与DARTServer数目比例确定的问题。Ciprian Docan等[5]提到了自适应地根据运行平台和程序的不同调整比例的重要性,但是并没有付诸实践。
针对并行I/O库经验式的进程管理和缓冲区管理方法所带来的性能损失,基于CFIO结合地球系统模式中的I/O特征设计并实现了一套参数自动选择的解决方案。通过目标模式程序的预执行收集I/O痕迹(I/O Trace)并统计其I/O特征信息,使用这套程序可以让CFIO在不同平台不同地球分量模式上既发挥CFIO最好的性能又不浪费资源。
本文首先介绍了CFIO的软件结构,之后分析了不同地球系统分量模式中的I/O请求到达规律和参数自动选择程序设计实现思路;最后,列出了具体实验结果。
2 CFIO软件结构
CFIO是一个适用于高分辨率地球系统模式的应用层并行I/O库。模式的运行过程是由计算过程和I/O过程两部分交替进行,在使用同步I/O接口时模式需要阻塞等待I/O过程的完成,即计算过程和I/O过程串行执行,模式运行时间也就是计算时间和I/O时间之和。由于高分辨率地球系统模式输出数据规模的急剧增加,越来越长的I/O时间对模式的整体运行性能造成了极大的影响。而通过分析地球系统模式I/O特征可以发现,模式的I/O过程总是跟随在计算过程之后且频率固定,同时模式的运行过程中只涉及简单的追加写输出,不会再次读入写出的数据。因此CFIO利用这种规律通过I/O转发技术实现了计算过程与I/O过程的重叠。在原来的应用场景中当一个模式启动时,所有的进程既负责计算过程又负责I/O过程,在CFIO中,在原有进程的基础上,额外地启动部分进程专门负责I/O过程,即I/O转发。如图1所示,所有进程被划分为两类进程:一是计算进程,负责地球系统模式中的计算任务,计算进程在执行I/O过程时并不直接在本地调用底层I/O接口执行I/O请求,而是通过网络将I/O请求转发到I/O进程中;二是I/O进程,负责地球系统模式中的I/O任务,I/O进程从计算进程接收I/O请求并调用PnetCDF为计算进程实际执行I/O请求。这样计算进程在完成I/O转发之后,并不需要等待计算过程的实际完成,而是继续进行下一个时间步的计算,而与此同时I/O过程也在I/O进程上并发地执行,从而实现了I/O过程与计算过程的重叠,隐藏了I/O时间,缩短了模式整体运行的时间。
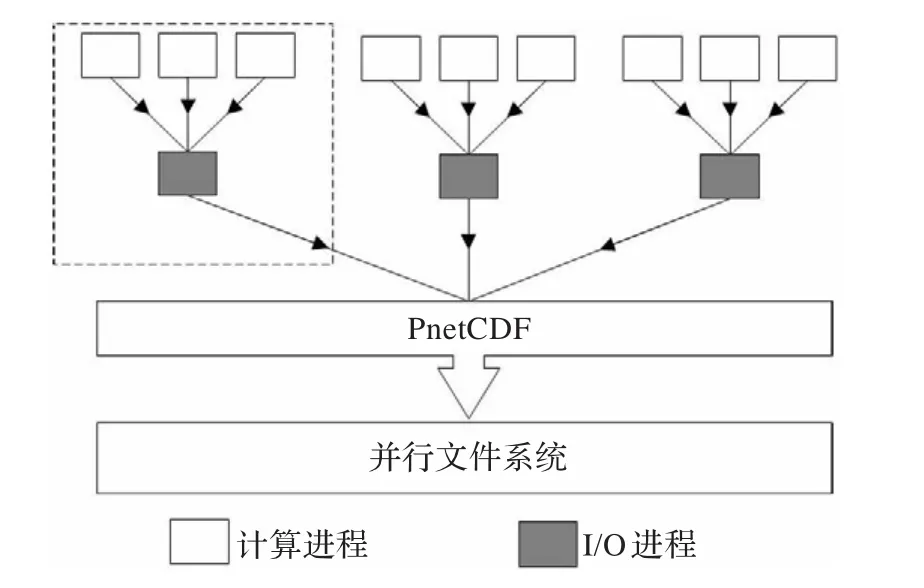
图1 CFIO中I/O转发结构图
具体分析CFIO的软件结构,如图2所示。运行在I/O进程上的CFIO服务器从运行在计算进程上的CFIO客户端接收I/O请求并缓存在缓冲区中,之后通过调用PnetCDF库按照先到先服务的原则处理I/O请求,将数据输出到文件系统中。CFIO服务器处理I/O请求的流程:当有新的I/O请求到达时,程序会检查现有缓冲区容量是否可以容纳最新到达的I/O请求,如果可以,服务器会正常接收转发而来的I/O请求;若由于到达的I/O请求过多导致I/O请求的大小超过了缓冲区大小,CFIO服务器则不会再接收I/O请求进入阻塞状态,需要处理并执行部分的I/O请求释放出部分的缓冲区空间,直到缓冲区有足够的空间来缓存下一条I/O请求,服务器才会由阻塞状态转变回接收者状态,继续接收数据。
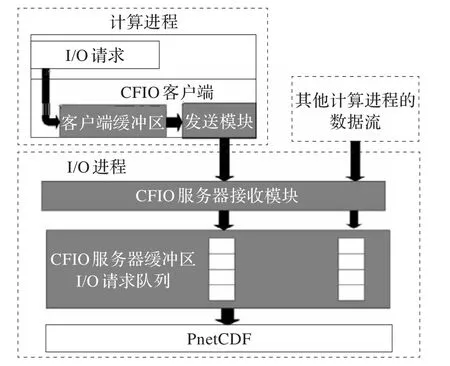
图2 CFIO结构细节图
一旦进入CFIO服务器进入阻塞状态,CFIO客户端的计算过程也必须停止等待I/O过程,这样计算过程与I/O过程隐藏效果就会变差,如图3(b)所示,阻塞会让CFIO客户端的转发等待时间变长,从而增加程序整体运行时间。服务器端的堵塞是由于后端PnetCDF数据处理的能力不足,根本原因是初始阶段分配的I/O进程太少;若分配的I/O进程过多则会造成I/O处理能力的过剩,如图3(a)所示,造成计算资源的浪费。只有在计算时间恰好等于I/O时间即如图3(c)所示的情况下,才既能保证模式程序运行性能又不浪费计算资源,实现I/O过程与计算过程的完美隐藏。同时,在计算进程数目一定的情况下,I/O进程数目的不同会影响到每一个I/O进程对应的计算进程的数目,因此每一个I/O进程需要处理的I/O请求数目也会不同,进而会影响CFIO服务器端缓冲区的使用量。

图3 计算过程与I/O过程的重叠
3 设计与实现
3.1 地球系统模式I/O特征分析
在地球系统模式中,模式的运行过程是有规律性的。由于地球系统模式中主要的计算过程均为动量方程组的迭代求解,在某些迭代步的计算之后会输出一些信息用于记录模式运行状况或者用于从程序崩溃中重新启动,所以地球系统模式的运行会出现周期性的特征:计算过程和I/O过程交替运行,计算过程是固定时间的一步或者几步迭代,I/O过程是以某一固定频率出现在计算过程之后的记录信息输出。因此,对于单个计算进程来说,其I/O请求在时间分布上是有周期性的,由一个个突发性的波峰和波峰之后长时间的无I/O的时间段构成。而且每一个周期内也有不同数量的I/O请求到达高峰,这是由于不同输出文件输出频率不同造成的。而经过对于海洋模式POP(Parallel Ocean Program)[11]、海冰模式CICE[12]两种常用地球分量模式中I/O请求在CFIO服务器端的到达分布情况的测试,可以发现多个计算进程的I/O请求在I/O进程聚合之后仍然呈现出于计算进程一样的周期性,且与计算进程发起I/O请求时的分布一致。这说明运行在不同节点上的CFIO客户端上计算过程是基本同步的,造成这种情况有两点原因,一是因为在大部分高性能集群中各个物理节点的配置状况相同或类似,二是因为在地球系统模式中,每一个时间步的最后会有全局的gather求和等需要全局通信的操作,因此相当于每一个时间步各个计算进程都需要同步一次。
此外,对于每个I/O请求块的大小进行分析可以发现,在同一个模式程序中I/O请求块大小是完全相同或者分段相同的。这是由于模式程序的输出通常情况下是嵌套在for循环中按照维度循环输出的,因此每次调用CFIO写入函数发起的I/O请求大小会相同;对于分段相同的情况发现是由于写入数据类型的变化,整个写入过程仍然嵌套在for循环中。
3.2 设计原理
根据第2章节对CFIO软件结构的分析,可以将CFIO服务器端对于I/O请求的处理看做一个排队系统。根据上文的分析,该排队系统到达分布为确定性的平均到达,服务规则为“先到达先服务”,其服务端分布即PnetCDF库的处理也可以看作是确定性的平均分布,服务台的个数为1,所以进程管理和缓冲区管理的问题可以转化为对于该排队系统中顾客源个数以及排队长度的计算问题。根据排队论可知,排队系统达到稳定的条件为:在概率上,一段时间内到达的顾客总量等于可以被服务的顾客总量。CFIO服务器端的I/O到达有周期性的特点,因为该系统达到稳定的条件是每一个周期内到达的所有I/O请求都恰好能在该周期内被PnetCDF完全处理,即

其中,Si代表一个周期内各个I/O请求块的大小,n为I/O进程的数目,Throughput(n)代表了n个I/O进程时PnetCDF的总体写入带宽。对于I/O进程数,必须是计算进程数约数这一点需要解释,是由于CFIO设计过程中为了保证负载均衡和输出数据的局部性,规定I/O划分必须为计算划分的整数倍,即I/O进程数必须为计算进程数的约数。
而由于I/O请求到达时间集中,在I/O到达阶段每一个I/O请求到达时间间隔为1~4 ms,且CFIO服务器处理机制为一旦有I/O请求达到则立即判断缓冲区空间是否充裕,以确定是否将I/O请求加入队列中,能够调用PnetCDF库处理I/O请求的时间极少。因此,可以认为缓冲区的大小需要容纳I/O请求最高峰时所有I/O请求,即

其中,Si代表I/O请求数量最高峰时到达的各个I/O请求的大小,n为I/O进程的数目,N为预执行时I/O进程的数目;乘N/n表示正式运行时每一个I/O进行需要接收N/n倍的I/O请求。
根据式(1)、(2)可知,为了确定I/O进程数目n的大小,需要两方面的信息:一是目标模式程序的相关I/O特征,包括周期的时间长度、I/O请求块的大小、一个周期内I/O请求块的数目;二是运行平台相关信息,即不同I/O进程数目下PnetCDF库的写入带宽。因此,为了解决该问题设计了如图4所示的解决方案。
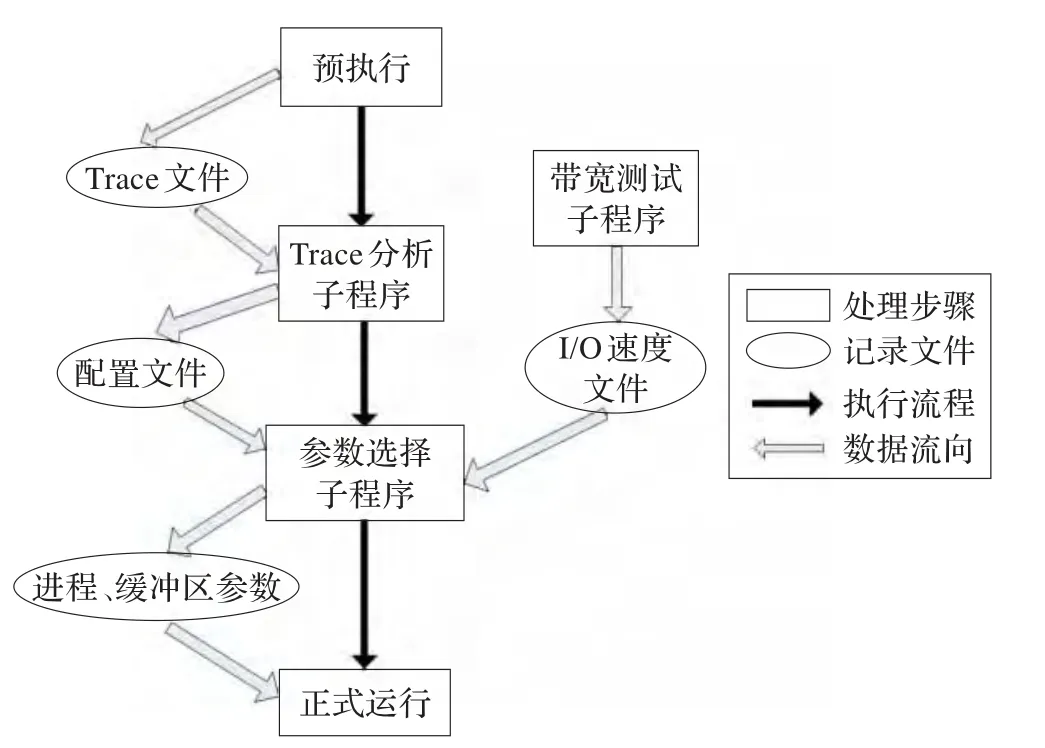
图4 参数自动选择过程图
通过目标地球系统模式程序的预运行利用CFIO库收集其I/O请求的痕迹信息,即Trace文件;然后用Trace分析子程序得到目标模式程序的I/O特征信息并写入到配置文件中。同时,对于每一个不同的运行平台,需要用带宽测试子程序测试不同I/O进程数目下PnetCDF的聚合写入带宽,并将测试结果写入I/O速度记录文件中。之后,利用配置文件中目标模式相关信息和I/O速度记录文件中的平台相关信息,通过参数计算子程序根据式(1)、(2)进行计算,得出最后需要的I/O进程数目和缓冲区大小并打印到屏幕上。最后,可以根据所得到的参数对CFIO进行设置,正式执行目标模式程序。在此过程中,用户仅需要通过命令行依次调用带宽测试、Trace分析和参数计算三个子程序,即可自动地得到适合于当前运行平台和目标地球系统模式的合适参数。
3.3 带宽测试子程序
带宽测试子程序负责针对不同的运行平台测试不同I/O进程数目下的PnetCDF库总体写入带宽,在同一个平台上带宽测试子程序只需要运行一次。该子程序输入为一个2的幂的正整数X,输出为I/O速度记录文件。
带宽测试子程序的核心是一个MPI测试程序,该程序调用PnetCDF库进行数据输出,生成500个变量,每个变量为一个二维双精度浮点数数组,数组大小为4 096×2 048。所有的变量都输出到同一个NetCDF文件中,最终文件大小为32 GB,程序的输出为32 GB除以程序运行时间,即为当前进程数目下的PnetCDF库的写入总带宽。带宽测试子程序用脚本从1开始以2的倍增直至X的进程数目调用MPI测试程序,并将I/O进程数目和相应的I/O写入带宽结果写入I/O速度记录文件中。
在实际CFIO使用过程中,I/O进程的数目可以为不大于计算进程数的任意正整数,出于效率和成本的考虑,在带宽测试子程序中不能够对于每个I/O进程数目的PnetCDF写入带宽进行测试。仅对2的正整数次幂数目的I/O进程I/O带宽测试,如果在后续的参数选择子程序计算中需要用到的I/O进程数目恰好在测试过的列表中,将会直接将测试结果返回;如果用到带宽测试子程序并没有实际测试过的I/O进程数目下的总体写入带宽,则需要利用已有的数据进行估计。Li等人在对PnetCDF库吞吐量的测试后发现[9],其吞吐量的变化趋势为先随着进程数增加而增加,到达峰值之后再随着进程数的增加略有回落,实际测试的结果也是如此。这是由于PnetCDF库后端调用了MPI-IO,而MPI-IO的聚合I/O采用两阶段I/O实现。以读操作为例,进程间通过互相通信交换各自需要读取的数据段进而得到一个全局的I/O视图,MPI-IO的一个实现ROMIO[13]会根据全局视图重新确定每个进程需要读取的数据段,然后执行两阶段I/O:第一阶段为I/O阶段,每个进程分别读取自己负责的数据段;第二阶段为通信阶段,进程间通过通信从其他进程获取自己原本应该读取的数据段。当I/O进程较少时,PnetCDF获益于进程增加带来的并行写入效率的增加,因此总体吞吐量随之增加;而受限于底层并行文件系统的写入带宽限制,PnetCDF库的吞吐量会达到峰值;之后随着进程数的进一步增加,两阶段I/O中的通信阶段代价会随之增大,因此总体的吞吐量会略有下降。
为了拟合这种先增加后减小的变化趋势,采用三次样条插值算法来对未知吞吐量数值进行估计。三次样条插值算法[14]是一种常见的插值算法,被广泛应用于各种理论研究和实际问题中,例如图形图像领域、数据同化领域[15-16]等等。相较于双线性等算法,三次样条算法能获得光滑连续的插值结果,更能满足PnetCDF吞吐量连续变化的数据特点,而且可以保证插值后的曲线仍满足PnetCDF库吞吐量先增大后减少的特征。具体的拟合效果将在后续实验部分呈现。
3.4 Trace分析子程序
Trace分析子程序负责根据I/O Trace文件统计目标地球系统模式程序的I/O特征信息,包括周期时间长度、一个周期内I/O请求数目、I/O平均请求大小等信息,其输入是目标模式程序的I/O Trace文件,输出为配置文件。
模式的I/O Trace文件是预执行阶段产生的,重新编写了CFIO库的两个函数,其名称和功能如表1所示。

表1 函数名称及功能
cfio_init函数是CFIO在PnetCDF接口的基础上新增加的一个函数,其主要作用是对CFIO的客户端、服务器进行初始化设置。对于cfio_init函数,加了一个标志位参数flag,用flag参数的值来表示是否需要进行I/O Trace输出,若flag值为0,表示正式运行程序,无需进行I/O Trace输出,在cfio_init函数中将全局变量tracing_flag设置为0;若flag值为1,表示模式程序处于预执行阶段,需要进行I/O Trace的输出,将全局变量tracing_flag设置为1。cfio_recv函数是CFIO服务器用于接收I/O请求并判断是否将其放入缓冲区的函数,在cfio_recv函数中先进行判断tracing_flag的值,如果tracing_flag值为0,则进行之前的操作;如果tracing_flag的值为1,则在将I/O请求加入缓冲区之前,按照维度遍历各个维度上count数组,即维度数据大小记录数组,将各个维度大小相乘得到此次I/O请求的数据块大小并同I/O请求到达时刻一起输出到屏幕上,在程序预执行的过程中将打印到屏幕的信息重定向到I/O Trace文件中。
在Trace分析子程序中,先对I/O Trace文件中I/O请求块大小信息和时间信息分开进行处理。根据3.1节对于地球系统模式中I/O特征的分析可知,I/O请求大小是分段一致的,为了保证在所有的周期内均不发生堵塞,需要统计出I/O请求块的最大值MaxSize并统计出I/O请求的总数量SumCount,这些操作仅需要对Trace中的块大小信息进行一次遍历即可获得。而对于周期的确定则相对复杂,首先要对Trace中的原始时间信息进行处理,CFIO中输出的时间是CFIO客户端启动之后的相对时间,单位为ms。为了便于后续操作,第一遍遍历以第一次I/O请求发出时间为基准计算出每一个I/O请求到达的相对时间,同时以秒为单位对相对时间进行向下取整;之后,第二次遍历时间信息,统计从第0到最后每一秒到达的I/O请求数目;第三次遍历是为了确定整个I/O过程的中各个I/O阶段请求个数最大值信息,记为MaxBlkNum;第四次遍历是记录I/O请求个数最大值出现的次数PeriodCount以及峰值第一次出现的时刻T1和最后一次出现的时刻Tend,则最后周期时间长度:

即用I/O请求个数最大值出现的次数表示在整个运行过程中的周期个数PeriodCount,而Tend与T1之间间隔了(PeriodCount-1)个完整的周期,两者相除即可得到每一个周期的时间长度。最后Trace分析子程序会将得到信息:I/O请求块大小的最大值MaxSize、I/O请求的总数量SumCount、周期个数PeriodCount以及周期时间长度T以文本的形式写入配置文件中输出。
3.5 参数选择子程序
参数自动选择程序负责根据记录在I/O速度记录文件中的平台相关信息和记录在配置文件中的目标模式相关I/O特征信息,计算出合适的CFIO库I/O进程数目和缓冲区大小。其输入为带宽测试子程序和Trace分析子程序的输出文件即I/O速度记录文件和配置文件还有预执行时计算进程的数目M,预执行时I/O进程数N,输出为合适的I/O进程数n和CFIO服务器端缓冲区大小BufferSize,并将结果打印到屏幕上。
整个计算过程的伪代码如图5所示,在整个参数选择计算过程中,先根据I/O Trace文件中的信息计算出要保证在一个周期内写入所有I/O请求所需要的PnetCDF写入带宽Threshold,即用Trace中I/O请求数量之和SumCount与周期数PeriodCount相除得到每个周期I/O请求的数量,乘I/O请求块大小的最大值MaxSize即为每一个周期最多处理的数据总量,再与周期时长T相除就可以得到所需要的写入带宽。之后,遍历I/O速度记录文件,得到S1、S2、S3和P1、P2、P3六个参数,其中S1表示I/O处理速度的峰值,S2表示在I/O速度上升阶段第二大的值,S3表示在I/O速度下降阶段第二大的值,而P1、P2、P3表示其各自对应的I/O进程数。接着,对多种情况展开讨论,如果Threshold大于S1,则表明可能的取值会在(P2,P3)区间内,对区间内所有可以整除计算进程数量M的值从小到大进行遍历,如果在I/O记录文件中存在则直接与Threshold值比较,如果不存在则进行插值比较,若存在大于Threshold的值则跳出循环。如果Threshold小于S1,需要找到其所在的速度区间的最小值S4和最大值S5及其对应的I/O进程数目P4和P5,其中S5有可能与S1、S2重合。之后从小到大遍历[S4,S5]区间,对于每一个可以被M整除的值对应的总体写入带宽进行插值操作,如果出现大于Threshold的值将直接跳出循环。

图5 参数选择程序伪代码
对于CFIO服务器端缓冲区的大小,根据公式(2)可知,BufferSize=MaxBlkNum×MaxSize,即I/O请求数目的峰值与I/O请求块大小的最大值相乘,可以根据Trace信息得到结果。
如果经过上述过程没有得到合适的I/O进程参数即找不到大于Threshold的值,说明该目标模式程序的写入数量超过了目前平台的写入处理能力,必然会出现堵塞,需要在写入速度峰值之前选择尽量多的I/O进程;如果找到了合适的I/O进程数n,将会连同BufferSize一起打印到屏幕上。
4 测试分析
在清华大学“探索100”百万亿次集群系统上,以海洋模式POP为目标程序,对该参数自动选择程序进行了测试。“探索100”集群的每个计算节点采用两个Intel Xeon X5670六核处理器,每个处理器主频为2.39 GHz,配有12 MB Cache;每个节点内存为32 GB,所有节点通过InfiniBand QDR通信网络实现高速通信,理论带宽为40 GB/s;使用Lusture并行文件系统作为其底层文件系统,配置为1个元数据服务器(MDS)和40个对象存储目标(OST),实测写带宽为4 GB/s;计算节点运行的操作系统为RedHat Enterprise Linux 5.5,所有程序使用Intel编译器v11.1编译,MPI版本为Intel MPIv4.0.2。
4.1 拟合效果测试
在“探索100”上运行带宽测试子程序,指定的最大进程数为256,得到的结果如表2所示。

表2 不同进程数目下PnetCDF写入带宽
为了验证插值算法的有效性,额外测试了当I/O进程数目为12、24、48、96和144时PnetCDF库的总体写入带宽的数值。如图6所示,其中蓝色圆圈代表带宽测试子程序中测量的写入带宽值,绿色曲线代表根据测量值插值获得的曲线,而红色折线代表了相应I/O进程数目时真实的写入带宽。根据结果可以发现,立方插值的结果反映了PnetCDF库总体写入带宽先增长后下降的趋势。同时在I/O进程数值较小时,拟合结果与实测值差距较小,随着I/O进程增大测量密度的降低,误差稍有增大,总体效果在可以接受的范围内。
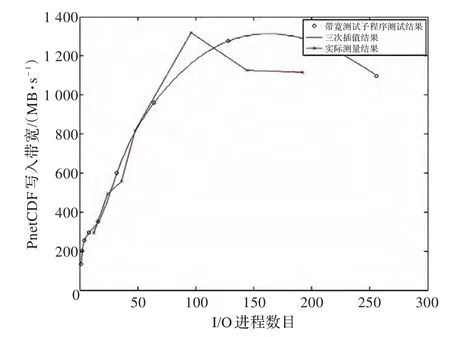
图6 三次样条插值效果
4.2 对海洋模式POP的测试
POP是美国洛斯阿拉莫斯国家实验室(Los Alamos National Laboratory)开发的海洋数值预报模式,利用POP模式可以推进10年期和大尺度气候预测科学的发展,现在已经成为许多气候模拟器中的标准模块。
在本次实验中,将POP的重启动文件输出频率设置为每10步一输出,映像文件和历史文件设置为每2步一输出,程序共运行40步,计算进程数M为120,在预执行阶段采用120个I/O进程,CFIO服务器端缓冲区大小设置为3 GB。
利用Trace分析子程序可以得到模式I/O特征信息为:I/O请求块最大值MaxSize为0.55 MB,I/O请求总数量SumCount为3 064个,周期个数PeriodCount为4,周期时长T为110 s。得出的满足条件的最小写入带宽为:
Threshold=120×3 064×0.55/4×110=459.6 MB/s
利用参数自动选择程序得到I/O进程数目为24,缓冲区大小为 1 141.25 MB,其中Throughput(24)拟合的结果为469.876 MB/s,大于Threshold值。
为了验证参数自动选择程序的正确性,在计算进程数目固定为120的情况下,分别用I/O进程数为20和24运行原有的POP程序,同时在CFIO服务器端cfio_recv函数中,在每一个请求加入缓冲区之间输出已用缓冲区大小信息和时间信息,并测量POP的整体运行时间。
如图7所示,当I/O进程为20个时,在340 s左右由于缓冲区已满,CFIO服务器堵塞不接受新的I/O请求,直到后端PnetCDF库处理让缓冲区有了新的空间,才会让新的I/O请求进入缓冲区,所以造成了I/O请求的时间分布被拉长,且在340 s处出现了每秒只有50个左右的I/O请求进入缓冲区,进而影响了模式程序的整体运行时间。当I/O进程为20个时,POP运行40步需要524.133 s;当I/O进程为24时,POP运行40步仅需要434.038 s。
而对于已用缓冲区信息,以秒为单位统计每秒内缓冲区使用大小最大值,结果如图8所示。
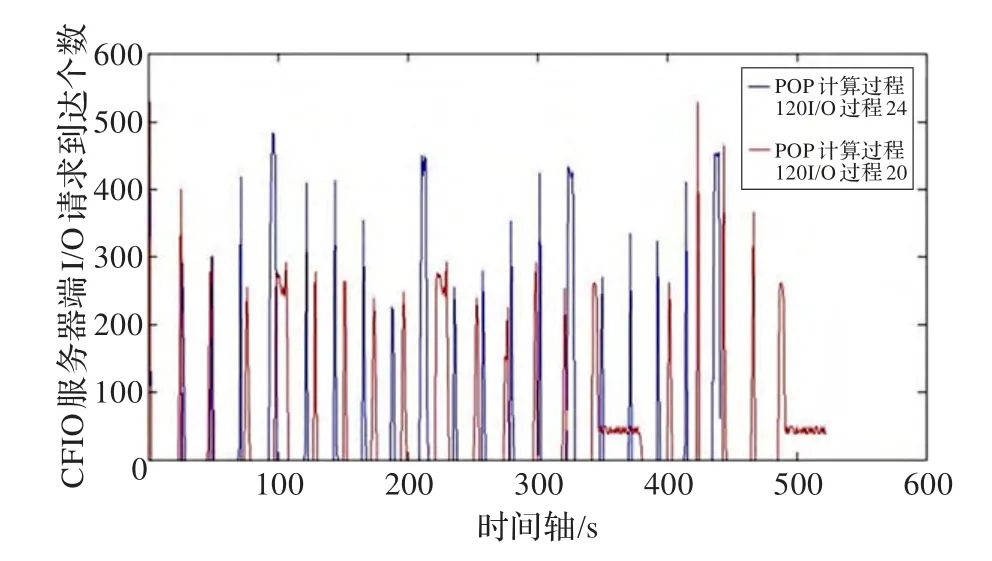
图7 POP计算进程120,计算进程20和24对比
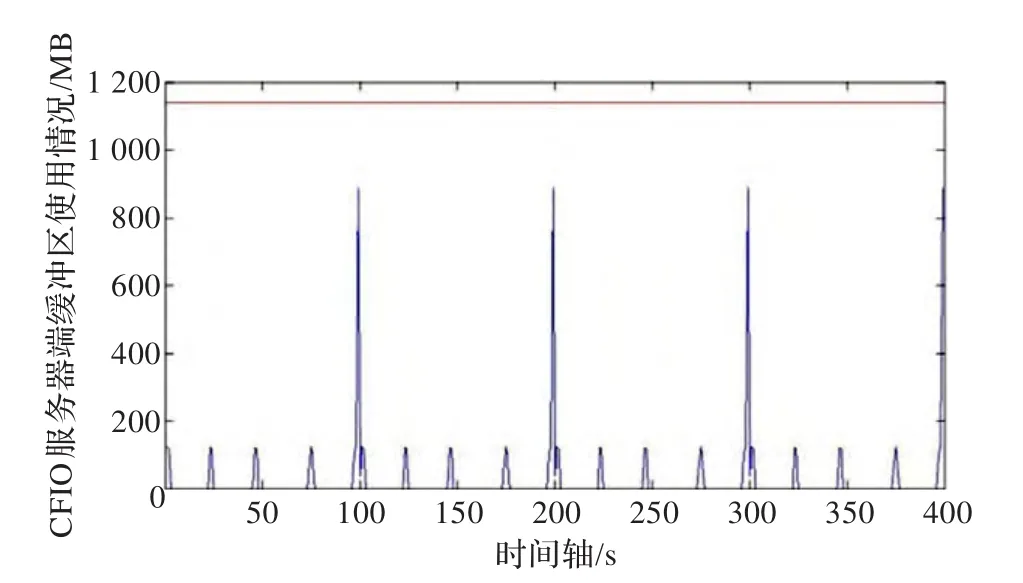
图8 CFIO服务器端缓冲区使用情况
缓冲区使用数量即图8中蓝色线在程序运行过程中始终没有超过本文通过参数选择子程序确定的1 141.25 MB的横线,即图中的红色线。
由以上分析可以认为,这套参数自动选择程序确实为海洋模式POP选择了在现有平台上的最优参数,既满足了性能的需求又避免了资源的浪费。
5 结束语
面向高分辨率地球系统模式的并行I/O库CFIO的出现,通过I/O转发技术实现了I/O过程与计算过程的重叠,提高了模式的整体性能。但是,对于缓冲区大小和进程数目的管理仅仅依靠过去经验式的参数指定方式会因为I/O过程与计算过程无法完美重叠而造成性能损失或者资源浪费,基于CFIO开发了一套参数自动选择程序,CFIO的使用者仅需要通过命令行的方式运行三个子程序就可以自动地获得针对当前平台当前应用的CFIO最佳参数。通过目标模式的预执行在CFIO的服务器端搜集模式I/O相关信息,并利用Trace分析子程序得出I/O块大小、数目等统计信息,结合带宽测试子程序得到的平台吞吐量相关信息,可以得到将I/O过程完美隐藏在计算过程中的参数设置。
对这套参数自动选择程序在POP和CICE两种分量模式上进行了测试。根据其提供的结果对CFIO进行设置可以发现,在相应参数下,POP和CICE都可以在使用尽量少的计算资源的情况下取得理论上最好的加速效果,可以让地学研究人员在模式中更加方便地使用CFIO。
[1]王斌,周天军,俞永强.地球系统模式发展展望[J].气象学报,2008,66(6):857-869.
[2]Strand G.Community earth system model data management:policies and challenges[J].Procedia Computer Science,2011,4:558-566.
[3]Huang X M,Wang W C,Fu H H,et al.A fast input/output library for high-resolution climate models[J].Geoscientific Model Development,2014,7(1):93-103.
[4]Dennis J M,Edwards J,Loy R,et al.An application-level parallel I/O library for Earth system models[J].International Journal of High Performance Computing Applications,2012,26(1):43-53.
[5]Docan C,Parashar M,Klasky S.Enabling high speed asynchronousdataextraction and transferusing DART[J].Concurrency and Computation:Practice and Experience,2010,22(9):1181-1204.
[6]Lawrence D,Yang L,Oleson K,et al.Community earth system model[Z].2010-10.
[7]Corbett P,Feitelson D,Fineberg S,et al.Overview of the MPI-IO parallel I/O interface[M]//Input/Output in Parallel and Distributed Computer Systems.[S.l.]:Springer US,1996:127-146.
[8]Rew R,Davis G.NetCDF:an interface for scientific data access[J].Computer Graphics and Applications,1990,10(4):76-82.
[9]Li J,Liao W,Choudhary A,et al.Parallel netCDF:a highperformance scientific I/O interface[C]//Supercomputing,2003 ACM/IEEE Conference.[S.l.]:IEEE,2003.
[10]Recio R,Culley P,Garcia D,et al.An RDMA protocol specification,IETF Internet-draft draft-ietf-rddp-rdmap-03.txt(work in progress)[R].2005.
[11]Smith R D,Gent P R.Reference manual for the Parallel Ocean Program(POP),ocean component of the Community Climate System Model(CCSM2.0 and 3.0),TechnicalReportLA-UR-02-2484[R].Los AlamosNational Laboratory,2002.
[12]Hunke E C,Lipscomb W H.CICE:the Los Alamos sea ice model documentation and software user’s manual,Tech Rep LA-CC-06012[R].Los Alamos National Laboratory,2004.
[13]Thakur R,Gropp W,Lusk E.Data sieving and collective I/O in ROMIO[C]//Proceedingsofthe 7th Symposium on Frontiers of Massively Parallel Computation(Frontiers’99).[S.l.]:IEEE,1999:182-189.
[14]李庆扬,王能超,易大义.数值分析[M].5版.北京:清华大学出版社,2008:41-44.
[15]Endrődi G.Multidimensional spline integration of scattered data[J].Computer Physics Communications,2011(6):1307-1314.
[16]Fahmy M F,Fahmy G,Fahmy O F.B-spline wavelets for signal denoising and image compression[J].Signal,Image and Video Processing,2011,5(2):141-153.
