自适应滤波语音增强算法改进及其DSP实现
2015-04-14王瑜琳田学隆高雪利
王瑜琳 ,田学隆 ,2,高雪利
1.重庆大学 生物工程学院,重庆 400030
2.重庆市医疗电子技术工程研究中心,重庆 400030
1 引言
语音通信中噪声干扰普遍存在,不可避免地降低了实际应用中语音通信的质量,严重时甚至会造成语义理解困难。语音增强的提出就是为了保证在减少语音失真度的同时,尽可能多地提取出有效的语音信号,抑制背景噪声,达到改善语音通信质量的目的。目前针对语音增强的研究大多致力于算法的改进,但缺乏实时性的处理系统,且依然存在适应性差,收敛速度慢等问题。因此,针对强噪声环境下的语音增强算法研究和系统研发具有重要意义。
目前应用较为广泛的语音增强算法主要有谱减法[1]以及自适应滤波法[2]。谱减法简单且对宽带噪声有显著的处理效果,但往往因对背景噪声估计不准确而产生较大的残留噪声。在这种情况下自适应滤波技术便发挥了其特有的优势,可在信号统计特性未知或变化的情况下,自动跟踪输入的变化,并不断调整自身参数,来达到最佳的滤波效果。传统的自适应滤波器大多采用双通道方式,与谱减技术相比,系统需多提供一路参考信号作为滤波器的辅助输入,这在一定程度上增加了系统设计的复杂性。针对这一问题,有研究指出取含噪信号的延时量作为滤波器的参考输入来构造单通道系统,可简化设计的复杂性[3-4]。而针对自适应滤波中存在的收敛速度慢,收敛精度差等问题,本文使用箕舌线函数[5-6]更新自适应滤波步长并引入解相关运算[7-8]更新权系数迭代方向,在加快自适应滤波收敛速度的同时提高精度。
在硬件实现上,本文选用具有高速帧处理能力的DSP[9-10]芯片与音频扩展芯片TLV320AIC23(简称AIC23)共同搭建系统的处理核心。在简化系统设计复杂性的同时完成了单通道语音增强系统的硬件设计、软件仿真及DSP实时实现。实验结果显示,经本文系统处理后能有效消除语音信号的背景噪声,提高语音的清晰度,证明了算法的有效性以及系统的可行性。
2 自适应滤波系统设计
2.1 基于时延结构的自适应滤波原理
语音信号是一种短时平稳信号,在10~30 ms内其频谱特性和相关特征参数基本不变,具有较强的相关性和准周期特性。而噪声通常是随机的,其自相关函数仅在原点处存在峰值[11-12]。因此可利用语音信号的相关性和噪声的不相关性,构造基于时间延迟方式的滤波系统,减小系统设计的复杂性。系统的结构形式如图1所示。

图1 时延结构自适应滤波原理
图1中期望输入v(k)为原始含噪语音,参考输入x(k)为v(k)延时后的信号。由于系统主要利用的是语音的相关性以及噪声的不相关性,来加强含噪语音的相关部分,同时削弱其不相关的部分,所以系统性能与信号间的相关特性密切相关,相关性越强就越容易从中提取出有用信号。
2.2 LMS算法设计
自适应滤波器的工作原理是依赖某一准则的约束,以实现对参考信号的最佳估计。常用算法有最陡下降法、最小均方误差算法(LMS)、递推最小二乘算法(RLS)等。在这一系列的算法中LMS算法以其运算简单,异于实现及稳健性能好等优点成为自适应滤波技术的首选算法,其基本迭代过程如下[13]。

其中,X(k)=[x(k),x(k-1),…,x(k-M+1)]T为M阶滤波器在k时刻的参考输入,y(k)为滤波器的估计输出,W(k)=[w(k),w(k-1),…,w(k-M+1)]T对应滤波器权系数矢量,μ为步长因子。然而LMS算法由于μ固定而存在收敛速度与收敛精度之间的矛盾,无法同时提高速度与精度。μ的选取对LMS算法性能的优劣起着决定性的作用:μ小可减小系统的稳定误差,提高算法收敛的精度,但降低了算法收敛的速度;μ大可加快收敛速度,却是以大的失调为代价的。为解决这一矛盾,出现了较多的改进型LMS算法,用一个变化的μ来优化LMS算法。
变步长的基本思想是在初始阶段用较大的μ来加快算法收敛的速度,收敛阶段则用较小的μ来减小系统的稳态误差。通过动态改变μ的大小,来获得最优的滤波效果。在这一过程中,μ的大小可依据不同的调控机制来进行调节,如W(k)、e(k)等。式(4)就是基于箕舌线函数而建立的μ与e(k)之间的函数关系式,参数α、β分别为函数形状及幅度控制因子。

由于 LMS 算法的收敛条件为μ∈(0,1/γmax),γmax为 X(k)的最大特征值,所以式(4)中μmax=β,因此有β< 1/γmax。
另一方面,由式(1)、(2)可得:

若定义Wopt(k)为最优权值向量,ξ(k)为零均值噪声,则v(k)可表示为:

由此可得:

其中Δ(k)=Wopt(k)-W(k)为权值误差向量。
将式(7)带入式(4)得:
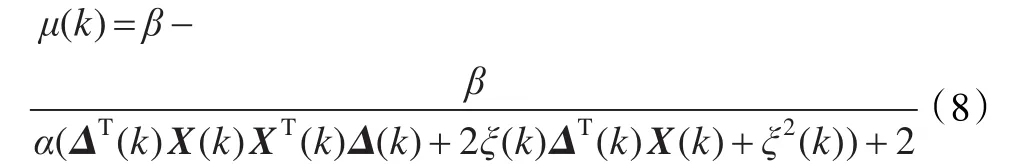
由式(8)可知,除独立噪声外,μ(k)还与 X(k)XT(k)密切相关。因此在输入信号高度相关的情况下,μ(k)除了与跟踪误差有关外,还受输入信号的影响,导致变步长自适应滤波算法的性能下降。若能在滤波前减小输入信号之间的相关性,便可加快算法收敛的速度。解相关运算的思想就是利用输入向量之间的正交变换去除输入信号之间的相关性。根据解相关原理,定义相关系数如下:

Γ(k)即为k及k-1时刻输入信号之间的关联性,从X(k)中减去 X(k)与 X(k-1)之间相关的部分便称为“解相关”运算,由此得出新的更新矢量如下:
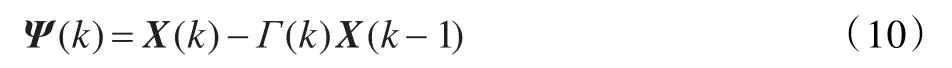
结合式(9)、(10)有 X(k-1)ΨT(k)=0 ,即解相关向量与k-1时刻的输入信号正交,正是这种正交关系,加快了LMS算法收敛的速率。基于解相关的权值迭代表达式为:
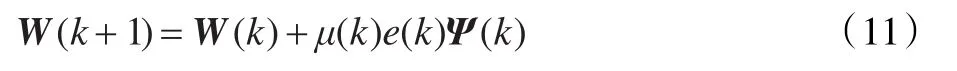
综上所述,本文自适应滤波算法过程如下:
(1)读入带噪语音v(k)并取其延时信号x(k)作为滤波器辅助输入,初始化W(0)。
(2)分别按式(1)、(4)、(10)计算滤波器输出y(k)、μ(k)以及权系数更新方向矢量Ψ(k)。
(3)将μ(k)、Ψ(k)代入式(11),更新W(k+1)。
(4)利用更新后的W(k+1)返回步骤(2),进行下一次迭代运算。
3 语音增强系统硬件及软件设计
3.1 基于DSP的语音增强系统硬件设计
TI生产的TMS320F281x系列DSP提供了多种外设通信接口,如串行通信接口(Serial Communication Interface,SCI)、串行外围接口(Serial Periperal Interface,SPI)、多通道缓冲串口(McBSP)等。其中McBSP支持全双工通信机制,并提供双缓存的发送和三缓存的接收寄存器,允许连续的数据流传输。数据长度通过编程设置,可与工业标准的解码器(CODEC)、模拟接口芯片(AIC)等直接进行串行连接。AIC23是一款Σ-Δ型高性能的音频编解码芯片,内部集成了16位A/D、D/A转换器,可与DSP的McBSP进行无缝连接,采样速率可通过DSP编程设置,高速实现语音信号的接收、发送。同时DSP以其高速的帧处理能力,灵活的运用方式以及低能耗等优点,逐步成为数字语音处理的首选。因此,本文选用TMS320F2812芯片作为主控芯片与AIC23及相应外围电路共同完成系统的硬件设计。然而DSP自带的程序和数据存储器容量有限,通常难以满足语音处理的需求,片外扩展了256K×16位SRAM作为外部数据存储器,512K×16位FLASH作为外部程序存储器。系统结构框图如图2所示。
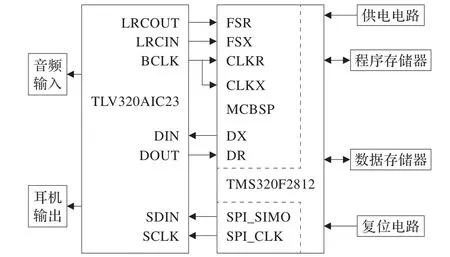
图2 DSP语音增强系统硬件结构设计
AIC23具有独立的控制接口和数据接口。控制接口用于配置器件内部的11个寄存器,设置音频芯片的工作状态,实现初始化AIC23的目的。控制接口的工作方式有SPI和I2C方式,可通过芯片管脚进行选择。数据接口则通过DIN、DOUT引脚传输AD转换和待DA转换的数据,实现与McBSP的无缝连接。数据接口的工作方式可通过数字音频格式寄存器设置为DSP模式,同时令AIC23工作于主模式下,即由AIC23提供时钟源,并通过分频器产生供串口通信的移位时钟及帧同步信号。其中CLKX、CLKR、BCLK为时钟同步信号,CLKR与CLKX之间通过一个0 Ω的电阻进行连接;FSX、FSR、LRCIN、LRCOUT为帧同步信号。在实现数据接口与McBSP的正常通信之前,需通过DSP的SPI口连续传输11串数据到控制接口,以达到配置AIC23的目的。设置AIC23时钟为正常模式,采样率为8K,并设置适当的输入/输出信号增益[14]。同时AIC23还具有一个其他音频处理芯片所不具备的功能,即模拟旁路设置,直接将输入的模拟信号送出去回放,而不经过AD及DA转换,这对于系统调试非常重要。
由于经AIC23采样输出的数据是串行数据,因此要先对McBSP的相关寄存器进行配置,以协调好与DSP的串行传输协议。即通过对McBSP内部的各寄存器(SPCR1、SPCR2、XCR1、XCR2、PCR1、PCR2、RCR 等)写入适当的控制字,使McBSP工作于SPI从模式下,同步McBSP的接收器和发送器,并使其在AIC23收发时钟的控制下,进行数据的接收和发送。设置McBSP的串行通信格式为单相位,每个相位一个字,每字传输16位,采用无压缩方式进行数据的传输。
基于DSP的McBSP和模拟接口芯片AIC23进行语音信号的数据采集和发送流程,如图3所示。
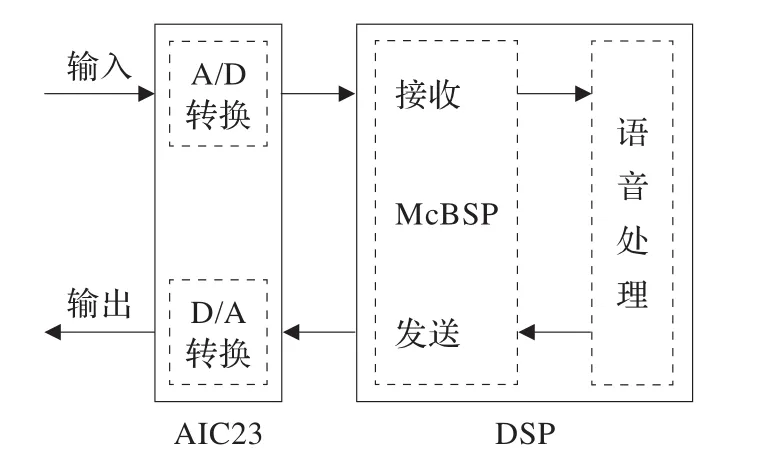
图3 基于DSP的语音处理流程图
麦克风采集含噪语音信号,并输入到AIC23进行抗混叠滤波、A/D转换,并经McBSP传至DSP芯片进行降噪处理。同时处理完的数据再经McBSP传回AIC23进行D/A转换、重构滤波。通常AIC23内置有耳机驱动电路,因此无需在外部进行驱动处理,而是直接由耳机输出经过降噪处理后的语音信号。
3.2 基于DSP的语音增强算法软件设计
首先通过MATLAB编写基于箕舌线和解相关的语音降噪算法,完成对算法性能的验证。然后在CCS集成开发环境下用C语言和汇编语言改写该算法,并下载至DSP进行在线仿真调试。系统软件实现流程如图4所示。
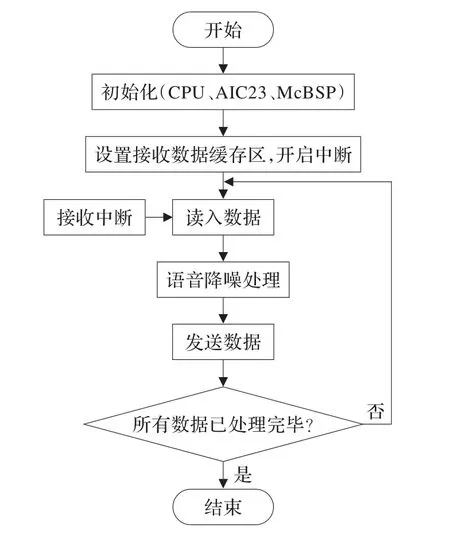
图4 系统主程序流程图
(1)合理分配程序和数据内存空间,将程序段和查表数据定义在FLASH中,仅进行读操作,数据段分配在DARAM中,可同时进行读写操作,避免调用和跳转造成流水延迟。
(2)通过配置片内时钟方式寄存器CLKMD实现DSP的CPU频率的初始化。
(3)利用DSP的SPI口,初始化AIC23内部各寄存器设置其工作方式、数据传输的位数、采样速率等。初始化McBSP,完成各串口寄存器的配置,保证其与AIC23的正常通信。
(4)开辟数据缓冲区,由于语音自适应滤波处理速度有时会跟不上数据接收速度。为避免丢帧,开辟多帧数据缓冲区,保存未处理的数据,在CPU空闲时间调用自适应滤波算法,完成缓存数据的降噪处理。
(5)开启串口接收中断,并开始接收数据。在每次中断处理过程中接收一个语音数据,同时发送一个已处理的语音数据,经McBSP传回AIC23进行后续处理并输出。
4 算法测试分析
4.1 基于MATLAB的算法性能测试
为了验证系统算法设计的有效性,本文在MATLAB平台上,从最小均方误差特性的角度出发,仿真对比在标准LMS算法、基于箕舌线函数的VS_LMS算法及本文使用的New_LMS算法作用下,系统的稳态误差及算法的收敛速度。仿真信号采用双极性随机序列构造,随机取值为+1、-1的伪随机信号通过FIR滤波器,并在输出端加入高斯白噪声,由此得到模拟的含噪信号。将该信号用于时延结构的单通道滤波系统,仿真计算采样点数为2 000,重复次数为1 000时系统的均方误差。仿真结果如图5所示。
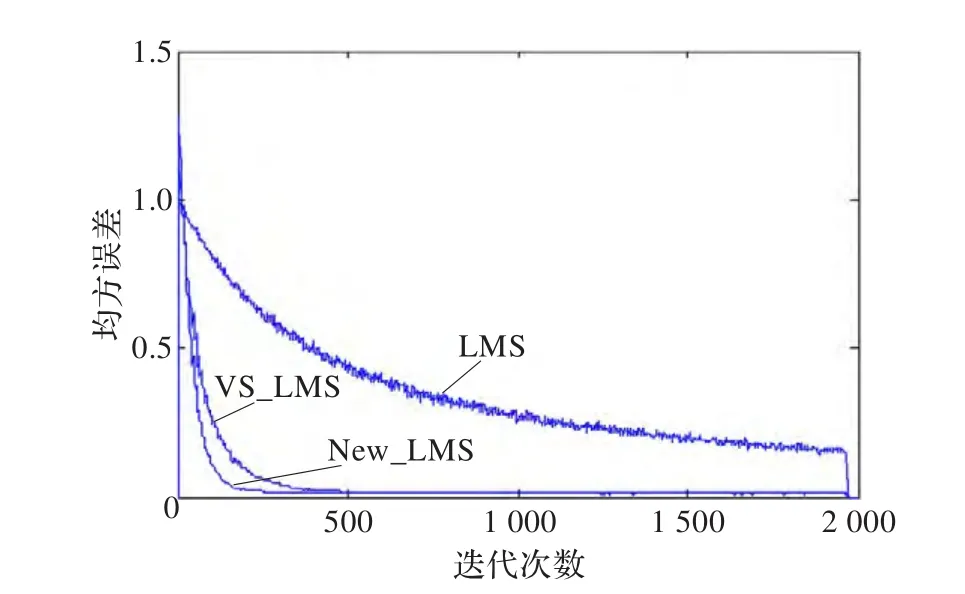
图5 三种LMS算法收敛性能比较
不同算法的相关参数设置及收敛性能比较,如表1所示。

表1 三种LMS算法参数设置及收敛性能对比
从图5和表1的稳态误差和到达稳态的迭代次数可知,对比于标准LMS,算法如果步长选取不合适,可能导致收敛速度很慢,且误差很大。在变步长算法的作用下,算法的收敛速度、稳态误差均得到了显著的改善。两种变步长算法相对比可看出,引入解相关原理之后,稳态误差基本不变,但算法收敛的速度得到进一步提高。由此证明了变步长解相关算法的有效性。
完成算法性能分析后,还需进一步验证算法的去噪效果。这里仿真信号选用标准女声朗读音频,对其添加白噪声后,取其延时信号与原始含噪语音共同构成噪声对消系统。使用上述三种方法分别进行降噪处理,处理效果如图6所示。
显然,结合图5、图6可知,本文算法在获得快速收敛速度与较小稳态误差的同时可有效去除加载在语音中的噪声成分,得到较纯净的语音信号。为进一步验证本文算法去噪效果,表2列出了语音信号在不同程度噪声干扰下,降噪处理前后的信噪比。
4.2 基于DSP的算法实时处理效果分析

图6 语音信号在不同算法作用下的降噪效果

表2 不同强度噪声干扰下SNR改善量 dB
完成降噪算法的MATLAB测试之后,就需要进一步对本文所设计的DSP处理系统进行硬件和软件电路的调试,来验证系统设计的可行性、稳定性及本文采用降噪算法的实时降噪效果等。首先依据MATLAB测试算法完成自适应滤波算法的C语言和汇编语言的移植,再根据音频芯片与DSP的通信协议实现系统的正常通信。测试中通过音频线将计算机声卡输出连接至AIC23音频输入端,并在计算机中播放待测试的噪语音音频文件。经AIC23完成AD转换后,输入到DSP芯片,利用集成开发环境(Code Composer Studio,CCS)对信号进行在线仿真测试,实现含噪信号的去噪处理及输出。为了清晰对比含噪信号滤波前后的波形效果,可在CCS环境下进入图形观察窗口,设置所需显示图形的相关数据的起始地址、显示的长度及数据类型等参数[15]。调试后,CCS图形显示窗口显示的波形如图7所示。

图7 基于DSP的语音信号降噪测试
观察波形易知,本文采用的滤波算法移植到DSP硬件系统上取得了显著的滤波效果,可显著去除语音信号中的噪声成分,接近MATLAB仿真效果,且算法效率高,能够稳定地实时处理。除了能直观观察波形变化外,还可以进行主观听觉测试,播放多个含噪音频文件,并使用耳机从AIC23输出端感受经DSP系统降噪后语音的听觉效果。对比未处理的含噪语音便可明显感觉语音信号变得清晰,可懂度也得到了提高。
5 结束语
本文采用基于时间延迟方式的单通道滤波系统,减小了语音增强系统设计的复杂性。在DSP平台上利用多通道缓冲串口McBSP和音频接口芯片TLV320AIC23进行串行通讯,实现了语音信号的高速采集和输出,运行稳定。在语音降噪处理上,引入了箕舌线变步长算法,同时提高传统自适应滤波算法收敛速度和收敛精度,有效地解决了跟踪速度与稳态误差之间的矛盾。引入解相关原理,使用输入向量的正交分量来更新权系数迭代方向,进一步加快了强相关信号的收敛速度和精度。实验表明,本文算法降噪性能好,能有效地消除噪声环境下语音信号的背景干扰,提高语音通讯的质量,具有一定的参考作用和应用价值。
[1]Paliwal K K,Schwerin B,Wojcicki K K,et al.Singlechannel speech enhancement using spectral subtraction in the short-time modulation domain[J].Speech Communication,2010,52(5):450-475.
[2]陈素芝,李英.一种基于变步长LMS算法的语音增强方法[J].声学技术,2005,24(1):42-46.
[3]万新旺,吴镇扬.基于自适应频率选择的鲁棒时延估计算法[J].东南大学学报:自然科学版,2010,40(5):890-894.
[4]Zhang Liyan,Yin Fuliang,Zhang Lijun.A new microphone array speech enhancement method based on AR model[C]//Proceedings of International Conference on Life System Modeling and Simulation,and Conference on Intelligent Computing for Sustainable Energy and Environment,2010:139-147.
[5]张安莉,陈丹.一种变步长自适应滤波算法在信号消噪中的应用[J].西安工业大学学报,2010,30(1):71-75.
[6]胡春娇,杨顺.基于箕舌线变步长LMS算法的分析与改进[J].计算机仿真,2010,27(11):359-362.
[7]段正华,王梓展,鲁薇.一种改进的解相关LMS自适应算法[J].湖南大学学报:自然科学版,2006,33(3):114-118.
[8]彭劲东,段正华,王梓展.一种变步长解相关LMS算法[J].计算机工程与应用,2004,40(30):136-138.
[9]TMS320x281x Multi-channel Buffered Serial Port(McBSP)Reference Guide(Rev.B)[M].[S.l.]:Texas Instruments,2004.
[10]TMS320x28lx,280x DSP Peripheral Reference Guide(Rev.B)[M].[S.l.]:Texas Instruments,2004.
[11]赵力.语音信号处理[M].北京:机械工业出版社,2003.
[12]夏冬冬.非平稳环境下的语音增强算法研究[D].西安:西安电子科技大学,2006.
[13]汪成曦,刘以安,张强.改进的最小均方自适应滤波算法[J].计算机应用,2012,32(7):2078-2081.
[14]田玉敏.基于DSP的激光侦听器语音处理研究[D].武汉:华中科技大学,2007.
[15]曹晓琳,吴平,丁铁夫.基于DSP的语音处理系统设计[J].仪器仪表学报,2005,26(8):583-585.
