基于Gammatone滤波器组的说话人识别算法研究
2015-04-14茅正冲王正创
茅正冲,王正创,王 丹
江南大学 物联网工程学院,江苏 无锡 214122
1 引言
说话人识别中最关键的问题之一就是提取有效的特征参数,目前常见的特征参数有线性预测系数(LPC)、线谱对参数(LSP)、Mel频率倒谱系数(MFCC)等[1]。然而,在实际的说话人识别系统中使用时,容易受到噪声的干扰,导致识别率降低[2]。人耳听觉系统是一个具有高度复杂性的系统,其研究意义非常重要,尤其是在噪声的环境下,人耳听觉系统比任何自动识别系统更具有可靠性、便捷性。因此,将人耳听觉模型融入到自动识别系统中,可以大幅提升系统的性能[3-5]。
声音的感受细胞在内耳的耳蜗部分,而基底膜是耳蜗接收声音最重要的组织。声波在外耳腔引起空气振动,从而引起行波沿基底膜的传播。基底膜能对不同频率的声音产生共鸣,反映不同频率的声音。不同频率的声音产生不同的行波,其峰值出现在基底膜的不同位置上[6-7]。
本文给出了一种基于人耳耳蜗听觉模型的Gammatone滤波器组,该滤波器组能很好地模拟基底膜的分频特性,并且基于该滤波器组,提出了一种Gammatone频率倒谱系数(GFCC)的提取算法,进而用于说话人识别系统中。在有噪声的背景下,该特征参数的识别率及鲁棒性优于传统的特征参数MFCC。
2 Gammatone滤波器
Gammatone滤波器[8-9]最早应用于描述听觉系统脉冲响应函数的形状,后来应用于耳蜗听觉模型,用来模拟人耳听觉频率响应,其时域表达形式如下:
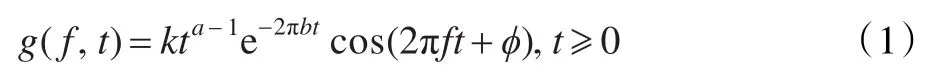
其中,k为滤波器增益,a为滤波器阶数,f为中心频率,ϕ为相位,b是衰减因子,该因子决定相应的滤波器的带宽,它与中心频率f的关系为:

由于Gammatone滤波器的时域表达式为冲击响应函数,所以将其进行傅里叶变换就可以得到其频率响应特性。不同中心频率的Gammatone滤波器的幅频响应曲线,如图1所示。

图1 一组不同中心频率下Gammatone滤波器的幅频响应曲线
3 GFCC特征参数的提取
根据Gammatone滤波器的特性,准备将该滤波器应用到说话人识别系统中。将输入的语音信号通过一组Gammatone滤波器,进而语音信号由时域转换到频域。这里采用的是一组64个的4阶Gammatone滤波器,其中心频率在50 Hz~8 000 Hz之间。由于滤波器的输出保留原来的采样频率,所以在这沿着时间维度,取响应频率为100 Hz,通道数为64的Gammatone滤波器。这样就产生了相应的帧移为10 ms,进而可以应用到短时间的语音特征提取中。当语音信号通过以上的滤波器时,输出信号的响应Gm(i)的表达式如下:
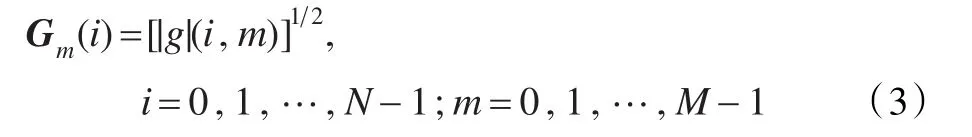
其中,N=64是滤波器的通道数,M是采样之后的帧数。
这样Gm(i)构成了一个矩阵,代表着输入信号在频域的分布变化,在这采用类耳蜗图[10]来描述输入信号在频域的分布变化。然而,与具有直观分辨率的语谱图[11]不同,类耳蜗图在低频段的分辨率优于在高频段的分辨率。图2是一段纯净语音信号的语谱图和类耳蜗图;图3是一段加噪语音信号的语谱图和类耳蜗图。从图中对比可以看出,类耳蜗图的分辨效果更加清晰,能更好地反映语音信号的能量分布,尤其是在有噪声背景下,类耳蜗图的优势更突出,更能反映出语音信号的特性。因此,将对类耳蜗图进行下一步的分析研究。
在这将类耳蜗图的每一帧称为Gammatone特征系数(GF),一个GF特征矢量由64个频率成分组成。但是在实际的说话人识别系统中,GF特征矢量的维度比较大,计算量较大。此外,由于相邻的滤波器通道有重叠的部分,GF特征矢量相互之间存在相关性。因此,为了减小GF特征矢量的维度及相关性,在这对每一个GF特征矢量进行离散余弦变换(DCT),具体的表达式如下:

图2 一段纯净语音的语谱图和类耳蜗图

图3 一段加噪语音的语谱图和类耳蜗图
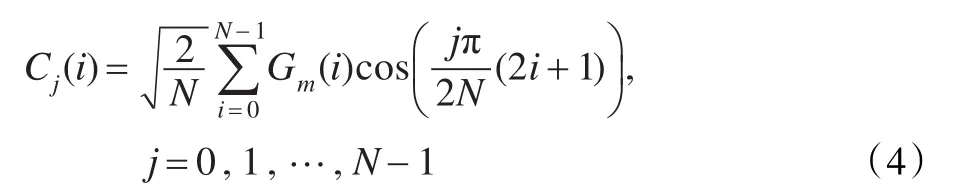
这里将系数Cj(i)称为GFCCs系数[12],严格来说,这个新的特征系数并不是倒谱系数。因为倒谱系数的产生一般要取对数能量,然而在这将GFCCs系数当作倒谱系数,是由于在上面的转换中和MFCC特征参数的提取转换有功能上的相似性。和MFCC特征参数类似,在实际的说话人识别系统中,并不是取全部维数的GFCCs系数,经过实验表明最前若干维以及最后若干维的GFCCs系数对语音的区分性能较大,在这取前26维的GFCCs系数[13]。这样GFCC特征参数的表达式如下:
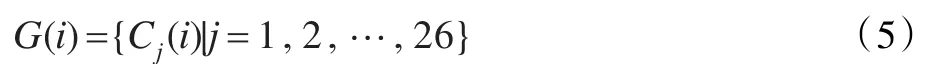
图4是基于图2中类耳蜗图的分析示图。图4(a)是GF系数,图4(b)是基于26维GFCCs合成的GF系数,图4(c)是基于26维GFCCs合成的类耳蜗图。

图4 类耳蜗图的分析示图
4 实验结果与分析
本文所采用的语音库是在实验室环境下录制的,语音采用的是单声道,8 kHz的采样频率,16 bit量化。该语音库由20人录制的,每个人录制10段语音,每段语音时长约5 s,其中每个人的4个语音段作为训练样本集,另外6个语音段作为测试样本集。混入的噪声选自NOISEX-92标准噪声库[14-15],采用的识别方法是高斯混合模型(GMM),GMM的混合数是16。
首先,在大信噪比的背景下,分别提取每个说话人的特征参数MFCC和GFCC。MFCC的提取采用26个Mel频率滤波器组,经DCT变换计算26维的倒谱系数。GFCC的提取采用64通道的Gammatone滤波器,经DCT变换后取26维的GFCCs系数。经过特征参数提取后,进行说话人识别实验,实验结果如表1。
其次,为了测试噪声环境下特征参数MFCC和GFCC的识别性能,选取噪声库中三种典型噪声作为测试系统的背景噪音。在这里选用的三种典型噪声是White噪声、Babble噪声、Factory噪声,信噪比为0 dB、5 dB、10 dB、15 dB,实验结果如表1。

表1 特征参数MFCC和GFCC的识别率(%)
从表1中可以看出,在大信噪比的背景下,GFCC的识别率能达到95%以上。在三种不同的噪声背景下,特征参数GFCC的识别率明显高于MFCC。随着SNR的增大,识别率越来越高,其中在Babble噪声背景下,由于受到背景中不同说话者之间的相互干扰,以至于系统的平均识别率略低于其他两种噪声。此外,在Factory噪声背景下,SNR为15 dB时,系统采用特征参数GFCC的识别率能达到80%以上,远高于特征参数MFCC。因此这些可以充分证明,采用Gammatone滤波器组模型对语音进行时域前端滤波是很有效的,这种模型具有很强的抗噪性,也说明了特征参数GFCC对加性噪声具有一定的抑制性,进一步体现了基于人耳耳蜗听觉特征的噪声鲁棒性。
5 结束语
本文给出了一种基于人耳耳蜗听觉模型的Gammatone滤波器组,并且基于该滤波器组,提出了一种GFCC的提取算法。实验结果表明,在说话人识别系统中采用特征参数GFCC,其识别率及鲁棒性都优于传统的特征参数MFCC,GFCC能降低加性噪声的影响,抑制加性噪声的不稳定性。此外,采用特征参数GFCC的计算量大,以及在短时间内进行说话人识别时,识别效果还需进一步改进。因此,如何减少说话人识别系统的计算量,提高系统的识别效率以及实现在短时间内识别将是接下来的研究工作。
[1]屈丹,王波,李弼程.VoIP语音处理与识别[M].北京:国防工业出版社,2010.
[2]蔡莲红,黄德智,蔡锐.现代语音技术基础与应用[M].北京:清华大学出版社,2003.
[3]尹辉,谢湘,匡镜明.一种基于Gammatone滤波和FrFT的抗噪语音识别方法[C]//第十届全国人机语音通讯学术会议暨国际语音语言处理研讨会论文摘要集.北京:清华大学出版社,2009:5-8.
[4]牛廷伟.噪声环境下的语音识别关键技术研究[D].天津:天津理工大学,2011.
[5]金银燕,于凤芹.基于Gammatone滤波和PCNN的说话人识别[J].科学技术与工程,2010,10(30):1671-1674.
[6]何朝霞,潘平.基于听觉模型的说话人语音特征提取[J].微型机与应用,2012,31(1):37-39.
[7]陈世雄,宫琴,金慧君.用Gammatone滤波器组仿真人耳基底膜的特性[J].清华大学学报:自然科学版,2008,48(6):1044-1048.
[8]王玥,钱志鸿,王雪,等.基于伽马通滤波器组的听觉特征提取算法研究[J].电子学报,2010,38(3):525-528.
[9]王玥.说话人识别中语音特征参数提取方法的研究[D].长春:吉林大学,2009.
[10]Shao Yang,Wang Deliang.Robust speaker identification using auditory features and computational auditory scene analysis[C]//Proceedings of IEEE International Conference on Acoustics,Speech and Signal Processing(ICASSP2008),March 30-April 4,2008.[S.l.]:IEEE,2008:1589-1592.
[11]张雪英.数字语音处理及MATLAB仿真[M].北京:电子工业出版社,2003.
[12]ZhaoXiaojia,Shao Yang,WangDeliang.CASA-based robustspeakeridentification[J].IEEE Transactions on Audio,Speech and Language Processing,2012,20(5):1608-1616.
[13]He Xu,Lin Lin.A new algorithm for auditory feature extraction[C]//Proceedings of InternationalConference on Communication Systems and Network Technologies.Washington,DC,USA:IEEE Computer Society,2012:229-232.
[14]胡峰松,曹孝玉.基于Gammatone滤波器组的听觉特征提取[J].计算机工程,2012,38(21):168-171.
[15]Shao Yang,Jin Zhaozhang,Wang Deliang.An auditorybased feature for robust speech recognition[C]//Proceedins of International Conference on Acoustics,Speech and Signal Processing(ICASSP2009),19-24 April,2009.[S.l.]:IEEE,2009:4625-4628.
