面向中文专利的开放式实体关系抽取研究
2015-04-14赵奇猛王裴岩冯好国蔡东风
赵奇猛,王裴岩,冯好国,蔡东风
沈阳航空航天大学 知识工程研究中心,沈阳 110136
1 引言
机器阅读旨在从大规模、非结构化文本中自动抽取知识,并将其应用到问答等任务中,一直是人工智能的主要目标[1]。
目前作为机器阅读手段之一的信息抽取大多关注于抽取二元实体之间的语义关系,David[2]认为动词至多作用于二元,若用一阶逻辑来形式化表式实体关系,那么多元关系可以通过多个二元谓词表示,在一阶逻辑形式意义表达的基础上,可以方便地进行深层推理。如“橙汁富含维他命C,维他命C防止疾病”用一阶逻辑可表示为“富含(橙汁,维他命C)∧防止(维他命C,疾病)”,通过推理可得到“防止(橙汁,疾病)”的隐含关系。传统的信息抽取需要预先定义所有的关系类型并附带标注过的一些实例,但随着数据尤其是网络信息的海量增长,目标关系类型过多甚至是未知的,此时仅仅依靠抽取规则或标注语料是不可能实现的。
早期Aone等[3]能够抽取100种关系和事件,但专家手工构建规则费时费力。Hasegawa等[4]利用上下文信息对识别的实体进行聚类,抽取频率较高的语义标签作为实体集的关系,但抽取的颗粒还不够精细。KnowItAll[5]采用领域独立的抽取模板,针对指定的关系进行抽取,能从大量网页中抽取多种实体关系。缺点是需要用户在每次抽取信息之前指出一个感兴趣的关系。后期出现大量基于统计的机器学习方法,很大程度上减少了用户的参与并增强了领域的适应性,但抽取的关系有限。
近年来出现的开放式信息抽取技术(Open Information Extraction,OIE)为应对大规模文本信息提供了新的思路和研究范式,即利用语言自身的完备性,抽取大量关系。如TextRunner-2008[6]利用启发式规则从宾州树库生成训练样本,抽取浅层特征训练二阶线性链CRF抽取模型,结合信息冗余过滤模型,从开放式文本中自动抽取关系三元组。Liu等[7]利用MLN将实体的识别和关系的分类统一起来联合推理抽取,相比于Text-Runner有较大提升。ReVerb[8]利用浅层句法和词汇约束,很好地解决了TextRunner抽取的无信息量和错误信息的问题。但这些系统有两个主要缺陷:一是仅抽取以动词为核心的关系;二是忽略上下文全局信息。OLLIE[9]利用学习到的开放式模板和依存分析很好地解决了以上问题。开放式信息抽取系统的结果已经被用来支持如获取常识知识[10]、识别蕴涵规则[11]和本体映射[12]等任务。
面对开放领域,如何针对每一领域内实体类别确定其关系类别,是开放式关系抽取的首要难点[13]。目前急需解决的难题是制定能表示关系的词的标准。与以英文为代表的西方语言取得的重大进展相比,中文在这方面的研究还很少。主要原因有:(1)缺少词的屈折形态,如,中文难以通过形态特征从动词序列中确定核心动词;(2)重语义而弱句法,关系词的是否难以通过句法特征判断,如,“……在/p MNP[接口/ng 20/sym]接收/vg MNP[编码/vg 参数/ng]”中的“接受”是关系词,而类似的句法形式“……在/p MNP[横截面/ng]是/vx MNP[任何/r 形状/ng]”中的“是”则相反;(3)汉语表达多出现省略,如省略主语。
为此,本文提出一种在组块内外层标注基础上应用马尔可夫逻辑网模型分层次进行中文专利开放式实体关系抽取的方法。实验结果显示:(1)在内外层组块标记的基础上进行开放式实体关系抽取的可行性;(2)本文提出的MLN-G模型F值优于SVM。
2 相关背景
2.1 中文专利依存树库
汉语缺少形态变化,句式灵活而又不像英语句法模式强。按照认知科学的观点,人们必须首先识别、学习和理解文本中的实体或者概念(具体的或抽象的),才能很好地理解自然语言文本,而这些实体和概念大多是由文本句子中的名词短语所描述,也就是说,如果掌握了文本中的名词短语,就可以在很大程度上把握文本所表达的主要意思,抽取出令人满意的信息,而且组块分析已经获得了广泛的研究。因此,本文设想在组块的基础上进行开放式实体关系抽取(Open Entity Relation Extraction,OERE)可行性的探索。
本文实验依赖于本单位构建的中文专利依存树库(Chinese Patent Dependency Treebank 1.0,CPDT1.0)。CPDT1.0的句子来源有生物、化学、计算机和机械等领域,其标记的内容主要有分词、词类、组块和依存等。本文利用的主要语义信息为前三项。其中组块标记分为三类:最大名词短语(MNP)、并列结构(BL)、术语(SY)。如“MNP[该/r SY[单向阀/ng]]允许/vg MNP[水/ng]按照/vg MNP[箭头/ng所/ussu示/vg的/usde方向/ng]流入/vg MNP[由/p BL[SY[片状物/ng]100/m和/c所/ussu述/vg SY[壁/ng]部分/ng 102/m]所/ussu限定/vg的/usde空间/ng]。/wj”。其中MNP可包含BL和SY,BL也可包含MNP和SY,SY为最小单位。语义实体来自上述三类组块。外层组块指不被其他任何组块标签包含,内层组块指被其他组块标签包含的。CPDT1.0各项分布统计见表1。
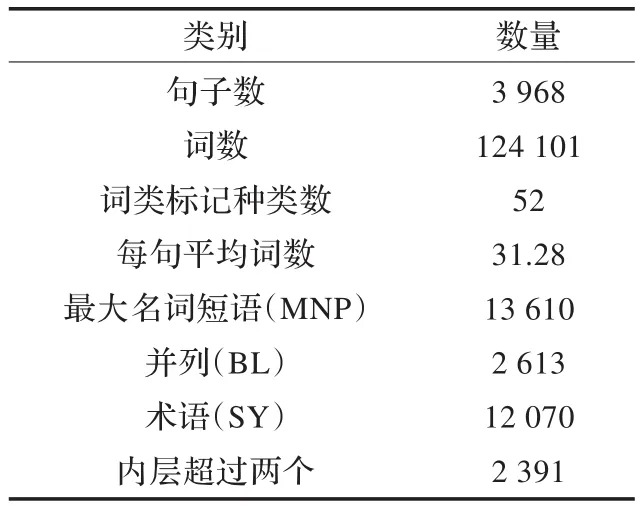
表1 中文专利依存树库统计表
2.2 Markov逻辑网
许多现实世界的问题具有不确定性和复杂结构。统计学习在解决不确定性上取得了很大的成功,比如贝叶斯网络和马尔可夫网络等;而关系学习主要针对客观世界的复杂结构,比如一阶逻辑编程等模型成功地为现实世界的逻辑性建模。统计关系学习希望能同时考虑这两个重要的因素。Markov逻辑网[14](MLN)是一种将Markov网络与一阶逻辑相结合的统计关系学习框架,为大型Markov网提供了一种精练的知识描述语言,为一阶逻辑增加了模糊推理能力。容易集成知识挖掘中的先验知识和结构输出,可以提高知识挖掘的效率。
其基本思想是弱化一阶逻辑的约束:即便一个可能世界(或状态)违反了知识库中的逻辑公式,也不是不可能发生,只是发生的概率变小。公式附带的权重体现了其限制强度,权重越大,越趋向于纯一阶逻辑知识。MLN被证明是更通用的模型,如CRF和概率关系模型等是其特殊的情况。MLN的一个主要任务是定义能反映普遍规律的一阶逻辑模板公式,能够很好地继承之前逻辑和无向图模型的相关理论。
MLN可看作用一阶逻辑公式来实例化Markov网络的模板语言,是公式φ及其相应权重w的集合,它定义了一个可能世界y的联合概率分布:
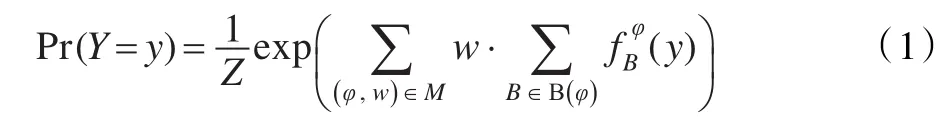
其中Z为归一化常数;B是将φ中的自由变量对应到常量的一个绑定;(y)是二元特征函数,若在y中将φ的自由变量替换为B中常量所得的公式为真,其值为1,否则为0。
Markov逻辑网的基本推理任务是给定证据 找到一个最可能的世界y,也称为MAP推理,即:
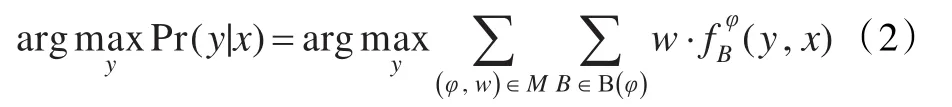
则推理归纳为寻找一个值使得可满足子句的权值之和最大。即使在规模很小的领域,直接计算也是很棘手的,本文使用一种既准确又高效的基于整数线性规划(ILP)的割平面算法[15](CPI)来进行推理。对于MLN的公式权重学习,采用Online Max-Margin的权重学习方法[16]。
3 开放式实体关系抽取方法
3.1 开放式实体关系抽取问题定义
OERE 的形式定义为三元组t=(ei,rij,ej),i≠j,其中ei和ej代表语义实体的字符串,rij代表两个实体之间关系的词序列。因为rij可以通过句子中的词来确定,所以不需要预先定义关系。需要注意的是三元组是有顺序的,即 (ei,rij,ej)≠(ej,rij,ei)(有对称性质的除外,如,“A 连接 B”,其中A和B分别代表组块,下同)。
本文中,ei和ej包括基本的名词短语及嵌套的名词短语和介词短语,rij包含的关系词有动词和修饰词,动词需要模型识别,如,“A 确定/vg设置/vg B”中识别“设置”为关系词。修饰词可以通过后处理获得,一般会就近依附于动词,如“难以”和“于”等。
3.2 获取实体关系对标注语料
在分析CPDT1.0组块特点的基础上,提出自动发现隐含动词之间的关系和识别关系的MLN模型。为了学习公式权重,需要构建三元组实例。有两个问题待解决:一是实体对如何组对;二是确定表示实体对的语义关系在句中的位置。为解决第一个问题,本文将相邻实体两两成对。例如“A利用B产生 C”,相邻两两组对有{A和B,B和C}两对。通过两两成对可以获得10 771对的实体对。至于第二个问题,本文提出以下假设。
假设代表两个实体之间语义关系的动词位于实体之间。
本文通过均匀随机采样,发现代表关系词的动词来源于实体对左右边界外的500对中,标记为正例的仅占0.01,虽然会过滤一些来自左右边界外的关系词,如“A与B通信”,通信可以看作是A和B之间的关系,但因在语料中出现比例较少,所以不计。而采样400例动词,来自实体对之间的则占0.55。故假设合理。
过滤不满足假设的实体对后,剩下未标注的有8 539对。实例对的标注通过自扩展[17]结合人工校验最终生成外层5 595对标注实例。包含的关系种类有1 020种,外层占91.76%。其中,自扩展的底层模型选择的是支持向量机,因其能够在小样本上取得较好的性能。
MNP和BL中可能会包含实例对,如“其中/r MNP[SY[非/h 挠性/ng 部件/ng](/wkl此后/t称为/vg“/wyl SY[片状物/ng]”/wyr)/wkr 的/usde 前/nd 端/ng] 旋转/vg支承/vg……”。包含的内层三元组为t={“SY[非/h 挠性/ng 部件/ng]”,“称为”,“SY[片状物/ng]”}。从887对内层实例中随机采样标注200对。
3.3 马尔可夫逻辑网公式定义
为识别动词是否为关系词及实现句子级别的结构输出,本文定义了两个隐谓词isRel(rn,i)和unRel(rn,i),前一个表达的意思是序号为rn的实体对位置i的词是关系词。同时利用负例信息,定义否定谓词unRel(rn,i)表示序号为rn的实体对位置i的词不是关系词。除了隐谓词之外,本文定义了描述语料中可用信息的观察谓词,如表2所示。
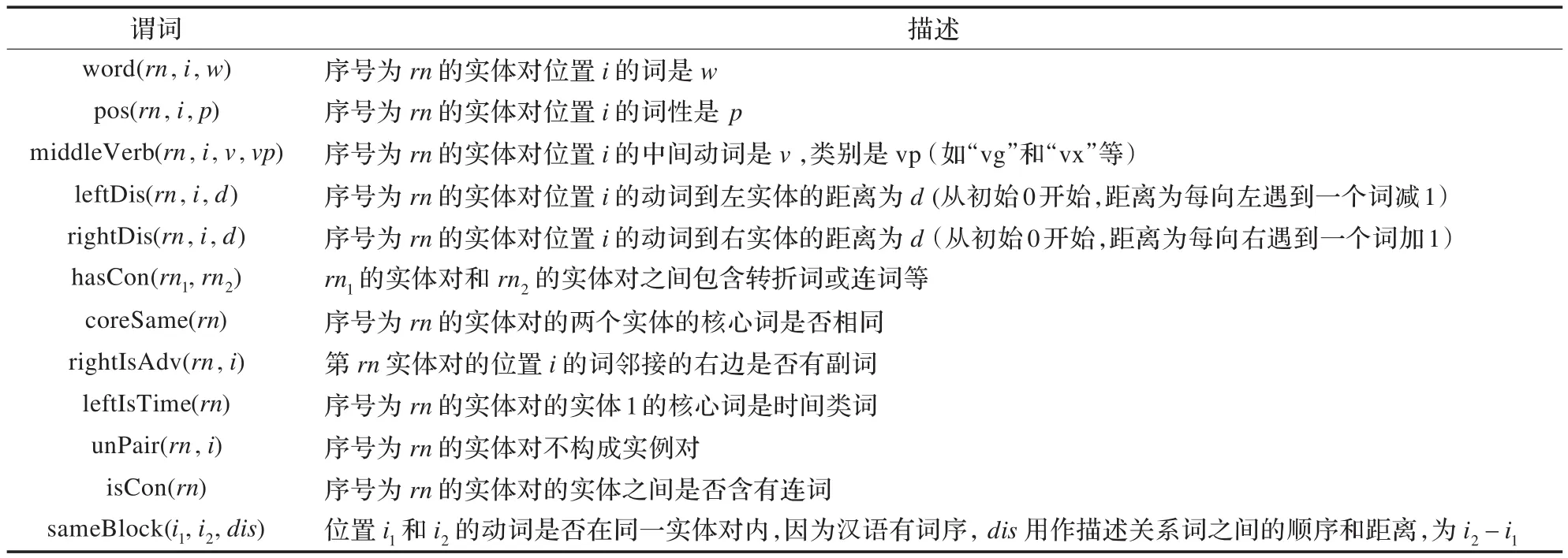
表2 观察谓词
定义好谓词,需要定义描述关系的公式。MLN中的公式可以分为局部公式和全局公式。
3.3.1 局部公式
局部公式通常表示关系词的局部特征,用来判断隐谓词是否成立。
实际应用中,公式中含有“+”的变量指实例变量,即需被替换为同类型集合中的常量,实例公式由公式中各个实例变量的笛卡尔积组合而成。MLN引擎为每个实例公式赋予相应权重,其他变量隐含为全称量词。公式结尾处有点号的代表严格约束(hard rule),反之为软约束(soft rule)。
词和词性特征可在一定程度上判断动词是否为关系词。如,从“MNP[SY[棱柱形/ng]结构/ng的/usde各边/r长度/ng]约/d为/vx MNP[1.5/m-/sym 2/m cm/sym]。/wj”中发现“约/d”可以充当动词“为”的修饰,可推出“为”可能是关系词;又如,从“在/p BL[MNP[第一/m 位置/ng]和/c MNP[第二/m 位置/ng]]之间/nd往复/vq 移动/vg,/wo 使得/vg MNP[SY[烤炉/ng]内/nd的/usde 材料/ng,……]”中的“在/p”和“之间/nd”识别实体1为状语,则中间的动词可能不构成关系词。式(3)和(4)是描述词和词性性质的公式:
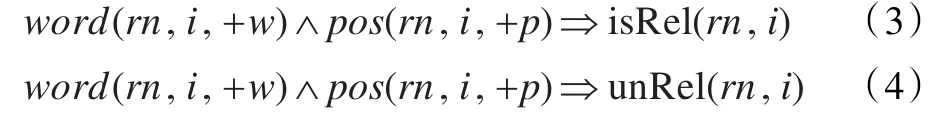
其中词和词性特征的范围取决于实体的上下文,设句子序列为{…,w2/p2,w1/p1,ent1,mid/midp,ent2,w1/p1,w2/p2,…}。如果窗口为1,特征可取w1/p1和mid/midp;窗口为2,可取w2/p2、w1/p1和mid/midp。mid/midp代表ent1和ent2中间的词/词性序列。为了泛化识别的关系词,mid/midp不包含待判断的关系词和词性。
距离特征在传统实体关系抽取中被广泛运用,实验发现在开放式实体关系抽取中同样有很好的效果,如式(5)和(6):
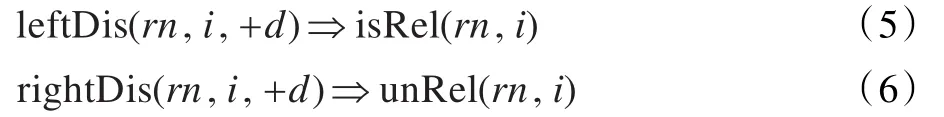
式(7)表示关系词及其词性的先验分布,此处没有利用负例是因为实验发现这样可以防止语料的偏置:
不同于传统授课,翻转课堂中学生所需投入的时间与精力较多,所以评价方法是否全面、客观、公平,对课堂效果的提升显得非常重要。目前的评价方法结合课前与课中,课前重视学生的努力程度,即任务是否完成、对团队的贡献量大小等,而课中则注重学习质量,强调学习深度。大多数研究者认为学生可以从翻转中获益,但能否提高成绩,则较为保守。加之翻转环节多,学生深度学习无法考量等,所以如何发展出一套适用的测评工具和方法来评估翻转课堂的效果,未来还需更长时间的观察与科学研究才能确定。
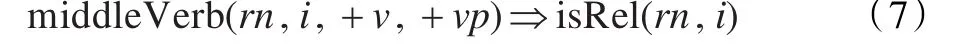
从“MNP[SY[路面板/ng]的/usde宽度/ng]等于/vg MNP[一个/m 行车道/ng的/usde宽度/ng]”中可以看出,如果实体核心词相同,动词可能作为关系词;从“MNP[塞/ng 301/m]可/vz与/p MNP[SY[充气器/ng]44/m]一起/d使用/vg,/wo或者/c代替/vg MNP[SY[充气器/ng]44/m]。/wj”中发现核心词相同且“使用”和“代替”有并列关系,推出动词可能不是关系词,如式(8)和(9):
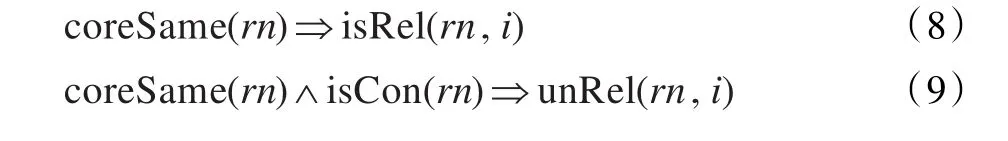
倘若关系词右边有副词,如“MNP[图/ng 3E/sym]示意/vg地/usdi示出/vg MNP[SY[麦克非/ng]……]”中的“示意”右边有“地/usdi”,则表明这个动词作修饰语不是关系,如式(10):
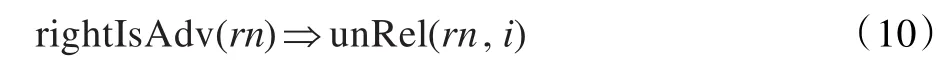
如果实体1含有时间类词,那么一般来说实体1作为状语,公式定义如下。
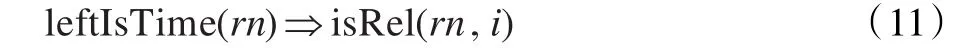
如果实体之间有连词,句子表达的意思是另一层,中间的动词可能不是关系词,如“MNP[所/ussu述/vg SY[片状物/ng]]可/vz由/p MNP[SY[驱动/vg单元/ng]83/m]进行/vg 驱动/vg,/wo 并且/c MNP[SY[扭簧/ng]11/m]……”中含有连词“并且”。负例有相反的现象,如式(12)和(13):
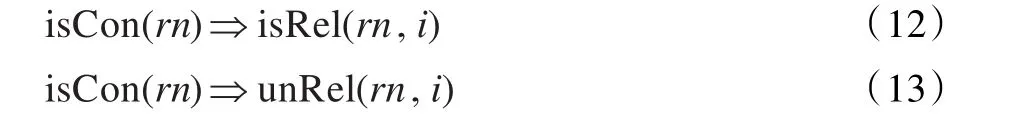
通过启发式规则容易发现一些实体不构成实体对,则第rn个实体对动词i不是关系词,通过式(14)描述:
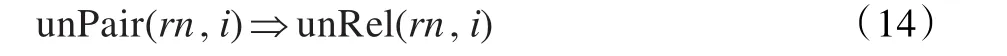
3.3.2 全局公式
涉及两个以上的隐谓词为全局公式,主要目的是建立隐谓词之间相互依存关系并使最终结果满足一定约束。在Markov逻辑网上,能够通过构建不同规则,来模仿很多算法任务。如式(15)~式(18)描述句子级别关系的结构输出:

汉语中常常会出现动词上下文的省略,导致特征不足,可以通过联合推理解决以上问题。如果两个关系词相同,先识别简单的,借助确定的推断难以判别的,如式(19)所示:

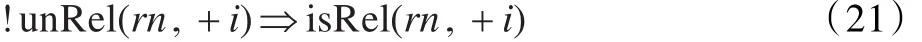
3.4 后处理
为使抽取结果更完善,建立词表,如果实体以及关系词左右紧邻的词出现在词表中,将其扩充。比如,实体扩充把方位名词“中”、“上”和“内”等扩充进来;动词扩充把相关的副词和介词扩充进来,如“难以”、“不”、“了”和“于”等。
4 实验结果及分析
4.1 实验设置
因SVM在实体关系抽取中被广泛运用,又能够同时利用正负实例,故将其作为对比实验。
为验证在组块的基础上进行开放式实体关系抽取的可行性和和对比本文提出的Markov逻辑网模型的效果,本文设置两组对比实验,一组是SVM、MLN-L(只包含局部公式和上述最后两个全局约束公式)和MLN-G(包括所有公式)对外层抽取效果的对比,另一组是在同样条件下对内层抽取效果的对比。
SVM工具包选用的是SVM-Light,内、外层用的核函数为线性核,SVM选取的特征与MLN相同。为防止距离特征影响过强而导致震荡的问题,对其进行缩放,区间为[-1,1]。MLN网实现的工具包用的是thebeast,外层学习规则为Plain Perceptron,内层为1-best MIRA。外层带标注的实例对共计5 595对,正例占44.25%;内层共计200对,正例占36%。第一组实验利用外层语料进行十折交叉验证,并比较了上下文窗口为1和2的情况。
第二组实验将所有外层语料作为训练集,内层为测试集。
4.2 结果及分析
第一组和第二组实验结果分别如表3、4所示。
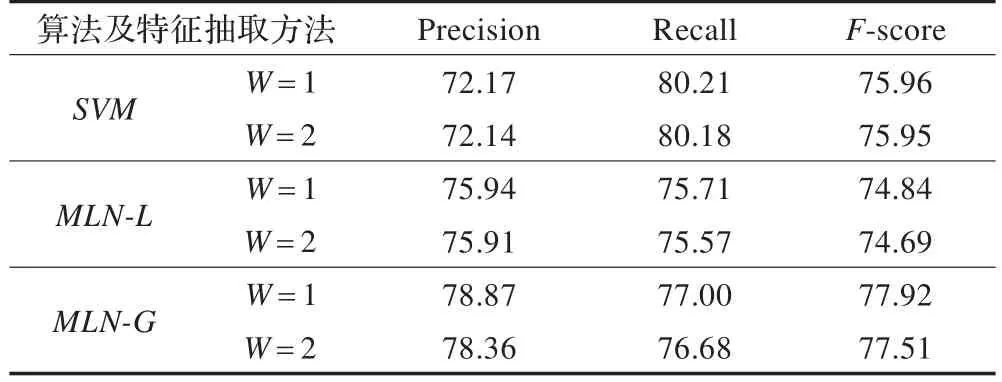
表3 SVM、MLN-L和MLN-G外层实验结果对比(%)
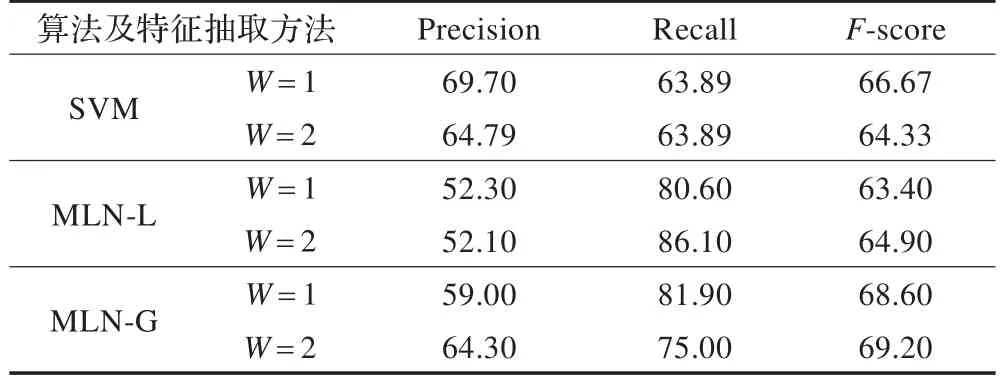
表4 SVM、MLN-L和MLN-G内层实验结果对比(%)
从实验结果来看,在组块的基础上实现OERE具有可行性。对于外层,如果将每个实例作为独立的实例,不考虑彼此的影响,MLN-L稍逊于SVM,但差别不大,主要原因是工具包的实现利用的采样随机算法不能获得全局最优解;而MLN-G明显高于其他两个。主要原因有:MLN-G考虑关系的结构输出和联合推理。如,通常“A 描述/vg为/vx B”中“为”是关系词,通过学习隐谓词的依赖关系能够发现,当得出“描述”不是关系词时,推得“为”是关系词,公式权重为0.026,反过来发现“为”是关系词时,能推出“描述”不是关系词的公式权重为0.019。
5 结束语
开放式实体关系抽取以及MLN是近年来文本信息处理和机器学习领域的研究热点,但是当前关于中文的开放式实体关系抽取研究较少。本文提出一种在组块标注基础上应用马尔可夫逻辑网分层次进行中文专利开放式实体关系抽取的方法,验证了句子经过组块分析后更易处理,且MLN-G模型较SVM取得更好的效果。
今后,将进一步考虑处理以名词和形容词等为核心关系的词,并融合实体的识别,做联合推理,从而更好地解决语料的稀疏问题,有助于中文Web的开放式信息抽取的研究。
[1]Poon H,Domingos P.Unsupervised ontological induction from text[C]//Proceedings of theForty Eighth Annual Meeting of the Association for Computational Linguistics,Uppsala,Sweden,2010:296-305.
[2]David D.Thematic proto-roles and argument selection[J].Language,1991,67(3):547-619.
[3]Aone C,Ramos-Santacruz M.REES:a large-scale relation and event extraction system[C]//Proceedings of the 6th Applied Natural Language Processing Conference,2000.
[4]Hasegawa T,Sekine S,Grishman R.Discovering relations among named entities from large corpora[C]//Proceedings of ACL,2004.
[5]Etzioni O,Cafarella M,Downey D,et al.Unsupervised namedentity extraction from the web:an experimental study[J].Artificial Intelligence,2005,165(1):91-134.
[6]Banko M,Cafarella M J,Soderland S,et al.Open information extraction from the web[J].Communications of the ACM,2008,51(12):68-74.
[7]刘永彬,杨炳儒.基于马尔可夫逻辑网的联合推理开放式信息抽取[J].计算机科学,2012,39(9):627-633.
[8]Etzioni O.Open information extraction:the second generation[C]//Proceedings of International Joint Conference on Artificial Intelligence,2011.
[9]Schmitz M,Rart R,Soderland S,et al.Open language learning for information extraction[C]//Proceedings of Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning(EMNLP-CONLL),2012.
[10]Lin T,Etzioni O.Identifying functional relations in Web text[C]//Proceedings of EMNLP,2010.
[11]Schoenmackers S,Etzioni O,Weld D S,et al.Learning first-order horn clauses from web text[C]//Proceedings of EMNLP,2010.
[12]Soderland S,Roof B.Adapting open information extraction to domain-specific relations[J].AI Magazine,2010,31(3):93-102.
[13]赵军,刘康,周光有,等.开放式文本信息抽取[J].中文信息学报,2011,25(6):98-110.
[14]Domingos P,Lowd D.Markov logic:an interface layer for artificial intelligence[M].San Rafael,CA:Morgan&Claypool,2009.
[15]Riedel S.Improving the accuracy and efficiency of map inference for markov logic[C]//Proceedings of the Annual Conference on Uncertainty in AI,2008.
[16]Huynh T N,Mooney R J.Online MaxMargin weight learning for markov logic networks[C]//Proceedings of the 11th SIAM International Conference on Data Mining,2011:642-651.
[17]Mihalcea R.Co-training and self-training for word sense disambiguation[C]//Proceedings of CoNLL,2004.
