CET-4作文评分人评分标准使用情况的研究
2014-08-24徐鹰
徐 鹰
(华南理工大学外国语学院,广东广州 510641)
CET-4作文评分人评分标准使用情况的研究
徐 鹰
(华南理工大学外国语学院,广东广州 510641)
本研究采用混合研究法对CET-4作文评分人如何使用评分标准进行分析。26位CET-4作文评分人对30篇CET-4模拟作文评分,并提供3条按重要性排序的评分理由。研究结果显示:(1)虽然存在严厉度的差异,但是26位评分人之间的一致性比较好,且大部分评分人的自身一致性也较好。(2)部分评分人的评分理由呈现了单一化趋势。(3)评分人所给评分理由的71.91%体现了CET-4作文评分标准所规定的5个文本特征,说明大部分评分人对标准的理解和把握还是比较准确的。
CET-4作文评分标准;混合研究法;评分理由
一、引言
CET-4写作测试采用的是总体评分法,即用一个分数和不同层级的描述语来表征写作质量[1]。虽然Charney[2]、Elbow[3]等人对总体评分法的主观性提出了质疑,但由于其具有较高的信度和效度、较强的可操作性等优点[4],还是得到了广泛肯定和运用。在这种评分模式下,阅卷质量除了受客观因素(如评分标准)的影响,同时还取决于评分人的主观判断,即评分人所给分数是否反映了文本特征[5]。因此,对评分人的研究历来也是语言测试研究的核心内容之一。本文拟在前人研究[6-7]的基础上,探讨CET-4作文评分人对评分标准的理解和使用情况,具体回答以下两个问题:(1)CET-4作文评分人给分一致性如何?(2)CET-4作文评分人所给评分理由能否反映评分标准?
二、研究设计
(一)研究对象
来自广州市9所高校的26位CET-4作文评分人在2012年7月CET-4作文阅卷期间参与了本研究。他们都通过了当次CET-4作文阅卷培训,且都教授大学英语课程,拥有硕士及以上学位。评分人平均年龄为32.96岁(SD=3.80),平均教龄为9.35年(SD=4.10),平均参加CET-4作文改卷次数为8.15次(SD=3.93)。为方便操作,以ri(i=1,2,…,26)的方式来标识评分人。
(二)研究材料和工具
来自广州某大学的200名大一非英语专业学生参加了本研究,他们都没有参加2012年6月的CET-4考试,笔者担任他们的大学英语任课教师。首先,在这次CET-4考试结束后第三天的课堂教学中,要求学生就作文题目“On Excessive Packaging”写一篇随堂作文。然后,笔者按照CET-4作文评分标准对作文进行了初评。最后,根据初评分进行随机分层抽样,从200篇作文中选择了30篇作文作为研究材料。这30篇作文涵盖了2分档(0~3分)、5分档(4~6分)、8分档(7~9分)、11分档(10~12分)和14分档(13~15分)等5个评分等级。
研究工具有CET-4作文评分标准[8]以及评分理由编码框架。CET-4作文评分标准要求评分人从以下5个文本特征给分:切题、表达思想的清晰性、语篇的连贯性、语言表达的准确性、篇幅及完整度。在Shi评分理由编码方案[9]324-325的基础上,笔者制定了本研究的评分理由编码草案,经过3轮实验和多次修正,最终确定了能对所有评分人的评分理由进行归类的评分理由编码框架。接着还邀请了一名语言测试方向的博士研究生对7位评分人(占总评分人数的26.92%)的评分理由进行编码。在她所编码的606条评分理由中,不同编码人之间的信度(intercoder reliability)达到了95.71%,从而验证了该编码框架的可靠性。
(三)数据搜集
阅卷工作第一天主要是对评分人进行培训,因此本研究在阅卷开始后第二天进行。30篇作文复印后随机排序,并在第二天工作结束时分发给评分人。评分人在第二天晚上给全部作文评分,同时按重要性顺序为每篇作文提供3条评分理由,所有材料要求在第三天工作开始前交回。相较于有声思维法,提供评分理由的方法相对更为简单,容易操作,有利于搜集更多的样本。
(四)数据分析
由于可以在同一洛基量尺(logit scale)上对所有层面(如考生、评分人)进行建模,多层面Rasch模型(Multi-faceted Rasch Model)在做事测试中的培训效果研究、评分人偏颇性研究以及量表效度验证等方面得到了广泛的运用[10-12]。本研究采用FACETS 3.58软件[13]进行数据分析,构建的数学模型包括评分人、考生两个层面,这两个层面可用下面数学模型表示:
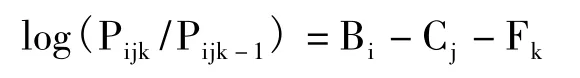
其中Pijk表示评分人j给考生i打k分数的概率;Pijk-1表示评分人j给考生i打k-1分数的概率;Bi是考生i的写作能力;Cj是评分人j的严厉度;Fk是k分数相对于k-1分数的难度。
三、结果和讨论
(一)评分人一致性分析
SPSS 18.0软件的统计结果显示26位评分人的Cronbach ɑ值为0.991,说明参加研究的评分人间一致性非常好,其主要原因在于参加此次实验的大部分评分人的阅卷经验丰富。
多层面Rasch模型分析结果显示:26位评分人的严厉度存在显著差异,最严格的评分人r15(0.90 logits)和最宽松的评分人r18(-1.00 logits)之间相差1.90 logits。全体评分人的平均严厉度为0.00 logits(SD=0.39)。12位评分人的严厉度高于平均值,14位评分人的严厉度低于平均值。Knoch指出,如果评分人的严厉度在平均值±0.50 logits之外,则可以认为其显著偏严或偏松[14]。因此r15、r10和r11显著偏严,r25、r18显著偏松,其他21位评分人的严厉度适中(见表1)。
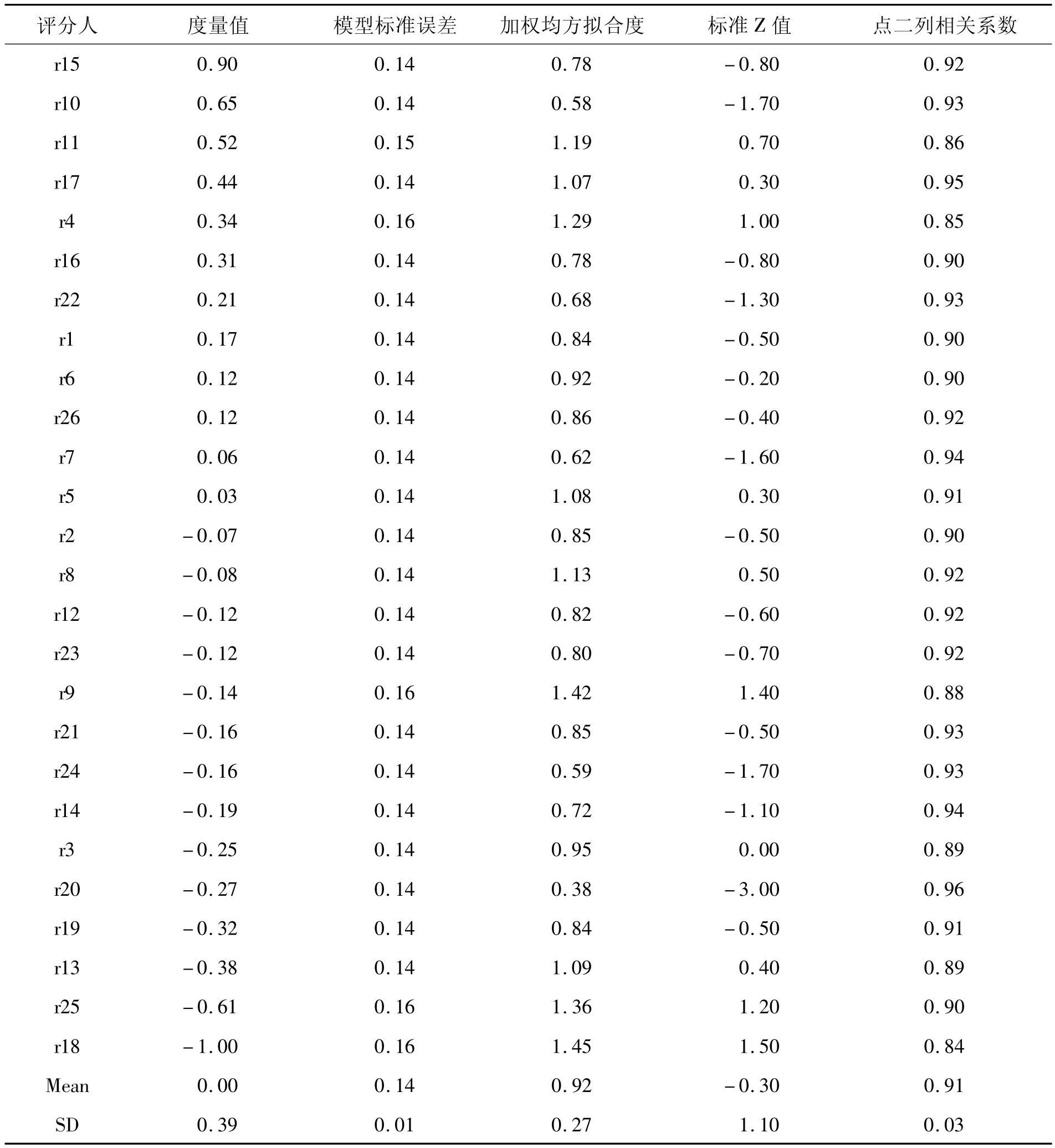
表1 评分结果统计
表1的第4列是加权均方拟合度(Infit MnSq),显示的是评分人自身一致性。McNamara建议其可接受的取值范围在平均值±2SD之间[15],因此本研究设定取值区间为(0.38,1.46):大于1.46的评分人评分出现不拟合(misfit),即评分人自身一致性较差;小于0.38的评分人的评分出现过度拟合(overfit),即评分人的评分没有区分考生的差异,可能存在集中趋势。除r20外其他所有评分人的加权均方拟合度均在合理范围内,说明绝大部分评分人自身一致性较好。此外,表1的第5列标准Z值也可作为判断自身一致性的依据,Z>2为显著不拟合,而Z<-2为过度拟合[16]。所有评分人中只有r20出现了过度拟合,这进一步验证了上述结论。
表1的最后一列数据显示,26位评分人的点二列相关系数(PtBis)介于0.84至0.96之间(Mean=0.91,SD=0.03),没有出现典型的随机效应,在可接受的范围内[17]208。但r18的点二列相关系数(0.84)低于平均值-2SD(0.85),说明该评分人的评分具有一定随机性,在使用某些分数段时其评分有明显不一致的地方,导致其对部分考生的分数高低排序与其他评分人有显著差别。分隔信度(0.87)和卡方分析(χ2=176.50,df=25,p=0.00)说明评分人的严厉度有显著差异。分隔比率(2.54)说明评分人的严厉度差异比测量误差大2倍多。按照Myford&Wolfe的分离指数计算公式(4G+1)/3,其中G为分隔比率[17]196,可算出分隔指数为3.72,说明评分人的严厉度大约可分为4个不同层次。
以上分析说明,虽然26位评分人之间的一致性较好,且大部分评分人的自身一致性也较好,但也存在一些个别问题,如r20的评分出现过度拟合,而r18的评分具有一定随机性。
(二)评分理由分析
由于评分人对CET-4作文评分标准理解和把握存在差异,容易导致分数相同但评分理由不同,而评分理由编码分析可以在一定程度上揭示这种差异。
1.评分理由编码框架概述
评分人评分理由编码框架包括6个大类和15个小类,具体见表2。
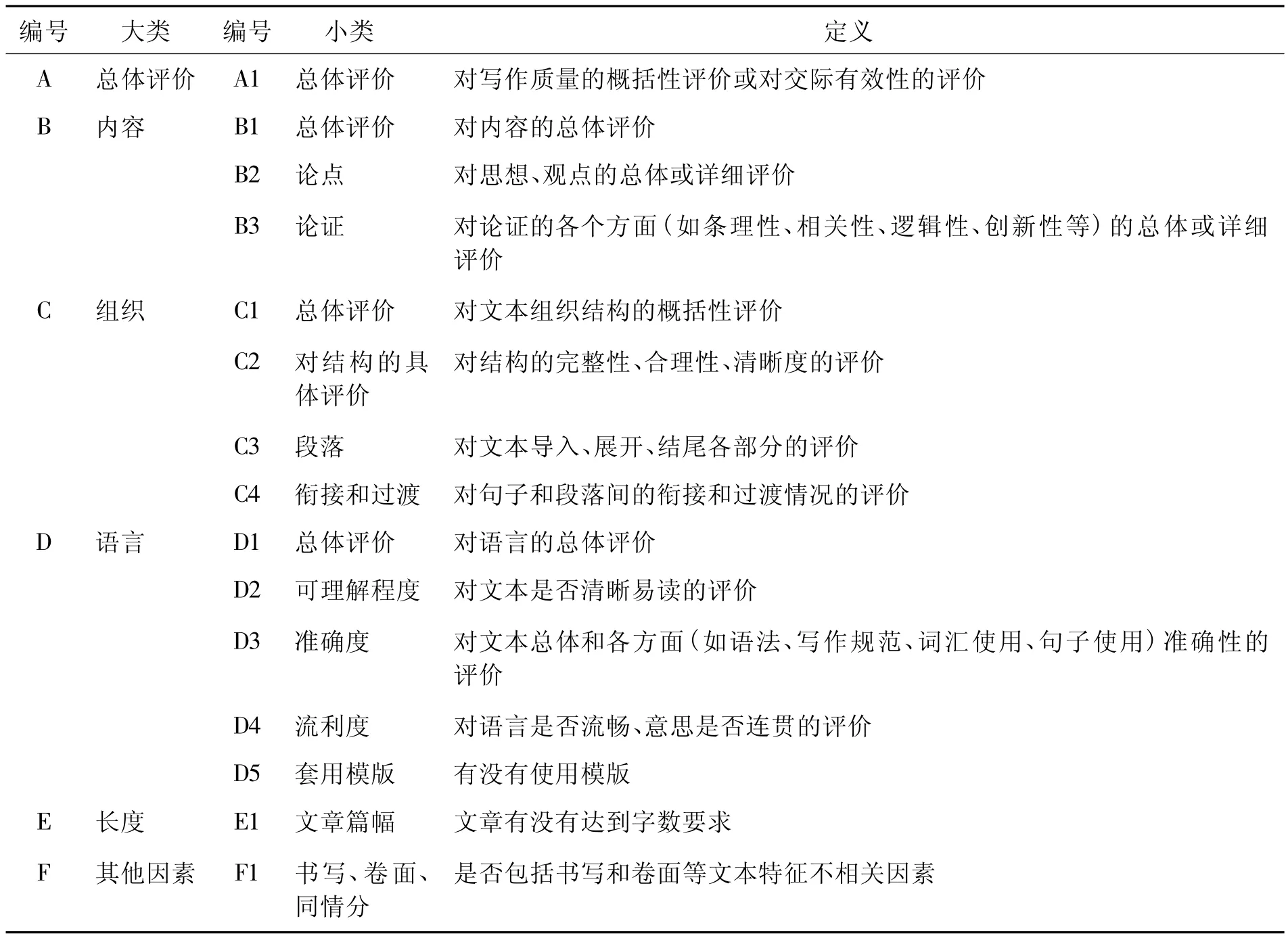
表2 CET-4作文评分人评分理由编码框架
2.评分理由编码的描述性统计
因为有少数评分人没有对每篇文章给足3条评分理由,所以26位评分人对30篇作文共提出了2104条评分理由,低于理想值(2340),其描述性统计见表3。

表3 评分理由编码的描述性统计
表3的第2列是评分理由1(即最重要的评分理由),B3(论证)数量最多(407条)。第4列是评分理由2,D3(准确度)数量最多(246条)。第6列是评分理由3,D3(准确度)的数量也是最多(309条)。在全部2104条评分理由中,语言大类(D)出现频数最多(1102),占比最高(52.38%);而准确度(D3)在小类中出现频数最多(681),占比最高(32.37%)。这个结论也印证了前人研究的结果:英语为非母语评分人在作文评分时更关注语言形式,尤其是语言的准确性[9]312[18]。
卡方分析显示,3条评分理由在5个大类上(由于F类频数太少,无法做统计分析)有显著差异(χ2=438.10,df=8,p=0.000)。且3 条评分理由在 B 类(χ2=351.21,df=2,p=0.000)、C 类(χ2=21.26,df=2,p=0.000)、D 类(χ2=84.39,df=2,p=0.000)和 E 类(χ2=14.31,df=2,p=0.001)上都有显著差异。
3.评分人的评分理由与CET-4评分标准的契合度分析
就评分人个体而言,评分人提供的主要评分理由占比情况的描述性统计见表4。
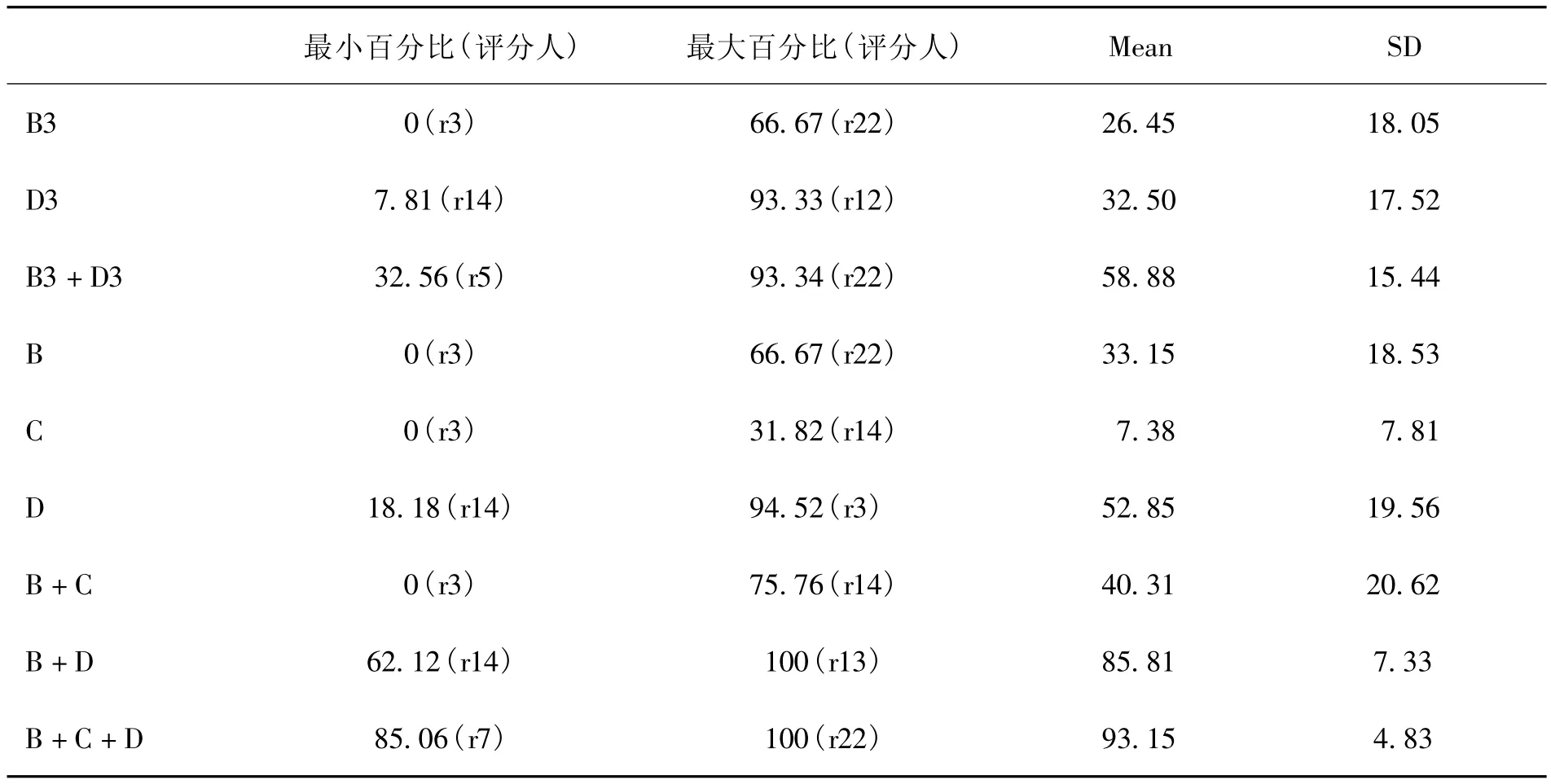
表4 评分人主要评分理由占自己全部评分理由的百分比
由表4可见:(1)就评分人个体而言,B类、C类和D类总占比的平均值达到了93.15%(SD=4.83),全体评分人中该值最小的r7也达到了85.06%,说明全部评分人的评分理由都集中分布在B类、C类和D类。(2)B类和D类总占比在全体评分人中最小的r14达到了62.12%,且B类和D类总占比的平均值高于B类和C类,而B类和D类总占比的标准差低于B类和C类,说明相较于B类和C类,全部评分人的评分理由更集中分布在B类和D类。(3)r3的评分理由中没有出现B类和C类,而D类则有94.52%;r12的D3类占比为93.33%;在r22所提出的全部评分理由中,B3类占比为66.67%,同时B3是其唯一的B类评分理由。这些结果都说明部分评分人的评分理由呈现标准单一化趋势,即所谓的评分还原主义(reductionism)[19]。
图1是B类和D类评分理由分布散点图。由图1可见,20位评分人(76.92%)的评分理由中D类占比高于40%,而11位评分人(42.31%)的评分理由中B类占比高于40%。上述现象的主要原因如下:首先,评分人都是有多年经验的、母语为非英语的大学英语教师,在教学中接触大量语言错误,对语言错误特别敏感;其次,参与本研究的学生的二语能力还不高,尤其是写作等产出性能力,因而语言准确性能较有效地区分学生。

图1 B类和D类理由分布散点图
在本研究中,与CET-4作文评分标准相关特征对应的评分理由编码频数为1513条(71.91%),这说明大体上评分人能按照CET-4作文评分标准所规定的文本特征评分,但仍有超过1/4的评分理由同评分标准不相关,典型例子如论证的创新性、套用模版等(见表5)。张洁对13位CET-4评分人的有声思维的文本编码研究也得出了类似结论[20]。这种评分标准不相关特征对测试的效度构成威胁,同时也间接说明CET-4作文评分标准作为一个基于专家直觉和经验开发的量表,需要不断进行效度验证并在相关研究基础上加以改进。

表5 评分理由编码与CET-4作文评分标准相关特征的对应
对于以上研究结果,有两个问题值得进一步思考:
第一,考虑到大部分评分人经验丰富,为什么还会出现28.09%的与CET-4作文评分标准不相关的评分理由呢?Pula&Huot[21]的观点值得参考:评分人丰富的评分经验已经帮助评分人建构了一套内在标准,多年的评分实践已经证明了这套标准的有效性。然而,仍有必要立足实证研究结果对CET-4作文评分标准进一步加以完善。
第二,为什么在有部分评分理由与CET-4作文评分标准不完全契合的情况下,大部分评分人评分的严厉度和自身一致性仍然在可接受范围之内呢?我们认为最重要的原因还是在于总体评分标准本身。首先,CET-4作文评分采用印象分,主观性较强,因此评分理由的差异和分数理解的歧义不可避免[22]。Lumley认为,即使评分人尽可能按照评分标准来评分,但还是会受到对文本初次阅读时的复杂直觉心理意象的影响,而这种影响难以用评分标准消除[23]。最终评分人是按照他们的感觉对文本的心理意象进行评分,而不是按照评分标准的规定进行评分;而且在实际评分工作中,由于评分人工作压力大,且每天要完成一定的评分量,这种情况就更明显。其次,Freedman&Calfee的作文评分信息加工模型[24]说明,评分人在阅读文本时建构了文本的心理意象并储存在工作记忆中,而文本质量的评判就是对文本的心理意象评分。每个评分人对同一文本产生不同的心理意象,故而给出不同的评分理由。再次,该现象也间接说明评分人采用了某些与CET-4作文评分标准不相关,但与语言能力相关的评分理由(比如语言的多样性),这在某种程度上能够有效区分考生。因此,修改评分标准时应考虑对这些特征作出明确界定。
四、结论
本研究以26位CET-4作文评分人为研究对象,系统分析了他们对评分标准的理解和使用情况,主要发现有:(1)虽然评分人之间存在严厉度的差异,但是26位评分人之间的一致性比较好,且大部分评分人的自身一致性也较好。(2)部分评分人的评分理由反应了内在评分标准单一化的问题。(3)全部评分理由中有71.91%体现了CET-4作文评分标准所规定的5个文本特征,说明大部分评分人对标准的理解和把握还是比较准确的。对于上述不一致问题,还需要通过进一步加强评分人培训(尤其是对分数意义的培训)和不断完善评分标准(如增加评分标准描述语、充实对不同评分档位的定义)来解决。未来的研究可以继续深入讨论如何将评分人按照评分理由分成不同决策类型,以及如何处理评分标准不相关的评分理由。
[1]Hamp-Lyons L.Scoring procedures for ESL contexts[C]//Hamp-Lyons L.Assessing Second Language Writing in Academic Contexts.Norwood,New Jersey:Ablex Publishing Corporation,1991:241-276.
[2]Charney D.The validity of using holistic scoring to evaluate writing:A critical review[J].Research in the Teaching of English,1984(1):65-81.
[3]Elbow P.Ranking,evaluating,and liking:Scoring out three forms of judgment[J].College English,1993(2):187-206.
[4]Weigle S C.Assessing Writing[M].Cambridge:Cambridge University Press,2002.
[5]DeRemer M.Writing assessment:Raters’elaboration of the rating task[J].Assessing Writing,1998(1):7-29.
[6]邹申,杨任明.他们如何使用写作评分标准?——TEM4新老评分员调查[J].国外外语教学,2002(3):1-6.
[7]徐鹰.不同性别评分人差异的实证研究[J].外语测试与教学,2013(3):16-24.
[8]杨惠中,Weir C.大学英语四、六级考试效度研究[M].上海:上海外语教育出版社,1998.
[9]Shi L.Native and nonnative-speaking EFL teachers’evaluation of Chinese students’English writing[J].Language Testing,2001(3).
[10]Weigle S C.Using FACETS to model rater training effects[J].Language Testing,1998(2):263-287.
[11]Kondo-Brown K.A FACETSanalysis of rater bias in measuring Japanese second language writing performance[J].Language Testing,2002(1):3-31.
[12] Knoch U.Diagnostic Writing Assessment:The Development and Validation of a Rating Scale[M].Berlin:Peter Lang,2009.
[13]Linacre J M.A User’s Guide to FACETS:Rasch-model Computer Program[M].Chicago:Chicago MESA Press,2005.
[14]Knoch U.Investigating the effectiveness of individualized feedback to rating behavior——A longitudinal study[J].Language Testing,2011(2):179-200.
[15]McNamara T.Measuring Second Language Performance[M].Harlow,Essex:Pearson Education,1996.
[16]李清华,孔文.TEM-4写作新分项式评分标准的多层面Rasch模型分析[J].外语电化教学,2010(1):19-25.
[17]Myford C M,Wolfe E W.Detecting and measuring rater effects using Many-faceted Rasch measurement:Part II[J].Journal of Applied Measurement,2004(2).
[18]Connor-Linton J.Looking behind the curtain:What do L2 composition ratings really mean? [J].TESOL Quarterly,1995(4):762-765.
[19]Rezaei A R,Lovorn M.Reliability and validity of rubrics for assessment through writing[J].Assessing Writing,2010(1):18-39.
[20]张洁.评分过程与评分员信念——评分员差异的内在因素研究[D].广州:广东外语外贸大学,2009.
[21]Pula J J,Huot B A.A model of background influences on holistic raters[C]//Williamson M M,Huot B A.Validating Holistic Scoring for Writing Assessment:Theoretical and Empirical Foundations.Cresskill,NJ:Hampton Press,1993:237-265.
[22]Knoch U.Diagnostic assessment of writing:A comparison of two rating scales[J].Language Testing,2009(2):275-304.
[23]Lumley T.Assessment criteria in a large-scale writing test:What do they really mean to the raters? [J].Language Testing,2002(3):246-276.
[24]Freedman S W,Calfee R C.Holistic assessment of writing:Experimental design and cognitive theory[C]//Mosenthal P,Tamor L,Walmsley S A.Research on Writing:Principles and Methods.New York:Longman,1983:75-98.
An Empirical Study on the Raters’Use of CET-4 Essay Rating Scale
XU Ying
(School of Foreign Languages,South China University of Technology,Guangzhou 510641,China)
This paper studies how raters used CET-4 essay rating scale following a mixed-methods approach.Twenty-six CET-4 accredited raters were invited to score thirty CET-4 mock essays and then to write and rank three reasons for their ratings.It was found that,although raters were different as regards severity,the inter-rater reliability was high and nearly all raters were internally consistent.Besides,some raters reduced the rating scale to certain criterion.Finally,71.91%coded rating reasons could be grouped under the five text features delineated by CET-4 essay rating scale,which indicated that most raters’understanding and utilization of the rating scale were accurate.
CET-4 essay rating scale;mixed-methods approach;reasons for ratings
H319.3 < class="emphasis_bold">文献标识码:A文章编号:
2095-2074(2014)02-0039-08
2013-12-27
课题项目:2013年广东省高等教育教学改革项目(51)
徐鹰(1979-),男,江西南昌人,华南理工大学外国语学院讲师,广东外语外贸大学文科基地语言测试专业2011级博士研究生。
