基于粗糙集与贝叶斯决策的不良网页过滤研究
2012-10-15周学广
孙 艳,周学广
(海军工程大学 电子工程学院,湖北 武汉430033)
1 引言
随着网络的普及,人们每天接触的信息与日俱增,信息的迅速膨胀产生了“信息过载”和“信息迷航”,同时也加大了网络不良信息(包括垃圾信息、反动信息、虚假信息、恶意信息等)的传播,带来了各种信息安全问题和社会问题,因此不良信息过滤问题日益被人们重视。
1982年,Denning在计算机协会通信(CACM)上首次提出信息过滤的概念[1]。1987年,Malone等人在CACM上提出了两种信息过滤行为方式:认知过滤和社会过滤[2]。认知过滤即基于内容的过滤[2]。Nanas将信息过滤分为基于内容的过滤和协同过滤[3]。基于内容的过滤是解决当前网络不良信息泛滥问题的主流技术。从内容上看,不良信息过滤问题可以看作是一个“两类”分类问题。因此,各种分类算法可以应用于不良信息过滤中,如贝叶斯算法[4]、支 持 向 量 机[5]、粗 糙 集 理 论[6]、决 策 树 算法[7]等。Pang等人曾用贝叶斯方法、最大熵法和支持向量机法对电影评论做分类效果评比,发现支持向量机的分类效果最好[8]。虽然SVM的分类效果优于其他分类方法,但是其计算开销大的缺点促使研究人员寻找更加完美的分类器。
贝叶斯算法是以贝叶斯定理为理论基础的一种在已知先验概率与条件概率情况下得到后验概率的文本分类算法。贝叶斯分类算法原理简单,健壮性强。粗糙集理论能够获得分类所需的最小特征属性集,在不影响分类精度的条件下降低特征向量的维数,得到最简的显式表达的分类规则。采用贝叶斯和粗糙集理论相结合的方法进行不良网页过滤,可以优化分类系统的总体性能。
在本文中,我们利用粗糙集中区分矩阵和逻辑运算对网页特性现象进行知识约简,剔除判断网页类别的冗余属性,对约简后的网页特征现象进行网页类别的初步分类,建立网页类别决策初表,然后进行网页分类,通过网页归类,建立网页类别决策复表,最后通过贝叶斯决策过程来判别网页类别以及决定是否过滤。
2 粗糙集理论
粗糙集理论是一种新的处理模糊和不确定性知识的数学工具。其主要思想就是在保持分类能力不变的前提下,通过知识约简,导出问题的决策或者分类的规则。知识约简是粗糙集理论的核心内容之一。众所周知,知识库中知识(属性)并不是同等重要的,甚至其中某些知识是冗余的。所谓知识约简就是在保持知识库分类能力不变的条件下,删除其中不相关或不重要的知识,并得到知识的最小表达。本文提出利用区分矩阵和区分函数[9]来表达知识,它能够很容易地计算约简和核。
设K=(U,P,AT,V,ρ)为一概率知识表示系统,即U是论域,P是U的子集全体构成的σ代数上的概率测度,AT={a1,a2,…,an}是有限个属性构成的集合,V=V1×V2×…×Vn,Vi是属性ai的值域,ρ:U→V是信息函数,对于U 中的每个对象x,ρ(x)称为x的描述,具有相同描述的对象是不可分辨的,记与x具有相同描述的对象全体为[x]。设Ω={ω1,ω2,…,ωs}是具有有限个特征状态的集合,每个具有状态ωi的对象是U的子集,常称为概念,A={r1,r2,…,rm}是 m 由个可能决策行为构建的集合,P(ωj|[x])表示一个对象在描述[x]下处于状态ωj的概率,一般假定P(ωj|[x])为已知的。令λ(ri|ωj)表示状态ωj时采用决策ri的风险损失。
3 粗糙集与贝叶斯决策的网页过滤方法
本文提出一种采用粗糙集与贝叶斯决策相结合的不良网页过滤方法,在相应的网页特征现象对应的各个网页类别下,利用粗糙集中区分矩阵和逻辑运算对网页特性现象进行知识约简,剔除判断网页类别的冗余属性,对约简后的网页特征现象进行网页类别的初步分类,建立网页类别决策初表,然后进行网页分类,通过网页归类,建立网页类别决策复表,最后通过贝叶斯决策过程来确定页面类别以及是否进行过滤。
粗糙集对网页特征现象信息的约简方法如下:设决策表系统为S=(U,A,V,f),S为知识表达系统,它对应网页分类决策系统;A=P∪D是属性集合,子集P={a[j]|i=1,…,k}和D={d}分别称为条件属性集和决策属性集,在网页分类中分别对应网页特征现象集和网页类型集;U={x1,x2,…,xn}为论域,对应网页分类中的被分类的单个网页对象集;a[i](xj)是被分类页面xj在特征现象a[i]上的取值。区分矩阵C(i,j)表示区分矩阵中第i行和第j列交点处的元素,则区分矩阵CD定义为:

其中{m[k]|m[k]∈P∧m[k](xi)≠m[k](xj)}。利用区分矩阵进行属性约简的算法如下:
贝叶斯决策过程在不良网页过滤中简述如下:假定一个对象的描述为[x],对于这个对象实施了决策ri,由于P(ωj|[x])是在给定描述[x]下的处于ωj的概率,因此对象在给定描述[x]下采用决策ri的期望损失(常称为风险条件)可由全概率公式得到:

对于给定描述[x],记τ(x)为一个决策规则,即τ(x)∈A,则τ是描述空间到A 的一个函数。令R是在给定一个总体决策规则下的期望总体风险。由于R(τ(x)|[x])是在描述[x]下决策τ(x)的条件风险率,因此总体风险其中的和是对整个知识表示系统而言。显然,如果决策规则τ(x)使得对每个[x]而言条件风险率R(τ(x)|[x])尽可能的小,那么总体风险就能达到最小值。对于每个对象x∈U,计算由式(2)给出的风险R(τ(x)|[x]),i=1,2,…,m,如果有两个或两个以上的决策使条件风险达到最小则根据实际情况取其中之一。设U是一系列不良的网页,设ω是某种不良类型的信息(如暴力、色情等),则ω把U 分成两部分,含某种类型的不良网页(记为ω)和不含此类型的网页(记为~ω),记pos(ω)和neg(ω)为ω的正域(存在不良信息需要进行过滤的网页)和负域(存在不良信息不需要过滤的网页)。
每一个网页x在网页特征现象[x]下面临两种可能的决策:
(Y)决策r1:x∈pos(ω),即r1=[x]→pos(ω);
(N)决策r2:x∈neg(ω),即r2=[x]→neg(ω)。
这时,A={r1,r2}。令λ={ri|ω}为含不良信息的网页实际为不良页面(对象实际属于ω)而采取决策ri时的风险,λ={ri|~ω}为含不良信息的网页实际不为不良页面而采取决策ri时的风险,p(ω|[x])为网页在页面特征现象[x]下有故障的概率,p(~ω|[x])为网页在页面特征现象[x]下没有故障的概率。这样,网页在页面特征现象[x]下采取决策ri的条件风险R(ri|[x])可由全概率公式得:
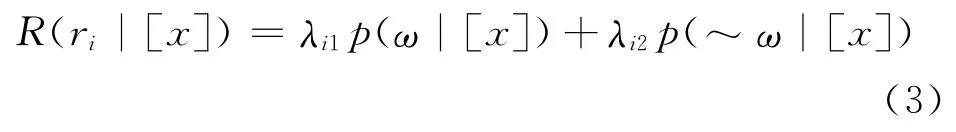
其中λi1=λ(ri|ω),λi2=λ(ri|~ω),i=1,2。
由贝叶斯决策过程可得最小风险规则为:
(Y)r1:[x]→pos(ω),若
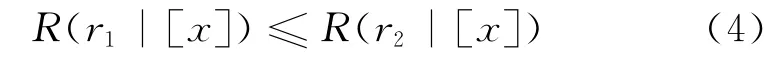
(N)r2:[x]→neg(ω),若
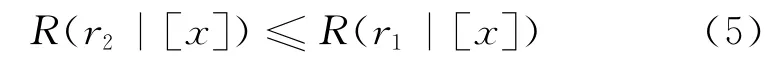
由于在实际情况中,对于存在不良信息的但还不能确定为哪类不良页面的网页来说,进行网页过滤的风险比不进行页面过滤处理的风险要小;而对于没有不良信息的网页来说,进行过滤的风险比不进行过滤的风险要大,即满足关系式:

将式(6)代入式(4)和式(5),并利用,p(ω|[x])+p(~ω|[x])=1经计算可得最小风险决策规则重新表达为:
(Y)r1:[x]→pos(ω),若p(ω|[x])≥α,
(N)r2:[x]→neg(ω),若p(ω|[x])≤α,
其中

显然,由式(6)可知0<α<1。这样最终得到了概念ω关于α的近似(全体实际被过滤网页)为:

即当页面特征现象表现为[x]的情况下,实际为某种不良网页ω的概率大于和等于α的那些网页肯定被过滤。
4 算法设计
4.1 风险系数
由于对网页中不良页面的确定并不一定通过存在不良信息的阈值百分之百的确定,所以算法在通过粗糙集确定不良类型页面后,根据贝叶斯准则,给予每种不良类型评定一个风险系数,用于进一步进行过滤决策,这样可以提高网页过滤的正确率和避免误过滤而带来的计算机开销。
由第3节可知λ11<λ21,且λ12>λ22。对于网页过滤来说,λ11=λ22=0表明不良网页被正确过滤的风险为0。但是网页被误判时风险明显提高,假设风险函数根据过滤网页重要度成指数增长。网页内容越重要,错误过滤后的风险越大。把非不良页面当作不良网页过滤的风险设为λ12=eβ,其中β为页面重要度,页面重要度分为Ⅰ、Ⅱ、Ⅲ、Ⅳ四个等级,其中Ⅰ为重要度小的网页(一般指普通的新闻、娱乐等网页),Ⅱ为重要度中等的网页(一般指企业、公司、学校等网页),Ⅲ为重要度较高的网页(一般指涉及商业秘密、网络交易等网页),Ⅳ为重要度很高的网页(一般指涉及国家机密、军事机密等网页)。重要度系数如表1所示。

表1 网页重要度系数表
其中重要度系数在0≤β≤1,网页为不良或存在不良信息时未被过滤而导致的风险为λ21=eγ,其中γ为网页的危害度。根据网页的信息内容,把页面危害程度也分为Ⅰ、Ⅱ、Ⅲ、Ⅳ四个等级,危害程度为Ⅰ<Ⅱ<Ⅲ<Ⅳ。网页危害度系数如表2所示。

表2 网页危害度系数表
由式(7)得到风险系数为

4.2 过滤算法
本文通过计算机和人工相结合地方式来提取网页的特征信息,由于考虑到某些特征现象(如流媒体中裸露镜头的比例)机器很难进行阈值判断,是通过人工判断来提取特征信息。例如,文本关键词的阈值以及文本夹杂恶意字符等是采用TFIDF的方法进行获取特征现象。在获取特征现象后,进行网页分类,根据粗糙集理论去除冗余的判别信息,只保留必要的特征信息;然后根据网页的重要性和危害性进行贝叶斯决策,从而达到利用最小的过滤代价来过滤最有危害性的不良网页的目的。具体步骤如下:
Step1收集网页特征信息,根据网页特征信息进行类别的初步分类,建立网页类别样本决策初表;
Step2根据粗糙集理论对网页类别样本决策初表建立相应的区分矩阵CD,用式(1)对其进行属性约简,选择最优的属性组合,简化网页类别样本决策初表,形成网页类别决策复表;
Step3对于网页特征信息不在类别决策复表中的根据收集的历史特征信息以一定的先验概率确定为某种类别的网页;
Step4对于网页实时分类用网页类别决策复表进行决策,确定网页为某种不良类别的后验概率为P(ω|[x]);
Step5由贝叶斯准则,根据公式(9),确定过滤网页的风险系数
Step6当网页为某种不良类别的后验概率为P(ω|[x])≥α时,确定为不良类别并进行过滤,当P(ω|[x])≤α时,定为非不良页面并不予过滤,最后给出决策结果。
诊断算法流程图如图1所示。

图1 诊断算法流程图
5 算例与仿真结果
5.1 算法实例
假定在客户端对网页进行过滤,由算法的Step1,建立表3和表4的网页特征现象和网页类别与相应特征现象表。得到表5的网页类别样本决策初表。由算法Step2,建立区分矩阵CD,如式(10)所示,用粗糙集理论对CD进行属性约简,得到表6的网页类别决策复表,由算法Step3,得到网页类别不确定表,如表7所示。由算法Step4~Step6,确定风险系数,由于考虑实际网页为普通的不良页面,根据表1和表2,风险系数中参数β定为Ⅰ级,γ定位Ⅲ级。所以0.425 6=42.56%,风险系数概率超过α=42.56%的都可以进行网页过滤,这样可以最大程度的保护网页的安全过滤。


表3 网页特征现象与属性值
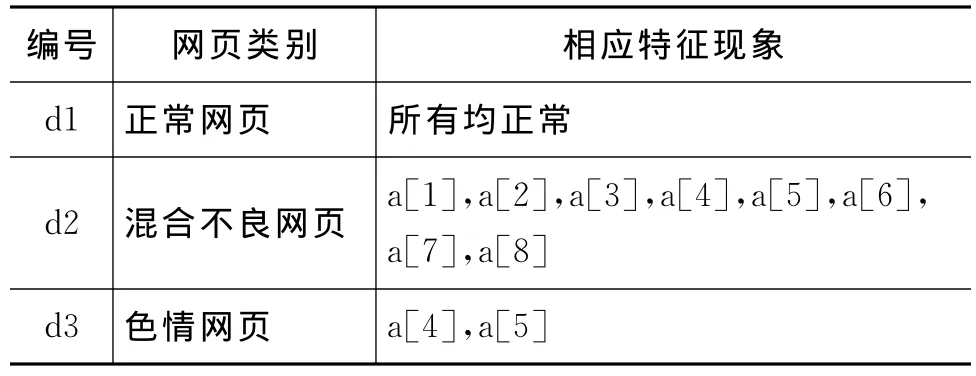
表4 网页类别及相应特征现象

续表
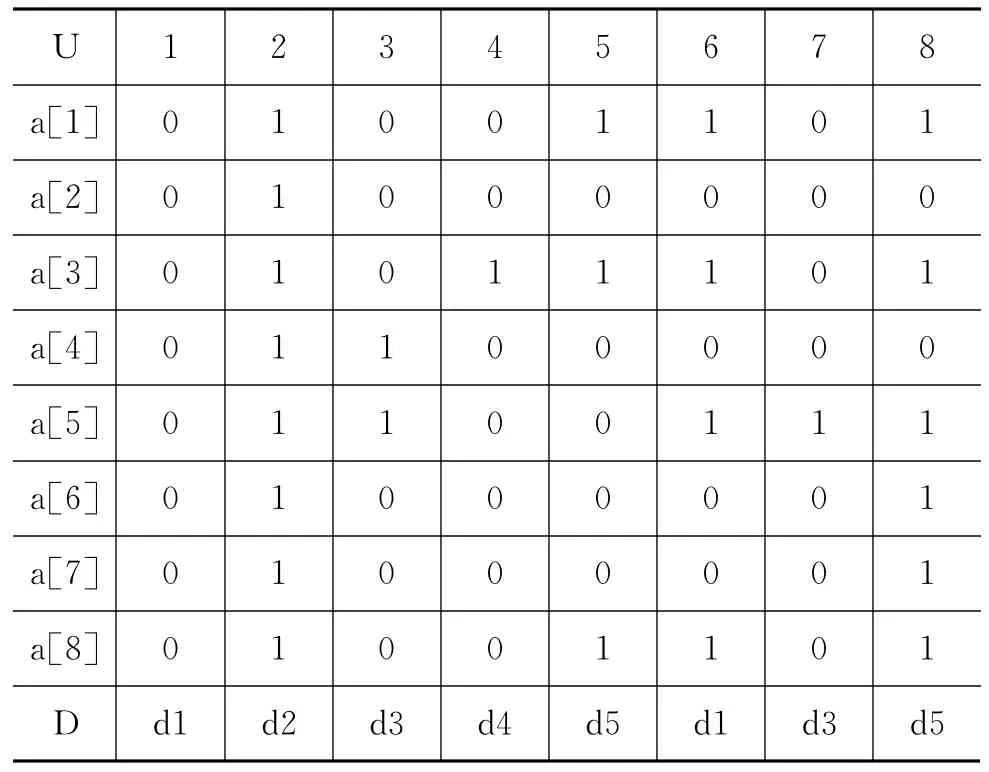
表5 网页类别样本决策初表
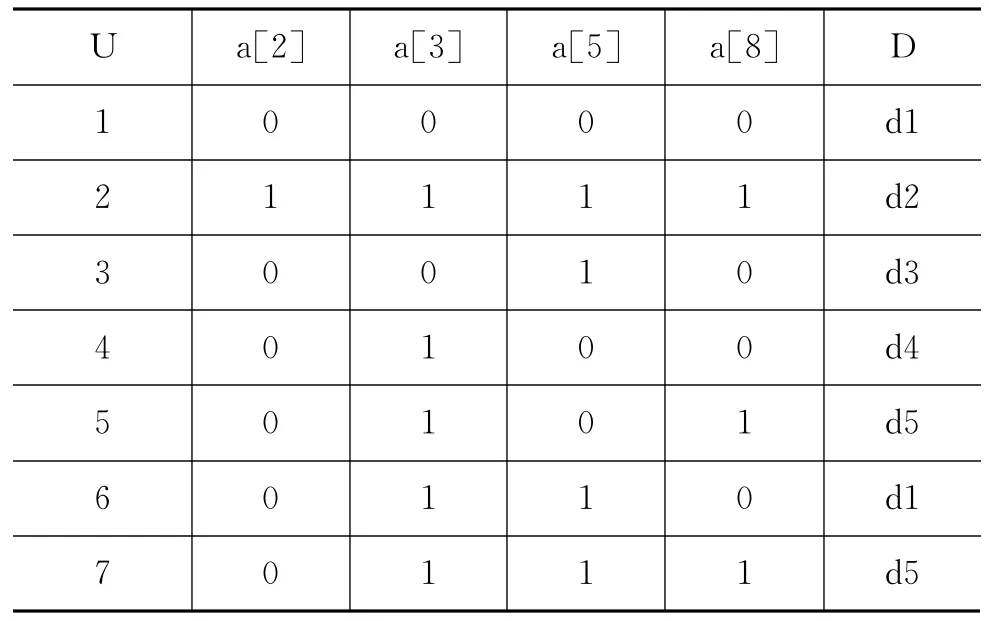
表6 网页类别决策复表

表7 网页类别不确定表
表中D表示网页类别的可能性,其分类概率为样本训练后得到的先验概率。
5.2 仿真结果
对此算法实例进行仿真,对仿真的417组不良网页特征现象反馈数据进行网页分类,假设考虑环境人为影响和外界干扰,每组数据的可靠性为98.5%,网页分类情况如图2和表8所示。

图2 不良网页分类结果图

表8 网页分类结果表
图中d1表示正常页面,d2表示混合不良页面,d3表示色情页面,d4表示封建迷信页面,d5表示宗教反动页面。
从仿真结果来看,利用本算法进行对不良网页分类过滤效果明显,并且能进一步提高过滤正确率,在对传统单用决策表进行不良网页分类过滤时,过滤正确率为88.6%(数据可靠性为98.5%)。与传统单用决策表的方法相比,本论文采用的算法平均分类正确率为93.2%,过滤正确率92.2%,与传统的算法相比有明显提高。这是因为网页分类过程实际上是一个搜索匹配过程。由于网页的数据庞大,这使得传统的搜索匹配过程冗余而效率低下。在本文所用的粗糙集理论对属性进行约简后再次进行匹配可以大大降低系统的冗余度,提高搜索匹配效率,也避免了大量冗余无用信息造成的误过滤。而且对于模糊类别采用贝叶斯决策可以使得过滤风险性降为最小并得到最佳分类过滤。
6 结论
本文提出的基于粗糙集理论和贝叶斯决策的网页过滤算法能够快速准确的解决不良网页的分类和过滤决策。尤其在大量冗余信息和部分信息缺失的情况下,更能有效准确的进行网页分类与过滤,提高了分类的效率和准确率。并且本算法融入了贝叶斯决策理论,根据网页重要度和危害度来定义风险函数,从而最小化了过滤页面的风险性,达到不良页面分类过滤的最优化。
由于不良网页获取的困难性,本文只做了几百组网页的过滤实验,如果考虑到海量网页的过滤,需要进一步对网页的特征提取方法进行优化,尤其是对于网页中流媒体、视频、图片识别的快速判断方法;另外还需要建立特征现象字典库,并且进行动态更新和添加以适应不断变化的互联网信息。
[1]Denning P J.Electronic junk[J].Communications of the ACM,1992,25(3):163-165.
[2]Malone T,Grant K,Trubak F,et al.Intelligent information sharing system [J].Communication of the ACM,1987,5:390-402.
[3]Nanas N,Roeck A D,Vavalis M.What happened to content-based information filtering?[J].ICTIR 2009,LNCS 5766,2009:249-256.
[4]张宇,刘挺,文勖.基于改进贝叶斯模型的问题分类[J].中文信息学报,2005,19(2):100-105.
[5]Lee W,Lee S S,Chung S,et al.An harmful contents classification using the harmful word filtering and SVM[C]//ICCS 2007,Part III,LNCS 4489:18-27.
[6]卢娇丽,郑家恒.基于粗糙集的文本分类方法研究[J].中文信息学报,2005,19(2):66-70.
[7]Malo P,Siitari P,Ahlgren O,et al.Semantic content filtering with wikipedia and ontologies [C ]//Proceedings of 2010IEEE International conference on data mining workshops,2010:518-526.
[8]Pang B.Lee L,Vaithyanathan S.Thumbs up?Sentiment classification using machine learning techniques[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing,2002:79-86.
[9]张文修,吴伟志,等.粗糙集理论与方法[M].科学出版社,2001.
