基于情感分布的微博热点事件发现
2012-10-15林鸿飞
杨 亮,林 原,林鸿飞
(大连理工大学 计算机科学与技术学院,辽宁 大连116024)
1 引言
随着Web2.0的发展,人的参与性不断提高,网络的使用方式发生了改变,人们不再是被动的从网络获取知识,而是通过网络主动地表达自己的观点或对其他人或事件的态度,微博通过简短的140字更新信息,并实现多工具即时分享,使其成为互联网上一种新的重要媒体。微博的出现,使信息在微博中呈现出碎片化、即时化和移动化的特性,而不再是具有完整的上下文信息,通过微博自由、便捷、即时地抒发自己的情感,已成为互联网上的时尚,同时也使得其成为热点事件产生和谈论的重要场所,其中热点事件指某一时间内被广泛关注、争论、议论的事件、话题或者信息,因此对微博平台中热点事件的发现、监控及管理等方面的研究工作也就越发显得重要了。
目前国内微博的研究正处于起步阶段,不少研究问题在该领域中亟待解决。现今,热点事件的发现、监控及管理正成为微博宏大信息流中的重要研究领域,当某一热点事件在微博平台中出现时,人们通过微博来表达自身对该热点事件的观点或态度,用户群体的情感分布发生变化,从微博内容方面表现为情感词出现的几率上升,这种现象为本文的研究工作提供了重要的依据。近年来,基于语言模型的地理信息检索[1],也在逐步引起许多研究人士的注意,本文依据情感词分布情况构建语言模型,对平台中用户群体情感变化进行了分析,首次提出了情感分布语言模型(Emotion Distribution Language Model,以下简称ELM),用于微博平台中发现热点事件。
根据文献[2],当热点事件出现时微博中情感词数量增多。具体表现为微博用户群体的情感波动,因此当相邻时段的情感分布存在差异时,往往伴有热点事件的出现。本文利用以上结论,通过分析相邻时段情感分布语言模型ELM间的差异,实现对热点事件的发现。
本文的组织结构如下:第1节介绍论文的研究背景和意义;第2节介绍一些相关工作;第3节介绍情感词汇本体构建技术和情感分布语言模型ELM;第4节是实验流程的介绍及实验结果分析;最后,在第5节中对研究工作进行总结,同时提出了下一步的研究方向。
2 相关工作
2.1 微博领域的研究及趋势
目前国外研究方面,H.Kwak等[3]对 Twitter是一种社会网络还是新媒体进行了分析。J.Weng等[4]提出了一种TwitterRank思想,在有影响力的Twitter发布者中寻找敏感话题。A.D.Sarma[5]对类似Twitter的论坛在其排序机制方面进行了研究。现今国外对微博的研究重点在Ranking方面,从时空角度对微博平台中谈论的事件发现、跟踪和还原正成为微博研究的又一个聚焦点。国内的研究主要有沈阳等[6-7]对微博的宏大信息流及其蕴含的情感进行分析。
2.1 话题跟踪检测
话题跟踪检测[8]的技术被广泛运用到热点事件发现中,话题跟踪检测与信息检索、文本挖掘、信息抽取等交叉学科相比更侧重对新信息的发现,其关注某一特定话题而不是广泛的各类主题信息[9]。
在传统的话题跟踪检测中,主要从事实中检测和追踪事件,多是依据不同的事件做聚类,很少将情感分析用于话题跟踪检测中;而微博中的信息多呈现出碎片化、即时性、移动性等特性,且微博内容大多为用户对自身情感的抒发,微博中情感词所占比重相比于传统文本信息要大,故传统的话题跟踪检测技术不适用于在微博中发现热点事件。
时达明、林鸿飞[10]提出了一种基于评论与话题相关度的方法,通过对评论内容进行情感分析来发现Blog中的热点话题。L.Ku等[11]提出了一种方法用于反映大众观点在某时刻的变化。该方法通过获取观点信息反映社会群体在总统选举过程中对各候选人的情感变化。Cuneyt Gurcan Akcora等[2]提出了一种通过Emotion Centroid(EC)及Set Space Model(SSM)的方法来发现Twitter中的舆情。以上研究从不同领域对事件或舆情进行发现,为本文结合微博特点提出情感分布语言模型ELM从微博平台中发现热点事件做出了重要贡献。
2.3 情感分析
目前情感分析在许多领域被广泛的应用,企业可以从网络上的信息获取用户建议和反馈意见,网络信息安全和垃圾过滤也已得到了国内外的广泛关注。目前文本倾向性的主要工作是基于人工标注语料库,利用相关机器学习算法,分析词语、句子、篇章的倾向性[11]。由于微博简短的特点,每条微博类似文章中的句子,故句子级的情感倾向性分析为本文研究提供了一定的基础。Pang[13-14]等利用人工标注训练语料,采用贝叶斯、最大熵等方法分析电影评论倾向性。Liu[15]等从用户评价中挖掘用户的观点。这些都为本文对微博的情感波动分析提供了重要依据。
3 关键技术
本文主要是通过分析微博平台中微博所含的情感词,对微博中的文本信息进行研究。主要工作分为以下三步:
第一步:识别微博中情感词,并构建情感词汇本体库。微博中情感词的发现是建立情感分布语言模型的基础,对于微博中的情感词,通常分为两类,一类是通常情况下的情感词,如喜欢、心疼等,另一类为在微博等网络平台中被用于情感词的词语,如稀饭(喜欢)、走召弓虽(超强)、果酱(过奖)等。本文通过大连理工大学情感词汇本体(以下简称DUTIR情感词汇本体)结合网络平台中常用的情感词实现对微博中情感词汇的获取。
第二步:情感分布语言模型的提出及建立。当热点事件出现时,情感出现波动是微博用户的直接反映,在微博中表现为情感词增多,造成情感词的分布发生变化。本文从情感词的分布角度出发,将每个时段全部微博对应为语言模型中的文章d,每条微博对应为文章d中的一个句子s,通过微博中情感词的概率分布变化反映情感波动。通过对各个时段建立情感分布语言模型ELM,对比相邻时段间ELM的差异来发现热点事件。
第三步:对Cuneyt Gurcan Akcora等[2]提出的Emotion Centroid(EC)、Set Space Model(SSM)等方法进行重现,实现在微博平台中发现热点事件。
3.1 情感词汇本体构建技术
本文使用的外部资源由大连理工大学信息检索实验室情感词汇本体[16]结合网络平台中常用的网络情感词汇,如稀饭(喜欢)、辣鸡(垃圾)等构成,以下简称为DUTIR情感本体库,该情感本体库将情感分为6大类。
对于通用情感词的获取,本文首先采用通过计算词汇w与DUTIR情感词汇本体中的标准词汇的互信息方法进行获取,计算公式如下:

其中Sui表示第u类情感的第i个词,P(w)表示词w出现的概率,P(Sui)表示第u类第i个情感词出现的概率,P(w,Sui)表示词w与第u类情感的第i个标准词一起出现的概率。
然后结合情感词汇的规律,如词性规律、否定词与程度副词搭配规律、共现规律、上下文规律等,通过机器学习的方法进行自动获取,再将两步结果结合,实现DUTIR情感词汇本体的扩充。本文考虑到微博短文本的特性,应尽量利用其上下文信息并避免标记偏见,故采用条件随机域(Conditional Random Field,简称CRF)的方法进行自动获取[17]。
对于网络平台(主要包括天涯论坛、新浪博客等网络平台)中常用情感词汇的获取,本文通过网络爬虫从网络下载并整理第二届中文倾向性分析评测(COAE2009)任务语料得到18G网络文本资源,经分词及去停用词处理等预处理得到总词表。首先利用DUTIR情感词汇本体去除总词表中通用情感词,DUTIR情感词汇本体格式如下:
情感词汇本体通过一个三元组来描述:
Lexicon=(B,R,E)
其中B:表示词汇的基本信息,主要包括编号、词条、对应英文、词性、录入者和版本信息。R代表词汇之间的同义关系,即表示该词汇与哪些词汇有同义的关系。E代表词汇的情感信息,包括情感类别、情感强度、情感极性,是情感词汇描述框架中比较重要的一部分。
再利用大连理工大学情感常识库[18](以下简称情感常识库),对余下词语中含常识、隐喻等情感信息的部分进行抽取并结合部分网络常用情感词汇,最终得到DUTIR情感本体库,情感常识库的格式如下:
(“emotion”“subject”“passive,attention”“conditions”)
emotion表示该条常识的情感,通常用大连理工大学情感词汇本体定义的20个小类的情感代码[16]表示或者赋值为“-1、1”,其中“1”表示积极情感类,“-1”表示消极情感类。subject表示情感持有者。passive表示被动标志,取值包括“0、1”,其中“0”表示主动,“1”表示被动。attention表示常识部分,包括常识词汇或短语。conditions表示条件说明,包括时间、方位等条件。
DUTIR情感本体库基本知识主要来源于现有的一些词典、语义网络和常用网络用语。其中词典包括《现代汉语分类词典》、《汉语褒贬义词语用法词典》、《汉语形容词用法词典》、《中华成语大词典》、《汉语熟语词典》、《新世纪汉语新词词典》。语义知识网络有知网和WordNet。另外还加入了《汉语情感系统中情感划分的研究》中的部分词汇及大量网络常用语中的网络常用情感词。因此,DUTIR情感本体库不仅适用于微博的情感分析,而且还可用类似微博的网络平台,如Blog、论坛等的情感分析,有较强的适用范围。
目前,DUTIR情感本体库收录情感词汇共17 243个,为本文研究微博平台中情感波动(即情感词数量变化)提供了词汇基础和分析的依据。
3.2 情感分布语言模型
统计语言模型[19]产生于基于统计方法的自然语言处理系统研究中,统计语言模型就是表示语言的基本单位(词、词组、句子等)的分布函数,它描述了该语言基于统计的生成规则。在语言模型中,文档在文档集中的排列通常取决于其与查询的相关度,对于给定文档D和查询Q,我们通过计算查询Q中词在文档D中的概率来实现文档排序:

其中V为文档集词集合,qw为词w 在查询Q中出现的次数。
相对熵(亦称KL距离)是评价语言模型性能的一项直观指标,相对熵的差异表示所学习的模型与真实模型间的差异,当两个模型一致时,相对熵值为0,相对熵值差异越大表明,两个模型间的差异越大,在测试集(即实验语料)上的相对熵函数公式为:
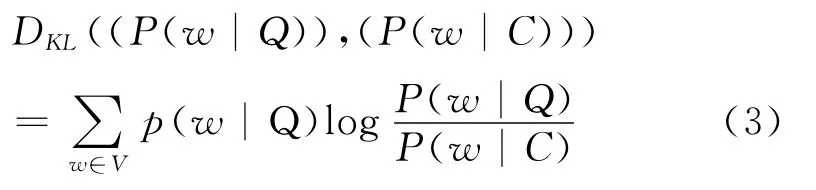
其中P(w|Q)为词出现在查询Q中的概率,P(w|C)为词w在整个文档集中出现的概率。
在信息检索中,根据“Bag of Words”的思想,对于文本集D中的每一个词都是独立的,不依赖于其他词是否出现,并且满足某种分布,因此情感词汇在微博平台中也应满足某种分布。根据语言模型的思想,结合微博碎片性的特点,本文对测试集(实验语料)中的微博做如下映射:每日收集的全部微博映射为语言模型中的文章d,故全部语料为文档集D;每条微博映射为语言模型中的句子S,故微博中的每个词即可视为语言模型中的词w。通过某时段微博中情感词概率变化可反映该时段微博集合d的情感波动。基于以上思想,本文提出情感分布语言模型的方法,通过比较相邻时段情感分布语言模型差异的方法来发现热点事件。我们可以定义Tn时段的情感分布语言模型如下:
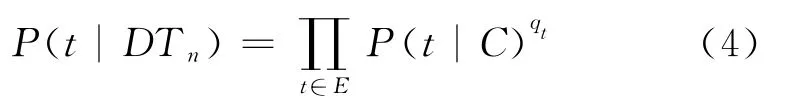
其中E为DUTIR情感本体库,DTn为Tn时段的全部微博,P(t|C)为情感词t在整个文档集中出现的概率,qt为情感词t在Tn时段中出现的次数。
考虑到微博简短的特性,在一定程度上会造成情感词的稀疏,故需要对实验语料进行平滑处理。本文选用的平滑方法为Dirichlet平滑,其平滑公式如下:

其中Pμ(w|d)为词w 平滑后的概率,c(w;d)为词在文档d中出现的次数,p(w|C)为词w在整个文档集C中的概率。
相对熵是统计语言模型的一个重要的评价指标,因此我们通过计算相邻时段Tn和Tn-1情感分布语言模型的相对熵来度量两个模型间的差异,相对熵的差值越大,表明相邻时段间情感分布语言模型的差异越大,这为发现潜在的热点事件时段提供了重要的依据。具体的计算公式如下:
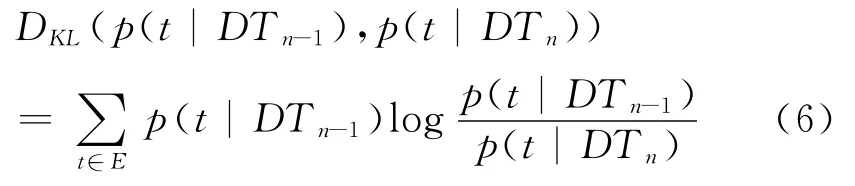
其中E为DUTIR情感本体库,w为E中的一个情感词,DTn为Tn时间间隔内的微博客博文集合,P(t|DTn)情感词w出现在Tn时刻的微博客博文中的概率。
根据文献[2]的观察结论,当一个热点事件出现时,该时段所发的微博含有情感词数量增多,由于下时段该事件热度降低,但仍可能被谈论,故所用词可能会存在部分重复,因此对于Tn时段若其DKL满足如下条件时,则认为该时段为潜在热点事件发生时段。具体判断条件如下:

对实验语料采用Dirichlet方法平滑,μ取值分别为50,100,500,1 000,2 000进行实验,当取值为2 000时,实验结果较好,故μ取值为2 000。随后计算实验语料中各个相邻时段间的相对熵,并结合判别条件(7)、(8),对所有潜在热点事件发生时段进行检验,从而发现该时段的热点事件。
3.3 Emotion Centroid(EC)and Set Space Model(SSM)
3.3.1 Emotion Centroid(EC)
对于每一条微博客博文,利用DUTIR情感本体库,将情感分为六大类,E=(喜,怒,哀,惧,恶,惊),每一类情感代表空间模型中的一维,我们在每一条微博客博文中查找情感词,如果存在则该维为1,否则为0。
对于每个固定时间间隔T的所有微博客博文,计算并获得所有相应情感向量的EC[2],将EC看作是此时间段微博客博文的情感反映,包含N条微博,V=(v1,v2,…,vn)表示该时段所有情感向量集合,则T时间间隔的EC定义为:
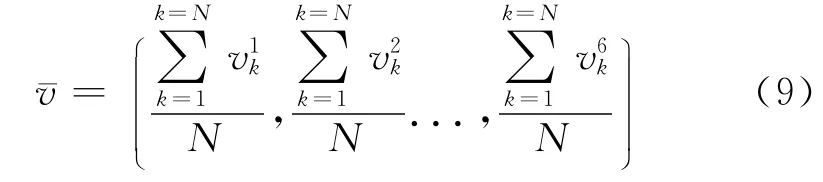
其中Vk为K 时段的Emotion Centroid,N为该时间间隔内所含的微博数量。
T1、T2两个相邻间隔EC相关度为二者的cosine相似度,此相关度越小,表明相邻时段间内的用户所发的微博博文话题差异越大,则热点事件出现的几率越大。
3.3.2 Set Space Model(SSM)
在潜在热点事件时段,SSM方法如下,实验语料经过预处理和去除停用词,收集各个时间间隔的所有词,再通过T1和T2的Jaccard相似性来定义相邻时间间隔的相关度,计算公式为:
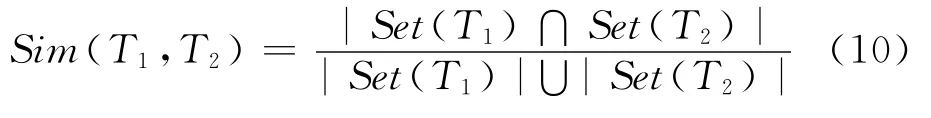
当热点事件出现时,所发微博与前一时段微博的Jaccard相似性降低,由于该话题可能仍被讨论,则下一阶段Jaccard相似性提高,则该时段应为一个潜在的热点事件发生时段,将符合条件的时间段记录并统计。
4 实验结果与分析
4.1 语料来源、相关实验及实验流程
4.1.1 语料来源
本文的实验语料来自新浪微博广场(http://t.sina.com.cn/pub/),从微博广场中进行语料收集是为了能更好地反映多个不同的微博用户可能同时在谈论或热议一个或几个话题。语料时间为2010年6月7日至2010年6月13日,每日8点到22点,每小时手工下载500条新浪微博,共52 500条微博,并统一格式保存,一条微博的存储及定义格式如下:

其中<name>表示微博用户名,<text>表示微博客内容,<rt>表示其他用户对该条微博的回复,<time>表示所发微博的时间信息。
经预处理及人工事件标注,发现该语料所在时间内共发生热点事件23例。具体事件分布见表1。
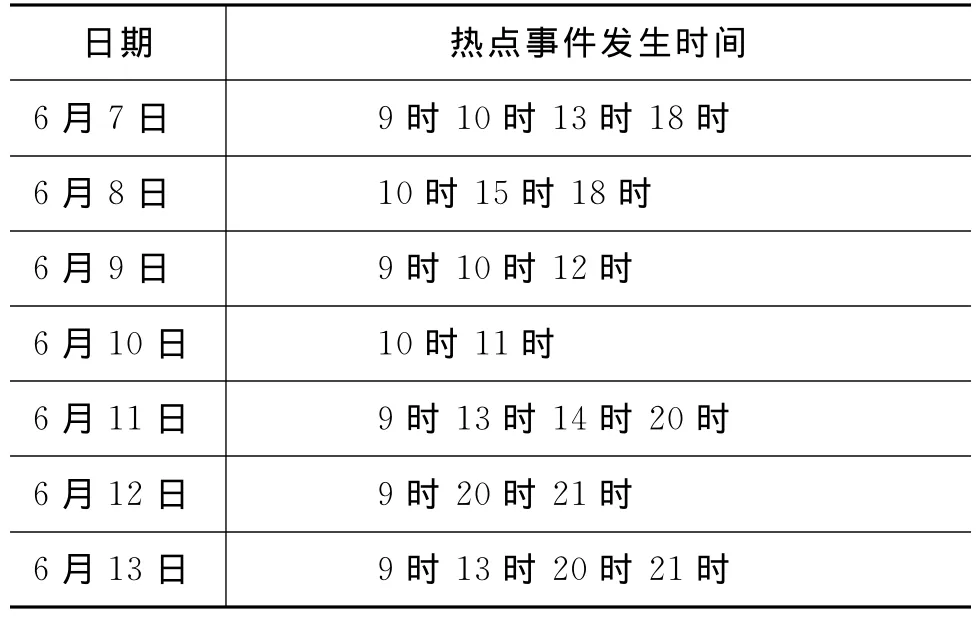
表1 热点事件分布表
4.1.2 实验流程
本文实验流程如下:
(1)从网络获取实验语料,通过人工标注发现并统计热点事件。
(2)将网络常用情感词汇与DUTIR情感词汇本体结合得到DUTIR情感词汇本体库.
(3)微博客博文的预处理。
(4)通过计算相邻时段情感分布语言模型间的差异发现热点事件,统计每日发现的热点事件数。
(5)构建各时段的EC和SSM,分别进行实验,计算相邻时段Cosine相似度差异和Jaccard相似度差异,发现并统计热点事件。
(6)进行对比实验,并分析结果的正确率和召回率。
4.2 对比实验及实验结果分析
Cuneyt Gurcan Akcora等[2]研究发现,微博客用户群在热点事件出现时会产生情感波动,主要表现为以下两点:热点事件时段所发微博客博文的情感词数量上升,使得微博平台内的情感词分布发生变化;当某一热点事件出现时,微博客用户群体的微博所采用的词的形式会不同于之前阶段,如果在下个时段该话题仍在被讨论,则相同的词模式会重复出现。若时间间隔长度小于1小时,则微博数量较少,不足以反映热点事件;而当时间间隔大于1小时时,则可能多个热点事件在同一时间段内发生,不利于多个热点事件的发现。因此,本文提出情感分布语言模型方法在相同实验语料并选取相同时间间隔(本文选取时间间隔为1小时)的基础上与Cuneyt Gurcan Akcora等人在Twitter平台中发现热点事件的方法进行比较。在实验中,为了实现与Cuneyt Gurcan Akcora方法情感空间一致,本文将情感空间维数统一定义为六维(即主要考虑DUTIR情感本体库的六大类情感)。表1中的时间表示发生热点事件的时段。
本文选取一周的实验语料中热点事件,对其进行发现。实验中,采取相同实验语料,选取一小时为时间间隔进行实验,发现并统计每种方法每日发现热点事件数量,首先采用Cuneyt Gurcan Akcora的EC方法,然后采用Cuneyt Gurcan Akcora的SSM方法,将之前两种方法结合为EC&SSM,最后采用情感分布语言模型ELM方法。通过四种方法进行实验,统计结果并对不同方法的实验结果进行对比。从实验结果看,ELM的实验结果在准确率和F1值方面为四种方法中最高的,实验结果也表明本文方法的有效性。具体实验结果数据见表2,在表2中出现的数字:括号外的数字为方法发现的正确热点事件数,括号中为方法发现的错误热点事件数,准确率、召回率、F1值等具体数值对比见图1。

表2 事件发现数表
由表2和图1可知,四种方法均能有效地从实验语料中发现热点事件,Emotion Centroid(EC)方法在获得最高召回率的同时准确率却最低,问题在于对于不同的热点事件,当相邻时段含有较少情感词时,EC可能被错误改变,因此当Cosine相似度阈值设置较低时,在发现正确结果的同时错误率也相应提高了。
而相比于EC,在Set Space Model(SSM)方法中,不少热点事件的发生并未对应明显的全局词汇变化,而只是引起情感词的变化,而SSM方法只能对前者进行识别,在一定程度上影响了SSM方法的结果,因此其的召回率较低。
EC&SSM方法(即在EC方法召回的结果集上进行SSM方法)综合考虑了EC方法和SSM方法的优缺点后,首先进行Cosine相似度分析发现潜在的热点事件,在通过分析Jaccard相似度进行验证,在保证一定召回率的基础上,使准确率得到一定的提高,表明EC&SSM方法可有效地用于热点事件发现,且相比于EC、SSM两种单独方法准确率和F1值都有明显提高。

图1 实验结果数值图
情感分布语言模型ELM相比于Cuneyt Gurcan Akcora提出的EC方法,尽管损失了一定的召回率,但在准确率和F1值上都有大幅度的提高,可见ELM方法比EC方法更能准确地从微博平台中发现热点事件;对于Cuneyt Gurcan Akcora提出的SSM方法,ELM方法在各项指标都有较大提高,尽管热点事件出现可用微博中词集合的变化来反映,但ELM方法表现的更准确且全面;而在同Cuneyt Gurcan Akcora提出的EC&SSM综合方法对比之后发现,ELM同样在各项指标上都有所提高,且在四种方法中有最高的准确率和F1值。

图2 6月13日相邻两时段情感词的相对熵
结果表明在微博平台中热点事件出现时,ELM方法通过情感词的概率分布变化结合语言模型相比于Cuneyt Gurcan Akcora提出的前三种方法能更好更准确地反映微博用户群体的情感波动,而用户的情感变化方面又是发现热点事件的重要依据,因此在相比于EC&SSM方法召回率提高的同时,又使准确率有了一定的提高。例如:6月13日相邻两时段情感词相对熵值见图2(其中如8&9表示8时和9时的情感词相对熵值)。根据图2中数据并结合判断条件(7)、(8),可知9时、13时、20时三个时段满足判断条件(7)、(8),且其都是当日热点事件发生的时段,可见本文提出的ELM方法实现了对当日微博平台中热点事件的发现。
分析原因可知,ELM方法中引入的语言模型与语言客观事实之间的关系是取得预期实验结果的关键,客观语言经过语言模型的描述更适合自然语言处理,而在语言模型基础上的情感分布语言模型也就近似地反映了实验语料的客观事实,即近似地反映了实验语料中的情感波动,因此在热点事件的发现过程中ELM方法的各项指标相对于EC&SSM方法都有了一定的提高。当然ELM方法中也存在着一定不足,ELM隐含着情感词间的相互独立关系,没有考虑情感词相互间的影响,且当情感词所占比重较低时,即微博多为记叙类微博时,也会在一定程度上影响ELM的结果,以上所述都需要本文在未来做进一步的分析和处理。
5 结束语
本文通过对微博特点进行分析,发现当热点事件出现时,微博用户情感产生波动,所发微博中情感词的数量增多,在此基础上,提出了情感分布语言模型ELM,用于对微博平台中的热点事件发现。实验中与Cuneyt Gurcan Akcora提出的三种方法进行对比,实验表明本文提出的方法可有效地从微博平台中发现热点事件,有助于对微博中热点事件的管理和监控。
Web2.0时代,人的参与性不断提高,微博平台已成为舆情产生和传播的重要场所。简短、即时的微博,让用户快速实时地表达自己的观点和对其他人或事进行评论,对热点事件发现是将事件由时空等不同角度还原的前提,这也是未来的研究目标之一。当然目前对于微博方面研究的语料还很有限,语料的扩充及规范化也是亟待解决的工作之一;同时DUTIR情感本体库和情感常识库也都需进一步完善;情感词之间的相互影响也应做进一步的分析,以上所述都有待通过未来详尽研究工作来完成。
[1]黎志升,王煦法.基于Language Model的地理信息检索模型[J].中国科学技术大学学报,2010,40(2):203-209.
[2]C Akcora,M Bayir,M Demirbas,H Ferhaosmanoglu.Identifying Breakpoints in Public Opinion[C]//Proceedings of KDD Workshop on Social Media Analytics.Washington,July 2010.
[3]H.Kwak,C.Lee,H.Park,and S.B.Moon.What is twitter,a social network or a news media?[C]//Proceedings of WWW,Raleigh North Carolina,USA,2010,591-600.
[4]J.Weng,E.P.Lim,J.Jiang,Q.He.TwitterRank:Finding Topic sensitive Influential Twitterers[C]//Proceedings of WSDM.New York,USA,February 2010.
[5]A.D.Sarma.Ranking Mechanisms in Twitter-like Forums[C]//Proceedings of WSDM.New York,USA,February 2010.
[6]沈阳,田晨耕,李舒晨,刘世超.闲言碎语中的宏大信息流:微博客研究[C]//第六届全国搜索引擎和网上信息挖掘学术研讨会,大连,2009.
[7]Yang Shen,Shuchen Li,Xiaodong Ren,Xiaolong Cheng.Emotion Mining Research on Micro-blog[C]//Proceedings of 1st IEEE Symposium on Web Society.Lan Zhou,China,2009.
[8]Allen J,Larenko V,Connell M E.A month to Topic Detection and Tracking in Hindi.ACM Transactions on Asian Language Processing[J],2003,2(2):85-100.
[9]李保利,俞士汶.计算机识别与跟踪研究[J].计算机应用,2003,39(17):7-10.
[10]时达明.Blog热点话题发现及其作者声誉度研究[D],大连:大连理工大学,2007.
[11]L Ku,Y Liang,and H Chen.Opinion extraction,summarization and tracking in news and blog corpora[C]//Proceedings of AAAI-2006Spring Symposium on Computational Approaches to Analyzing Weblogs.California,USA.2006,100-107.
[12]刘康,赵军.基于层叠CRFs模型的句子褒贬度分析研究[J].中文信息学报,2008,22(1):123-128.
[13]Pang B,Lee L,Vaithyanathan S.Thumbs up?sentiment classification using machine learning techniques[C]//Proceedings of EMNLP'2002,University of Pennsylvania Philadelphia,USA,2002,79-86.
[14]Pang B,Lee L.A Sentimental education:sentiment analysis using subjective summarization based on minimum cuts[C]//Proceedings of the 42ndAnnual Meeting on Association for computational Lingusitics,Barcelona Spain.2004,271-278.
[15]M Hu,B Liu.Mining and summarizing customer reviews[C]//Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery &Data Mining,Seattle,Washington,USA.2007.
[16]徐琳宏,林鸿飞,潘宇,等.情感词汇本体的构造[J].情报学报,2008,27(2):180-185.
[17]陈建美,林鸿飞,杨志豪.基于语法的情感词汇自动获取[J].智能系统学报,2009,4(2):100-106.
[18]陈建美,林鸿飞.中文情感常识知识库的构建[J].情报学报,2009,28(4):492-498.
[19]邢永康,马少平.统计语言模型综述[J].计算机科学,2003,30(9):22-26.
