基于事件抽取的网络新闻多文档自动摘要
2012-10-15韩永峰许旭阳李弼程朱武斌
韩永峰,许旭阳,李弼程,朱武斌,陈 刚
(解放军信息工程大学 信息工程学院,河南 郑州450002)
1 引言
在当今计算机和互联网蓬勃发展的时代,大量的文本信息被快速地传送与分享到全球各地,信息过载(Information Overload)问题也随之产生。如何从大量无序、杂乱、无结构的文本中高效获取有用信息已成为一个亟待解决的问题。在众多的信息处理方法中,多文档自动摘要被视为一项不可或缺的关键技术,它是利用计算机将同一主题下的多个文本描述的主要内容通过信息压缩技术提炼为一个文本的自然语言处理技术[1],在军事和民用方面都具有极其重要的实用意义。
目前,自动摘要方法主要分为两大类:一是基于统计的机械摘要;二是基于意义的理解摘要。基于统计的机械摘要源于Luhn[2]的思想,主要是利用各种统计信息如位置信息、频率统计等找出最能代表文章主题的句子作为摘要句。这种方法虽然容易实现,但对于包含多个事件的文档集进行摘要时,不仅常常漏掉次重要的事件,而且对文档内容的覆盖度较低,往往形成大量的冗余。
基于意义理解的摘要是从语言学角度理解文档集合,进而生成文档集合的自动摘要结果[3],它需要对文章进行句法分析和语义分析。此方法生成的摘要质量较高,但需要庞大的专家知识库和完善的语言学规则,且受限于领域,性价比较低。
为了克服这些缺点,近年来一些自动摘要方法基于文本片段(例如,段落、句子或事件等)聚类划分文档主题,并在此基础上生成摘要。这种方法理论上冗余性更少,信息覆盖率更大,是目前比较流行的一种研究方法。
Jiang Changjin等[4]通过识别组合词和段落聚类实现中文自动摘要。首先根据词或短语的频率、词性、位置和长度计算它们的权重,在此基础上计算句子的权值;然后将相邻的段落依据相似度聚到相同类或不同类中;最后根据类中句子的权值选择摘要句组成摘要。
Zhang Peiying等[5]提出了一种基于句子聚类和抽取的自动摘要方法。首先对文本中的句子依据语义距离进行聚类;然后用基于多特征融合的方法计算类中每个句子的权重;最后通过一定规则抽取句子组成摘要。
Naomi Daniel[6]首次提出将新闻话题划分为一系列子事件并应用在多文档摘要中,引起了人们对基于事件多文档摘要研究的兴趣。刘茂福等[7]提出一种基于事件项语义图聚类的多文档摘要方法,将文档中的动词和动名词看成事件项,然后对事件项进行聚类,最后通过抽取包含代表事件项的句子生成摘要。然而,多文档摘要以段落为单元的研究已没有更多的余地,因为以段落为单元会包含许多冗余信息;实际上句子作为摘要的最小单位也不是最理想的,因为文本中有些句子和主题无关,且有时在一个句子中还会包含冗余信息,有时单个句子表达的意思也不够完整,需要多个句子才能表达清楚;其实文献[7]中的方法也存在一定的问题,例如,事件项只能部分标识事件的发生,更有甚者是包含事件项的句子不一定都是事件。另外,文档中很多词语会出现兼类情况,例如,“袭击”可以是动词,也可以是名词。
针对以上问题,本文将事件抽取技术与自动摘要技术相结合,提出一种基于事件抽取的多文档自动摘要方法。首先,改变以段落和句子作为摘要基本单元,尝试以“事件”为知识粒度去表示、处理文本,且本文所考虑的“事件”包含的特征更加丰富,不仅仅是文档中包含动词和动名词的句子;然后,对抽取出的事件采用两层聚类得到不同的事件集合;最后,通过对事件集合中主旨事件的抽取、排序以及润色,生成摘要。实验结果表明,该方法生成的摘要进一步减小了冗余,更加简洁,是一种有效的多文档摘要方法。
2 网络新闻文档事件抽取
2.1 网络新闻文档特点
互联网上新闻内容丰富、形态多样,据中国互联网络信息中心(China Internet Network Information Center,CNNIC)2010年7月15日发布的《第26次中国互联网络发展状况统计报告》[8]显示:网络新闻使用率为78.5%,占网络信息极大的比重,且几乎所有人每天都在关注新闻信息。尽管内容多种多样,出版社、发布源也不尽相同,但这一体裁的文档却有着一些共性。
(1)冗余性。由于新闻具有很强的时效性,因此同一时间关于同一主题的不同报道会陈述某些相同的信息,这些报道之间有很大的重复性,甚至包含完全相同的句子或段落。
(2)层次性。某些重大的新闻,通常会有多家媒体对其进行多天的跟踪报道。随着时间的推移,观点和事实会不断更新,导致出现“重心”漂移,即一个新闻主题中出现了不同的事件集。例如,2010年3月29日“莫斯科地铁爆炸”这一主题新闻就出现了包括:现场、救援、伤亡、调查、善后以及各方反应等不同的事件集合,如图1所示。
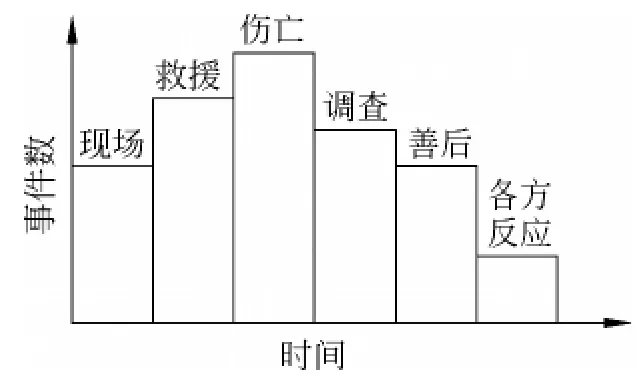
图1 事件动态变化图
2.2 概念层次关系及事件定义
1.概念层次关系
著名语言学家许嘉璐认为目前中文信息处理技术中统计概率的路已走到了尽头,必须另辟语义“蹊径”[9]。而汉语是以“字义基元化,词义组合化”方式构造新词,因此可以构建概念层次关系,如图2所示。

图2 概念层次关系示意图
本文结合新闻文档特点,直接从事件层描述文档内容,建立语言模型,不再以段落、句子或词语对文档进行物理上的划分,而是以“事件”为单位进行内容逻辑的划分。这种方法从理论上来说,更接近人的认知过程,符合人们正常的认知规律,实验结果表明:以“事件”进行建模是合理有效的。
2.事件定义
“事件”(Event)起源于认知心理学,认知科学家认为,人类主要是以“事件”为单位进行记忆和理解现实世界。但是目前对“事件”还没有统一的定义,不同领域对“事件”的理解不同。
在ACE评测会议中,“事件”[10]被描述为一个动作的发生或状态的变化。
美国佛罗里达州大学的Zwaan[11]将每个单句等同为一个“事件”。
本文研究的“事件”也属于句子级,但不是每个句子都是事件,只有当一个句子含有事件特征时才构成事件,否则为非事件。
2.3 事件抽取算法
事件抽取(Event Extraction)隶属于信息抽取领域,主要研究如何把含有事件信息的非结构化或半结构化文本以结构化的形式呈现出来[12]。目前,事件抽取的相关研究主要分为两大类:模式匹配方法和机器学习方法。
模式匹配方法[13-14]尽管知识表示直观、便于推理,但过于依赖具体领域,可移植性差,性价比不高。因此,基于机器学习的事件抽取方法[15-16]成为研究的主流,根据抽取模型中所采用的不同驱动源,主要分为三类:事件元素驱动、事件触发词驱动和事件实例驱动。然而,前两种方法所面临的最大问题就是正反例不平衡和数据稀疏,影响了抽取的性能。为此,本文提出了一种基于事件实例聚类的事件抽取方法,主要思想是:首先,以单句作为事件的基本抽取单位,通过二元分类器辨析出事件句和非事件句;然后,通过对事件句聚类,得到同一主题文档集中所包含的不同事件集合,完成事件抽取。
1.事件实例的识别
统计表明,新闻文本中包含大量非事件实例,降低了事件抽取的准确率,因此,需要尽可能地过滤掉非事件实例。
首先对新闻文本进行预处理;然后将每个句子作为一个候选事件,抽取出刻画一个事件的有代表性的特征构成候选事件实例表示;最后通过二元分类器对事件实例与非事件实例进行自动识别。具体步骤如下。
(1)预处理。主要包括中文分词、词性标注、句子切分等,完成对自然语言文本的初步处理;
(2)特征提取。在步骤(1)的基础上,主要选取了以下几个事件特征:句子长度、位置、词语个数、命名实体个数、时间个数、数值个数、停用词频率、以及相应的词语等。完成特征提取后利用向量空间模型(Vector Space Model,VSM)对所有候选的事件进行向量表示;
(3)事件识别。事件实例识别的实质是分类问题,由于支持向量机[17](Support Vector Machine,SVM)分类器通用性好、分类精度高、分类速度快、且分类速度与训练样本个数无关。因此,本文选用SVM分类器对候选事件进行分类,过滤非事件。
2.聚类算法
目前,聚类算法的研究相对比较成熟,传统的聚类算法大体可分为两大类[18]:层次聚类算法和非层次聚类算法。
层次聚类算法(如CURE等)应用较广泛,优点是不需要预先设定聚类最后的目标类别数,通过停止阈值就可以确定聚类是否结束。但层次聚类也存在明显的缺点,在层次聚类中一个点一旦被归为某类就不能再改变,不能进行迭代修正,但在聚类的过程中有许多情况需要通过不断的迭代使聚类中心逐渐清晰,层次聚类不能满足这个要求,在一些情况下会导致错误的分类。
非层次聚类算法如k-中心(CLARA等)聚类可以满足不断调整聚类结果的要求。但是非层次聚类算法需要预先设定目标类别k的值,而文本的主题数与内容有关,无法预先设定,且初始质心的选取也是随机的,但是k值和初始质心对聚类结果会产生很大的影响。
为解决单一聚类算法存在的不足,本文提出了基于层次聚类的k-中心聚类方法,具体步骤如下。
(1)完成事件识别后,对所有事件进行层次聚类,直到任意两个事件集合之间的相似度都小于停止阈值,层次聚类结束。聚类的结果为k个类C1,C1,…,Ck;
(2)步骤(1)完成后,得到的聚类总数作为k-中心聚类算法中的k值,从每个Ci(1≤i≤k)中任意选取一个事件作为k-中心聚类的k个初始中心点,将余下的事件按照最相近的原则分到k个类中去,然后重新选取类的中心点,循环进行,当各类别中的事件不再移动时,聚类结束。
3.基于事件实例聚类的事件抽取
基于事件实例聚类的事件抽取方法,一方面通过事件实例驱动构建抽取模型解决了以触发词驱动所带来的正反例失衡和数据稀疏问题,另一方面通过引入聚类的思想突破了传统方法对事件类别限制的局限性,有效提高了事件抽取的性能。本文事件抽取的流程如图3所示。

图3 新闻文档事件抽取流程图
基于事件实例聚类的事件抽取具体步骤如下。
(1)事件实例识别。通过基于SVM的事件实例的识别辨析出新闻文本中的事件实例和非事件实例,并过滤非事件实例;
(2)两层聚类。经过步骤(1)后获得了文本集中的所有的事件实例,然后对所有的事件实例采用基于层次聚类的k-中心聚类算法,最终得到k个类C′1,C′2,…,C′k,其中C′1(1≤i≤k),代表了新闻文档集中同一主题下的不同的事件集合,其中的事件具有相似的语义。
3 基于事件抽取的摘要生成
事件抽取完成后,得到同一主题下不同事件的集合,每个集合都是对主题某一侧面的集中描述。若想生成最终的摘要还需要解决四个问题:首先,事件集合中主旨事件的抽取;其次,主旨事件的排序;再次,摘要的平滑修饰;最后,摘要标题的确定。基于事件抽取的摘要流程如图4所示。
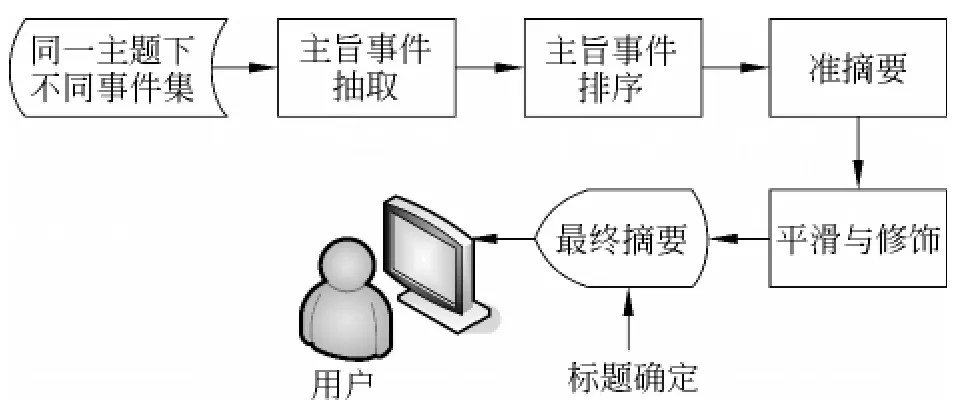
图4 基于事件抽取的摘要流程
3.1 主旨事件抽取
类C′1(1≤i≤k)中的每个事件都是相关或相似的,要生成最终的摘要,首先需要挑选出每个类中的主旨事件来概括该类的中心思想,然后才能对主旨事件排序,最终生成摘要。类中事件之间的关系可以抽象出来如图5所示。
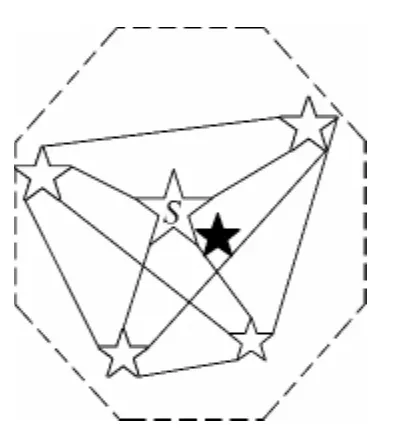
图5 类内事件关系示意图
从抽象的几何关系来看,类内事件之间的距离可看作事件之间边的长度。图5所示的类中有5个事件,10条边,显然,最接近中心的事件所对应的边的总长度最短。从图5也可以看出,事件S最靠近类的中心,应该作为这个类的主旨事件抽取出来。因此,本文认为最靠近类中心的事件就是主旨事件,抽取算法如下。
输入:同一主题下的不同事件集合
输出:事件集中的主旨事件
(1)类内事件相似度计算。设类内任意两个事件sI和sJ,sI中包含的词语为sI1,sI2,…,sIm,sJ中包含的词语为sJ1,sJ2,…,sJn,利用刘群[19]提出的利用《知网》[20]计算词汇语义相似度的方法计算词语sIi(1≤i≤m)和sJj(1≤j≤n)之间的语义相似度s(sIi,sJj),则事件sI和sJ之间的相似度Sim(sI,sJ)为:

其中,ai=max(s(sIi,sJ1),s(sIi,sJ2),…,s(sIi,sJn)),bj=max(s(sJj,sI1),s(sJj,sI2),…,s(sJj,sIm))。
(2)在步骤(1)的基础上,通过公式:

计算类C′i中事件之间的距离;
(3)利用公式计算类内每个事件和类内其余事件之间的总距离,总距离最小的事件就是类内的主旨事件。类的主旨事件计算公式为:

其中,N为类C′i中的事件数。这样就从每个类中
抽取主旨事件作为摘要句,完成主旨事件抽取。
3.2 主旨事件排序
主旨事件排序是生成摘要的重要环节。如果顺序不当,会降低摘要本身的质量和可靠性。本文认为主旨事件排序不能简单的依靠重要度进行排序,应按照事件的发展过程进行排序,这样才能使用户更加清楚地了解事件的来龙去脉。因此,提出了一种基于时间的主旨事件排序方法。具体流程如下。
(1)对于可以直接比较时间的主旨事件按照时间先后排序;
(2)对于无法比较时间,但属于同一文档的主旨事件按照其先后顺序排序;
(3)对于无法比较时间,且属于不同文档的两个主旨事件,则根据它们所在文档中的报道时间先后排序。
时间的比较算法描述如下(精确到时):
以“2010年03月29日23:18”为例,假设时间信息提取与规范化已在预处理阶段完成。
(1)查找字符“年”,抽取该字符左边部分字符串“2010”,将其转化为整型,用“year”表示。
(2)查找字符“月”,抽取该字符左边部分字符串“03”,将其转化为整型,用“month”表示。
(3)查找字符“日”,抽取该字符左边部分字符串“29”,将其转化为整型,用“day”表示。
(4)查找字符“:”,抽取该字符左边部分字符串“23”,将其转化为整型,用“hour”表示。
(5)令time=year×365×24+month×30×24+day×24+hour。
由算法可以看出,时间越小,事件发生的越早,排序时应靠前;时间越大,事件发生的越晚,排序时应靠后。
3.3 摘要平滑修饰
文章中句子间具有一定上下文关系,而摘要时只是从文章中抽取部分句子,失去了其表达上下文的关系,使得摘要的连贯性难以保证,需要进行一些平滑修饰提高摘要的连贯性和平滑性。
(1)标点符号平滑修饰。一些跨句需匹配的标点符号(如引号等),可能由于切分句子的原因被分离开,在摘要句子中发生失配。在平滑处理时,可以把摘要句中失配的标点符号删除或补上。
(2)删除摘要句中“无用信息”。摘要句集合中常包含一些无用信息,如句首关系词、转折词等。句首关系连词包括“另外”、“因此”等连词,如果出现在摘要句句首,则显得非常突兀,句子表达不连贯,需要删除。
(3)指示代词消解。指示代词的消解可以使摘要的结果更通顺流畅。所谓指示代词包括人称代词(你、我、他)、一般代词(前者、后者)等。
本文采用的方法是,如果一个被抽取的摘要句前面n个词中含有这些代词,则将该句的前一个句子也作为摘要句,依次类推。本文通过实验n取7。
经过以上的后处理步骤,基本达到了摘要润色的目的,增加了可读性。
3.4 标题确定
标题是摘要的重要组成部分,好的标题不仅能在第一时间吸引住人们的目光,而且能够概括文档的主旨,使人们一目了然。本文将多文档集合中核心文档的标题抽取出来作为摘要标题,算法如下。
(1)文本特征提取。对文本进行分词后,由于低频词和停用词所含有的信息量很小,故对已经切分的词语过滤掉这些词后所得的词称为文本的有效词,这些词都在一定程度上反映了原文的特征。假设一篇文本中共有n个有效词,分别为t1,t2,…,tn。通过tf*idf对它们进行权重计算,其权值Wk(1≤k≤n)的计算公式如下:

其中,tfk为tk的绝对词频,N为文档总数,nk为包含tk的文档数。
(2)相似度计算。采用基于向量空间模型(Vector Space Model,VSM)统计的方法计算同一主题下N篇文档集中任意两篇文档di=(Wi1,Wi2,…,Win)和dj=(Wj1,Wj2,…,Wjn)之间的相似度,计算公式如下:

其中,0<i,j≤N,O为向量空间的原点。
(3)对文档集合中的每一篇文档di求其与当前文档集合中所有其他文档之间相似度的和Sum,计算公式如下:

其中,i≠j且0<i,j≤N。
(4)对文档集合中每一篇文档求其相似度之和的平均值average(Sum),并求
其中,average(Sumi)的计算公式如下:
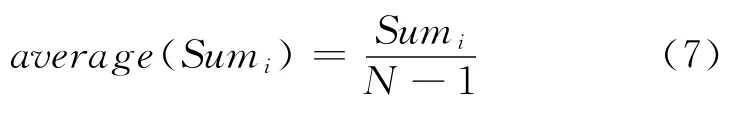
(5)第i*篇文档di*被定义为当前文档集的核心文档,选取该文档的标题作为摘要的标题。
4 系统评价及分析
4.1 实验数据
本文实验数据是从新浪、网易和搜狐等实际网络环境中采集的3个主题相关的3组语料,所属内容均为2010年间国内、国际相关话题的网络新闻报道。通过网页分析去除广告链接等无关内容,只保留标题、报道时间和正文内容,并经去重和规范化处理转化为同一文本格式(*.txt)。
本文所选取的语料具有代表性和区分性,既有时政新闻,又有社会新闻;既有国际新闻,又有国内新闻;既有突发事件,又有热点问题。语料的具体统计信息如表1所示。
4.2 系统评价及性能分析
目前,自动摘要的评价方法大致分为两大类:内部评价(Intrinsic)和外部评价(Extrinsic)。

表1 实验数据统计结果/个
内部评价方法通过直接分析摘要的质量来评价摘要系统,主要采用准确率、召回率等性能指标,方法简单、容易实现,但主观性太强。
外部评价方法是一种间接方法,使用自动摘要系统生成的摘要去完成某个外部的任务,以任务完成的质量来评价摘要的质量,评价方法较为客观,适用于大规模地对多个摘要系统进行综合评价,但需要设计具体的评价任务,很耗时间和人力,且每次评价只针对一个特定的任务,有一定局限性。
可见,两种评价方法都有其优势和劣势,因此,本文分别采用内部评价和外部评价进行讨论。1.内部评价
自动摘要的本质是信息的抽取和压缩,因此本文借鉴信息抽取中的评价指标,主要采用召回率R(Recall)、准确率P(Precision)和流利度Flu(Fluency)三个指标对自动摘要系统进行内部评价。各评价指标如下:
· 摘要召回率反映摘要对原文主题信息的覆盖程度,是对摘要质量的一个重要评价标准。摘要召回率R定义为:
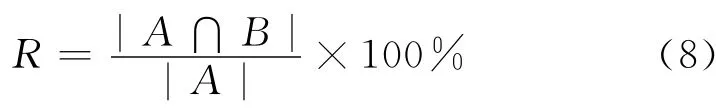
·摘要准确率反映摘要表现原文主题信息的准确程度。摘要准确率P定义为:
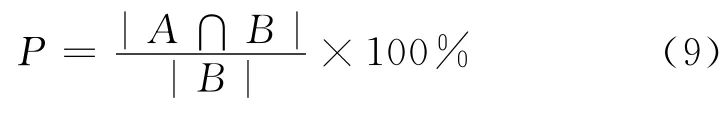
·摘要流利度反映摘要流畅性和可读性。在本文的评测中,通过比较系统摘要与人工摘要相匹配的句子在顺序上是否一致。摘要流利度Flu定义为:

其中,A为人工标准摘要的语句集合,B为系统产生摘要的语句集合,C为系统摘要与人工摘要顺序一致且最长匹配的语句数。
在综合评测系统性能时,为了一目了然,应同时考虑R、P和Flu多个指标,本文利用多指标综合评价方法中的线性加权综合法进行综合评价。所谓线性加权综合法是指应用线性模型来进行综合评价。本文综合评价公式定义为:
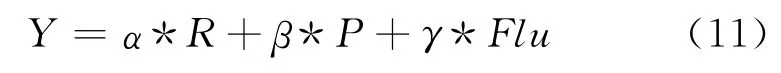
其中,Y为系统的综合评价值,α,β和γ分别为指标的相应权重,且α+β+γ=1。
权重α,β和γ的确定方法有很多种,本文采用较为简单和成熟的专家咨询权重法。按照指标对用户重要程度的大小,主观规定了各指标的权重大小,这里α=0.4,β=0.4,γ=0.2。
此外,为了评价不同摘要方法对不同主题语料的影响,本文引入了指标算术平均值(Arithmetic Mean),公式定义如下:
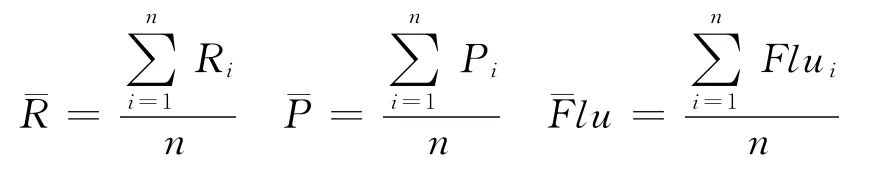
其中,¯R、¯P和¯Flu分别为同一种摘要方法不同语料下的召回率、准确率和流利度的均值,n为同一种摘要方法下主题语料的数目,本文n=3。
(1)实验结果
为了验证本文自动摘要方法的有效性,依据当前比较主流的多文档自动摘要研究方法[4-7],建立了两个自动摘要系统与本文方法进行对比实验。
系统一:首先,将同一主题下的文档集合按照段落为单位进行物理上的划分;然后,计算自然段之间的相似度,高度相似的不同文档段落聚集到不同的类中;最后,从每个段落类中选择代表段落生成摘要。
系统二:首先,将文档集合按照句子为单位进行物理划分;然后,计算句子之间的相似度,高度相似的不同句子聚集到不同的类中;最后,从每个句子类中选择代表句生成摘要。
实验中,先用本文方法对每个实验语料生成一个摘要,然后人工分别对这三个主题做出标准摘要,将本文生成的摘要以及系统一、二生成的摘要分别与人工标准摘要对比,计算上面三个指标的值。
本文硬件实验环境为Intel(R)Core(TM)2 DUO CPU E7400 @ 2.80GHz,2GB 内 存,Microsoft Windows XP Professional(SP3)操作系统,开发工具为Visual C++6.0。实验对比结果如表2所示。

表2 不同主题语料下不同方法实验对比结果/%
由表2可见,相同语料下本文方法生成摘要的综合评价值均高于系统一和系统二的,说明本文方法生成的摘要很好地兼顾了召回率、准确率和流利度;同时,本文方法生成摘要的召回率、准确率和流利度的算术平均值整体上也优于系统一和系统二的,说明本文方法生成的摘要很好地兼顾了不同种类的语料。可见,该方法不仅适用范围广,而且具有一定的鲁棒性,生成的摘要具有较高的质量。
系统一以自然段为摘要单元进行聚类,可以保留句子和句子之间的关联关系,因而流利度较好,但是包含了很多的冗余信息,严重影响了准确率,且摘要的长度过长。因此,多文档摘要中以段落为摘要单元的研究已没有更多的余地。
目前的研究大部分以句子作为基本的摘要单元,句子是一个相对较小的摘要单元,它只是一个词序列,不包含更多词频等统计信息。从表2来看,系统二中以句子作为摘要基本单位也不是最理想的;此外,当考虑所有句子时,不仅带来了很多的“噪声”,且时间复杂度将呈指数级增长。
本文以“事件”作为摘要的基本单元,从总的实验结果来看,所生成摘要的效果达到了预定的实验目标,可以被用户接受。
实验中还发现,所选摘要单元越小,包含的信息越丰富和细腻,但一方面会失去许多关联关系,影响对文本集合中信息的正确判断,另一方面对自然语言生成技术要求很高,很难付诸实用;而摘要单元过大又会带来许多冗余信息,降低聚合的程度。由表2不难看出,本文较好地兼顾了上述两个问题,所选摘要单元的平均长度——“事件”介于句子的和段落的之间,生成的摘要不仅没有失去关联关系,而且进一步减小了冗余,是一种有效的多文档自动摘要方法。
(2)实验分析
分析“莫斯科地铁爆炸”主题中的文章可知,每篇新闻的重点比较明确,有关于爆炸现场、救援情况、伤亡情况、原因调查、采取措施、善后工作以及各方反应等,因此,聚类结果较准确,生成的摘要效果很好。
分析“钱伟长逝世”这个主题中的文章可知,文章中的新闻时间差不多是相同的,但每个新闻文本的内容在时间上跨度很大,包括对钱伟长生平的纪事、钱伟长的贡献、逝世的时间、地点以及各界的追思等的描述,且不同报道从不同侧面对其生平、贡献等进行描述,造成聚类结果不准确,同时严重影响了摘要的流利度。
分析“日本民主党选举”主题中的文章可知,主题中的新闻分为四个阶段——选举前瞻、选举结果、分析评论及政坛影响,每个阶段有6-8篇新闻,但都是围绕选举这个主题来描述的,不同阶段之间的文档有交叠,而且同一个阶段的文档往往从不同的角度进行叙述,中心不是很明确。因此,在对此主题下所有的事件聚类时,结果的准确性不能得到很好的保证,同时也造成信息的召回率偏低;由于根据时间对主旨事件进行排序,从而使得摘要的流利度还比较好。
分析实验中影响自动摘要质量的因素主要有以下两点。
a、聚类数目确定
本文的实验中,没有硬性规定摘要的压缩比,而是根据聚类数目确定摘要的长度。通过实验注意到聚类数目与文本的描述内容有关,如果一个文本内容很广,即使文本句子数不多也具有较多的聚类数目,但这种情况往往出现单个样本的类,影响摘要效果。因此,如何根据文本自身内容自适应确定类别数并完成聚类是今后的努力方向。
b、主旨事件抽取
聚类结束后,每个类成为一个事件集。在每个事件集中,包含的事件都是相似的。它们之间有很多信息可以互补,若只是简单地从这些相似的事件中选出主旨事件作为这类的代表,那么有些信息将会丢失。较好的一种方法是以其中包含信息最多的事件作为主旨事件,将其它相似的事件中合适的信息添加进来,保持信息的丰满,同时也不影响摘要的连贯性,这就涉及到事件句的压缩和合并以及语义处理等深层语言处理技术,也是下一步要研究的主要内容。
2.外部评价
本文采用基于问答任务(Question Answering,Q&A)进行外部评价,通过提供一定数量的源于语料1、2、3的问题集及相应的标准答案,让不同的评测员分别阅读原文、阅读由系统一、二生成的摘要以及本文方法产生的摘要,然后对比其回答问题的平均时间和准确率。不同测试环境下实验对比结果如表3所示。
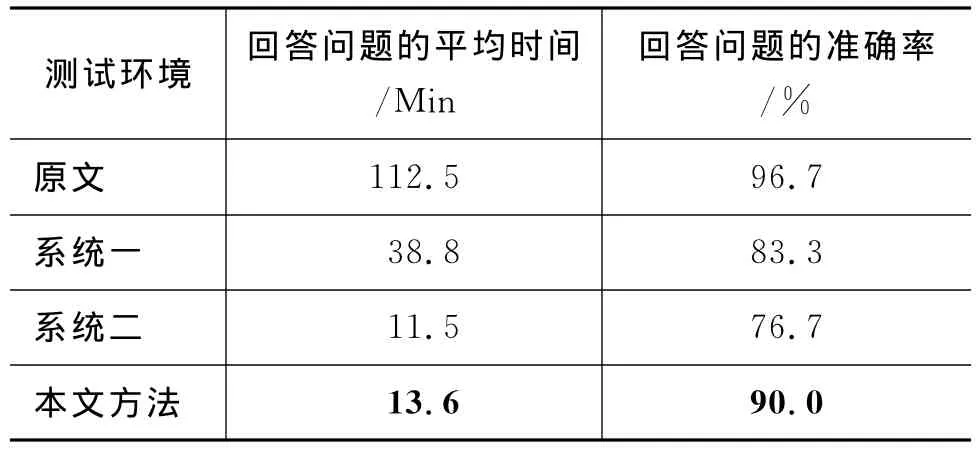
表3 基于Q&A外部评价实验对比结果
由表3可见,阅读原文所用的平均时间最长,回答问题的准确率也最高;阅读系统一产生的摘要准确率有所降低,但所用时间缩短了近三分之二;阅读系统二生成的摘要,虽然所用的平均时间是最短的,但准确率也是最差的。相对而言,对于本文方法产生的摘要能够更加全面地覆盖文章的主题信息,并很好地兼顾回答问题的时间和准确率,从而在回答问题的准确率与阅读原文的准确率相差不大的情况下,大大节省用户的浏览时间,提高了获取信息的速率和效率。
5 总结与展望
目前,信息社会对能够有效浓缩文本信息的自动摘要技术有着迫切的需求,它能对自然语言文本进行深层次知识的挖掘,通过阅读它可以在短时间内了解事件的发生、发展和结束的全过程,以及对人们和社会造成的影响,同时有效地解决了数据的冗余问题,具有重要的现实意义。
针对当前自动摘要方法的不足,提出一种基于事件抽取的多文档自动摘要方法,不仅进一步减小了流行方法中的冗余问题,而且很好地解决了传统方法中由于给定压缩比造成摘要有时由于字数限制表达不够全面的问题,实现了摘要长度随文档内容自动确定。下一步研究的重点将是探索跨句子级事件抽取方法,构建完善的事件知识表示模型并应用于多文档摘要中,从而生成更高质量的新闻摘要。
致谢 作者要向《知网》的发明人董振东先生和董强先生表示感谢,他们的工作是本文的基础。另外,本文在文本预处理中采用了中科院计算所汉语词法分析系统ICTCLAS 3.0,这里一并表示感谢!
[1]秦兵,刘挺,李生.多文档自动文摘综述[J].中文信息学报,2005,19(6):13-20.
[2]Luhn H P.The Automatic Creation of Literature Abstract[J]. IBM Journal of Research and Development,1958,2(2):159-165.
[3]宋锐,林鸿飞.基于文档语义图的中文多文档摘要生成机制[J].中文信息学报,2009,23(3):110-115.
[4]Jiang Changjin,Peng Hong,Ma Qianli,et al.Automatic Summarization for Chinese Text Based on Combined Words Recognition and Paragraph Clustering[C]//Proceedings of 2010 3rd International Symposium on Intelligent Information Technology and Security Informatics(IITSI),2010:591-594.
[5]Zhang Peiying, Li Cunhe. Automatic text summarization based on sentences clustering and extraction[C]//Proceedings of 2nd IEEE International Conference on Computer Science and Information Technology(ICCSIT),2009:167-170.
[6]Naomi Daniel,Dragomir Redav,Timothy Allison.Sub-event based multi-document summarization[C]//Proceedings of HLT-NAACL workshop on text summarization,2003:9-16.
[7]刘茂福,李文捷,姬东鸿.基于事件项语义图聚类的多文档摘要方法[J].中文信息学报,2010,24(5):77-84.
[8]中国互联网络发展状况统计报告[OL].[2010-08-03].http://www.cnnic.net.cn/uploadfiles/pdf/2010/7/15/100708.pdf.
[9]司联合.《概念层次网络理论》(HNC)述评[J].语言科学,2003,2(4):101-108.
[10]ACE (Automatic Content Extraction) Chinese Annotation Guidelines for Events[M].National Institute of Standards and Technology,2005.
[11]Zwaan R A,Radvansky G A.Situation models in language comprehension and memory [J].Psychological Bulletin,1998,123(2):162-185.
[12]赵妍妍,秦兵,车万翔等.中文事件抽取技术研究[J].中文信息学报,2008,22(1):3-8.
[13]梁晗,陈群秀,吴平博.基于事件框架的信息抽取系统[J].中文信息学报,2006,20(2):40-46.
[14]冯礼.基于事件框架的突发事件信息抽取[D].上海:上海交通大学,2008.
[15]David Ahn.The stages of event extraction[C]//Proceedings of the Workshop on Annotations and Reasoning about Time and Events,Sydney,2006:1-8.
[16]许红磊,陈锦秀,周昌乐等.自动识别事件类别的中文事件抽取技术研究[J].心智与计算,2010,4(1):34-44.
[17]Vapnik V.Nature of Statistical Learning Theory[M].New York:Springer Press,2000.
[18]赵世奇,刘挺,李生.一种基于主题的文本聚类方法[J].中文信息学报,2007,21(2):58-62.
[19]刘群,李素建.基于《知网》的词汇语义相似度的计算[J].Computational Linguistics and Chinese Language Processing,2002,7(2):59-76.
[20]董振东,董强.知网[OL].[2010-06-08].http://www.keenage.com.
