基于Tika语义分析的文档标题提取研究*
2012-08-10丁振凡
丁振凡
(华东交通大学信息工程学院,江西 南昌 330013)
随着Internet的迅速发展与普及,如何从海量的网络信息资源中及时、准确地找到所需的信息成为当今的一个研究热点[1].为满足查全和查准的要求,出现了基于语义的内容检索,而文档语义信息的提取是其核心研究内容之一[2].在各类信息资源网站中均含有类型各异的文档资源,如:HTML文档、PDF文档、Word文档、PPT文档等.随着网站信息资源的不断丰富,对站内信息资源进行资源搜索也就很有必要.Lucene是目前最为流行的开源全文检索工具包.Apache Tika是一个开源的文档语义提取工具包,利用Tika可获取文档的元数据并实现文档内容的文本分析.将Tika分析的元信息和内容分析结果加入索引,然后用Lucene在建立好的索引中实现基于元信息的全文检索.如图1所示.

图1 Lucene和Tika结合实现基于元信息的全文搜索流程
1 文档语义提取
各种类型的资源文件的语义信息的提取是一件复杂的工作[3].Tika作为一个优秀的元数据分析和内容分析工具,支持众多格式的文档(例如HTML、PDF、Doc等),在Tika分析的基础上进行再加工,可简化基于元信息的搜索服务的建立.Tika能自动甄别文件类型,调用相应的解析器进行分析.在分析中能识别文档的字符编码、语言及各类属性,还能提取文档的结构化内容.如图2所示.

图2 Tika对文档分析的基本过程
1.1 Tika的文档分析器
Tika能自动甄别文档类型,并根据文件类型调用相应的解析器进行分析.Tika包含不针对任何特定文档格式的通用解析器,图 3 为 Tika解析器的设计结构.org.apache.tika.parser.Parser接口是Tika的关键组件,它隐藏了不同文件格式和解析库的复杂性,为应用程序从各种不同的文档提取结构化的文本内容以及元数据提供了一个简单且功能强大的机制.

图3 Tika分析器的继承层次
其中,AutoDetectParser类将所有的 Tika功能包装进一个能处理任何文档类型的解析器.这个解析器可自动决定文档的类型,然后会调用相应的解析器对文档进行解析.用户也可以使用自己的解析器来扩展Tika.
Tika的parse方法接受要被解析的文档,并将分析结果写入元数据集合中.以下为parse方法的最简单形态:

将元数据加入索引实际是完成资源语义的注册,在全文搜索中主要是依据检索关键词对文件内容进行查询匹配.而其他元数据可用于综合搜索处理中(例如:作者、标题等),并可为内容搜索提供关联的信息服务(例如:文档的标题、文件名等).
1.2 关于元数据
Apache Tika是一个工具箱,用来通过现有的解析器库检测以及从各种文档提取元数据和结构化的文本内容.parse方法的最后一个参数用来将文档元数据传递进/出解析器.文档元数据被表述为一个元数据对象.
图4给出了Tika中Metadata的继承层次.可以看出元消息来自多方面的定义.Dublin Core(都柏林核心)元数据是应用广泛的信息资源描述格式.DC元数据包含15个核心元素[4]:Title(题名)、Creator(创建者)、Subject(主题)、Description(资源描述)、Publisher(出版者)、Contributor(其他责任者)、Date(制作日期)、Type(类型)、Format(数据格式)、I-dentifier(资源标识符)、Source(来源)、Language(语种)、Relation(关联)、Coverage(覆盖范围)、Rights(权限).

图4 Tika Metadata的继承关系
1.3 文档元数据信息的获取
利用tika对象的parse方法可从输入流中分析出元数据存入Metadata对象中.分析提取一篇文档的元数据的代码如下:

接下来,利用met的getValues(“title”)方法可获取文档的title属性的值.
利用tika对象的parseToString方法可分析提取文件的文本内容.可将分析得到的文本内容并作为content域加入索引的document对象中,进而实现全文检索.例如:


1.4 Tika抽取元信息的结果分析
在微软的工具Word、PPT等工具中,均提供有属性设置对话框,可以设置一个文档的属性.这些信息是构成文档语义的核心.通常情况下,用户并不有意设置文档的这些属性.工具将自动设置标题、作者、单位等属性,而标题是根据PPT第1页首次保存含有的标题内容确定.
图5为Tika的图形界面应用中对一个Word文档的元信息的分析显示结果,显然,标题栏的语义与实际内容不一定符合;这是因为该文档是原来某文档的修改结果.很多文档是按工具默认的规则设置的标题;Word在文件保存时自动将第1行作为文档的Title,以后即便第1行进行了修改再次保存时title属性仍不变.

图5 Tika分析结果的元数据
类似地,Tika分析网页的元信息时,title元信息是从网页的title标记获取,制作网页时,FrontPage会自动设置“新建网页1”等标题,显然这不能反映网页的应有标题.
2 基于内容特征确立文档标题
在全文搜索应用的查询结果显示时,要将满足查询的所有文档的标题和摘要信息显示在网页中,并提供文件访问超链.前面建索引时,标题是用Tika获取的元信息构建.Tika获取的标题是来自用户文档的Title属性,文档的Title属性为空或者文档编辑工具给文档默认起名的标题(网页的title标签为“新建网页1”)等不适合作为标题,可通过分析标题中是否含有“特征串”进行判断.
为了让标题能准确反映文档内容,需要对标题进行改进.确定文档标题的一个简单处理办法是先考虑一些候选对象,然后,对这些候选对象进行评估,确定最优者.评估最优者要兼顾文档作者的意图和标题中含有文档的高频词的数量.
2.1 确定候选标题
根据文档标题通常在文档的开始、文件名、文档的标题属性等处出现的特点,可以初筛出一些候选标题:
(1)非特殊情形的Tika的Title元数据.
(2)文件名.特别地,文件名长度小于8不能作为标题.
(3)从文档中提取到的各条候选标题.
从文档选择标题,可以扫描文档的所有行,满足以下条件者可作为候选标题.
①标题长度不少于8.
②考虑到本文是针对中文文档的标题提取,因此,如果候选标题中不包含汉字字符,则不能作为标题.
③考虑到从文档中提取的字符串有各类标号,要删除候选标题中这些特殊的前缀和后缀.要去除的字符有:数字字符、大写数字字符以及各类标点符号.
2.2 候选标题的特征计算与选取过程
(1)设置候选标题的初始特征值
给每个候选标题设置一个初始特征值,初始特征值设置时考虑候选标题的重要性,如Tika获取的标题给予较重特征值(为N),文件名的特征值也较重(为0.9*N).其他标题特征值根据其在文档中的排列顺序依次降低,也就是文档前面的内容更可能作为标题.设候选标题个数为N,第i个候选标题对应的特征值为compare[i],则其他候选标题的特征值初始计算代码如下:

(2)对文档中的词项-词项频率进行统计,获取高频词
在获取标题的方法中只对一个文档进行索引,且索引的存储位置为内存,以提高处理效率.利用lucene API获取该文档的词项,以及每个词项在文档中出现的频率.然后,按照词项频率高低对词项排序,选取词项-词项频率列表中前10个词项来参与标题权值的计算.
(3)根据标题中出现的高频词数量调整特征值
设每个候选标题根据高频词出现的次数增加其权值,TN表示词项个数,算法如下:
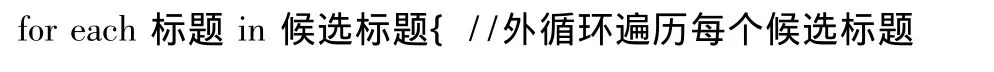

(4)选择候选标题中特征值最大者作为文档标题.
3 结束语
利用Tika可从各种类型的文档中提取语义信息.Tika能自动检测文档的编码,并对文档元信息和内容进行分析.Tika得到的元数据信息一般是通过文档的属性分析中得到,由于各种原因,这些属性未必能体现文档内容的实际,文中的采用多方竞选得到文档标题的解决方法,准确率较好,从而为基于语义的资源检索和全文内容检索提供更为准确的信息表达.标题提取是一个具有挑战性的问题,进一步的研究是引入领域本体[5],利用领域本体实现对文档的概念理解,从而辅助标题提取.
[1]赵庆龄,钱平,苏晓路.本体论在基于Web的土壤知识体系智能检索系统中的应用[J].计算机工程与应用,2005,(5):211-214.
[2]王伟,赵东岩,赵伟.中文新闻关键事件的主题句识别[J].北京大学学报(自然科学版),2011,(9):789 -796.
[3]刘建华,张智雄,谢靖,等.基于规则的网络文本资源标题快速自动识别方法[J].现代图书情报技术,2011,(5):27 -31.
[4]李秀丽,徐越权,浅析DC在高校图书馆网络信息资源组织中的应用[J].农业图书情报学刊,2010,(5):111 -114.
[5]位传海,范太华.基于本体的学习资源语义检索系统研究与设计[J].电化教育研究,2012,(2):70 -74.
