基于DNA 编码的多重约束目标的智能组合优化①
2012-07-09修建新范晓敏
修建新, 范晓敏, 张 磊
(黑龙江东方学院计算机科学与电气工程学部,黑龙江哈尔滨150086)
0 引言
1994年,DNA计算理论由L.Adleman首次提出[1].DNA编码在DNA计算过程中起到十分重要的作用,数据信息通过DNA编码以后,就具有了DNA染色体的许多的特性,可以解决现实中的很多问题.在有限的离散的数学空间中,在满足多个约束条件下,如何去求得目标函数的最优解问题就是多约束目标的组合优化问题.DNA编码和DNA计算表现出来的新特性,正好符合多重约束目标的组合优化问题的要求.所以,本文将DNA编码引入到多重约束目标的组合优化问题中,完成了基于DNA编码的多重约束目标的组合优化的全过程,并提出了相关组合优化算法,经过实验证明其求解的结果优于其他算法.
1 DNA编码
DNA编码是DNA计算中的一个非常重要的组成部分,DNA编码利用了DNA染色体特殊的双螺旋结构和碱基互补配对的特性来进行编码[2].关于DNA编码的问题可以表述为:DNA分子的四个碱基对可以定义为字母表P(A,C,G,T),对于一个长度为N的DNA编码的集合S,对于任意一个子集C,C⊆S,使得对于任意的Xi,Yj⊆C,F(Xi,Yj)≥k,k为任意的整数,F函数是DNA序列的评价函数,也就是编码应满足的约束条件.如果有多个约束条件,可以预先设定多个约束函数.
2 多重约束目标组合优化
某一对象要同时满足多个约束条件都会得到一个目标值,要求得目标值就必须建立相应的目标约束函数,这些约束函数的值和目标值之间的偏差达到最小就是多重约束目标的组合优化[3].多重约束目标组合优化问题可以用数学形式表述如下:已知一个n元组(X1,X2,…,Xn),一个约束集C(C1,C2,…,Cm),组成的一个状态空间S∈{(X1,X2,…,Xn)|Xi∈Di,i=l,2,…,n},S是满足C中的所有约束条件的所有n元组.其中,Di是分量Xi的定义域,且Di是有限集,则S就是满足C的所有约束条件的任一n元组为问题的一个解.
3 优化过程
基于DNA编码的多重约束目标的组合优化的过程包括DNA编码、初始化种群、计算个体适应度、个体选择、交叉、变异6个步骤,本文在DNA编码、初始化种群、遗传操作、控制参数等方面都提出了自己的方案,经过优化后可以得到较好的效果[4-5].具体优化过程如下:
3.1 DNA 编码
传统的编码方式都是采用二进制编码,二进制编码方式编码过长造成搜索空间过大,速度较慢.本文采用分段的DNA编码方式,采用DNA编码方式可以减少一半编码长度,大大克服了二进制编码的缺点.同时分段的方式可以满足多重约束目标的组合优化的需要,每段编码可以对应相应的约束条件,效果较好.DNA的碱基用二进制数来表示就分别是A=00,C=01;G=10,T=11 ,假设任意二进制编码序列为001101000111100100011011,采用DNA编码方式为ATCACTGCACGT,对DNA序列根据不同的约束条件可以分成多段,形式如下AT|CACT|GCACGT.
3.2 初始化种群
种群的初始化直接影响到遗传的计算结果和效率,一般都采用随机函数生成种群,本文在随机函数的基础上选择具有离散功能的随机函数,离散的种群有利于实现全局最优,可以提高求解速度.种群的初始化过程如下:
For i=1 to Pop_size do
Discrete_random(i)随机生成第i个DNA endfor

图1 遗传算法(GA)和DNA_YH算法的最优适应度的结果比较
3.3 计算个体适应度
每个种群中的个体一个最主要的遗传指标就是个体适应度,个体适应度就是个体对各个约束目标的适应程度,一般用适应度函数来表示.本文采用加权函数法来求得个体适应度函数.假设用fi(x)(i=1,2,…,n)表示目标函数,用Si(i=1,2,…,n)表示函数权系数,0 ≤Si≤ 1,(i=1,2,…,n),且,Si的大小表示在各个目标函数中的重要的程度,则各个目标函数的线性加权和为.
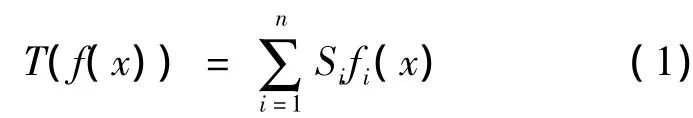
若f(x)非负,可以采用转换F(x)=,则最终的适应度函数为
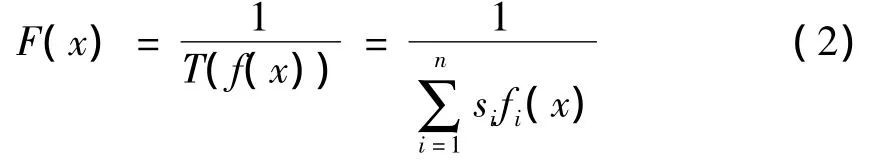
3.4 选 择
在传统的遗传算法中,选择算子采用的是轮盘赌选择法,这种方法会出现未成熟收敛和搜索速度较慢的缺点.所以对已有的生物的小生境方法进行改进,先对个体进行分组,然后选择每组中个体适应度较高个体进行遗传,同时子代个体的适应度超过父代个体就可以替换,这样就解决了未成熟收敛和父子代的相似度较高所产生的冗余个体.
3.5 交叉和变异
交叉算子和变异算子的选择直接影响到遗传的结果,交叉算子选的过大,将影响到遗传个体的适应度急剧变小,交叉算子过小,会造成搜索缓慢.变异算子过大就大大降低了遗传的效果,变异算子过小就会造成未成熟收敛,使个体早熟.交叉算子fc和变异算子fm直接受到平均适应度favg和最大适应度fmax的影响,根据它们之间的线性变化的规律,交叉算子和变异算子如公式4-3和4-4所示:
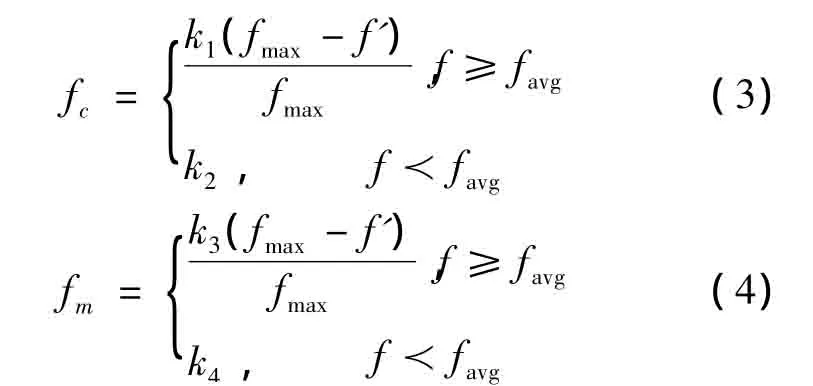
其中k1=k2=0.9,k3=k4=0.3,fmax是最大适应度值,favg是平均适应度值,f'是要交叉的两个个体中较大的适应度值,f是变异个体的适应度值.
4 算法设计
根据以上几个步骤的优化,很容易得到相应的基于DNA编码的多重约束目标组合优化算法,本文成为DNA_YH,具体的算法如下:
(1)对输入的数据进行DNA编码.
(2)设置参数,初始化种群.
(3)计算种群中个体的适应度函数的值.
(4)在种群中选择相应的个体进行交叉、变异的操作,产生下一代个体.
(5)子代适应度大于父代的进行替换.
(6)达到终止条件时结束算法,否则转(2).
5 实验与结论
本文提出的基于DNA编码的多重约束目标的组合优化算法在在线考试系统的组卷子系统中已经得到实现[6].DNA_YH算法采用的交叉算子和变异算子和最优适应度的关系如表1,2所示,从表中数据可以看出本算法的交叉算子和变异算子对最优适应度的影响都非常小,得到了较好优化.
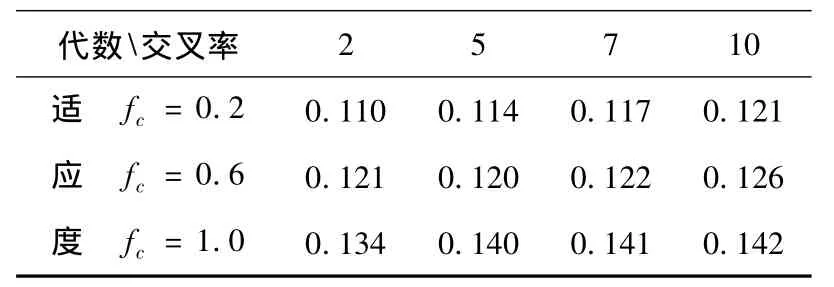
表1 DNA_YH的交叉算子和适应度关系
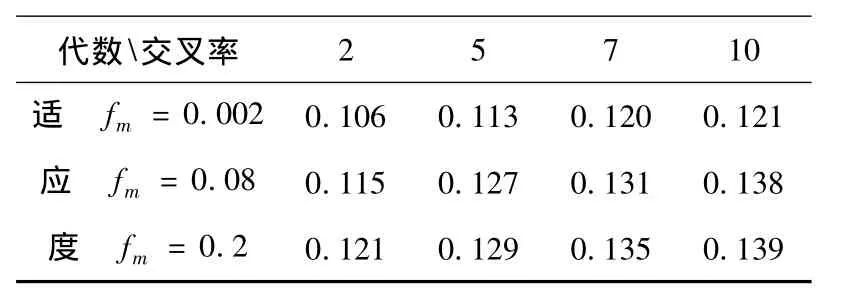
表2 DNA_YH的变异算子和适应度关系
实验还将传统的遗传算法和本文提出的DNA_YH算法进行了10代种群的比对,具体数据和比对结果如表3和图1所示:从图1中可以看出DNA_YH算法的种群最优适应度远远高于传统GA算法的最优适应度,验证了采用DNA_YH算法进行多重约束目标的组合优化可以得到更优的目标解.
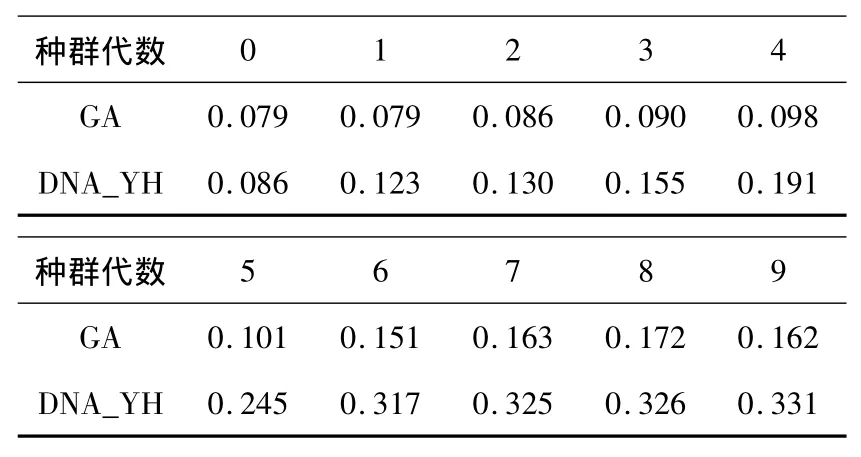
表3 遗传算法(GA)和DNA_YH算法的10代种群最优适应度数据
[1] Adleman L M.Molecular Computation of Solutions to Combinational Problems.Science.1994,266(5187):1021 -1023.
[2] 许世明,张强.基于遗传粒子群算法的DNA编码优化.计算机工程.2008,34(1):1 -4.
[3] Shin Si- Yong,Kim Dong-Min.Evolutionary Sequence Generation for Reliable DNA Computing Proc of Congress on Evolutionary Computation[C].IEEE Computer Society Press,2002.
[4] Baum EB.DNA Sequences Useful for Computation[C].Proc.The 2nd Annual DIMACS Meeting on DNA - based Computers.Princeton.1996 -06.
[5] Tanaka F,Yamamoto M,et al.Developing Support System for Sequence Design in DNA Computing Proc of the 7th International Workshop on DNA - based Computers[C].Tampa,FL,USA:2001.
[6] 陈宇,陈治平.启发式遗传算法组卷模型研究[J].计算技术与自动化.2006,25(l):35 -120.
