一种针对新闻话题的多文档文摘技术
2012-06-29岳大鹏
岳大鹏,饶 岚,王 挺
(1. 国防科技大学 计算机学院,湖南 长沙 410073;2. 国防科技大学 人文与社会科学院,湖南 长沙 410073 )
1 引言
当今社会信息的产生和传播速度大大加快。在谷歌中查询“动车 事故”,就能搜索到上万篇有关最近国内一起动车出轨事故的相关报道,包括事故的起因、发展,政府组织的抢救工作,有多少人生还,应由谁来承担事故责任等。如果想了解事件的全貌,面对如此海量报道,逐一阅读是一件费时费力的工作。因此,人们迫切需要一个整理和归纳信息的工具,以便于在最短时间内对一个事件进行全面的了解。多文档文摘技术[1-2]能够把大量的文本进行提炼,摘取出重要或用户感兴趣的信息生成一篇文摘,因而能满足我们的要求。
系列事件的报道越来越多地会采用按照话题组织新闻的方式。这能方便读者了解到事件的来龙去脉。不同于一般的多文档集,以话题为纽带组织起来的一组文档有重复度高、无用信息少、文档间联系紧密等特点。针对这些特点,需要一种基于话题的多文档文摘以处理这种文档集。
本文介绍了一种基于话题的多文档文摘方法TBMMR(Topic Based Maximal Marginal Relevance),并在添加了人工文摘的TDT4汉语新闻语料上做实验验证了它的有效性。
2 基于话题的多文档文摘特点
本文研究的对象,基于话题的多文档文摘是指对按照某一话题组织的文档集进行自动文摘。它来源于话题发现与追踪的研究。话题发现与追踪[3]是对新闻语料进行话题方面处理的一个强有力的工具,它能根据用户感兴趣的话题筛选有用文本,将涉及某个话题的报道组织起来返回给用户。而基于话题的多文档文摘就是对这些经过过滤、按照话题组织起来的报道进行文摘。
由于经过了话题追踪的处理,与普通的文档集相比,由话题组织的语料有以下特点。
(1) 话题文档集叙述的所有事件都围绕一个核心事件(即种子事件)展开;
(2) 文档间有更强的内聚性。各个文档的内容重复度更高;
(3) 报道的内容间有时间上的联系性和承接性,而不是简单的叠加。
在话题结构上,文档集中反应的所有事件一般按照以下两种方式组织。
(1) 顺序式话题结构。顺序式结构中,话题文档集涉及到的所有事件都是单线结构发展,常常是针对一个主体的连续事件的跟踪报道。所有的事件有明显的时序关系,报道的主体不发生改变。
(2) 发散式话题结构。发散式话题结构中,会有许多事件独立发生,但这些事件都是由种子事件引起或和种子事件有很大关联。这样的结构中,事件间没有明显的时序关系,或者时间不重要。
由于话题文档集基于话题的特点。在针对其做文摘时,要充分利用话题的信息。话题中,种子事件是重点描述事件,针对种子事件的信息可以通过话题描述得到。而非种子事件的信息必须从文档内部获得。针对文档内容在话题结构上的不同,顺序式结构和发散式结构的话题最终得到的文摘描述事件的结构也应当有所区别。所以,针对以上两点,我们提出了一种基于话题的多文档文摘方法。
3 基于话题的多文档文摘方法
针对基于话题的文档集合的特点,我们以Maxi-mal Marginal Relevance(MMR)文摘方法为核心,充分考虑话题信息,设计实现了一个基于话题的多文档文摘方法,称为TBMMR(Topic Based MMR)方法。该方法区别对待种子事件和非种子事件,用不同的方法得到对两种事件的描述;该方法根据话题文档集在文档内容结构上的不同,采用不同的文摘句排序算法。
3.1 多文档自动文摘技术和 MMR 方法
多文档文摘是将多文档集合中的多次重复信息,根据重要性及压缩比依次抽取的文本集合压缩技术[1,4-5]。较为常见的抽取式文摘的方法通常按如下流程[6]进行,如图1所示:
(1) 按照评分标准给文档集合中所有的句子进行打分;
(2) 按照一定的比例, 把句子按照打分由高到低挑选作为文摘句;
(3) 把文摘句按一定顺序排列,组成文摘。
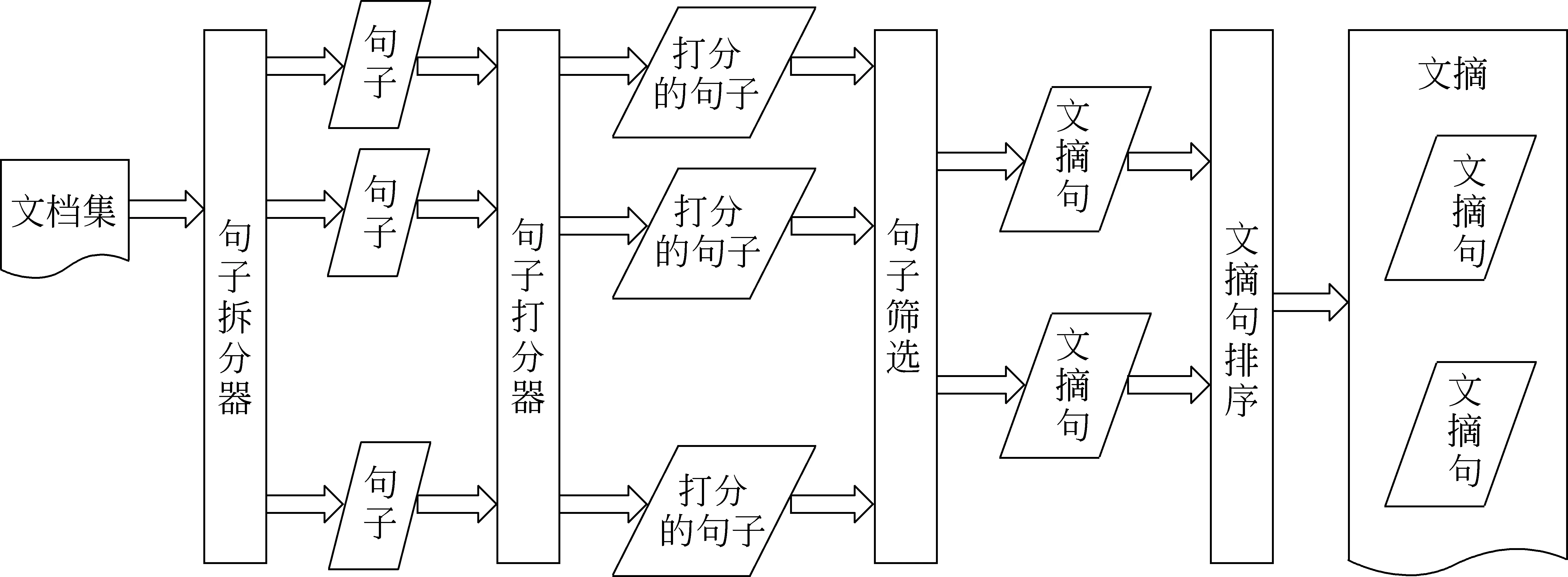
图1 抽取式自动文摘方法
一种有影响力的文摘方法是MMR(Maximal Marginal Relevance)[7]方法,由Carbonell和Goldstein于1998年提出。它是一种偏重文摘方法,即生成文摘过程不仅仅考虑文档本身,还考虑用户的查询输入。MMR方法对句子打分时考虑两方面因素: 用户的关注度和句子本身内容的新颖度。句子打分标准MR(Marginal Relevance)反映了这两个方面,如式(1)所示:
其中,Di是当前要打分的句子,函数Sim1、Sim2是比较句子相似度的函数,一般使用向量空间模型余弦值计算。Q是依赖于用户的查询输入。Dj是已经被选入文摘句集S的句子。λ是调节用户关联度和句子新颖度二者权重的参数。
与一般抽取式文摘方法计算一次句子得分立即抽取文摘句不同,MMR算法反复计算文档集中所有句子的MR值,选取得分最高的句子到文摘句集合S中去,先抽取出的文摘句对其余句子的评分会产生影响。
MMR方法在实际应用中的瓶颈在于,查询Q是由用户给定的。如果Q能够全面准确地反映话题的信息,该方法能得到会全面概括话题文档集的比较好的文摘;反之,就会概括片面,文摘质量差。本文的TBMMR方法首先要解决如何用话题描述信息得到高质量的用户输入Q这一难题。
3.2 获取话题信息
一个话题文档集报道了一个种子事件和若干个非种子事件,从而话题信息分为两部分: 种子事件的信息、非种子事件信息。而话题描述只有种子事件的概要,没有提及非种子事件,所以非种子事件描述要单独处理。
首先确定每篇报道的主事件是话题集的种子事件,还是非种子事件。选取新闻报道的标题(HeadLine)和前三句话作为这篇报道的主题句集合Theme(doc),按照句子内容相近度和事件间隔对话题文档集的每篇文档计算话题相关度,见式(2)。
其中,doc是话题文档集中一篇文档,sim函数计算句子的相似度。在系统实现上,本文利用向量空间模型的余弦值来计算两句话的相似度。s是文档主题句,st是话题描述句。time(doc,topicTime)是文档描述事件和话题事件的时间间隔。
如表1所示,选取话题信息时,把每篇报道的话题相似度和选定的threshold进行比较,从而判断文档是否是种子事件的报道。抽出非种子事件报道的主题句作为非种子事件的信息,直接利用话题描述的句子作为种子事件的信息。二者同时作为TBMMR方法的话题信息输入句子打分器。

表1 判断文档是否是种子事件的报道算法
3.3 句子打分
传统的MMR句子打分公式没有使用句子的位置信息和描述时间等信息[8-9]。而对于结构简单清晰,而且时效性强的新闻报道,这些信息是十分重要的。
一个句子的时间属性可以简单认为由句子中出现的时间状语所决定[9],可以如表2所示的算法计算。

表2 获取句子的时间属性算法
一个句子的位置得分由句子在通篇文章中的位置和在段落中的位置决定[10],定义如式(3)所示。
其中,L(document)是句子所在文档的总句子数,No(document)是句子在文档中的序号,L(paragraph)是句子所在段落的总句子数,No(paragraph)是句子在段落中的序号。这里的句子位置信息度量选取两方面: 句子在整个报道中的位置,和句子在所在段落中的位置。
TBMMR句子打分的标准定义是使用传统MMR方法的公式再加上位置信息得分,见式(4)。
其中,句子相似度定义为空间向量模型的余弦相似度,并附加考虑两句话反映的时间间隔,如式(5)所示。
其中,TimeSimilarity反映的是两个句子发生时间的相似度,利用式(6)计算。
t1、t2是句子描述的事件的时间属性,根据时间是否一致或相近定义为1或0.3或0。γ是用于调整比重的参数,经过比较实验,程序实现中γ取0.4。
文摘句顺序的调整
文摘系统对挑选的文摘句的排序一般会考虑以下几点。
(1) 按照句子在原文中的顺序;
(2) 按照句子的打分由高到低;
(3) 按照句子反应事件的发生时间。
因为新闻报道语料反映的大多是叙事性的句子,时间性很强,所以,生成的文摘中主要按照时间来排列句子顺序,兼顾句子在原文的顺序和句子打分。
话题结构组织方式直接影响生成文摘的结构。两种不同的文档集结构需要按照不同的句子排序算法。顺序式结构中,事件是按照时间先后顺序,一件一件的发生,所以生成的文摘可以简单的按时间顺序来列举。发散式结构中,多个事件同时出现的可能性较大,这时,在文摘中就应该把一个事件叙述完整再叙述下一个事件,而各个事件之间的叙述顺序就无关紧要。
首先确定一个文档集是顺序性结构还是发散性结构。鉴于两种组织结构的区别主要体现在时间序上,所以可以通过查找是否有多个事件在同时发生来简单区分这两种话题结构组织方式。确定话题结构组织方式使用表3的算法。

表3 判断文档集组织结构算法
针对文档集组织结构不同,使用不同的文摘句顺序调整方法:
• 顺序式话题文档集结构
所有文摘句按时间属性整体排序,时间属性不同的文摘句,按照时间先后排列。时间属性相同的文摘句,按照文摘句打分给出顺序: 得分高的放在前面。
• 发散式话题文档集结构
先把文档集原文按照时间顺序排序,按照一天为单位,把报道时间相同的文摘句分组。不同组的文摘句由时间顺序给出文摘句句序。相同组文摘句,由句子打分高低作为句子顺序。
4 实验评估
4.1 TDT4语料
TDT4是用于话题发现与追踪系统测试的一个语料集。收集2001~2003年的大量中文、英文和阿拉伯文的新闻汇集而成。语料集精选了2002年和2003年的80个热门话题,并用这些话题对新闻进行人工标注。所有的新闻报道都被标记成是否是80个话题中的某一个话题的相关事件。
TDT4语料中,分别提取80个话题的所有相关中文报道,于是得到了80个通过话题组织的文档集。由于TDT4语料没有对每个话题文档集提供相应的文摘,就要求我们对测试话题文档集添加人工的文摘。
从80个话题中选取了16个质量较好的话题进行人工的文摘标注,选取标准如下:
• 每个话题的汉语报道数目不少于6篇,不多于20篇,总句子数不多于200句,防止人工文摘产生阅读疲劳,影响文摘质量。
• 每个话题包含的报道至少来自3个不同的新闻社,防止内容单调,观点单一。
我们找到8个志愿者进行话题标注工作。每个话题,要有两个不同的文摘人做文摘,以提高评价准确度。要求文摘人通读整个话题文档集中包含的所有汉语报道,抽取话题文档集中15%的原句,组成一篇压缩比例为15%的文摘。然后进一步缩写出10%和5%的文摘。
4.2 评价方法
ROUGE[11-13]评价指标是目前常用的评价文摘质量好坏的标准。这里使用最常见的ROUGE-1、ROUGE-2和ROUGE-3作为评测依据。
Rouge-N是基于N-gram和召回率的评价方法: 把参考文摘的每一个N-gram在待评价文摘中寻找匹配。多参考文档的ROUGE-N计算时,利用多篇参考文档分别计算待评价文摘ROUGE-N值,选取最大的作为此待评价文摘的ROUGE-N值,见式(7)和式(8)。
其中n表示n-gram的长度,Count(n-gram)为专家摘要中出现的n-gram数,Countmatch(n-gram)为算法生成的候选摘要与专家摘要中共现的n-gram数。
4.3 实验结果及分析
实验过程构造实现了两个Baseline系统本文的TBMMR系统进行比较:
• Location系统: 单纯利用句子的位置信息作为打分依据,即使用式(3)。每篇文档的首句具有最高的分数,位置越靠后,得分越低。
• SMMR系统: 传统的MMR方法实现。把所有的话题描述句作为用户的查询得到系统文摘。
实验过程中,利用三种文摘系统分别对TDT4语料的16个话题文档集做出不同压缩率的文摘,对得到的系统文摘利用Rouge评价方法得到评价数据,见表4、表5和表6。

表4 ROUGE-1 评价结果

表5 ROUGE-2评价结果

表6 ROUGE-3评价结果
从结果可以看出,在压缩比例为5%和10%时,TBMMR系统三个评价指标上得分均优于其余两个系统;压缩比例15%时,TBMMR系统在ROUGE-1、ROUGE-2两个评价指标上得分最高,ROUGE-3评价指标TBMMR略低于SMMR。从不同压缩比例的结果上看, TBMMR在5%压缩比例上具有最好的改进效果;在10%压缩比例上也有明显的改进,但提高幅度不如5%压缩比例;在15%压缩比例上,改进效果有所下降。综上表明,本文方法能够较好地利用话题特点,提高文摘句重要性的度量和排序的效果。
5 结论和下一步工作
本文提出一种基于话题的新闻语料多文档文摘方法。此方法以MMR方法为基础,结合话题多文档集的特点,通过在句子打分过程中区分话题种子事件和非种子事件,来达到更好的文摘句抽取效果,通过区分话题组织的顺序式结构和发散式结构,达到更好的文摘句排序效果。经过在TDT4语料上的验证,此方法确实优于传统的MMR方法和通过位置信息打分的方法。
在下一步工作中,我们将尝试以下两个角度来考虑和展开新的研究。
(1) MMR方法针对大数据量元数据操作时具有时间花费特别大的缺点。接下来可以研究用某种方式把文档集进行适当的分组,以减少运算时间花费。
(2) 考虑利用语义信息辅助句子间的内容匹配。
[1] McKeown K R,Radev D R. Generating summaries of multiple news articles [C]//Proceedings of SIGIR’95,1995: 74-82.
[2] Luhn H P. The automatic creation of literature abstracts [J]. IBM Journal of Research Development, April, 1958: 159-165.
[3] 洪宇, 张宇,刘挺,等.话题检测与跟踪的评测及研究综述[J]. 中文信息学报,2007,21(6):71-87.
[4] 秦兵,刘挺,李生. 多文档自动文摘综述[J]. 中文信息学报, 2005,19(6):13-20.
[5] 张其文, 李明. 多文档文摘提取方法的研究[J]. 兰州理工大学学报, 2007,1:96-99.
[6] 徐永东, 徐志明, 王晓龙. 基于信息融合的多文档自动文摘技术[J]. 计算机学报, 2007,30(11):2048-2054.
[7] Carbonell J, Goldstein J. The use of MMR, diversity-based reranking for reordering documents and producing summaries [C]//Proceedings of SIGIR’98, 1998:335-336.
[8] 徐永东,王亚东,刘杨,等. 多文档文摘中基于时间信息的句子排序策略研究[J]. 中文信息学报, 2009,23(4):
[9] 索红光,粱玉环,刘玉树. 基于时间戳的多文档自动文摘[J]. 计算机工程, 2007,33(16):164-172.
[10] Bossard A. Using Document Structure for Automatic Summarization[C]//Proceedings of SIGIR 2009 , 2009:850-858.
[11] Pitler E, Louis A, Nenkova A. Automatic Evaluation of Linguistic Quality in Multi-Document Summarization[C]//Proceedings of ACL2010,2010:544-552.
[12] Lin C. ROUGE: A package for automatic evaluation of summaries[C]//Proceedings of Workshop on Text Summarization Branches Out, Association for Computational Linguistics, 2004:74-81.
[13] Lin C, Hovy E. Automatic evaluation of summaries using n-gram co-occurrence statistics[C]//Proceedings of 2003 Language Technology Conference, 2003: 71-78.
