构建查询需求形式分类体系
2012-06-29刘奕群马少平
王 超,朱 彤,刘奕群,马少平
(智能技术与系统国家重点实验室,清华信息科学与技术国家实验室(筹),清华大学 计算机系,北京 100084)
1 引言
互联网络已经成为人们日常生活中必不可少的基础设施,而搜索引擎作为人们从互联网上获取信息的重要渠道,也已经成为非常重要的网络应用。根据2011年1月19日CNNIC发布的《第27次中国互联网络发展状况统计报告》[1],截至2010年12月底,我国网民规模已达到4.57亿,而搜索引擎的使用率更是达到了81.9%,成为网民第一大应用。
搜索引擎作为人们目前进入网络的重要入口,是人们进行信息查询的主要方式之一,在目前搜索引擎提供的交互接口和服务条件下,用户一般只能通过提交若干个词汇或短语来抽象和概括自己的需求(例如,早时有人对Excite搜索引擎日志分析发现搜索平均词汇长度为2.4个左右)[2]。这样的搜索方式意味着用户首先需要对自己的需求进行概括,然后再进一步用若干关键词表达需求。这也导致了两个问题: 1)不同的用户可能使用不同的词汇表达相似的需求;2)相同的查询词可能代表不同的用户需求。因此,研究查询分类问题可以让我们更好地解决上述两个问题,从而帮助搜索引擎进行更好的优化。
对于查询歧义问题,现有的研究主要是对查询内容上的歧义进行分类[3-4],而忽略了用户查询需求形式上的歧义。所谓查询内容上的歧义是指同一个词汇可能代表不同的含义(如“apple”作为查询词时可能表示水果也可能表示苹果公司),而查询需求形式上的歧义则是指同一个词汇可能代表用户的不同需求(如“三国”作为查询词时用户可能是需要相关的小说也可能是寻找相关的视频)。
本文主要针对事务类查询中的需求形式歧义进行研究,目的是针对查询需求形式构建合适的查询分类体系,在相应体系基础上构建分类模型并设计合适的算法。
在第2节我们将首先介绍查询分类和查询歧义已有相关研究工作,第3节介绍查询需求分类体系的构建,第4节介绍分类模型的构建以及分类流程,第5节介绍实验的具体结果,最后总结全文,给出未来工作的一些方向。
2 相关研究工作概述
针对于查询歧义,人们较多关注的是内容上的歧义,而现有的解决思路大致有以下三种。
1) 根据上下文语境或依存关系,通过语义分析来消除歧义[5]。实现此方法要借助大量的语法、句法分析,实现较为复杂,并且如何定量计算语义关系也制约着该方法的实际应用。
2) 建立大型综合数据库来解决用户查询表达差异。此方法需要预先对大规模的文档进行数据挖掘,建立词与词之间的关联性度量,同时需用不同的词表达同一概念,如采用同义词词典的形式或者WordNet的形式。实现此方法需要大量的文档作为基础资料,因此文档的选择以及文档的覆盖面会很大程度影响实际效果。
3) 先检索出所有可能相关的文档,再将文档进行聚类来判断是否有歧义存在[6]。此方法对于聚类的准确性依赖很大,如果不能有效地进行聚类,则很难得到准确的结果。
另外,目前还有利用Wikipedia[7]或ODP[8]等外部资源帮助进行用户意图理解和查询歧义分析的方法。
相对于上述方法,利用搜索日志可以很好地结合互联网实际的查询情况, 通过大量的日志所得到的统计信息也可以更加准确地反映出实际用户的需求,因此近年来有不少研究者开始结合大规模搜索日志进行查询需求理解的相关工作: Li[9]试图利用用户点击信息中查询和点击网站的链接图,结合部分标注好需求的查询来计算所有查询的需求;Radlinski[10]利用搜索日志得到用户查询过程中经常相关出现的查询集合,再针对每个集合进行聚类以得到不同的用户需求。
我们提出的查询需求理解方式则是利用搜索日志,结合网页目录的形式来构建分类站点列表,这样的方法可以较好地代表网络中实际存在的资源情况,二者结合可以得到相对更为准确且具有实用性的查询需求理解。
3 查询需求分类体系的构建
3.1 传统查询需求分类
现有比较常见的查询分类方式为Broder等人提出的三大类别分类,即查询意图可分为导航类、信息类和事务类三种。
1) 导航类: 用户查询意图主要是为了访问某个特定的网站,如某公司的主页。
2) 信息类: 用户查询意图主要是为了获得某一方面的相关信息,信息可能出现在多个网页上,如配置Apache服务器。
3) 事务类: 用户查询意图主要是为了进行一些基于网络的活动,获得自己需要的资源,如软件下载。
3.2 根据查询需求形式构建分类体系
在传统体系下,不同的研究会根据不同的需求在此基础上进一步细致分类。由于用户查询对于导航类的需求往往比较一致,不需要进行更细致的分类;对于事务类查询往往需求形式明确且集中,适合进行分类;而对于信息类的查询需求形式往往比较零散,所以本文主要针对事务类的用户查询需求形式进行类别上的扩展,将事务类查询进行了进一步的细分,划分为财经、人才、视频、数码、体育、图片、小说、音乐、游戏、汽车、军事、交友等多个子类,通过同一个用户事务类查询对多个子类的需求情况来探究用户需求形式上的歧义,图1显示了当前构建的查询需求分类体系结构。

图1 查询需求分类体系
4 查询需求分类模型的构建及分类流程
4.1 Query-URL二部图模型
确定了用户需求的分类体系,下一步需要构建从查询到需求的模型。对于给定的用户查询,搜索引擎会返回相应的URL列表,如果假设每一个URL都属于一个或多个需求类别,则可以建立以下(图2)形式的查询需求分类二部图模型。

图2 查询需求分类模型
模型公式如下:
其中n表示需求类别,q表示查询,u表示用户点击的URL。我们假设用户提交了一个查询q,众多用户在提交这个查询q之后,会点击一系列的网页URL,而这些URL的背后体现着一种用户需求。在这些URL中,我们可以提取用户点击最多的若干
URL,从而通过对URL需求的分析推测出用户的需求分类。例如,这个URL是个导航类的页面,那么一般q就是导航类,如果这个URL是个视频播放的网页,那么查询q很有可能就是视频需求的。
4.2 简化模型
如Query-URL二部图模型所示,一个URL可能符合多种需求形式。在这里为了简化计算,我们认为每一个URL只对应一种需求形式,即p(n|u)=1,那么上述二部图模型就可以简化为式(2):
这样我们就只需要根据定义好的分类体系得到用户点击的URL的分类标注,就可以计算出查询的需求分类。
4.3 构建URL分类标注集合
由于用户实际点击的URL数量十分庞大,对于每条URL进行标注是不现实的,因此我们需要设计一种自动对于URL进行标注的方法。
在这里我们利用了网络上现有的网页目录资源,我们从网页目录中选取与我们构建的分类体系相关的类别,并从中抽取出所包含的站点。之所以选取网页目录作为参考构建方法,是因为网页目录所提供的分类为用户最为常见的需求分类,并且目录上所包含的网站也为用户相对最常访问的网站。因此使用网页目录可以较为简单快捷地得到一些合适的分类,并得到网络中实际存在的资源站点列表。抽取的结果和覆盖度检测在实验部分进行了详细说明。
4.4 URL需求分类判定流程
在判断查询需求分类之前,我们要能够对每一个URL判定其需求分类,具体流程如图3所示。首先判定其是否为导航类,若不是,则根据已有的事务类各个子类的站点列表来判断此URL是否属于其中某一子类,若不是则直接判定为信息类。
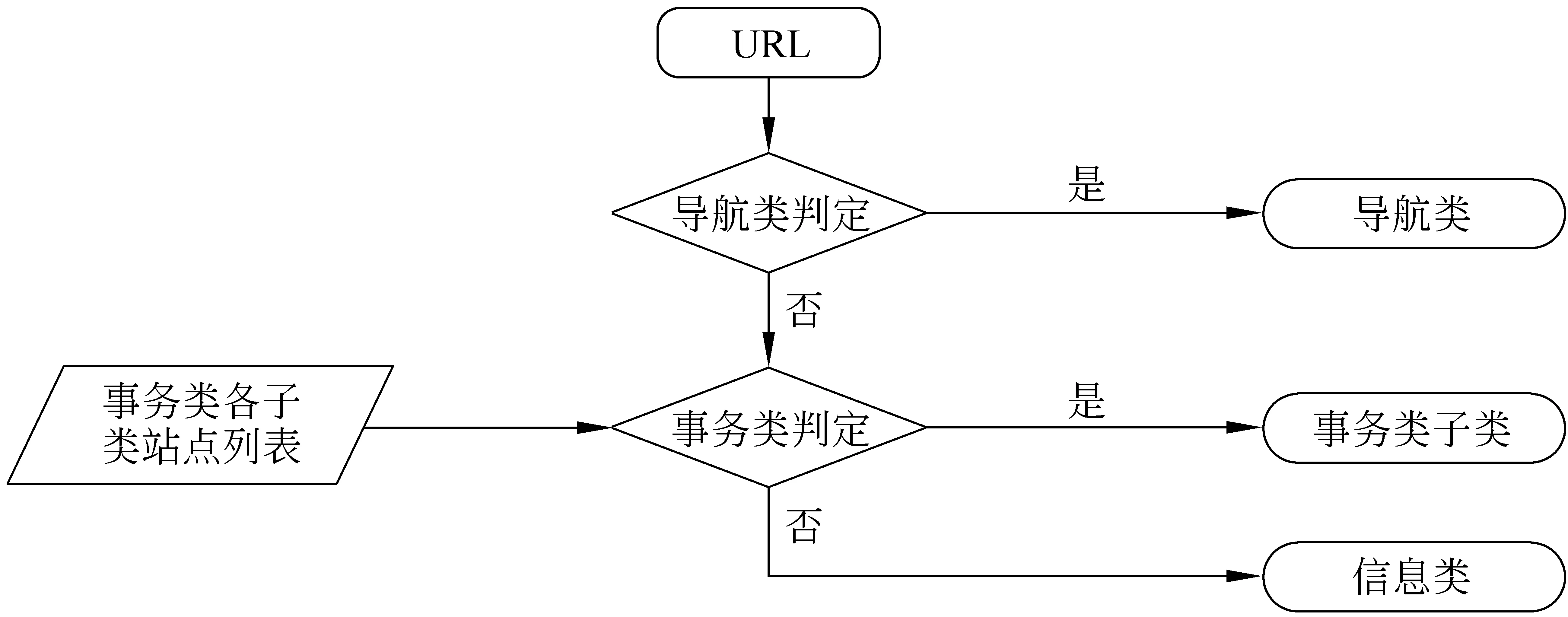
图3 URL需求分类判定流程
4.5 查询需求分类判定流程
在URL需求分类判断基础上,查询需求分类判定的流程如图4所示。首先根据搜索引擎日志统计出该查询所有用户点击过的URL列表,对每一个URL进行需求分类,然后统计出每一种需求类别在总点击中占有多少比例,根据所得比例来判定该查询有哪些需求形式。

图4 查询需求分类判定流程
5 实验结果
5.1 实验准备与数据
本次实验所采用的搜索引擎日志是国内一家搜索引擎公司所提供的,实验中抽取了2011年2月份一个月的点击记录。表1显示了所使用的搜索引擎日志中可以提取的相关信息。

表1 搜索日志信息
5.2 构建URL分类标注集合实验
我们选用了hao123、搜狗等网页目录作为构建分类的参考。从网页目录中我们选取了对应于我们的事务类子分类的资源,提取的分类及站点数量如图5所示。
为了检验我们的分类对于实际搜索的覆盖程度,我们对搜索引擎日志进行了统计,结果如表2所示,其中总查询数表示在搜索日志中查询频率较高的查询(阈值为100)。
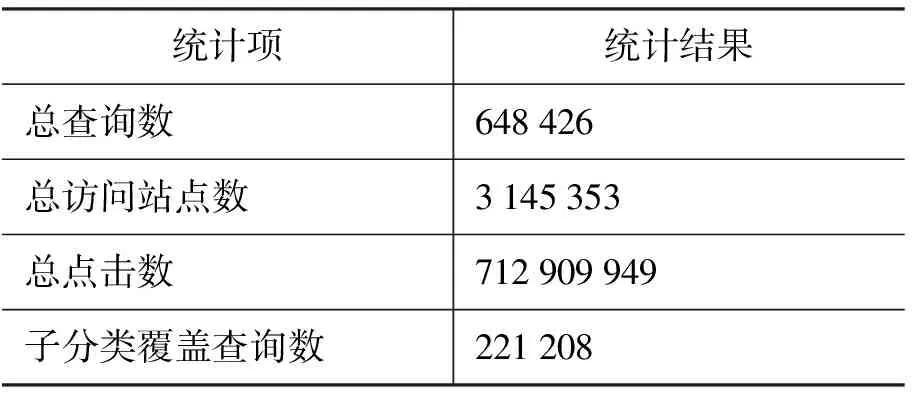
表2 覆盖度统计
对于表2所示的统计情况,首先可以看出实验的数据规模较大,足以体现互联网用户真实搜索情况,并且通过子分类的覆盖查询数达到了总查询数的1/3量级,可以看出从网页目录中选出的分类确实是用户真实生活中最常搜索的一些类别,可以达到后续对查询需求形式分布的实验需求。

图5 事务类子类站点列表数量分布
5.3 查询需求形式分布实验
由于同一个查询可能会有多种需求,用α表示对于给定查询的某一需求在该查询所有用户点击中所占的比例阈值,不同的阈值α会得到不同数量的查询,表3列出了当α分别取0.1、0.15、0.2、0.25时所得到的查询数量。
为了检测所得查询的需求描述准确率,我们选取α=0.2时所得到的含有2个及以上需求的查询中随机抽取了100个结果进行人工标注, 标注方式为对于每个查询,标注人员可以判断该查询是否有财经、人才、视频、数码、体育、图片、小说、音乐、游戏、汽车、军事、交友12个方面的需求,如有则标出相应需求,对于每个查询至多可以标注3个需求。
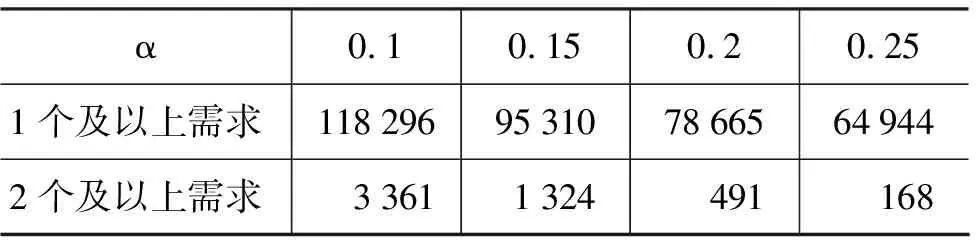
表3 所得查询数量随α的分布
表4显示了两位标注人员的标注结果Kappa一致性系数。
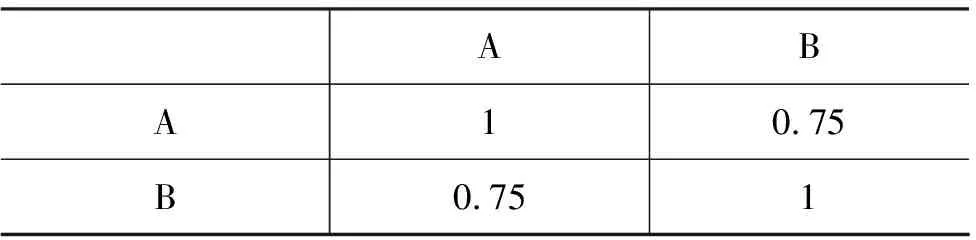
表4 标注结果之间Kappa统计
表4中A,B分别代表两名标注人员。可以看到平均的Kappa值为0.75,达到了高度的一致性(substantial)的程度,可以用来进行准确性的评价。
根据人工标注结果我们对查询需求描述的准确率进行了检测,表5是检测结果。

表5 精确度统计
通过上述统计可以看出我们分析出的查询需求具有比较高的覆盖度,只有16%的查询我们存在没有得到的标注需求,说明当我们对某一个查询进行了意图分析之后,我们基本可以确定这个查询的主要意图只会在我们得到的集合中。但是相对于覆盖度,我们的准确率并不是让人十分满意,只有64%的查询我们所得到的需求与标注没有冲突。经过对于具体查询的分析,我们发现其中很多的错误都是由于查询本身限定了需求的种类,例如,“qq飞车视频”,其本身是一个游戏,所以很容易会有游戏类别的网站与其相关,但是由于其查询中明确指出了视频类别的需求,所以在标注的时候会被认为只有视频类别的需求, 而我们根据点击情况得到的游戏类
别就会被认为是错误的需求。所以如果我们能根据查询本身进行一些限定,那么判断的准确率就会进一步提高。但是如果我们换一种角度来考虑,用户虽然提交了一个明确意图的查询,却仍然点击了大量其他意图类别的网站,这也说明用户对于自己的意图并非查询词显示的那么明确,如果我们给予其相关的其他类别的网站,也会对用户的查询起到一定的帮助作用。
6 结论与未来工作
这篇文章针对查询需求歧义问题进行了研究,提出了相应的查询需求分类模型,并利用网页目录构建用户需求形式分类体系及站点列表,在大规模商业搜索引擎日志上进行了用户点击覆盖检测的实验,并通过标注的方法进行了分类准确率的检测,验证了我们的方法的实用性和有效性。该工作的意义在于不仅说明了用户需求形式上的歧义是普遍存在的,并且提供了一种可行的需求形式检测方法。
在接下来的工作中,我们将设计实现基于非简化模型的分类方法,同时针对导航类和信息类查询设计更为合理的分类方法,从而实现一个较为完整实用的用户需求分类系统。另外针对Query-URL的点击链接结构图,我们目前只对其中URL能够被网页目录覆盖到的部分进行了利用,还没有尝试利用整个链接结构关系从已标定的节点集合扩散到未标定的节点集合,从而试图对更多的查询进行意图的分析。因此,接下来我们还将尝试更多地利用点击链接结构信息来对更大规模的查询进行意图分析,希望能够找到一种具有更加普遍的应用范围的方法。
[1] CNNIC (China Internet Network Information Center)[EB/OL]. The 25th report in development of Internet in China. http://www.cnnic.net.cn/dtygg/dtgg/201101/P020110119328960192287.pdf, 2011.
[2] A Broder. A taxonomy of Web search[C]//SIGIR Forum, 2002, 36(2):3-10.
[3] J Teevan, S T Dumais, D J Liebling. To personalize or not to personalize: modeling queries with variation in user intent[C]//Proceedings of SIGIR, ACM, 2008: 163-170.
[4] Ruihua Song, Zhenxiao Luo, Ji-Rong Wen, et al. Identifying ambiguous queries in Web search[C]//Proceedings of WWW 07, 2007: 1169-1170.
[5] Allan J, Raghavan H. Using Part-of-Speech Patterns to Reduce Query Ambiguity[C]//Proceedings of the Annual International ACM Conference on Research and Development in Information Retrieval (SIGIR 02). ACM Press, 2002: 307-314.
[6] S Cronen-Townsend, W B Croft. Quantifying query ambiguity[C]//Proceedings of HLT ’02 : 94-98.
[7] Hu Jian, Gang Wang, Fred Lochovsky, et al. Understanding user’s query intent with Wikipedia[C]//Proceedings of WWW-09, 2009.
[8] G Qiu, K Liu, J Bu, et al. Quantify query ambiguity using ODP metadata[C]//Proceeding of SIGIR ’07: 697-698.
[9] X Li, Y Wang, A Acero. Learning query intent from regularized click graphs[C]//ACM Special Interest Group on Information Retrieval, 2008.
[10] F Radlinski, M Szummer, N Craswell. Inferring query intent from reformulations and clicks[C]//Proceedings of WWW, New York, NY, USA, 2010: 1171-1172.
