基于情感向量空间模型的歌曲情感标签预测模型
2012-06-29林鸿飞李瑞敏
李 静,林鸿飞,李瑞敏
(大连理工大学 计算机科学与技术学院,辽宁 大连 116024)
1 引言
音乐的情感标签对基于情感的音乐检索研究有着十分重要的意义。情感标签是用户对音乐的情感诠释,它将“隐性”的音乐情感“显性化”,可以避免专家标注跟大众用户在音乐情感认知上的“代沟”问题[1]。同时,大量的情感标签从不同的角度表达出不同用户对音乐的情感体验,可以避免将复杂的音乐情感“单一化”。但是,并不是所有的音乐都有被标注的“情感标签”,对于一些新的音乐,在它还未被大众所熟识的情况下,它的情感信息还是以一种“隐性”的特征蕴涵在音乐中。因此,本文提出一种基于半监督学习的音乐情感标签预测方法,利用歌曲的歌词信息进行情感分类,找到与待预测歌曲情感主类一致的歌曲集合,并在此集合上通过歌词的情感相似度计算找到最邻近的k首歌曲,对这些歌曲的情感标签进行相似度加权计算,选择前M个作为候选标签推荐给待推荐歌曲。
歌词主题集中、用语简单、结构规范,具有节奏性和韵律性,对歌曲的情感表达有至关重要的作用。文献[2]通过调查发现,中文歌曲中只有不到5%的歌曲因不同歌手演唱而导致所携带的情感信息发生变化。因此,以歌词为歌曲情感的分析依据具有合理性和有效性。传统的文本特征提取方法种类较多,但是对歌词的文本特征提取存在以下问题: (1)歌词文本较短,一般为50~80个字,传统的文本基于“词袋”的方法会不可避免地出现严重的数据“稀疏性”问题;(2)文本特征数量较大,高维度的特征空间大大增加了计算的复杂度;(3)文本特征中含有大量与情感无关的词汇,可能影响情感分析的效果。针对上述问题,本文提出了情感向量空间模型,用歌词中的情感特征词代表歌曲情感向量。并在此基础上,提出基于“情感词—情感标签”共现的特征降维方法,将歌词中的情感词映射到140维的情感标签中,既避免了数据的稀疏性,同时又降低了计算的复杂度。
本文利用基于内容的情感标签推荐技术来实现新音乐的情感标签预测,首先,根据Hevner情感模型[3],将音乐情感标签划分到8大类中;然后,抽取歌词情感词作为特征,利用SVM分类器,将待推荐歌曲分类到它所在的情感大类,并在该情感类中找出与自身相似度最高的歌曲列表;最后,根据相似度排序将列表中歌曲对应的标签作为未知标签歌曲的“虚拟”标签。由在“百度音乐掌门人”下载的音乐歌词及其对应的情感标签作为语料进行实验发现,本文提出的基于分类的情感标签推荐可以有效地防止音乐“主类情感漂移”,同时,以“情感词—情感标签”共现的特征降维方法能够更好地提取歌词的情感特征,比传统的“词袋”方法和简单的情感特征词提取方法能够更好的提高分类准确率。
本文的组织结构如下: 第2节介绍相关的技术背景,第3节介绍基于歌词情感相似度的音乐标签推荐方法,第4节介绍本文的实验语料及实验结果,并对结果进行分析,第5节为总结和展望。
2 相关技术
目前,音乐的情感分析主要是通过音频分析来实现,即从音乐自身的曲风、旋律、节奏、音色、强度、频谱质心、能量等来获取音乐的情感信息,Dan Liu等[4]提出了基于GMM的层次化情感检测系统,通过对声音数据的强度、音色和节奏三个特征使用Thayer情感检测模型对音乐片段进行分类。文献[5]也是通过选取音乐的音频特征用SVM进行情感分类。但是,音频信号的研究已有近20 年的历史,至今无法获得准确反映情感的音频特征,所取得的成效非常有限,无法达到满意的水平[2]。因此,越来越多的研究者开始从文本的角度去分析音乐的情感,主要是从歌曲的歌词内容、结构、节奏等角度去分析。文献[6]从歌词文本中提取了182个能够描述心理的特征词,通过机器学习的方法将音乐划分为23个类别。陈若涵等[7]用KNNR、GMM、SVM三类分类方法,通过对歌词中的不同长度的词赋予不同权重来辅助情感分析,将古典音乐和流行音乐分为四种情感。文献[8-10]同时考虑音乐的音频和歌词文本两种信息进行情感分类,但是,由于所选的语料集规模较小,同时,在分析歌词文本信息时,只考虑了简单的基于“词袋”的方法,用TF-IDF计算特征词权重,效果不是特别明显。由于单纯地利用歌词的文本特征分类效果不够理想,清华大学的夏云庆等[2,11]在利用歌词分析音乐情感时,提出了情感向量空间模型的初步设想,在特征定义中以情感单元取代词汇,以情感单元的统计量作为情感特征,使得音乐情感分析取得较明显地提高。
上述研究在进行情感分类时,均采用二维的Thayer情感模型[12]。在分类时,将音乐的情感分为满意(Contentment)、消沉(Depression)、充沛(Exuberance)以及忧伤或狂乱(Anxious)4大类,该模型分类类型过少,导致每一个类型都过于笼统,无法使音乐情感得到恰如其分的描述。本文采用Hevner情感模型,它从音乐学角度提出,考虑歌曲演唱者和听众的心理感受,比Thayer模型更加符合音乐情感的心理交互实际情况。另外,Hevner情感模型将音乐情感分为8大类,比4大情感类的Thayer模型情感分类更加细致。
3 基于歌词情感相似度的标签推荐
3.1 情感空间向量模型
情感空间向量模型以情感词为特征,歌词中的全部情感特征构成高维的空间向量模型,其每一维对应一个情感特征,每一首歌曲对应空间中的一个向量。情感特征的权重计算如式(1)所示,它在传统基于词频的权重计算方法的基础上增加了情感词唱速对情感表达的作用,如果情感词所在的句子平均唱速大于全部歌词的平均唱速,则该情感词对歌曲的情感表达有增强的作用,反之,会减弱歌曲情感表达;如果情感词所在的句子平均唱速等于全部歌词的平均唱速,既不增强也不减弱歌曲的情感表达[12]。
式(1)中,tf(wi)为情感词wi在同一个歌词中出现的次数,eSpeed(wi)表示唱速系数,Speed(wi)取值范围为(-1,1),如式(2)所示。

3.2 “情感词—情感标签”共现的特征降维方法
在歌曲情感描述中,情感标签是用户从自己的角度概括歌曲情感内容的理解与分析,往往能够比较真实地反映用户的情感认知,一首音乐可以被用户标注为多个情感标签,这也符合音乐复杂渐变的情感波动。另外,歌曲的歌词往往简洁明了,直抒胸臆,包含着大量的情感词汇。由此,用户标注的情感标签与歌词中的情感词以歌曲为枢纽,构成了“多对多”的映射关系。如图1所示,上层{t1,t2,t3,…tm-1,tm}表示情感标签集合,中层{s1,s2,…,sk-1,sk}表示歌曲集合,下层{w1,w2,w3,…,wn-1,wn}表示歌词中的情感词集合。情感标签是对音乐的“显性”情感描述,歌词中的情感词蕴涵着音乐的情感信息,是对歌曲情感的“隐性”描述。

图1 情感标签与情感词的“多对多”映射关系图
由于情感标签是用户对歌曲的情感标注,用词规范、简洁,是歌曲情感的浓缩描述,通过对“百度音乐掌门人”中的情感标签进行简单去噪处理,剩余的有意义的情感标签为140个,而歌词中的情感词数目庞大,且包含大量的低频词,传统的特征选择方法容易将其过滤掉,直接影响分类的准确率,本文将低频词通过“共现”方式映射到140维的情感标签特征空间中,从而保留低频的情感词对分类的贡献。图2为将高维的情感词汇映射到低维的情感标签类型。
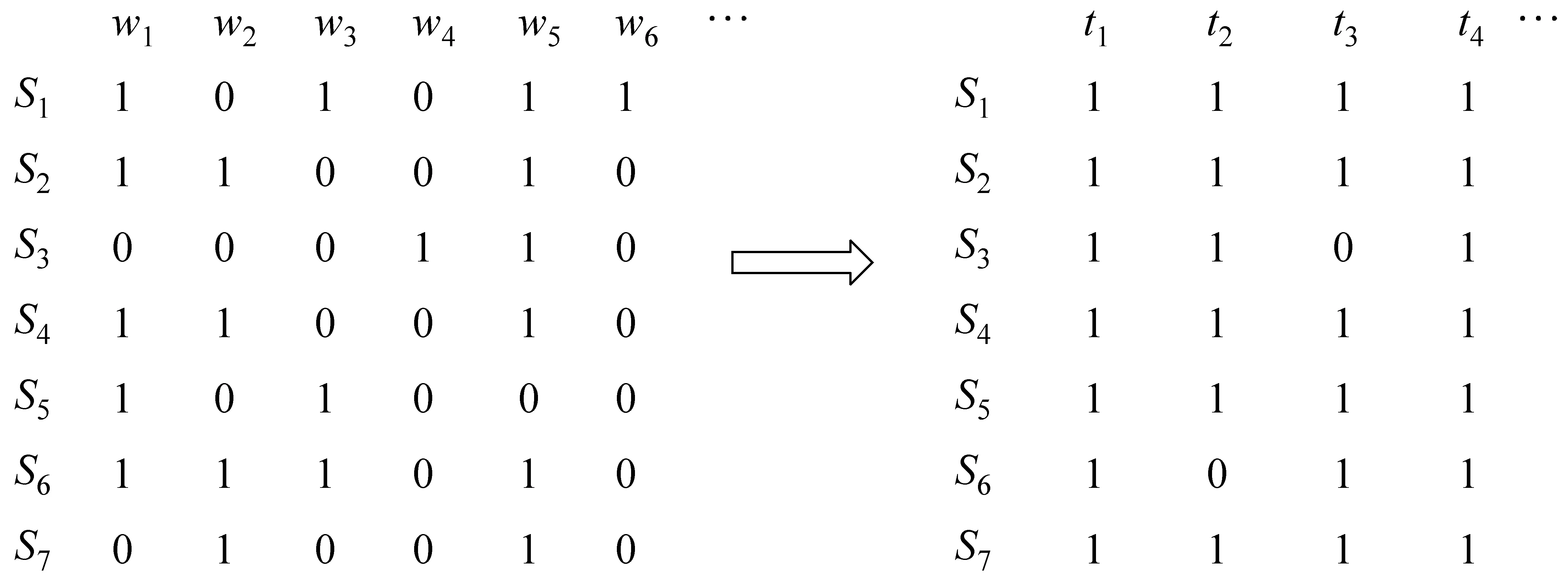
图2 情感词降维过程
“情感词—情感标签”的共现度计算如式(3)所示,其中S(w)表示包含情感词w的歌曲集合,S(t)表示情感标签t所标注的歌曲集合,|S(w)∩S(t)|表示两个集合的交集的大小,即S(w)和S(t)中相同的歌曲数目。|S(w)∪S(t)|表示集合S(w)和S(t)的并集的大小,即共有的歌曲数目。
式(3)仅考虑到情感词与情感标签的共现信息,没有考虑到词频、唱速等因素对歌词情感表达的重要程度不同。式(4)中将情感词的词频、唱速两个因素引入式(4)。
从情感词到情感标签的映射过程中,如果某情感标签与歌曲存在直接标注关系,则该特征的权重为1。反之,权重为歌词中的所有情感词与该情感标签的平均共现度,如式(5)所示。
3.3 标签推荐过程
本文为利用解决新音乐情感标签缺乏的问题,使用典型的基于内容的标签推荐技术,首先,通过计算待推荐歌曲和已知歌曲的歌词情感相似度找到情感最相似的歌曲列表,然后,根据相似度排序选择前M首歌曲将其对应的标签作为新歌曲的“虚拟”标签,从而使得没有标签的新音乐也能够拥有情感标签,进行下一步情感分析。
整个的标签推荐过程如下:
(1) 利用IR情感本体库[13],获取歌词的情感向量;
(2) 利用SVM分类器训练多情感分类模型;
(3) 输入待推荐歌曲的情感空间向量,利用SVM多类分类器去预测该歌曲所属的情感主类;
(4) 采用余弦相似度公式计算待推荐歌曲与所属主类的全部歌曲的相似度;
(5) 对相似度进行排序,取相似度最高的前M1个歌曲作为相近歌曲;
(6) 将相近歌曲的标签根据相似度加权计算,选择前M2个作为候选标签推荐给待推荐歌曲;

在待预测歌曲所属的情感类别中,选择相似度最高的k首音乐(用Mset(si)表示),假设歌曲sk的情感标签集合用Tset(sk)表示,候选标签tj的推荐度为它所在的音乐与未标注歌曲si的相似度之和。如式(7)所示。
4 数据集及实验分析
4.1 数据集
本文选取的数据集是百度音乐掌门人中“音乐情绪”类别下的全部歌曲歌词、情感标签集合。歌曲的情感类别采用Hevner情感模型,将音乐的情感分为8大类,每一首音乐都包含一个主类情感和若干次类情感。表1为Hevner情感环中中英文情感类别的映射。

表1 中英文情感类别的映射
本文将所有歌曲分为表1所示的8大类别,一般研究者对音乐的情感判断主要有两个来源: (1)从研究者自己的角度去进行标注,这个容易导致情感判断的主观性,以及没有公开语料对研究的扩展性和可信度带来的挑战;(2)专家标注,专家的标注是建立在他们严格的专业水平之上,跟普通的用户之间会产生一个明显的“代沟”。文献[1]中提到,2007年ACM任务中提供的专家情感标注跟大众情感判断存在30%的差异。本文利用用户标签去标识歌曲的主类情感,保证了情感标注的客观性。
文献[14]考虑到中西方文化,思维、习惯、历史背景的差异,通过实际调查问卷,将Hevner情感环中的词表从英文转化为中文,词表数目从67减到47,使得所选择的情感形容词更符合中国人的表达习惯。本文将140个情感标签划分到这8大类中,如果情感标签没有出现在Hevner情感词典中,则选择最相似的情感类别,最终这8大类中的情感标签数如表2所示。
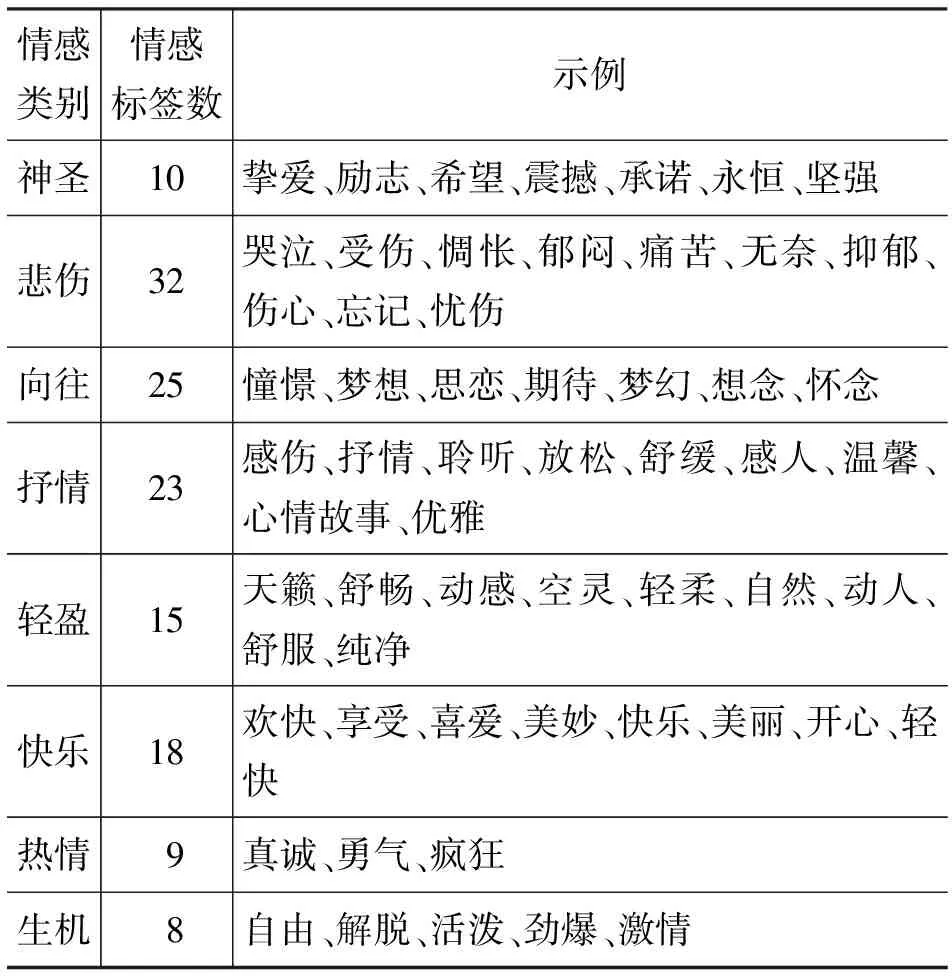
表2 8大类情感包含的标签数
将每一个情感标签都分到一个情感类别之后,可以统计每一首歌曲的情感标签在哪一类中的数量最多,该类为该音乐的情感主类。本文的语料是一个相对平衡的数据集,共包含4 565首中文歌曲,随机地选择其中的3 044首为训练语料,剩余的1 521首为测试语料。
4.2 实验结果分析
本文将实验分为两部分: 分类效果分析和标签预测效果分析,在分类效果分析中,使用的评价指标是子类的准确率;在标签预测效果分析部分,采用的是如式(8)所示的准确率指标。
其中,Tpre表示预测的标签集合,Ts表示实际用户标注的情感标签集合。
4.2.1 分类效果分析
本文设置了如下几个对比方法:
(1) 传统文本向量空间模型w-VSM;
(2) 情感向量空间模型s-VSM;
(3) 基于“情感词—情感标签”共现的特征降维方法Co-s-VSM;
(4) 融合词频和唱速的“情感词—情感标签”共现的特征降维方法WCo-s-VSM;
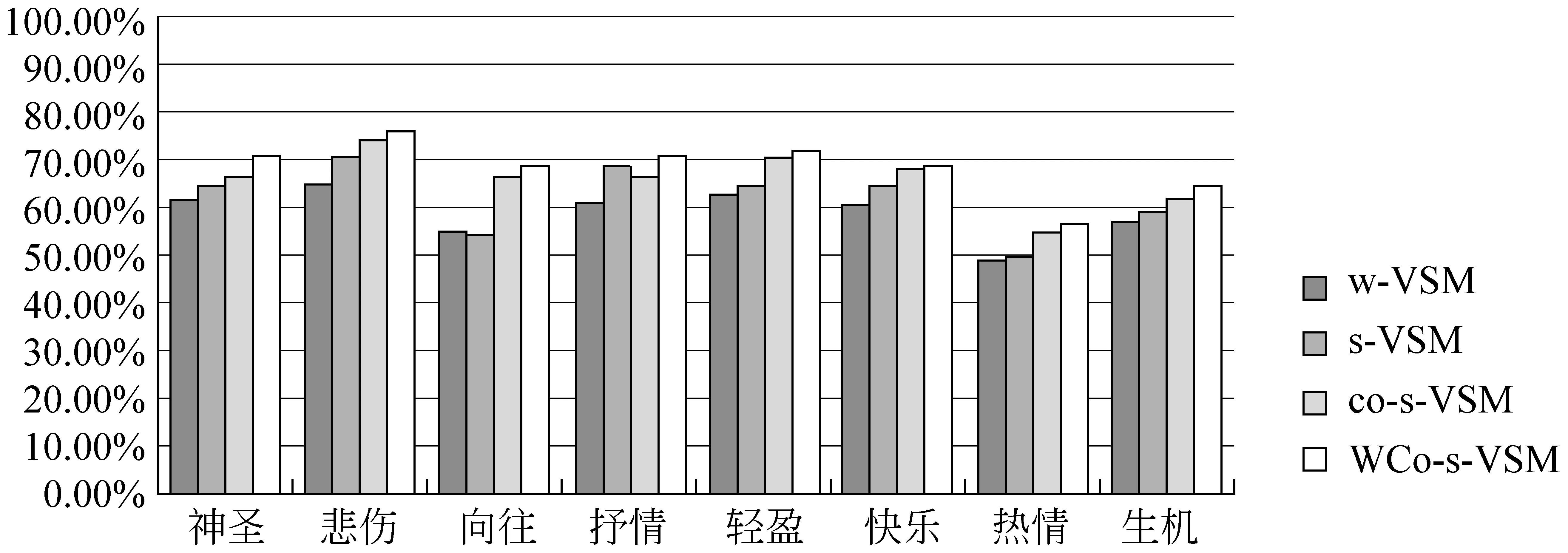
图3 情感子类准确率比较
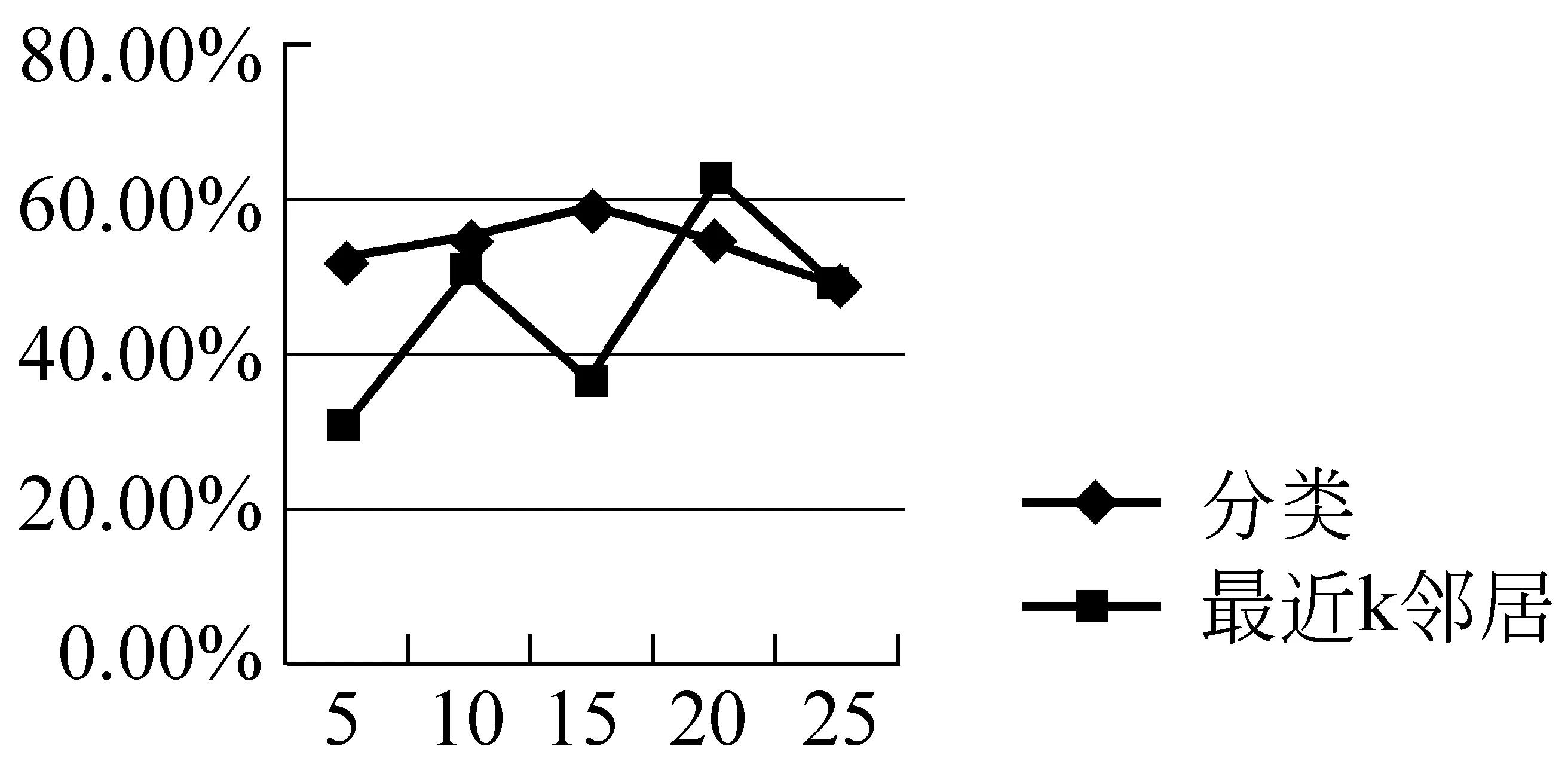
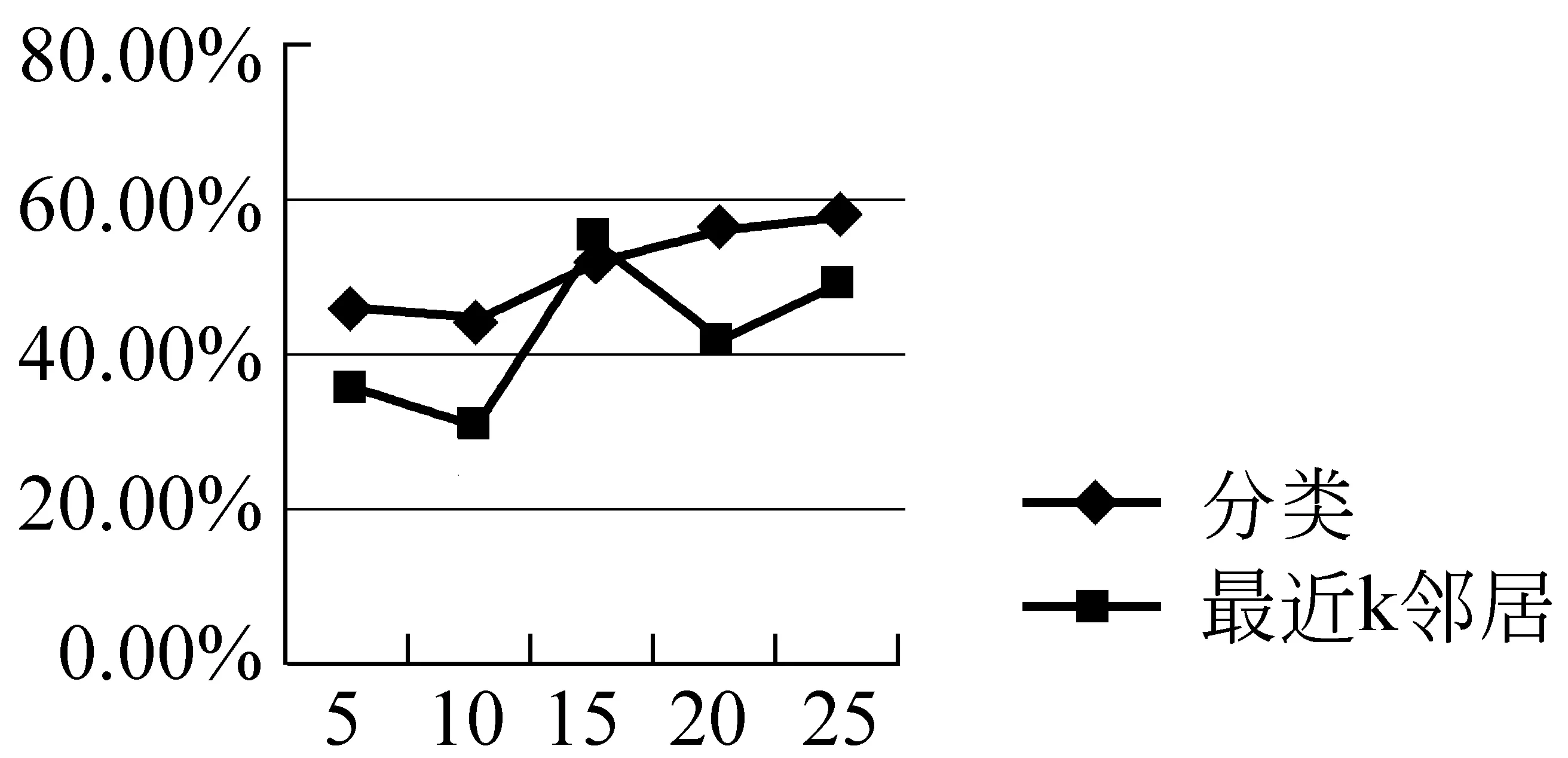
如图3所示,在每一个情感子类的分类准确率基本满足w-VSM 图4 平均准确率比较 图4为在全部数据集上的平均分类准确率,可以看出,满足w-VSM 4.2.2 标签预测效果分析 在本实验阶段,将本文提出的基于分类的标签预测方法与直接最近k邻居法进行比较,图5至图8表示推荐的标签数M分别为3、5、8、10时,最近邻居(歌曲)数目k分别为5、10、15、20、25时,预测的标签准确率。可以看出,本文提出的方法无论M和k取值为多少,基本能够保证基于分类的标签预测方法准确率高于直接最近k邻居法。另外,当M和k取值发生变化时,基于分类的标签预测准确率动荡不大,能够保持相对稳定的状态。直接最近k邻居法得到的相似度较高的歌曲由于分属不同的情感主类,导致进行标签推荐时,发生歌曲“主类情感漂移”,从而影响标签预测的准确率。 图5 M=3时,标签预测的准确率 图6 M=5时,标签预测的准确率 图7 M=8时,标签预测的准确率 图8 M=10时,标签预测的准确率 本文提出一种基于情感向量空间模型的歌曲情感标签预测算法,通过挖掘歌词中包含的情感词及歌词的唱速等音乐情感的“隐形”基因,给一首新音乐去标注一些“虚拟”的情感标签。其贡献主要包括以下三个方面: (1) 提取歌词中的情感特征词,构建情感向量空间模型,能够很好地描述音乐情感,提高情感分类的准确率。 (2) 提出“情感词—情感标签”共现的特征降维方法,在降低维度的情况下,对情感分类效果有所改进。 (3) 提出基于分类的情感标签推荐可以有效地防止音乐“主类情感漂移”。 下一步工作包括两个部分: 对于情感词的提取工作不仅仅依赖于情感词典,要去进一步提取出歌词中常用的“情感启发词”,例如,“黑夜”、“大雨”、“冷冰冰”等能够暗示歌曲情感的词汇。有效融合音频特征和文本特征去分析歌曲的情感,以期实现更好的情感判断。 [1] X. Hu, J. S. Downie, C. Laurier, et al. The 2007 MIREX Audio Music Classification Task: Lessons Learned[C]//Proceedings of the International Conference on Music Information Retrieval, Vienna, Austria,2008:462-467. [2] 夏云庆,杨莹,张鹏洲,等.基于情感向量空间模型的歌词情感分析[J].中文信息学报,2010,1(24):99-103. [3] Hevner K. Expression in music: a discussion of experimental studies and theories[J]. J. Am. J. Psychiatry.1936:246-268. [4] Dan Liu, Lie Lu. Automatic mood detection from acoustic music data[C]//Proceedings of the International Symposium on Music Information Retrieval, Baltimore, MD, USA, 2003: 81-87. [5] Ogihara M. Content based music similarity search and emotion detection[C]//Proceedings of 2004 IEEE International Conference on Acoustics, Speech, and Signal Processing, Montreal, Quebec, Canada, 2004:17-21. [6] Dan Yang, Won-Sook Lee. Music Emotion Identification from Lyrics[C]//Proceedings of 11th IEEE International Symposium on Multimedia, San Diego, Canada, 2009: 624-629. [7] 陈若涵.以音乐内容为基础的情绪分析及辨识[C]//第二届电脑音乐与音讯技术研讨会, 台北, 2006:68-75. [8] D. Yang, W. Lee. Disambiguating music Emotion Using Software Agents[C]//Proceedings of the 5th International Conference on Music Information Retrieval, Barcelona ,Spain, 2004: 52-58. [9] C. Laurier, J. Grivolla , P. Herrera. Multimodal Music Mood Classification Using Audio and Lyrics[C]//Proceedings of the International Conference on Machine Learning and Applications, San Diego, Canada,2008:688-693. [10] Y. H. Yang, Y. C. Lin, H. T. Cheng, et al. Toward multi-modal music emotion classification [C]//Proceedings of Pacific Rim Conference on Multimedia, Tainan,China,2008:70-79. [11] 夏云庆. 歌曲情绪压力分析方法及系统: 中国,200910087827.X[P],2009,11,25. [12] Thayer R. E. The biopsychology of mood and arousal[M]. Oxford University Press, 1989. [13] 徐琳宏,林鸿飞,潘宇,等. 情感词汇本体的构造[J]. 情报学报, 2008, 27(2): 180-185. [14] 孙守迁,王鑫,刘涛,等. 音乐情感的语言值计算模型研究[J]. 北京邮电大学学报. 2006, 11(29): 35-40.


5 结论与展望
