基于区分加权干扰属性投影的语种识别方法
2012-06-29刘伟伟吉立新李邵梅何赞园
刘伟伟,吉立新,李邵梅,何赞园
(解放军信息工程大学 信息工程学院,河南 郑州 450002)
1 前言
语种识别是判别一段语音信号所属语言种类的过程。作为语音识别和其他相关应用的前端处理,语种识别技术在多语种信息服务、多语种机器翻译、军事及安全等领域都有着重要的应用。在语种识别系统处理中,语音信号包含不同信道、说话人及方言等复杂的信息,如何消除和抑制这些因素的影响,是提高系统鲁棒性的关键。
高斯混合模型超矢量—支持向量机(Gaussian Mixture Model Super Vector-Support Vector Machine, GSV-SVM)[1-2]是目前应用最为广泛的语种识别和说话人识别声学模型,针对该模型中训练测试失配的问题,干扰属性投影(Nuisance Attribute Projection, NAP)[3]已做了卓有成效的研究。NAP的基本思想是,利用训练数据估计训练和测试失配子空间,并通过投影去除失配子空间。目前,针对NAP的研究主要局限于去除信道影响方面的应用,且投影矩阵的训练需要繁杂的参数调整和大量的标注语料[4],这些限制导致该方法难以实现,且在投影去除信道影响时会不可避免地删除部分有价值的信息,因此NAP并未得到广泛的应用。
本文提出一种区分加权干扰属性投影(Discriminating Weighted Nuisance Attribute Projection, DWNAP)算法,该算法首先利用各语种训练语音的GSV,统计其协方差矩阵特征值的离散度,用来估计影响语种识别的非语种信息(如信道、说话人、麦克及环境等),即“干扰源”。此干扰源的估计值代表该语种训练语音受“噪声”污染的程度,干扰源大说明该语种的训练语音内包含更多的信道、说话人等语种无关的信息。基于此估计值对不同语种的训练语料进行区分训练,获得理想的投影矩阵。该方法构建了一种更具鲁棒性的语种识别系统失配补偿方案,投影矩阵的训练较为简单,不需要复杂的参数调整和大量的标记语料。实验选取汉语普通话、英语和日语3种语言,测试结果表明本文提出的方法能够有效地提升系统性能,且大大简化了训练的过程。
本文的结构组织如下: 第2节介绍了NAP的基本知识;第3节详细分析了干扰源的估计及区分加权方案;第4节是实验及结果分析,最后给出了本文的结论。
2 干扰属性投影
NAP的基本思想就是减少信道、说话人、麦克或其他变量对语种识别的影响。其思想是基于如下假设: 在SVM扩展后的核函数高维空间中,信道等干扰因子的影响存在于一个较低维的一个子空间中,如果能够找到一个投影方向,使得观测信号能够经过投影去除这部分干扰,那么投影后的特征就不会再受这些干扰的影响[5]。从而,NAP构建了一个新的核函数,如式(1)所示。
(2)
其中xi,xj为训练语音的GSV,权重wij有几种不同的取值方式[5-7]。式(2)的最优化过程可以演变成一个求取矩阵特征值和特征向量的问题[8]。
式(1)中的wi=Avi,vi是式(3)中第i大的特征值对应的特征向量,将所有特征值进行排序选取前c个对应的特征向量,用于干扰子空间的估计。A=[φ(x1),φ(x2),…,φ(xn)],1是一个全1的列向量。
2.1 权重矩阵
针对语种识别,权重矩阵W一般为下面几个小矩阵的和:
其中ch(·)表示信道标签,spk(·)表示说话人标签,lang(·)表示语种标签。(wch)ij表示将不同信道的语音拉近,减少信道影响,(wspk)ij表示把相同语种不同说话人的语音聚集在较近的空间上,(wlang)ij表示将同一语种的数据拉近。权重矩阵W由如下形式表示式(7):
文献[8]通过实验得到当(α,β,γ)=(0,0,1)时,系统性能最好,即在权重矩阵中仅考虑了语音的语种信息,而未考虑信道及说话人信息,因此该加权方案并未取得非常理想的效果。分析其仅考虑语种信息的原因,是因为若要考虑信道及说话人信息,此加权方案就会出现将不同语种的语音进行拉近的情况,因此(α,β,γ)=(0,0,1)时性能相对最优。但是只考虑语种信息,就会出现这样的情况,即同一语种的两段语音不管是否来自同一信道或说话人都采取了相同的权重。事实上,当两段相同语种的语音来自不同说话人或信道时应该去除掉更多语种无关的因素将它们拉近,即在优化算法中应该增加其权重。因此,该加权方案不能充分考虑语音的语种、信道及说话人信息。
2.2 投影秩
投影秩是干扰因子所在子空间的估计维度,即从式(3)中选取的特征向量个数。投影秩在一定范围内变化时,系统错误率会随之增加而明显下降,但超过一定的范围后错误率就会随之增加而增加。这是因为投影秩太小将不能完全估计出干扰子空间,而过大则可能将部分有价值的信息给去除掉,因此选取合适的投影秩特别重要。恰当的投影秩应当根据所给的数据集来选定,它决定于训练与测试的失配程度及系统配置参数,如果SVM的扩展空间在10 000左右,投影秩一般不会超过几百[5]。目前,大部分的说话人系统采用的投影秩在64至128之间[5,6,9],文献[10]中的语种识别系统选取2 048个混元,56维的SDC,实验结果表明投影秩选择128识别性能最佳。
3 区分加权干扰属性投影
不同的信道及说话人会导致相同语种不同语音之间的变化,这会引起语种识别系统性能的下降。NAP可以有效补偿这种训练测试失配,但传统NAP的训练需要大量包含信道、说话人等标记信息的语料,这在实际中很难得到,因此限制了该方法的应用。本文即是寻找一种方法能够对未标记的语料进行干扰源量化估计,然后针对干扰源的不同有区分地利用训练语料,计算出干扰子空间,从而补偿由干扰源导致的训练和测试失配问题。
3.1 干扰源的估计
文献[11]提出了一种简化的本征信道子空间估计方法,其本征信道与本文的干扰源属于同一概念,都是估计的干扰信息。借鉴其思想和估计方法本文利用协方差矩阵的特征值量化估计干扰源。协方差矩阵的特征值能量越分散,说明该语音集受到的语种无关信息越杂越多,即其中包含的干扰越多,特征值能量越集中,说明该语音集越纯净,所受的干扰越少。
首先通过式(8)求出协方差矩阵的特征值:
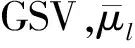
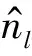
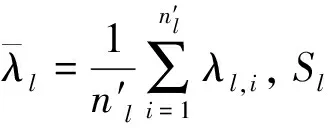
3.2 区分加权干扰属性投影(DWNAP)
3.1节已经提出用语音特征值的离散度估计干扰源。现在,将这种方法引入NAP投影矩阵的设计准则里,用来区分加权不同特性的各语种训练语料。
为了得到适当的加权值,对各语种的干扰源估计值做式(11)的规整处理:
为了验证特征值离散度的大小能否用于估计干扰源,用汉语和英语进行试验。首先选择一人(男)单独在实验室环境下录制了不同内容的100段30s的电话信道汉语语音,此汉语集用“汉pure”表示;另外选取15男10女分别在实验室和马路环境,用电话和录音麦克各录制一条30秒的汉语(内容不同),此汉语集用“汉mix”表示共100段。选择不同的人用同样的方式录制英语,得到“英pure”和“英mix”。
分别计算4个语音集的规整干扰源估计值,如图1所示。

图1 各语音集规整的干扰源估计值
由图1可以看出跨说话人、跨信道的语音集规整的干扰源估计值,远远大于单一说话人、单一信道的语音集,此结果证明该估计值可以用来表征干扰源的大小。
由式(11)可以看出各语种规整干扰源的均值应该为1。所以如果某语种的该规整值大于1,说明该语种的训练语音内包含的非语种信息过多,即干扰源较大,在投影矩阵的训练中应该对其重视,增加其在优化方程里的权重将其拉近;如果该值小于1,说明语种的训练语音比较纯净,未包含太多说话人及信道等非语种信息,因此在优化过程中无需给予太大的权重。利用规整的噪声源估计值作为NAP投影矩阵设计准则里的权重。
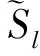
本文提出的DWNAP也会存在信息损失的问题,但DWNAP能够根据每个语种训练语音的特性进行区分性训练,更为重要的是,DWNAP权重的获取是自动计算的,而非传统的NAP,需要复杂的参数调整过程和大量的信息标注。
利用式(12)所给的权重矩阵解决式(3),
其中矩阵A=[φ(x1),φ(x2),…,φ(xn)],W是由wi,j组成的权重矩阵,1是一个纯1的列向量。为了简化问题,假定只有一个训练语种l,有nl条训练语音。则有式(14):
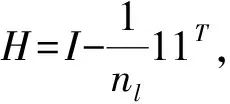
由于AHAT=(AH)(AH)T,则可得
其中(AH)(AH)T为A=[φ(xl,1),φ(xl,2),…,φ(xl,nl)]的自相关,即
其中ηl是该语种所有训练语音的平均矢量。进一步将式(17)转化为式(18):
推广到多个语种即为:
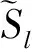
4 实验配置及实验结果
语种识别分为语种辨认和语种确认,鉴于当前国内外语种识别研究机构的研究对象,以及美国国家标准技术署(National Institute of Standard and Technology, NIST)所组织的语种评测均为语种确认,故本文进行语种确认实验。
4.1 数据选择及评价标准
语料库为实验室采集的电话信道通话语音,含汉语普通话、英语和日语三个语种,共有4 600段30s的语音以及300段5min左右的长时语音。语音信号的采样频率为8KHz,并经过16bit量化处理。30s语料中,有汉语1 800段(男女各900段)、英语1 250段(男600段,女650段)、日语1 550段(男850段,女700段)。5min长时语料中,每个语种有100段话音(男女各50段)。上述语音段中所含的说话人均不相同,且每段语音仅含一个说话人。实验采用30s的语音进行训练和测试,从各语种中挑选600段(每个语种男女各300段)用于训练高斯混合数为512的UBM模型。100段5min的英语,每段剪出5段30s长的语音,共500段,同样方式剪出500段30s长的日语,另外在实验室环境下录制的500段电话信道汉语(3男2女每人100段30s的汉语),利用这些语料训练NAP。从30s的语音中为每个语种挑选200段语音(男女各100段)作为SVM的训练语料,剩余语料有汉语1 000段,英语450段及日语750段将其作为测试语音。
本文采用检测错误折中(Detection Error Tradeoff, DET)曲线、等错误率(Equal Error Rate, EER)来衡量语种识别系统的性能。
4.2 系统描述
本文的特征参数是MFCC及SDC[12](7-1-3-7),共56维,前端预加重系数选为0.97,帧长25ms,帧移10ms。利用VAD算法[13]去除静音帧,同时通过CMS[14]去除倒谱域的卷积噪声。GMM混合高斯数选择512,SVM算法采用的是中国台湾林智仁教授开发的LibSVM[15]工具包,SVM核函数采用的是Kullback-Leibler核函数(K-L核)[16],传统NAP中(α,β,γ)=(0,0,1)。
为评价本文所提算法的识别性能,共搭建了3个语种识别系统,分别是: 未加任何补偿措施的GSV-SVM语种确认系统、基于传统NAP的GSV-SVM语种确认系统和基于DWNAP的GSV-SVM语种确认系统,通过比对这3个系统的性能以验证本文所提DWNAP方法的有效性。
4.3 实验结果
首先考察各种NAP投影秩的最优值,图2给出了实验结果。

图2 各投影秩对应的系统EER
由图2可以看出随着投影秩的增加,两种方法的识别性能都有所提升,但当投影秩超过64以后两种方法的性能均开始下降,即在投影秩为64时,性能达到最优。
图3为上述3个语种识别系统的DET曲线图,其中NAP和DWNAP投影秩为64。

图3 各系统DET曲线图
表1给出了投影秩为64时各系统的EER。

表1 各系统的EER/%对比表
由图3和表1可以看出,相对于基线系统GSV-SVM,传统NAP及DWNAP的系统性能均有提升,EER分别相对降低了约10.75%和17.46%。相对于传统NAP,本文提出的DWNAP的EER较其降低了7.51%。
综上所述,本文提出的区分加权干扰属性投影去除了更多的干扰因子,且NAP的训练过程得到了简化,不再需要繁杂的参数调整和大量的标注语料,有效地提升了系统的识别性能。
5 结论
本文针对GSV-SVM语种识别系统训练测试失配问题,提出了一种区分加权干扰属性投影算法。这种算法通过利用各语种训练语音特征值的离散度量化估计干扰源,然后利用规整的干扰源估计值,作为各语种训练语音在投影矩阵训练中的权重。本文所提的方法简化了参数的自适应过程,构建了一种更具鲁棒性的失配补偿方案。实验结果表明,本文所提的DWNAP比传统的NAP表现出了良好的优越性。
[1] V. Wan, W. M. Campbell. Support vector machines for speaker verification and identification.[C]//Procedings of Neural Netw. Signal Proces. 2000:775-784.
[2] W. M. Campell, E. Singer, P. A. Torres-Carrasquillo, et al. Language recognition with support vector machines[C]//Proceedings of IEEE Odyssey: The Speaker and Language Recognition Workshop Toledo, Spain, 2004: 41-44.
[3] W. Campbell, D. Sturim, P. Torres-Carrasquillo, et al. A Comparison of Subspace Feature-Domain Methods for Language Recognition[C]//Proceedings Interspeech, 2008: 309-312.
[4] A. Solomonoff, W. M. Campbell. Advances in channel compensation for SVM speaker recognition[C]//Proceedings of ICASSP, 2005:629-632.
[5] A. Solomonoff, W. M. Campbell. Channel compensation for SVM speaker recognition[C]//Proceedings of Odyssey, Speaker Lang. Recognition Workshop, 2004:57-62.
[6] Alex Solomonoff, W. M. CamPbell, Ian Boardrnan. Advances in channel compensation for svm speaker recognition[C]//Procedings of ICASSP. 2005(l):629-632.
[7] R. Vogt, S. Kajarekar, S. Sdridharan. Discriminant NAP for SVM speaker recognition[C]//Proceedings of Odyssey, 2008.
[8] 雷文辉. 基于支持向量机的语种识别研究[D].中国科学技术大学硕士学位论文.2009,5.
[9] W. M. CamPbell, D. E. Sturim,D. A. Reynolds, et al. SVM based speaker verifieation using a gmm supervector kemel and nap variability[C]//Proceedings of ICASSP. 2006(1): 97-100.
[10] Torres-carrasquillo P A, Singer E, Campbell W, et al. The MITLL NIST LRE 2007 Language Recognition System[C]//Proceedings of Interspeech. 2008: 719-722.
[11] Matejka P. Phonotatic and Acoustic Language Recognition[D]. Brno: Brno University of Technology, 2008.
[12] 姜洪臣, 郑榕, 张树武, 等. 基于SDC特征和GMM-UBM模型的自动语种识别[J]. 中文信息学报, 2007,21(1):49-53.
[13] L. Lamel, L. Labiner, A. Rosenberg, et al. An Improved Endpoint Detector for Isolated Word Recognition[C]//Proceedings of IEEE Transactions on Acoustics,Speech,and Signal Processing,Aug 1981,29(4): 777-785.
[14] Douglas A.Reynolds,Thomas F.Quatieri, Roberr B.Dunn.Speaker verification using adapted Gaussian mixture models[J].Digital Signal Processing,Jan.2000,10: 19-41.
[15] C. Lin. LIBSVM: a library for support vector machines [EB/OL.]2010-12-14. http://www.csic.ntu.tw/cjlin/libsvm/index.html. 2010.
[16] PedroJ. Moreno, Purdy P. Ho, Nuno Vasconcelos. A Kullback-Leibler divergence based kernel for SVM classification in multimedia applications[J]. in Adv. in Neural Inf.Procedings Systems 16,S.Thrun,L.Saul, and B.Schölkopf,Eds. MIT Press,Cambridge,MA,2004.
