多源域分布下优化权重的迁移学习Boosting方法
2023-06-07李赟波王士同
李赟波,王士同
1.江南大学 人工智能与计算机学院,江苏 无锡214122
2.江南大学 江苏省物联网应用技术重点建设实验室,江苏 无锡214122
迁移学习是为了解决源域与目标域数据空间分布不一致情况下,从源域中抽取有用的知识训练模型。因其可以在目标域训练数据不完备的情况下从源域迁移获取知识,减少了获取标注目标域数据的成本。近年来,迁移学习在各个领域都有着高度的关注与广泛的应用[1]。当一组数据很容易过时,可能会出现迁移学习的需求。在这种情况下,在一个时间段内获得的标记数据在以后的时间段内可能不会遵循相同的分布[2]。此外,在目标域没有标注或者标注目标域数据代价高昂的情况下,迁移学习可以节省大量的标记工作[3]。
在迁移学习中,Liu等人[4]提出了一种Butterfly学习框架,该框架同时使用四个深度学习网络,其中两个负责所有域的适应工作,剩下的两个专门负责目标域的分类。Wang 等人[5]给出了负迁移的定义,并提出了一种形式化的避免负迁移的方法。Scott[6]提出了一种新的可以强化领域适配表现的度量方法。Tokuoka 等人[7]提出了一种归纳迁移学习方法,通过基于Cycle-GAN(cycle-consistent generative adversarial networks)的无监督域适应使源域样本的注释标签应用于目标域数据样例上。Bucci等人[8]提出了一种以监督方式学习语义标签的模型,并使用相同图像自监督信号拓宽对数据的理解。Moreno-Muñoz 等人[9]提出了一个基于模块化变分高斯过程迁移学习框架,可以在不重新访问任何数据的情况下,构建集成变分高斯GP(Gaussian processes)模型。
Boosting方法在迁移学习中较为常见,通过多次迭代训练多个弱分类器从而集成输出为一个强分类器[10]。Zhang等人[11]提出了一种新的加权技术,生成具有加权源域和目标域实例的加权合成实例。Schapire等人[12]提出了经典的AdaBoost(adaptive Boost)算法,在每一次迭代训练过程中,分类错误的样本权重或提高。更新权重过后的样本会用于下一个基分类器的训练。Cortes 等人[13]提出了一种新的集成学习算法DeepBoost,它可以使用包含深度决策树或其他丰富或复杂的家族成员的假设集作为基分类器,并在不过度拟合数据的情况下获得较高的精度。Dai 等人[14]提出了TrAdaBoost(adaptive Boosting for transfer learning)算法,该算法对于分布不一致的训练数据做了优化,可以自动调整训练样本的权重,利用Boosting来区分分布不一致的训练数据。但由于假设的固定性和高复杂度,TrAdaBoost 存在过拟合的问题,在迁移学习的场景下可能拟合与目标域分布不一致的源域数据。为了弥补这一缺陷,Jiang 等人[15]提出了DTrBoost(deep decision tree transfer Boosting)算法,该方法根据Rademacher复杂度最小化源域和目标域的数据依赖学习边界来学习并分配给基础学习者,这保证了该算法可以在不过度拟合的情况下学习深度决策树。周晶雨等人[16]提出了一种可以在源域和目标域的特征空间中过采样的多源在线迁移学习算法,使用类别分布较为平衡的源域数据训练分类器,从而提升精度。徐光生等人[17]提出了一种借助具有完整模态的辅助数据集,通过跨模态或跨数据集方向的迁移学习来帮助模态或数据集之间的数据对齐,从而实现更好的分类效果。林佳伟等人[18]提出一种对抗域适应深度对抗重构分类网络的迁移学习模型(deep adversarial reconstruction classification networks,DARCN)。DARCN 借鉴了自动编码器的思想,在对抗域适应的基础上,增加了自动解码器的解码部分,因此可以提高从低维度特征重建原数据的效率。在实践中,对于某数据集的数据按照某一或某些特征划分出来的数据往往分布不一致。并且这些不同分布的数据对于最终模型的重要性也不一致,知识迁移的权重也因此不平等。这就导致了学习的模型收敛速度的下降,同时也导致了学习过程中的振荡。并且DtrBoost 算法对多源域迁移学习情况适应性不强,在多源域数据情况下不能很好地完成分类任务。
因此,本文提出了一种针对多源域不同分布数据的优化样本权重迁移学习算法。该算法使用KL距离(Kullback-Leibler divergence)[19]衡量源域与目标域的距离计算目标函数的源域权重,从而增强相似的源域目标函数权重,减少分布距离较大的源域目标函数权重,将源域分配不同的学习权重可以减小梯度方向的振荡,加快收敛速度。同时将不同的学习权重赋予不同的源域,使算法适应多源域迁移学习。之后,由目标函数导出梯度函数,根据梯度下降最快的方向确定本批次的最佳梯度,并与之前的学习梯度进行对比确定最优基分类器,并更新最优基分类器权重。完成了最优基分类器后按照源域与目标域不同的分布特点,对所有的训练样本进行权重更新。
1 迁移学习简介
本章简要介绍单源域迁移学习算法DtrBoost,DeepBoost 提出了基于Rademacher 复杂度[20]的基分类器集的凸集学习边界。DTrBoost在不同迭代时从源域数据和目标域数据中学习不同复杂度的假设族,并对较低复杂度的假设族分配更多的权值,以避免过拟合。
对于不同的假设集合hj,j∈[1,2,…,N]。{h1,h2,…,hj,…,hN}是一组不同的假设,FW是源域和目标域中数据梯度的损失函数,FS为目标域内数据梯度的损失函数。具体计算如下:
其中,αt,j为假设j在第t次迭代中的基分类器权重,Φ是一个非递增的凸函数。式(1)、式(2)中的第二部分是假设Rademacher 复杂度的正则化,其中λ和β为参数。是标准的Rademacher 复杂度。d(ht)表示ht所属的假设集的索引,即接下来就是训练的目标函数,目的是最小化FW与FS在ej方向上的梯度差值。
在第t次迭代中,通过式(4)梯度增强函数选择一个新的函数ht(xi,at)作为当前最优的假设。
其中,ft←ft-1+αtht(x,at)。分别是FW与FS在ej方向上的导数。然后开始迭代训练,在每一个迭代次序内计算目标域的梯度值为:
上述算法只能从一个源域中学习知识转移到目标域中,在多个源域的情况下缺乏适应性。下面介绍一种新的多源迁移算法,可以从不同分布的多个源域中按分布相似程度确定知识重要性,增加相似源域样本权重,减少其余样本权重,从而减少分类的错误率。
2 多源域分布下的迁移学习
2.1 问题描述
在具有多个源域的迁移学习场景中,设X=XS⋃Xd1⋃Xd2⋃…⋃Xdp为实例空间,其中XS为目标域实例空间,Xdp为p个分布不同的源域实例空间。源域的数据空间为Xdk×Ydk,其中1 ≤k≤p。目标域的数据空间为Xs×Ys,其中,源域与目标域使用相同的数据标签空间Ydk=Ys=Y={-1,+1}。测试数据是与目标域同分布的数据,记为Q。设q是将X映射到Y的布尔函数,将训练数据L={X×Y} 分成,Ldk为不同源域上的训练数据空间,Ls为目标域的训练数据空间。
因此,在给定少量带标记的目标域训练数据Ls和大量带标记的p个源域训练数据Ld1,Ld2,…,Ldp的情况下,本文的目标是学习一个布尔函数q从X到Y,使测试集数据的预测误差值最小化。
源域的训练数据来自p个不同的分布,如果将p个源域数据合并视为一个源域,在计算全局梯度的时候,不同源域上的知识重要程度是同等的。然而实际的数据相似程度并不一致,会导致相似程度较小的源域知识也同等学习。考虑到源域的相似程度,按照相应的权重学习不同源域的知识,提高相似源域的学习权重,减少相似程度较小源域的学习权重,从而获得更高的测试精度。
2.2 多源域分配权重的Boosting迁移学习
本节提出一种称为MtrBoost(multi-source decision tree transfer Boosting)的算法,该算法通过赋予不同源域不同的学习权重计算全局梯度从而提升目标域决策函数的精确度。
首先计算KL距离式(7),根据源域的KL距离确定两个源域的相似程度。计算距离的统计函数还有很多,例如Jen-sen Shannon 距离、Hellinger 等距离。只要计算距离的统计函数是凸函数且是一个闭函数,都可以用来衡量数据分布情况[21]。但这两种距离都具有上界,KL距离没有上界,在数值上可以更为直观地表达数据分布情况。通常情况下[13-15],迁移学习中较为普遍地使用KL距离衡量数据分布情况,因此本文也选择KL距离确定源域与目标域的相似程度。
其中,Ld(x)是源域上的样本,Ls(x)是目标域样本。分别计算出源域Ld1,Ld2,…,Ldp到目标域对应的KL距离为KLd1,KLd2,…,KLdp,之后根据式(8)计算出对应的学习权重ω1,ω2,…,ωp。式(8)可以根据这p个源域KL距离的大小分配对应的权重,并且满足ω1+ω2+…+ωp=1的约束。
其中,1 ≤j≤p,ωj表示第j个源域的学习权重。H={h1,h2,…,hj,…,hN}是N个不同的假设的集合。Qdk是第k个源域上的损失函数,Qta是目标域上的损失函数。
其中,n为目标域训练集Ls上的实例数目,mk为源域训练集上第k个源域的实例数目,w(k)=n+m1+m2+…+mk-1为第k个源域样本起始位置的映射函数。xi是输入的实例,且i∈{1,2,…,n,…,n+m1,…,n+m1+…+mp},yi是xi真实类别。t∈{1,2,…,T}是迭代训练的次数。ht(xi,bt)是在第t次迭代时的假设,bt是假设的参数,包括最佳分割特征、剪枝节点位置。τt是假设ht的权重。ψ是非增凸函数,与DtrBoost一致,这里选择指数函数。式(9)、式(10)的第二部分是正则化后的Rademacher复杂度,rt=,其中f(ht)是将假设ht映射到该假设下标,σ、γ是参数。
在得到了源域与目标域的损失函数后,在源域与目标域总体上的全局损失函数如下:
式(11)中,在源域与目标域的损失函数上增加了对应的权重,从而强调了目标域的损失。通常情况下目标域的样本重要程度大于各个源域,各源域的样本重要程度相对一致。因此本文对于源域分配一定系数后,各源域平均分配剩下的系数,使得各源域与目标域系数和为1。本文参考DtrBoost算法,为了保持计算量纲的一致且便于后续的收敛性分析,对目标域赋予0.5 的系数,剩下的多个源域平均分配0.5 的系数。对于各个不同的源域也按照KL 距离分别赋予权重,由此可以得到目标函数。
对于全部的样本,使用式(11)进行学习,在方向μj上的导数可以通过式(13)计算得到。
至此,在经过了t次迭代后,假设集合更新为H={h1,h2,…,hj,…,hN},其中N≤t≤T。之后,计算目标域的梯度导数,在每次的迭代计算过程中,计算在μj方向上的导数,计算步骤与计算全局样本上的梯度大小一致。
在搜索到最佳学习者hl后,对hl的权重进行更新。基本的更新学习者权重思路是每次迭代仅更新当前搜索到的最佳学习者hl,并增加hl的权重,其他学习者的权重保持不变,更新公式如下:
式中,ηt是DtrBoost中提出的步长,可用线性方法计算[15]。在迭代过程的最后阶段,对所有的样本权重进行更新,更新公式与DtrBoost 一致[15],增加目标域中相同分布的样本权重,减少源域中不同分布的样本权重。目标域样本权重更新公式如下:
各源域样本的更新公式如下:
决策函数只使用了T/2 次迭代之后的分类器权重,在T/2 次迭代之前,源域中不同分布的数据的权重没有减少到非常小的数量。与目标域学习梯度方向相比,它将在很大程度上阻碍学习相同的梯度方向。因此,使用T/2 次迭代后的分类器权重可以提高决策函数输出的准确性。多源域优化权重的迁移学习框架如图1所示,在这里展示的是两个源域迁移情况下前4 个迭代过程,分类器数目为3。三角形样本为目标域样本,菱形与正方形表示两个源域的样本,样本的大小表示权重的大小。每次迭代后,都会增加错误分类的目标域数据的权重,降低错误分类的源域数据的权重。在下一轮迭代学习时,目标域的错误分类的样本权重增加会使得分类器的权重错误率增加,模型在选择最佳分类器的时候会选择对该样本分类情况更好的分类器。相反的,降低错误分类的源域数据的权重,使得模型选择最佳分类器的时候降低对于源域分类错误的情况的考察,从而变相地提高了目标域分类情况的重要性。基于这两个样本权重更新策略,MtrBoost算法可以逐步地提高目标域的分类准确性。
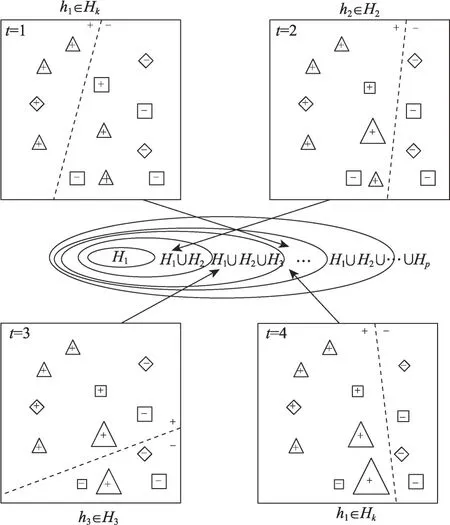
图1 多源域优化权重的迁移学习框架Fig. 1 Multi-source weight optimization transfer learning framework
下面论证本文提出的MtrBoost 算法的收敛性,DtrBoost算法是个单源域的迁移学习框架,而MtrBoost算法是一个多源域的迁移学习模型。
2.3 MtrBoost算法描述
算法1MtrBoost算法
算法的过程可以分为两部分:第一部分是步骤1处的基分类器的迭代训练过程,该部分算法时间复杂度记为T1(n)。第二部分是步骤2 处的决策函数的集成输出过程,该部分算法时间复杂度记为T2(n)。在第一个训练过程中又可以分为分类器训练和训练样本权重更新两个小的步骤,分别位于步骤1.1至步骤1.3,步骤1.4 至步骤1.6。这两个步骤时间复杂度分别记为T1.1(n)、T1.2(n)。设目标域训练集Ls的样本数目为n,源域训练集Ld1,Ld2,…,Ldp的样本数目分别为m1,m2,…,mp,训练批次数目为M,分类器集合数目为N。
3 实验及数据分析
本章对本文提出的算法与基线算法进行性能比较,在多个数据集上进行实验。为了使实验结果客观公正,本章实验评价指标均为进行10 次实验后的平均值。结果表明,本文算法性能优于对比算法。
3.1 数据集简介
本文在9个数据集上进行了测试,前4个数据集来自UCI 数据集网站(https://archive.ics.uci.edu/ml/datasets),后5个数据集来自Kaggle数据网站(https://www.kaggle.com/datasets)。如表1 所示,表中涵盖了数据集特征数、训练样本数、测试样本数。因每个数据集按照类别分类下来的数据样本数目各不相同,为保证从各个类别抽取的总体数据样本数目大体一致,针对不同数据集不同类别设计了不同的抽取比例。
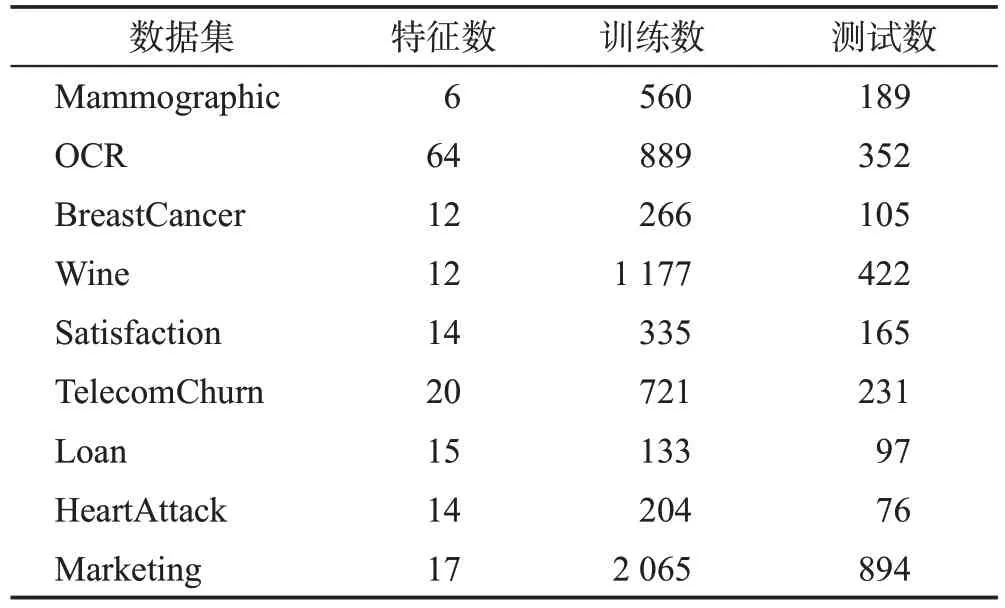
表1 UCI和Kaggle的9个数据集Table 1 Details of 9 datasets for UCI and Kaggle
Mammographic是一个多元多变量乳腺X射线数据集,由埃尔兰根纽伦堡大学放射性研究中心在2003 年至2008 年间采集。该数据集包含了两类标签,将恶性肿瘤样本设置为阳性标签,良性肿瘤设置为阴性标签。每一个特征域都包含多个离散类别信息。根据肿块的形状特征的类别情况分为3类,依次分别从3类里抽取50%、25%、15%的样本,抽取25%、50%、15%的样本,抽取25%、25%、70%的样本构成1个目标域与2个源域。
OCR是一个0到9手写数字的图片数据集,原图像大小尺寸为32×32像素,通过划分为64个4×4像素的图像块进行降维得到8×8 像素的图像。每个像素特征是0到16的整型灰度信息。根据手写数字的形状特征,抽取50%的数字8样本与20%的数字6、25%的数字9样本作为目标域。抽取60%的数字6样本与数字8、9 各25%的样本作为第一个源域。抽取50%的数字9样本与20%的数字6、25%的数字8样本作为第二个源域。
BreastCancer 数据集的特征是根据乳房肿块的细针穿刺(fine needle aspiration,FNA)的数字化图像计算得出的,它们描述了图像中存在的细胞核的特征,从而使得图片信息降维成12 个维度的多变量分类信息。将每个样本的灰度值的标准偏差作为特征域纹理特征,从低到高分为3个等级。根据这3个等级,分别从3 类里抽取50%、25%、25%的样本,抽取25%、50%、25%的样本,抽取25%、25%、50%的样本构成1个目标域与2个源域。
Wine 数据集是红酒品质的分类数据集,包括红酒的固定酸度、残糖、酒精度等信息。根据酒精度的高低,依次设置3 个分界点9.5、10.2、11.2,将红酒分为4 个等级。红酒的评分以6 为界线,大于6 分为阳性样例,反之为阴性样例。根据这4个等级,分别从4类里抽取55%、15%、15%、20%的样本,抽取15%、55%、15%、20%的样本,抽取15%、15%、55%、20%的样本,抽取15%、15%、15%、40%的样本构成1个目标域与3个源域。
Satisfaction 是一个部门员工对职业满意度的调查统计数据集。该数据集包含员工薪资、部门、学历、是否对工作满意等信息。根据职工的部门不同划分为4类。根据这4个类别,分别从4类里抽取46%、13%、18%、18%的样本,抽取18%、61%、18%、18%的样本,抽取18%、13%、46%、18%的样本,抽取18%、13%、18%、46%的样本构成1个目标域与3个源域。
TelecomChurn 是一个电信用户流失信息数据集。该数据集包含客户地区、客户通话时间、电话推销次数等信息。选择累计通话1、2、6、7 次的客户作为4 个类别。根据这4 个类别,分别从4 类里抽取40%、20%、20%、20%的样本,抽取20%、40%、20%、20%的样本,抽取20%、20%、40%、20%的样本,抽取20%、20%、20%、40%的样本构成1 个目标域与3 个源域。
Loan数据集是一个银行对于客户贷款业务信息的记录,这些详细信息包括性别、工作类别、婚姻状况、教育、家属人数、收入、贷款金额、信用记录、是否通过贷款申请等。将通过贷款申请作为阳性标签,未通过贷款申请记为阴性。根据家属人数情况,将数据集按照家属人数递减顺序依次划分为3类,依次分别从3类里抽取40%、30%、20%的样本,抽取30%、40%、20%的样本,抽取30%、30%、60%的样本构成1个目标域与2个源域。
HeartAttack 数据集记录了患者的身体状况信息,包括年龄、性别、最大心率、血压、胸痛类型,并记录了患者心脏发作次数情况。将发作高频度记为阳性标签,低频段记为阴性。根据胸痛类型划分为典型心绞痛、非典型心绞痛、非心绞痛3 个样本类别。依次分别从3 类里抽取50%、25%、25%的样本,抽取25%、50%、25%的样本,抽取25%、25%、50%的样本构成1个目标域与2个源域。
Marketing 是一个营销情况数据集,记录了客户年龄、婚姻、职业、教育程度、是否参与过营销活动等信息。将客户成功订购业务记为阳性标签,未成功订购记为阴性标签。客户职业特征域有多种类别,从中选取蓝领职业、学生、退休人员3 个类别。依次分别从3类里抽取60%、20%、20%的样本,抽取20%、60%、20%的样本,抽取20%、20%、60%的样本构成1个目标域与2个源域。
本文实验基于Visual Studio 2019完成,操作系统为Windows 7 64 位,计算机处理器为Intel®CoreTMi7 4710MQ CPU@2.50 GHz,内存16 GB。
3.2 实验设置
针对本文实验的9个不同数据集,分别按照各自特征的类别信息特点进行了目标域与源域的划分,由于数据的分布的差异性,源域数据与目标域数据相似性也不一致。本文使用式(7)对多个源域到目标域的KL距离进行了计算。KL距离计算结果具体情况如表2所示。
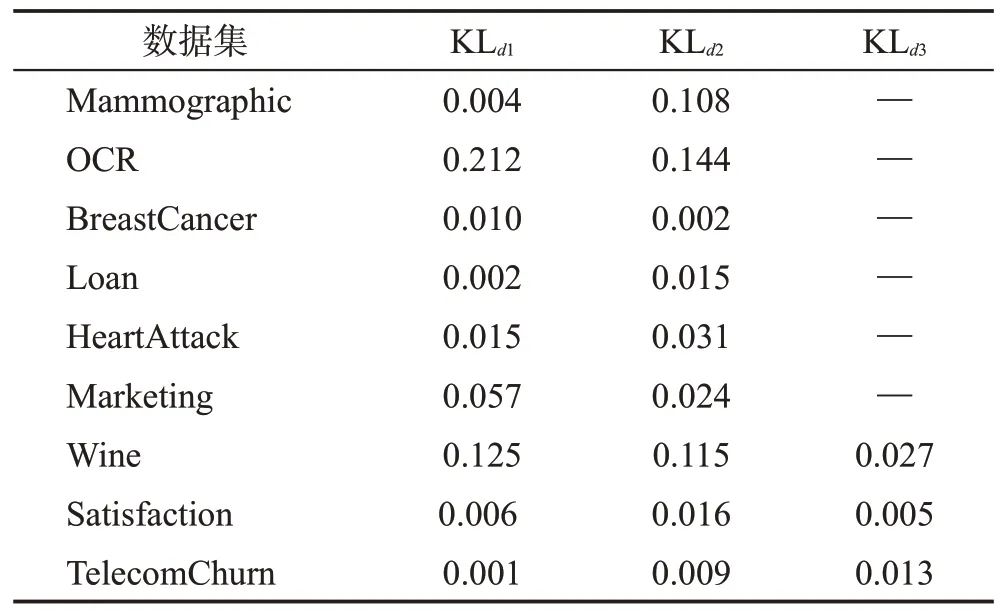
表2 UCI和Kaggle的数据集KL距离Table 2 KL divergence of datasets for UCI and Kaggle
对于算法的样本权重初始值设定,考虑到普遍通用性[13-15],对于重要性未知的所有训练样本应当使用平均权重初始化。本文与DtrBoost算法一致,使用平均权重初始化方法初始化样本权重。由于各个数据的特征类别、特征数目、样本分布情况的不一致,模型达到最优情况的参数σ、γ的值也不同,这两项参数共同决定了惩罚项的大小与振幅。由于多源域相对于单源域迁移学习而言,知识的迁移从不同分布的数据域向目标域迁移,迭代学习过程更为复杂,更容易出现振荡,为确保梯度计算的量纲一致,惩罚项的大小与Dtrboost算法的惩罚项参数相比,应当相对变小,从而避免权重更新可能出现的振荡。因此σ的搜索空间为{10-16,10-17,…,10-20},参数γ的搜索空间为{2-17,2-18,…,2-20},均小于Dtrboost 算法的搜索空间。本文采用10 次实验的平均结果,逐步遍历搜索空间,找到各数据集的最佳参数。以Marketing 数据集为例,图2展示了参数搜索过程中不同参数设置对模型平均分类错误率的影响。选择恰当的参数σ、γ可以使得惩罚项大小与振幅更为合理,使模型更好地选择最佳的基分类器并增加权重,最终降低集成模型的分类错误率。
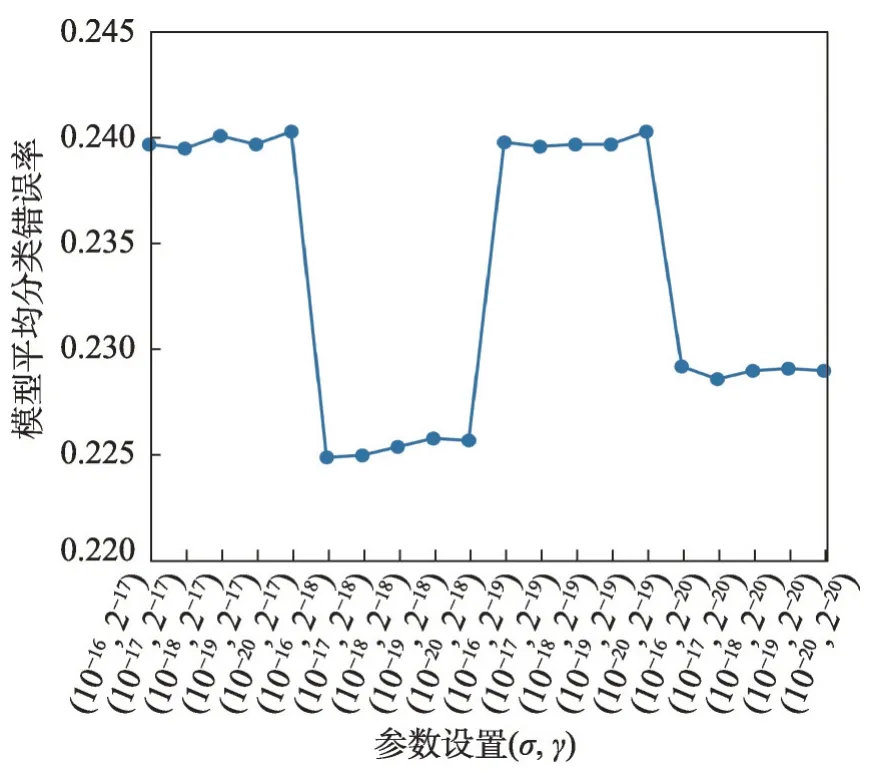
图2 Marketing数据集上参数设置对平均分类错误率的影响Fig. 2 Influence of parameter setting on average classification error rate on Marketing dataset
参数设置具体情况如表3 所示。实验的前6 个数据集设置了2个源域的迁移学习,后3个数据集则设置为3个源域的迁移学习。
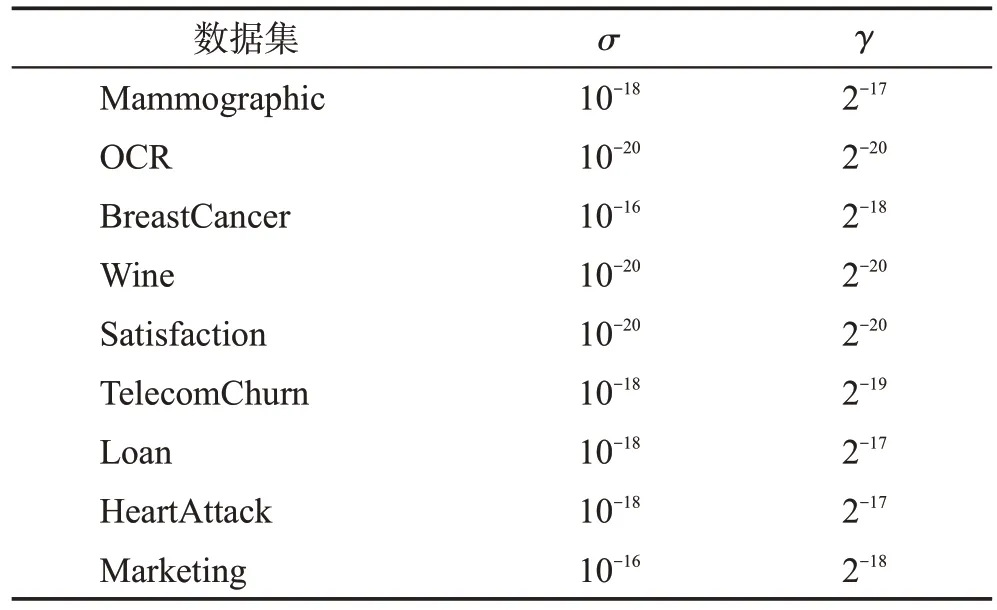
表3 UCI和Kaggle的数据集参数设置Table 3 Parameter setting of datasets for UCI and Kaggle
本文采用EasyTL、TrAdaBoost、Dtrboost、Dynamic-TrAdaBoost(adaptive Boosting for transfer learning using dynamic updates)[23]这4个主流迁移学习算法作为对比算法。EasyTL算法是一种无需超参数的迁移学习算法,该算法时间复杂度低,分类精度高。TrAdaBoost 算法是迁移学习中最具有代表性的算法,该算法将AdaBoost算法进行了拓展,使其能够在迁移学习的场景中使用。Dynamic-TrAdaBoost 算法通过引入动态因子扩展了算法,使得该算法满足加权多数算法的设计预期。由于TrAdaBoost 与Dynamic-TrAdaBoost 算法决策树深度可调,为了更好地比较算法,将决策树最大深度为1 的算法记为H1,最大深度为2 的算法记为H2。DTrBoost 算法根据Rademacher复杂度最小化源域和目标域的数据依赖学习边界来学习并分配给基础学习者,这保证了该算法可以在不过度拟合的情况下学习深度决策树。为公平起见,本文所有算法的迭代训练次数均为100次。
3.3 实验结果
本文在2 个源域与3 个源域数据集上的分类结果分别如表4、表5 所示。加粗数据表示在该数据集上最低的分类错误率,下划线数据表示该组数据分类错误率的次小值。各个数据集上的实验结果显示,MtrBoost算法均优于各对比方法。对于特征维度较大的OCR 数据集,MtrBoost 算法分类错误率明显低于DtrBoost 算法,这是因为MtrBoost 算法具有两个独立更新训练样本权重的源域,对于不同分布的源域数据可以根据相似性大小区别地将源域中的知识迁移至目标域。DtrBoost算法只有一个源域,对于源域的训练样本权重更新只通过一个更新公式进行更新,导致源域样本权重的更新不够准确,从而影响最终的分类精度。对于其余5 个二源域数据集,MtrBoost 算法提升的幅度并不是很大。主要是由于划分的源域到目标域的KL距离不是很大,这就说明源域数据分布相对于目标域数据分布具有一定的相似度,MtrBoost算法的双源域样本权重独立更新的优势相对被削弱。DtrBoost 算法在这几个数据集上的分类错误率并没有比MtrBoost 算法高出很多,这是因为两个源域数据与目标域数据均存在相似度,相对于MtrBoost算法,双源域独立更新权重,不同源域的样本权重在每次更新迭代后差别并不是很大。因此,源域与目标域KL距离的分布情况对于最终的分类错误率有一定影响,较大的KL距离可以突出各源域样本权重独立更新的优势。对于3 个源域的数据集,MtrBoost 算法均比基线对比算法分类效果更好。这说明MtrBoost 算法在3 个源域分布情况的数据集上也能很好地完成分类任务。TrAdaBoost、Dynamic-TrAdaBoost 算法每次迭代会更新训练样本权重,每次使用新的样本权重训练基分类器,在100次迭代后模型节点数目均为固定的100个。图3展示的是100次迭代训练后的MtrBoost算法模型平均节点数目与平均节点深度。与TrAdaBoost、Dynamic-TrAdaBoost算法对比,所有的模型节点数目都没有达到迭代训练次数,这说明MtrBoost算法具有自适应能力,每一次迭代训练并不都是将新训练的基分类器加入模型中,也可能是选择已经存在的当前梯度最大的基分类器作为最佳分类器并按照分类器权重式(16)增加基分类器的权重。节点的平均深度说明训练完的模型中有深度为1和2的两种基分类器,在不同数据集上平均深度并不相同,这也体现了MtrBoost 算法对于不同训练数据的自适应性。这种自适应性使得模型可以增加当前最优的基分类器的权重,从而提高最终集成函数输出结果中的比重,提高分类的准确性。
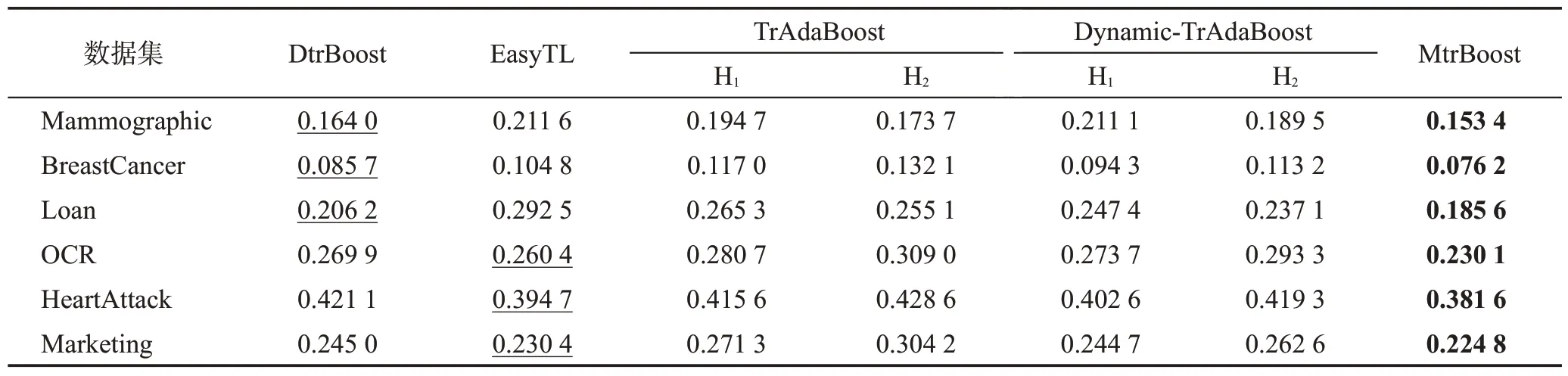
表4 各种算法对于二源域数据集的分类错误率Table 4 Classification error rates of various algorithms on 2-source domain datasets

表5 各种算法对于三源域数据集的分类错误率Table 5 Classification error rates of various algorithms on 3-source domain datasets

图3 MtrBoost模型平均节点数目与平均节点深度Fig. 3 MtrBoost model average number of nodes and average depth of nodes
总的来说,本文提出的MtrBoost 算法分类准确率均高于对比算法。在样本特征数目较多、源域到目标域KL 距离较大时性能提升较为明显。在源域与目标域KL距离不大、样本维度不多的情况下也有小幅的性能提升。
4 结束语
本文提出了一种多源域分布下优化权重的迁移学习Boosting方法。同时,根据不同源域到目标域的KL距离设计了梯度学习函数。与单源域迁移学习的DtrBoost算法相比,本文算法在每一次迭代训练后可以独立更新不同源域的样本权重,增加误分类的目标域样本权重,降低误分类的源域样本权重。实验证明,本文算法较对比算法在整体精确度上实现了更好的性能并且对于不同的训练数据能够实现自适应效果。在将来的改进中,可以使用部分数据训练给目标域数据打标签,从而实现无标签的目标域训练数据迁移学习。此外,可以根据源域的KL距离相似程度分别设计源域样本权重的更新公式,使得模型更快收敛。
