提取驾驶员面部特征的疲劳驾驶检测研究综述
2023-06-07杨艳艳李雷孝
杨艳艳,李雷孝+,林 浩
1.内蒙古工业大学 数据科学与应用学院,呼和浩特010080
2.内蒙古自治区科学技术厅 内蒙古自治区基于大数据的软件服务工程技术研究中心,呼和浩特010080
3.天津理工大学 计算机科学与工程学院,天津300384
目前,交通事故依旧是威胁生命安全的主要因素之一。缺乏道路安全驾驶意识、酒后驾驶以及疲劳驾驶是危害交通安全的主要因素。其中,疲劳驾驶占14%~20%,重大交通事故约占43%,大型卡车和高速公路的交通事故约占37%[1]。此外,由于操作不当和粗心而导致的其他交通事故在某种程度上也很有可能与疲劳驾驶有关。交通安全法明确规定,如果驾驶员在不休息的状态下开车超过4 h,将被视为疲劳驾驶。目前交管部门针对这种情况可以对其进行处罚并扣减驾驶证记分,尽管在一定程度上可以减少驾驶员过度疲劳驾驶行为,但这种措施也仅仅是在制度层面对驾驶员的行为进行约束,实际情况并不能很大程度地减少因疲劳驾驶而发生的交通事故。而且,有一些驾驶员开车时间未超过4 h,但因为休息不当等原因,也可能存在疲劳驾驶的情况。若能在驾驶员有疲劳驾驶的迹象发生时,及时地给驾驶员发出疲劳警告才是减少交通事故的有效手段。因此,为了维护交通安全,对驾驶员的疲劳驾驶检测就显得尤为重要。对驾驶员疲劳检测的研究也具有重要的理论与现实意义。
虽然疲劳驾驶检测技术层出不穷,但至今仍未有一个准确率较高、实用性较强且对驾驶员较友好的检测方法。当前疲劳驾驶检测的研究成果主要可分为三大类:基于驾驶员生理特征的检测方法、基于驾驶员车辆行驶信息的检测方法以及基于驾驶员面部特征的检测方法。基于驾驶员生理特征的方法[2-3]一般需要硬件设备,而且使用方式为接触式的,对大多数驾驶员来说,佩戴复杂的硬件设备会给驾驶员带来强烈的不适感,这很可能会对驾驶员的操作带来影响,对驾驶员不够友好;基于驾驶员车辆行驶信息的检测方法[4-5]与道路状况、交通情况以及驾驶员行驶习惯有很大的关联,检测结果会存在很大误差;基于驾驶员面部特征的疲劳驾驶检测方法由于其对驾驶员友好、准确率较高等优势成为研究热点。虽然基于驾驶员面部特征的疲劳驾驶检测已产生了很多研究成果,但大多数检测方法都较为相似,并未有特别创新的突破。有一些较为重要的问题也未考虑,例如驾驶员个性化问题、数据集问题以及戴墨镜下的疲劳驾驶检测问题等。因此,本文主要目的是希望通过分析总结当前基于驾驶员面部特征的疲劳驾驶检测方法的优缺点,为后续该领域的研究者提供一定的帮助,进而推动疲劳驾驶检测领域技术的发展。
至今为止,大部分疲劳驾驶检测的综述,往往侧重于综合介绍上述三类检测技术[6-10]。在其综述时,仅罗列了近几年这三类方法所使用的技术、取得的研究结果以及对未来的研究展望,但并未针对某一类检测方法进行深入研究。因此,本文重点关注基于驾驶员面部特征的疲劳驾驶检测方法,根据疲劳驾驶检测流程,从人脸检测、特征提取以及数据集等角度深入分析总结了现有研究成果。
本文首先通过对比实验分析近几年疲劳驾驶领域常用的四种人脸检测算法;其次详细总结了目前常用的公开数据集的优缺点以及适用场景;然后论述总结三类特征提取方法;最后提出了基于驾驶员面部特征的疲劳驾驶检测方法目前所面临的挑战。
1 疲劳驾驶面部表现
研究表明,当驾驶员睡眠不足、长时间驾驶、夜间驾驶、单调驾驶、未知环境驾驶时均可能引起疲劳[11]。而在驾驶中的易怒、行动迟缓、注意力不集中、打哈欠、眼睛沉重、不耐烦等表现都是疲劳驾驶的早期迹象[11]。故当人处于疲劳状态时,眼睛状态、嘴巴状态、头部姿态以及面部表情等驾驶员面部特征能直观地反映驾驶员是否处于疲劳的状态。具体原因如下:
(1)眼睛状态。无外界因素影响的状态下,一个人正常的眨眼频率是每分钟10~20 次,且每次眨眼持续时间在100~400 ms。但在疲劳状态时,眨眼频率会增加大约64%,且眨眼的持续时间延长至1 s左右[12]。
(2)嘴巴状态。打哈欠是疲劳状态下嘴部的主要表现,是一种深呼吸的连续活动,一般持续3~5 s[13],是一种在疲劳状态下的条件反射。当人在懒惰、疲劳和缺乏休息的时候,通常会通过打哈欠的方式使肺部吸入大量氧气,刺激中枢神经系统,使精神振奋。
(3)头部姿态。当驾驶员出现频繁的点头或者头部忽然下垂时,说明驾驶员存在疲劳驾驶的风险[12]。
(4)凝视方向。凝视可以检测驾驶员是否疲劳驾驶以及注意力是否集中[14]。驾驶员清醒状态下和疲劳状态下的凝视区域存在明显的不同。清醒状态下驾驶时,驾驶员会直视前方,目光较聚集。但当驾驶员疲劳驾驶时,会出现目光呆滞、眼神涣散、长时间视线下移或者偏移的现象。
(5)面部表情识别(facial expression recognition,FER)。FER 是面部肌肉的一个或者多个动作、状态的结果。它是人体语言的一部分,也是一种生理及心理的反应,通常可以表达出一个人的情感状态。在驾驶员疲劳驾驶时,频繁眨眼、打哈欠等面部表情都是面部肌肉动作的结果。因此FER也可以衡量驾驶员的疲劳状态[15]。
表1 总结了近几年上述五类面部特征在疲劳驾驶检测领域中的应用情况。

表1 各个面部特征在疲劳驾驶领域中的应用Table 1 Application of individual facial features in field of fatigue driving
从表1可以看出,由于驾驶员疲劳时眼睛和嘴巴状态是最为直观的,目前大多数研究都集中在驾驶员眼睛和嘴巴状态;另外驾驶员FER 是面部肌肉活动的共同结果,疲劳表情也是面部表情之一,因此也有一些学者通过FER来检测驾驶员是否疲劳驾驶并取得了较理想的结果;虽然凝视方向也能够反映出驾驶员的驾驶状态,但目前在驾驶员疲劳驾驶检测领域应用较少,主要原因是目前在疲劳驾驶检测领域缺少驾驶员清醒状态和疲劳状态时有关凝视方向的数据集,若有数据集做支撑,驾驶员的凝视方向将是一个研究重点。
2 数据集
在疲劳驾驶检测领域,很多研究者自建了数据集,但由于疲劳驾驶数据集涉及到驾驶员的个人隐私,很少有研究者选择将数据集公开。近几年来公开的可以免费获取且比较常用的数据集有5个,分别为野外眨眼图片数据集CEW[30]和MRL[31]、打哈欠视频数据集YawDD[32]、疲劳驾驶视频数据集NTHUDDD[33]和UTA-RLDD[34]。
(1)CEW。由2 423位成员组成的只包含眼部区域的图片数据集。其中实验人员包括男性和女性、戴眼镜和不戴眼镜。数据集中1 192 位成员提供双眼闭合的图形,来自网络采集;1 231位成员提供双眼睁开数据集,来自野外标记的人脸数据库。
(2)YawDD。该数据集来自不同种族的男性和女性司机,戴眼镜和不戴眼镜,包含两个具有不同人脸特征的驾驶员视频数据集,主要被用于打哈欠检测的算法和模型。第一个数据集中共322个视频,摄像头安装在汽车的前视镜下,每个参与者有3~4个视频,其中包括正常说话、说话和唱歌以及打哈欠的场景;第二个数据集中共有29个视频,摄像头安装在驾驶员的仪表板上,每个参与者都有一个单独的视频,其中包括正常驾驶不说话、边开车边说话以及边开车边打哈欠的场景。
(3)NTHU-DDD。该数据集来自36 个不同种族的男性和女性司机,戴眼镜和不戴眼镜,模拟了正常驾驶、打哈欠、慢速眨眼、入睡以及大笑五类驾驶场景,在白天和夜间照明下拍摄的视频数据集,受试者坐在椅子上模拟驾驶。整个数据集的总时长为9.5 h。有关打哈欠、缓慢眨眼以及点头动作每个都被记录了大约1 min;与疲劳相关的动作组合(打哈欠、点头以及慢速眨眼)和与非疲劳相关的动作组合(说话、大笑以及看两边),每个记录约为5 min。
(4)UTA-RLDD。该数据集由60 名受试者拍摄的大约30 h 的RGB 数据集。受试者包括大学本科生、研究生或为了获得额外学分的职员等人。所有的参与者都超过了18岁,有51名男性和9名女性,来自不同种族和不同年龄段。该数据集共有180 个视频,在这180个视频中,有21个视频中的受试者戴眼镜,72 个视频中的受试者有相当多的毛发。视频是在不同的现实生活和背景下拍摄的。每个视频都是参与者用手机或者网络摄像机自己录制的,帧速率小于30 FPS。对于每个参与者,都有3 个类别的视频:清醒、低清醒和困倦。
(5)MRL。该数据集是有关人眼图像的大规模数据集,包括低分辨率和高分辨率的红外图像,收集了37个不同的人(33名男性和4名女性)的数据。数据集包含两种眼睛状态,睁眼和闭眼,总共由84 898张图像构成。
以上5 个数据集的优缺点以及在疲劳驾驶检测领域适用范围如表2所示。
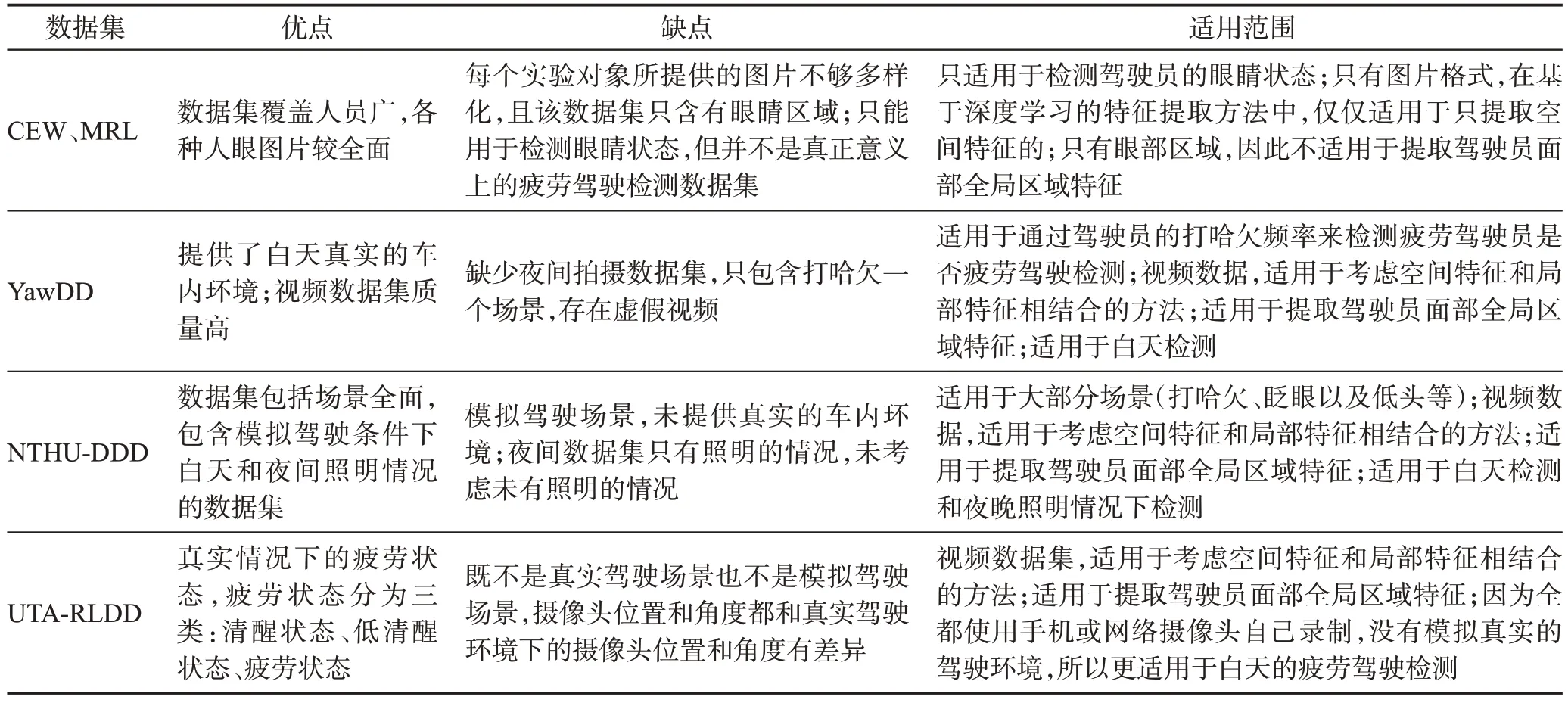
表2 三种数据集的优缺点以及适用范围Table 2 Advantages and disadvantages of three datasets and scope of application
从表1 可以看出,在目前公开数据集中,大部分数据集都是模拟驾驶场景,而且困倦的状态也是模拟出来的。很多学者自制的数据集因需拍摄驾驶员的人脸区域,可能泄露驾驶员个人隐私而不对外公开。且也有很大一部分自制数据集存在真实性较差的情况。目前所公开的数据集大部分都是较理想情况下的,缺乏真实性和图像质量高的数据集。Bakker等[14]在瑞典道路上拍摄了驾驶员在真实疲劳驾驶情况下的面部特征数据集,但该数据集目前并不对外公开。虽然UTA-RLDD 是真实状况下的疲劳状态,但并不是疲劳驾驶下的真实状态。因此,在疲劳驾驶检测领域依旧缺少高质量的公开数据集。
3 疲劳驾驶检测
驾驶员面部特征是检测疲劳驾驶的非入侵性指标,是通过驾驶员的闭眼率、眨眼频率、打哈欠频率、头部位置、凝视方向以及面部表情等来衡量驾驶员的疲劳感[6]。基于驾驶员面部特征疲劳驾驶检测方法主要是使用摄像机和计算机视觉技术来提取驾驶员的面部特征,随后经过对驾驶员面部特征分析来预测驾驶员是否疲劳驾驶。图1 给出了基于驾驶员面部特征的疲劳驾驶检测的整体框架。
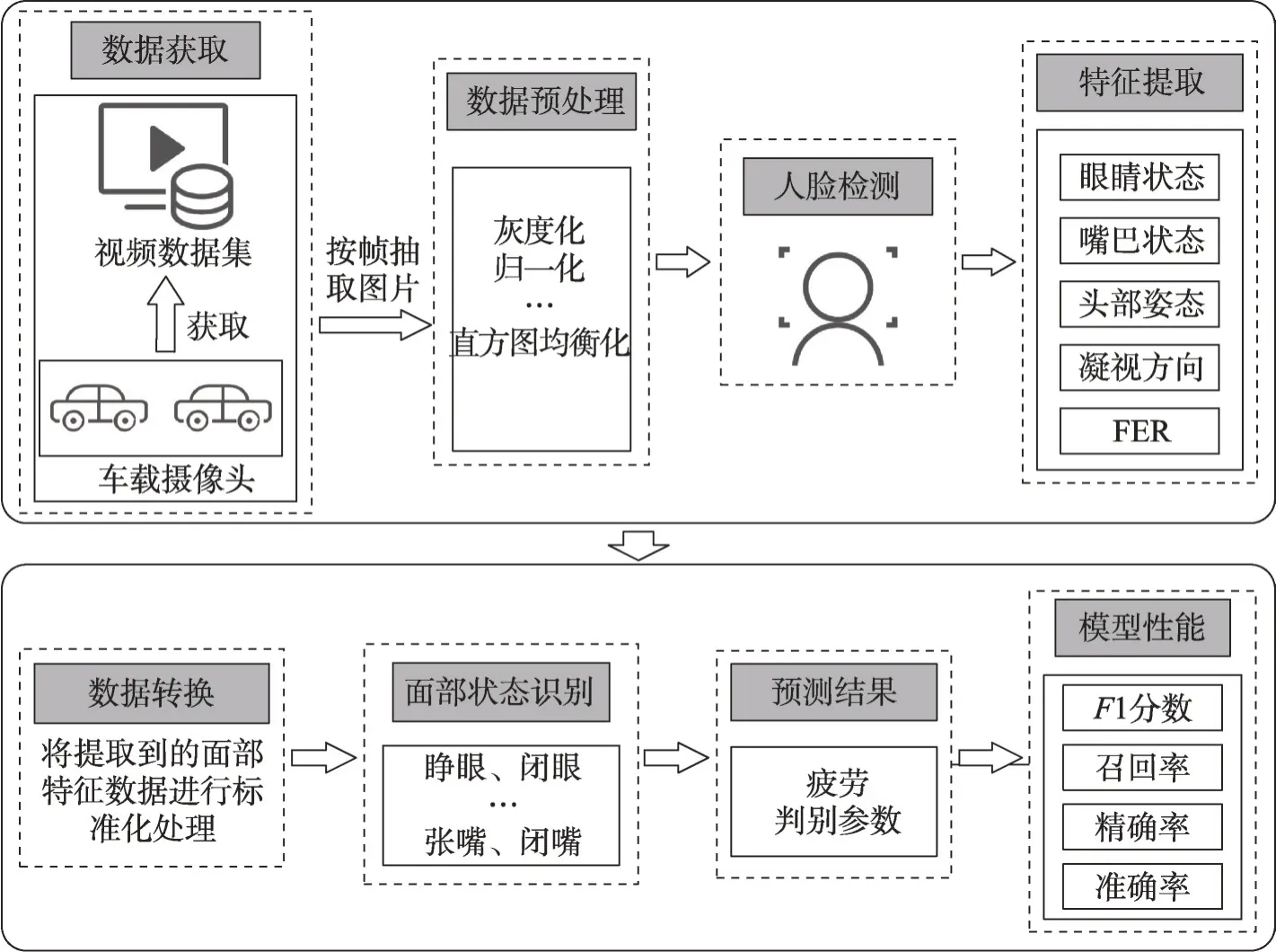
图1 基于驾驶员面部特征的疲劳驾驶检测流程Fig. 1 Fatigue driving detection process based on driver facial features
如图1流程图所示,首先通过车载摄像头获取驾驶员驾驶的数据集,将数据集进行预处理之后输入人脸检测模型。当检测到驾驶员的人脸后,提取驾驶员面部特征。将提取到的面部数据进行标准化处理后,进行面部状态的识别,随后依据疲劳判别参数来预测是否疲劳驾驶。最后根据F1 分数、召回率以及精确度来评价疲劳驾驶检测模型的性能。
其中,最关键的步骤为人脸检测、特征提取和预测结果。首先,人脸是后续特征提取以及结果预测的基础,在检测到驾驶员人脸的基础上才能进行面部特征提取,因此其检测结果决定了后续面部特征提取以及疲劳驾驶检测的准确性;其次,在检测到人脸区域后,需要进行疲劳特征的提取,本文第3.2 节总结了三类特征提取方法的优缺点,研究者可根据自己需要来选择使用什么样的方法来进行特征提取,或者是根据优缺点,使用多技术融合的方法来进行特征提取;预测结果部分,需要根据提取面部的区域来选择合适的疲劳判别参数,最终实现驾驶员疲劳驾驶的检测。
图1模型性能中所提到的评价指标,其具体描述以及计算公式如下所示。
(1)准确率(Accuracy)。即所有预测正确的分类(包括正类和负类)占总的比例,计算公式如下:
(2)精确率(Precision)。即正确预测为正类的占全部预测为正类的比例,计算公式如下:
(3)召回率(Recall)。即正确预测为正类的占全部实际为正类的比例,计算公式如下:
(4)F1 分数(F1 score)。即精确率与召回率的调和平均值,计算公式如下:
上述公式中的TP(true positive)为将正类预测为正类数,TN(true negative)为将负类预测为负类数,FP(false positive)为将负类预测为正类数,FN(false negative)为将正类预测为负类数。
其中,根据特征提取的面部特征的数量,可以将疲劳驾驶检测分为单特征检测和多特征融合检测两个类别,具体内容如图2所示。

图2 驾驶员疲劳驾驶检测类别Fig. 2 Driver fatigue driving test category
本章根据图1 所展示的基于驾驶员面部特征疲劳驾驶检测流程的框架,总结归纳流程中关键步骤所用到的技术以及方法。
3.1 人脸检测
人脸检测是疲劳驾驶检测的基础,其检测结果决定了后续面部特征提取以及疲劳驾驶检测的准确性。目前在疲劳驾驶检测领域使用最广泛的人脸检测算法包括基于OpenCV[35]库来实现的人脸检测算法(Haar+AdaBoost[36])、基于Dlib[37]库的人脸检测算法(HOG+SVM[38])、SSD[39]算法以及MTCNN[40]算法四种。
基于OpenCV库的人脸检测算法为Viola提出的基于Haar-like特征和AdaBoost分类器构建的人脸检测器;基于Dlib 库的人脸检测算法是利用含有方向的梯度直方图(histogram of oriented gradient,HOG)和级联SVM 分类器来实现的;SSD 是单阶段目标检测算法中的一种,可用来进行图片分类;MTCNN 算法是由中科院深圳研究院提出的用于人脸检测任务的多任务神经网络模型。由表2 可知,YawDD 数据集为在真实驾驶环境下收集的数据集,包括戴眼镜打哈欠、戴眼镜不打哈欠、不戴眼镜打哈欠和不戴眼镜不打哈欠4 个场景;NTHU-DDD 数据集为模拟驾驶环境下收集的数据集,包括了说话、唱歌、打哈欠、缓慢眨眼、点头等各种驾驶过程中会出现的场景。本节主要测试疲劳驾驶检测领域中常用的4 个人脸检测算法的性能,上述两个数据集涵盖了驾驶员驾驶时出现的各种情况,且上述两个数据集是基于驾驶员面部特征的疲劳驾驶检测领域常用的数据集,具有代表性。因此本文将疲劳驾驶检测领域中常用疲劳数据集YawDD 和NTHU-DDD 视频数据集按帧提取,组成图片数据集。使用YawDD 数据集中的756 张无遮挡和469 张戴墨镜和NTHD-DDD 数据集中的610 张无遮挡和610 张戴墨镜的驾驶员驾驶图片,通过实验得出这4种算法的人脸检测速度以及准确率,用来评估这4种人脸检测算法的性能。实验环境主要为表3所示,实验结果如表4、表5所示。实验所用GPU 为NVIDIA GeForce RTX 2060,处理器为Intel®CoreTMi7-9700 CPU@3.00 GHz,8核。

表3 实验环境Table 3 Experimental environment
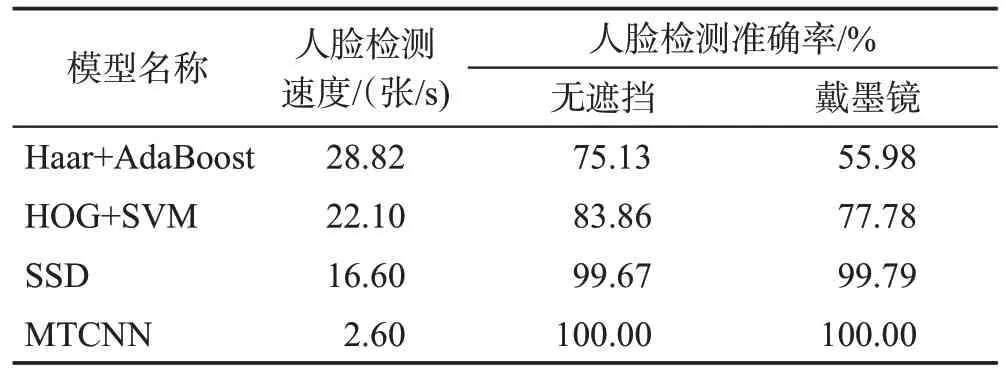
表4 YawDD数据集下人脸检测模型性能Table 4 Face detection model performance under YawDD dataset
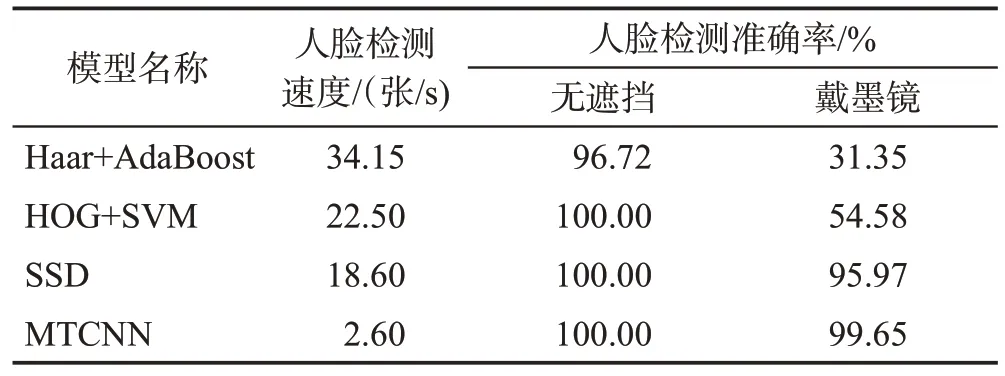
表5 NTHU-DDD数据集下人脸检测模型性能Table 5 Face detection model performance under NTHU-DDD dataset
由表4和表5可以看出,在检测速度方面,Haar+AdaBoost 和HOG+SVM 算法表现较好,能够快速地检测驾驶员的人脸区域,检测速度最慢的是MTCNN算法,其次是SSD 算法。在人脸检测准确率上,MTCNN算法和SSD算法表现较好,且这两种算法的鲁棒性也较好,在戴墨镜的数据集上,准确率并没有下降。其中SSD 的准确率是置信度分别为0.5、0.6、0.7 以及0.8 时的平均值。当设置SSD 人脸检测的置信度为0.5和0.6时,在YawDD数据集下,人脸检测的准确率在无遮挡以及戴墨镜时都为100%。当置信度超过0.6 时,SSD 算法未检测出来的照片大多是侧脸超过45°或者是高度模糊的照片。本文从YawDD 数据集中随机抽取4张驾驶员不同角度的驾驶图片,如图3到图6所示。

图3 不同算法人脸检测结果(正脸无遮挡)Fig. 3 Face detection results of different algorithms(no masking of face)

图4 不同算法人脸检测结果(侧脸无遮挡)Fig. 4 Face detection results of different algorithms(unobstructed side face)

图5 不同算法人脸检测结果(正脸戴眼镜)Fig. 5 Face detection results of different algorithms(wearing glasses on face)

图6 不同算法人脸检测结果(侧脸戴眼镜)Fig. 6 Face detection results of different algorithms(wearing glasses on side of face)
由图3 检测到的人脸区域可以看出,Haar+AdaBoost和HOG+SVM的人脸检测算法检测到的人脸区域包含很多干扰区域(非人脸区域),SSD算法和MTCNN 算法检测的人脸区域没有明显的差异。从图4 的检测结果可以看出,Haar+AdaBoost 的人脸检测算法对于侧脸的驾驶员鲁棒性较差,不能准确检测到人脸。MTCNN 算法检测到的人脸区域比SSD算法检测到的区域更为精准,不会包含太多的噪声区域。图5和图6的实验结果表明,HOG+SVM的人脸检测算法在有遮挡驾驶员的检测中表现不佳。
综上所述,从整体实验结果来看,SSD 以及MTCNN 算法作为基于深度学习的人脸检测算法准确率要高于非深度学习的人脸检测算法,但由于深度学习算法需要经过多层卷积来提取特征,实时性较差。目前,MTCNN是疲劳驾驶检测领域中应用较多的人脸检测算法,其为了得到精准的人脸框,采用了3个级联网络。因此,MTCNN算法检测速度较慢,但疲劳驾驶检测对实时性要求较高,检测速度越快,越能保证驾驶员的安全性。针对此问题,文献[28]指出,MTCNN 在进行人脸检测时,通常会设置一个最小人脸尺寸。若MTCNN 输入的图片大于设置的最小人脸尺寸,则MTCNN 会根据提前设置的缩放比例,生成不同尺寸的人脸,组成人脸金字塔。由于驾驶员驾驶区域比较固定,且人脸区域在图片中占据比例较大,可以通过固定车载摄像头的位置以及金字塔图片相邻层间的缩放比例,减少MTCNN输入图片金字塔的层数来提高人脸检测的速率。该方法虽然在一定程度上能提高人脸检测的速率,但MTCNN设计的初衷是用来在复杂场景的多个目标中检测人脸,因此其能否被应用在疲劳驾驶检测领域的人脸检测上仍是一个值得研究的问题,如何改良MTCNN,使其在不损失精确度的情况下更好地提高MTCNN的人脸检测速度仍是一个亟待解决的问题。
3.2 特征提取
特征提取是指在检测到人脸的基础上,提取出每一帧的面部特征。通过调研大量文献发现,目前在疲劳驾驶检测领域,多数研究者基于眼睛或者嘴巴的特征来进行驾驶员疲劳驾驶的检测。本节将分别论述使用基于形状的特征提取方法、基于手工的特征提取方法以及基于深度学习的特征提取方法在进行眼睛或嘴巴特征提取时的优缺点。
3.2.1 基于形状的特征提取方法
基于形状的特征提取方法,即根据眼睛、嘴巴以及头部姿态的外观形状来提取特征。通过计算眼睛、嘴巴的开合度以及头部姿态偏转角度来提取眼睛、嘴巴以及头部的特征,以此来作为识别驾驶员眼睛、嘴巴以及头部状态的标准[12,21-23]。具体流程如图7所示。
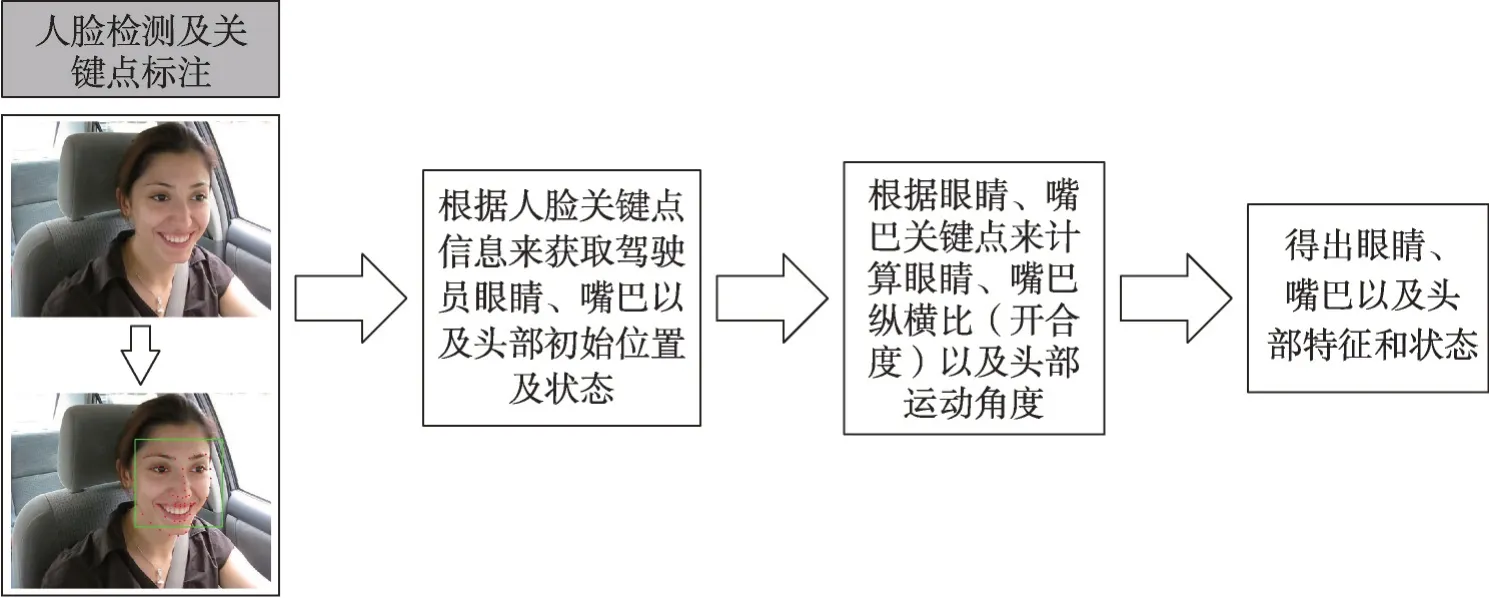
图7 基于形状的特征提取方法Fig. 7 Shape-based feature extraction method
3.2.1.1 眼睛特征提取
由图7 所示,检测到人脸以后,模型会对人脸上的关键点进行标注,随后利用欧式距离来计算眼睛纵横比EAR[41],求解方式如图8以及式(5)所示:
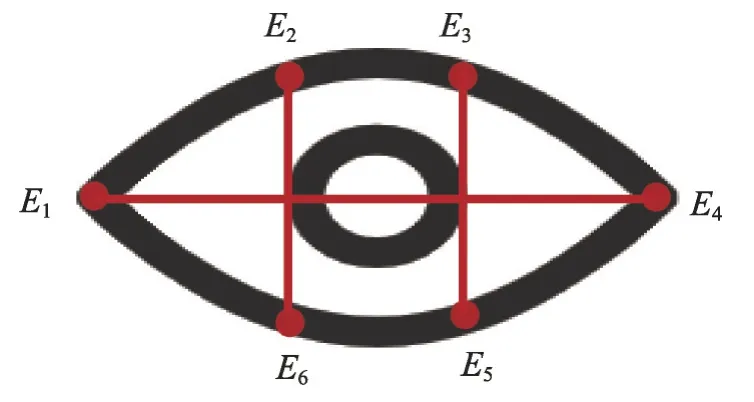
图8 眼睛纵横比求解示意图Fig. 8 Schematic diagram of eye aspect ratio solution
上述式(5)用来求解眼睛纵横比EAR,根据求解出来的EAR来表示眼睛状态。若EAR大于预先设定的阈值,则代表驾驶员为睁眼状态。
3.2.1.2 嘴巴特征提取
同理,对人脸进行关键点标注后,可以利用嘴巴关键点使用欧氏距离来计算嘴巴的纵横比MAR[42],求解方式如图9以及式(6)所示:
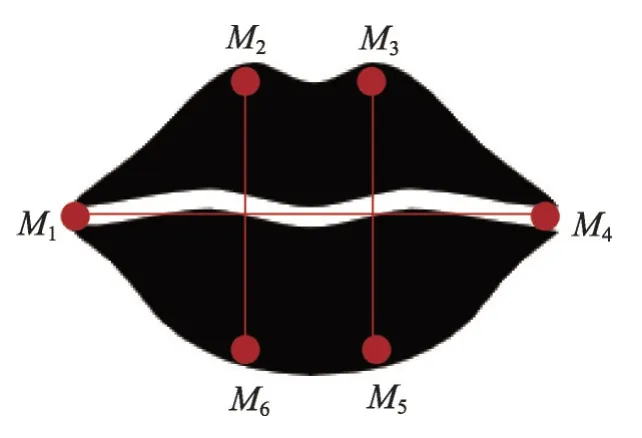
图9 嘴巴纵横比求解示意图Fig. 9 Schematic diagram of mouth aspect ratio solution
上述式(6)用来求解嘴巴纵横比MAR。根据求解出来的MAR来表示驾驶员的嘴巴状态。若MAR大于预先设定的阈值,则代表驾驶员为张嘴的状态。
3.2.1.3 头部姿态特征提取
由文献[22]可知,头部姿态的变化可分为3 个角度,即Pitch、Yaw以及Roll,分别表示为绕x轴旋转的角度、绕y轴旋转的角度以及绕z轴旋转的角度。如图10所示。
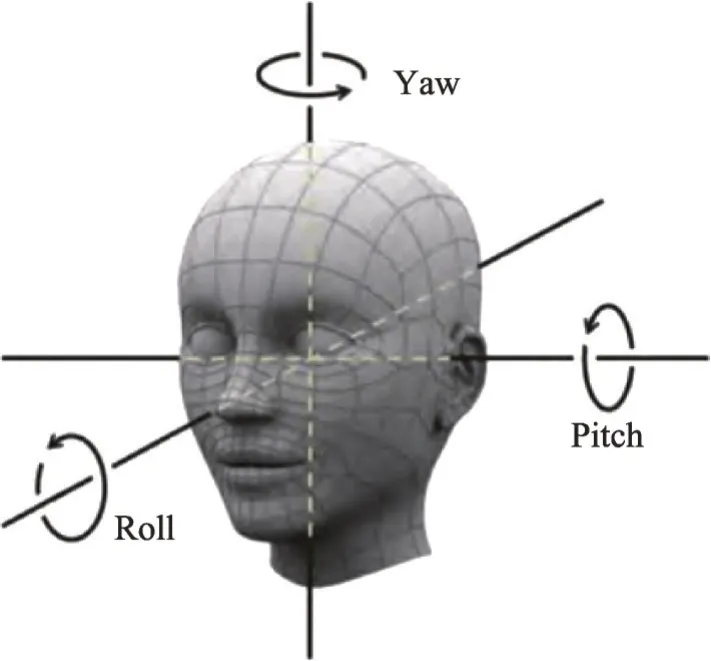
图10 头部姿态三维变动方向图解Fig. 10 Diagram of three-dimensional changing direction of head posture
当驾驶员在疲劳驾驶时出现点头的现象,就可以理解为头部在x轴和z轴进行的运动,相应的Pitch和Roll 角度会发生变化;而当驾驶员头部左右晃动时,可认为头部是在y轴上进行活动,此时Yaw角度会发生变化。因此可通过计算Pitch、Yaw 以及Roll的角度变化即可提取驾驶员头部姿态特征。目前,在头部姿态上的提取方法不多,大部分提取方法都是在获取到驾驶员的人脸关键点后通过几何关系转换坐标系,从而获得头部姿态在角度Pitch、Yaw以及Roll上的变化情况。
3.2.1.4 基于形状的特征提取方法小结
虽然用上述方法来识别眼睛、嘴巴以及头部的状态极其容易实现,但是该方法存在如下缺点:
(1)在驾驶过程中,驾驶员的人脸是一直动态变化的,那么关键点的定位将会不准确。因此,就无法准确计算EAR和MAR。
针对该问题,有部分学者提出了解决方法[19],虽然在一定程度上能够缓解因为检测人脸关键点不准确而导致计算眼睛和嘴巴闭合度有误差的问题,但依旧未能解决人脸关键点不准确的问题。
(2)此方法忽略了驾驶员个体差异这一关键问题。人的眼睛、嘴巴有大小之分[43-44],若固定相同的阈值,不同的眼睛、嘴巴大小会有不同的结果。文献[12,45]提出事先针对每一个人的训练分类库,用来解决驾驶员个体差异的问题。但是,该方法对于一些租赁车辆和共享车辆来说,驾驶员身份是不能预料的。因此该方法的泛化能力较弱,而且随着后续驾驶人数的增加,对计算机的存储能力的要求会越来越高。
3.2.2 基于手工的特征提取方法
由于基于手工的特征提取方法需要根据图片像素值进行特征提取,只能用于提取驾驶员眼睛和嘴巴的特征。基于手工的特征提取方法摒弃了需要通过人脸精准的关键点来计算眼睛和嘴巴的开合度后,才能提取出驾驶员眼睛和嘴巴特征的方法。该方法只需要在得到人脸区域后,划分出驾驶员眼睛和嘴巴的区域,后续通过图像处理的技术来检测眼睛和嘴巴的开合来提取驾驶员眼睛和嘴巴的特征,以此来识别眼睛和嘴巴的状态,如图11所示。
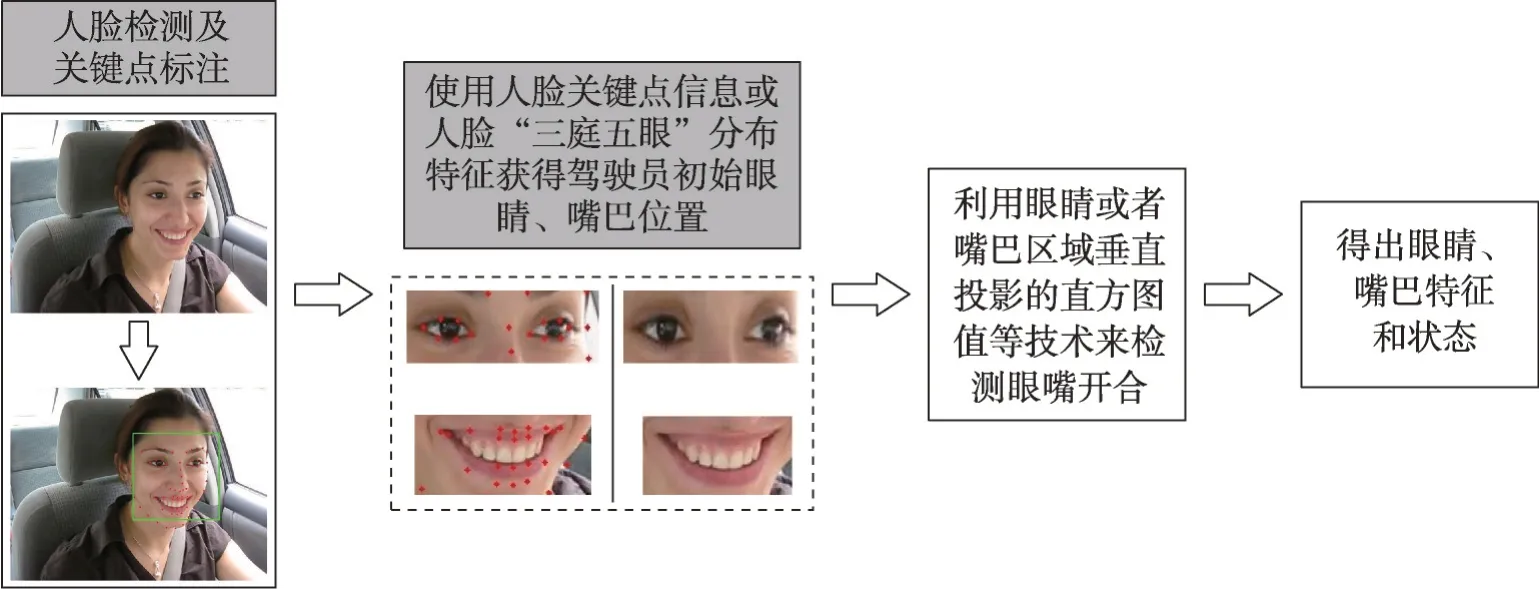
图11 基于手工的特征提取方法Fig. 11 Hand-based feature extraction method
与基于形状的特征提取方法不同的是,在分割眼睛和嘴巴区域时,可根据人的“三庭五眼”的分布特征分割出眼睛和嘴巴的位置[24],或者根据关键点分割出大致的眼嘴区域。所谓“三庭五眼”,即人脸从纵向上,可分为三等份,发际线到眉毛占整张脸的1/3,眉毛到鼻子底部占1/3,鼻子底部到下巴为1/3;人脸从横向上来说,可分为五等份,左脸发际线到左眼外眼角为1 份,左眼外眼角到左眼内眼角为1 份,左眼内眼睛到右眼内眼角为1份,右眼内眼角到右眼外眼角为1份,右眼外眼角到右脸发际线为1份。如图12所示。
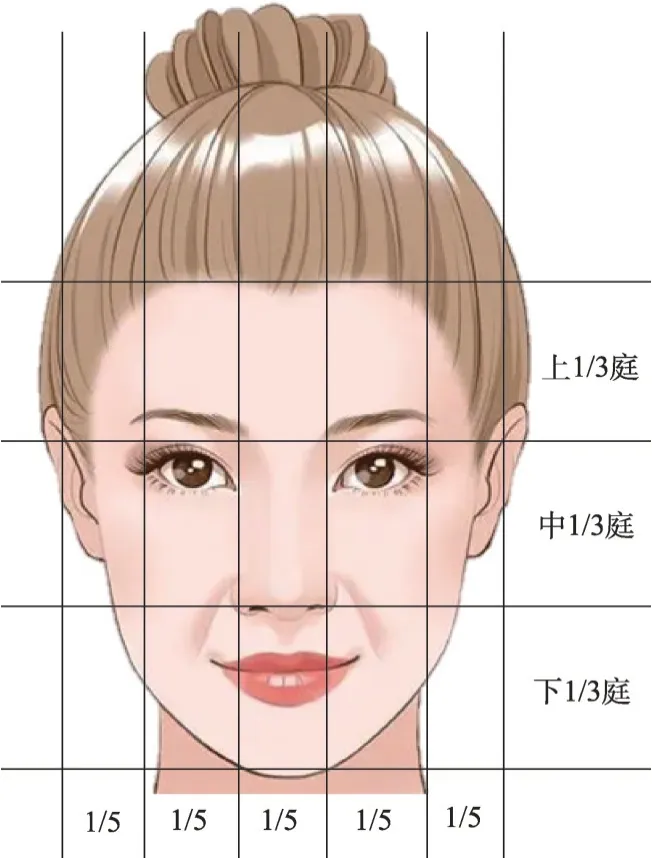
图12 人脸的“三庭五眼”Fig. 12 “Three courts and five eyes”of human face
根据人脸“三庭五眼”的分布特征来截取人眼和嘴巴的大致区域,能够缓解驾驶员侧脸时,人脸关键点定位不准确的问题。与基于形状方法存在的固有问题[46-48]相比,基于手工的特征提取方法能够保证特征提取的鲁棒性,提高眼睛和嘴巴状态识别的准确率。
3.2.2.1 眼睛特征提取
基于手工的特征提取方法在提取眼睛特征时,主要是根据眼睛睁开和闭合时皮肤纹理不同来判断眼睛和嘴巴的状态。当眼睛闭合时,瞳孔被遮盖,此时皮肤纹理占据较多,反映到图像上时表现为此区域偏亮,像素值较高。当驾驶员睁眼时,此时瞳孔可见,反映到图像上时表现为此区域偏暗,像素值较低。从本质上来讲,使用基于手工的特征提取方法对眼睛的状态进行判断就是基于整张图片像素值的总体变化来进行状态判断的。表6 所示为人眼不同状态下的二值图像。

表6 人眼不同状态二值图像Table 6 Binary images of human eyes in different states
3.2.2.2 嘴巴特征提取
同理可得,基于手工的特征提取方法在提取嘴巴特征时,则是根据嘴巴张开和闭合时皮肤纹理不同来判断嘴巴的状态。当嘴巴闭合时,嘴唇紧闭,当嘴巴张开时,能够看到口腔,反映到图像上时,该区域会有不同的像素值。因此,可根据像素值的差异来区分驾驶员的嘴巴状态。表7 所示为人嘴不同状态下的二值图像。
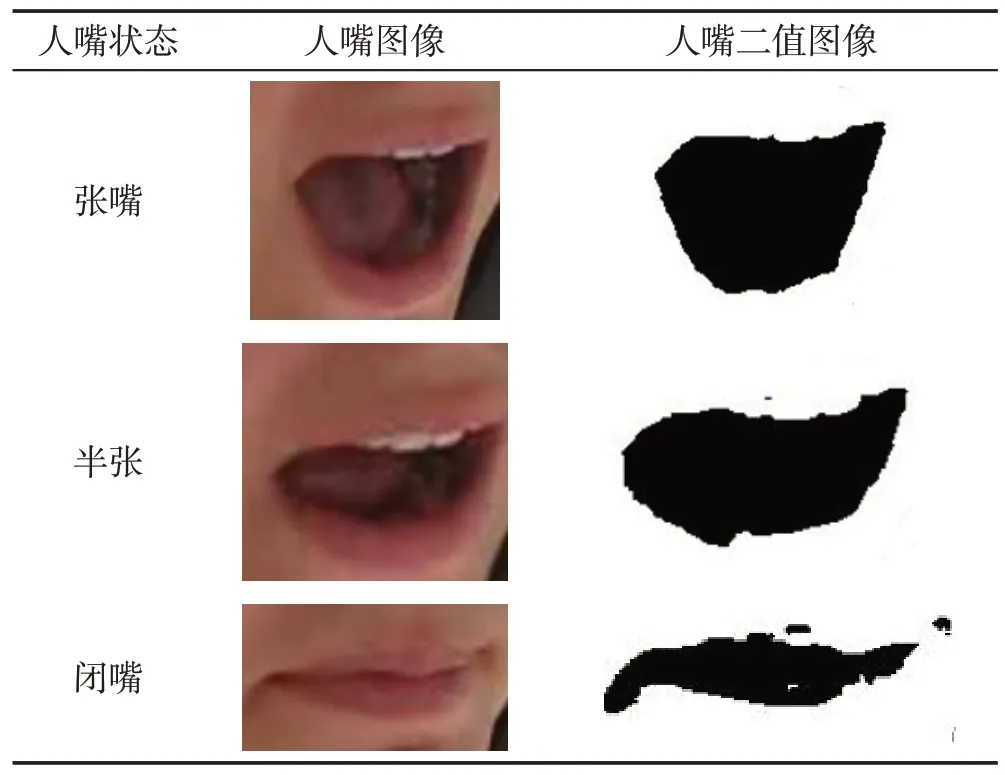
表7 人嘴不同状态二值图像Table 7 Binary images of human mouth in different states
3.2.2.3 基于手工的特征提取方法小结
综上所述,基于手工的特征提取方法不通过人脸关键点来判断眼睛和嘴巴的状态,解决了由于关键点不准确而导致特征提取不准确的问题。本小节总结了近几年来使用基于手工的特征提取方法的各种技术,详细内容见表8。

表8 基于手工的特征提取技术Table 8 Manually based feature extraction technology
虽然该方法不需要训练且易于实现,但该类方法对图片质量要求较高,受光照强度、驾驶员是否佩戴眼镜以及图片中是否存在不相关的目标等因素的影响较大,而且在进行眼睛和嘴巴区域分割时对像素值较敏感,多变的环境也容易使图像分割效果变差。虽然文献[17]提出了可以使用多种方法综合评价驾驶员眼睛和嘴巴的状态,一定程度可以缓解外界环境带来的影响,但严格意义上来说,并未能解决驾驶员个性化问题。
3.2.3 基于深度学习的特征提取方法
由于使用深度学习算法能在复杂环境下获得更有效的特征且具有较高的识别准确率,在疲劳驾驶检测领域已成为研究热点。在使用基于深度学习的特征提取方法时,通常分为两种:
一种是只提取驾驶员整张脸的局部特征,如文献[24]通过改进的多任务卷积神经网络确定人脸区域,根据人脸的面部比例关系定位驾驶人的眼部与嘴部区域,利用基于Ghost 模块的轻量化AlexNet 分类检测眼部与嘴部的开闭状态;文献[53]首先在普通卷积神经网络的基础上构建一个疲劳检测卷积网络(fatigue detection convolutional neural network,FDCN),然后将投影核引入FDCN 来构造P-FDCN 用来提取眼睛的特征;文献[29]提出了一种基于特征校准和融合的多粒度深度卷积模型用于驾驶员疲劳检测,该深度模型利用来自局部人脸的线索来减轻姿态变化,并从全局人脸和不同的局部部分获得鲁棒的特征表示,使用长短期记忆网络用于探索序列帧之间的关系,以区分具有相似外观(说话、大笑和打哈欠)的动作。
另一种是提取驾驶员整张脸的全局特征,进而识别驾驶员的面部表情。例如文献[15]提出一种以softmax损失与中心损失相结合的深度卷积神经网络算法用来提取驾驶员面部疲劳特征,在自建测试集和YawDD数据集上的实验结果显示,该方法能够准确地识别检测驾驶员疲劳表情;文献[26]为了充分利用驾驶员面部特征信息与时间特征,提出一种基于伪3D卷积神经网络与注意力机制的驾驶疲劳检测方法,利用注意力机制进一步分析哈欠、眨眼和头部特征运动,将哈欠行为与说话行为动作很好地区分开来。
在目前的研究成果中,大部分研究者通常使用关键点定位法或者根据人脸“三庭五眼”的分布特征,来获取人脸局部区域,随后将其获取的局部区域送入特征提取网络来进行特征提取;将整张脸输入到特征提取网络中,进而提取驾驶员面部疲劳特征或者眼睛、嘴巴状态的方法较少。这两类提取方法的流程如图13所示。
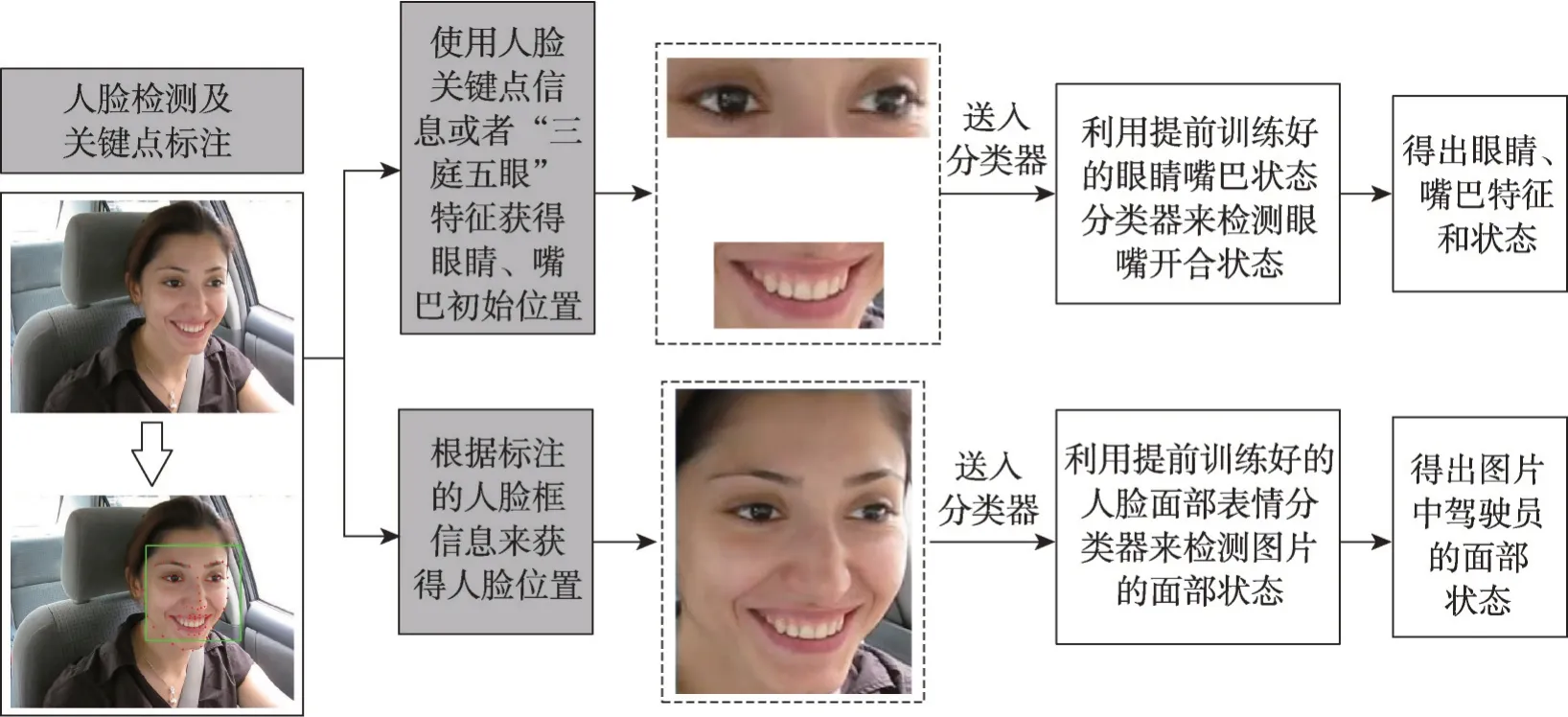
图13 基于深度学习的特征提取方法Fig. 13 Feature extraction method based on deep learning
3.2.3.1 眼睛特征提取
在进行眼睛特征提取时,研究者将提前训练眼睛状态分类器。在训练眼睛状态分类器时,需要事先准备大量不同眼睛状态的数据集,包括闭眼数据集、睁眼数据集以及半闭眼数据集,如表9所示。
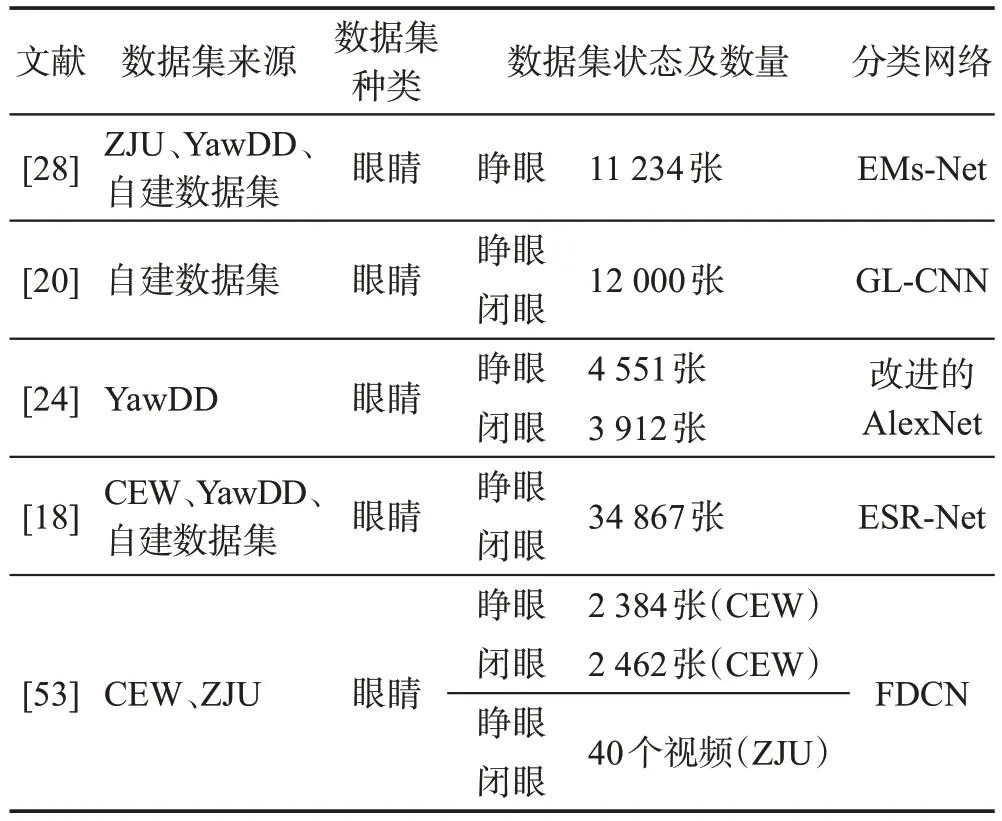
表9 基于深度学习的眼睛特征提取方法Table 9 Eye feature extraction methods based on deep learning
3.2.3.2 嘴巴特征提取
与眼睛特征提取方法类似,在进行嘴巴特征提取时,也需要提前训练嘴巴状态分类器。训练嘴巴状态分类器时,也需要事先准备大量打哈欠、正常说话以及闭嘴状态下的嘴部图片数据集,如表10所示。
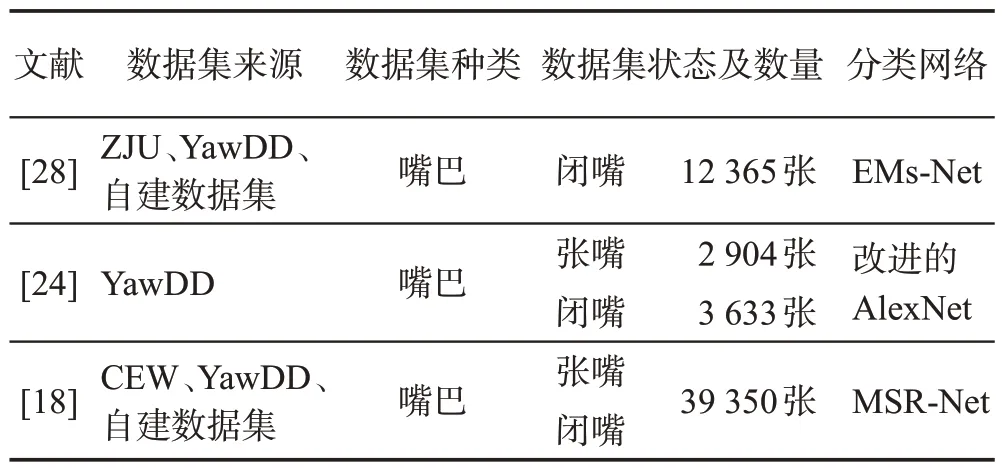
表10 基于深度学习的嘴巴特征提取方法Table 10 Mouth feature extraction methods based on deep learning
3.2.3.3 面部表情特征提取
有部分研究者表明,人脸面部表情也能够表明驾驶员是否存在疲劳驾驶。当驾驶员打哈欠、闭眼时,此时的面部表情与清醒状态下的面部表情存在一定的差异。因此,有研究者将整张人脸区域送入CNN 中进行驾驶员面部表情的提取。与眼睛、嘴巴特征提取同理,在进行驾驶面部表情特征提取时,需要提前训练面部表情分类器。在疲劳驾驶检测领域,该表情分类器可分为四类表情:清醒、说话、大笑和疲劳等。因此,在训练表情分类器时,需要事先准备好大量清醒、说话、大笑以及疲劳状态下的人脸图像,如表11所示。
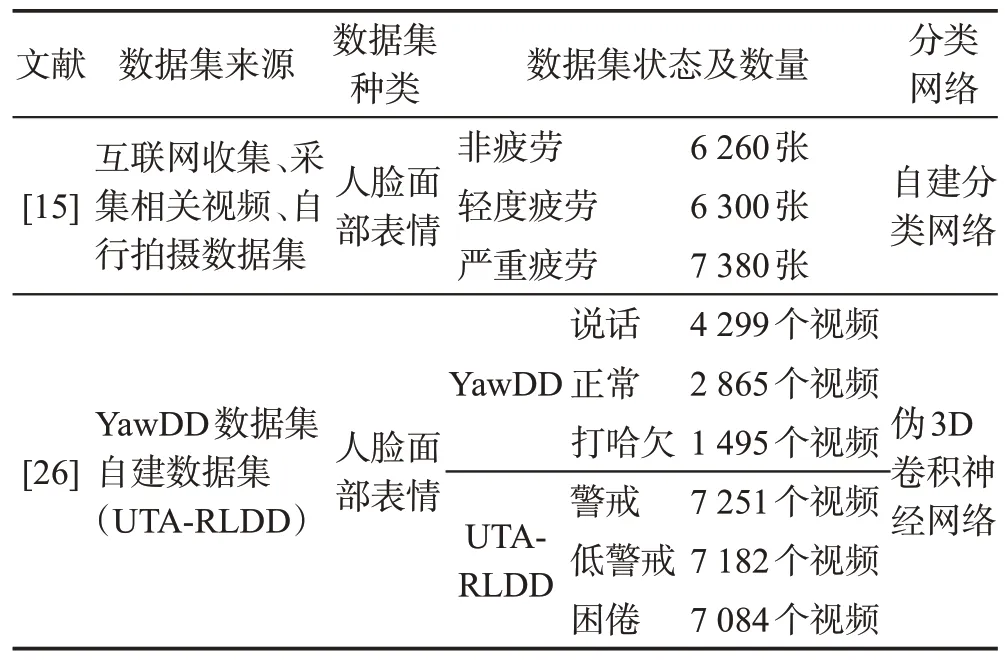
表11 基于深度学习的面部表情特征提取方法Table 11 Facial expression feature extraction methods based on deep learning
3.2.3.4 基于深度学习的特征提取方法小结
综上所述,无论是进行眼睛、嘴巴特征的提取还是面部表情特征的提取,该方法都需要提前训练好一个分类网络来识别驾驶员的局部或者全局特征。因此需要预先准备大量的数据集,才能在复杂环境下获得更有效的疲劳特征。
从表9~表11 可以看出,该类方法在特征提取方面使用的数据集的来源、种类以及数据集状态较为相似,虽然所使用的分类网络大不相同,但对分类网络的选择并没有统一的标准。分类网络的选择可以根据疲劳驾驶检测需要,结合疲劳驾驶检测实时性要求以及提取特征能力等方面进行考虑。研究者们可以在原有网络的基础上进行改进或者设计一个新的网络,有关深度学习目标检测算法的改进可参考文献[54-55]。
虽然基于深度学习的特征提取方法是目前较为流行的方法之一,但目前仍旧存在以下问题:
(1)从上述表中可以看出,大部分研究者在使用该类方法提取人脸特征时,只将人眼(嘴巴)数据集状态分为完全睁眼(张嘴)和完全闭眼(闭嘴)两类,但驾驶员的眼睛有大小之分,因此,若在训练分类模型时,所使用的数据集不够全面,未考虑驾驶员的个性化问题,那么训练出来的模型的鲁棒性以及泛化能力将会较弱,且模型通用性不强。
(2)目前,大部分研究者仅仅是提取驾驶员眼睛和嘴巴的疲劳特征,但除了眼睛和嘴巴之外,脸部其他位置也能够反映出来驾驶员的疲劳状态[18]。因此,后续研究者也可以考虑除眼睛、嘴巴之外的面部特征。
3.2.4 小结
现阶段,上述三种特征提取方法依然被广泛应用于疲劳驾驶检测领域,其优缺点如表12 所示。表13总结了几篇具有代表性的疲劳驾驶检测方法的优势和所存在的局限性。

表12 三种特征提取方法的优缺点Table 12 Advantages and disadvantages of three feature extraction methods
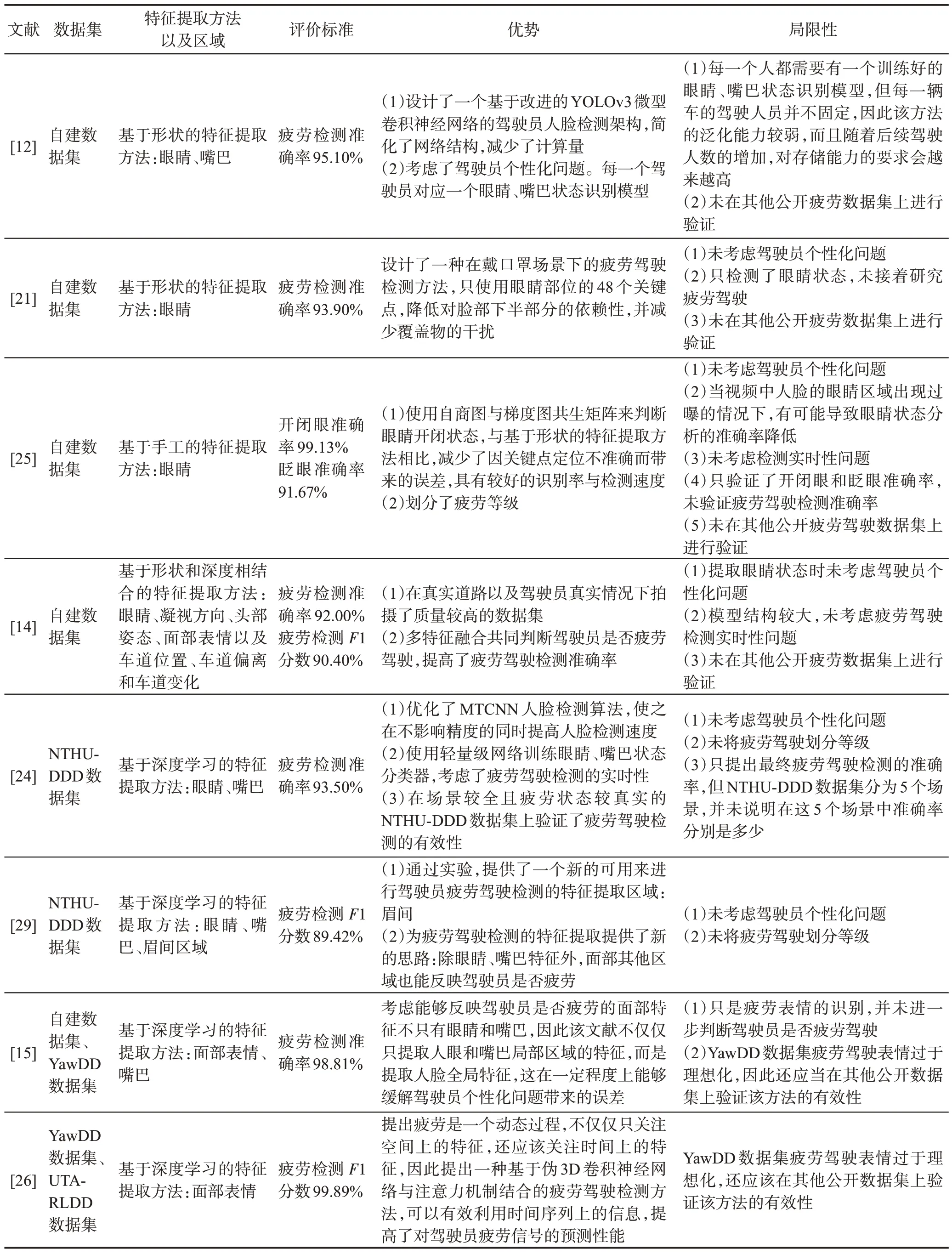
表13 基于驾驶员面部特征的疲劳驾驶检测方法Table 13 Fatigue driving detection methods based on driver‘s facial features
近几年,虽然随着深度学习以及计算机视觉技术的发展,基于深度学习的特征提取方法逐渐成为了研究热点,但从表12 和表13 可以看出,上述三种方法各有优缺点,都还有很大的研究空间。
3.3 疲劳驾驶预测
3.3.1 疲劳判别参数
一段时间内眼睑闭合覆盖瞳孔的面积百分比(percentage of eyelid closure over the pupil over time,PERCLOS)是最权威的疲劳判别参数,也是最主流的参数之一[56],它是卡内基梅隆研究所经过反复实验和论证,提出的度量疲劳或者瞌睡的方法。其定义为单位时间内眼睛闭合一定比例所占的时间,计算公式如式(7)所示:
其中,NCloseFrame为单位时间内的闭眼帧数,NTotalFrame为单位时间内的总帧数。
PERCLOS 通常用P80、P70 和EM 来判断眼睛是睁开还是闭合,具体标准如下:
(1)P80:眼睑覆盖瞳孔的面积超过80%就判定眼睛为闭合状态,统计在单位时间内眼睛闭合所占总时间比例。
(2)P70:眼睑覆盖瞳孔的面积超过70%就判定眼睛为闭合状态,统计在单位时间内眼睛闭合所占总时间比例。
(3)EM(EYEMEAS):眼睑覆盖瞳孔的面积超过一半就判定眼睛为闭合状态,统计在单位时间内眼睛闭合所占总时间比例。
受PERCLOS疲劳参数的启发,有学者提出了新的眼睛状态疲劳参数。由于PERCLOS 参数只是计算单位时间内眼睛闭合帧数占检测时间段总帧数的百分比,文献[12]提出检测单位时间内眨眼次数的百分比也能准确反映出驾驶员的疲劳状态。并通过实验证明了此疲劳参数相较于PERCLOS参数,检测疲劳驾驶状态的准确率得到了提升。此疲劳参数的公式如式(8)所示:
其中,NEyeBlink为眨眼的次数,T为总时间。
借鉴应用到眼睛状态上的疲劳参数,将单位时间内打哈欠的次数作为嘴巴状态的疲劳参数[28]。嘴巴状态的疲劳参数公式如式(9)所示:
其中,NYawn为打哈欠的次数,T为总时间。
凝视方向的疲劳判断参数定义为单位时间内出现视线下移或偏移的帧数占单位时间内总帧数的百分比[14],如式(10)所示:
其中,NDownGazeFrame为单位时间内视线偏移或者下移的帧数,NTotalFrame为单位时间内的总帧数。
面部表情的疲劳判别参数定义为单位时间内出现疲劳表情的帧数占单位时间内总帧数的百分比[14]。其面部特征的疲劳判断参数如式(11)所示:
其中,NFatigueFrame为单位时间内出现疲劳表情的帧数,NTotalFrame为单位时间内的总帧数。
上述提出的疲劳判别参数都是疲劳驾驶检测中经常被使用的,研究者们应根据所研究驾驶员面部特征的实际情况选择。另外也可以使用多指标融合来进行疲劳驾驶检测的判别,例如使用式(7)和式(8)共同作为眼睛状态的判别参数。
3.3.2 疲劳驾驶结果预测
当驾驶员出现疲劳状态时,一般情况下,驾驶员会出现第1 章中所提到的疲劳驾驶面部表现。因此疲劳驾驶应为一个连续性的动作,仅仅只凭借一帧图片的特征并不能判定驾驶员存在疲劳驾驶的行为。另外当驾驶员出现交谈的行为时,其和打哈欠的行为是非常相似的,都有张嘴和闭嘴的行为。驾驶员在清醒状态时也会存在眨眼的行为,也会出现睁眼和闭眼的状态。因此,需要有一个指标来评价驾驶员是否疲劳驾驶。
目前,大多数研究者往往根据3.3.1 小节中提到的疲劳判别参数,统计一段时间内驾驶员眼睛闭合帧数、眨眼次数、嘴巴张开帧数、哈欠次数以及出现疲劳状态帧数等所占总时长的比例,然后结合第1章提到的疲劳驾驶面部特征表现来判断驾驶员是否疲劳驾驶[57]。
但判断驾驶员是否进行了一个眨眼动作或者打哈欠的动作时,必须要提取驾驶员睁眼时的特征,还要提取到驾驶员闭眼时的特征,整个过程才是一个眨眼过程。因此,有关学者认为只关注空间特征的方法忽略了疲劳特征的时间信息和特征之间的关系,会降低识别的准确率。针对该问题,一部分研究者使用3D神经网络[26-27]、LSTM网络[29]以及递归神经网络[57]等网络用来获取特征的时间信息。该类方法不会只关注空间上的特征,还会关注帧与帧之间的时间特征。该方法在提取特征时,会将提取到的每一帧特征连接起来,最终呈现出一个大的特征向量,然后送入分类网络。此时分类网络输出的结果不再是睁眼、闭眼、张嘴以及闭嘴等,而是输出结果为眨眼和打哈欠等。
虽然考虑时间信息的方法结合了驾驶员空间以及时间特性,但该类方法所使用的网络一般较复杂,在时间开销上较大,且并未有具体且全面的实验表明考虑时间信息的方法在实时性、实用性以及模型轻量化等方面相较于只提取空间特征的方法会有较为明显的优势。而且该类方法在判断驾驶员是否疲劳驾驶结果时依旧需要在疲劳判别参数的基础上进行。因此,在后续的研究中,还需要使用大量实验证明考虑时间信息方法是否在各方面都具有较为明显的优势。
3.4 总结
本节分析总结了疲劳驾驶检测流程中关键步骤所常用的方法以及现存的优缺点。在疲劳驾驶检测模型的选择中,研究者应该从以下两方面考虑:
(1)实时性。对驾驶员来说,疲劳驾驶检测系统能够快速响应,及时地给驾驶员提醒是十分重要的。因此这就要求所选模型应当轻量化。
(2)准确性。疲劳驾驶检测结果应该尽可能准确,尽量避免出现误检、漏检的情况。
因此,若要兼顾上述两方面,每个步骤方法或者模型的选择就需要从宏观上来考虑。
在人脸检测模型选择上,应该考虑的重点方面是模型实时性、准确率以及标注的人脸区域的精准性(非人脸区域面积占比较少)。比较理想的人脸检测模型应当满足实时性好、准确率高以及标注的人脸区域精准。但往往一个模型并不能同时兼顾这三方面,因此需要结合特征提取方法来进行选择。
由3.2 节可知,特征提取方法分为三类:基于形状的特征提取方法、基于手工的特征提取方法以及基于深度学习的特征提取方法。
基于形状的特征提取方法速度较快,但是对人脸关键点的标注要求较高,越标准的人脸姿态,人脸关键点标注得越精准。因此在选择人脸检测算法时,应当选择一些人脸检测准确率较高和带有人脸矫正功能的算法。该类算法一般结构较复杂,因此实时性较差,但基于形状的特征提取方法速度较快,可以弥补人脸检测算法的缺点。
基于手工的特征提取方法速度稍慢于基于形状的特征提取方法,且其对图像质量要求较高,受光照等环境因素影响较大。因此在人脸检测算法的选择上,可侧重于选择准确率较高、实时性稍好且标注的人脸区域较精准的算法。
基于深度学习的特征提取方法由于对图像质量要求不是特别高且提取结果较好的优点,尤其是基于CNN 的特征提取方法,成为目前研究者使用最多的方法。目前大部分基于CNN的特征提取方法精度较高,但由于网络结构较深,实时性较差。因此在选择人脸检测算法时,应选择一些实时性较好的算法。但在真实驾驶环境下,驾驶员的人脸一般会占据图片的主要区域,因此也可以考虑使用轻量型网络来实现人脸特征提取及分类。而此时在人脸检测算法的选择上,可以使用一些功能较全面的算法。
另外,在后续的疲劳驾驶预测时,在进行疲劳判别参数的选择时,多个参数共同进行疲劳驾驶的判别要比单参数判别较好,因此可以使用多参数共同进行疲劳的判别。例如,眼部状态可以使用PERCLOS参数和眨眼次数共同来进行眼部疲劳的判别。同理,嘴部状态也可以使用多参数共同判别。
综上所述,在驾驶员的疲劳驾驶检测中,人脸检测算法的选择和特征提取方法的选择尤为重要。因此,在后续研究中,研究者根据实际情况为每一步选择合适的方法,使得最终模型兼顾实时性和准确性。
4 未来展望
随着计算机视觉的发展,基于驾驶员面部特征的疲劳驾驶检测在疲劳驾驶检测领域成为了大量学者的研究热点,本文根据基于驾驶员面部特征的疲劳驾驶检测流程,总结了常用数据集的优缺点以及适用范围,整理分析了近几年检测流程中关键步骤所使用的方法技术。虽然基于驾驶员面部特征的疲劳驾驶检测已有很多研究成果,但目前依旧面临着很大的挑战,主要问题可概括为以下几个方面:
(1)数据集。如第2 章提到的,目前公开免费且使用较多的数据集仅有三种。这三种数据集各有优缺点,但这三种数据集都存在一个很严重的问题,即数据集的真实性。YawDD虽然拍摄环境是真实的车内环境,有一些哈欠数据集存在明显摆拍痕迹;NTHU-DDD数据集是这三种数据集中最全面的数据集,包括了很多的疲劳动作,虽然也是摆拍视频,但是驾驶员疲劳或者清醒的状态较真实,该数据集拍摄环境并不是真实的车内环境,且夜间的数据集是在夜间照明情况下拍摄的,很多驾驶员在夜间行驶时并不会打开照明等;有一些质量较好的数据集,目前仍未公开。目前在疲劳驾驶检测领域最主要的问题就是缺乏真实且全面的数据集,这将为后续研究带来很大的阻力。
(2)驾驶员个性化问题。在疲劳驾驶检测的研究中,多数研究者只将关注重点放在检测驾驶员的眨眼频率以及打哈欠频率上,但由于每个驾驶员眼睛大小以及嘴巴大小各不相同,虽然有研究者提出提取驾驶员脸部的全局特征或者除眼睛、嘴巴之外的局部特征来解决驾驶员个性化的问题,但在数据集的选择上只有疲劳特征较明显的数据(打哈欠时的数据),并没有在各种疲劳状态时做大量实验来证明该方法的通用性。
(3)人脸检测问题。在基于形状的特征提取方法中,需要利用精准的人脸关键点才能准确计算出眼睛和嘴巴的纵横比。但如果驾驶员被摄像头拍摄到的不是正脸区域,只是一个侧脸区域,这往往会导致驾驶员人脸关键点标注不准确,从而导致驾驶员面部特征提取不够精准。基于手工的特征提取方法和基于深度学习的特征提取方法虽然可以不使用人脸关键点,但这两类方法仍然需要一个较精准的正脸区域。
(4)疲劳过程的检测。目前,在疲劳驾驶检测领域的研究中,大部分学者使用的方法是提取每一帧图片中驾驶员的面部疲劳特征,提取完连续多帧面部疲劳特征后,根据疲劳判断参数来判断驾驶员是否存在疲劳驾驶的风险。但疲劳驾驶也是一个面部表情发生变化的过程问题,虽然有一些学者提出检测驾驶员一段视频中的眨眼和打哈欠动作,并在一些数据集上取得了不错的成果,但目前在这方面的研究成果还是较少,且使用的数据集都是较为理想状态下的数据集,而且该方法模型结构一般较大。
(5)疲劳眨眼检测。目前,大部分研究者都是通过统计一段时间内的眨眼或者打哈欠的次数来判断驾驶员是否存在疲劳驾驶风险。但有一些驾驶员习惯于频繁眨眼,因此,并不能仅把眨眼次数算作疲劳检测的标准。
因此,在后续研究中,可通过以下方法来解决上述问题。
(1)数据集。在后续研究中,希望更多研究者可以将自建数据集对外公开;另外,在后续拍摄数据集时,为了数据集的真实性,拍摄过程中可随时对驾驶员进行问卷调查,以此来确定驾驶员当前的驾驶状态,进而对拍摄的数据集打标签。
(2)驾驶员个性化问题。在后续研究中,有三个待研究的方向:一是使用基于形状的特征提取方法,通过设定个性化阈值来解决该问题;二是探究除眼睛和嘴巴之外的可以体现驾驶员疲劳的脸部区域,例如人眼的凝视方向、面部表情的编码等;三是完善实验设计,来证明一些研究者所提方法的通用性以及有效性。
(3)人脸检测问题。在后续研究中,当摄像头拍摄到的驾驶员图像是侧脸时,可考虑使用3D建模、生成式对抗网络(generative adversarial networks,GAN)等技术,通过驾驶员的侧脸生成驾驶员正脸图像。
(4)疲劳过程的检测。在后续的研究中,学者们可通过使用高质量的数据集来验证一些学者提出检测驾驶员一段视频中的眨眼和打哈欠动作方法的优点,另外,在保证方法的准确率的情况下研究轻量型的网络。
(5)疲劳眨眼检测。大量研究表明,当一个人存在缓慢眨眼时,很可能存在疲劳驾驶的风险。因此,在后续研究中,研究者们可以尝试通过统计缓慢眨眼的次数来作为驾驶员是否疲劳的标准。
