自适应约束评估的代理模型辅助演化算法
2023-06-07魏凤凤陈伟能
魏凤凤,陈伟能+
1.华南理工大学 计算机科学与工程学院,广州510006
2.华南理工大学 大数据与智能机器人教育部重点实验室,广州510006
演化算法(evolutionary algorithms,EAs)是求解复杂优化问题的常用方法,在求解传统约束优化问题中有很好的效果[1-3]。然而在很多工程问题中,目标和约束的计算没有明确的公式表达,需要仿真软件模拟,甚至真实实验才能获得结果,这样一次复杂目标和约束值的计算过程需要花费几个小时甚至几天,例如,一次20~50 维的毫米集成电路的仿真需要花费20~30 min[4],这类问题被称为昂贵优化问题。
传统EAs 往往需要进行上万甚至几十万次适应值评估才能得到满意解,在求解昂贵优化问题中的时间代价是难以接受的。因此学者们提出基于代理模型辅助的演化方法(surrogate-assisted evolutionary algorithms,SAEAs)[5-6],使用较少的历史数据建立模型,用模型预测结果替代演化过程中真实适应值评估,从而降低时间成本,获得满意的优化结果。
当前SAEAs在求解昂贵无约束优化问题中已有较好发展[7-10],但在处理昂贵约束优化问题方面仍有待研究。Sasena 等人比较了在高斯过程回归模型的辅助下,现有的不同样本选择准则的性能差异[11];Yannou 等人利用表面响应模型来拟合约束,并在约束编程环境中调研模型保真度和由此产生的约束可处理性之间的关系[12];Singh 等人将代理模型嵌入到模拟退火算法来求解多目标昂贵约束优化问题[13];Regis等人提出一种解决昂贵约束优化问题的径向基函数辅助进化编程算法[14];Singh 等人提出一种利用不可行解进行驱动的进化算法来求解软约束和硬约束混合的优化问题[15]。上述工作是将代理模型应用到昂贵约束优化问题中的早期尝试,通过对昂贵约束进行建模,减少算法的昂贵评估,使算法在可接受时间内完成对问题的优化。
虽然模型的使用提高了算法运行效率,但模型拟合的不准确性也降低了算法性能。为了提高SAEAs 在昂贵约束优化问题的求解质量,一些学者对模型管理策略进行研究,他们通过利用模型进行样本选择[16-18]、设计排序和修正策略[19-20]提高模型预测结果的可靠性及加入局部选择和局部搜索[21-22]等策略来提高代理模型对约束的处理能力。上述工作聚焦于将多目标处理技术与代理模型有机结合,展现了SAEAs求解昂贵约束优化问题的巨大潜力。
然而,上述工作对所挑选的候选解都要进行所有约束的昂贵评估,导致耗费大量不必要的计算代价。在一些问题中,最优解往往被某个或某几个约束的可行域限制,其他约束可行域非常大。在这种情况下,对每个挑选的候选解都真实评估可行域非常大的约束是不必要的;尤其当可行域大的约束数量较多的时候,对这些约束进行真实评估是浪费计算时间和有限评估次数的。因此,如何进行评估资源与昂贵约束的分配是影响算法性能的关键,直接关系到算法设计中两个亟需解决的难点:
(1)个体的选择。如何根据模型预测结果选择对优化有帮助的个体进行昂贵评估,引导种群向优质区域演化。
(2)约束的选择。如何选择可行域信息较少的约束进行更多的评估和信息补充,加快算法对可行域的探索。
为解决评估资源与昂贵约束的分配问题,本文提出一种自适应约束评估策略,并从两个思路出发,设计了两种自适应约束评估的高斯过程回归模型辅助差分进化算法,在少量昂贵评估下完成对问题的优化,验证自适应约束评估策略的有效性和通用性。文章的主要贡献点如下:
(1)提出一种自适应约束评估策略,自适应地根据种群信息进行个体选择、约束选择和昂贵评估。在演化过程中,并非对挑选候选解的所有约束进行昂贵评估,而是评估当前种群中可行域信息较少的约束,节省的评估次数可以用来进一步演化。因此,不同的候选解消耗的真实评估次数不同,并且随着种群的演化而自适应动态变化。
(2)从代理模型辅助无约束演化方法思路出发,通过加入自适应约束评估策略和约束处理技术,设计一种自适应约束评估的约束优化高斯过程回归模型辅助的演化算法。
(3)从无代理模型辅助的传统约束优化演化算法思路出发,通过加入自适应约束评估策略和代理模型技术,设计一种自适应约束评估的代理模型辅助的复合约束差分进化算法。
在实验方面,本文以约束优化问题标准测试集CEC2006 和四个工业应用为测试实例,验证自适应约束评估策略及两种自适应约束评估SAEAs的有效性,展示其在工业中良好的发展前景;在理论方面,本文从性能提升和效率提升两方面进行分析,并对两种自适应约束评估SAEAs进行对比分析。
1 相关工作
约束优化SAEAs主要由模型管理、演化算法、约束处理三部分组成,本章对昂贵约束优化问题和三个算法部分使用的方法作简要介绍。
1.1 昂贵约束优化
通常情况下,一个单目标最小化约束优化问题可以由下式表达:
其中,x是一个D维变量,ld和ud分别是每一维的取值上下界;f(x)是目标函数,y是需要优化的目标值;G(x)是需要满足的约束违反程度,由一个或多个不等约束和等式约束组成,其计算方法如下:
其中,g(x)是需要满足的q个不等约束,h(x)是需要满足的m-q个等式约束。一般情况下,g(x)≤0 表示x对于不等约束条件的满足;h(x)=0 表示x对于等式约束条件的满足。对于变量x,当且仅当满足所有约束时,该变量称为可行解,此时,约束违反程度G(x)≤0;若变量x违反至少一个约束,则该变量称为不可行解,此时,约束违反程度G(x)>0。
在一些现实问题中,f(x)和G(x)需要通过仿真软件模拟甚至真实实验获得,计算代价是非常昂贵的。在这种情况下,用传统EAs通过大量真实评估寻优所花费的时间代价非常大。为解决这个问题,代理模型被结合到演化过程中降低真实评估次数。由于模型的训练和预测时长与真实评估相比可以忽略不计,这种方法能够在可接受时间内获得优化解,在解决昂贵优化问题中有广泛应用。
1.2 高斯过程回归
在SAEAs 演化过程中,后代质量的评估绝大部分依赖于模型。现有的SAEAs 大部分使用回归模型,高斯过程回归模型备受关注[6,23-25]。
高斯过程回归模型是一种广泛使用的监督学习模型[26],它将多元高斯分布拓展到高维。假设一个含有n个样本的D维数据集Y={f(x1),f(x2),…,f(xn)},每个点都满足高斯分布N(μ,σ2),其中μ是期望,σ是标准差。不失一般性,假设μ=0。对数据集中的任意两点x1和x2,它们之间的相关性仅依赖于x1-x2,即:
其中,参数pd∈[1,2],控制每一维变量与f(x)的平滑度;θd>0 控制每一维变量的权重;更多细节可以参照Rasmussen的文章[27]。
在求解最小化优化问题中,高斯过程回归的结果一般取置信下界。假设预测结果满足分布N(f′(x),s(x)2),则该分布置信下界为:
其中,ω是一个常量,通常设置为2[28]。
由于高斯过程回归模型的有效性,本文采取该模型作为辅助,分别对目标和每一个约束训练一个高斯过程回归模型;对于产生的候选解进行质量预测,根据自适应约束评估策略进行真实评估,并更新模型,以提高模型的训练质量,更好地引导种群进化。
1.3 差分进化算法
演化算子是算法的核心部分,直接影响算法的探索和开发能力。本文采用一类基于群体的启发式算法——差分进化算法[29-30]。
差分进化算法框架如图1所示,包括变异、交叉、选择。首先,算法开始前初始化参数及种群;然后,种群中每个个体通过变异操作产生变异个体;变异个体通过交叉操作产生试验个体;最后,试验个体作为后代与父代比较并选择较好个体进入下一代。

图1 差分进化算法框架Fig. 1 Framework of differential evolution algorithm
根据变异操作的不同,差分进化算法可分为不同的版本,本文涉及的进化算子有:
(1)DE/best/1
在交叉操作中,本文用到的是二项交叉来产生试验个体,过程如下:
差分进化算法在解决传统约束优化问题中应用非常广泛,且求解效率和质量非常高[31-33],本文使用该算法作为演化算子对搜索空间进行开发和探索。
1.4 约束处理技术
约束处理技术大致可以分为四类:基于惩罚函数的方法、基于支配准则的方法、基于多目标优化的方法和混合方法。下面介绍本文用到的基于惩罚函数的方法和基于支配准则的方法。
1.4.1 基于惩罚函数的方法
基于惩罚函数的方法是指将约束违反程度转换为惩罚因子加到目标值上,将约束优化问题转化为无约束优化问题。本文参照一种多目标约束优化问题中的基于惩罚函数的约束处理技术[34],首先将目标值和约束值进行如下归一化处理:
rf是当前种群的可行解比例。惩罚项目标值F(x)为:
根据上述计算公式可得,惩罚目标值F(x)能够根据种群中可行解比例调整对目标和约束的侧重。当种群中可行解个数较少时,惩罚目标值中约束所占比重较大,有利于种群继续搜索可行域;当种群中可行解个数为0 时,惩罚目标值即个体约束值,种群只进行可行域的搜索。当种群中可行解个数较多时,惩罚目标值中目标所占比重较大,有利于种群开发可行域;当种群中所有个体均为可行解时,惩罚目标值即个体目标值,种群只进行目标的优化。由于该方法能够调整对目标和约束的演化侧重,并且在求解约束问题中有较好的性能表现[34],本文选择该方法作为一种约束处理技术。
1.4.2 基于支配准则的方法
基于支配准则的约束处理方法主要有可行解支配准则和ε约束支配准则。可行解支配准则内容为:(1)可行解优于不可行解;(2)同为不可行解,约束违反程度小的个体优于约束违反程度大的个体;(3)同为可行解,目标值好的个体优于目标值劣的个体。由此可见,可行解支配准则倾向于保留可行解,不能有效利用目标值有重要意义的不可行解,不利于处理某些最优解在可行域边缘的问题。ε约束支配准则对其改进,根据种群进化情况可以自适应地调整对不可行解的保留程度:对于两个不同的个体,满足下列关系之一时,x1优于x2:
其中,ε0是初始种群的最大约束违反程度,T是最大进化代数,t是当前进化代数,λ是常数,设置为6;p是控制目标值开发的参数,设置为0.5。由于考虑了可行域周围的不可行解,ε约束支配准则能够有效利用目标值较好的不可行解帮助对可行域的探索。
可行解支配准则能够综合目标值和约束值对个体进行最直接的优劣排序,是求解约束优化问题中最常用的方法之一[3,21,32-33],因此本文选择该方法作为一种约束处理技术。
2 自适应约束评估策略
在设计约束优化SAEAs 时,核心问题是个体选择和约束处理,本文提出一种新的自适应约束评估策略,其具体实现过程如算法1所示。
算法1自适应约束评估策略伪代码
在自适应约束评估策略中,除维护一个全部真实评估个体数据集DBf之外,还需维护一个部分真实评估个体数据集DBp,用来保存部分约束完成真实评估、部分约束只有预测值的个体。相对应地,该策略主要包括两部分,部分评估个体选择和全部评估个体选择。自适应约束评估策略的步骤如下:
首先,判断当前代数需进行哪一种选择。若当前代数需进行部分评估个体选择,在产生的后代中选择被预测为支配最优的个体,并初始化需进行真实评估的约束集合J为空。针对每一个约束j,按照式(21)计算当前种群在该约束可行域比例r,其中,Nfea是种群在该约束可行域内的个体数量,NP是种群大小。
同时,设置需进行真实评估的约束可行比例阈值thr=0.5。若r<thr,则将该约束的索引加入到需真实评估的约束索引集合J中;否则不需加入。对所有约束判断完之后,将所选个体xsel按索引集合J进行真实评估,未进行真实评估的约束保留预测值。由此,该个体便成为了部分评估个体,被加入到部分评估个体数据集DBp,更新已消耗的真实评估次数fes。
若当前代数需进行全部评估个体选择,则从DBp中根据1.4.1小节的惩罚函数方法挑选最优的部分评估个体,标记该个体未被真实评估的约束,对这些约束及目标进行真实评估。由此,该个体便成为全部评估个体,从DBp中删除并加入到全部评估个体数据集DBf,更新消耗的真实评估次数fes。
在自适应约束评估策略中,需进行信息补全的代数Gap是一个重要的参数,它决定着算法进行种群和代理模型更新的频率。Gap值越大,算法要消耗越多的真实评估次数来进行部分约束评估,导致种群和代理模型更新缓慢,有效演化大大减少;极端情况下,当Gap值大到种群完全没有信息补全,则算法终止后没有任何全部评估的新个体产生,无法得知DBp中是否有更好的解,这种无效优化是不可取的。Gap值越小,种群和代理模型更新越快,导致算法在可行域信息较多的约束上频繁消耗昂贵评估,不能在可行域信息较少的约束上节省真实评估次数而使种群进行更多代演化;特别地,当Gap值为1 时,与大多数约束优化SAEAs 一致,算法对每个被选择的个体进行所有约束和目标值的真实评估。因此,Gap值的设置对算法的演化影响较大,如何对该变量进行合适设置有待于进一步研究。在本文中,由于真实评估次数较少,且测试问题的约束数量不同,根据实验性能设置Gap=10。
自适应约束评估策略的自适应特性主要体现在对约束选择方面。与其他约束处理不同,自适应约束评估策略旨在对不同约束进行区别对待,仅对可行域信息较少的约束进行真实评估,即计算当前种群在每个约束的可行域比例,当且仅当该比例小于阈值thr时,选择该约束进行昂贵评估。thr是一个重要的参数,根据4.3节参数调研结果设置;同时,参数调研实验显示,在演化前期,不能达到阈值thr的约束较多,这些约束均被选择进行昂贵评估;随着演化的进行,种群逐渐掌握更多可行域信息,达到阈值thr的约束较多,被选择进行昂贵评估的约束变少;当种群完全在可行域内时,在每个约束的可行域比例均为1,不需要选择约束进行昂贵评估。因此,在整个演化过程中,被选择进行昂贵评估的约束是一个自适应变化的过程。
另外,为了掌握所选解的全部约束及目标信息,提高种群掌握信息的准确性和更新训练代理模型,每隔Gap代进行全部评估个体选择,从部分真实评估个体数据集DBp中选择个体进行信息补全,即真实评估仍保留的预测值信息;该选择基于1.4.1 小节所描述的基于惩罚函数的方法,目的是使算法根据当前种群的可行域信息调整对目标和约束的演化侧重。
3 自适应约束评估的约束优化SAEAs
3.1 框架
本文提出了一种自适应约束评估策略,并从两个思路出发设计了两种基于自适应约束评估策略的约束优化SAEAs。
思路1从无约束SAEAs 出发,通过加入约束处理技术和自适应约束评估策略,设计一种基于自适应约束评估策略的约束优化算法,详见3.2节。
思路2从约束优化EAs 出发,通过加入高斯过程回归模型辅助和自适应约束评估策略,设计一种基于自适应评估策略的代理模型辅助约束优化算法,详见3.3节。
这两种基于自适应约束评估策略的约束优化SAEAs 流程框架如图2 所示。首先用拉丁超立方采样(Latin hypercube sampling,LHS)初始化样本作为已知数据并加入数据库DBf中;在算法终止前,从DBf中按照可行解支配准则选取最优的NP个个体组成种群,通过演化算子产生后代;用DBf中最优的NT个数据训练目标和约束模型,并对后代进行预测;按照自适应约束评估策略进行个体选择、约束选择和昂贵评估,并将个体加入到相对应的数据库中;算法终止时,输出DBf中最优结果。两种算法的具体内容如下。
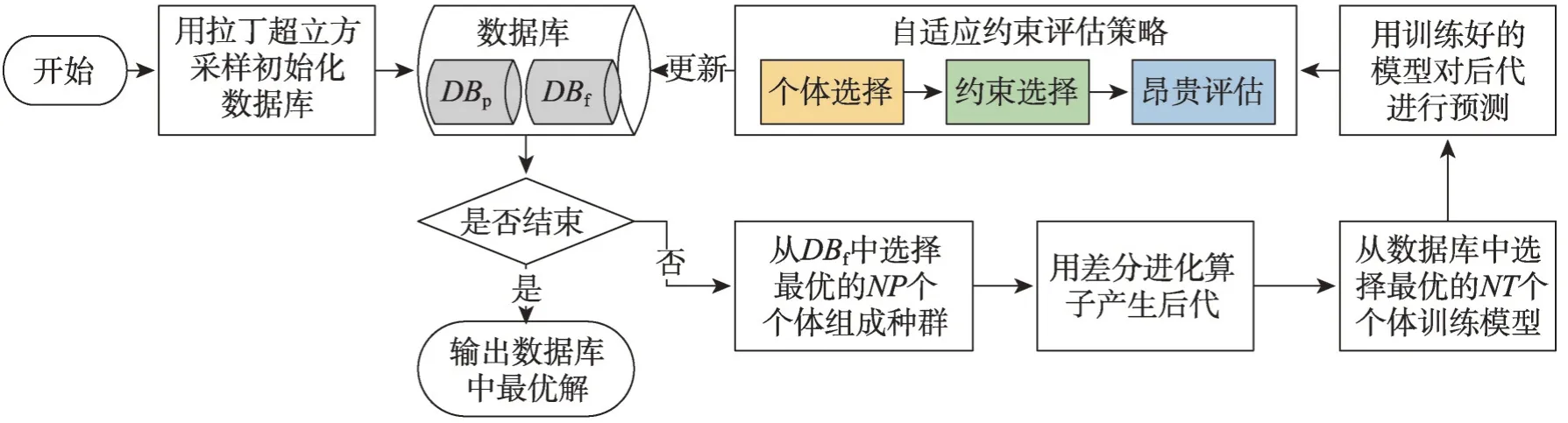
图2 自适应约束评估的约束优化SAEAs框架Fig. 2 Framework of adaptive constraint evaluation aided SAEAs for expensive constrained optimization
3.2 自适应约束评估的约束优化GPEME
本节从基于代理模型辅助的单目标优化方法(Gaussian process surrogate model assisted evolutionary algorithm,GPEME)[7]出发,通过加入约束处理技术和自适应约束评估策略,设计一种自适应约束评估策略的约束优化GPEME(D-GPEME-CH),具体过程如下:
(1)用LHS 从搜索空间中随机采样NT个样本,进行真实评估后加入数据库DBf中。
(2)判断是否达到终止条件,若达到终止条件,则停止算法并输出数据库DBf中最优解;否则跳到第(3)步执行。
(3)选择DBf中支配最优的NP个个体组成种群。
(4)对种群应用DE/best/1算子产生后代。
(5)选择数据库中支配最优的NT个个体组成训练集,对目标和每个约束各训练一个高斯过程回归模型。
(6)用训练好的模型对种群产生的后代进行目标和约束值预测,并执行自适应约束评估策略,更新对应数据库。
在D-GPEME-CH 中,DE/best/1 是全局搜索能力很强的差分进化算法,能够有效开发已知最优区域;自适应约束评估策略能够使算法在可行域较大的约束上节省昂贵评估,在可行域较小的约束进行更多的信息探索,加强对可行域的探索。在高斯过程回归模型的辅助下,该算法能够有效求解昂贵单目标约束优化问题。
3.3 自适应约束评估的代理模型辅助C2oDE
本节从传统单目标复合差分进化约束优化算法(composite differential evolution for constrained optimization,C2oDE)[33]出发,通过加入代理模型辅助技术和自适应约束评估策略,设计一种自适应约束评估策略的代理模型辅助C2oDE(surrogate-assisted C2oDE with adaptive constraint evaluation,D-SA-C2oDE),具体过程如下:
(1)使用LHS 从搜索空间中随机采样NT个点,进行真实评估后加入数据库DBf中。
(2)判断是否达到终止条件,若达到终止条件,则停止算法并输出数据库中最优解;否则跳到第(3)步执行。
(3)选择DBf中支配最优的NP个个体组成种群。
(4)对种群使用复合差分进化算子C2oDE 产生后代,即每个个体使用DE/current-to-rand/1、DE/randto-best/1和DE/current-to-best/1三种差分算子进行演化,拥有三个子代个体。
(5)选择数据库中支配最优的NT个个体组成训练集,对目标和每个约束各训练一个高斯过程回归模型。
(6)对于每个个体产生的三个子代个体,基于高斯过程回归模型的预测目标值和约束值,根据可行解支配准则进行预筛选,保留最好的个体作为后代。
(7)在预筛选的后代中,执行自适应约束评估策略并更新对应数据库。
在D-SA-C2oDE中,复合差分进化算子DE/currentto-rand/1 能够提高种群多样性;DE/rand-to-best/1 和DE/current-to-best/1能够提高种群的收敛速度。可行解支配准则在对后代进行预筛选时,能够取优去劣;ε约束支配准则在对后代进行选择时,能够随着进化程度自适应调整是否保留可行域边缘的不可行解。因此,该算法在自适应约束评估策略和高斯过程回归模型的辅助下能够在可接受时间内对昂贵约束优化问题进行有效求解。
4 实验与分析
本章首先对测试问题进行介绍,说明两种算法参数设置情况;然后通过实验展示自适应约束评估策略的有效性,并在CEC2006 测试集和四个工业优化问题中进行对比实验并分析结果,展示本文设计的两种算法性能;最后从理论方面对性能提升和效率提升进行分析,并对本文从两个思路设计的自适应约束评估SAEAs进行对比分析。
4.1 测试问题简介
CEC2006 是一个单目标约束优化问题标准测试集,包含24个问题,每个问题的维度及约束个数都不相同,具有大部分工业约束优化问题的特征[35],如表1所示。其中,ρ是可行域占整个搜索空间的比例,0.000 0%表示该问题的可行域相对于整个搜索空间的比例小于0.000 1%;LI是线性不等约束个数,NI是非线性不等约束个数;LE是线性等式约束个数,NE是非线性等式约束个数;a指在可行域最优解附近比较活跃的约束个数,该值越大,表示待优化问题的最优值受约束的影响越大。
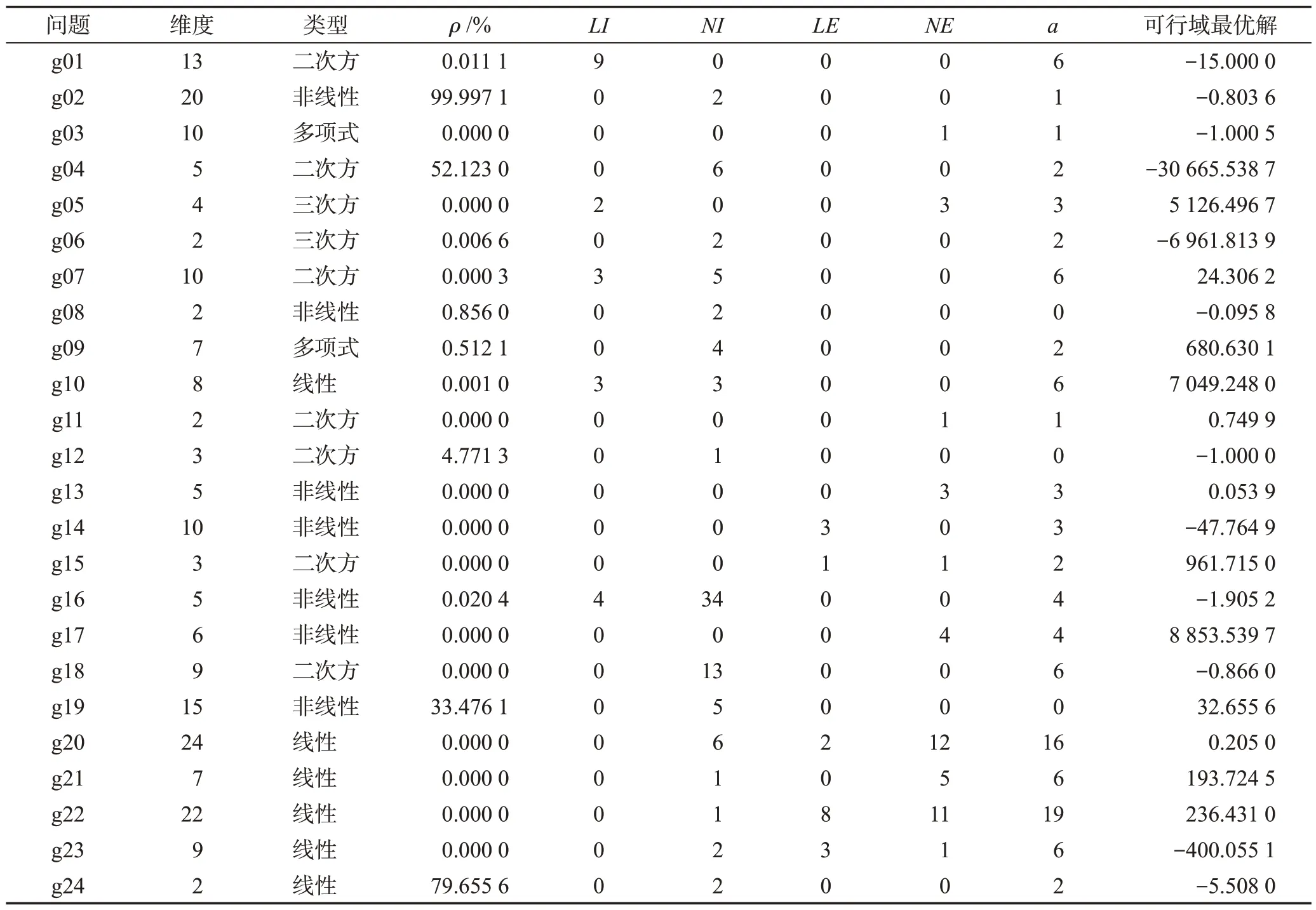
表1 CEC2006测试问题Table 1 CEC2006 benchmark functions
本文测试的工业优化问题包括4个:碟形弹簧设计优化(belleville spring design,BS)、散货船设计优化(bulk carrier design,BCD)、轿车侧面碰撞优化(car side impact design,CSI)和螺旋弹簧设计优化(helical spring design,HS)。BS是一个带有7个不等约束的4维优化问题,BCD是一个带有9个不等约束的6维优化问题,CSI是一个带有10个不等约束的11维优化问题,HS是一个带有9个不等约束的3维优化问题,详细问题介绍可以在文献[36]中找到。目前,这4个问题都没有已知最优可行解。
4.2 参数设置
算法开始前初始化样本量为300;高斯过程回归模型训练集大小NT=300,种群大小NP=50。经参数调研,需进行真实评估的约束可行比例阈值thr=0.5。在D-GPEME-CH中,DE/best/1演化算子的变异概率F=0.8,交叉概率CR=0.8 。在D-SA-C2oDE 中,差分进化算子的变异概率F和交叉概率CR通过参数调研设置为F=0.6,CR=0.7。需注意的是,对目标或约束的单独评估即为消耗一次评估次数。由于对比算法C2oDE 的原文设置种群大小为50,且每一代对产生的50×3个后代进行真实评估[33],若按无约束优化SAEAs[7-8]中常设置的最大评估次数maxFES=1 000,则在该算法中,种群进化代数为1 000/(50×3×(NC+1)),约为7/(NC+1),其中NC为该测试问题的约束个数。然而,由表1中测试问题的约束个数可得,在该设置下,大多数问题仅能演化非常少的代数,有的问题甚至无法完成一代演化,使算法无法对问题进行有效求解。因此,本文设置maxFES=1 000×(NC+1),即最大评估次数由问题的约束个数决定,不同问题的终止条件不同。这个设置是合理的,约束多的问题,可行域较复杂,优化过程相对困难,因此最大评估次数较多;相反,约束少的问题,可行域较简单,优化过程相对容易,因此最大评估次数较少。为保证实验公平性,所有结果均取自25次独立实验的均值。
4.3 参数调研
为调研参数设置合理性,本节调研不同的取值对需进行真实评估的约束可行比例阈值thr和D-SAC2oDE 中差分进化算子的变异概率F、交叉概率CR的影响。不失一般性,本节以函数g01、g02、g06、g07、g09、g19为例,由表1可知,此6个函数能够代表不同类型、不同约束数量的函数。
需进行真实评估的约束可行解比例阈值thr是自适应评估策略中一个重要的参数,它决定着演化过程中哪些约束需要进行真实评估。对于每一个约束,若种群在该约束的可行域个体比例大于thr,则认为种群大部分处于该约束的可行域内,不需要频繁对该约束进行昂贵评估;相反,若种群在该约束的可行域个体比例小于thr,则认为种群大部分处于该约束的不可行域内,需要对该约束进行昂贵评估观察其演化方向。为调研该参数的取值对实验结果的影响,设置thr={0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1.0},在D-GPEME-CH 和D-SA-C2oDE 两种方法分别进行实验并对比分析结果,实验结果如图3所示。
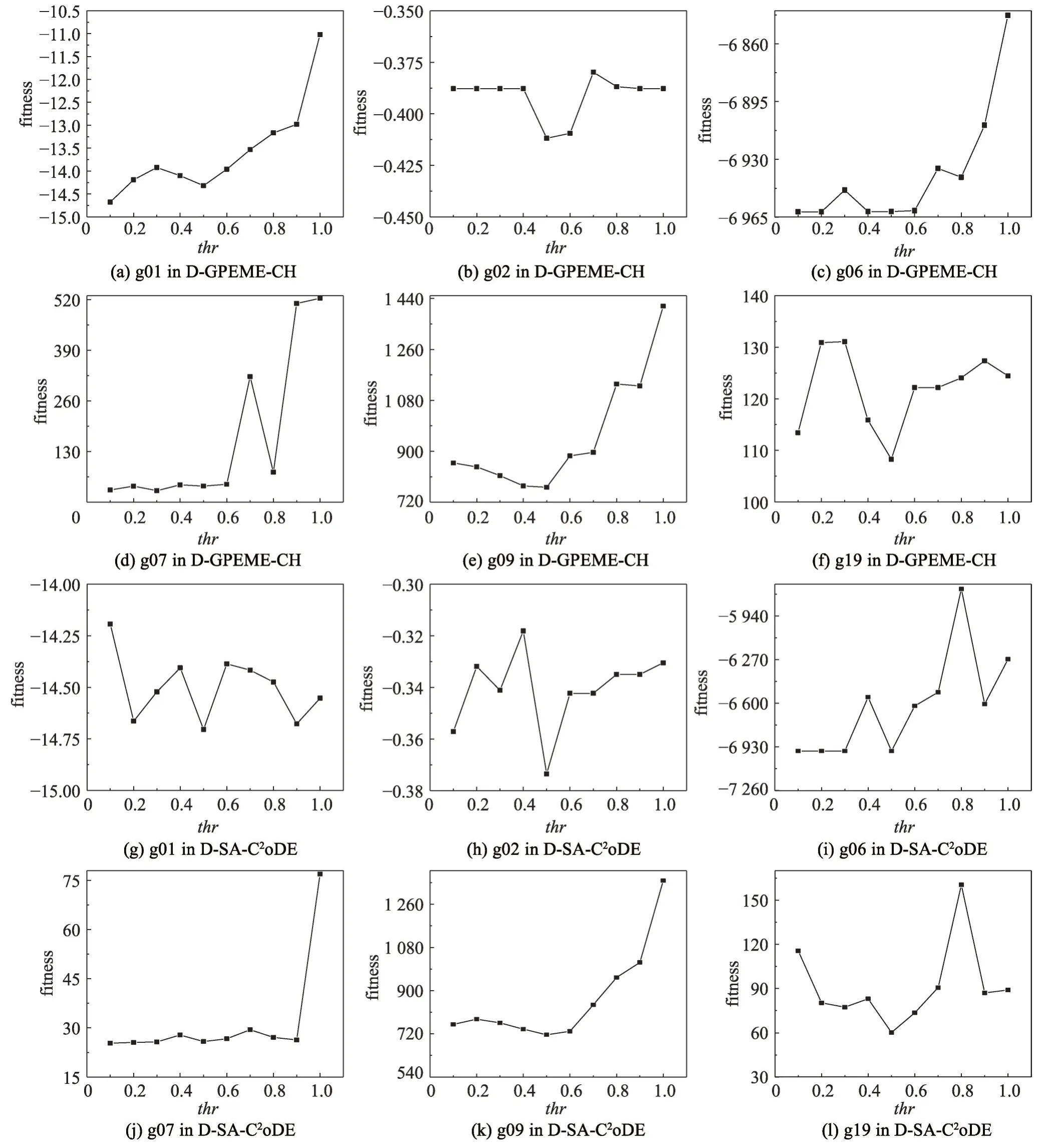
图3 thr不同取值对实验结果的影响Fig. 3 Influence of different values of thr on results
图3 中横轴为thr不同的取值,纵轴为对应取值获得的适应值。从图中可以看出,两种算法在不同的函数中呈现出大致相同的规律,当thr<0.5 时,适应值随着thr的增大而变好;当thr>0.5 时,适应值随着thr的增大而变差。这个现象是合理的,thr较小时,昂贵评估的约束较少;极端情况下,若thr=0,则所有约束都不被昂贵评估,难以在演化过程较快寻找到可行域。thr较大时,昂贵评估的约束较多;极端情况下,若thr=1,则所有约束都被昂贵评估,在昂贵评估次数有限的情况下,对昂贵评估造成浪费,限制了算法的进一步演化。结合实验结果与分析,本文设置thr=0.5。为进一步说明自适应评估策略的自适应特性,以g01 和g07 为例,用D-GPEME-CH 测试在thr=0.5 的演化中可行约束个数的变化情况,实验结果如图4。由于算法在少量评估次数内就找到所有约束的可行域,为方便观察,横坐标只绘制最大评估次数为1 000。
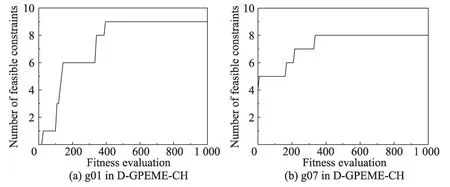
图4 演化过程找到可行约束的个数Fig. 4 The number of found feasible constraints during evolution
图4中,g01是一个带有9个约束的函数,在算法演化初期没有任何约束的可行域信息被搜索到;随着算法的演化,找到可行域信息的约束个数逐渐增加,在400 多次昂贵评估时,所有约束的可行域都被找到。g07 是一个带有8 个约束的函数,其中4 个约束的可行域比较大,在算法初期就已经被找到;随着算法的演化,找到可行域信息的约束个数逐渐增加,在400 多次昂贵评估时,所有约束的可行域都被找到。因此,thr=0.5 是一个比较合理的设置,能够体现自适应评估策略的自适应特性。
在文献[33]中,变异概率F建议以相等概率从{0.6,0.8,1.0}取值,交叉概率CR建议以相等概率从{0.1,0.2,1.0}取值。为进一步调研在D-SA-C2oDE 中差分进化算子的变异概率F、交叉概率CR的不同取值对实验结果的影响,首先固定CR以相等概率从{0.1,0.2,1.0}取值的设置,对比F={0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1.0}与F以相等概率从{0.6,0.8,1.0}取值的结果,如图5 所示。图5 中,横轴为F不同的取值,纵轴为对应取值获得的适应值,红色虚线为F以相等概率从{0.6,0.8,1.0}取值的结果。从图中可以得出,在加入自适应评估策略后,F=0.6 时的实验结果比较好,因此本文设置F=0.6。
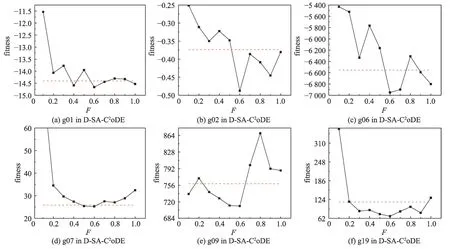
图5 F不同取值对实验结果的影响Fig. 5 Influence of different values of F on results
固定F=0.6 后,本文对比CR={0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1.0}与CR以相等概率从{0.1,0.2,1.0}取值的结果,如图6 所示。图6 中,横轴为CR不同的取值,纵轴为对应取值获得的适应值,红色虚线为CR以相等概率从{0.1,0.2,1.0}取值的结果。从图中可以得出,在g06 中,CR以相等概率从{0.1,0.2,1.0}取值的结果较好;在多数其他测试函数中,CR=0.7 时的实验结果比较好,因此本文设置CR=0.7。
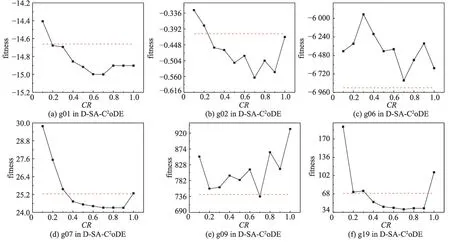
图6 CR不同取值对实验结果的影响Fig. 6 Influence of different values of CR on results
4.4 实验结果
本节首先验证复合差分进化算法和自适应约束评估策略的效果;然后对比从两个思路设计的自适应约束评估SAEAs在标准测试集CEC2006中的寻优情况,以验证SAEAs相对于传统EAs的性能提升,并以四个函数为例进行时间结果的统计与分析;最后在四个工业约束优化问题中进一步验证自适应约束评估SAEAs的求解质量和效率。
4.4.1 复合差分进化算子性能验证
为验证复合差分进化算子的性能,本小节以函数g01、g02、g19 为例,比较独立差分进化算子DE/current-to-rand/1、DE/rand-to-best/1 和DE/current-tobest/1与复合差分进化算子的实验结果。相对应地,上述算法分别命名为D-SA-DEc2r、D-SA-DEr2b、DSA-DEc2b、D-SA-C2oDE。算法收敛结果如图7所示。
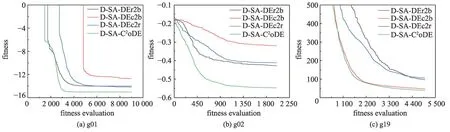
图7 差分进化算子对实验结果的影响Fig. 7 Influence of different DEs on results
图7中横轴为消耗的昂贵评估次数,纵轴为算法寻优的适应值。可以看到,复合差分进化算子的DSA-C2oDE 收敛速度更快,且收敛效果更好。这是因为独立差分进化算子的D-SA-DEr2b、D-SA-DEc2b在最优个体的引导下容易陷入局部最优,而D-SADEc2r虽然随机性比较大,但没有最优个体的引导难以往全局最优方向收敛。复合差分进化算子结合了三种算子的特点,既能够保证种群的收敛性,又能够提高种群多样性,帮助种群跳出局部最优,往全局最优的方向收敛。因此,复合差分进化算子能够提高种群多样性,并加快收敛速度,提高收敛效果。
4.4.2 自适应约束评估策略性能验证
为验证自适应约束评估策略的效果,本小节对比从两种思路设计的自适应约束评估SAEAs(DGPEME-CH、D-SA-C2oDE)及不带该策略的SAEAs(GPEME-CH、SA-C2oDE)实验结果。其中,GPEMECH、SA-C2oDE 按照1.4.1 小节选择惩罚适应值最优的个体进行昂贵评估。所有算法真实评估次数均为1 000×(NC+1),算法25 次独立运行所得结果如表2所示。均值是指25 次独立实验最优解的均值,方差是指25 次独立实验最优值的方差。“NaN”表示算法在25次实验中均未找到可行解。
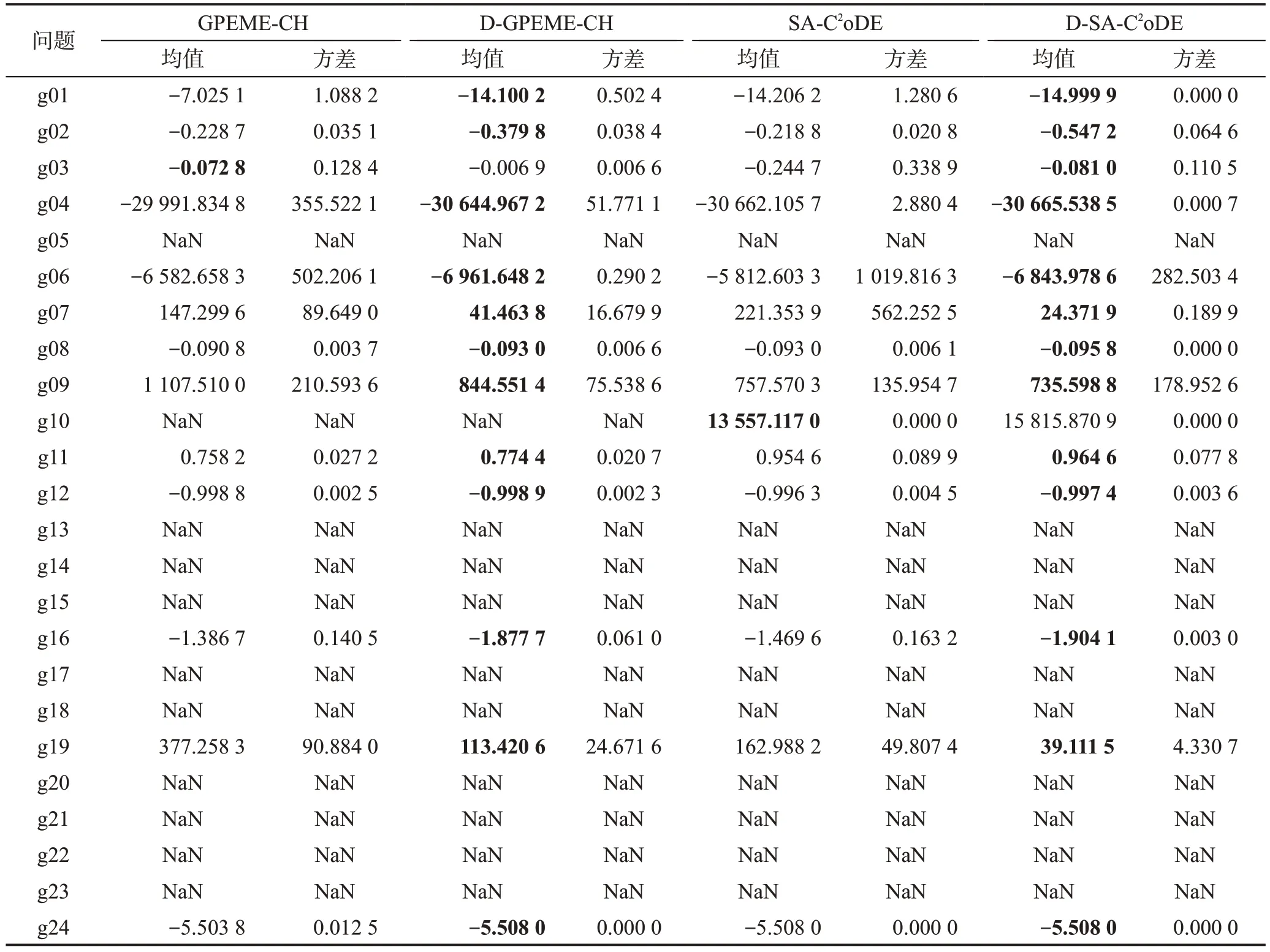
表2 自适应约束评估策略性能验证对比结果Table 2 Comparison results to validate effectiveness of adaptive constraint evaluation strategy
从表2 中可以看到,加入自适应约束评估策略后,两种思路设计的约束优化SAEAs 性能均有所提升。在无自适应约束评估策略的算法中,每一代选择的候选解要进行所有约束和目标值的真实评估,消耗的真实评估次数较多,限制了种群演化代数。而自适应约束评估策略仅对需要的信息进行评估,节省的评估次数可以用来进一步演化种群。因此,在自适应约束评估策略的辅助下,算法性能能够有进一步提升。
需注意的是,在测试函数g05、g13、g14、g15、g17、g20、g21、g22、g23 中,算法无法找到可行解。从表1函数性质可得,这些函数均含有多个等式约束。一方面,等式约束在变量空间形成的可行域是一个超平面、平面、一条线甚至一个点,如此复杂的函数特性对于代理模型来说是很难拟合的;另一方面,代理模型通过对后代预测辅助种群演化,而等式约束形成的可行域是一个精细化的点线面,用一个近似的模型去预测一个精细化的函数是不现实的。因此,如何对昂贵等式约束有效处理仍有待研究,在下面的实验中,不对上述函数进行分析讨论。
为说明自适应评估策略的自适应特性,以及自适应约束评估策略在减少评估次数的情况下对算法精度的影响,首先,以g01和g07为例,测试自适应约束评估策略的算法D-GPEME-CH和所有约束评估策略的算法GPEME-CH在演化过程中可行约束个数的变化情况,实验结果如图8。由于算法在少量演化代数内就找到所有约束的可行域,为方便观察,横坐标只绘制到演化代数为100。
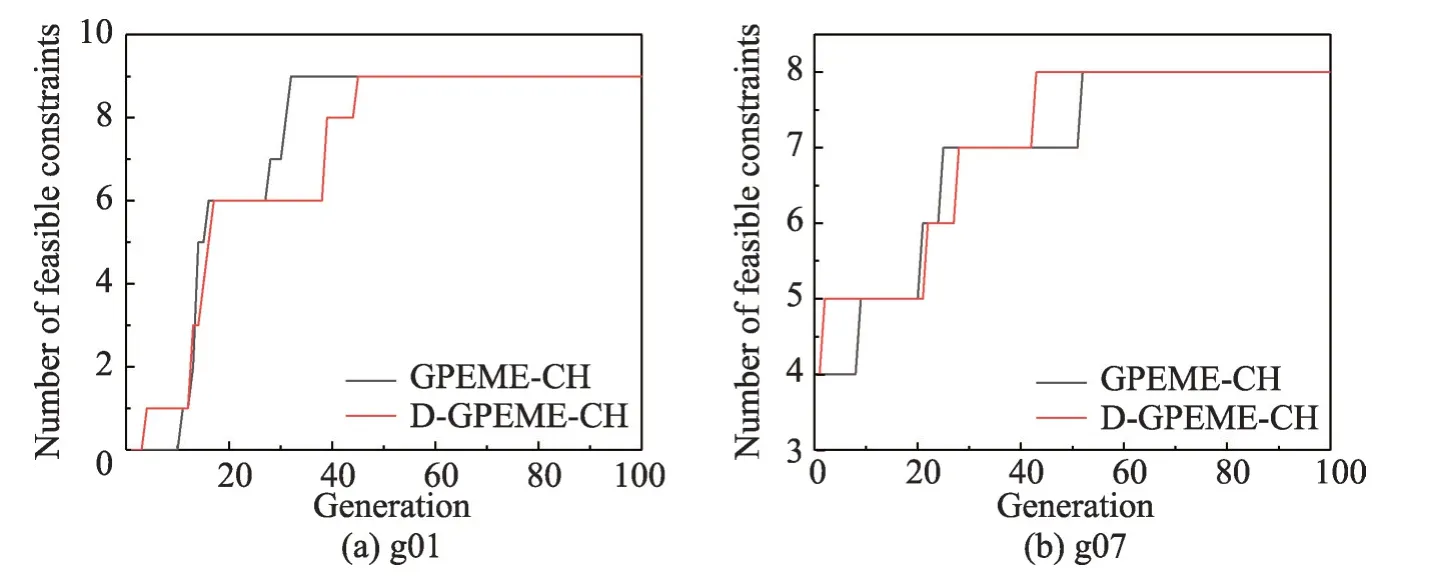
图8 约束评估策略对约束演化效果调研Fig. 8 Influence investigation of different constraint evaluation strategies on constraints exploration
图8中,g01是一个带有9个约束的函数,在算法演化初期没有任何约束的可行域信息被搜索到;g07是一个带有8个约束的函数,其中4个约束的可行域比较大,在算法初期就已经被找到。随着算法的演化,两种策略均能在60 代演化内找到所有约束的可行域,虽然自适应约束评估策略在相同的演化代数减少昂贵评估次数,但对算法找到所有约束可行域的影响不大,这是因为在自适应约束评估策略中,种群在约束可行域比例大于thr表明种群已大部分进入该约束的可行域内,无需频繁对其进行昂贵评估寻找可行域;相反,种群在约束可行域比例小于thr表明种群大部分在该约束的可行域外,需要通过昂贵评估引导演化方向,探索可行域。因此,自适应约束评估策略节省的是种群掌握大部分可行域信息约束的昂贵评估次数,对算法进入可行域的速度并没有太大的影响,但节省的昂贵评估次数可以用来进一步演化,增加演化代数,使算法找到更优的解。
为进一步分析自适应约束评估策略与对所有约束进行昂贵评估策略对算法性能的影响,本文以函数g01、g02、g06、g07、g09、g19为例,分析演化代数相同和昂贵评估次数相同两种情况下自适应约束评估策略与对所有约束进行昂贵评估方式对算法性能的影响。设置演化代数为1 000,此时若对所有约束进行昂贵评估,昂贵评估次数为1 000×(NC+1);若执行自适应约束评估策略,昂贵评估次数小于等于1 000×(NC+1)。因此,在演化代数相同的情况下,自适应约束评估策略可以减少昂贵评估次数。为保证比较结果的公平性,进一步比较在昂贵评估次数相同的情况下自适应约束评估策略算法的性能。实验结果如表3所示。
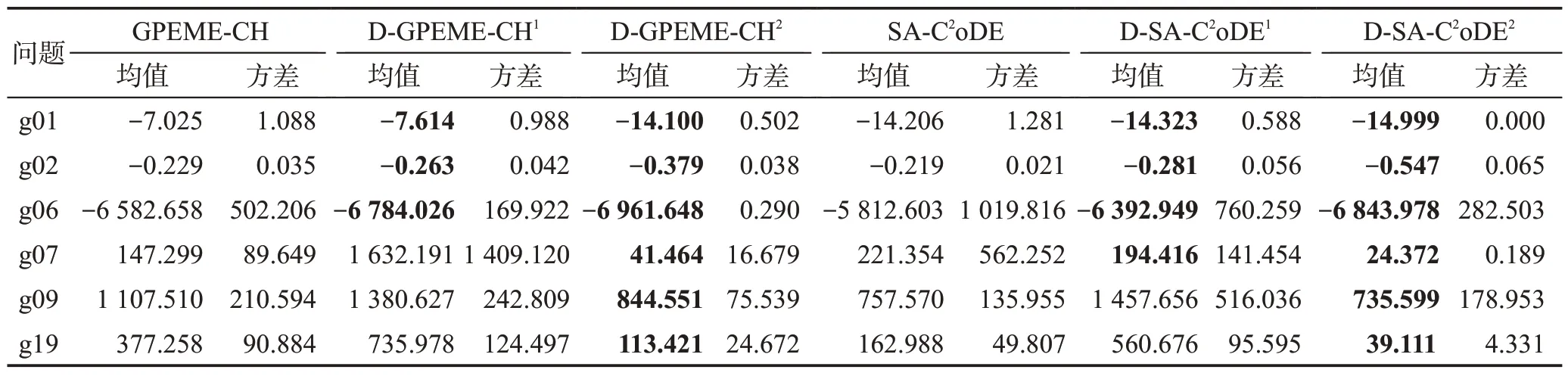
表3 自适应约束评估策略性能调研Table 3 Influence investigation of adaptive constraint evaluation
表3 中,上标“1”代表自适应约束评估策略的SAEAs 演化代数与所有约束评估策略的SAEAs相同,均为1 000;上标“2”代表自适应约束评估策略的SAEAs昂贵评估次数与所有约束评估策略的SAEAs相同,均为1 000× (NC+1)。从表中结果可以看到,演化代数相同的情况下,自适应约束评估策略的SAEAs并没有在所有测试问题中比所有约束评估策略的SAEAs效果好。这是因为自适应约束评估策略的SAEAs在每一代中是自适应地进行约束选择和昂贵评估,在一定的部分约束评估个体积累之后才进行个体选择并补全真实约束值和目标值。相比所有约束评估策略的SAEAs,自适应约束评估策略的SAEAs 对所选解真实信息的掌握有一定的延迟,演化受到预测误差的影响。在演化代数相同的情况下,自适应约束评估策略的SAEAs 所花费的昂贵评估次数有所减少。当自适应约束评估策略的SAEAs的昂贵评估次数和所有约束评估策略的SAEAs相同时,效果均有明显提升。这是因为自适应约束评估策略可以减少对可行域信息较多的约束的频繁评估,节省的昂贵评估次数可以用来进一步演化。因此,自适应约束评估策略的SAEAs能够有效提升算法性能。
4.4.3 自适应约束评估的SAEAs性能验证
昂贵优化是一个具有挑战性研究方向的原因之一是真实评估次数非常少。为验证SAEAs在求解昂贵优化问题相对于传统EAs的性能优势,本小节对传统约束优化算法(C2oDE)和本文设计的两种自适应约束评估的SAEAs(D-GPEME-CH、D-SA-C2oDE)在CEC2006 中25 次独立运行结果作对比分析,算法优化的最优解如表4所示,算法结束时的可行解情况如表5 所示。由于在上一小节已经分析了代理模型处理昂贵等式约束的困难和在此领域的研究空白,这一小节不对带有多个等式约束的函数进行测试分析。
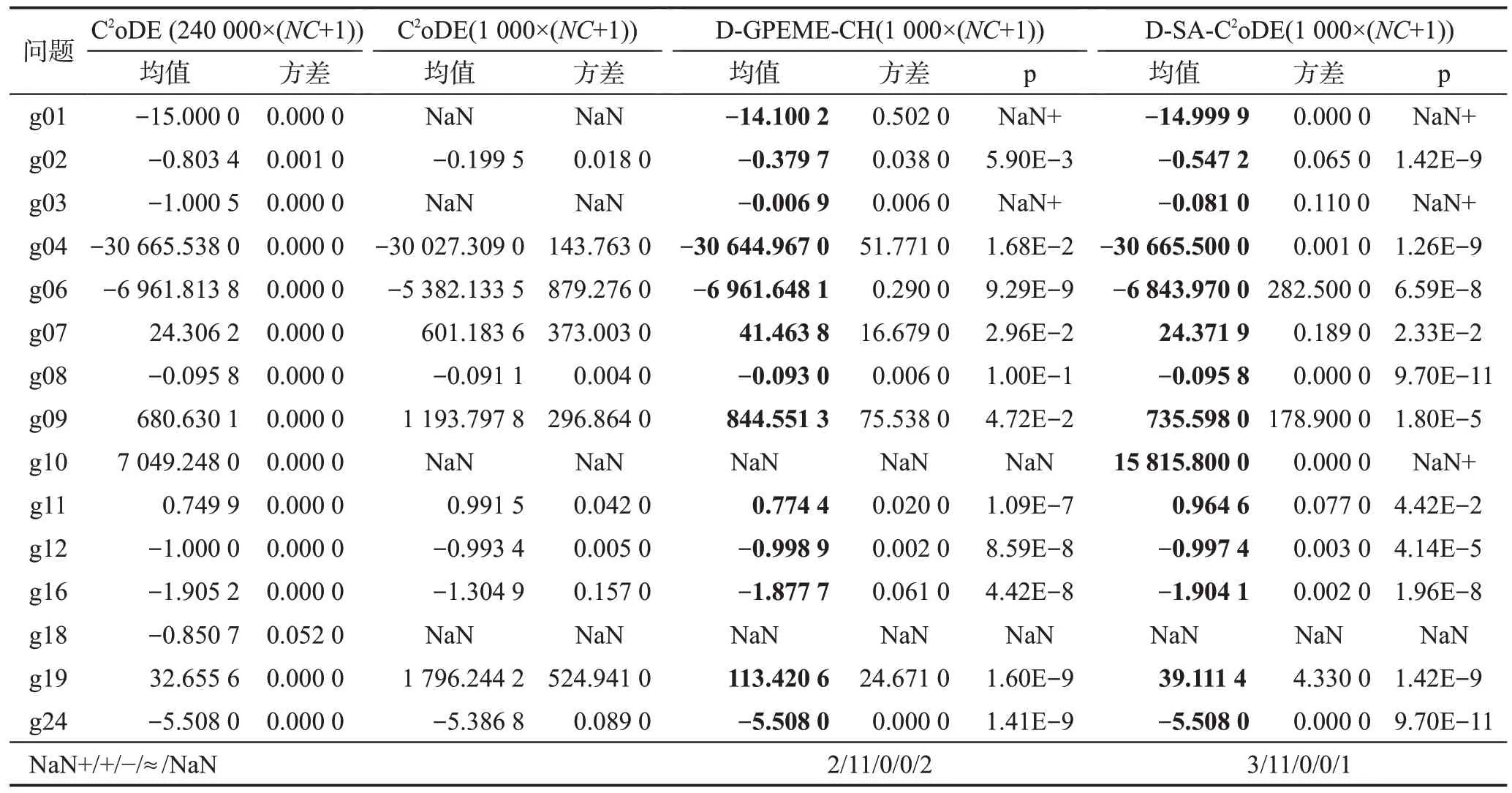
表4 自适应约束评估的约束优化SAEAs性能对比结果Table 4 Comparison results to validate effectiveness of adaptive constraint evaluation aided SAEAs for expensive constrained optimization

表5 CEC2006测试问题的可行解对比结果Table 5 Comparison results of feasibility in CEC2006
在表4中,p表示自适应约束评估SAEAs与C2oDE威尔克逊秩和检验的结果,+/-/≈表示显著水平为0.05 的情况下,对应SAEAs 比C2oDE 寻优结果显著好、显著差和无明显差异的次数。NaN+表示C2oDE无法找到可行解,而自适应约束评估SAEAs 可以找到可行解,此时无法进行统计学检验,但后者性能明显优于前者。NaN 表示C2oDE 和自适应约束评估SAEAs 均未找到可行解,无法进行统计学检验和算法性能比较。表5中rf是算法结束时种群中的可行解比例在25 次独立运行的均值;rs指所有运行中算法在结束时成功找到可行解的比例。C2oDE(240 000)指算法适应值评估次数为240 000×(NC+1)次,即原文设定的最大评估次数[33];由于评估代价昂贵,本文设计的D-GPEME-CH 和D-SA-C2oDE 最大评估次数为1 000×(NC+1),并将算法C2oDE 最大评估次数设置为1 000×(NC+1)进行实验,以保证实验的公平性,比较在有限次真实目标和约束评估次数下算法性能。
综合表4 和表5 的结果可知,C2oDE(240 000)在真实评估次数非常多的时候,能够在15 个测试问题中找到最优解,并且在所有问题中都能找到可行解且算法结束时种群中可行解比例为1。为公平比较,将该算法最大评估次数调整为1 000×(NC+1)后,算法性能急剧下降,在4个问题中无法找到可行解且在找到可行解的问题中求解质量不高。然而表4 显示自适应约束评估SAEAs 求解质量有明显提高,在15个测试函数中,D-GPEME-CH 和D-SA-C2oDE 均在11个函数中显著优于相同评估次数的C2oDE;在g01和g03 中,C2oDE 无法找到可行解,而D-GPEME-CH和D-SA-C2oDE均能找到质量较好的可行解。同时,表5结果显示,D-GPEME-CH和D-SA-C2oDE找到可行解的运行次数和在算法结束时种群的可行解比例普遍比C2oDE 高。由此可见,D-GPEME-CH 和DSA-C2oDE在有限目标和约束的真实评估次数内能够取得较好的可行解,在自适应约束评估策略和代理模型的辅助下,比传统EAs效果更好。
为进一步说明本文设计的两种算法相对于其他求解昂贵约束优化问题算法的性能优势,本文以近两年提出的代理模型辅助的部分评估演化算法(surrogateassisted partial-evaluation-based EA,SParEA)[37]、代理模型辅助的分类协同差分进化算法(surrogate-assisted classification-collaboration DE,SACCDE)[38]为对比算法,在上述CEC2006 测试问题中进行对比分析;另外,为了测试本文设计的两种算法在较高维问题中的性能优势,本文增加在标准测试集CEC2010[39]的30维问题的测试。正如在4.4.1小节中提到的昂贵等式约束处理的难度和当前在此方面研究的空白,只测试CEC2010中不含等式约束的问题c01、c07、c08、c13、c14、c15。为保证实验公平性,测试算法的最大评估次数均设置为1 000×(NC+1),实验结果如表6所示。
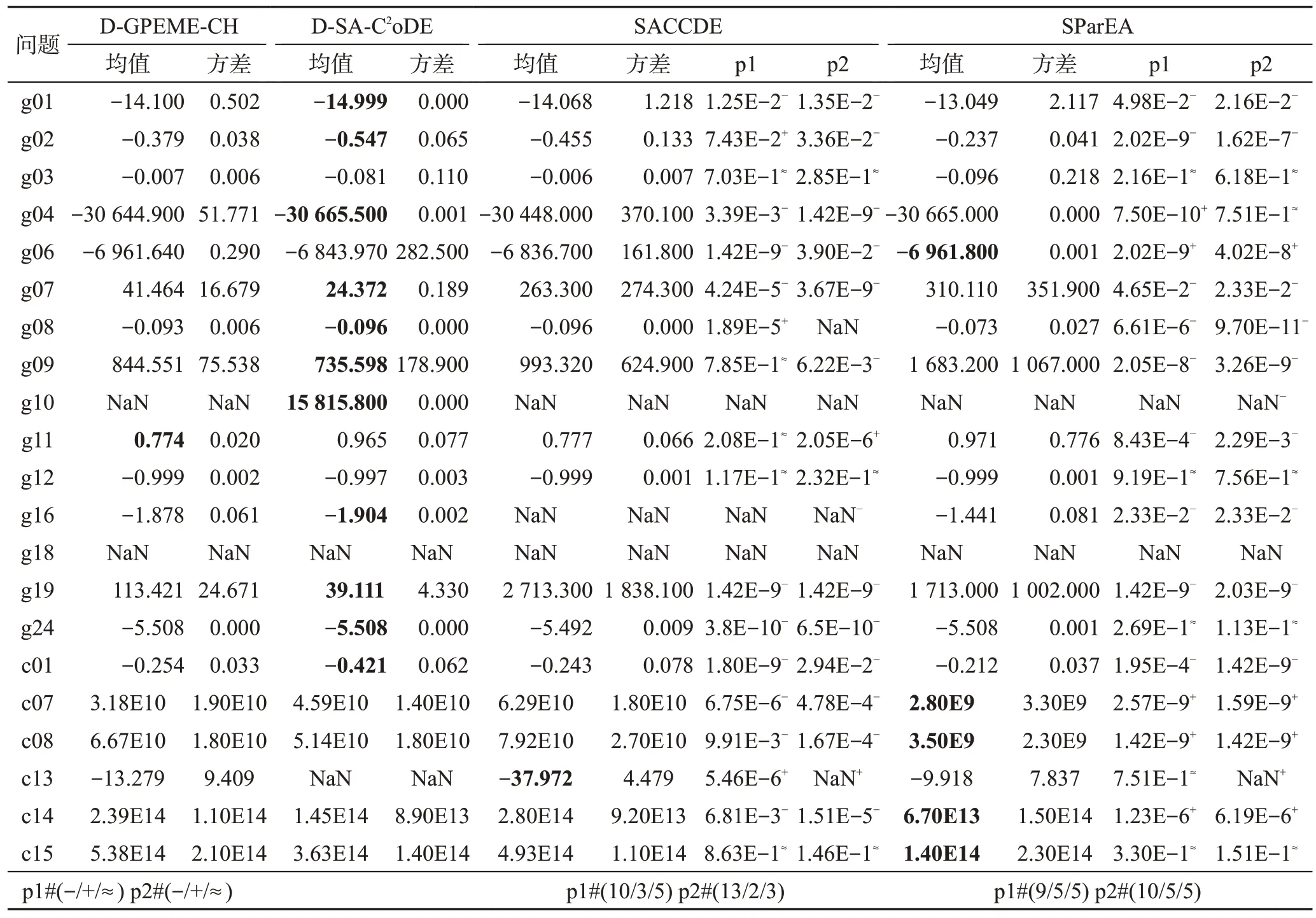
表6 自适应约束评估的SAEAs与其他SAEAs的性能对比Table 6 Comparison results of adaptive constraint evaluation aided SAEAs with other SOTA SAEAs
表6 中,p1 表示对比算法与D-GPEME-CH 的威尔克逊秩和检验结果,p2 表示对比算法与D-SAC2oDE的威尔克逊秩和检验结果。-/+/≈分别表示在显著水平为0.05的情况下,对比算法明显劣于、优于本文设计的算法,或与本文设计的算法无明显差别;最后一行总结对比算法与本文设计的两种算法总体比较情况。从表中结果可以得出以下结论:(1)SACCDE在10个测试函数中显著劣于D-GPEME-CH,在13个函数中显著劣于D-SA-C2oDE。(2)SParEA 在9 个测试函数中显著劣于D-GPEME-CH,在10 个函数中显著劣于D-SA-C2oDE。(3)SACCDE 在CEC2010 的30维函数中大部分劣于D-GPEME-CH和D-SA-C2oDE;而SParEA 在CEC2010 的30 维函数中大部分优于DGPEME-CH和D-SA-C2oDE。
上述结论是合理的。SACCDE 和SParEA 对所挑选的解进行全部约束评估。在测试集2006 中,当约束个数较多时,频繁地评估可行域信息较多的约束对昂贵评估次数造成浪费,限制了算法的演化程度;而D-GPEME-CH 和D-SA-C2oDE 采取了自适应约束评估策略,仅对可行域信息较少的约束进行评估,能够有效避免昂贵约束评估的浪费,使算法进一步演化。而CEC2010测试集函数设计的初衷在于问题维度的可扩展性,问题约束通常只有1个(c01,c07,c08)和3个(c13,c14,15),且约束的可行域较小,自适应约束评估策略极大概率将所有的约束加入待评估集合,因此,D-GPEME-CH、D-SA-C2oDE和SACCDE、SParEA一致,对所挑选的解进行了全部约束评估,并没有发挥自适应约束评估策略的优势。另外,SParEA使用了四种不同的代理模型对约束进行拟合,准确率相对于只采用一种模型的其他三种算法有所提升,因此在CEC2010测试问题中的性能表现较好。
4.4.4 运行时间对比与分析
为进一步说明SAEAs能够提高求解昂贵优化问题的效率,本小节对自适应约束评估SAEAs 和传统约束优化EAs 的运行时间进行统计分析。由于昂贵工程问题使用的仿真软件需要花费几个小时甚至几十个小时进行一次评估,且大部分都是商用软件,本文通过对测试函数添加时间延迟来模拟昂贵评估。不失一般性,本文采取4个函数g01、g02、g03、g04,设置一次适应值评估的时间延迟为0 s、1 s、10 s和100 s,记录算法平均运行一次所需时间,时间延迟为0 s,即算法真实运行时间。为保证实验的公平性和有效性,D-GPEME-CH 和D-SA-C2oDE 的停止条件如4.2节所设,为1 000×(NC+1)次,而C2oDE的停止条件为搜索结果达到两种算法的平均值,即算法性能达到和自适应约束SAEAs相近,此时进行的评估次数分别是126 500×(9+1)(g01)、108 050×(2+1)(g02)、135 950×(1+1)(g03)、137 300×(6+1)(g04),显然,消耗的评估次数均远远大于1 000×(NC+1)。运行时间记录如表7所示。
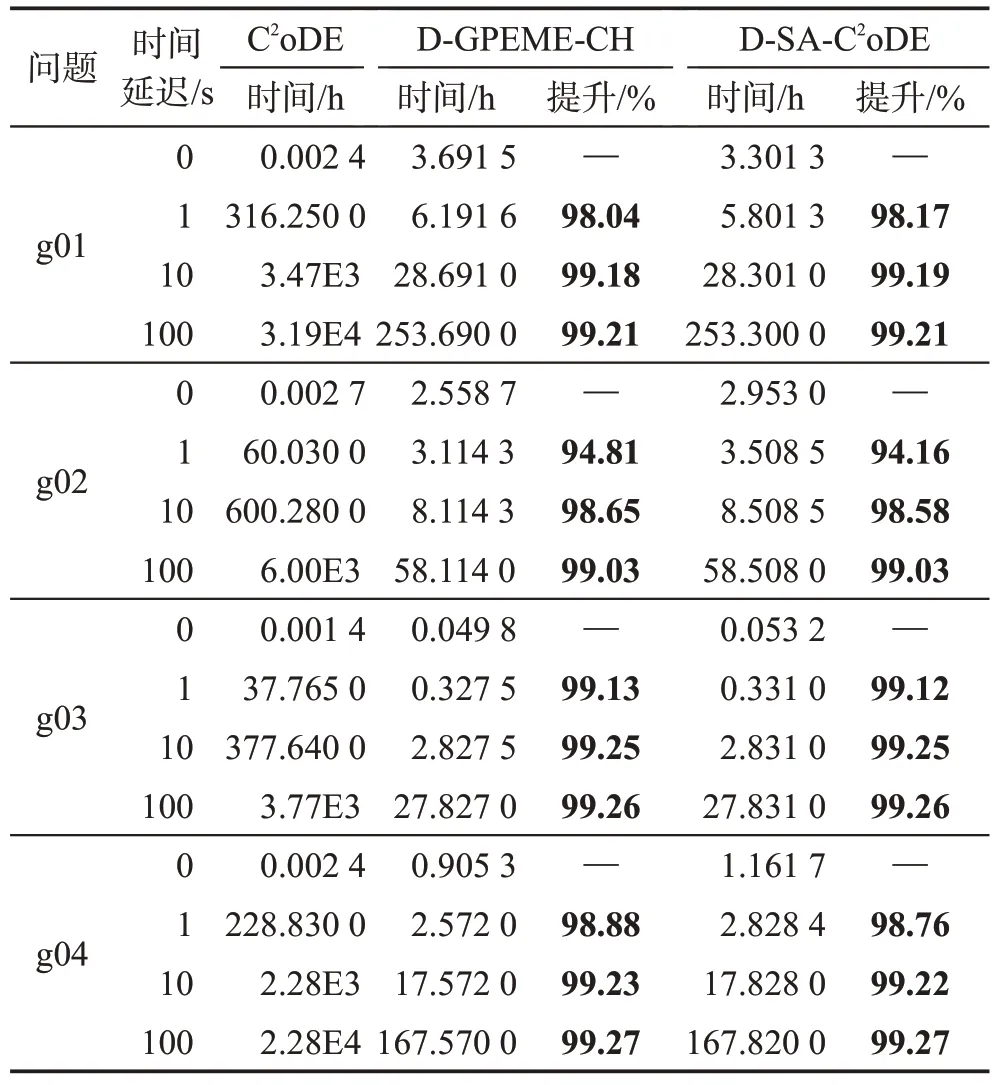
表7 不同时间延迟的运行时间对比结果Table 7 Comparison results of execution time with different time delays
表7 中效率提升的计算是由C2oDE 运行时间减自适应约束评估SAEAs 时间的差,除以C2oDE 运行时间所得。当时间延迟为0 s 时,可以看到自适应约束评估SAEAs 比C2oDE 运行时间长,这是因为模型训练时间相对简单函数评估较长,且维度越高,问题越复杂,训练时间越长;而真实函数评估所需时间非常短,因此在运行时间对比上并没有优势。然而,当单次适应值评估有时间延迟后,自适应约束评估SAEAs 运行时长比C2oDE 效率提升在94%以上,其中91.67%的测试例子效率提升在98%以上。这是因为模型的训练和预测时间相对昂贵函数评估较短,在代理模型的辅助下,真实适应值评估次数大大减少,由此减少了评估时间,加快算法运行效率。随着时间延迟的增大,自适应约束评估SAEAs 的时间优势更加明显,效率提升幅度更大。
4.4.5 工业问题优化结果与分析
为进一步证明自适应约束评估SAEAs在工业中有良好的应用前景,本小节在碟形弹簧设计优化(BS)、散货船设计优化(BCD)、轿车侧面碰撞优化(CSI)和螺旋弹簧设计优化(HS)问题中将设计的两种算法与传统约束优化方法C2oDE 进行对比实验,并进行威尔克逊秩和检验,实验结果如表8所示。

表8 工业优化问题的实验对比结果Table 8 Comparison results in engineering optimization problems
由表8 中结果可得,D-GPEME-CH 和D-SAC2oDE均取得比C2oDE好的结果。特别地,显著水平为0.05 时,D-GPEME-CH 在两个问题中显著好于C2oDE,D-SA-C2oDE在四个问题中均显著好于C2oDE。因此,本文设计的两种自适应约束评估SAEAs 能够对四个工业约束优化问题进行有效求解,在自适应约束评估策略的辅助下,能够提升对可行域搜索的成功率,表现出其在昂贵复杂工业约束优化问题中较好的应用前景。
4.5 理论分析
首先在性能方面,算法的性能受演化程度影响,自适应约束评估策略从演化程度提升算法性能。现有的处理昂贵约束方法大都是对每个候选解进行全部约束和目标评估,即每一代消耗NC+1 次昂贵评估,对应的演化程度为maxFES/(NC+1)。而在自适应约束评估策略中,算法根据当前种群对可行域信息的掌握程度自适应决定评估约束。具体地,本文将约束分为三大类:第一类是初始化随机采样种群在可行域内比例达到评估阈值thr,算法很容易找到可行解,在自适应约束评估策略中不会被选择做昂贵评估;第二类是初始化随机采样种群在可行域内比例小于评估阈值thr,且算法非常难找到可行解,在自适应约束评估策略中被频繁选择做昂贵评估;第三类是初始化随机采样种群在可行域内比例小于评估阈值thr,但随着演化种群在可行域内比例会达到评估阈值thr,即演化前期被频繁选择做昂贵评估,演化后期不会被选择做昂贵评估。当问题的约束都是第一类时,部分评估过程中没有约束被选择进行昂贵评估;全部评估过程对所有约束和目标值进行昂贵评估,因此演化程度为[maxFES/(NC+1)]×(Gap+1),其中,如第2 章描述,Gap是需进行信息补全的代数,它决定着算法进行种群和代理模型更新的频率,因此Gap≥1。此时,算法演化程度满足以下关系:
这时,自适应约束评估策略的演化代数与所有约束评估策略的演化代数成倍数关系,Gap越大,演化代数越多,演化程度越高。当问题的约束都是第二类时,部分评估过程中所有约束被选择进行昂贵评估;全部评估过程仅对目标值进行昂贵评估,因此演化程度为[maxFES/(NC×Gap)]×(Gap+1)。结合Gap≥1,算法演化程度满足以下关系:
因此,在所有约束被选择进行昂贵评估的情况下,自适应约束评估策略的SAEAs的演化程度都比对所有约束进行昂贵评估的SAEAs 高。也就是说,自适应约束评估策略在最差情况下每一代消耗的昂贵评估次数也比所有约束进行昂贵评估的方法少,演化程度高。当问题的约束为第三类时,或者包含这三类中的多类约束时,演化程度在区间{[maxFES/(NC×Gap)]×(Gap+1),[maxFES/(NC+1)]×(Gap+1)}内,因此,在求解包含不同类型约束的问题时,自适应约束评估策略能够在少量评估次数下自适应评估昂贵约束,提升算法性能。
其次在运行时间方面,由4.4.4小节知,C2oDE取得和D-GPEME-CH、D-SA-C2oDE 在1 000×(NC+1)次评估相近的效果需100倍以上评估次数,为方便说明,记C2oDE 评估次数为1 000×times×(NC+1),其中,times是达到相近效果所用评估倍数。由于CEC2006 函数并非昂贵优化问题,在时间延迟为0 s时,模型的训练和预测时间占支配地位,因此C2oDE运行时长较短。当对真实评估加上时间延迟td模拟昂贵约束优化时,评估时间占支配地位。此时,DGPEME-CH、D-SA-C2oDE所需的评估时间为1 000×(NC+1)×td,而C2oDE所需的评估时间为1 000×times×(NC+1)×td,效率提升如下:
由此可知,基于代理模型的算法的效率提升与传统算法所需评估次数有关,所需评估次数越多,效率提升越大。由表7可知,本文算法的效率提升均在94%以上,且大部分达到98%。
4.6 算法对比分析
本文从两个思路出发设计两种基于自适应约束评估策略的约束优化SAEAs,D-GPEME-CH 和DSA-C2oDE,二者具有一定的相似性。首先,二者都采用高斯过程回归模型作为代理,在昂贵约束和目标的拟合上没有本质区别;其次,二者都采用自适应约束评估策略对昂贵约束进行处理,在演化过程中都能够自适应决定评估的约束,节省的评估次数用来进一步演化,相对于传统约束优化算法能够在有限次真实评估下找到优胜解。
然而,这两个算法在演化算子上也存在一定的差异性。D-GPEME-CH是基于代理模型辅助的无约束演化算法加入约束处理技术设计的,本身的演化算子为DE/best/1,无需处理约束;而D-SA-C2oDE 是由无代理模型的约束优化算法加入代理模型的辅助设计的,采用的是复合差分进化算法,并设计有良好的约束处理技术。因此,D-GPEME-CH 在对可行域的搜索和收敛能力上较D-SA-C2oDE 差,算法性能不如后者,这也体现在CEC2006 及工业优化问题的测试结果中。相对应地,D-SA-C2oDE 的演化算子较为复杂,导致D-SA-C2oDE 的运行时间普遍较DGPEME-CH 长,这体现在运行时间对比与分析的实验中。但是,即使二者在性能和时间上有所差异,在真实评估次数非常有限的情况下,它们都比传统无代理模型辅助的约束优化算法有更好的搜索能力和更高效的求解时长。事实上,无论从哪个思路出发设计约束优化SAEAs都有挑战。
(1)从基于代理模型辅助的无约束优化算法思路出发,由于昂贵约束的加入,需要考虑如何合理处理约束。昂贵约束与昂贵目标性质不同,约束不需寻找最优值,只要在可行域内的解都是满足的;另外,在多目标或超多目标的优化问题中,目标的个数往往小于5,而约束个数大于10的优化问题是非常多的,这使得可行域空间变得极其复杂,在利用代理模型拟合约束时要考虑如何对复杂约束进行有效处理。
(2)从无代理模型辅助的约束优化算法思路出发,代理模型的加入需要考虑如何选择代理模型,如何使用代理模型以及如何对模型进行有效管理。代理模型的预测结果相比真实评估有一定的误差,如何降低预测误差的负面影响,是这类问题的研究重点。同时,当约束个数增加时,如何降低模型管理负荷,提高算法运行效率也需进行考虑。
因此,当前约束优化SAEAs 的设计仍然存在很多挑战,对于昂贵约束优化问题的求解仍有较大的研究空间。
5 总结与展望
本文提出了一种新的自适应约束评估策略来自适应地进行个体选择、约束选择和昂贵评估。为验证该策略在约束优化SAEAs 中的作用,本文分别从代理模型辅助的无约束优化算法和无代理模型的传统约束优化算法两个思路出发,设计两种自适应约束评估SAEAs:D-GPEME-CH和D-SA-C2oDE。通过在测试集CEC2006和四个工业优化问题中的实验验证及理论分析,表明本文设计的自适应约束评估SAEAs 能够在较短时间内有效求得可行解,降低求解昂贵约束优化问题的时间成本,在复杂的昂贵工业约束优化问题中有较好的应用前景。
在今后的研究中,可以就如何利用局部模型对已有信息进一步开发,加快算法对可行域的探索,提高算法求解质量展开进一步研究。
