基于参数字典的多源域自适应学习算法
2020-12-04郑雄风汪云云
郑雄风,汪云云
(1.南京邮电大学 计算机、软件、网络空间安全学院,江苏 南京 210023; 2.江苏省大数据安全与智能处理重点实验室(南京邮电大学),江苏 南京 210023)
0 引 言
迁移学习利用相关的源域知识辅助目标域学习,以解决目标域数据或数据标签稀缺的问题,目前已得到机器学习领域的广泛关注。在推荐系统中,迁移学习利用评分完善的电影数据帮助推荐无评分记录的书籍,解决冷启动问题;在室内wifi定位中,借助迁移学习,利用前时刻已有设备采集的信号数据,帮助学习新设备和未来时刻产生的信号。其实,迁移学习广泛存在于人类活动中,一个人学会了自行车,便很容易学会开电动车;熟悉五子棋,则可将知识迁移到学习围棋中。迁移学习的关键在于如何找到源领域和目标领域间的相关性进行迁移。
近年来,大量迁移学习方法被相继提出[1-2]。根据所迁移知识形式的不同,现有迁移分类学习方法可大致分为4大类:(1)基于样本[3-5]的迁移学习方法,通常采用对源域样本采样或加权的方式,选择或侧重与目标域相关的样本辅助目标域学习。如TrAdaBoost[4]和域适应支持向量机(domain adaptation support vector machine,DASVM)[6]等;(2)基于特征的迁移学习方法,关注并迁移源域特征或特征参数中的相关知识,如特征增广方法[7-8]、迁移成分分析(transfer component analysis,TCA)方法[9]和联合域适应(joint domain adaptation,JDA)方法[10]等;(3)基于模型的迁移学习方法,其假设源域和目标域的模型参数之间存在一定的相似性或联系,将源域模型参数迁移至目标域中。如域适应机(domain adaptation machine,DAM)[11]和域选择机(domain selection machine,DSM)[12]等;(4)基于关系的迁移学习方法,实现关系型域间的知识迁移。在关系型域中,数据的呈现形式为关系而非独立同分布的样本,如社会网络数据。在针对该类知识的迁移学习中,研究者们常采用统计关系型学习技术[13],如马尔可夫逻辑网络(Markov logic networks,MLNs)[14]。
而根据源域个数的不同,迁移学习又可分为单源域和多源域学习。多源域自适应学习旨在从多个源领域中挖掘相关知识以辅助目标域的学习。目前多源域自适应学习方法主要有两类[15-19]:一是在迁移过程中对各源域赋予权重,描述各源域和目标域间的相关性。Chattopadhyay等人[15]提出多源域加权方法(conditional probability based multi-source domain adaptation approach,CP-MDA),用于衡量各源域和目标域的条件分布差异;Sun等人[16]利用各源域和目标域间的边缘分布差异对源域样本进行加权,同时利用条件分布差异对各源域进行加权;Duan等人[11]在支持向量回归模型中引入数据依赖的正则化项,对各源域进行选择或加权。另一类则是通过多源域分类器集成进行知识迁移。Schweikert等人[17]提出用于基因组序列分析的域自适应方法,寻求各源域分类器和目标域分类器间的凸组合;Sun等人[18]则提出多源域自适应的动态贝叶斯学习框架,利用无标签目标域数据上的拉普拉斯矩阵获得各源域的先验,并利用k近邻距离计算似然。
此外,随着深度神经网络机器学习的发展,迁移学习又可分为传统迁移学习和深度迁移学习。Zhao等人[19]通过构建一个新的泛化边界,利用对抗神经网络实现多个源域的知识迁移。Hoffman等人[20]将多个源域的交叉熵损失和其他损失分布加权组合。Zhang等人[21]从因果关系的角度研究多源域自适应问题,通过考虑因果模型的不同模块随着多个域变化状况,挖掘出合适的迁移知识。
现有多源域自适应学习方法通常仅关注各源域和目标域间的知识迁移,并不考虑各源域间的知识共享和共性信息。即各源域的知识迁移是相互独立的,源域间的相关性并没有被考虑和利用。因此,该文尝试利用各源域间的相关性指导迁移学习。而字典学习可以挖掘数据的本质特征,因此在多源域自适应学习中利用字典学习,挖掘各源域的共性信息,提出基于参数字典的多源域自适应学习方法(multi-source domain adaption based on dictionary learning,DL_MSDA)。DL_MSDA通过学习多个源域模型参数的共享字典,挖掘各源域间的内在关系,并将其迁移至目标域模型参数的学习中,提升目标域学习模型的准确性与可靠性。
1 相关工作
1.1 域自适应机
Duan等人[11]提出域自适应机DAM,通过最大均值差异(maximum mean discrepancy,MMD)衡量每个源域与目标域间边缘分布差异,并对各源域进行加权,约束目标域的拟分类输出与各源域对目标域分类输出相近,如图1所示。
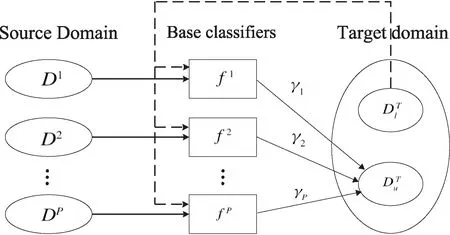
图1 DAM算法原理
在获得各源域与目标域间的相似性权值后,其目标函数刻画如下:
(1)

1.2 字典学习
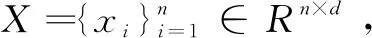
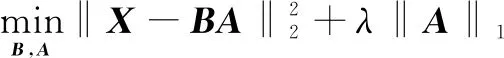
(2)
2 算法框架
2.1 问题定义
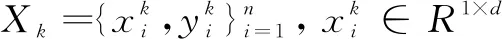
2.2 算法模型
2.2.1 基于目标域数据的学习
基于结构风险最小化理论和流形正则化约束,仅利用目标域数据的学习模型构建如下:
minΩ(fT)+μVL(fT)+γMf(PT)
(3)
其中,Ω(fT)为用户控制目标域分类器复杂度,VL(fT)为目标域有标签样本的分类损失。第三项是流行正则化项,用于刻画数据分布的流形结构:
(4)
W是样本相似性矩阵,其中元素为:
(5)
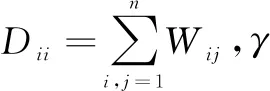
对于目标域数据的学习,其原理与半监督学习一致,在确保有标签的样本分类正确的同时,保持无标签样本数据的流行结构。
2.2.2 基于参数字典学习的知识迁移
首先,对于每个源域学习一个分类器参数Ws∈Rd×c。为了更好地挖掘源域间的共享信息,对k个源参数学习共享字典D,并将其迁移至目标域分类参数的学习中,指导目标域分类,算法框架如下:
(6)
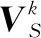
联合式(3)和式(6),并基于平方损失函数,提出基于参数字典的多源域自适应学习框架:
(7)
同时,采用非线性随机傅里叶特征[22]对样本进行非线性映射,近似逼近非线性高斯核函数。对给定数据X,利用Bochner定理生成h维随机特征:
(8)

2.3 算法优化
采用ADMM(alternating direction method of multipliers)[23]对式(7)中目标函数进行求解,即交替迭代方式优化每个参数。
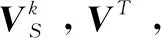

(10)
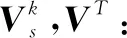
(11)

(12)
(13)
基于FISTA (fast iterative shrinkage thresholding algorithm)[24],该问题为近端(proximal)正则化问题,可由下式迭代求解:
(14)
其中:
(15)
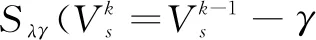
(16)
其中,Sλγ(·)是软阈值算子,且Sλγ(·)=sgn(x)·(|x|-λ)。
算法流程如图2所示。

图2 DL_MSDA算法流程
3 实验结果与分析
3.1 数据集和实验设置
该文选择了3组经典多源数据集进行实验,其中各个源域之间都满足不同分布。
3.1.1 Office+Caltech数据集
Office数据集包含三组数据集:Amazon (Amazon购物网站的商品图像),Webcam(网络相机拍摄的低分辨率图像)和DSLR(数码单反相机拍摄的高分辨率图像)。Caltech也是常用的目标识别数据集。每个数据集包含下列10类物体的图像数据:双肩包、旅行自行车、计算器、耳机、电脑键盘、笔记本电脑、电脑显示器、电脑鼠标、咖啡杯和投影仪,且每类样本数都不尽相同,数目在8到151之间,样本总数为2 533。图3显示了各数据集中电脑显示器的图像。实验中提取出了每个域图像的4 096维的DeCAF6特征,并将所有特征进行了标准化处理。

图3 目标识别数据中的电脑显示器在不同数据集中的图像
3.1.2 PIE数据集
PIE数据集包含68种共计11 554幅面部图像,其中每幅图像由32×32个像素构成。采用了五个不同照明和姿势条件下拍摄的面部图像数据集进行实验,使用SURF特征提取方法,并对特征进行标准化处理。图4展示了PIE数据集中姿势的变化,分别是PIE05(左侧)、PIE07(向上的姿势)、PIE09(向下的姿势)、PIE27(前摆姿势)。

图4 不同姿势下拍摄的面部图像
3.1.3 YalB数据集
该数据集由不同光照条件下38人的2 414张面部图像组成,每幅图像分辨率是32×32。图像的处理和文献[23]中一样,将数据集划分为了五个子集(Y1-Y5,从第一行开始依次为Y1,Y2,Y3,Y4,Y5,见图5)。子集1由正常光照条件下的266张图像组成(每人7张图像);子集2和3由受试者的12张图像组成,表征轻微到中等的亮度变化;子集4(每人14张图像)和子集5(每人19张图像)体现了严重的光照变化。

图5 不同光照条件下的人脸样本
3.2 对比方法及参数设置
实验中,源域样本皆为有标签样本,目标域包含部分有标签样本。将DL_MSDA与多源域自适应学习算法DAM进行了对比,其中DAM采用文献[11]中的参数设置。此外,还采用SVMS和SVMT作为基础对比方法,SVMS仅利用源域样本学习并对目标域分类,SVMT仅利用目标域样本进行学习。对每个数据集组合,实验重复运行了20次并取平均分类精度。
DL_MSDA中源域参数模型可通过任意分类方法得到,如SVM、C4.5等。实验中,采用线性SVM结合傅里叶特征变换得到源域分类参数。对每个数据集,分别从目标域的每个类中随机选取1个样本作有标签样本,用于训练,其他样本归为无标签样本,用于测试。实验中涉及5个参数取值为:α=1,β=5,λ=0.1,γ=30,μ=0.1。最大迭代次数设为100。
3.3 实验结果
表1给出了DL_MSDA与其他算法在不同源域-目标域组合下的分类准确率,其中每个数据集下最高准确值加粗表示。表2和表3分别是PIE数据集和Yale B数据集上的分类性能。
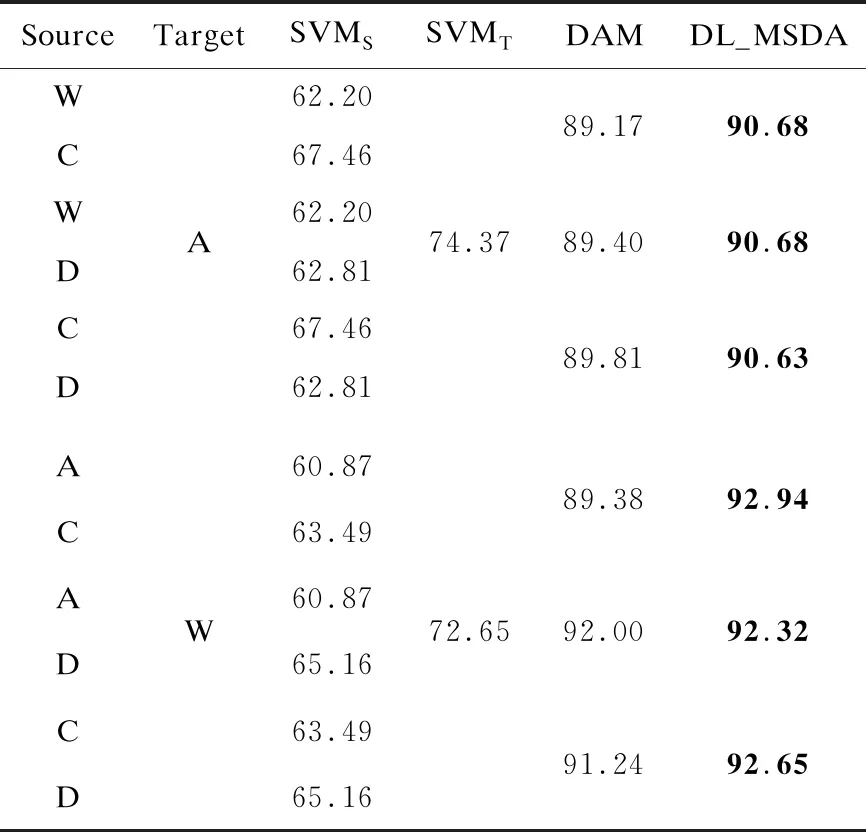
表1 Office+Caltech数据集上实验平均准确率 %

表2 PIE数据集上实验平均准确率 %
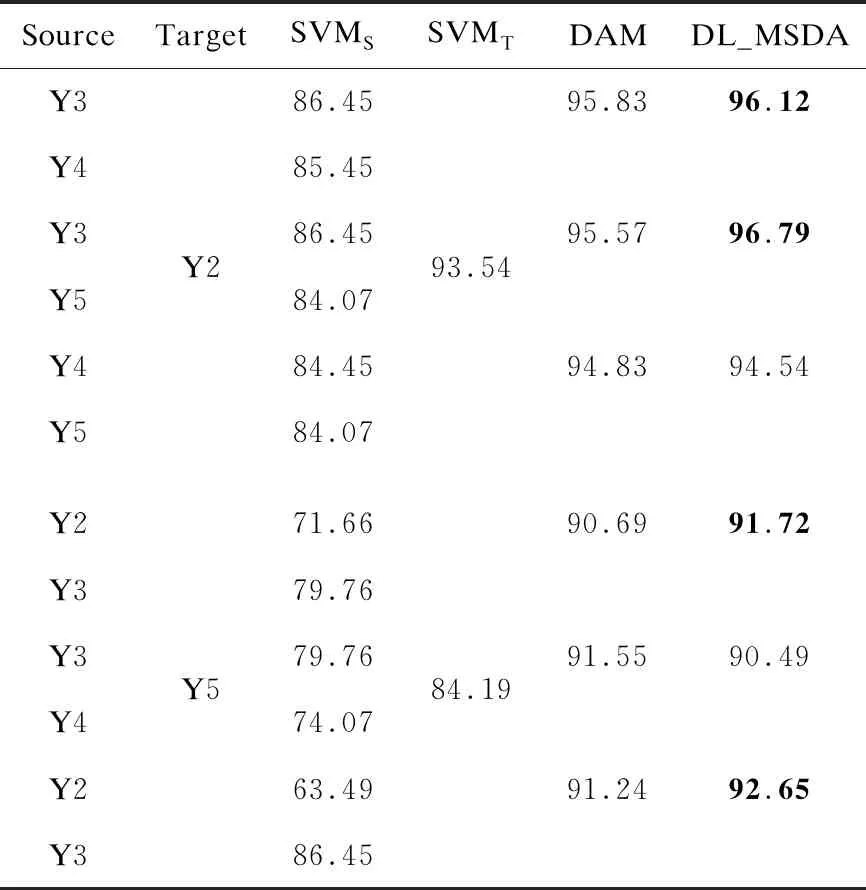
表3 Yale B数据集上实验平均准确率 %
3.4 参数分析
本节对正则化参数α和β进行实验分析,研究其对DL_MSDA性能的影响,从而分析源域相关知识对目标域分类性能的影响。α,β的取值范围为[0.000 1,0.001,0.01,0.1,1,5,10],λ的取值同α,其余参数值固定。图6给出了Office+Caltech数据集上4种不同组合下DL_MSDA的性能图。
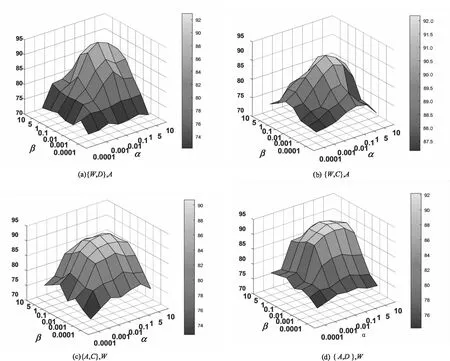
图6 Office数据集中不同源域下的参数分析
由图6可看出,当α和β取值趋近于0,仅利用目标域数据进行学习;随着α和β取值不断增大,模型的分类准确率有了明显的提升,这表明DL_MSDA可以有效地从多个源域中学习到共享知识并帮助目标域学习。但是当α,β取值过大时,模型由源域知识主导,忽略了目标域自身信息,因此分类准确率也随之降低。因此,用多个源域间的共享信息辅助目标域数据学习,可有效提升目标域的学习性能。
4 结束语
提出的基于参数字典学习的多源域自适应(DL_MSDA)学习框架,能够有效利用多源域间的共享信息,解决目标域仅有少量有标签样本的多源域自适应学习任务。字典学习较其他多源域自适应学习框架可以更多地探索各个源域之间的共享信息,并把这些重要信息传递到目标域分类模型的学习过程中。实验表明,DL_MSDA可有效提升目标域分类模型的分类精度。DL_MSDA算法仅通过多个源域模型参数的共享字典进行迁移,挖掘源域参数间的共享知识,而后续工作将考虑从数据空间出发,进一步拆分字典为多源域共享字典和每个源域特有字典,在挖掘源域间的共享知识进行迁移的同时减少负迁移,提升目标域的学习性能。
