少样本知识图谱补全技术研究
2023-06-07彭晏飞张睿思王瑞华郭家隆
彭晏飞,张睿思,王瑞华,郭家隆
辽宁工程技术大学 电子与信息工程学院,辽宁 葫芦岛125100
知识图谱(knowledge graph,KG)用结构化的形式描述客观世界中概念、实体及其关系,它将互联网的信息表达成更接近人类认知世界的形式,提供了一种更好地组织、管理和理解互联网海量信息的能力[1]。知识图谱以三元组的形式(头实体,关系,尾实体)存储知识和事件,以网络的形式作为展示,在网络中每个节点代表实体,节点之间相互连接的边代表关系。目前一些大规模知识图谱NELL(never-ending language learner)[2]、Wikidate[3]、YAGO(yet another great ontology)[4]等被广泛应用于各种自然语言处理任务中,例如语义搜索[5]、智能问答[6-7]、推荐系统[8-9]等。
尽管知识图谱中有着大量的实体、关系、三元组,但是现有的大部分知识图谱都是不完整的,具体体现在一些实体之间缺少对应的关系,一些头实体和关系间缺少对应的尾实体。知识图谱补全任务(knowledge graph completion,KGC)旨在学习知识图谱中现有的实体关系三元组,进而推断出知识图谱缺失的实体或关系。
知识图谱嵌入(knowledge graph embedding,KGE)旨在将实体和关系嵌入到潜在的低维数字表示中[10]。在过去几年,KGE 方法被证明在KGC 任务上是有效的[11-12],并且许多KGE方法已经应用于KGC任务,其中包括TransE(translating embedding)[13]、ComplEx(complex embeddings)[14]和ConvE(convolutional 2D knowledge graph embeddings)[12]等方法。但是目前的这些方法都假设KG包含足够的实体和关系数据,然而在KG 中少样本关系数据是广泛存在的,例如Wikidate 中大约有10%的关系只有不超过10 个三元组实例[3]。此外,在实际应用的过程中,社交媒体或推荐系统产生的KG,会随着时间的流动进行动态更新,更新后的新关系通常只有少量的三元组实例。这种情况会导致大部分KGC 方法的效果下降,因为这些方法都要求拥有足够的训练实例[15],所以在只拥有少数三元组实例的情况下,如何完成知识图谱补全任务是重要且具有挑战性的。
鉴于上述问题,Xiong等人[16]在2018年第一次定义少样本知识图谱补全概念,并提出Gmatching 模型用来解决FKGC(few-shot knowledge graph completion)任务。这也是少样本学习[17]在知识图谱补全上的第一项研究,之前少样本学习的研究主要集中在计算机视觉[18]、情感分析[19]和文本分类[20]等领域上。近年来,学者们也提出了很多解决FKGC 任务的方法[21],然而FKGC模型仍然面临着FKGC补全程度不高、无法很好利用KG中的结构信息、太过依赖于实体的邻域信息[22]等问题。本文将现有的FKGC 方法作为研究对象,整理并归纳FKGC经典方法以及最新研究成果,总结目前研究面临的挑战,并对未来的研究趋势进行展望。本文的主要贡献如下:
(1)对目前FKGC 方法进行全面分类,以解决问题的方法作为分类依据,分为基于度量学习的方法、基于元学习的方法以及基于其他模型的方法。
(2)详细阐述了每种FKGC 模型的思想,归纳并分析每种模型的核心、模型思路、特点和局限性;最后从方法分类、发表年份、数据集、评价指标、模型优缺点和模型思路上对FKGC方法进行横纵比较。
(3)列出常用的FKGC 数据集;对FKGC 中常用的评价指标进行说明;以NELL-One 和Wiki-One 数据集为例,在不同数据集上比较各个模型间的性能差异并进行分析。
(4)讨论了目前FKGC 任务的难点问题,展望了FKGC方法未来值得关注的发展方向。
1 少样本知识图谱补全概述和相关内容
知识图谱G表示为三元组{(h,r,t)}⊆E×R×E的集合,其中E和R是实体集合和关系集合。每个三元组都由一个关系r∈R和两个实体h,t∈E组成,它们之间可以表示为头实体h到尾实体t有一条有向边r连接。
在知识图谱中,知识图谱补全任务分为两种:一种是在已知两个实体(h,?,t)的情况下,预测其中的关系r;另一种是在已知头部实体和关系(h,r,?)的情况下,预测尾部实体t。目前研究者更专注于后一种研究。
少样本知识图谱补全任务考虑了实际场景,与知识图谱补全中假设每个关系都有足够的实体对不同。该任务只拥有少数与关系r相关的三元组作为参考集,需要预测查询集中潜在的尾实体t。
对于该任务而言,少样本知识图谱补全方法的目标是在给定参考集S的情况下,查询集Q正确尾实体ttrue的排名要高于其他错误尾实体。
对于FKGC任务而言,一些当前领域的相关内容如下:
背景知识图谱G′:是当前知识图谱G的一个子集,其中包含和任务关系r相关的三元组。
实体的一跳邻居集合Ne:一般在FKGC任务中Ne也被称为实体e的邻域,它是由背景知识图谱G′产生,其中包含所有与实体e相连接的关系r和尾实体t。
少样本关系的邻域:针对少样本关系r而言,它自身的邻域可以被定义为{h,t,Nh,Nt},其中h、t是头实体和尾实体,它们和关系r可以构成一个三元组(h,r,t);Nh、Nt是头实体和尾实体的一跳邻居集合。
2 少样本知识图谱补全方法
2018 年Xiong 等人[16]提出了少样本知识图谱补全的任务,并利用基于匹配网络的模型Gmatching试图对少样本三元组进行少样本关系学习来解决这一问题。由此少样本知识图谱补全任务受到学者们的广泛关注,目前现有的FKGC方法按照解决问题的方法分类可以分为基于度量学习的方法[16,23-34]、基于元学习的方法[35-45]以及基于其他模型的方法[46-63]。
2.1 基于度量学习的方法
度量学习的方法一般是从一组待训练的任务中学习到可概括的距离公式和相应的匹配函数,进而推广到新出现的任务中[20],此类方法大多采用深度孪生网络中所提出的通用匹配框架Matching Nets[64]。在KGC中,很多KGC模型在训练过程中都需要大量的数据作为支撑,如果在FKGC任务中使用,就会面对性能受限制或者没有足够数据支持的问题。针对这种情况,学者们结合度量学习的思想,提出了若干模型。
Gmatching 模型[16]是由Xiong 等人在2018 年提出,该模型的核心是利用实体嵌入信息和局部图结构来构建匹配度量函数。模型思想是针对当前任务的关系r,计算查询实体对与参考实体对的相似度,排序得到正确尾实体ttrue的排名。
如图1 所示,Gmatching 模型由邻居编码器和匹配处理器构成,在邻居编码器部分,为了得到实体e的邻域表示f(Ne),首先将实体e相连接的每一个关系和尾实体拼接,得到关系实体对的嵌入信息将每个关系实体对的嵌入信息合并:
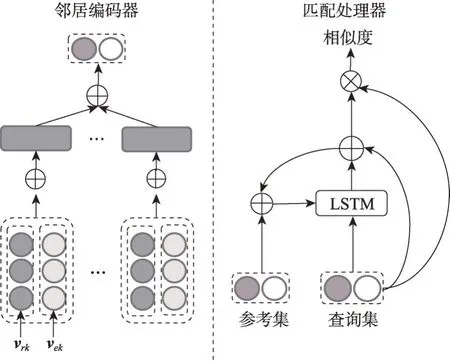
图1 Gmatching模型结构Fig. 1 Gmatching model structure
其中,vrk、vek分别是关系实体对(rk,ek)中关系和实体的嵌入信息,⊕表示拼接操作,σ为激活函数tanh,Wc是权重参数。在匹配处理器中,为了得到ttrue排名,分别将参考集实体对(h0,t0) 和查询集实体对(hi,tij)的邻域表示拼接后得到对应的参考集关系向量s和查询集关系向量q;最后利用式(2)求出所有查询集与参考集的关系相似度得分。
其中,hk、ck是LSTM(long short-term memory)网络的隐藏状态和单元状态,k是超参数。
作为少样本知识图谱补全任务的开山之作,Gmatching模型提出了一种基于关系学习的框架,与传统的知识图谱补全方法相比,该模型可以对任何关系进行预测,处理新添加的关系时也无需重新训练模型,而之前的方法通常需要微调模型以适应新关系。
虽然Gmatching模型的整体结构简单,但是每个部分都有各自的作用,其中邻居编码器利用局部的图结构更好地表示了实体信息,匹配处理器利用多步循环对两个集合的信息进行打分。在基于Wiki-One 数据集的实验中,该模型性能比TransE 在MRR(mean reciprocal rank)指标上提高12.8%,具有较好的实验效果。然而,此模型也存在一定缺点,由于邻居编码器在获取实体的邻域表示时,平等地集合邻域中的不同信息,忽略了无效实体对模型产生的影响,导致模型效果降低。
为弥补Gmatching 模型的缺点,Zhang 等人[23]在2020 年提出FSRL(few-shot relation learning)模型。该模型的核心是利用异构邻居解码器分配给邻域信息不同的权重,并在参考三元组集合中集成了来自多个三元组的信息,而在Gmatching中仅将单个三元组用于FKGC。如图2 所示,FSRL 模型提出了异构邻居解码器模块和聚合模块,在异构邻居编码器中,实体e的邻域表示f(Ne)不再采用集合所有嵌入信息的计算方式,而是为每个嵌入信息赋予一个权重αi,具体公式如下:
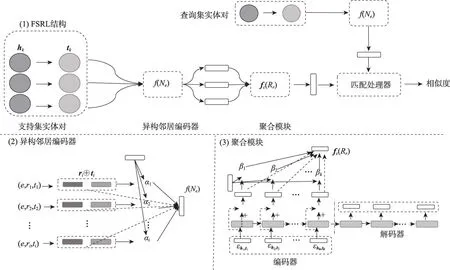
图2 FSRL模型结构Fig. 2 FSRL model structure
与Gmatching 模型相比,FSRL 模型的异构邻居编码器弥补了Gmatching模型平等分配权重的缺点,新增的聚合模块增加了三元组间的交互。实验结果表明,在Wiki-One 和NELL-One 数据集上,该模型的性能比Gmatching模型分别提高了0.08、0.04,这足以证明它的改进是有效的。此外,FSRL还通过实验证明在训练过程中参考集的大小会影响参考集嵌入的质量,为后续FKGC的研究提供了支撑。
尽管FSRL模型根据不同实体提供不同权重,在一定程度上降低了无效实体对模型的影响,但其赋予权重的方式仍是静态的,2020年Sheng等人[24]提出FAAN(novel adaptive attentional network)模型,该模型的核心是使用了实体和关系的动态属性[65]。之前的模型大多关注于实体和关系的静态信息,而忽略了它们的动态信息,例如实体在不同关系下的含义可能有所不同。为此FAAN模型提出自适应注意力[66]邻居编码器和Transformer[67]编码器来捕捉实体与关系的动态信息。
如图3 所示,在自适应注意力邻居编码器部分,由任务关系嵌入r和邻接关系嵌入rk求得权重αk,实体对嵌入信息为尾实体嵌入信息的集合,最后利用头实体嵌入h和实体对嵌入得到邻域表示f(Ne)。公式如下所示:
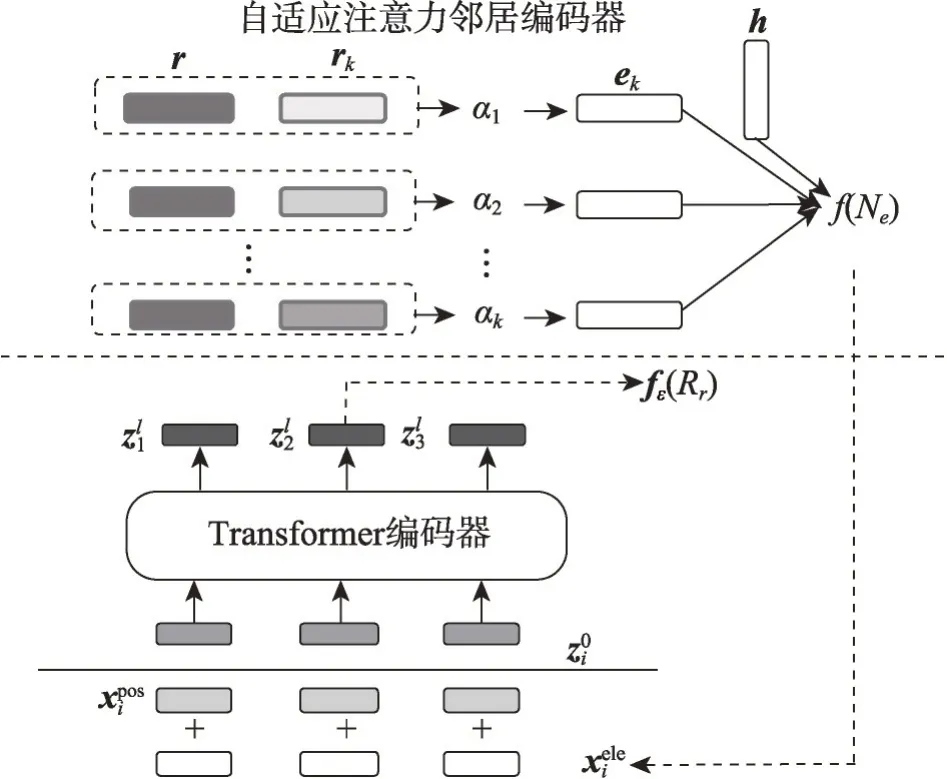
图3 FAAN模型结构Fig. 3 FAAN model structure
其中,qr为查询集关系嵌入表示,sk为参考集关系嵌入表示。
与当时其他模型不同,FAAN模型提出了一种新的范式,并且在邻居编码器部分将任务关系与邻接关系结合,这些改进不仅为邻域表示加入了更多的细粒度信息,也提供了一种计算相似度得分的新方法。在FKGC数据集上,FAAN模型的实验结果优于当时其他的FKGC方法,其他实验证明FAAN模型获取动态属性的方法提升了模型效果并且针对不同的任务关系具有良好的鲁棒性。但是FAAN 模型在邻居编码器部分,只是针对实体的动态信息进行改进,并没有建立参考集三元组间的联系,忽略了三元组间的交互信息。
现有的大多数基于度量学习的方法,都忽略了三元组内部和三元组间的实体交互,因为这些模型都是针对实体对表示进行相似度匹配。为探索这种交互信息在FKGC 中的作用,Liang 等人[25]在2022 年提出TransAM(transformer appending matcher)模型,他们认为这些实体的交互信息可以提供有价值的颗粒度语义表示。该模型的核心是将参考实体对和查询实体对作为序列以捕捉三元组内和三元组间实体的交互信息。具体过程为,将参考集和查询集实体化为一个序列sq,sq=[[CLS],h1,t1,…,hK,tK,hq,tq],其中hK、tK是参考集实体对的头实体和尾实体,hq、tq是查询集的头实体和尾实体;再通过实体编码器和实体邻域得到每个实体的最终表示xe,即:
与其他模型相比,TransAM模型利用旋转操作编码每个实体对的头尾实体,这种操作使得模型学习到了更多的结构化信息(即对称和反对称信息)。为了使三元组内部交互,TransAM构建了块注意掩码矩阵来约束每个实体,使它只关注于自身三元组。此外,Liang 等人为了保留三元组结构的同时分离实体信息和三元组位置信息,设计了一种分离三元组位置信息的编码方式。上述的这些方法使TransAM模型成为了目前最先进的方法之一,但是TransAM 的局限性在于模型过多地关注实体信息,而三元组内的关系信息只用于贡献权重,导致模型不能处理复杂的少样本关系,今后可以在这一方向上进一步研究。
表1汇总了本节所提到的基于度量学习的FKGC方法,可以看出度量学习的方法在逐步完善缺点的同时也在寻找更适合的匹配方法,但是复杂的少样本关系不仅是少样本知识图谱补全所遇到的问题,也是目前知识图谱补全存在的难点。

表1 度量学习方法汇总Table 1 Summary of measurement learning methods
根据对现有的基于度量学习的少样本知识图谱补全方法的整理,可以发现:目前的模型一方面在探索如何通过实体的邻域信息,获得更加丰富的关系嵌入表示,如FSRL、FAAN 等;另一方面受到当前自然语言处理中预训练语言模型的影响,探索如何构建一种匹配方法,能够更好地求出参考集与查询集的相似度得分,如TransAM等。
2.2 基于元学习的方法
元学习就是学会学习的学习[68],其特点是只使用少量的训练样本,也能快速学习新的概念或知识[69]。在FKGC的研究中,基于元学习的方法旨在学习训练任务中的关联三元组特征,从而在新的任务上进行泛化,其中比较有代表性的方法有MetaR(meta relational learning)模型[35]、Meta-KGR(meta-based multi-hop reasoning)模型[36]、GANA(gated and attentive neighbor aggregator)模型[37]、Meta-iKG模型[38]。
MetaR 模型[35]是由Chen 等人在2019 年提出的,该模型是第一个将元学习应用于FKGC 上的方法。MetaR 模型的核心是利用关系元信息和梯度元信息来加速模型的更新迭代与完成FKGC任务。
如图4 所示,首先聚合所有实体对的关系表示R(hi,ti),计算得到关系元信息RTr:
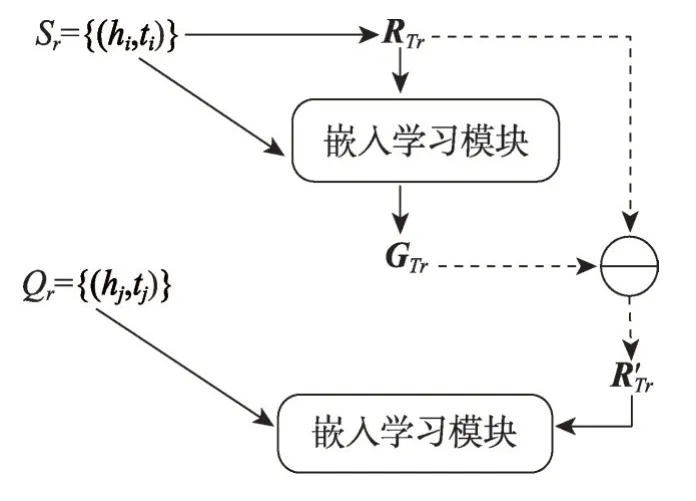
图4 MetaR模型结构Fig. 4 MetaR model structure
在得到当前任务Tr的关系元信息后,通过损失函数生成梯度元信息GTr:
其中,||x||代表向量x的L2 范数,s(hi,ti)是利用了TransE中的思想得到的评分函数,它假设头实体嵌入h、关系嵌入r、尾实体嵌入t满足h+r=t,L(Sr)是模型的损失函数,γ是超参数,L(Sr)代表损失函数的梯度。之后利用GTr对关系元信息的更新进行加速:
作为第一个将元学习应用于FKGC 的方法,MetaR模型不仅融合了TransE模型的思想,还证明了将关系特定的元信息从参考集转移到查询集的方法,在FKGC 任务上是有效的。同时,在基于Wiki-One 和NELL-One 数据集的实验中,无论是1-shot 还是5-shot的结果,都比当时的其他模型效果更好。但是MetaR模型的局限性在于计算关系元信息时,认为所有实体对的贡献相同,忽略了参考集中三元组对关系表示的不同影响。
Meta-KGR 模型[36]是由Lv 等人在2019 年提出的,该模型的核心是将强化学习(reinforcement learning,RL)[70]与元学习结合。该模型将具有相同关系r的三元组查询都视为一项任务,对每个任务先利用RL 训练一个代理,目的是搜索目标尾实体和推理路径,其中该模型为了使用决策的历史信息使用LSTM网络对搜索路径进行编码,训练过程中,此部分的损失函数定义为:
其中,r是查询关系,D是查询关系的三元组集合,es、eo代表头实体和目标尾实体,ai是动作,R(sT|es,r)是RL 中的奖励机制。在得到参考集合DS的参数θ后,为了使其包含不同任务的共同特征,达到能够快速适应少样本任务的效果,该模型利用元学习的思想,通过每个任务的查询集合DQ对θ进行更新,更新公式如下:
Meta-KGR 模型作为一种基于元学习的多跳推理模型,与之前的多跳推理模型相比,Meta-KGR 模型在FKGC 任务上更有优势。与其他FKGC 方法相比,Meta-KGR 模型能提供多跳的解释路径,而大多数方法都是缺乏可解释性的。此外,在基于FB15k-237 和NELL-995 数据集的少样本实验中,该模型效果均优于当时最先进的多跳推理方法,并且实验还证明了模型具有鲁棒性,即可以推广到不同类型的知识图谱。但是由于该模型的推理每一步都要求有对应的路径进行搜索查找,当出现没有路径的答案时,模型效果就大大降低。
在少样本知识图谱补全过程中,如果当前邻域过于稀疏,那么在构建邻域表示时邻域中的噪音信息会被放大,从而影响模型效果。为解决该问题,Niu等人[37]在2021年提出了GANA模型,该模型的核心是通过门控网络和图注意力机制[71]过滤邻域中的噪音信息,找到邻域中最有价值的信息。为了确定实体邻域的范围进而减少实体邻域中噪音信息的影响,GANA 模型首先拼接与实体相连接的每个关系嵌入和尾实体嵌入得到ci,同时赋予每个ci对应的权重αi:
其中,g是门值,它的目的是自动确定实体邻域的范围,进而利用图注意力机制赋予权重,得到噪音信息更少的实体邻域表示e′,即:
其中,ve是当前实体的嵌入信息,W是权重参数。对于当前三元组(h,r,t)而言,将头实体邻域表示h′和尾实体邻域表示t′拼接就得到了减少噪音信息后的三元组关系邻域表示s。此外,GANA模型为了对复杂关系进行建模,提出了MTransH 方法,这种方法将TransH[72]作为评分函数与元学习进行结合,与MetaR模型相比,这种结合效果更好,因为TransH模型相对于TransE 模型可以更好地模拟三元组中的复杂关系。GANA 模型在基于Wiki-One 和NELL-One 数据集的实验中,与MetaR模型相比,MRR指标分别提升8%、5%。在针对复杂关系建模的实验中,GANA 模型也证明了自身在处理1-N、N-1上的优势,这说明将元学习与TransH结合的方法在对复杂关系建模时是有效的。但是实验同时也暴露出GANA在N-N上的效果不佳,这也和N-N 的情况下,FKGC 任务难度增加有关。
Meta-iKG 模型[38]是Zheng 等人在2022 年提出的,该模型的核心是利用局部子图传输特定子图信息。该模型将FKGC任务转换为子图建模问题,将相同关系的三元组查询视为一个任务。在特定关系学习模块利用GNN网络[73]围绕特定关系的子图学习到参数θ,再构建元学习器模块,从θ中提取出不同任务中的相同特征,最终达到快速适应少样本和多样本任务的目的。
与其他元学习模型相比,Meta-iKG 模型在传统元学习的基础上,引入了多样本关系的更新过程,使其能够很好地对少样本关系进行泛化,基于FB15k-237 数据集的实验也证明了这一观点。同时因为模型只能提取子图的结构语义,而子图是一个有向图结构,这就导致模型不能很好地解决反对称关系的三元组类型。
表2 汇总了本节所提到的基于元学习的FKGC方法,MetaR模型[35]、Meta-KGR模型[36]、GANA模型[37]、Meta-iKG 模型[38]都在元学习的方法中具有代表性,同时它们都能够较好地适用于FKGC任务,只是每个模型的侧重点不同。MetaR 模型侧重于利用元学习来解决少样本问题,Meta-KGR 模型侧重于将RL 和元学习结合,GANA 模型侧重于使用门控网络和图注意力来消除噪音,Meta-iKG 侧重于利用局部子图来传输特定的子图信息。
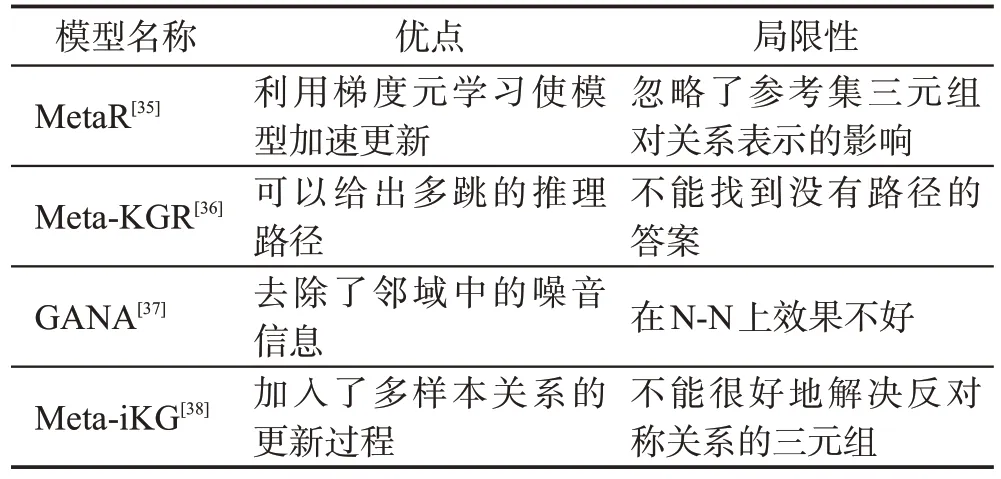
表2 元学习方法汇总Table 2 Summary of meta learning methods
整体而言,基于元学习的方法更关注于关系信息的获取,模型整体结构一般分成两部分:第一部分负责融合信息,获取到任务关系的表示;第二部分负责利用元学习加速更新过程,达到快速适应新关系的目的。在这个过程中,研究者为了达到更好的效果,一般将元学习的方法与其他方法进行结合,例如Meta-KGR 模型中结合RL,GANA 模型中结合图注意力网络,Meta-iKG模型中结合GNN网络等。
2.3 基于其他模型的方法
除了上述两种主流方法外,还有少数研究者正在拓展其他方法的研究,但是由于这些方法之间理论不同,又无法汇总出一个新的类别,只能暂时将它们归为基于其他模型的方法。虽然这些研究并不一定有突破的进展,但是为后续的研究者提供了一条新的思路。本节将介绍一些其中典型的方法,例如基于双重过程理论的模型CogKR(cognitive knowledge graph reasoning)[46]、基于知识协同微调方法的模型(knowledge coordination fine-tuning,KnowCo-Tuning)[47]、基于对抗迁移学习的模型wRAN(weighted relation adversarial network)[48]和基于注意力机制的模型[49]。
双重过程理论[74]认为人类的推理系统由两种不同形式的系统组成:一个系统是无意识且隐藏的,它负责检索大脑中的信息;另一个系统是有意识且可控的,它负责将收集到的信息进行推理。基于此理论,Du 等人[46]在2019 年提出了CogKR 模型,该模型的思路是首先在摘要模块中通过实体对(h,t)得到潜在关系表示ωh,t:
其中,Ne是实体e的邻域,ve、vr是实体和关系的嵌入表示,W是权重参数,ωe是实体的信息表示。之后给定一个头实体h^,与人类的推理过程类似,模型通过对认知图谱的迭代更新,最终预测出正确的尾实体t^,这个过程结合了隐式搜索和可控推理。
与其他方法相比,认知图谱的使用具有两个优势:一是图结构的数据更加灵活;二是搜索效率更高,因为传统的嵌入方法完成一次查询需要遍历整个实体集合,而CogKR 模型依靠局部结构大大降低了时间复杂度,所以CogKR 可以更容易地扩展到大型知识图谱上。在FKGC 的数据集上,CogKR 模型与Gmatching模型相比,MRR指标提高了5.0%,但是在长路径的推理上,Gmatching 模型更占优势,尤其是一些没有路径的答案,这与CogKR 模型结构模拟了推理系统的搜索与推理有关,导致路径越长找到答案的概率就越小,在后续的研究中,可以将更多的信息融入到模型中,进而加强长路径上的推理能力。
预训练语言模型已经在自然语言处理的各个领域取得了优异的结果[75],研究者最近的工作是研究如何利用提示对下游任务进行微调,以更好地利用预训练语言模型。提示包含两部分:一是模板,它由自然语言组成用来提示模型的输出;二是提示词,它表示如何将模型输出的词汇转换为每一个类别的分数。因此,在FKGC 任务中,如何结合知识图谱的显示知识和预训练语言模型的隐式知识成为了一个问题。针对此问题,文献[47]提出了一种知识协同微调模型(KnowCo-Tuning),该模型的核心是通过协同微调算法来学习最优的模板和标签。具体过程如下:
首先基于知识图谱的结构化知识为FKGC 任务生成模板τ:
其中,XS、XO分别是头实体和尾实体。
其次使用一对多的映射函数M(yj)=={v1,v2,…,vk},v∈V来表示标签的语义信息特点,其中v表示语言模型字典中的字或词。
最后KnowCo-Tuning 模型的标签概率组合为如下形式:
其中,h[MASK]是τ中[MASK]位置对应的特征向量,wM(y)是标签词汇对应的特征矩阵,两者相乘最终得到匹配概率。
与其他FKGC模型相比,KnowCo-Tuning模型不仅是一种新颖的基于预训练语言模型的微调范式,而且模型训练过程简单、有效,同时KnowCo-Tuning模型具有拓展到其他任务的能力。与常规的Fine-Tuning模型相比,KnowCo-Tuning模型能够更好地利用模型中存储的外部信息,这是因为其自身没有引入新的网络框架和其他参数并且将微调和预训练统一进行。在FKGC 的实验中,其性能优于传统的TransE[13]、TransH[72]等模型。但是在模板τ中,头尾实体被直接使用,由于实体在不同情况下,它的含义可能是不相同的,而通过实体的邻域可以得到更多的实体信息,KnowCo-Tuning模型忽略了实体的邻域信息。
对抗迁移学习指通过对抗性学习提取域的不变特征以完成迁移学习,一般从一个领域的多资源数据中学习特征,用于不同但相关的领域中,通常应用于少样本领域[76]。受到对抗迁移学习的启发,Zhang等人[48]在2020 年提出了wRAN 模型,模型核心是在特征迁移的过程中,通过选取无关样本减少负迁移的影响。首先利用卷积神经网络将三元组编码成向量,其次利用对抗迁移学习框架区分不同关系的分布,最后为了识别不相关的样本并降低它们的权重,该模型提出了一种关系门控机制成功解决负迁移问题。作为第一个将对抗迁移学习应用于FKGC 任务的wRAN 模型,不仅可以将FKGC 任务和关系提取任务相结合,而且在FKGC和关系提取的少样本数据集上都超过了当时的模型。但是wRAN模型在识别不相关样本时,会对语义相似样本给予不正确的权重,这也影响了模型的最终结果,在未来的研究中,可以将注意力机制引入到模型中,与关系门控机制一起合理分配权重。
现如今,注意力机制已经被广泛应用于各个领域中。Xie 等人在2019 年提出了一种基于注意力机制的模型(因为原文中并没有给出模型名称,所以下文皆用AMmodel代表此模型)[49],与FAAN 模型获取关系嵌入信息相比,该模型直接利用注意力机制构建了一种新的匹配函数。首先将Gmatching 模型的1-shot匹配处理器升级成为少样本匹配处理器;接着利用注意力机制对隐藏层状态进行处理,这样的操作为模型引入了更多的信息;最后集合所有少样本信息得到相似度分数。与其他模型相比,新的匹配函数不仅可以获取到更为丰富的关系表示,还在训练的过程中减少了大量的参数。在基于Nell-One 的实验中,该模型与Gmatching 相比,性能提高了0.03。但是由于该模型在获取关系实体对的嵌入信息时,只是单纯地将实体关系信息拼接,没有考虑到邻域中的噪音信息。
表3汇总了本节所提到的基于其他模型的FKGC方法,可以看出CogKR模型[46]、Know-CoTuning模型[47]、wRAN模型[48]、AMmodel模型[49]分别在搜索和推理效率、结合预训练语言模型、降低不相关信息权重、减少参数和优化匹配函数等方面都发挥了各自的优势,提高FKGC方法的效果。但是由于它们都来源于不同的理论方法,它们的局限性也互不相同,例如CogKR模型的理论源自推理模型,从数学角度分析,路径越长推理出结果的概率就越小,因此CogKR 模型在长路径的推理上效果不好;wRAN模型的理论源自对抗迁移学习,对于对抗网络而言,语义相似但是字符不同的语句就是不相同的两句话,这样就会导致wRAN 模型初始在语义相似样本上的效果不好。总体来说,这些模型的提出不仅推动了FKGC领域的进步,还丰富了FKGC 方法的研究,为后续的研究者提供了广泛的思路。

表3 其他方法汇总Table 3 Summary of other methods
3 少样本知识图谱实验比较
本章介绍了在少样本知识图谱补全任务中常使用的数据集,介绍了实验中常用的评价指标,对上述模型的常用数据集、评价指标、模型特点和实验结果进行了总结归纳。最后以NELL-One 和Wiki-One 数据集为例,展示了上述模型在少样本知识图谱补全任务上的实验结果。
3.1 常用数据集介绍
随着研究者对少样本知识图谱补全任务的探索,逐渐出现了一些针对少样本知识图谱补全任务的数据集,其中Xiong 等人构建的两个数据集NELL-One和Wiki-One频繁被用于少样本知识图谱补全任务。
NELL-One和Wiki-One分别源自NELL和Wikidata数据集。NELL数据集[2]是一个通过阅读网络持续收集结构化知识的数据集,而NELL-One数据集删除了NELL中的反向关系并筛选出其中拥有少于500个大于50个的实体关系三元组。但是NELL-One数据集不能测试出模型在大规模KG 上运行的能力,同时,Xiong等人也希望有足够多数据可以对此进行评估,因此他们用同样的方法构建一个基于Wikidata[3]的FKGC数据集Wiki-One。从表4中可知,就实体和三元组的数量而言,Wiki-One数据集比NELL-One数据集都要大一个数量级。
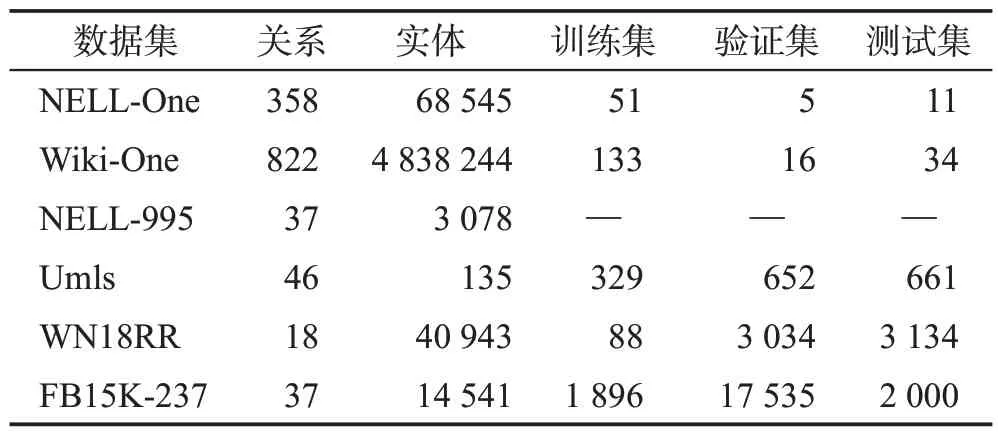
表4 少样本知识图谱补全常用数据集Table 4 Often-used datasets of FKGC
除了上述两种经常被使用的数据集外,还有一些在FKGC 任务中使用过的数据集,其中包括具有多种关系类别的Umls[77]数据集、基于WordNet[78]的WN18RR 数据集、基于Freebase[79]的FB15K-237 数据集和基于NELL的NELL-995数据集。本文收集了出现在FKGC 任务中的数据集,总共6 个,每个数据集的实际数据见表4。
3.2 评价指标
目前针对少样本知识图谱补全算法,还没有特定的评价指标,而是使用传统的知识图谱补全算法的评价指标MRR 以及Hits@n,其中MRR 是每个少样本知识图谱补全算法普遍使用的评价指标,此外,不同的少样本知识图谱补全算法也会采用不同的Hits@n指标。
(1)MRR
MRR指标代表在所有预测的三元组中正确实体在预测结果中的平均排名的倒数,该指标数值越大代表正确实体的排名越靠前,是评价少样本知识图谱补全算法的重要指标。
(2)Hits@n
Hits@n指标代表在所有预测的三元组中正确的缺失实体排名在前n名的概率,例如Hits@1 代表正确的缺失实体在所有预测结果中排名第一的概率。该指标的数值越大代表少样本知识图谱补全算法的性能越好,常见的指标参数为Hits@10、Hits@3 和Hits@1。
3.3 方法比较
本文将FKGC方法分为三类,并针对每种方法所述模型,从方法分类、发表年份、数据集、评价指标、模型优点、局限性和模型思路上进行比较,具体的比较结果见表5。
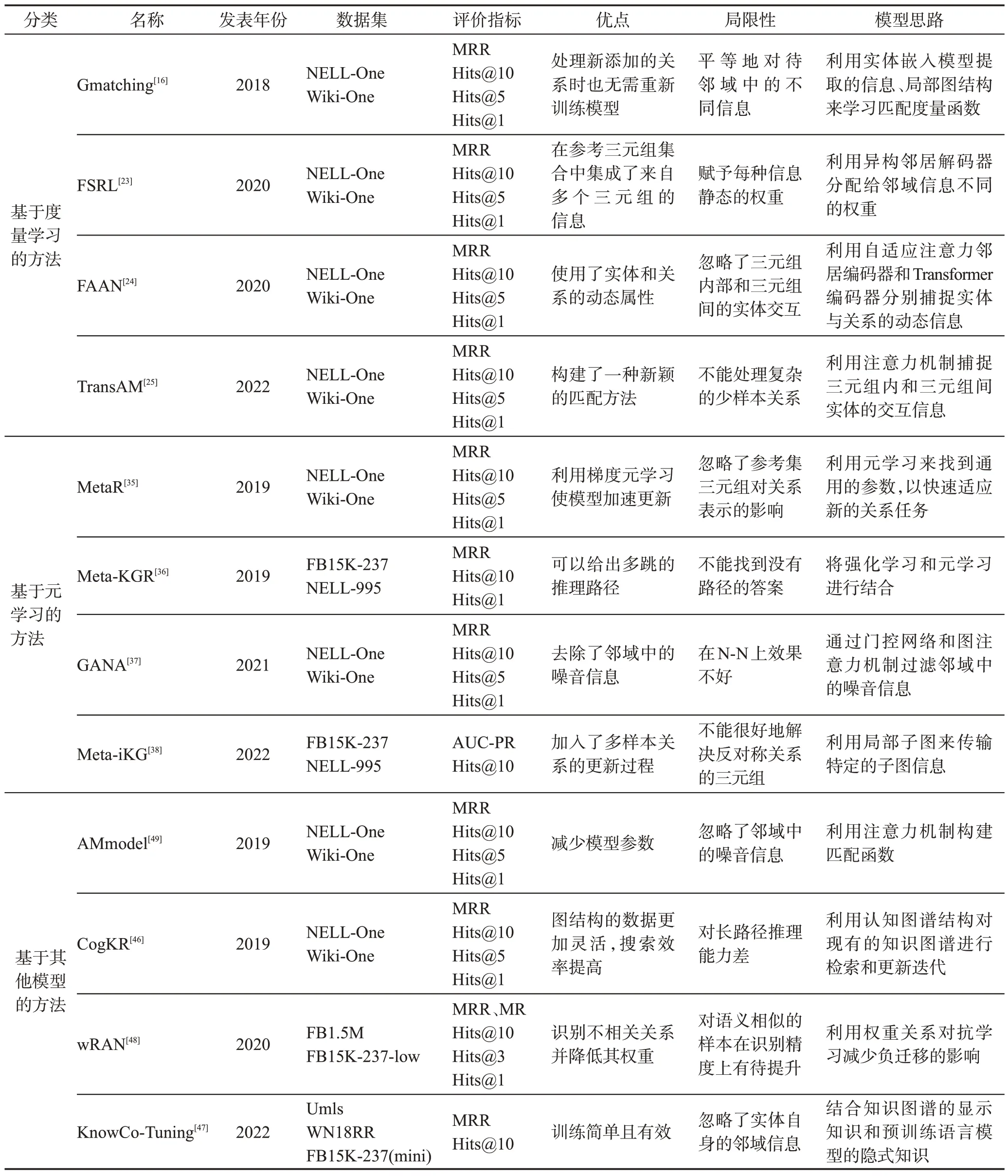
表5 少样本知识图谱补全模型比较Table 5 Comparison of FKGC models
从论文的发表时间可以看出,自从FKGC任务在2018 年被提出后,有越来越多的研究者开始探索如何完善FKGC 方法或者是提出新的方法来完成FKGC任务;从数据集的使用上可以看出,NELL-One和Wiki-One 数据集是FKGC 任务中的常用数据集,但是随着时间的发展,一些新的数据集也被用于此任务,例如2022年KnowCo-Tuning[47]模型使用umls、WN18RR、FB15K-237(mini)数据集,这些数据集第一次出现在FKGC任务中;从评价指标的使用上可以看出,MRR、Hits@n已经成为FKGC方法通用的评价指标,但是一些模型也在使用新的评价指标,这些新出现的评价指标也可能成为以后的通用评价指标;从模型的局限性分析,可以看出早期模型的局限性问题已经被新的模型所解决,但是对于最新的模型来说,少样本中复杂的关系、对称与反对称问题一直是一个难点。
3.4 实验结果
为了加深对FKGC方法的理解,本节汇总了上述模型在NELL-One 和Wiki-One 数据集上的实验结果。此外,为了与传统的KGC方法进行比较,表中还加入了TransE 模型、TransH 模型、DisMult 模型等经典的传统KGC模型结果。为了保证实验结果的公平和客观,本文只选用了这些模型中在NELL-One 和Wiki-One 数据集上的结果,并保证它们在训练时的嵌入维度分别是100和50。
传统KGC方法的最佳参数源自相关文献[26,37];FSRL模型中LSTM层隐藏状态维度为200和100,匹配网络的递归步数为2;FAAN 模型中transformer 层数为3和4;GANA模型中BiLSTM层数为2;TransAM模型中transformer层数为3和4(其中传统KGC方法实验结果来自文献[26]和文献[37],Gmatching 模型、MetaR模型、FSRL模型、GANA模型结果来自文献[37],其余模型结果均源自相关文献。表6、表7 中加粗为最好结果,下划线为次好结果,“—”代表此模型并没有相关的实验结果)。
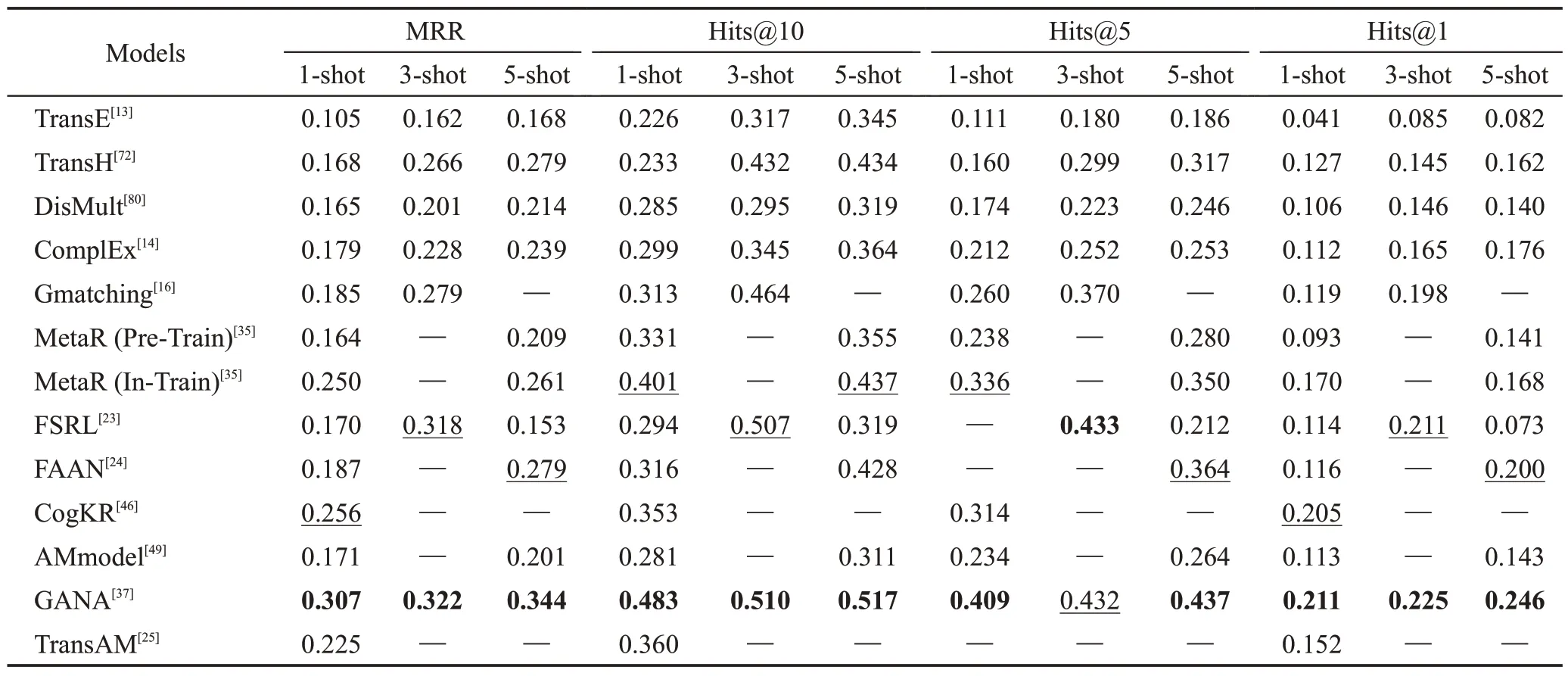
表6 在NELL-One数据集上FKGC实验结果Table 6 Experimental results of FKGC on NELL-One dataset
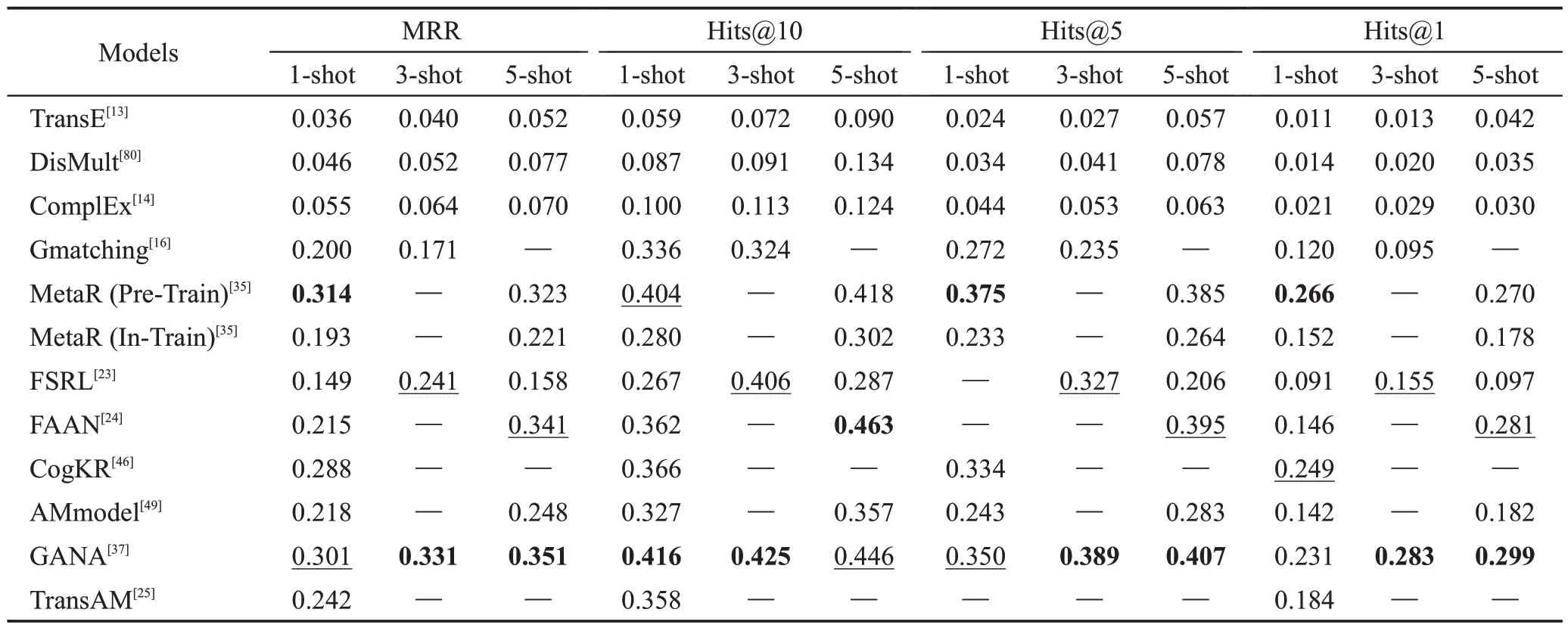
表7 在Wiki-One数据集上FKGC实验结果Table 7 Experimental results of FKGC on Wiki-One dataset
从表6可以看出,在NELL-One数据集上,FKGC的方法在5-shot 的条件下,每个指标都优于传统的KGC模型,在其他shot的条件下,大多数指标都优于传统的KGC 模型,这证明了FKGC 方法在FKGC 任务上的优越性;在基于度量的方法中,1-shot 的条件下,TransAM的效果最好,其MRR指标优于其他的方法;整体而言,GANA 模型的效果最好,因为其大部分指标都是最好的结果,只有3-shot 条件下,Hits@5的结果是次好结果。
从表7 可以看出,在Wiki-One 数据集上,FKGC方法的指标没有全部优于传统的KGC 模型,这是因为Wiki-One 数据集比NELL-One 数据集大一个数量级,使得传统的KGC 模型学习到了更多的信息。在基于其他模型的方法中,CogKR模型的效果在1-shot的条件下最好;在基于度量学习的方法中,TransAM模型的效果在1-shot 的条件下最好;整体而言,GANA模型的效果要优于其他FKGC模型。
4 研究与展望
本文对目前FKGC任务的研究现状进行了阐述,对目前FKGC 领域中经典的模型和最新的成果进行了总结和归纳。本章讨论了目前FKGC 研究的难点问题,并对少样本知识图谱补全技术的发展方向进行了展望。
基于各种方法的FKGC 任务虽然已经取得了一些成果,但是依然面临着一些问题:
一是邻域信息的使用和去噪。目前大部分的FKGC 方法都是集合实体的邻域信息得到关系表示最终完成任务,这就导致在集合实体邻域信息的过程中,很多方法只选用了实体的一阶邻居信息,而忽略了三元组周围的高阶邻域信息。其次,在集合实体邻域信息时,有些实体并没有很多邻居信息,但是伴随编码范围的扩大,就需要引入很多无关的信息甚至是噪音信息,这就导致得到的实体邻域信息质量不高甚至严重影响最终模型效果。目前研究者已经开始研究如何获取和使用更高阶的邻域信息同时降低邻域信息中的噪音,例如GANA 模型中使用门控网络处理了一部分的噪音信息并取得了很好的效果。后续的研究者还需要探索更好的方法。
二是复杂的关系。对于三元组的关系而言,可分为1-1、1-N、N-1 以及N-N 的关系;对于模型而言,越复杂的关系越需要更多的样本来学习,但是少样本知识图谱补全任务又无法提供大量的样本,这就导致了复杂的关系对于所有FKGC 方法而言都是困难且充满挑战的。因此如何设计一种针对复杂关系的表示方法,让模型在少量样本下也能识别出复杂关系,仍是今后研究难点。
随着FKGC技术的不断发展,越来越多的研究者开始关注此任务,未来的发展方向可以从以下几方面考虑:
一是少样本时序知识图谱的补全。现有的大多数知识图谱都是静态的图结构[81],但在实际使用的过程中,知识图谱的图结构往往会伴随着时间而发生变化,例如增加实体或者删除实体之间的关系。这种结构变化虽然短时间内对全局影响不大,但在长期的改变下,为了静态图而研究的方法无法适用于动态的变化。文献[82]提供了一种新颖的思路,利用自我注意力机制来编码实体间的时序信息,通过一次性学习框架来完成少样本时序知识图谱的补全任务。除此之外,还有很多少样本时序知识图谱的补全方法[83-84]。因此如何对少样本时序知识图谱进行补全具有较大的显示意义和应用价值,同时可能也是未来的研究方向之一。
二是知识图谱嵌入方法的结合。知识图谱嵌入的方法被广泛应用在FKGC 的方法中,例如:Gmatching模型[16]中利用知识图谱嵌入的各种方法作为预训练得到实体和关系的嵌入信息;MetaR 模型[35]中利用TransE[13]的思想求出梯度元信息,并对最终的结果进行打分;GANA模型[25]在局部阶段将TransH[72]与元学习结合建模复杂的关系信息。知识图谱嵌入方法的质量对FKGC方法的效果具有显著的影响[22],因此研究FKGC 中如何更好地结合知识图谱嵌入方法具有重要的意义。
三是对零样本方法的研究。零样本学习[85-86]的目的在于预测出没有在训练数据中出现的数据。在现实生活中,知识图谱每次更新都有可能加入新的数据,那么这些没有被模型见过的数据,会影响到模型的实际效果[86-87],如文献[88]利用GAN(generative adversarial networks)的思想,创建了一种生成类的零样本学习框架,对不可见数据进行预测以完成零样本知识图谱补全任务。因此,对零样本知识图谱补全任务的关注和研究也具有一定的意义。此外,为了更加有效地评估零样本知识图谱补全方法,根据具体的任务定义,制作通用的数据集和评价指标也有着一定的必要性[89]。
