半监督多源域适应集成的球磨机负荷参数软测量
2019-10-21李思思阎高伟杜永贵
李思思, 阎高伟, 闫 飞, 程 兰, 杜永贵
(1.太原理工大学 电气与动力工程学院,太原 030024;2.山西工程技术学院,阳泉 045000)
流程工业在实际运行过程中,由于运行任务与设定值的变化、外界环境的改变、设备重组等因素,会导致工况发生改变[1]。球磨机是应用于电力、化工等流程领域的典型设备,具有强耦合、非线性和多工况等特点。该设备负荷参数的准确检测对于磨矿作业环节的质量控制、磨矿效率和能耗降低起着至关重要的作用。因此,本文以球磨机负荷参数的预测为例开展研究。
目前,球磨机负荷参数检测受限于建模机理及物理条件的复杂性,常采用软测量方法建模,即选择与主导变量相关的辅助变量(筒体振动或振声信号[2-3])建立软测量模型得到负荷参数预测值。常见的建模方法有偏最小二乘(Partial Least Squares,PLS)[4]、核模糊回归[5]以及极限学习机(Extreme Learning Machine,ELM)[6]等。上述建模方法仅适用于单一工况的数据。
在实际运行过程中,不定期添加钢球或输入矿石成分的变化会引起工况的改变。工况改变后导致待测数据(目标域数据)和历史数据(源域数据)分布存在差异及待测工况数据不足的问题。若根据源域数据建立软测量回归模型,则会违背机器学习方法建立在数据同分布条件的前提;若利用少量目标域数据建模,模型预测效果往往不理想。近年来,为适应工况的变化,广泛采用即时学习、集成学习的建模策略。文献[7]提出一种基于k近邻的局部建模方法。文献[8]引入因果关系利用动态主成分分析实现过程监控。Ma等[9]和Jaffel等[10]运用移动窗策略,对模型实时更新。针对在线测量中可能产生的偏差,Shao等[11]提出半监督的选择性集成建模策略。然而,即时学习在数据分布差异大的情况下会形成较大的期望风险,集成学习更新策略由于各子模型的输出置信难以估计,存在较大的结构风险。
因此,针对工况改变引起的模型失配问题引入迁移学习[12-14]策略。该策略放宽了数据服从同分布的假设,通过抽取领域间“隐含语义”或挖掘领域间“共享知识结构”,利用源领域已有的知识来解决未知目标领域(但与源领域相关)中仅有少量有标签样本数据甚至没有标签样本情况下的学习问题。迁移学习方法分为特征表示法和实例权重法。流形正则化域适应[15]通过特征映射实现知识的迁移。但是,流形正则化域适应是一种无监督的方法,在特征变换过程中不能有效利用已有的标签信息,导致算法性能受到影响。为此,将标签信息引入流形正则化域适应的目标函数,研究基于半监督域适应的球磨机负荷参数软测量方法,该方法优点为:① 通过迁移学习的方法实现变工况数据的建模;② 将标签信息考虑在特征空间变换的过程中以提高负荷参数预测精度。为进一步提高模型预测精度,采用多源域集成策略,利用多源域信息互补,更加有效地迁移源域知识到目标领域,提高目标领域的预测能力。
1 理论与算法
迁移学习是运用已有的知识对不同但相关领域问题进行求解的一种新的机器学习方法。该方法放宽了传统机器学习中的两个基本假设:① 用于学习的训练样本与新的测试样本满足独立同分布的条件;② 必须有足够可利用的标记样本才能习得一个好的模型。本文通过流形正则化保持空间结构不变;通过最大方差保证目标域数据对不同负荷参数表示能力;通过希尔伯特-施密特独立标准(Hilbert-Schmidt Independence Criterion,HSIC)[16]引入标签信息;通过扩展非参数最大均值差异减小源域和目标域的均值距离,得到特征变换矩阵,将历史数据和待测数据映射到公共子空间。具体方法如下。
1.1 流形正则化域适应方法
针对不同工况数据分布差异性的问题,采用流形正则化域适应的方法实现负荷参数预测。该方法首先集成流形约束、最大方差及扩展非参数最大均值差异方法得到最佳特征变换矩阵;然后,将目标域数据和源域数据的特征信息通过投影变换矩阵投影到公共子空间;最后,应用统计方法(如PLS)或神经网络(如反向传输神经网络(Back Propagation,BP))建立软测量模型,从而合理、有效地对目标域球磨机负荷参数进行预测。其目标函数为
(1)
式中:V为特征变换矩阵;L为Laplacian矩阵;Mc为扩展非参数最大均值差异矩阵;上标s、t分别表示源域数据及目标域数据;X=[Xs,Xt];λ1、λ2为平衡因子。
1.2 半监督域适应方法
流形正则化域适应属于无监督特征映射方法,无法将标签信息融入特征映射的过程来提高公共子空间数据的可辨识属性。为提高模型预测精度,将少量目标域及源域的标签信息引入流形正则化域适应,解决数据分布差异造成模型预测精度低的问题以及待测工况样本少的问题。
本文通过HSIC将标签信息引入流形正则化域适应。HSIC计算两组数据集间再生核希尔伯特空间的协方差来衡量数据之间的独立性。设Kx、Ky为两组数据集X、Y相应的核矩阵,由文献[16]得希尔伯特经验估计为
EHSIC=(n-1)-2Tr(KxHKyH)
(2)
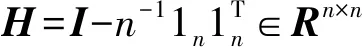
max Tr(VTXHYHXTV)
(3)
将式(3)引入式(1)得到半监督域适应的目标函数
(4)
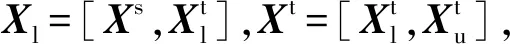
为求得特征变换矩阵V,将式(4)最大化问题转化为
(5)
引入拉格朗日乘子
(6)
式(6)对V求偏导,并令其为0,得:
τV=(λ3XsLs(Xs)T+
(7)
半监督域适应方法具体过程如表1所示。

表1 半监督域适应方法
半监督域适应方法利用源域数据、目标域数据、源域数据标签及少量目标域数据的标签信息得到特征变换矩阵;然后,将源域数据及目标域数据投影到公共子空间。该过程充分考虑标签信息对特征变换矩阵的作用、数据流形结构的不变性,从而提高球磨机负荷参数的预测精度。
1.3 半监督多源域适应方法
半监督域适应是迁移已有单一源域的知识来解决未知目标领域的域适应学习方法。当历史数据库中有多个源域时,如果仅使用其中一个域作为源域进行训练就会忽略其它域对目标域的有用信息,且不同源域数据存在信息相关与互补的特点,因此,可以充分利用多个源域的数据从而提高模型的预测性能。本文建立基于半监督多源域适应集成的软测量模型。该模型首先根据式(8)求得特征变换矩阵V′;然后分别将多个源域及目标域数据投影到公共子空间,并建立相应的回归模型;最后通过最大均值差异(Maximum Mean Discrepancy, MMD)加权多个源域负荷参数预测值。
(8)
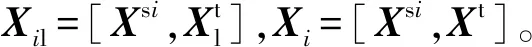
(9)
半监督多源域适应方法具体过程如表2所示。

表2 半监督多源域适应方法
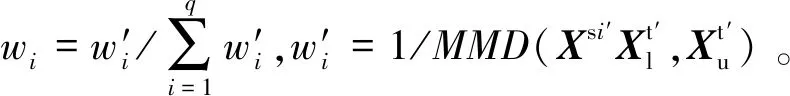
2 实验研究
球磨机负荷参数(如料球比(Material to Ball Volume Ratio,MBVR)、浓度(Pulp Density,PD)、充填率(Charge Volume Ratio,CVR))的准确检测对于磨矿作业环节的质量控制、磨矿效率和能耗降低起着至关重要的作用[17]。为此,采集与负荷参数相关的振动信号,建立模型,得到负荷参数预测值。
2.1 数据采集与预处理
实验采用Φ602 mm×715 mm小型实验球磨机。其中,球磨机最大钢球装载量为0.6 t,实验过程筒体转速为43 r/min。磨机筒体中部有圆形加料口,用于添加钢球、物料和水。实验过程采用的物料是铁矿粉,密度为2.3 t/m3。研磨介质采用直径为30 mm的钢球。球磨机型号为Y112M-4的三相异步电机驱动。三相电机功率为4 kW、额定电流为8.8 A、电压380 V、转速为1 440 r/min。
首先,在轴承座上安装振动传感器,通过振动传感器采集振动信号;然后利用数据采集模块将振动传感器输出的模拟信号放大并转换成数字信号,送入上位机,用LabVIEW编写的程序完成数据的读取、显示和保存工作。
通过改变介质充填率(Ball Charge Volume Ratio,BCVR)来模拟工况突变,即分别采集BCVR为0.30、0.35、0.40、0.45、0.50的5组实验数据。这5组数据对应工况为工况1、工况2、工况3、工况4、工况5。每组实验通过连续添加物料量改变CVR、MBVR、PD。每个工况下的数据如表3所示。以工况1的数据为例,分别固定球磨机筒体内球和水的质量,筒体内物料由起始重量25.5 kg逐渐增加到174 kg,共增加了139次。
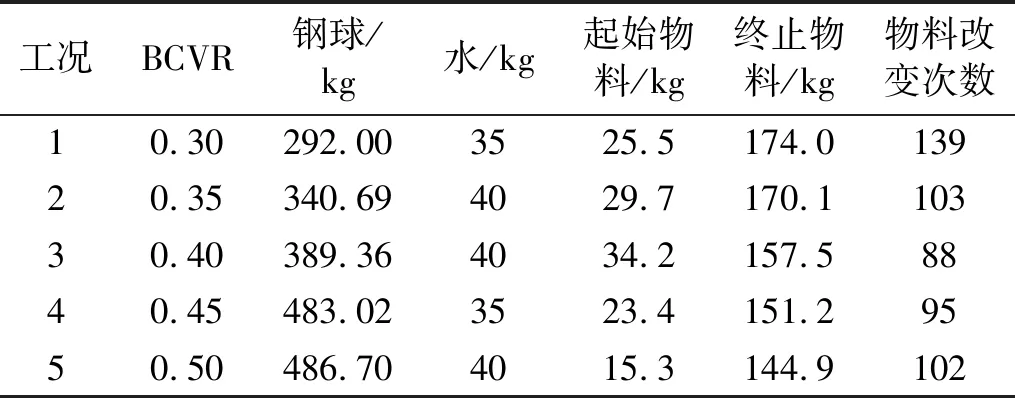
表3 工况突变实验情况
将每个工况振动信号平均分为28个样本,每个样本覆盖长度大于湿式球磨机旋转一周所用时间,然后将时域信号通过快速傅里叶变换转换为频域信号。
邻域保持嵌入(Neighborhood Preserving Embedding,NPE)[18]算法通过最优映射变换矩阵将数据从高维空间映射到低维的特征空间中。在低维空间中保持数据固有的局部领域流形结构不变性。以介质充填率变化的五种工况为例,每个工况下随机选取500个振动信号的样本,通过NPE将高维频谱特征降维至三维空间进行可视化。图1给出了五种工况下数据三维空间的分布情况。从图1可知,在不同工况下,数据分布存在差异性。
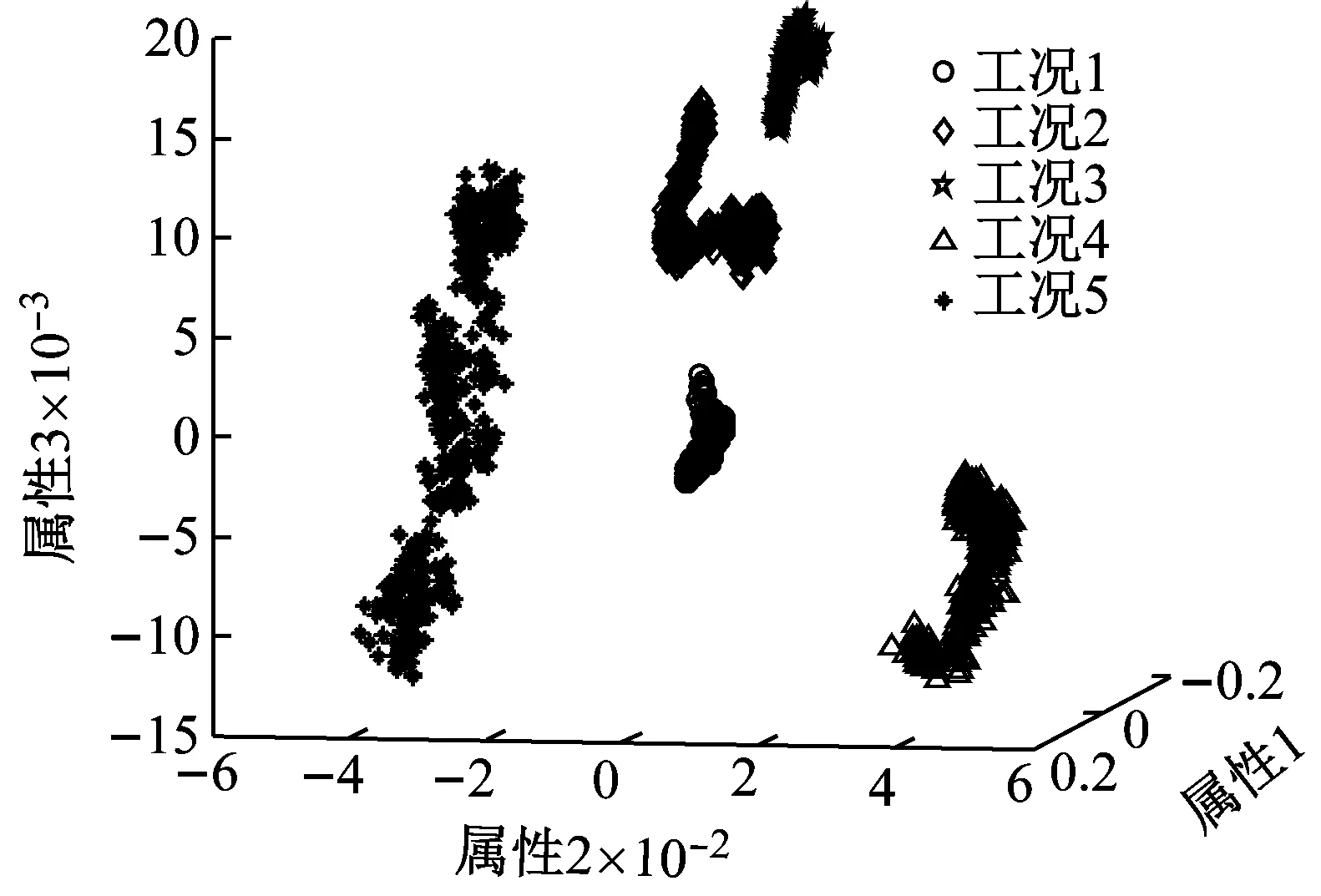
图1 不同工况数据降维后的分布情况
Fig.1 The distribution of data of different working conditions after dimensionality reduction
2.2 基于半监督域适应的磨机建模方法
基于半监督域适应球磨机负荷参数建模方法通过特征映射将数据从高维空间投影到公共子空间,实现负荷参数较高精度预测。
2.2.1 特征映射
特征映射具体过程如下:根据表1的Step1~Step3将源域数据、目标域有标签数据、目标域无标签数据分别投影到公共子空间。其中式(7)中参数λ3、λ4和λ5通过网格搜索法确定。
为得到特征变换后的数据分布情况,采用半监督域适应将源域和目标域数据进行特征映射,并与传统降维方法(NPE)作对比。首先,利用工况1的数据作为源域数据,工况3的数据作为目标域数据。然后,分别通过NPE、半监督域适应得到特征变换后的数据。最后,以特征变换后的第一维数据为例绘制图2。图2中:NPE_S、NPE_T、SDA_S、SDA_T分别为NPE降维后源域数据、目标域数据、半监督域适应变换后的源域数据、目标域数据。由图2可知,半监督域适应方法可以有效减小特征变换后源域和目标域数据中心差异。

图2 数据分布图
2.2.2 负荷参数预测
为验证本文方法的有效性,设计两组对比试验。第一组在工况变化后,利用少量目标域数据建模得到负荷参数预测值。第二组借助源域数据建模得到负荷参数预测值。为了评价各种模型的预测能力,本文使用均方根误差(Root Mean Square Error,RMSE)作为度量准则。
在第一组实验中,随机选取目标域数据中的20个样本作为少量带标签样本。利用偏最小二乘回归(Partial Least Squares Regression,PLSR)建立软测量回归模型得到负荷参数预测值。参数预测情况如图3及表4所示。图3中传统方法指利用工况3中随机抽取的20个样本建立偏最小二乘回归模型得到负荷参数预测值。表4中,“少量3”表示利用传统方法建模得到负荷参数预测的RMSE。由图3可知,根据少量待测工况样本建立的模型无法预测负荷参数值。因此有必要借助历史工况数据建模。
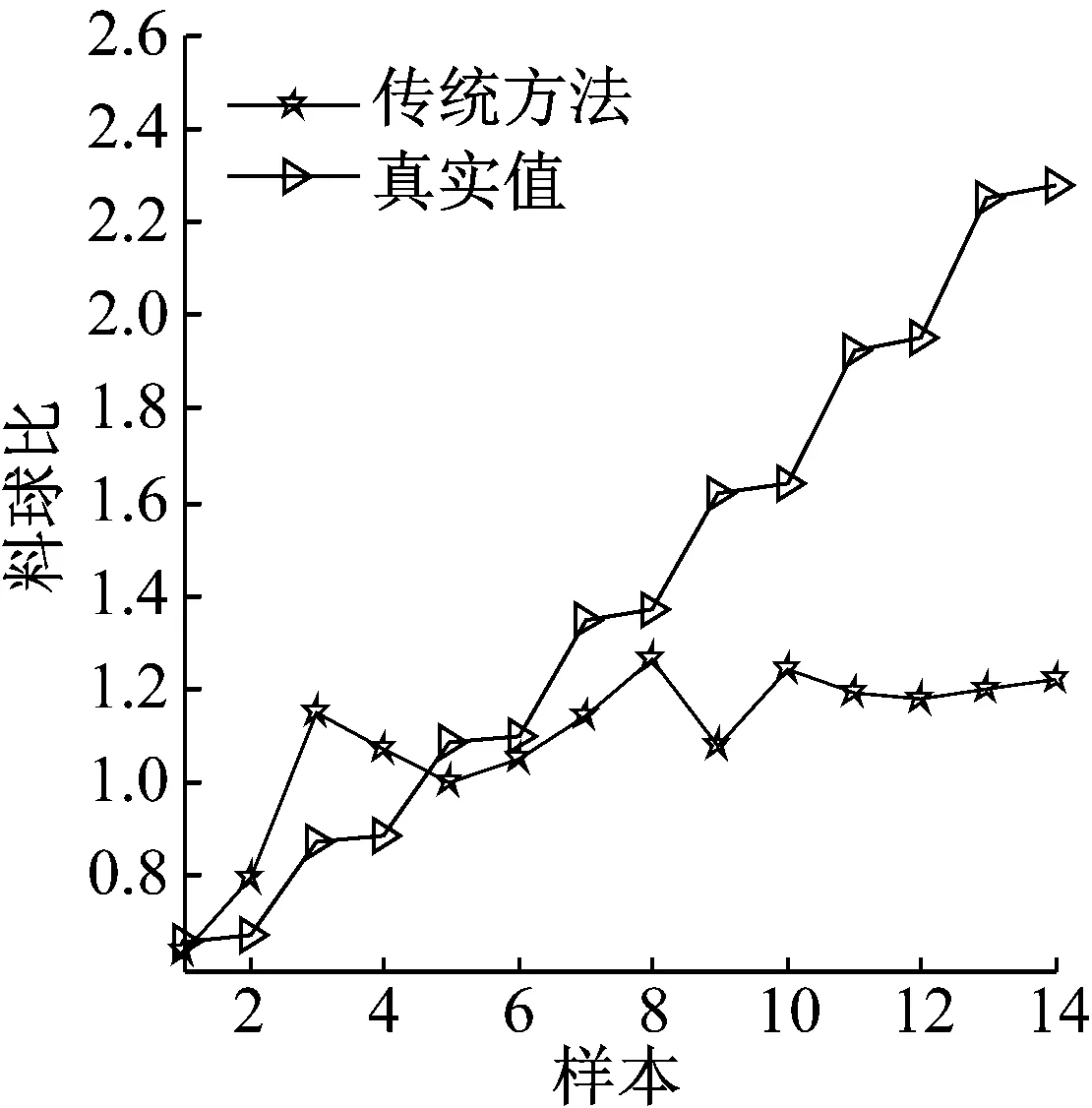
图3 少量样本建模负荷参数预测结果
Fig.3 Load parameter prediction results of a small amount samples
第二组实验借助源域数据建模。为模拟实际工业过程中目标域存在少量带标签样本的现象,随机选取目标域数据中的20个样本作为少量带标签样本。半监督域适应方法根据“2.2.1”节中投影到公共子空间的源域数据和目标域少量带标签数据,建立PLSR模型从而得到目标域中无标签样本的负荷参数预测结果。近年来,为使系统模型能够及时适应工况的变化,即时学习和集成学习的建模策略被广泛采用。因此,本文采用传统方法、即时学习、集成学习及“1.1”节中的流形正则化域适应方法作为对比实验。传统方法利用PLSR建立软测量回归模型;即时学习通过在历史数据库中寻找与目标域数据相似的样本,然后根据相似样本建立PLSR回归模型;集成学习使用各个学习器间不存在依赖关系的随机森林建立模型。对比结果如图4及表4所示。



图4 工况2→工况3负荷参数预测结果
Fig.4 Load parameters prediction results of working condition 2 transfer to working condition 3
表4 单源域负荷参数预测均方根误差对比
Tab.4 Comparison of RMSE in single source domain load parameter prediction
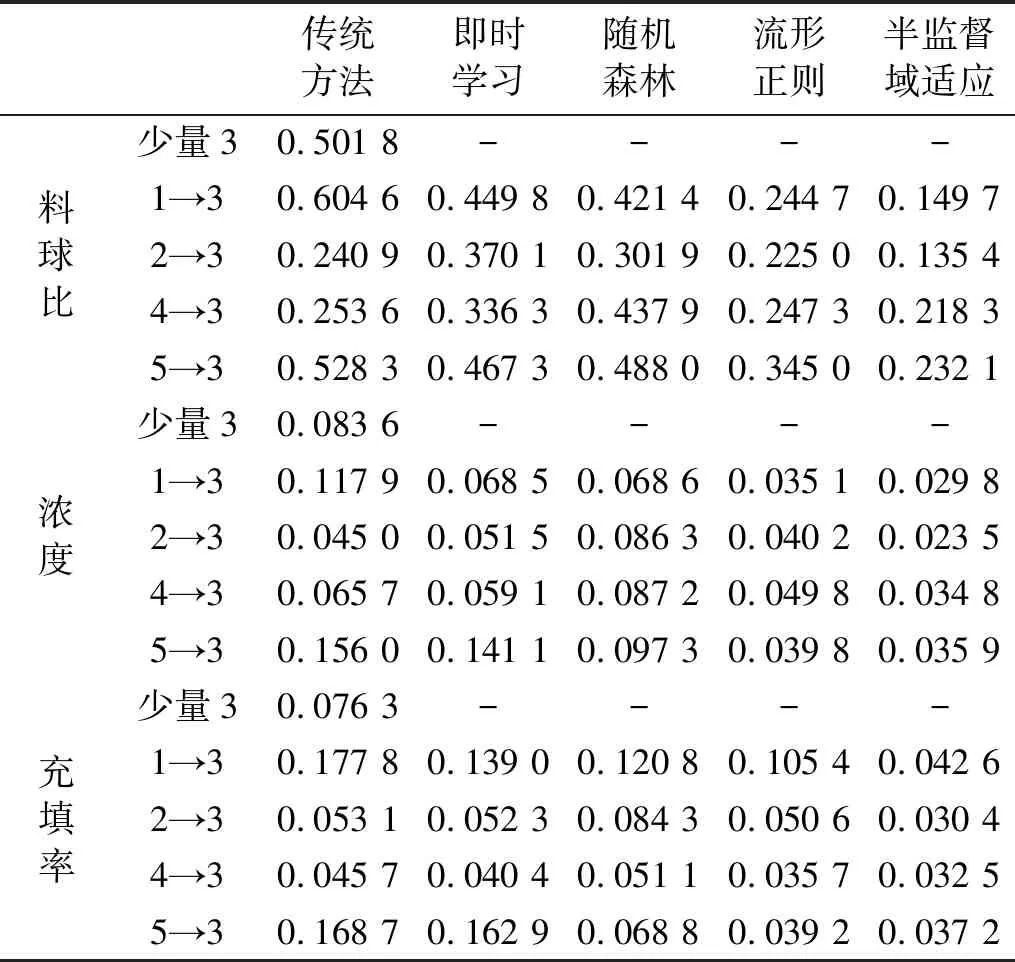
传统方法即时学习随机森林流形正则半监督域适应料球比少量30.501 8----1→30.604 60.449 80.421 40.244 70.149 72→30.240 90.370 10.301 90.225 00.135 44→30.253 60.336 30.437 90.247 30.218 35→30.528 30.467 30.488 00.345 00.232 1浓度少量30.083 6----1→30.117 90.068 50.068 60.035 10.029 82→30.045 00.051 50.086 30.040 20.023 54→30.065 70.059 10.087 20.049 80.034 85→30.156 00.141 10.097 30.039 80.035 9充填率少量30.076 3----1→30.177 80.139 00.120 80.105 40.042 62→30.053 10.052 30.084 30.050 60.030 44→30.045 70.040 40.051 10.035 70.032 55→30.168 70.162 90.068 80.039 20.037 2
表4中“1→3”为工况1的数据作为源域数据工况3的数据作为目标域数据。由图4及表4可知:①当数据分布差异大时,传统方法、即时学习、集成学习结果相对较差。其原因为即时学习存在期望风险,集成学习存在结构风险,传统方法建立在数据同分布的前提下;②在料球比、浓度、充填率参数预测中,流形正则化域适应、半监督域适应都能以一定的精度实现负荷参数的预测,但是半监督域适应精度相对较高,其原因为考虑了标签对投影矩阵的影响。
2.3 基于半监督多源域适应的磨机建模方法
在工业过程中,不同工况信息存在互补的特点,因此,可将多个源域的数据作为历史数据建模得到负荷参数预测值。采用流形正则化多源域适应方法作为对比实验。流形正则化多源域适应方法通过加权策略融合多个源域的数据。半监督多源域适应和流形正则化多源域适应方法建模后得到负荷参数预测均方根误差结果,如表5所示。表中“1&2→3”为工况1、工况2的数据作为源域数据,工况3数据作为目标域数据。为直观了解负荷参数预测情况,则以工况1和工况2为源域数据、工况3数据为目标数据为例,得到目标域料球比预测曲线,如图5所示。由表5可知,半监督多源域适应方法比流形正则化多源域适应方法的预测均方根误差小,精度高。对比表4及表5中工况3的预测均方根误差得出,当充分利用多源域数据作为历史数据时,半监督多源域适应方法可以挖掘出更多与负荷参数相关的特征信息,从而得到较高预测精度。
表5 多源域负荷参数预测均方根误差对比
Tab.5 Comparison of RMSE in multi source domain load parameter prediction

1&2→34&5→3料球比流形正则化多源域适应0.224 10.255 4半监督多源域适应0.128 40.189 8浓度流形正则化多源域适应0.027 30.035 0半监督多源域适应0.022 40.021 4充填率流形正则化多源域适应0.043 50.032 2半监督多源域适应0.025 60.027 2

图5 工况1 &工况2→工况3料球比预测结果
Fig.5 The MBVR prediction results of working condition 1 and working condition 2 transfer to working condition 3
3 结 论
本文针对球磨机工况改变后,历史数据与待测数据分布差异导致的模型失配问题以及待测工况样本少的问题,研究了半监督域适应方法及半监督多源域适应方法,得出如下结论:
(1) 域适应方法能够有效改善数据概率分布失配对软测量建模的影响,半监督域适应方法将标签信息融入特征映射的过程能提高模型预测能力。
(2) 半监督多源域适应方法利用多源域信息互补的特点,更加有效地迁移不同源域知识到目标领域,提高目标领域的预测能力。
(3) 利用多工况下小型试验球磨机数据进行实验,结果表明:本文方法在一定程度上能有效跟踪实际值的变化。这对选矿过程全流程优化运行和控制具有十分重要的意义。
