华语流行音乐的歌词情绪分析
——基于新媒体音乐终端的大数据分析方法
2017-02-10黄美帆
■薛 亮 黄美帆
(中国社会科学院大学,北京,102488;南加州大学,美国洛杉矶,CA 90089-0851)
无论流行音乐产业以何种方式获利,最根本的问题依然是如何真正理解受众,抓住受众的喜好。过去流行音乐业者主要透过唱片销售量了解歌曲畅销程度,但近年来数字音乐兴起,受众并非只能透过购买唱片聆听音乐,在线流媒体服务与社交媒体均是可以轻易接触到流行音乐的方式。在线流媒体播放平台(如网易云音乐、QQ音乐、KKBOX、Spotify、Apple Music)兴起,使得收听不同种类的流行音乐成本大幅下降,受众更能够轻易选择喜爱的曲目;同时,判断流行音乐是否为畅销曲目,不再能仅凭唱片销售的数字,因此,音乐产业必须开始重视并且分析应用这些数字流媒体平台及社群间不断产生的大量数据。
流行音乐的相关研究可大致分为流行音乐内容(文本)分析、流行音乐制作分析、流行音乐受众分析等等。其中,音乐内容可分为两个部分,分别是:以音乐特征为主体的歌曲结构分析,如音乐本身的旋律、节奏、音色、和弦等等;以流行音乐演唱的歌词内文作为主体的分析。本研究则是属于以流行音乐演唱的歌词文本作为主体的音乐内容文本分析。
一、研究目的与研究对象
本研究期望基于大数据的分析,利用文字挖掘以及情绪分析的技术,了解受众对流行音乐之喜好,协助流行音乐制作出版相关产业,提供制作出版与营销之参考。研究将针对华语流行音乐,以歌词的面向了解听众对音乐情感之喜好,提供流行音乐制作出版之音乐类型建议,帮助流行音乐产业在进行音乐出版销售时能够更精准地运作。
本研究欲了解2011年至2016年华语热门流行歌曲歌词情感趋势,因此,选取了“MusicRadio中国TOP排行榜”、“QQ音乐内地/港台巅峰榜”和“网易云音乐热歌榜”等三个较有代表性的与新媒体平台相关的榜单作为研究对象的来源,经交叉比对后,选出同一时间内三个榜的共同作品作为文本分析对象。需要说明的是,由于“网易云音乐”这款终端是2013年才发布的,因此2013年之前的榜单主要从另外两个排行榜中选取。
二、技术背景
大数据(Big Data)是指以现有科技的水平难以处理的大量数据,数据的大小并没有被定义,而是依照当时的科技能力而定;大数据的数据类型可分为结构化数据(即关系数据库能够容易处理之数据类型,如数值、字符字串、布尔值等)与非结构化数据(即关系数据库难以直接处理之数据形态,如网页、文件、多媒体等)。大数据具有“4V”的特征:
Volume(大体量)——指数据的数量庞大,而大数据的数据量通常是以现有的科技能力难以处理的数量,会随着科技的演进不断地增加;
Velocity(高速度)——指数据产生与更新的速度是极快的,例如云音乐歌单不断快速产生的用户的活动记录(收藏、评论)等数据,它们每分每秒都在快速地增加与更新;
Variety(多样性)——指数据的内容与结构有丰富的多样性,除了结构化的数据,也存在着非结构化的图像、声音、影片及社交网站上的推广性质文章内容等;
Veracity(真实性)——指数据本身可靠、可信,由于所有数据的存储和采集,均由系统后台无差别记录、保存而成,因此能够客观、真实地反应用户状态、需求、行为以及判断。
由于大数据有以上特性,配合数据分析的技术,能够从海量的数据中分析得出有效信息,进而转换成商业信息,协助企业科学地找出现象背后的本质、了解目前的状况,进而分析未来的趋势。大数据的应用范围很广泛,对于音乐产业而言更是意义重大,例如美国流媒体音乐服务商潘多拉(Pandora)靠用户数据预测格莱美奖(Grammy Awards),靠用户数据精准投放广告,并为了让优秀的乐队和歌手能被大众听到,为音乐人提供受众数据分析工具AMP(Artist Marketing Platform),以帮助音乐人了解关于他们的受众的数据(如收听习惯等),以方便创作。
三、分析方法
本研究所用的分析方法主要涉及文字数据挖掘与情绪分析两大方面。
文字数据挖掘文字数据挖掘(Text Mining)是针对文字数据进行分析的技术,透过各种不同的量化技巧,试图找出隐含且有助于决策之信息或知识。相较于传统的数据挖掘主要是针对结构化的数据进行挖掘,其主要针对半结构化(semi-structured)或非结构(unstructured)格式储存之文字数据进行处理。文字数据挖掘是一种编辑、组织及分析大量文件的过程,以为特定的决策者提供特定的信息,以及发现隐藏的特征及其关联。文字不像数值具有单位统一性质,其使用以及表达方式也是因人而异,因此,文字挖掘的技术最重要的就是将非结构化或半结构化文字或文件进行量化,再利用其属性寻找出各文件之间的相关性或关键词语——而如何将其进行结构性量化,是文件挖掘最首要的目标。
文字数据不像数字或者运算公式是全球通用的,文字挖掘中文字数据的分析处理方法会因地区文化及语言使用习惯不同而有所异。例如:英文的“Together”这个词,对计算机来说可以清楚地理解是一个单一的词“在一起”,而不会认为是一句话“得到她”(to get her),这是因为英文语言由空格判断字词的位置;但是对于中文来说,并没有可以进行字词判断的标准,如“你好不好”这句话可以断词为“你|好|不好”、“你|好不好”、“你好不|好”,而它们所产生的意思完全不同。
文字挖掘技术经常应用于处理分类议题,透过分类相关算法与技术,将大量文件分门别类,以满足检索与分析的需求。文字挖掘分类技术可分成以下两种方向,分别为“群集”(clustering)与“分类”(categorization)——群集法是将集合切割成不同的未知主题或特性的小群集,并在切割后找出属于该群集的主题和特性;分类法则是依照已知的主题或特性进行分类,必须事先定义好集合。而由于分类法中类别集合为事先定义,因此可透过改善范本训练数据的精确程度及特征值,提升分类结果之准确率。
情绪分析情绪分析(Sentiment Analysis,或可称“情感分析”)是指通过一些主题或文件的整体脉络判断或预测文本的情绪或者意见态度。情绪分析常用的分析方法是通过找出文字内容和经由人工标记的情绪类别,寻找文字跟情绪之间的关联性。因此,当我们所搜集的关联样本足够多,使得寻找出来文字与情绪之间的关联性具有显著相关性时,即可预测出未知情绪类别的文字内容可能带有的情绪。
情绪分析可区分为三种层级来讨论,分别为字词、语句、文章。大多数的相关研究在文章层级,根据文章中的图释预测作者表达的情感,并将图释作情绪分类,如喜、怒、哀、乐。最后发现,若将情绪区分为正反两面来做,SVM(Support Vector Machine,支持向量机)上的情绪分类效率是最高的。在情绪分类方面,Thayer二维情绪分类模型,将情绪分为四种,分别为满足(contentment)、忧郁(depression)、热情(exuberance)、焦虑/烦躁(anxious/frantic)。
就音乐的研究而言,以往的研究多借由音乐特征(旋律、节奏等)来区分能量(Energy)的程度,而压力(Stress)的程度则多以歌词内容来区分。本研究的研究目标为歌词,以压力程度为情绪的分类目标,将热门歌曲的歌词分为“快乐”(正向)以及“焦虑”(负向)两类情绪;另外,本研究并未搜集音乐特征数据,因此情绪的能量(Energy)程度将不在探讨范围。在词汇的情感倾向层面,本研究将词语分为正面情感词(如“开心”、“幸福”、“温暖”等)和负面情感词(如“堕落”、“放手”、“绝望”等)。另外特别标明了“程度词”,即形容情感词程度的词汇,如“好幸福”中的“好”这类程度副词,并且为其做了加权处理——“极其”、“最”的加权值为2,“超”、“非常”为 1.5,“很”为 1.25,“较”为1.2,“稍”为0.8,“缺”、“欠”等这类为0.5;而否定词,例如“不”、“没”、“无”、“非”、“莫”等标示为相反情感,如“不开心”则被标示为负面情感词。
四、分析路径
为利用SVM分类算法进行歌词情感分类,歌词数据须先经过断词处理,并比对情感词库中词的情感,最后选取出歌词情感的特征值。按以下步骤操作:
(一)中文断词
词为中文文章意义的最小单位,相较于英文文章中对于词的处理,中文无法利用词与词之间的空格分辨出哪几个字可组合成词,因此若要对中文的文章运用词进行分析,需要先经过断词处理,将文章中的每个词分隔出来才能运用。本研究采用开源的中文断词系统Jieba,进行歌词的断词。例如:
如果|感情|会|挣扎,没有|说的|儒雅;把|挽回的手|放下,镜子里的|人|说|假话,违心的|样子|你决定了吗?……我们的|距离|到这|刚刚好,不够|我们|拥抱|就|挽回不了,用力|爱过的|人|不该计较,是否|要逼人|弃了|甲,亮出|一条|伤疤,不堪的|根源|在哪,可是|感情|会挣扎,没有|别的办法|……再|不争|也|不吵,不必|再|煎熬……天空|有些|暗了|暗的|刚刚好,我难过的|样子|就|没人看到,你|别|太在意|我身上的|记号。(选自薛之谦《刚刚好》)
(二)情感词库及比对
本研究整合HowNet(知网)和“搜狗”中文情感词库作为比对范本。综合词库可以表示概念之间以及其所带有的属性之间的关系。对于中文词汇,“词”是语句中的最基本概念,最小语义单位。由于中文中“词”的含义非常复杂,往往在不同的情境中会表达不同的意义,因此在综合对比词库中,将“词”分为若干词义的集合,包含2 812个正面情绪词(如“开心”、“幸福”、“温暖”等)与4 276个负面情绪词(如“堕落”、“放手”、“绝望”等)。为分辨词汇的情感,本研究整合情感词汇、程度词汇以及否定词汇,比对歌词,寻找歌词中的情感特征值。如前文所述,程度词指的是形容情感词程度之词汇,如“好幸福”中的“好”。要找出歌词中带有情感色彩的词汇,须先将断词处理后的词汇与情感词库中之情感词汇进行比对,然后将比对结果标记于歌词数据中。
例如对《刚刚好》的歌词,系统会做出如下划分:
正面情感——好、爱过、在意、儒雅……
程度词——刚刚(好)、太(在意)、没(+儒雅)、不够、有些……
负面情感——挣扎、没+儒雅、假话、违心、挽回不了、伤疤、不堪、煎熬、暗、难过……
可以初步得出一个结论,整首歌词情绪非常负面,本就不多的正面情感词汇前几乎都加了否定词,或者程度词,而在本就很多的负面情感词汇前还添加了程度词,由此越显得负面。
(三)SVM模型
SVM(Support Vector Machine)是在分类问题上经常使用的数学模型,其主要的概念是将欲分类用的特征值建构成一个多维度的超平面来分类数据,利用训练用的范例数据向量分成相应的类别,并寻找这个平面的边界最大化。例如下页图1所示的原理:欲将图中的黑点与白点利用SVM分类,SVM会寻找黑点所在的平面与白点所在的平面之间的界线——如图中的深色线,两条浅色线则用来示意两平面上的点与黑线之间的距离w,而SVM的目标为寻找到拥有最大距离的黑线Max(w)。本研究将使用台湾大学林智仁教授所开发的SVM工具套件 LIBSVM(Chang et al.,2011),利用R语言进行训练分类。
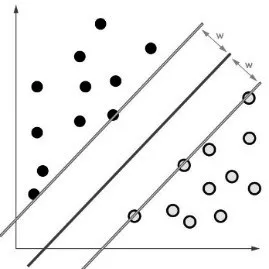
图1 SVM分类原理示意图
利用SVM分类算法进行歌词自动分类,要先列出可能成为分类特征之特征值(见表格)。例如,将每首歌的歌词先经过Jieba断词系统将歌词分为个别词汇,接着将每个词汇对照情感词库,找出每个词汇的属性,计算出正面情感与负面情感数量为特征值。

图2 SVM训练模型运算参数格式
(四)比对分析
当利用SVM分类算法而建立的分类模型将所有歌曲歌词情感分类完毕后,由统计出来的具有正负向歌词的歌曲情况,可大略知道受众对华语流行音乐歌词情感喜好的画像,例如大部分受众喜好有正面情感歌词的歌曲还是有负面情感歌词的歌曲,同一年度中具有何种情感倾向的歌曲数量较多等等。当然,这里要说明的是,歌词体现出来的负面情感,对于听众而言,并不一定都是负面影响,因为伤感的、消极的负面情感也是听众排遣自己伤感情绪的一种重要方式,因此,负面情感也有积极作用。
五、结论:歌词情感公式及五年来呈现的规律
本研究最后利用数据可视化软件Tableau将排行榜数据及依照时间序列分析后的结果进行可视化呈现,以探讨隐藏于其中之信息,如每年上榜的歌曲之歌词情感是否会依照季节而变化等等。本研究将观察统计时间切割为每月一次,查看每月中具有各类情感歌词之歌曲的数量变化;将歌曲数量化为可公平比较的情感数值,让每月都从相同的基准点出发,以利于更精确地观察热门歌词情感的变化。情感分数计算公式见下页,其中Score(m)为某月的情感分数,m(d)为该月份总天数,d则为该月份的某个日期,SPd为该日期具有正面情感歌词的歌曲总数,SNd为该日期具有负面情感歌词歌曲的总数,最后会得到一个1与-1之间的分数Score(m)——若Score(m)>0,代表当月的歌词情感以正面的为主,Score(m)<0则表示当月的歌词情感以负面的为主。
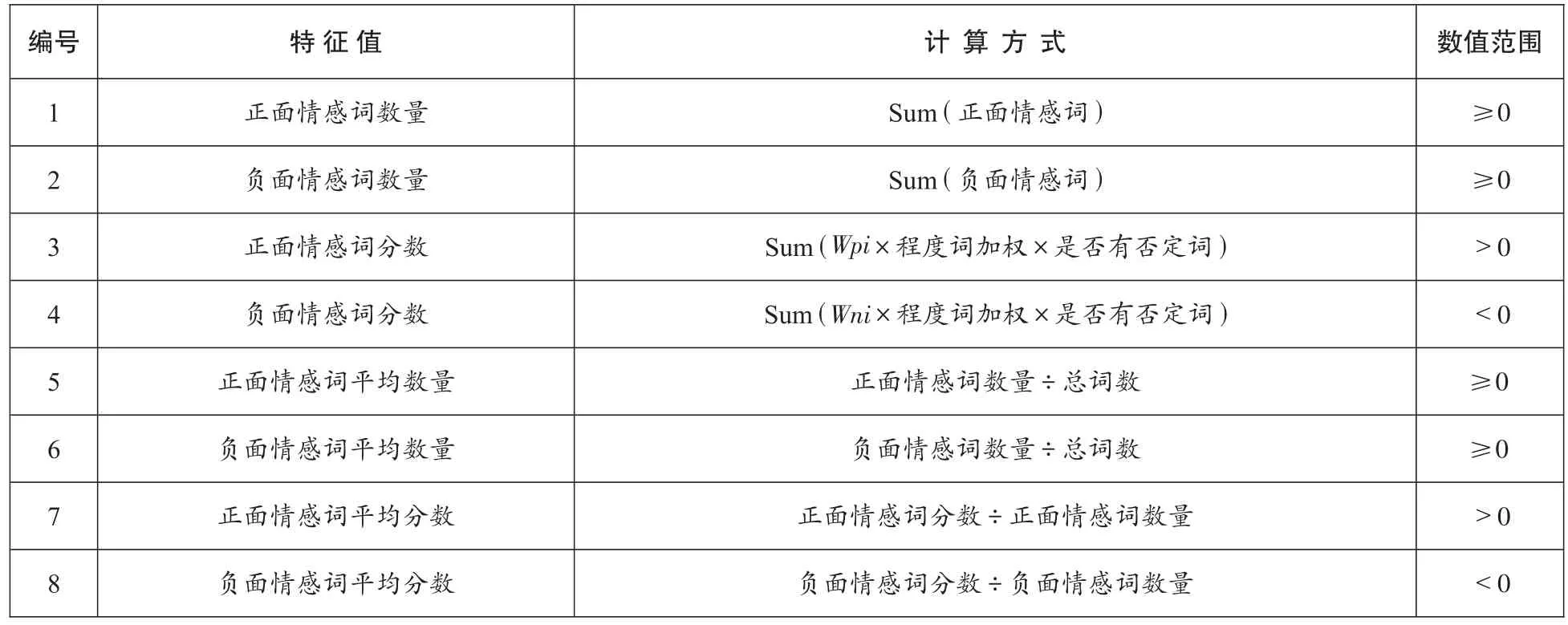
表格 可能成为歌词分类特征的各个特征值

图3 2011至2016年的每月情感分数变化

本研究将每月的歌词情感数量标准化后得到每月情感分数,并按时间序列画出2011年至2016年每月情感分数变化的折线图(如图3)。由图可见,上榜歌曲的情感分数皆为正数,可认为受众对具有“正面情绪”歌词之歌曲有较高的偏好。另外,这五年间,歌曲的情感分数从原本的0.5分缓慢地减少至2016年的0.1分,由此可发现,榜单虽以歌词具有正面情感的歌曲为主,但却有逐渐转向具负面情感的趋势,到2016年已经表现出正面情感歌曲与负面情感歌曲接近持平的状态。
此外,从图中可以发现,每年12月至来年3月之间,每月情感分数会出现一个高峰,7月和8月则呈现低点,可以观察到歌曲情感偏向也有依季节(暑期、“毕业季”、“分手季”等)变化的趋势。另外,从折线起伏变化中还能发现一些规律,例如当一部现象级的电影或者电视剧热播之际,其主打歌或主题曲会带来局部情感趋势的波动,例如《平凡之路》、《匆匆那年》①《平凡之路》为电影《后会无期》插曲,该片上映时间为2014年7月;《匆匆那年》为同名电影主题曲,该片于2014年12月上映。——但由于是单首作品带来的波动,不会对整体长期趋势有实质性影响。
大数据分析方法被越来越多地用于音乐等艺术的分析和使用上,随着各大音乐流媒体终端和平台逐渐成熟,该方法的影响力也将逐渐增大。本研究暂未将其他平台的排行榜数据及用户反馈采纳入样本,且只探讨华语流行音乐,并未涉及其他语言或风格的音乐如欧美、日韩歌曲甚至独立制作之歌曲等。另外,本研究只针对音乐歌词进行分析,探讨其情感趋势,其他音乐特征并未涉及。
今后的研究会着重从以下几方面改善:首先,修正情感特征值,增加训练数据集,提升分类准确度;第二,加入其他在线音乐流媒体终端的排行榜数据,增加热门曲目判断的依据;第三,加入对其他音乐类型的考察,增加了解受众喜好的途径,寻找各音乐类型之间的关联;第四,结合歌曲的音乐特征,如节奏、旋律等,增加情感类别并提升分类的准确度;第五,结合不同的事件或新闻,探讨华语流行音乐受众对歌词情感的喜好变化的原因。
[1]夏云庆、杨莹、张鹏洲、刘宇飞《基于情感向量空间模型的歌词情感分析》,载《中文信息学报》2010年第1期。
[2]V.N.Vapnik,The Nature of Statistical Learning Theory,New York:Springer,2000.
[3]“知网”信息库。http://www.keenage.com/html/c_index.html
