基于深度强化学习算法的纯电动矿用汽车再生制动策略研究
2024-02-22杨威威罗登昊张文明
杨威威,罗登昊,张文明
北京科技大学机械工程学院车辆工程系,北京 100083
在内燃机车辆发明之后,它在运输领域得到了广泛的应用,促进了各个车辆产业的扩大,但是这导致了化石燃料需求的大量增加[1].传统燃油车辆的缺陷在于消耗化石能源并造成污染以及碳排放[1-3].随着电池与电机技术的发展,纯电动车渐渐成为了交通运输的一种选择.针对纯电动车与内燃机的碳足迹研究指出,电气化能够使车辆的碳足迹减少22.6%.这一比例随着车辆的使用寿命延长而延长[4].对公交车的碳足迹研究发现全面电气化能够减少37%~52%的碳排放[5].与内燃机相比电动车的能源使用效率达到了59%,有着更高的能量利用率[1].因此纯电动车辆在未来将会是运输业的主要设备.
Mohammadi 等[1]对用于电动车的各类型电池进行了分析,认为锂电池最具经济性.但针对纯电动车的研究仍旧能够发现很多不足.Das 等[6]认为锂电池是现有的比能量最高的电池,为100~180 W·h·kg-1,但是与燃油相比仍旧有较大的差距.同时他们发现电池容量与行驶里程为非线性关系.电池容量的增加可以增加车辆的续航里程,但是随着电池质量的增加,车辆的能耗也会相应增加,从而无法进一步提高航程.Guo 等[7]发现电动车电池的不断更换使电动车的成本变高,也认为纯电动车需要在同航程下有更小的电池容量与更长的电池寿命.而为了增大航程导致的电池质量增加也使电动车成本难以与燃油车竞争.Hoekstra[8]认为,现在的电机技术已经较为成熟,而限制电动车的因素变为了电池的寿命.因此可以看出纯电动车辆由于电池的容量导致航程受限.同时,由于电池的寿命问题使成本上升.
有一些研究希望在硬件方面与使用方面进行尽可能的优化.Diahovchenko 等[9]使用了安装在车顶的光伏板来延长行驶里程,在实验中能够提高1.16%~6.32%的行驶里程,但是这一方法只能用于小型家用车,并且行驶里程取决于气温与光照条件;Eider 等[10]则针对电池寿命建立了一套规则体系,利用模糊逻辑作为控制系统,对用户提出使用建议来减缓用户的不当使用造成的电池寿命损耗.
由于现在电池技术较难产生突破性发展,因此为了提高电池寿命与提升航程,对车辆的再生制动管理策略进行优化是更具有可行性的方法.再生制动是电动车辆所能使用的一种特殊的制动方式,能够将车辆的制动能量利用电机进行回收.通过对制动能量的回收,与传统车辆相比在一定工况下能够节约31%的能量[11].因此对再生制动管理策略的优化,能够提高电动车辆在相同电池容量下的航程.在对未来电动车制动能量回收的展望中,认为控制策略上的研究将会偏向于多性能综合控制以及控制策略的迭代优化[12].
对再生制动的控制算法在各类载具上已经有较多的研究,主要使用的有基于规则、模型预测控制(MPC)、动态规划(DP)以及强化学习(RL)的控制算法对再生制动进行控制.这些算法都能在不同程度上同时考虑提高航程与电池寿命.
在基于遗传规则等的算法中,针对纯电动车,Xu 等[13]使用了多岛遗传算法对能量消耗和电池寿命进行了全局优化,以此来提高电池寿命与航程.
在理论上较为优秀的算法为Dynamic programming (DP) 算法,能够提供理论上最好的控制策略,但是DP 算法在实际使用上对连续动作具有较大的计算负荷,随着动作变得复杂计算时间也会相应地上升.因此在Zhou 等[14]的研究中针对电动车辆的动态规划进行了优化,仿真结果表明根据燃料系统是否关闭,计算时间分别减少了22.36%和94.3%.
在现在的研究中,RL 算法由于其较强的鲁棒性与收敛性也得到了充分的应用,在Matsuo 等[15]的研究中认为现在的人工智能代理能够利用强化学习算法为给定的任务提取适当的特征;Han 等[16]在一个针对混动车的研究中,基于强化学习的控制策略使用了马尔可夫链(MC)模型,并利用强化学习对模型进行更新,提高了策略的适应性,在仿真中与Q 学习和基于规则的策略相比更具有优势.在李卫等[17]的研究中,利用深度强化学习(DRL)算法针对燃料电池混合动力汽车制定能量管理策略,以燃油经济性与燃料电池寿命为目标进行多目标优化,并验证了算法的工况适应性.
最早出现的强化学习算法为Q 学习算法,在引入了神经网络之后能够用于连续环境,被称为Deep Q learning (DQL),在王博文[18]的研究中利用深度Q 网络Deep Q-Network (DQN)网络制定了针对纯电动汽车的再生制动控制策略,验证了DQN网络用于车辆再生制动的可行性.在Tang 等[19]的研究中针对燃料电池混动车设计了基于DQN 的能量管理策略,以DP 算法为基准能够达到其88.73%的经济性,且计算效率提高了70%;在Huo 等[20]的研究中则将基于DQL 算法与Deep deterministic policy gradient (DDPG) 算法的控制策略进行比较,认为两者在不同的工况下各有优势,并且都能够在提高经济性的同时维护燃料电池寿命.杨丽丽[21]的研究中将DQN 算法与DP 算法等控制策略进行对比,认为DQN 算法能够达到接近DP 全局优化的控制效果.这一方法产生的问题为会对价值函数进行过度估计,导致输出值难以达到最优解.
也有研究在DQL 基础上对算法进行优化,Xu等[22]针对使用超级电容的纯电动车辆,设计了双层Q 学习策略(DDQL),与DQL 相比减少了12%的电池容量损失,并提升了一定的续航里程;针对双电机驱动的混动履带车辆,Han 等[23]提出了基于DDQL 的能量管理策略,避免了对价值函数的过度估计,与DQL 算法相比经济性提高了7.1%,且达到了DP 算法的93.2%.使用Q 学习算法的共同问题为收敛效率较低,并且容易陷入局部最优之中.
为了提高强化学习控制策略对各个工况的鲁棒性与运行效率,一些研究中使用了Twin delayed deep deterministic (TD3)算法.在针对城市混合动力客车的研究中,Huang 等[24]利用TD3 算法的控制策略进行仿真,与DDPG 算法相比效率提高了10.98%,且成本降低了9.58%;与DDQL 相比成本则降低了17.29%.Deng 等[25]在对使用燃料电池的混动铁路车辆的研究中,基于TD3 的能量管理策略与另一种在线策略相比,电池容量退化的速度降低了28%.TD3 算法使用在动作函数中加入噪音的方法来避免算法收敛到局部最优的位置.
在TD3 之后研究者提出了Soft actor-critic (SAC)算法,利用熵权重对动作策略进行更新,比起TD3 算法,熵权重对动作的选择影响是可以根据环境的变化进行调整的,使收敛的效率得到了提高.Gaiselmann 等[26]在针对自动换挡控制器的研究中,利用近端策略优化(PPO)算法与SAC 算法对控制策略进行优化,经过仿真与实车实验后,证明了强化学习相比经典的控制方法更具有优势,并验证了强化学习控制器用于现实的可能性;Zhou等[27]针对一个生产执行系统(MES),使用了优化的SAC 算法进行控制,与MPC 算法相比能够降低61.57%的能量成本,并且具有较强的鲁棒性与收敛性;Fang 等[28]针对插电式混合动力汽车,利用基于SAC 算法的电源管理策略进行训练以减少能源成本与电池寿命,在测试时得到了优于规则控制的结果,并且这一控制策略能够通过在线更新进行进一步优化;在对混动车的控制策略测试中,Wang 等[29]比较了13 种深度强化学习的算法,发现PPO 算法具有最快的训练速度,与其他算法相比能够提升27.9%~57.6%,而SAC 算法具有最高的奖励,能够提高2.48%~15.7%,在离散动作空间下,SAC 的油耗比规则控制低8.26%;Sun 等[30]在对混动车的能量管理策略制定中,使用了基于SAC 的控制策略,经过仿真验证了控制策略的可行性,并且与DDPG 相比具有更高的鲁棒性与适应性;Xiao 等[31]利用强化学习算法,对增程式电动车的能量管理策略进行制定,并将基于SAC 算法的策略与DDPG 策略进行比较,在仿真结果中性能优于DDPG,且训练效率提高了30%.
综上所述,可以看出基于强化学习的控制策略算法能够在各类型的车辆中得到应用,并且能够适应不同的工况环境,在训练完成之后能够得到接近DP 算法的性能.在各类强化学习算法中,能够避免出现局部最优并且能够有较好收敛效率的算法为SAC 算法.而现在大部分的再生制动控制策略集中于汽车等小型车辆中,针对负载和坡道变化的纯电动矿用自卸车的再生制动控制策略的研究较少,且利用SAC 算法制定的再生制动控制策略的研究也较少,因此在本文中考虑对载重45 t 纯电动矿用汽车(TR50E)使用基于SAC 算法的控制策略,并与基于规则、基于DP 算法和基于DDPG 算法的控制策略进行比较,通过仿真模拟得到各个控制策略的性能差异.
1 建立车辆动力学模型
本论文对TR50E 矿用自卸车进行控制策略的制定,需要对车辆进行仿真分析,因此对车辆进行如下数学模型的建立.
车辆结构如图1 所示.
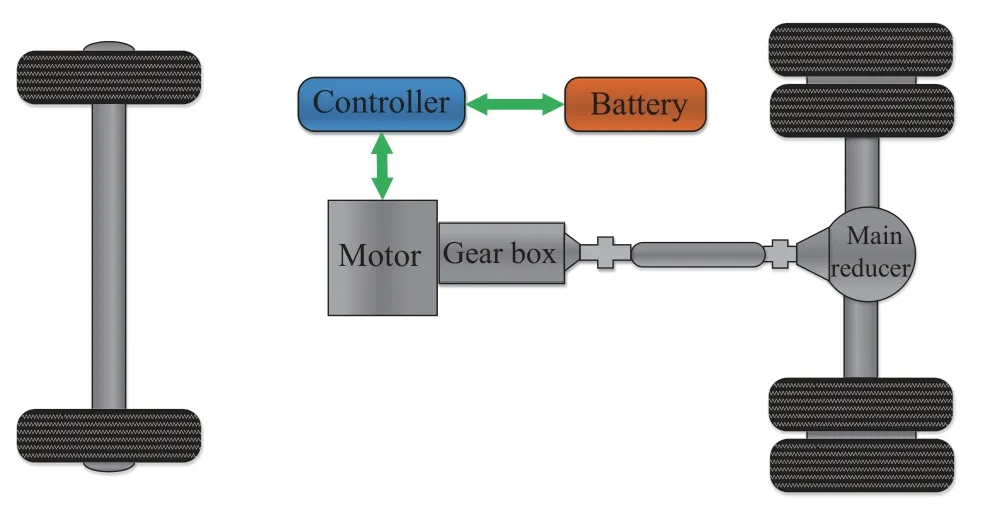
图1 车辆结构示意图Fig.1 Schematic of vehicle structure
由车辆结构可以看出,车辆的动力源为电池,利用控制器控制电机的运行,利用变速箱改变电机的运行工况.前轮与后轮能够使用机械制动,同时车辆为后轴驱动,因此当使用再生制动时只能够从后轴输出制动力矩.由于再生制动的特殊性,在紧急情况下应当减小再生制动力的输入并加大机械制动力在总制动力中的比例.因此,在使用再生制动之前需要对机械制动与再生制动力进行规划.
TR50E 矿用自卸车的车辆参数如表1 所示.
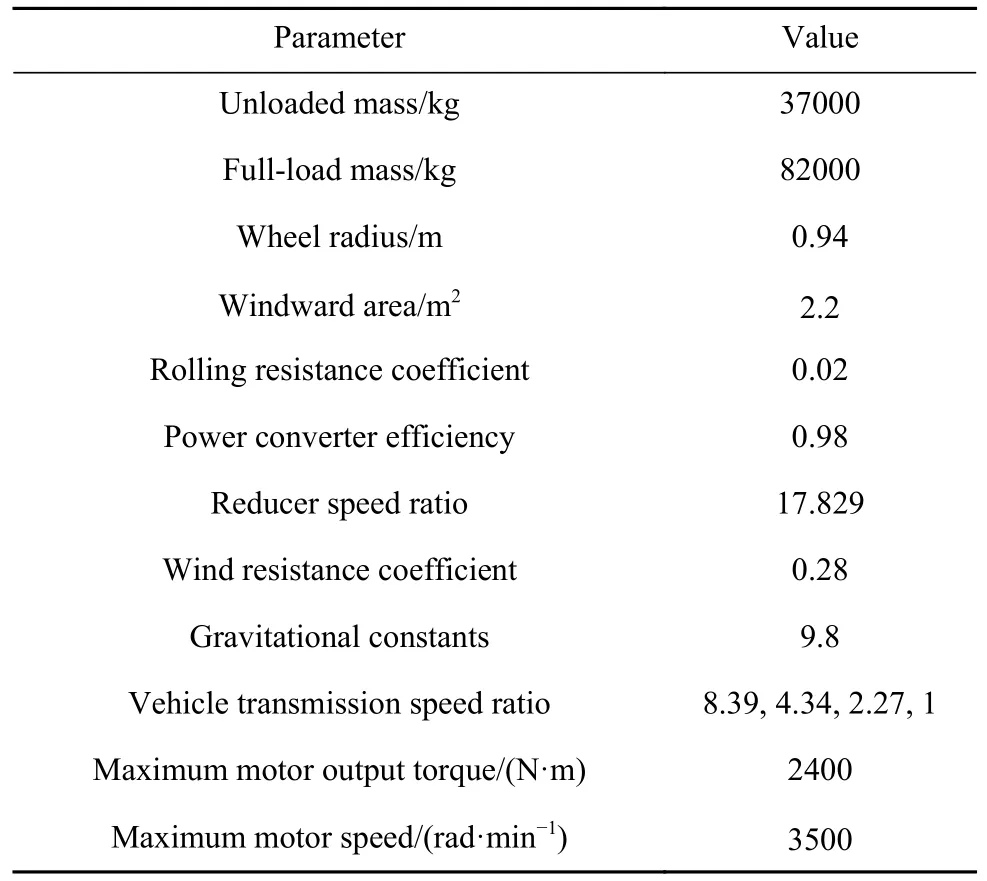
表1 TR50E 车辆参数Table 1 TR50E vehicle parameters
1.1 车辆动力学分析
对车辆的行驶过程进行动力学分析,TR50E矿用自卸车的行驶工况示意图如图2 所示.
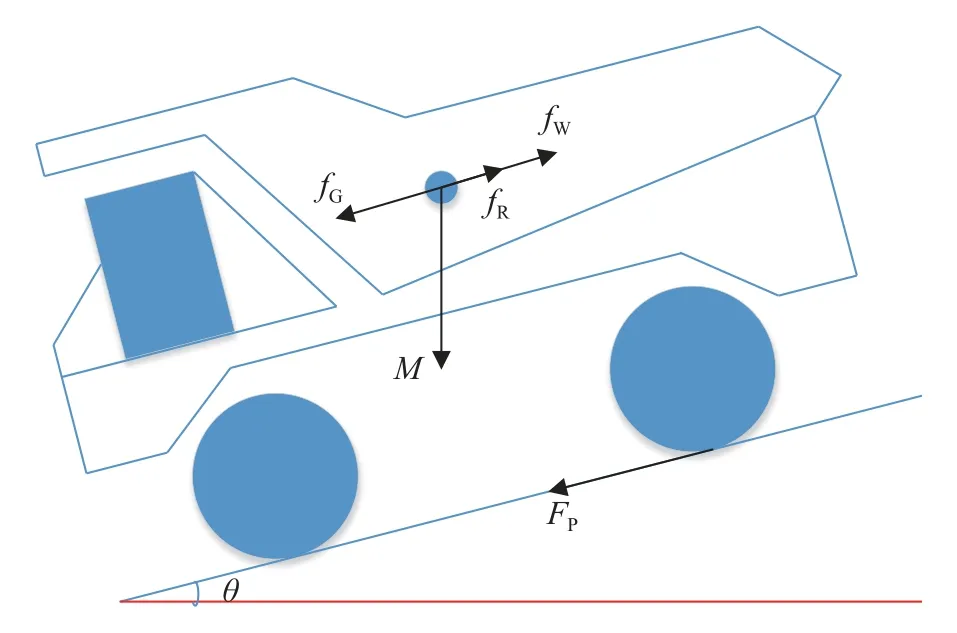
图2 TR50E 矿用自卸车行驶工况Fig.2 TR50E mining dump truck driving conditions
受坡度影响,车辆由于坡度产生的沿路面平行的分力为:
其中,M为车辆质量,θ为坡度.车辆的滚动阻力为:
其中,RC 为滚动阻力系数.车辆的风阻为:
其中,A为车辆迎风面积,Cd 为风阻系数,v为车辆速度.由式(1)到式(3)可知车辆受到的总阻力为:
设TP为电机输出力矩,由此可以得到车辆轮上驱动力为:
其中,gb 为车辆变速器速比,Ra 为减速器速比,WR为车轮半径.由此可以得到车辆行驶时所需的加速度a如式(6)所示:
1.2 建立电机模型
驱动电机是纯电动矿用自卸车的动力部件,将电池的电能转化为车辆的动能,并且能够在制动时回收制动能量.本文中电动机忽略其内部复杂的动态特性,采用基于实验数据的电机-转速-扭矩简化模型,得到电机输出转矩与效率如图3所示.
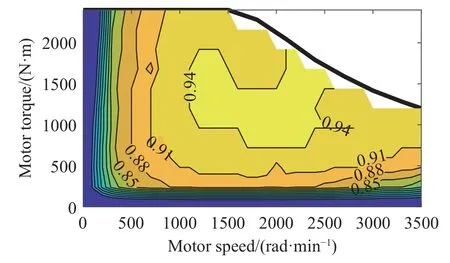
图3 电机输出转矩与效率图Fig.3 Motor output torque and efficiency graph
由图3 可知电机最高转速为3500 rad·min-1,最大输出转矩为2400 N·m,在工况中已知电机的转速与转矩的情况下可以利用查表的方式得到电机的效率,从而得到电机的输入功率与输出功率.
电机输出与输入功率如式(7)所示
其中:Pout为电机输出功率;Pin为电机输入功率;Tin为车辆制动力矩;Tout为车辆驱动力矩 N·m;em为电机效率;epc为功率转换器效率;n为电机转速.
1.3 建立电池模型
动力电池是纯电动车辆的唯一动力源,针对动力电池的复杂非线性模型和考虑电池寿命的时变模型的研究很多,由于本文研究系统的能量管理策略,可以忽略动力电池的瞬态特性且不考虑温度对动力电池的影响,动力电池模型可以简化为一阶近似内阻模型,如图4 所示.其中Voc是电池开路电压,Rb是电池的等效内阻,Ib是电池电流,Vb是负载电压,Rsb与Csb分别为电池的极化电阻与极化电容,由于在电池计算中影响较小因此可以忽略.
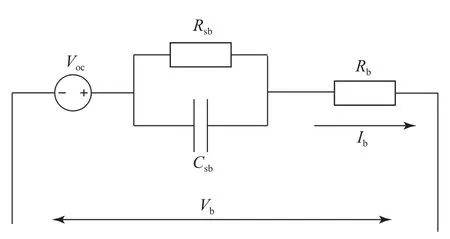
图4 简化电池模型Fig.4 Simplified battery model
由于动力电池组是由一定数量的电池单元串并联而成,忽略电池单元之间的差异性,则动力电池组的特性可以表示为
其中,Qbcell为电池容量;Qb为单个电池容量;Rbcell为电池内阻;Rb为单个电池内阻;I为电池电流;Vdrop为单个电池压降;Vb为单个电池电压;Mb为并联电池个数;Nb为串联电池个数.
由上式可以得到电池输出电压与电流如下所示
其中,Vout为电池输出电压;P为电机功率;
SOC 可由式(10)进行计算,
其中,Cmax为电池最大容量;SOCint初始电池荷电状态.
电池寿命通过实验中得到的电池充电率与SOC 数据查表得到.
电池的各类参数如表2 所示.
表2 电池参数表Table 2 Battery parameters
1.4 再生制动与机械制动分配策略
由于TR50E 矿用自卸车是后驱车,而再生制动必须使用电机进行,当车辆使用前轴以及后轴的机械制动装置时消耗的制动能量便无法回收,因此想要回收制动能量就首先需要考虑车辆再生制动与机械制动的制动力分配策略.在本文中,针对的车辆制动工况为正常行驶时的制动,因此制动强度较小.判断制动力矩所使用的工况为图5所示工况,当选择1、2 挡时电机能够输出的制动力矩较大,但是在工况中电机的转速会超出额定范围,当选择3 挡以上后电机的转速能够保持在额定值以内,因此,对电机制动力矩的输出判断依据为利用变速箱维持3 档状态时得到的制动力矩,当制动力矩能够维持在额定转矩下,意味着在该工况下仅用电机能够满足车辆行驶的制动要求.在行驶工况中车辆固定在3 挡时所需的制动力矩如图5(a)所示,得到的车速如图5(b)所示,可以看出电机所输出的制动转矩能够满足制动需求,因此,对车辆的制动力分配策略为仅使用电机进行再生制动.由于考虑的制动工况为正常行驶的制动,不考虑紧急制动的状态,因此不考虑前后轴的制动分配策略.
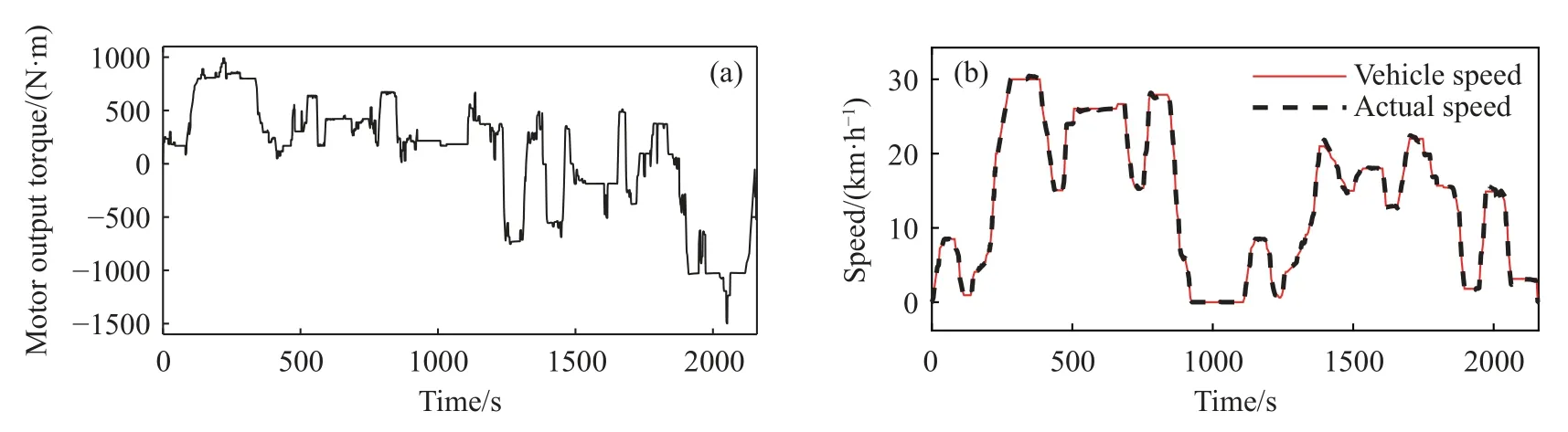
图5 工况所需制动力矩(a)电机输出转矩图;(b)车速图Fig.5 Required braking torque for working conditions: (a) motor output torque;(b) vehicle speed
2 基于强化学习的控制策略制定
2.1 强化学习
强化学习主要包含智能体、环境、状态、动作和奖励函数部分,这一算法的核心思想是利用智能体输出动作,通过智能体输出的动作与环境交互,再从环境中更新智能体状态并且获得相应的奖励信号,智能体根据奖励信号改善自身的策略直到智能体策略收敛.基于强化学习的控制策略框架如图6 所示.
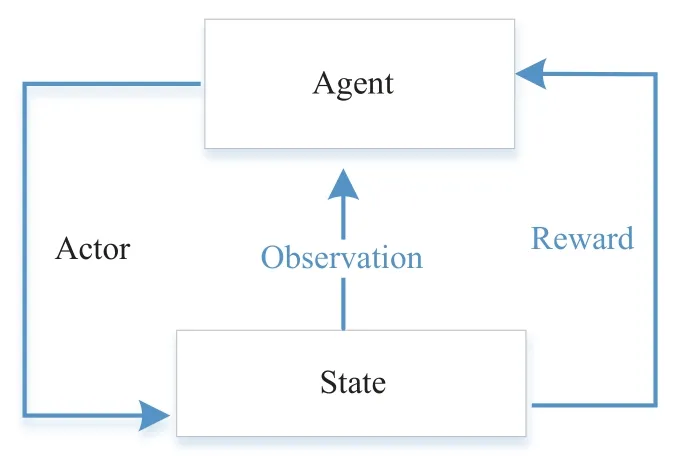
图6 强化学习策略框架Fig.6 Framework for reinforcing learning strategies
不同的智能体算法也有一定的不同,最早的Q 学习算法确定了强化学习的基本方法,通过动作获得的奖励更新环境的状态与价值,其中状态与动作为能够确定的各个定值,如上下或前进等,因此Q 学习能够利用表格形式表示各个策略价值,但也代表其只能用于离散动作且动作数量的提升会导致所需计算量指数级上升.
为了使算法能够用于连续动作与环境,DQN算法引入神经网络来评估离散的状态与对应价值之间的关系,进而得到连续状态下的价值,同时将各个动作取得的信息保存在经验池中以打消相关性并提高神经网络训练的质量,但是动作仍旧是离散的.为了保证训练的稳定性,神经网络被分为Q 网络与Target Q 网络.之后出现的策略梯度 (PG)算法采用计算高斯概率分布的神经网络来对动作进行策略分析,从而能够输出连续的动作.但是单一的Q 网络会对状态价值产生过度的估计,使计算值比实际值更高,因此使用两个Q 网络,取两个网络中的较小值进行计算,以此来避免过度估计,优化后的PG 算法被称为DDPG 算法.
此时大部分算法都采用贪婪策略作为动作的选取依据,这会导致动作有可能趋向局部最优而不是全局最优,为了使策略动作能够尽可能找到最为优秀的动作,被称为TD3 的算法在动作中采用了加入噪音的方法让动作策略跳出局部最优区间.在SAC 算法中,不但利用两个Q 学习网络避免了神经网络的过度估计,并且在策略网络中引入了熵权重保证了智能体对各个策略的探索,与TD3相比提高了神经网络训练效率与质量.
在本文中,利用Matlab 软件中的SAC 算法对强化学习再生制动控制策略进行制定,在Matlab中,SAC 算法流程如下:
初始化两个评价网络与一个策略网络,随后先以初始化网络执行一系列策略来初始化经验池.在每一个训练步长中,依靠现在的动作策略选择一个动作作用于现在的环境,之后得到下一个环境与相应的奖励,将环境、动作与奖励信息保存入经验池中.为了更新神经网络,在每个特定步长从经验池中取出一定数量的经验,首先更新评价网络,用于更新评价网络的loss 函数如公式(11)所示:
其中,Ma 为取出的经验数量;Qk为评价网络;Si为相应的状态;Aci为选择的动作;ϕk为评价网络输出值;yi为这一状态下的加权价值,如下所示
其中,Rei为选择的动作所得到的奖励;α为熵权重;为动作选择策略网络;γ为衰减因子;Qtk为目标评价网络;ϕtk为目标评价网络输出值.
之后按照以下loss 函数更新动作网络:
最后以如下loss 函数更新权重函数
其中,χ为目标熵.
为了避免神经网络的过度估计,提高算法的稳定性,目标评价网络在一定步长之后进行更新,更新时将评价网络Qk的内容复制到Qtk中.
2.2 制定再生制动控制策略
在基于SAC 算法的再生制动策略中,需要设定的关键参数为系统环境状态、动作空间、奖励函数以及神经网络状态,各类关键参数设定如下.
2.2.1 系统状态与动作空间
系统状态需要充分地表示整个模型的各个状态,因此在本模型中以车速V、加速度a、电池SOC、车辆质量M与道路坡度Grd 为系统环境状态,如式(15)所示,为了提高神经网络的训练效率,将各个环境状态的区间调整为[0,1].
根据TR50E 车辆的结构进行分析,车辆能够输出的动作为变速器挡位,因此将动作空间设置为输出变速器挡位,限制挡位区间在[1,4],离散化表示为:
2.2.2 奖励函数
奖励函数用于智能体在向环境施加动作后,环境对智能体进行反馈,使智能体对自身的策略进行修改,调整神经网络参数.在本次强化学习中,首先需要考虑的是在行驶过程中车辆的电机转速不能超过电机的上限,因此关于电机转速的奖励信号设置如公式(17)所示:
一般对纯电动车辆的再生制动奖励设置为电池的SOC 相关函数,通过对车辆的再生制动进行分析,再生制动需要倾向于减小电力消耗、尽量维持SOC 以及延长电池使用寿命.因此对奖励信号设置如公式(18)所示:
其中,ε、β、φ分别是奖励信号中功率、效率、电池寿命的权重因子;P(t)为电机功率;Eff(t)为电机效率;L(t)为电池寿命.在该奖励信号中,智能体会倾向于提高电机效率,减小电机输出功率,提高电池寿命.
2.2.3 算法设计
评价网络和目标网络具有相同的结构,均由3 个隐含层组成,动作网络由4 个隐含层组成,其中激活函数采用线性激活单元,每一层由128 个整流单元全连接组成.在针对神经网络的参数中,主要调整的是学习率与单次取出经验数量,学习率过高会导致神经网络的震荡,而学习率过低会导致神经网络的收敛速度过慢.单次取出的经验数量决定了神经网络对环境的泛化能力,过小可能会导致算法的泛化性较差,过大则会占用过多计算资源.
智能体的其他参数中最主要的为熵权重.熵权重影响智能体对动作环境的探索.熵权重过大会导致智能体对环境的探索不足,陷入局部最优的状态.而熵权重过小则会导致智能体始终处于探索状态,无法收敛.
在经过多次不同参数的训练之后,将训练效果最好的参数作为算法的主要参数,算法的主要参数设置如表3 所示.
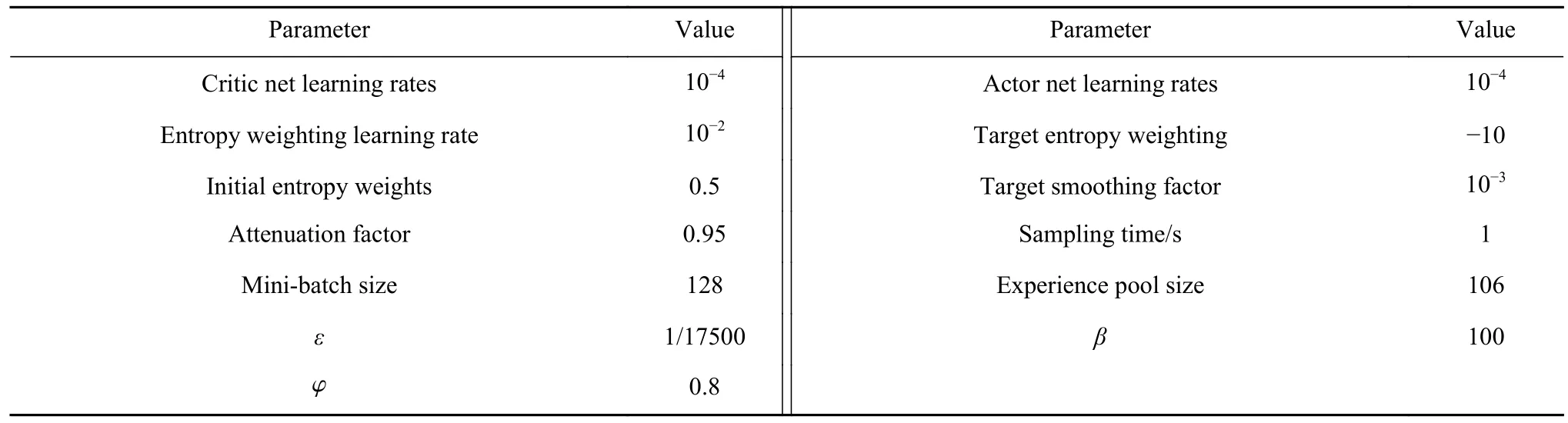
表3 SAC 主要参数Table 3 SAC main parameters
2.2.4 控制策略对比
在本次仿真中,需要对控制策略进行对比,以对该工况的动态规划、DDPG 强化学习以及基于规则的换挡策略作为控制策略的对比对象.
本次使用动态规划算法对车辆的数学模型进行分析,输入车辆运行工况后利用第2 节所得的各个公式与效率表将各个挡位下的电机功率、效率计算出来后,选择最优挡位.
基于规则的换挡策略以电机转速以及踏板开度作为换挡依据,所使用的换挡规则如图7 所示.

图7 车辆换挡规则图.(a)车辆降档依据图;(b)车辆升档依据图Fig.7 Vehicle shift rule diagram: (a) vehicle downshifting based on the chart;(b) vehicle upshifting based on the chart
图中不同的颜色代表了相应踏板开度以及档位下的车速高低,在降档时,当逻辑模块在相应挡位处检测车辆速度比降档图中的车速更小并保持50 个机器时间时,则发出指令对变速器进行降档.在升档时与降档时类似,当逻辑模块在相应挡位处检测车辆速度比升档图中的车速更大并保持50 个机器时间时,则发出指令对变速器进行升档操作.
3 仿真与分析
本次仿真采用Matlab/Simulink 软件作为仿真工具,利用正向建模方法对车辆进行建模,以驾驶员意图作为起点,通过驾驶员意图模块决定车辆制动与油门踏板的开度.利用踏板开度大小与变速器挡位决定车辆的制动力矩与驱动力矩.利用力矩得到车辆电机所需功率.利用功率得到车辆电池输出功率与SOC.其中智能体决定相应的变速器挡位.同时观测系统环境与获得的奖励.调整自身神经网络的状态从而尽可能在一个循环中得到最大的奖励.本次训练使用一个车辆的速度工况,在每次训练中随机选择电池SOC 初始值.最后将训练完成的智能体用于车辆的运行工况进行仿真测试.在本次训练中对SAC 以及DDPG 进行了100 次训练,最后得到的训练值图像如图8 所示.
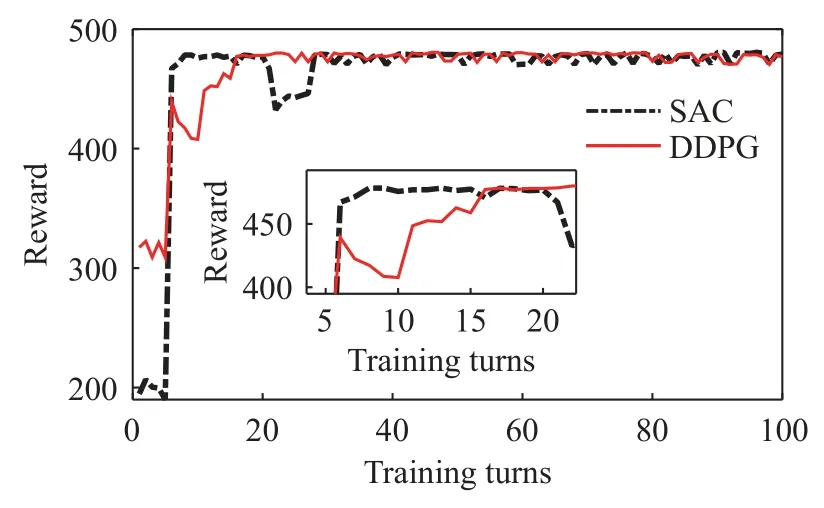
图8 SAC 训练值结果Fig.8 SAC training value results
本次仿真中车辆的运行工况如图9 所示,由矿用自卸车在矿场中运行得到的数据整理后得到.
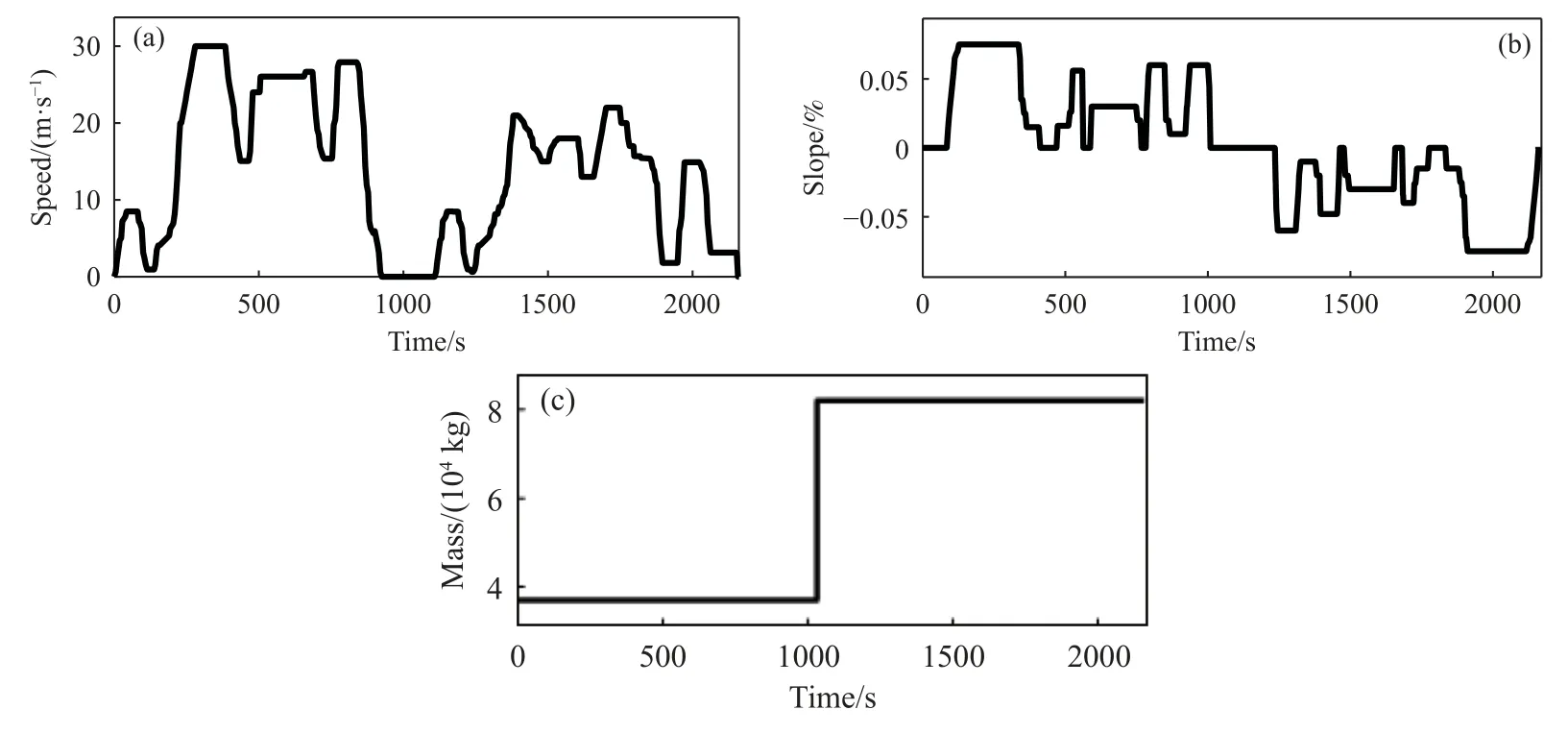
图9 车辆运行工况.(a)为车辆车速;(b)为车辆坡度;(c)为车辆质量Fig.9 Vehicle operating conditions: (a) vehicle speed;(b) vehicle slope;(c) vehicle mass
从训练值中可以看出SAC 能更快达到高点,同时能够保持一定的探索来寻找最优.DDPG 在到达最高点后便达到收敛,探索阶段在收敛后便不再进行.
在训练完成之后利用SAC 智能代理运行模型进行仿真,之后分别换为DDPG 算法训练后的智能体、动态规划以及基于规则控制策略得到的挡位输入模型进行仿真.仿真之后得到的SAC 车辆速度如图10 所示.可以看出SAC 算法都能够满足正常行驶条件下的车辆控制性能.
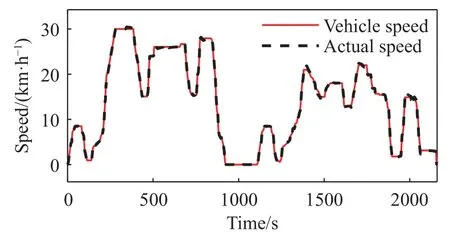
图10 仿真速度结果Fig.10 Simulation speed results
SAC 训练后挡位如图11 所示,可以看出SAC输出的挡位基本上较为确定,曲线基本上与车辆运行所需挡位吻合,没有不太合理的挡位选择.
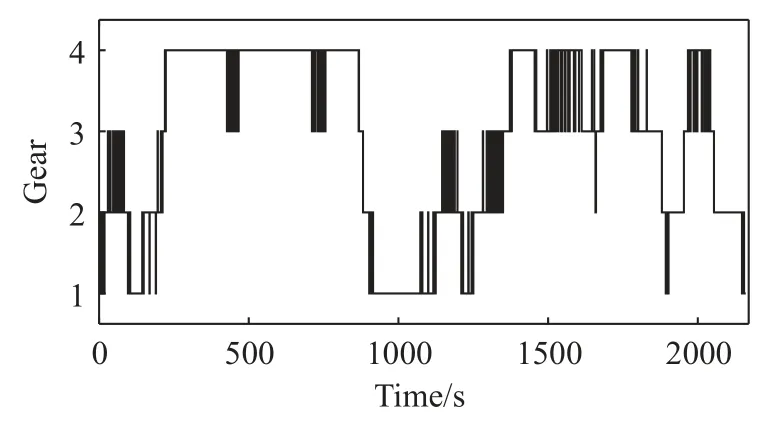
图11 SAC 输出挡位Fig.11 SAC output gears
仿真后得到的四个控制策略的车辆电机工作效率区间如图12 所示,可以看出,SAC 算法控制策略下智能体会趋向于将电机效率维持在较高的峰值范围处,并且点位较为分散,说明SAC 算法在一些环境下仍旧保留了一定的探索能力,在最高效率处SAC 则与DDPG 以及DP 算法所得到的电机效率重叠,说明SAC 在最高效率时能够减小对动作的探索.
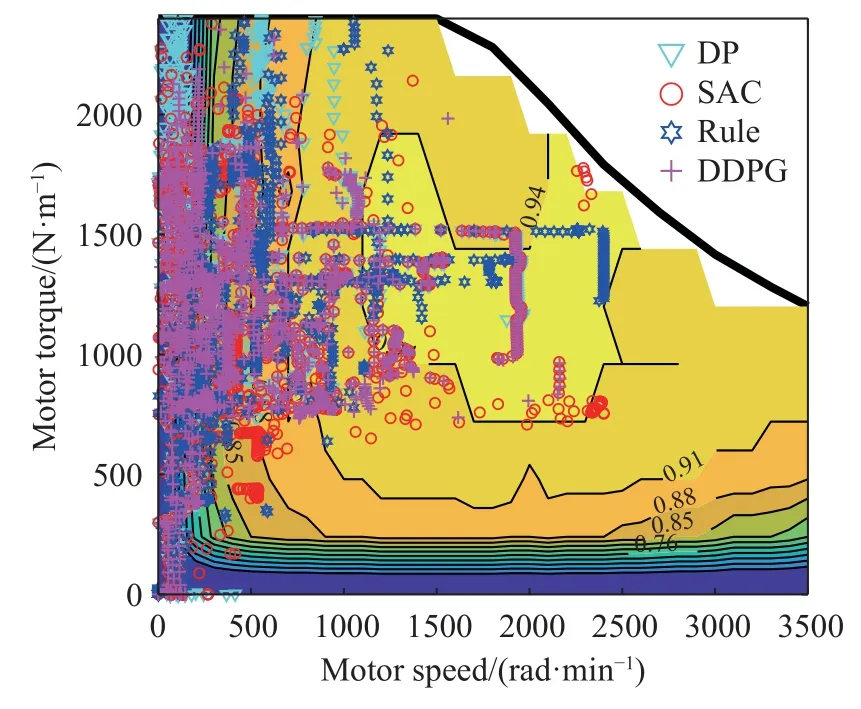
图12 仿真电机效率区间Fig.12 Simulated motor efficiency interval
DDPG 算法得到的电机效率则较为集中,在高效区与DP 算法的重合度也较高,说明在这一工况下DDPG 算法也能够将电机维持在一个较高效的工况下,但是过于集中的动作有可能代表算法的过收敛,使算法在其他工况下的效果不佳.而基于规则的控制策略所得到的电机效率则较为分散,与DP 的重合度较低.
仿真后得到的四种车辆电池SOC 状态如图13所示.可以看出SAC 与DDPG 控制策略与DP 在SOC 上差距不大,最终值都接近0.74,而基于规则的控制策略所得到的SOC 则接近0.72,与前三个控制策略的差距较大.
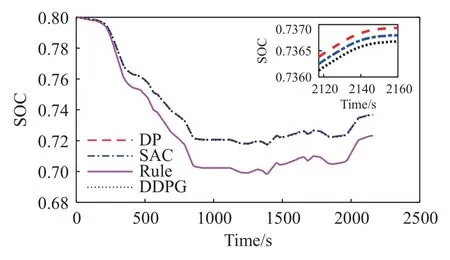
图13 仿真车辆SOCFig.13 Simulated vehicle SOC
车辆的电池寿命在这一仿真中更多地取决于电池的充电率C-rate,在对电池寿命的判断中,利用C-rate 以及电池温度进行查表得到电池寿命的损耗参数,在查表中得到了C-rate 越大则对电池的损害越大,使电池的寿命下降地更快的结论,因此本次仿真中以C-rate 的大小来判断电池的寿命变化.在仿真中得到的电池C-rate 如图14 所示
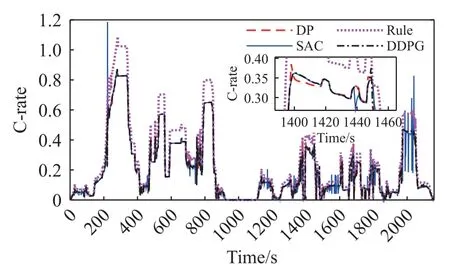
图14 仿真车辆C-rateFig.14 Simulated vehicle C-rate
在图中可以看出,除了有少数的突变以外,SAC控制策略下的C-rate 基本上与DP 控制下的C-rate相同,并且基本上在0.8 的范围以内.DDPG 与SAC以及DP 在C-rate 上的差距较小,三个策略的C-rate曲线可以看作基本上重叠.
而基于规则的控制策略的C-rate 则普遍比其他策略的C-rate 高,且最大的差距上能达到0.2 左右.因此可以认为SAC 与DDPG 的控制策略也能够实现与DP 类似的延长电池寿命的效果.
为了量化四个控制策略的差距,对车辆的最终能耗与损耗的电池寿命进行比较,在本文中使用对C-rate 的积分作为电池寿命的最终损耗,在仿真中车辆得到的最终能耗与电池寿命的损耗在四个策略下具体的差距如表4 所示.
可以看出相比于规则的控制策略,DP、SAC、DDPG 在能耗方面分别降低了18.15%、17.18%、16.63%.从电池寿命的损耗上看,与规则策略相比,DP 降低了57.31%,SAC 降低了56.87%,DDPG 降低了57.38%.从电池寿命上看DDPG 的策略对电池寿命的损耗较低,但是从能量消耗上看DDPG较高,因此DDPG 中电池寿命损耗较低的一个原因是在再生制动中回收的能量较少,由于C-rate 与能耗在一定程度上为线性关系,因此SAC 与DDPG算法在能耗与寿命上各自具有的0.5%差距,可以看作是同一性能的算法对寿命与能耗之间的取舍.
综上可以看出DDPG 算法与SAC 算法在性能上较为接近,优于规则算法,并且与DP 算法的性能差距极小.
4 总结
本文针对TR50E 矿用自卸车进行了研究,对车辆的动力学进行分析,并对车辆的电机与电池进行了建模.在此基础上为车辆制定了基于SAC、DDPG 的强化学习、动态规划与规则的控制策略.使用Matlab/Simulink 软件对车辆进行仿真模拟并对车辆智能体进行训练,将训练完成后的强化学习控制策略与其他三个控制策略用于车辆仿真中,进而验证其可行性与性能.在特定工况下进行仿真后得到了车辆速度、SOC、效率与C-rate 的仿真结果.对结果进行分析,证明了所制定的SAC、DDPG 能够满足车辆运行的动力性需求,并与DP 算法相近.同时将强化学习与动态规划算法下控制得到的SOC、效率、C-rate 与规则算法相比,从结果上看强化学习与动态规划的控制策略在效率、C-rate 以及SOC 方面差距较小,且优于基于规则的控制策略.最后将四种控制策略的能耗与电池寿命损耗进行比较,SAC、DDPG 与DP 的差距在1%左右,且三种算法在能耗上与规则算法相比降低了16.63%~18.15%,在电池寿命上提高了56.87%~57.38%.证明了基于强化学习的控制策略优于基于规则的控制策略,并且能够达到与DP 几乎相同的效果.在之后的研究中考虑将强化学习策略用于实车进行实验,验证该策略在再生制动方面的效果,并与DP 算法在车辆的运行实时性上进行比较.
