基于突发公共卫生事件影响下的铁路客流量恢复率预测研究
2023-12-27周明杉卫铮铮李聚宝
周明杉,卫铮铮,李聚宝
(中国铁道科学研究院集团有限公司 电子计算技术研究所,北京 100081)
0 引言
突发公共卫生事件是指突然发生,造成或者可能造成社会公众健康严重损害的重大传染病疫情、群体性不明原因疾病、重大食物和职业中毒以及其他严重影响公众健康的事件。自2020 年新冠疫情出现以来,我国铁路运输和运营遭受了一定影响。进入后疫情时代,各地疫情的阶段性爆发使铁路客流量呈现较大的波动,在此背景下,准确研判客流趋势对铁路客运决策起着关键作用。
国内外针对铁路客流量预测已有不少的研究,研究初期主要采用的是统计学和传统机器学习方法[1-3],后期出现了混合预测方法[4-6]。随着计算机算力的提升,深度学习模型在该方向得以广泛应用。近几年的研究证明,深度学习在客流量预测方面的应用[7-9]具有显著效果。这些研究方法各有其优势和应用范围,针对的预测对象也有所不同,其中涉及突发公共卫生事件影响下的铁路客流量恢复率预测研究较少。
突发公共卫生事件对铁路客流量产生的影响是复杂而多样的[10],需深入分析后疫情时代的客流量特征。基于此,尝试分析后疫情时代的客流量特征,提出恢复率的概念,综合考虑疫情严重等级、地理位置和铁路分布等因素,建立不同城市间的影响模型,通过对客流量特征进行主成分分析,结合XGBoost算法对客流量恢复率进行预测,为突发公共卫生事件影响下的铁路客流量恢复率预测提供理论指导与参考。
1 城市间铁路客流量影响因素分析
为提高城市间客流量恢复率预测模型的准确性,需全面分析其影响因素,并进行权重计算。
1.1 城市间铁路客流量影响因素
在受疫情影响下,城市间铁路客流量影响因素的选取对模型的建立十分重要。从宏观角度来看,铁路客流量在疫情期间受多个因素的综合影响而发生变化,并且具有一定的规律性。通过对疫情下的城市间客流量的观察,分析得出疫情期城市间客流量主要由城市间铁路里程、非疫情期城市间客流量、城市间地理位置和铁路分布、疫情的严重程度4个因素决定。
(1)城市间铁路里程。通常来说,铁路里程较短的城市间地理位置更接近,人们的通勤和往来频率更高。随着城市间铁路里程的增加,城市间的通勤活动相对减少,长距离出行中,旅客更倾向于选择飞机来代替铁路出行。选取2021 年城市间列车运行距离的平均值作为城市间铁路里程,得到二级及以上城市间铁路里程统计如图1所示,其中二级及以上城市数据来自国家统计局,共计622 个。根据图1,得出大多数城市间铁路里程在 3000 km以内。经过统计,得到城市间铁路平均里程为 1204 km,方差为740。此外,其1/4,1/2,3/4 分位数对应的距离依次为644 km, 1089 km, 1631 km。

图1 二级及以上城市间铁路里程统计Fig.1 Railway mileage statistics among cities of level II and above
(2)非疫情期城市间客流量。城市间的客流量包括客流发送量和客流到达量2 部分,为了获取城市间的客流量数据,选取2019 年每天平均发客量大于50 人次的二级及以上城市作为样本。二级及以上城市间2019 年每日平均客流量统计如图2 所示。经统计得到二级及以上城市间2019 年每日平均客流量为882 人次,数据呈现典型的长尾分布,可以将城市间的客流量划分为发送量和到达量2 个维度进行研究。

图2 二级及以上城市间2019年每日平均客流量统计Fig.2 Statistics of daily average passenger flow among cities of level II and above in 2019
(3)城市间地理位置和铁路分布。由于地理位置的隔绝和铁路线路的分布,铁路系统会呈现出一些区域特征。根据地理位置的分布,将城市划分为7个地区:东北、华北、西北、华东、华南、华中、西南,不同地区城市与铁路分布具体特征如表1所示。

表1 不同地区城市与铁路分布具体特征Tab.1 Distribution characteristics of cities and railways in different regions
(4)疫情严重程度。一般来说,随着疫情严重程度的增加,客流量会逐渐减少。当疫情严重到一定程度时,客流量会趋近于0。依据国家卫生健康委员会发布的每个城市2021 年1—9 月的疫情新增数据,参考国家卫生健康委员会中高低风险的疫情周期划分标准,提出疫情等级划分如表2 所示,以该城市连续7 d 无新增病例作为一段疫情结束的标记,统计该段时间内该城市疫情的持续时间和累计病例数。根据疫情持续时间、累计病例数和平均每日新增病例数3 个数据,将疫情分为5 个等级。

表2 疫情等级划分Tab.2 Pandemic level
1.2 城市间铁路客流量影响因素权重计算
通过权重量化城市间客流量影响因素,为客流量预测和决策提供参考,城市间铁路客流量4 个特征因素权重具体计算如下。
(1)城市间铁路里程。在铁路客流量预测和影响因素分析中,为更准确地反映不同城市之间的联系和影响程度,将城市间铁路里程转换为权重,其计算公式为
式中:i,j分别代表不同城市;di,j为城市间铁路里程的权重,di,j∈[0,1),di,j值越大说明i与j市之间的里程越近;xi,j为城市i与j间的铁路里程,km;σ为城市间铁路里程的标准差。
以最高速度400 km/h的高速动车组为基准,考虑中间站点的停站,当城市间铁路里程大于 1589 km时,其运行时长约为4 h。超过4 h旅行时间的旅客其疲劳程度明显增加,此时选择铁路的旅客较少[11],故一般认为铁路里程相距 1589 km的城市相互间的影响不大。基于此,可以设置当xi,j> 1589 km 时,其权重di,j取0,表示2个城市间没有明显的铁路联系。同样,如果2 个城市间没有铁路连接,其权重也取0。
(2)城市间客流量。对城市间的客流量进行权值计算,客流发送量fi,j,是以某个城市为出发城市其对应的到达城市的客流到达量占该城市客流总发送量的百分比,其计算公式为
式中:fi,j为i至j市客流发送量百分比,%;SFi为自i城市出发能到达的所有城市集合;numi,j为i至j市的客流量,人次。
客流到达量ti,j,是以某个城市为到达城市其对应的出发城市的客流发送量占该城市客流总到达量的百分比,其计算公式为
式中:ti,j为i至j市客流到达量百分比,%;STj为能到达j城市的所有出发城市集合。
客流发送量和客流到达量的百分比分布如表3所示。

表3 客流发送量和客流到达量的百分比分布Tab.3 Percentage distribution of passenger flow sending and arriving
从表3 可以看出,客流发送量与客流到达量百分比分布基本相同。大部分城市的到达和出发百分比在(0.2,5]之间,因此如果fi,j或ti,j在[0,0.2]之间,则该占比过低,将其出发和到达权重置为0,如果fi,j或ti,j在(5,100]之间,则将其出发和到达权重置为5。对于百分比在(0.2,5]之间的数据进行如下标准化处理。
(3)城市地理位置和铁路分布。由于位于相同地区城市间的影响远大于不同地区城市间的影响,故根据下面公式,对其进行分类。
式中:wi,j代表i市与j市的地理权重。
2 基于XGBoost 的城间客流量恢复率预测模型
2.1 XGBoost模型算法
XGBoost在大部分的回归和分类问题上有广泛的应用[12],表达的性能良好,可以使用该算法对疫情等级进行分类,从而预测城间客流量的恢复率。XGBoost 对应的模型包含了多个CART 树,其损失函数为
式中:n为需预测数据的总量;yi为实际受疫情影响等级;为模型的预测等级;为模型的训练误差;K为模型生成树的总量;Ω(fk)为第k棵树的正则化项。
训练过程中,XGBoost 采用贪心算法进行树节点的分裂,根据疫情等级、地理和铁路分布特征、客流发送量等级等属性对树中的每个叶子结点尝试进行分裂。每次分裂后,原先的叶子结点将被划分为左右2 个子叶子结点,原叶子结点中的样本集将根据该结点的判断规则分散到左右2 个叶子结点中。新分裂1 个结点后,需要检测这次分裂是否会给损失函数带来增益,增益的定义表达式为
式中:λ为岭回归正则化系数;其中GL为左子树的所有叶子结点的输入样本的一阶导之和;HL为左子树的所有叶子结点的输入样本的二阶导之和;同理,GR,HR为右子树的所有叶子节点的一阶导和二阶导之和。和分别为划分后的左子树和右子树的分数;为划分前的分数;γ为加入新叶子节点的复杂度的代价。
当引入1 次分裂后,重新计算新生成的左、右2 个叶子结点的样本权重和。如果任一个叶子结点的样本权重低于某一个阈值,将会放弃此次分裂。
2.2 K均值聚类
K 均值聚类是一种常用的数据聚类算法[13],旨在将数据点分组为具有相似特征的群集。在这种方法中,首先需要选择分成多少个群集,通常称为K值。然后,算法随机选择K个数据点作为初始群集的中心,称为质心。通过计算每个数据点与每个质心之间的距离,将数据点分配到最近的质心所代表的群集;根据每个群集中的数据点,计算新的质心位置。这个过程不断迭代,直到质心的变化很小或者达到预定的迭代次数。K均值聚类通过最小化群集内数据点与其质心之间的平均距离,同时在不同群集之间保存了一定的距离,从而实现了数据的分组。
肘部图是用于确定合适的K值的一种图形方法[14]。构建肘部图的步骤包括尝试不同的K值,对每个K值执行K均值聚类,然后计算每个群集内数据点到其质心的平均距离,通常称为簇内平方和(SSE)。随后,将不同K值对应的SSE值绘制成图表。肘部图的特点是,随着K值的增加,SSE 值逐渐减少。然而,当K值增加到一定程度时,SSE的减小幅度会减缓,形成一个图像上的“肘部”,这个肘部对应的K值通常被认为是数据分组的最佳选择。
2.3 恢复率的引入
所有2021 年及以后的客流量数据以2019 年的客流量数据为参考,将其节假日、周末和工作日对齐后进行如下处理。
式中:r为恢复率;I21,I19分别为2021 年和2019 年的同期客流量,人次。
r取值范围为[-1,∞],通常情况下为[-1,0]之间,-1 代表2021 年的客流量为0,0 代表2021 年的客流量与2019 年同期持平,取值为正数则表明2021年的客流量大于2019年的同期客流量,2021年北京至上海客流量恢复率曲线如图3所示。

图3 2021年北京至上海客流量恢复率曲线Fig.3 Recovery rate curve of passenger flow from Beijing to Shanghai in 2021
图3中红点和蓝点标注了疫情开始到结束的时间范围,恢复率能从客流量变化识别疫情持续时间和严重程度,可以将不同城市间客流发送量的变化转变为统一的判别指标,因此恢复率的概念对客流量识别有重要价值。
2.4 预测目标值的选取
对于二级及以上城市之间的客流量数据,剔除2019年平均每天客流量小于50人次的城市间数据。截取其疫情期间的数据,计算疫情持续天数和平均恢复率,去掉疫情期间平均恢复率大于-0.5的异常数据。由于疫情持续天数和平均恢复率数据呈现长尾分布,故将对其作box-cox变换处理。
式中:γ为常数,通过最大似然估计方法求得;y(γ)为box-cox变换后的恢复率与疫情持续天数。
将处理后的数据进行K均值聚类,得到疫情持续天数和平均恢复率聚类肘部图如图4所示。
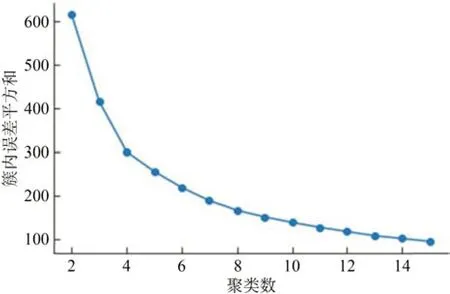
图4 疫情持续天数和平均恢复率聚类肘部图Fig.4 Cluster elbow diagram of pandemic duration and average recovery rate
通过肘部图可以看出K均值聚类,聚类数等于4 时为曲线的拐点,故肘部为K=4,将其聚为4 类。疫情持续天数和平均恢复率聚类图如图5 所示,每一聚类对应的客流量受疫情影响等级如表4 所示。经过聚类分析,将客流量受疫情影响程度划分为了4 个不同的等级,每个等级都呈现出独特的特征,故预测目标便是客流量受疫情影响程度所对应的等级。

表4 客流量受疫情影响等级Tab.4 Passenger flow level affected by the pandemic

图5 疫情持续天数和平均恢复率聚类图Fig.5 Cluster diagram of pandemic duration and average recovery rate
3 实验与评估
3.1 实验流程
选取2021年1—9月发生疫情的城市至城市间的数据进行分析。经过预处理,得到了总计 5721 条受疫情影响的城市至城市间数据。为了建立模型并进行实验,将随机选取80%的数据作为训练样本,剩下20%的数据作为测试样本。由于目标值分布不均匀、样本数不均衡,需要对训练集里的少数类进行“过采样”,使得正、反例数目接近,并进行机器学习。过采样后对数据进行主成分分析,使数据维数压缩,尽可能降低原数据的复杂度,损失少量信息。
在模型训练的过程中,首先对XGBoost的重要参数进行高效调参。通常情况下,很多模型需要手动调参,故引入网格搜索来预设几种超参数组合。每组超参数都采用4 组交叉验证来进行评估,以防止过拟合。将数据分为4 份,其中一份作为验证集,进行4 组测试,每次更换不同的验证集,得到4 组模型的结果,取其平均值作为最终结果。最后引入朴素贝叶斯算法和LightGBM 算法与XGBoost算法进行对比。
3.2 模型评估
对于分类模型常采用的损失函数有合页损失和对数损失。
(1)合页损失。当类别有多个时,依据Crammer&Singer 提出的多类损失办法来计算,其计算公式为
式中:yw是对真实类标签的预测值;yt是对其他类标签的预测里面最大的值。
(2)对数损失。对数损失是定义在概率分布基础上的,其计算公式为
式中:a表示样本;b表示类别;Pab代表第a个样本属于类别b的概率。
使用朴素贝叶斯、LightGBM、XGBoost 分别进行预测,得到的算法性能对比如表5所示。

表5 算法性能对比Tab.5 Algorithm performance comparison
由表5 可知,XGBoost 算法在整体准确率方面表现最佳,并且具有最小的合页损失和对数损失值;从预测准确率来看,XGBoost 算法优于LightGBM 算法,而LightGBM 算法又好于朴素贝叶斯算法;从运行耗时来看,朴素贝叶斯的执行速度最快,其次是LgihtGBM,而XGBoost 的执行速度相对较慢。尽管XGBoost算法由于最优参数中树的最大深度导致耗时较长,但其总体预测效果最好。
4 结束语
基于XGBoost 算法,选取2021 年1—9 月所有二级及以上城市间的铁路客流量恢复率进行模型训练和预测,其准确率为87.09%,总体效果良好。研究为完善疫情下客流量恢复率预测的方法进行了有益的探索,对于减少铁路客运收益损失和降低运输风险具有重要价值。在后续的研究中,将考虑加入疫情下影响铁路客流量的其他相关因素,如各地疫情管控政策、客流周期性和季节性等。此外,还可将客流量受疫情影响等级进行更加精细的划分,以进一步提高模型的实用性和预测精确度,也将有助于更全面地理解疫情对铁路客流量的影响,并为客流量预测提供更准确、可靠的方法和决策支持。
