基于词向量模型的漏洞检测方法
2023-11-24胡景浩侯正章
肖 巍,胡景浩,侯正章,王 涛,潘 超
(1.长春工业大学 计算机科学与工程学院,长春 130012;2.吉林大学 软件学院,长春 130012)
在万物互联的时代,网络安全问题备受关注.目前最常见和影响力最大的网络安全问题均由软件漏洞引起[1].软件漏洞不仅容易被发现、被利用,而且能让非法入侵者窃取数据或阻止应用程序正常运行,常导致巨大的经济损失,严重危害了网络安全,如浏览器插件中的漏洞,威胁着数百万互联网用户的安全和隐私.为解决软件漏洞问题,研究人员提出了许多方法,包括静态分析、动态分析和混合分析.静态分析是指对于给定程序的源代码进行分析,如基于规则/模板的分析、符号执行和代码相似性检测,主要依赖于对源代码的分析;动态分析是指通过使用特定输入数据执行给定程序并监视其运行时的行为对其进行分析,如模糊测试和污点分析;混合分析是指将静态分析和动态分析技术相结合,对给定的程序进行分析.
机器学习和数据挖掘技术的进步以及它们在解决复杂应用问题上的成功案例,促使研究人员开始考虑如何有效地利用这些技术进一步解决计算机安全问题.目前已有许多研究利用数据挖掘和机器学习技术自动提取漏洞代码段的特征和模式,通过模式匹配技术发现软件漏洞[2].Yamaguchi等[3]将函数构建成AST(abstract syntax tree),利用词袋技术将其映射到向量空间后,通过语义分析检测软件漏洞;Pang等[4]采用N-gram语法分析和统计特征选择相结合的方式预测漏洞软件;Grieco等[5]提出综合使用N-gram和Word2vec模型对代码进行向量表示,利用随机森林等多种机器学习算法进行漏洞检测.
近年来,神经网络模型在漏洞检测方面的应用也越来越广泛.Russell等[6]使用Word2vec做为词向量模型,通过卷积神经网络结合随机森林的方法检测代码漏洞,获得了很好的实验效果;Li等[7]提出的VulDeePecker系统在SARD(software assurance reference dataset)数据集上使用Word2vec词向量模型作为神经网络的输入,检测切片级C/C++代码漏洞,通过SySeVR框架对代码的语法和语义进行表征,提高了漏洞检测的准确性;Lin等[8]通过在手动标记的漏洞数据集上进行实验,将代码序列化为抽象语法树,经过Word2vec模型输入到以双向长短期记忆网络为基本框架的神经网络模型中检测漏洞,与传统方式相比,漏洞检测效果更显著.
在漏洞检测领域,目前研究者大多数在自己收集的数据集或SARD上进行研究和测试.数据集与实验环境的不同,会导致无法准确衡量算法的优劣.多数漏洞检测的研究是通过在同一种词向量模型上应用不同的神经网络提高准确率,而对于多种词向量模型,哪种词向量模型与神经网络相结合能更有效地检测漏洞还没有准确结论.
本文通过在同一数据集同一实验环境中对不同的词向量模型结合不同的神经网络进行实验,分析得出最适用于漏洞检测的词向量模型和神经网络模型.本文的贡献主要有以下三方面:
1) 本文在同一数据集上对数据进行预处理,先采用不同的词向量进行转化,再结合不同的神经网络进行实验,通过比较统一平台、统一框架下产生的不同实验结果,分析出代码漏洞的特点;
2) 本文在C/C++函数漏洞数据集上使用Word2vec,Fasttext,GloVe(global vectors for word representation),ELMo(embeddings from language models)和BERT(bidirectional encoder representation from transformers)词向量模型,对源代码生成的抽象语法树结构进行知识表示,由于不同模型生成的词向量对代码的语义和语法关系表征不同,漏洞检测结果不同,分析出适用于漏洞检测的词向量模型;
3) 本文使用主流神经网络模型对代码漏洞进行检测,如DNN(deep neural networks),GRU(gate recurrent unit),LSTM(long short-term memory),Bi-GRU(bidirectional gated recurrent unit),Bi-LSTM(bidirectional long short-term memory)和Text-CNN(convolutional neural networks for text classification),不同网络结构的神经网络模型对漏洞检测效果不同,根据实验结果分析出适用于漏洞检测的神经网络模型.
1 词向量模型的基本原理
1.1 Word2vec模型
NNLM(neural network language model)[9]以前馈神经网络模型为基础,使用低维紧凑的词向量对上下文进行表示,解决了词袋模型产生的数据稀疏和语义鸿沟等问题.RNNLM(recurrent neural network language model)[10]在NNLM的基础上将上一轮计算状态应用到新一轮计算中,不再计算相同的词表征,从而提高了模型的时间效率.CBOW(continuous bag-of-words)模型[11]采用先求和再求平均的计算方法,在降低向量维度和减少参数数量的同时采用线性分类,从而提高了模型效率.CBOW模型的输入是中心词的上下文,输出是预测的中心词.Skip-gram模型[11]是在已知当前词的情况下去预测上下文.由于序列化数据的局部信息具有关联性,Word2vec模型将自然语言中的词一一映射为长度相等的词向量.使用该模型能分析出前后文的语义和语法关系,因此其广泛应用于自然语言处理的情感分析[12]、文本分类[13]和关系抽取[14]任务中.
1.2 Fasttext模型
基于CBOW模型的文本分类模型Fasttext[15]与CBOW模型结构基本一致,不同的是输出结果为输入文本对应的类型标记.该模型利用子词N-gram信息,获得字符之间的顺序关系,以便更好地捕捉单词内部的语义信息,特别是在处理大数据时,能更准确地对生僻词和词的变形进行向量表示.Fasttext在保持分类效果的前提下,采用线性分类并在输出层使用层次Softmax和负采样技术,加快了训练速度,缩短了训练时间,常应用于情感分析[16]、拦截垃圾邮件[17]和文档语言识别等方面.
1.3 GloVe模型
词向量生成模型GloVe[18]通过构建单词上下文的共现矩阵,计算词间的共现比率,再建立词与共现比率之间的映射关系,得到GloVe的模型函数,用加权平方差作为损失函数,通过AdaGrad优化算法学习生成词向量.GloVe模型广泛应用于命名实体识别[19]、情感分类[20]和区别相似词[21]等问题中.
1.4 ELMo模型
基于Bi-LSTM的语言模型ELMo[22]包含前向语言模型和后向语言模型.前向语言模型根据前面的词汇预测当前词的概率,后向语言模型根据后面的词汇预测当前词的概率,通过最大化前向和后向语言模型的对数概率得到当前词的预测概率.该模型包含两层Bi-LSTM,第一层主要嵌入词的语法结构信息,第二层主要嵌入句子的语义信息.ELMo能根据不同的上下文场景生成不同的词向量,有效解决了一词多义的问题.ELMo模型在情感分析[23]、命名实体识别[24]及文本分类[25]等方面性能优异.
1.5 BERT模型
BERT模型[26]是由MLM(MASKed language model)和NSP(next sentence prediction)构成的深度双向Transformer语言模型.MLM以15%的概率用[MASK]随机对训练序列中的标记进行替换,其中80%的标记被替换为[MASK],10%的标记被随机替换,10%的标记保持不变,根据所给的标记学习被替换的词.NSP是一个二分类任务,主要判断两个语句中的其中一条语句是否是另一条语句的下一句.训练数据中50%的数据从真实的上下文中抽取,剩余的50%数据从语料库中随机选择用于加深学习其中的相关性.MLM能抽取标记层次的表征,但不能直接获取句子层次的表征,NSP能帮助理解句子间的关系进行预测.因此BERT模型在解决句子或段落的匹配、句间关系、理解深层语义特征等任务中效果显著,如知识图谱补全[27]、问答任务[28]、阅读理解[29-30]、文本分类[31]和关系抽取[32]等.
表1列出了各词向量模型的特点及其在漏洞检测方面的应用程度.

表1 各词向量模型的特点及其应用程度
2 词向量模型在漏洞检测上的应用
词向量模型在各自然语言处理任务中均有不同程度的应用,效果也较好.在漏洞检测方面,Word2vec作为早期的词向量模型被广泛应用,Fasttext和BERT模型应用较少,GloVe和ELMo模型尚未发现应用于漏洞检测方面.
2.1 Word2vec模型在漏洞检测上的应用
Word2vec模型将源代码转化为向量作为神经网络的输入,由于生成的词向量维数少、速度快、通用性强被广泛应用于漏洞检测中.
Russell等[6]使用Word2vec词向量模型,将CNN(convolutional neural networks)结合RF(random forest)实现代码漏洞检测.实验结果表明,将源代码通过神经网络训练生成的特征向量作为随机森林分类器的输入比单独使用神经网络在漏洞检测上的效果更好,在准确率、精确率及F1值上均有约2%~3%的提升.Fidalgo等[33]使用Word2vec模型对PHP语言的代码进行向量表示,应用LSTM进行代码漏洞预测.LSTM模型有助于理解代码之间的语法和语义信息,可更好地处理序列化的文本信息,准确率和召回率均达95%以上.文献[7-8,34-38]采用Word2vec作为词向量模型,将C/C++语言的源代码转换为向量,使用不同的神经网络模型进行漏洞检测.其中,Zou等[34]提出了多类别的深度学习漏洞检测系统,同时提供了用于测评漏洞系统的标准检测数据集.文献[7-8,35-36]分别采用抽象语法树、最小中间表征以及代码段表征等技术对源代码进行预处理,通过Bi-LSTM捕捉上下文语义关系检测漏洞,实验结果的准确率均有不同程度提升.Li等[37]为更好地学习漏洞特征采用了Bi-GRU代替Bi-LSTM,比其他神经网络模型更有效.Xu等[38]提出了使用基于上下文的长短期记忆神经网络模型对源代码进行漏洞检测,该模型性能比CNN和LSTM模型更好,准确率可达96.71%,F1值最高为97%.
Zhou等[39]提出了基于图神经网络的漏洞检测模型.该模型将源代码转换为抽象语法树,结合不同层次间的程序控制和数据依赖关系,形成具有全面程序语义结构的联合图.通过Word2vec对代码进行编码,采用Bi-GRU模型学习节点嵌入.该模型检测漏洞的准确率提高10.51%,F1值提高8.68%.
2.2 Fasttext模型在漏洞检测上的应用
Alenezi等[40]通过Fasttext模型训练后得到词向量,采用DNN模型从输入向量中学习更深层的隐藏特征并进行漏洞检测.实验结果表明,该方法的效果及性能较好,在不同的数据集上,最好实验结果达到准确率98.6%,召回率98.6%,F1值为98.55%.
Fasttext模型与Word2vec模型相比,更注重词语内部的形态,有助于模型对低频词和集外词更好地表示.由于Fasttext模型需要提取子词与词本身的特征,因此随着语料库的增加,内存需求也不断增加,严重影响了模型的构建速度,从而限制了Fasttext模型在漏洞检测问题上的应用.
2.3 BERT模型在漏洞检测上的应用
Ziems等[41]采用SARD作为数据集,通过BERT模型使代码具有更深层的语义表征,分别使用了LSTM和Bi-LSTM神经网络进行训练,实验准确率为93%.实验结果显示,Bi-LSTM模型的准确率并没有在LSTM模型的基础上有所提升.原因在于BERT是基于双向Transformer的结构,多一层双向机制并不能提取更有益的信息.目前BERT模型在漏洞检测方面的应用较少.
3 实验设计
本文使用手动收集的真实漏洞数据集进行实验,主要包括4个阶段: 1) 数据预处理;2) 利用CodeSensor解析器提取源代码的语法和语义信息,生成对应的抽象语法树;3) 通过预训练的词向量模型将序列化的抽象语法树向量化;4) 使用神经网络对漏洞表征进行学习,检测漏洞函数.实验设计的整体框架如图1所示.
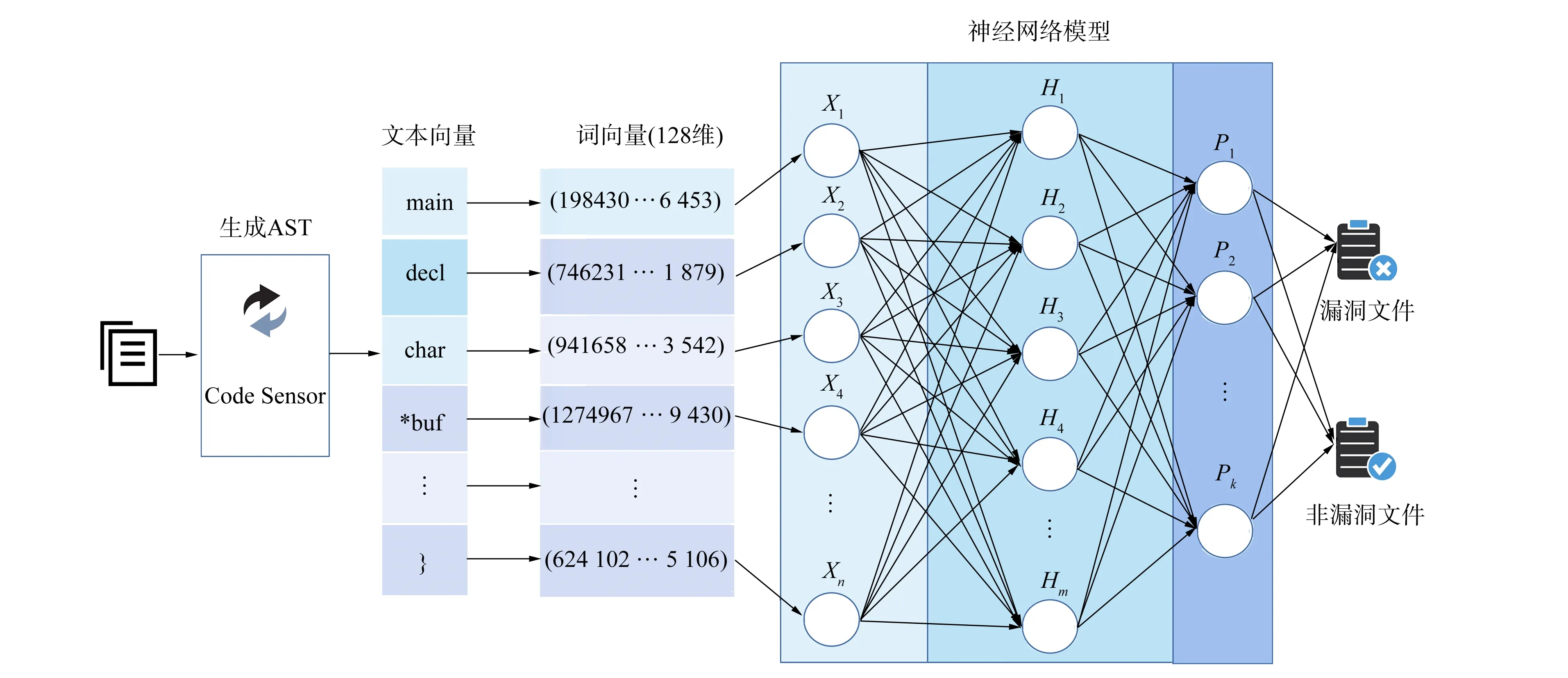
图1 漏洞检测整体框架Fig.1 Overall framework of vulnerability detection

图2 示例代码Fig.2 Example code

图3 代码的抽象语法树Fig.3 Abstract syntax tree of code
3.1 数据预处理
本文将数据集按6∶2∶2的比例划分为训练集、验证集和测试集.为从数据中去除不必要的噪声,删除了函数中所有的注释与常见的停用词,如空格、换行和制表符等.
3.2 生成抽象语法树
抽象语法树是常见的代码表征方式,用于代码基本结构和语法语义的中间表示.本文将如图2所示的源代码输入到CodeSensor解析器中,经过解析输出如图3所示对应的抽象语法树.代码被解析为函数声明、代码块、语句等不同类型的节点,其中内部节点表示运算符及节点类型,叶节点表示操作符,有向边表示节点间的层次关系.
3.3 向量化
考虑到树的层次结构,本文使用深度优先遍历算法将抽象语法树中的节点用文本向量的形式进行表示,向量中元素的顺序反映了抽象语法树中节点的层次关系,图3的抽象语法树转换为文本向量如下: (main,decl,char,*buf,assign,buf,=,express,(char*),call,malloc,arg,BUFSIZE,if,pred,call,…).
将所得的文本向量通过词向量模型生成128维向量,作为神经网络模型的输入.词向量转换过程中,本文分别使用Word2vec,Fasttext,GloVe,ELMo和BERT词向量模型进行实验,以检验哪种词向量模型更适用于漏洞检测.
3.4 训练及测试
本文分别使用DNN,GRU,LSTM,Bi-GRU,Bi-LSTM和Text-CNN神经网络模型对数据进行训练,根据训练后的模型结果不断调整迭代次数、学习率、损失函数和激活函数等参数,保留效果最好的模型进行测试.在相同实验条件下,将各词向量模型结合神经网络模型对真实数据集中的数据进行漏洞检测,以获得实验效果最好的词向量模型和神经网络模型.
4 实 验
4.1 数据集
采用文献[42]提供的数据集,该数据集是从NVD网站中手动收集的C语言函数,共包含9个开源项目: Asterisk,FFmpeg,HTTPD,LibPNG,LibTIFF,OpenSSL,Pidgin,VLC Player和Xen.收集函数数据60 768个,其中漏洞函数1 471个,非漏洞函数59 297个.本文已将漏洞数据集和源代码开源到GitHub(https://github.com/ithicker/MWEMVD)上.为能获得准确的检测结果,保证数据的均衡性,将9个项目均以6∶2∶2的比例划分为训练集、验证集和测试集.
4.2 实验环境及参数配置
实验在Ubuntu Linux系统上运行,硬件配置为处理器IntelXeon(R) Silver 4210 2.2 GHz,内存78 GB,GPU Quadro P2200,硬盘1.3 TB.软件分别使用Keras 2.2.4,TensorFlow 1.12.0,Keras 2.3.1和TensorFlow 1.15.0.词向量模型及配置环境列于表2.

表2 词向量模型及配置环境
4.3 结果处理
为能准确地衡量神经网络模型在漏洞检测上的效果,实验以精确度和召回率为评估指标.精确度是指正确预测为漏洞的函数占全部预测正确函数(漏洞函数和非漏洞函数之和)的比例;召回率是指正确预测为漏洞的函数占全部漏洞函数的比例.由数据集特征可见,漏洞函数和非漏洞函数占比不均衡,非漏洞函数数量远多于漏洞函数数量,从而导致无法准确判断.为解决该问题,本文对神经网络模型输出结果的权重(预测为漏洞函数的可能性)从高到低排序,求取前k个值(Top-k)计算精确度和召回率,精确度和召回率公式表示如下:
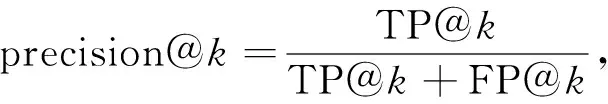
(1)
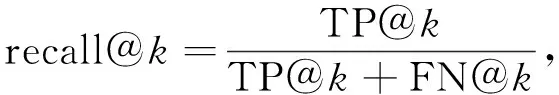
(2)
其中TP@k表示检测前k个函数正确预测为漏洞的函数数量,FP@k表示检测前k个函数错误预测为漏洞的函数数量,FN@k表示检测前k个函数未被预测为漏洞的函数数量.
4.4 结果分析
对于高级程序设计语言,代码漏洞通常是由于多行代码间存在的逻辑关系产生的问题,漏洞代码段与前文或后文的代码有关,因此上下文信息对代码漏洞检测十分重要.函数级别的代码通常由多个if-else条件分支语句及for和while等循环语句构成,但条件分支语句和循环语句代码块相对独立,代码块内的语句相互之间存在上下文语义关系,而代码块与代码块之间虽有关联但并不紧密.表3列出了实验结果.
从词向量方面分析表3的实验结果得出如下结论: Word2vec模型能表征浅层语义关系,通过滑动窗口处理代码段能抓住程序的局部特征,应用于漏洞检测总体效果相对较好;Fasttext模型在RNN上实验效果与Word2vec模型相近,其原因在于两个模型的原理相似,Fasttext模型更注重单词内部的形式,而代码更注重单词之间的语义关系,因此在DNN与Text-CNN上的实验效果不如Word2vec模型;Glove模型通过共现矩阵统计单词共现比率计算词向量,不仅增加了模型的计算量,且易误导词向量的整体训练方向,因此整体效果较差;ELMo模型在循环神经网络中实验效果差异较小,归因于ELMo是以Bi-LSTM构建生成的词向量模型,双层循环神经网络对漏洞检测并无太大影响.Word2vec,Fasttext,Glove和ELMo模型在Text-CNN神经网络上漏洞检测效果最好.BERT模型能通过上下文抽取代码特征,在循环神经网络上实验效果较好,由于BERT是双向Transformer模型,因此其实验结果在LSTM和Bi-LSTM神经网络上无明显差异,这种现象与文献[41]中分析得到的结论相符.由于BERT模型适用于处理长距离依赖关系的文本,而漏洞检测需要处理短距离文本代码块,因此实验效果并非最好.
从神经网络方面分析表3的实验结果得出如下结论: 循环神经网络模型能捕捉代码之间的依赖关系,因此在代码漏洞检测方面效果好于DNN模型,但由于代码之间并没有长距离的上下文依赖关系,因此使用循环神经网络并未能取得最好的实验效果;Text-CNN模型通过卷积层的局部窗口学习代码的局部特征,通过池化层将各代码块的局部特征整合形成复杂抽象的特征,使模型更注重代码块内的关系,而不过分关注代码块间的联系,因此Text-CNN模型在神经网络中效果最佳.
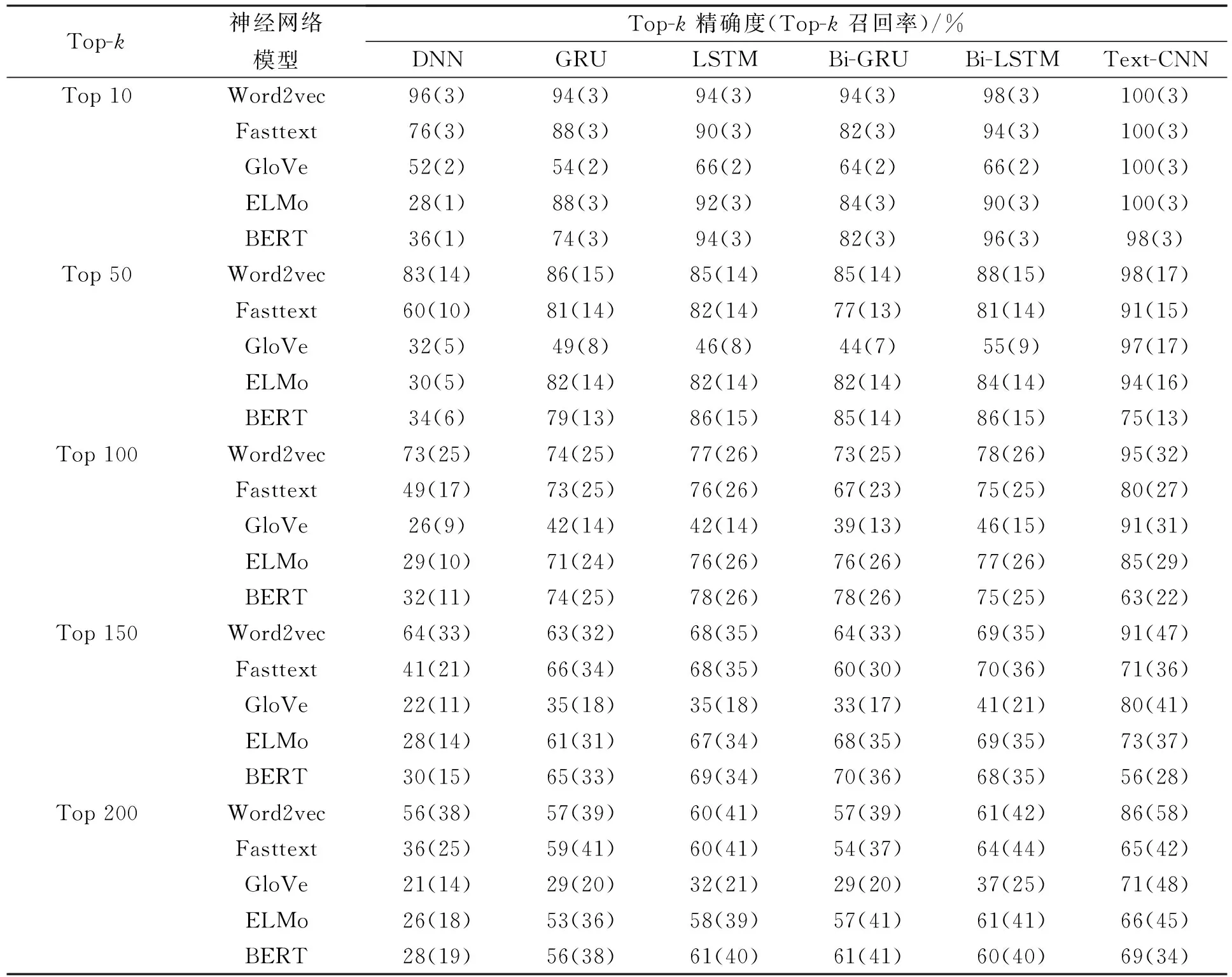
表3 实验结果
根据漏洞代码的特点及实验结果综合分析可知,使用Word2vec作为词向量模型并结合Text-CNN模型检测代码漏洞的效果最好.
综上所述,本文在介绍了各词向量模型的基本原理和词向量模型在漏洞检测方面的应用后,将各词向量模型结合神经网络模型在相同实验条件下进行了漏洞检测,并分析了实验结果.对于函数级别的漏洞,代码之间存在着上下文关联而代码块之间的联系并不紧密,因此代码之间属于浅层的语义关系.在5个词向量模型中,Word2vec模型具有简单的模型结构,对于描述浅层的语义关系效果相对较好;在6个神经网络模型中,Text-CNN模型对文本浅层特征的抽取能力强.实验结果表明,Word2vec词向量模型结合Text-CNN神经网络检测代码漏洞的效果最佳.
