融入词性自注意力机制的方面级情感分类方法
2023-11-24杜孟洋王红斌普祥和
杜孟洋,王红斌,普祥和
(昆明理工大学 信息工程与自动化学院,昆明 650504;昆明理工大学 云南省人工智能重点实验室,昆明 650504;昆明理工大学 云南省计算机技术应用重点实验室,昆明 650504)
0 引 言
方面级情感分类(aspect-level sentiment classification,ASC)是情感分析的一个细粒度子任务[1-2],目的是确定给定句子或评论中每个方面实体的情感极性(消极、中性或积极).例如,餐馆数据集中的一条评论“The price is reasonable although the service is poor.”,price和service是评论中的两个方面实体即方面词,reasonable和poor是描述这两个方面实体的观点词.该评论表达了对价格方面的积极情感,但也传达了对服务方面的消极情感.
方面级情感分类技术广泛用于分析各平台的在线帖子及评论,以帮助商品生产商理解消费者的需求或提高消费者对产品体验的能力,指导制造商进行产品改进.ASC比传统的单一句子级情感分类复杂得多,ASC的任务是识别一个句子中多个方面对应的多个情感极性.传统方法大多数使用带有手工特征的浅层机器学习模型构建ASC任务的情感分类器[3-4].但人工特征工程的过程耗时、劳动密集型高,分类性能有限.
近年来,随着深度学习技术的发展,各种基于注意力机制的神经网络模型在ASC任务中取得了显著进展[5-8].但这些方法忽略了句子中方面词与上下文词之间的句法依赖性.如图1所示,标记的边表示句法依赖关系,每个单词下的分数表示由注意力机制分配的权重分数,方括号中的单词为方面词.在该句子中有两个具有不同情感极性的方面词falafel和chicken.对于chicken,基于注意力机制的模型错误地将高注意力权重分配给单词but和dried,导致模型预测错误.因此,当前的注意力模型可能会错误地关注语法上不相关的上下文词,表明基于注意力机制的模型在方面级情感分类任务中具有局限性.例如,如果模型在这个句子中学习到chicken和fine之间直接的句法依赖关系,而不是与but之间有直接依赖关系,则情况可能会不同.

图1 方面、注意力和语法之间的关系示例Fig.1 Example of relationship between aspect,attention,syntax
为利用单词之间的句法依赖关系,Zhang等[9]在依赖关系树上构建了一个图卷积网络(graph convolutional networks,GCN),但仍存在一些局限性: 1) 该模型忽略了句子中的词性信息,因此不能很好地学习到方面词及与该方面词有关联的单词的词性信息;2) 该模型未考虑建立方面词与观点词之间的联系,即未利用词性信息充分学习单词间的句法依赖关系;3) 预测一个方面实体的情感极性需要对该方面有用单词的情感进行综合考虑,但该模型未考虑用词情感的结合表示方面词的情感.例如,评论“The price is reasonable although the service is poor.”中,能表示price和service这两个方面实体的情感分别应该是reasonable和poor这两个单词的情感,而不仅是方面实体向量的表示.因此,这些局限导致模型的性能欠佳.
针对上述不足,本文通过对大量的评论数据进行分析,发现一个句子中的方面实体一般都为名词词性,表示方面词情感的单词即观点词一般多为形容词词性或副词词性,且名词与形容词或副词修饰词之间有一定的句法依赖关系.因此,通过分析本文提出一种融入词性自注意力机制的方面级情感分类方法.该方法首先在句子向量嵌入的同时考虑融入句子的词性嵌入向量,使模型能更准确地学习句子中关键单词的词性信息,如方面词和观点词的词性信息;其次,为充分利用单词之间的句法依赖关系,在句子的词性嵌入向量上利用自注意力机制使模型学习到单词词性之间的句法依赖关系,然后将其融入句子嵌入向量中,使模型能学习到方面词与该方面词相关上下文单词的语法信息以及它们之间的依赖关系;最后,计算出句子中每个单词的情感分数,通过聚合单词情感获得特定方面实体的情感.
1 相关工作
ASC是情感分析的一个重要分支,旨在识别句子中每个方面实体的情感极性.方面级情感分类本质上属于自然语言处理(natural language processing,NLP)领域的分类问题.传统方法首先会定义情感词典[10]、语法规则等一系列特征,然后采用支持向量机(support vector machine,SVM)[3]、朴素Bayes[11]等分类器进行分类.这种方法虽然在特定领域性能良好,但通常需要耗费大量的人工成本.与传统机器学习方法相比,深度学习方法在方面级情感分类上性能更好.卷积神经网络(convolutional neural networks,CNN)[12-13]在捕获句子中潜在的语义信息方面性能良好.与CNN相比,循环神经网络(recurrent neural network,RNN)[14]可以捕获句子间的上下文依赖关系,对给定方面与上下文单词之间的相关性进行建模,有利于对特定方面的情感极性进行分类.因此,RNN广泛应用于方面级情感分类任务中.
方面词的情感极性通常由方面词周围的上下文单词确定,由于RNN无法准确计算给定方面词周围的每个单词对情感分类的重要性,于是引入了注意力机制有效捕捉上下文单词相对于给定方面词的重要性,因此,现有模型主要将RNN和注意力机制相结合以实现方面级情感分类[5-6,15-17].Ma等[5]利用长短期记忆网络(long short-term memory,LSTM)和注意力机制交互学习方面及其上下文单词的注意力权重,以获得每个方面及其上下文的精确表示,从而有效区分句子中不同方面的情感极性;Qiu等[6]先利用双向门控循环单元(BiGRU)网络对句子进行编码,然后通过自注意力机制对句子和表情符号的向量表示进行特征提取,以提高分类精度;Song等[18]提出注意力编码器网络(attentional encoder network,AEN),采用多头注意力建模方面词与上下文的关系.尽管基于注意力机制方法已经在ASC任务中取得了良好的性能,但由于缺乏对句法信息的利用,当句子成分较复杂或句中存在多个方面词时,很难对目标方面词的情感极性做出准确判断.因此一些研究者将图卷积网络(GCN)应用到ASC任务中以克服这种限制.Zhang等[9]提出了在句子依赖树上使用GCN为方面级情感分类任务挖掘句法信息,利用了单词之间的语法信息和依赖关系;Zhou等[19]使用外部构造的知识图谱嵌入与句法依存关系,利用两种不同结构的GCN得到了上下文词节点与给定方面词之间的语义关系;Li等[20]提出了一种Dual GCN模型分析一个给定句子的语义信息和句法结构,还提出了一种正交正则化以及差分正则化获得更好的语义表示;Zhong等[21]从多个不同的角度捕捉情感特征表示,其中一个角度利用GCN提取句子的语法特征学习特定方面的表示向量,获得基于语法的特征表示向量;Xu等[22]提出了一种混合图卷积网络(HGCN)合成自成分树(由句子的短语构成)和依赖树的信息,探索了连接两种语法解析树的方法,以丰富句子的表示.
虽然方面级情感分类任务目前已经取得了较大进展,但现有的方面级情感分类方法未考虑到句子中的词性信息,从而不能利用词性信息充分学习单词间的句法依赖关系,导致模型的性能不理想.因此,本文使用词性嵌入层获取词性信息,通过词性信息模型能更准确地判断方面词和观点词,并利用自注意力编码层学习方面词与观点词之间的句法依赖关系,同时利用GCN学习更深层的语法信息和远程词间(句子中距离相对较远的单词)的依赖关系,最后利用单词情感分数层对方面词进行情感分类.
2 模型结构
本文模型的总体框架如图2所示.由图2可见,该模型主要包含单词嵌入层、词性嵌入层、自注意力编码层、全连接层、双向LSTM层、图卷积网络层、特定方面的特征表示层、注意力机制层、单词情感分数层、情感预测层等模块.

图2 模型总体框架Fig.2 Overall framework of model
2.1 单词嵌入层
给定一个由n个单词组成的句子,句子表示为W={w1,w2,…,wτ+1,…,wτ+m,…,wn-1,wn},句子中包含一个从(τ+1)标记开始的由m个单词组成的方面实体,wi表示句子中第i个单词.每个单词通过嵌入矩阵E∈|v|×d嵌入到一个低维实值向量空间[23],其中|v|表示词汇表的大小,d表示单词嵌入的维度,则得到的句子嵌入向量用T∈n×d表示为

(1)

2.2 词性嵌入层和自注意力编码层
使用Stanford NLP词性标注工具[24]得到输入句子的词性标注序列,例如,评论“The price is reasonable although the service is poor.”词性转换后句子中每个单词对应的词性表示为“[(‘The’,‘DT’),(‘price’,‘NN’),(‘is’,‘VBZ’),(‘reasonable’,‘JJ’),(‘although’,‘IN’),(‘the’,‘DT’),(‘service’,‘NN’),(‘is’,‘VBZ’),(‘poor’,‘JJ’),(‘.’,‘.’)] ”.随机初始化一个词性嵌入矩阵Epos∈|s|×d,其中|s|表示随机初始化的词汇表大小,d表示词性嵌入的维度,本文设置其与上文单词的嵌入维度相同(300维),由此得到输入句子的词性嵌入向量表示P∈n×d为

(2)

词性嵌入后使用一个自注意力机制层获取词性之间的句法依赖关系,如名词与形容词之间的词性依赖关系.自注意力机制表示为
Att(Q,K,V)=ω(QKT)V,
(3)
其中: Att(Q,K,V)为得到的自注意力值,Q∈nq×dq,K∈nk×dk,V∈nv×dv分别为查询向量矩阵、键向量矩阵和值向量矩阵,这3个矩阵中每行分别表示一个对应的向量,Q,K,V是通过把输入序列P分别乘以3个矩阵Wq,Wk,Wv得到,dq,dk,dv分别为Q,K,V中向量的维度,nq,nk,nv分别为Q,K,V中向量的个数;激活函数ω(·)通常表示为对QKT施加激活函数ω(·)后得到各单词与其上下文单词之间的相似度分布值;ω(QKT)与V∈nv×dv相乘后得到Att(Q,K,V),即值向量的加权和,权值即各单词与其上下文单词之间的相似度分布值.
本文将经过自注意力机制后的词性嵌入向量记为词性自注意力嵌入向量S∈n×d,用公式表示为

(4)

2.3 全连接层和双向LSTM层
为实现更准确的方面级情感分类,需要让模型学习单词之间的句法依赖关系,同时更好地建立方面词与观点词之间的联系.因此,本文将句子向量与经过自注意力机制后的词性向量相融合.即将上文得到的句子嵌入向量T与词性自注意力嵌入向量S做一个拼接操作,将拼接后的向量输入一个全连接层得到向量表示C∈n×d,用公式表示为
C=(T⊕S)W+b,
(5)
其中⊕表示拼接操作,W表示全连接层,b表示偏置矩阵.
将得到的向量C输入BiLSTM层捕获每个单词的上下文信息,得到对应的隐藏层状态向量Hc为
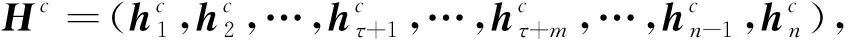
(6)

2.4 依赖关系树上的图卷积网络层
GCN实际上与卷积神经网络(CNN)的作用相同,即一个特征提取器,但它的对象是图数据.对于具有k个节点的给定图,通过枚举该图得到了一个邻接矩阵A∈k×k.为方便,本文将节点i的第l层的输出表示为其中表示节点i的初始状态.Aij为节点i与节点j在邻接矩阵中的表示.对于是节点i的最终状态.在节点表示上操作的图卷积记为

(7)
其中Wl为线性变换权值,bl为偏置项,σ为ReLU非线性函数.
由于图卷积过程只对近邻节点的信息进行编码,因此图中的一个节点只能受L层GCN中L步内相邻节点的影响.这样句子依赖树上的图卷积为句子中的一个方面词提供了语法约束,基于句法距离识别描述性单词即观点词.此外,GCN能处理一个方面词的极性被非连续单词描述的情况,因为依赖树上的GCN可以将描述该方面词的非连续单词收集到更小的范围,并通过图卷积正确地聚合其特征.例如,图1所示的句子中,方面词falafel被两个非连续的观点词cooked和dried描述,这两个单词在句子中与方面词的距离分别为3和5,但基于句法距离这两个单词与方面词的距离分别为1和2,这3个单词的距离被拉近,在GCN的邻接矩阵中它们会被收集到更小的范围内聚合其特征.因此,本文使用GCN学习句法信息与远程词的依赖关系.
注意力机制和CNN对方面词及其上下文词有语义对齐的固有能力,因此被广泛应用于方面级情感分类任务中.但这些模型缺乏一种机制解释相关的句法约束和长期的词依赖性,因此可能会错误地识别出语法无关的上下文词,并将其作为判断方面词情感的关键信息.为解决该问题,本文在句子的依赖关系树上使用一个GCN,使模型能更好地学习句子语法信息与单词间的依赖关系.本文在构造了给定句子的依赖树后,首先根据句子中的单词得到一个邻接矩阵A∈n×n,然后按照文献[25]中的自循环思想,对每个单词都手动设置为相邻,即A的对角值均为1.将BiLSTM的输出向量Hc作为图卷积网络的输入,即H0=Hc,最后用具有归一化因数的图卷积网络更新每个节点的表示,用公式表示为
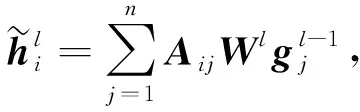
(8)

(9)

(10)


(11)


(12)

(13)
其中qi∈是第i个单词的位置权重.经过L层GCN的最终向量表示为
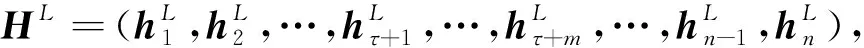
(14)

2.5 特定方面的特征表示层
在该层中,本文屏蔽了非方面词的隐藏状态向量,并保持方面词的状态不变,用公式表示为
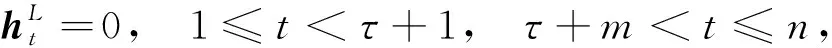
(15)
2.6 注意力机制层
本文使用注意力机制的目的是从BiLSTM输出的隐藏层状态向量中检索与方面词语义相关的重要特征,并据此为每个上下文词设置一个基于检索的注意力权重.注意力权重的计算公式为
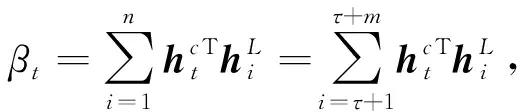
(16)
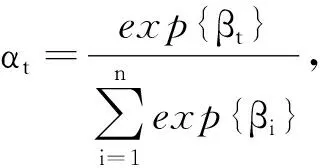
(17)

本文用点积计算句子中每个单词与方面词之间的语义相关性.式(17)最终得到的是每个单词相对于方面词的注意力权重分数.
2.7 单词情感分数层


(18)
其中W1∈2d×2d,W2∈3×2d,b1∈2d,b2∈3均为可学习的参数.
2.8 情感预测层与训练
本文使用注意力机制层得到的注意力权重分数聚合单词的情感分数,最终获得方面实体的情感极性.注意力权重分数得到与方面词相关联的观点词的概率分布,本文用描述方面词的观点词的情感聚合表示该方面实体的情感.方面实体对应的情感极性P计算公式为

(19)
其中pi为第i个单词的情感预测,αi为第i个单词与方面词之间的语义相关性.
该模型采用交叉熵损失和L2正则化的标准梯度下降算法进行训练,用公式表示为

(20)
3 实 验
3.1 实验数据集
本文在以下5个公共数据集上进行实验: TWITTER评论数据集[28],数据集LAP14,REST14,REST15,REST16分别从Semeval2014任务4[29]、SemEval2015任务12[30]和Semeval2016任务5[31]中检索得到,其中包括两种类型的数据,即对笔记本电脑和餐馆的评论.这些数据集中包含了消极、中性和积极3种不同的情感极性,各数据集信息列于表1.
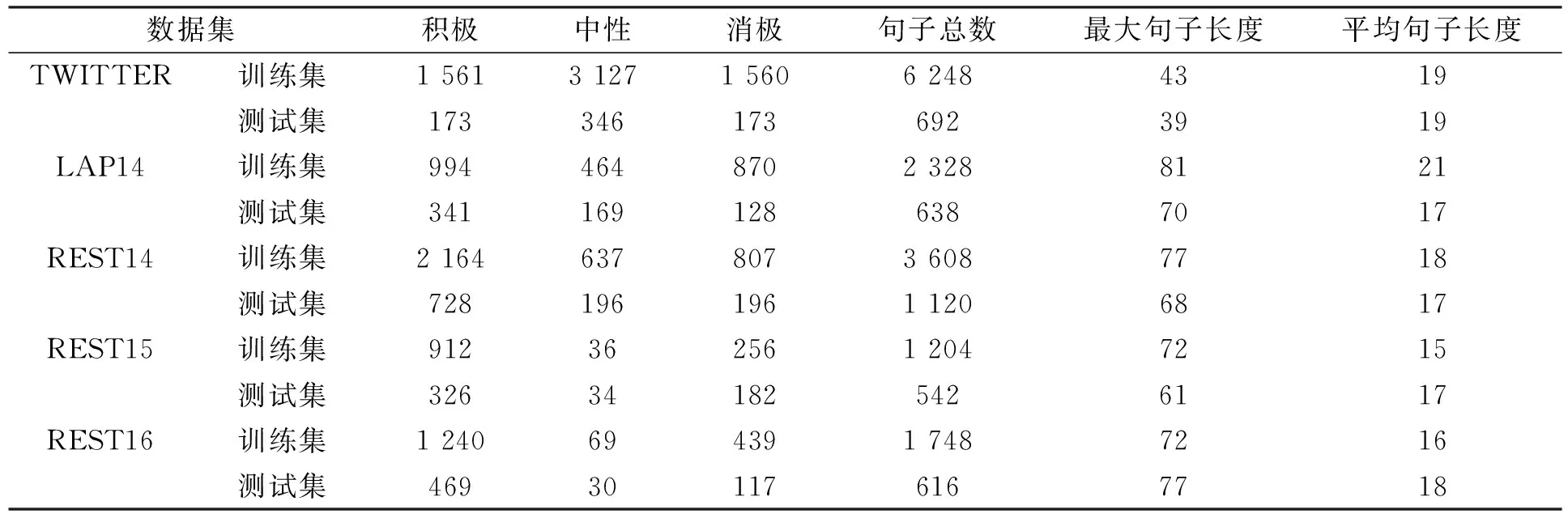
表1 各数据集信息
3.2 实验参数设置
在本文实验中,使用300维预训练的GloVe向量[32]初始化单词嵌入.模型的权值均采用均匀分布进行初始化,隐藏状态向量的维数为300,使用Adam作为优化器,学习率为0.001,L2正则化的系数为105,批处理大小为32,GCN层数设为2.
3.3 评价指标
在模型的性能测试方面,为更好的与基线模型比较,所有实验结果均采用与基线模型相同的计算方法,采用随机初始化方法得到3次实验结果并求平均,使用准确率(ACC)和宏观平均F1分数作为评价指标,计算公式为
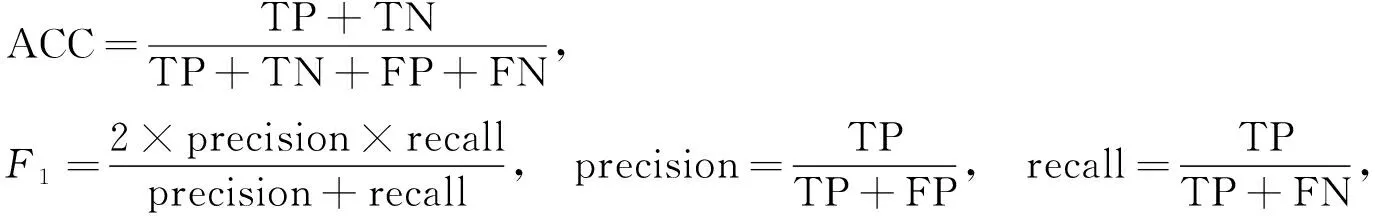
(21)
其中: precision和recall分别表示精确率和召回率;TP表示实际为正、模型预测为正的样本数量;FP表示实际为负、模型预测为正的样本数量;FN表示实际为正、模型预测为负的样本数量;TN表示实际为负、模型预测为负的样本数量.这些指标常用于方面级情感分类任务[19,33]中,准确率越高或F1分数越高,说明预测性能越好.
3.4 对比实验
为全面评价本文模型的性能,选择以下基线模型进行性能对比:
1) LSTM[14],使用LSTM的最后一个隐藏状态向量预测情绪极性;
2) TD-LSTM[14],将方面词嵌入与上下文词嵌入相连接,获得最终的词嵌入表示,然后用LSTM分别对方面词的两侧进行建模,得到隐藏层表示;
3) MemNet[27],将上下文视为外部记忆,并受益于多跳架构;
4) IAN[5],交互式地模拟了各方面及其上下文之间的关系;
5) AOA[34],从机器翻译领域借鉴了过度关注的思想;
6) TNet-LF[35],提出了上下文保护转换(CPT)保存和加强上下文的信息部分;
7) ASGCN[9],通过图卷积神经网络使用外部语法信息,同时获取与方面词相关的语法上下文信息.
3.5 实验结果与分析
本文在5个数据集上进行实验,实验结果列于表2.由表2可见,本文模型(POS+SA+WSS)在数据集TWITTER,LAP14,REST14,REST15,REST16上的准确率和F1分数始终优于所有的基线模型,其中在数据集REST16上的准确率与基线模型最好的效果也持平,表明了本文模型的有效性.本文模型可以有效学习到方面词与该方面词有关联的上下文单词的语法信息及其依赖关系,进而捕获到对情感分类具有重要意义的观点词的信息,从而提高方面情感分类器的性能.
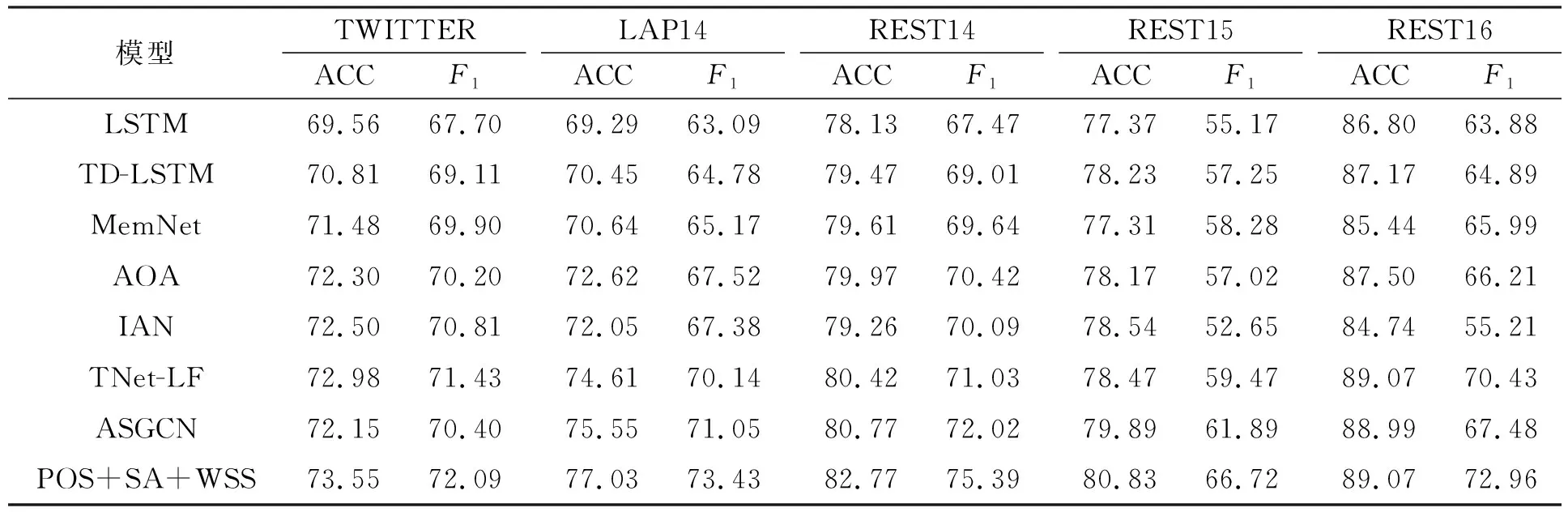
表2 不同模型的比较结果
与基线模型相比,在数据集TWITTER,LAP14,REST14,REST15,REST16上,本文模型的F1分数与基线模型最好的效果相比分别提高了0.66%,2.38%,3.37%,4.83%,2.53%,表明除数据集TWITTER,本文模型在其他4个数据集上的F1值均有明显提升,说明这4个数据集上的句子语法结构比数据集TWITTER上的句子更复杂.其中在数据集REST15上F1分数的提高最多,可达4.83%,说明数据集REST15上的句子语法结构比其他4个数据集上的句子更复杂.同样,在准确率指标上,本文模型在数据集TWITTER,LAP14,REST14,REST15上均有明显提升,分别比基线模型最好的效果提升了0.57%,1.48%,2%,0.94%,且在数据集REST16上的准确率也与基线模型达到了持平的效果.
3.6 消融实验
为验证本文提出的词性嵌入层(part-of-speech embedding layer,POS)、自注意力编码层(self-attention encoding layer,SA)、单词情感分数层(word sentiment score layers,WSS)的有效性,进行消融实验.以句子嵌入层、双向LSTM层、图卷积网络层、特定方面的特征表示层、注意力机制层为基准(Base),Base加上词性嵌入层记为POS,POS加上自注意力编码层记为POS+SA,POS+SA加上单词情感分数层记为 POS+SA+WSS.实验结果列于表3.

表3 消融实验结果
下面从单词情感分数层的有效性、自注意力编码层的有效性和词性嵌入层的有效性3个方面进行消融实验结果分析.
1) 单词情感分数层的有效性.去除单词情感分数层(POS+SA),由表3可见,与本文的最终模型相比,在数据集TWITTER,REST14,REST15,REST16上的F1值分别下降了0.52%,0.98%,1.9%,1.28%;在数据集LAP14上的准确率和F1分数变化均较小,表明模型在数据集TWITTER,REST14,REST15,REST16上能更准地学习到单词的情感分数,也说明该数据集上的方面词对应的观点词即情感词大多数由一个单词组成.
2) 自注意力编码层的有效性.去除自注意力编码(POS+WSS),由表3可见,去除后的模型在所有数据集上仍比基线模型高,但与本文的最终模型相比却均有下降,说明本文的自注意力编码层有用.与本文的最终模型相比,在数据集TWITTER,LAP14,REST14,REST15,REST16上的准确率分别降低了0.86%,0.65%,0.69%,1.8%,0.97%,F1分数分别降低了1.12%,0.85%,1.73%,5.04%,2.45%,可见在数据集REST15上的下降较多,原因是数据集REST15中词性嵌入的语法信息较重要,词性嵌入层之上使用一个自注意力编码层能更容易学习到方面词与观点词之间的联系.
3) 词性嵌入层的有效性.当去除自注意力编码层和单词情感分数层(POS)时,相当于只看词性嵌入层的影响,由表3可见,虽比本文的最终模型有所下降,但此时的模型已经比基线模型在准确率和F1分数两个指标上都有提升,准确率最高提升1.55%,F1分数最高提升2.03%,只有在数据集TWITTER上的准确率和F1分数没有明显提升.由于数据集TWITTER上评论杂乱且包含的隐式方面实体较多,因此词性标注并未表现出明显效果.
上述消融实验的结果表明了本文模型的有效性.
3.7 可视化
从数据集REST15中随机选择一个句子“The food is great and the environment is even better.”,对该句子进行单词情感分数的可视化,结果如图3所示.

图3 单词情感分数可视化Fig.3 Visualization of word sentiment scores
图3表示模型学到的每个单词对应情感分数的分布情况.这句话中两个方面词food和environment对应的情感极性均为积极.由分析可得food的观点词为great,其表示的情感是积极的;同理,environment对应的观点词为even better,其情感极性很明显也是积极的.由可视化结果得出模型学习到的情感分数中方面词food及其对应的观点词great均是积极的占比最大,方面词environment及其对应的观点词even better的情感分数也是积极的占比最大,除方面词及与之对应的观点词外,模型学习到的其他单词的情感分数均为中性占比最大,可见模型能准确学习到这句话中每个单词的情感分数,也能准确学习到与方面词有关联的观点词的信息,并能准确判断出其情感极性,验证了单词情感分数层的有效性.
综上所述,针对现有基于注意力机制模型在方面级情感分类问题上忽略了单词的词性信息,不能充分利用句子的语法依赖信息,并且现有方法大多数都是用生成词表示向量预测情感极性,忽略了对方面有用的情感词综合考虑的问题,本文提出了一种融入词性自注意力机制的方面级情感分类方法.该方法首先通过学习句子中单词的词性以及单词之间的句法依赖关系捕获方面词与观点词之间的句法依赖关系;然后利用GCN更深层地学习句法信息与远程词的依赖关系,从而提升模型的整体性能;最后通过聚合句子中与方面实体有关联单词的情感预测句子中特定方面的情感极性.实验结果表明,本文方法在方面级情感分类任务上优于对比方法.
