一种基于MLP的高效高精度三维视线估计方法
2023-11-17吴志豪张德军吴亦奇陈壹林
吴志豪,张德军,吴亦奇,陈壹林
(1.中国地质大学(武汉)计算机学院,湖北 武汉 430078; 2.智能机器人湖北省重点实验室(武汉工程大学),湖北 武汉 430205)
1 引言
视线是最重要的非言语交际线索之一,它包含丰富的人类意图信息,使研究人员能够深入了解人类的认知和行为,已被广泛应用于医疗[1]、辅助驾驶[2]、市场营销[3]和人机交互[4]等领域。高精度的视线估计方法对其应用至关重要。为此,研究人员针对视线估计展开了大量研究。根据不同的场景,视线估计方法分为3类:二维注视点估计[5]、注视目标估计[6]和三维视线估计[7-19]。二维注视点估计根据输入的图像估计出视线聚焦的落点。注视目标估计是要检测出输入人物的注视对象。三维视线估计方法是通过双眼图像或人脸图像估计出三维视线方向。本文旨在设计一个高效高精度的三维视线估计方法。
三维视线估计方法主要分为基于几何的方法和基于表观的方法2大类。基于几何的方法通过检测眼睛的眼角、虹膜位置等关键点估算三维视线[7],然而这类方法对图像分辨率要求较高。因此,基于表观的方法受到研究人员更多的关注。基于表观的方法直接学习一个将图像表观映射到三维视线的模型,在低分辨率和高噪声的图像上表现更好。
近年来,基于表观的深度学习三维视线估计方法成为研究热点。与传统的基于表观的三维视线估计方法[8-11]相比,基于表观的深度学习三维视线估计方法显示出了许多优势:(1)它能够从图像中提取出高层次的抽象三维视线特征。(2)它能够学习从眼睛表观到三维视线的非线性映射函数。这些优点使得它比传统方法更加健壮和精确。随着卷积神经网络CNN(Convolutional Neural Network)在计算机视觉领域的崛起,以及大量数据集的公开,研究人员开始将CNN用于基于表观的三维视线估计方法[12-19]。由于CNN结构复杂、模型加载速度不够快等原因,这类方法在实时性要求较高的场合还有待进一步改进。Tolstikhin等[20]提出的MLP-Mixer(MultiLayer Perceptron Mixer)给计算机视觉领域带来了新的选择。MLP-Mixer是一种仅基于多层感知机MLP(MultiLayer Perceptron)的深度学习模型,结构更为简单、模型加载速度也快于CNN和Transformer模型的,但性能与CNN和Transformer模型的相当。
本文提出一种基于MLP的高效高精度的视线估计方法UM-Net(Using MLP Network)。UM-Net包括3条支路,利用MLP模型分别对人脸图像、左眼图像和右眼图像进行特征提取,对得到的特征进行融合后回归出三维视线。实验结果表明,对MPIIFaceGaze数据集和EyeDiap数据集中包含的31位不同相貌的受试者使用UM-Net进行视线估计,其精度比肩基于CNN方法的,甚至在某些受试者上的精度表现更好,并且在视线估计的速度上具有明显的优势。
2 相关工作
2.1 基于表观的三维视线估计
Zhang等[12]最早利用神经网络来进行视线估计。他们提出用CNN对输入的单眼图像进行特征提取,然后将头部姿态信息与提取出的眼睛特征进行拼接,回归出相机坐标系下的三维视线。Cheng等[13]提出了一个基于双眼图像的非对称回归视线估计方法,主要思想是由于光照等原因2只眼睛的视线估计精度不同,因此网络在训练中对2只眼睛对应的损失函数赋予不同的权重。基于几何的方法是通过检测眼睛关键点特征信息来估计三维视线的。这启发了研究人员使用额外的语义信息来提高视线估计的精度。Park等[14]提出了一种基于眼睛图形表示的视线估计方法,通过神经网络将眼睛抽象为一个由视线真实值几何反推出的眼球图形表示来提升视线估计精度。Yu等[15]提出了一种基于约束模型的视线估计方法,基于多任务学习的思想,即在估计视线的同时检测眼睛关键点信息,2个任务同时进行训练和信息交流,在一定程度上得到了共同提高。
上述视线估计方法都需要以单眼/双眼图像为输入,这存在2个不足:需要额外的模块检测眼睛区域;需要额外的模块估计头部姿态信息。因此,Zhang等[16]提出了基于注意力机制的全脸视线估计方法,其主要思想是通过一条支路学习人脸区域各位置的权重,目标是增大双眼区域的权重,抑制其他与视线无关区域的权重,网络的输入为人脸图像并采用端到端的方式直接学习出相机坐标系下的三维视线。Zhu等[17]也提出了一个全脸视线估计的方法,与上述方法不同之处在于除人脸输入外,该方法同时需要输入眼睛图像。Zhu等认为文献[12]将视线特征与头部姿态简单拼接的方式并不能准确地反映两者之间的几何关系,因此该方法利用一个视线的几何变换层将人脸支路学习到的头部姿态信息与眼睛支路学习到的人脸坐标系下的视线进行几何分析,得到最终相机坐标系下的三维视线。
为了进一步提高三维视线估计的准确性,Chen等[18]提出了空洞卷积网络Dilated-Net,使用空洞卷积对人脸和双眼进行特征提取,通过使用深度神经网络从眼睛图像中提取更高分辨率的特征来提高基于表观的三维视线估计的准确性。Cheng等[19]为了减少与视线无关因素的干扰,提出了一个即插即用的自对抗框架实现视线特征的简化,降低光照、个人外貌甚至面部表情对视线估计的学习的影响。
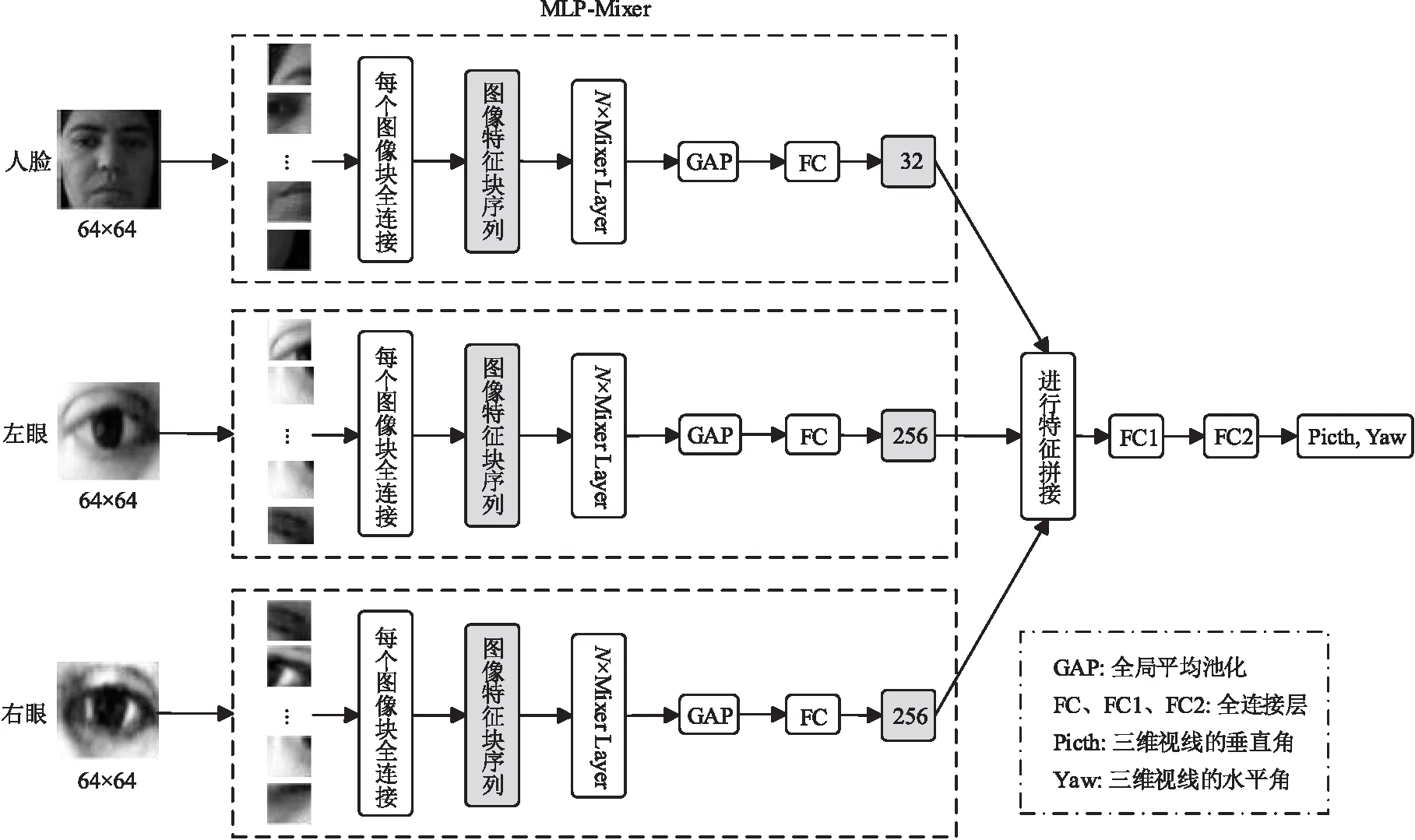
Figure 1 The proposed UM-Net method图1 本文提出的UM-Net方法
2.2 MLP模型
目前,CNN已成为计算机视觉领域的首选模型。但是,近年来兴起的Vision Transformer[21]提供了新的思路,该方法对输入的图像进行分块并展平为序列,然后将其输入到Transformer模型的编码器部分,紧接着在全连接层进行图像分类,实验结果表明该方法性能优异。该研究表明将深度神经网络直接应用于图像块序列时,Transformer模型也能很好地执行图像分类任务。
另外,Tolstikhin等[20]也提出了一种区别于CNN和Transformer的新模型MLP-Mixer。MLP-Mixer是一种极具竞争力且概念与技术简单新颖的模型,它无需卷积与自注意力,仅依赖MLP进行图像处理工作。MLP-Mixer包含2种类型的模块:一种是独立作用于图像块的MLP,即用于融合每个图像块位置的特征信息;另一种是跨图像块作用的MLP,即用于融合图像序列空间信息。与CNN、Transformer等相比,MLP-Mixer的性能并不是最优的,但MLP-Mixer在仅使用结构更为简单的MLP的条件下,不仅取得了与当前最佳CNN和Transformer模型相当的性能,模型加载速度也快于CNN和Transformer模型的,可见其适用于视线估计这个强调精度也重视速度的领域。
3 本文方法
基于表观的视线估计面临许多挑战,例如头部运动和主体差异,尤其在无约束环境中时,这些因素对眼睛表观有很大影响,并使眼睛表观复杂化。传统的基于表观的视线估计方法拟合能力较弱,无法很好地应对这些挑战。神经网络在视线估计中展现出了良好性能。不同于其他的方法使用CNN,本文提出的UM-Net使用结构更为简单的MLP模型进行视线估计。如图1所示,UM-Net采用3条支路分别对左眼图像、右眼图像和人脸图像进行特征提取,然后对提取到的特征进行拼接,最后利用2个全连接层回归出三维视线方向。接下来,本节将详细介绍本文提出的三维视线估计方法。
3.1 特征提取模块
特征提取对大多数基于学习的任务至关重要。由于眼睛表观的复杂性,从眼睛表观中有效地提取特征是一个挑战。提取的特征质量决定了视线估计的准确性。
UM-Net的特征提取模块先将输入的图像拆分为多个图像块(每个图像块之间不重叠[20]),以便于对图像中的信息进行交换以及特征整合。假设输入图像的分辨率为(J,K),拆分后的图像块分辨率为(P,P),那么图像块的数目H计算如式(1)所示:
(1)
本文输入UM-Net的原始图像分辨率为(64,64)。首先将输入图像拆分为16个分辨率为(16,16)的图像块,然后通过全连接将每个图像块投影到512维空间,所有图像块都使用相同的投影矩阵进行线性投影,投影之后图像特征块序列X∈R16×512。全连接操作将不重叠的图像块投影到更高的隐藏维度,不仅保留了图像的关键特征,还有助于后续局部区域的信息融合。
接下来将图像特征块序列送入N(8≤N≤24)个Mixer Layer。Mixer Layer未使用卷积或自注意力,仅使用了结构简单的MLP,并将之重复应用于空间位置或特征通道。3.3节详细介绍了Mixer Layer模块。
UM-Net利用Mixer Layer模块中的token-mixing MLP模块和channel-mixing MLP模块分别对图像特征块序列进行列方向的特征提取和行方向的特征提取。这些操作是交替堆叠进行的,有助于2个输入维度间的交流。将图像特征块序列反复经过N个Mixer Layer,提取图像特征信息。接着UM-Net使用全局平均池化对整个网络模型在结构上进行正则化以防止过拟合,最后使用全连接层分别回归出所需要的图像特征。
3.2 网络支路
本文利用上述特征提取模块从双眼图像和人脸图像中提取图像特征。
双眼特征提取支路(左眼支路和右眼支路):视线方向与眼睛表观高度相关,视线方向的任何扰动都会导致眼睛表观发生变化。例如,眼球的旋转会改变虹膜的位置和眼睑的形状,从而导致视线方向的改变。这种关系使得能够从眼睛的表观来估计视线。使用MLP模型可以直接从眼睛图像中提取深度特征,对环境的变化更具鲁棒性。因此,UM-Net使用特征提取模块分别从左眼图像、右眼图像提取256维特征。但是,随着环境变化,眼睛图像特征也会受到冗余信息的干扰。
人脸特征提取支路:三维视线方向不仅取决于眼睛的表观(虹膜位置、眼睛开合程度等),还取决于头部姿态。人脸图像包含头部姿态信息,所以UM-Net使用特征提取模块从人脸图像中提取32维特征以补充更丰富的信息。3条特征提取支路参数共享。
UM-Net使用3条特征提取支路回归出左眼图像特征、右眼图像特征和人脸图像特征之后,将提取到的特征进行拼接,然后将544维特征输送到第1个全连接层降至256维之后,再使用第2个全连接层回归出三维视线方向。这个三维视线方向是由垂直方向上的pitch角和水平方向上的yaw角来表示的,如式(2)所示:
(pitch,yaw)=δ(C{φθ(f)+φθ(l)+φθ(r)})
(2)
其中,f,l和r分别表示模型输入的人脸图像、左眼图像和右眼图像;φθ(·)表示网络的特征提取模块;C表示对提取到的左眼图像特征、右眼图像特征和人脸图像特征进行连接操作;δ(·)表示使用全连接层回归出三维视线方向。
UM-Net (no face):由于三维视线与双眼图像信息高度相关,为了提高视线估计的速度,可以去除人脸支路,仅将左眼图像和右眼图像作为输入,特征提取之后再进行特征拼接,回归出三维视线方向,如式(3)所示:
(pitch,yaw)=δ(C{φθ(l)+φθ(r)})
(3)
另一方面,本文认为人脸支路有助于提供头部姿态等更丰富的信息,去除人脸支路之后会降低视线估计精度。因此在实验部分,本文对去除人脸支路前后的网络进行视线估计精度和速度对比,评估人脸支路的有效性。
在UM-Net估计出pitch角和yaw角之后,可以计算出代表视线方向的三维向量a=(x,y,z), 如式(4)~式(6)所示:
x=cos(pitch)cos(yaw)
(4)
y=cos(pitch)sin(yaw)
(5)
z=sin(pitch)
(6)
该向量与真实的方向向量b之间的夹角即为三维视线估计领域常用的评价指标,即视线角度误差θ,如式(7)所示:
(7)
损失函数采用均方损失函数MSELoss(Mean Squared Error Loss),如式(8)所示:
(8)
其中,i表示训练样本集的大小。
3.3 Mixer Layer模块
当前深度学习模型对图像特征进行融合的方式主要分为3类:对不同通道进行融合;对不同空间位置进行融合;对不同通道、空间位置都进行融合。不同的模型作用方式不同。在CNN中,使用1×1卷积进行不同通道融合,对于不同空间位置融合则使用S×S(S>1)卷积或池化,使用更大的卷积核进行上述2种特征融合。在Vision Transformer等注意力模型中,使用自注意力层可以进行不同通道融合和不同空间位置融合;而MLP则只能进行不同通道融合。Mixer Layer模块的主要思想是利用多个MLP实现上述2种特征融合并且作用过程分离进行。反复经过Mixer Layer模块,交替实现上述2种特征的融合,即可提取出图像特征信息。
Mixer Layer结构如图2所示,其中左虚线框内是token-mixing MLP模块,右虚线框内是channel-mixing MLP模块。token-mixing MLP模块先对图像特征块序列X∈R16×512进行转置,然后将MLP1作用在图像特征块序列的每一列上,实现图像特征块序列不同空间位置间的交流,并且所有列共享MLP1参数。得到的输出再进行转置,然后在channel-mixing MLP模块中将MLP2作用在图像特征块序列每一行上,实现图像特征块序列不同通道间的交流,所有行共享MLP2参数。

Figure 2 Mixer Layer module图2 Mixer Layer模块
Mixer Layer模块中还使用了跳跃连接(Skip-Connection)和层规范化(Layer Normalization)。跳跃连接可以缓解梯度消失的问题,层规范化可以提高模型的训练速度和精度,使模型更加稳健。对于输入的图像特征块序列X∈R16×512,Mixer Layer模块作用过程如式(9)和式(10)所示:
U*,i=M1(LayerNorm(X)*,i),i∈[1,512]
(9)
Yj,*=M2(LayerNorm(U)j,*),j∈[1,16]
(10)
其中,M1(·)和M2(·)表示MLP1模块和MLP2模块,LayerNorm(X)*,i表示图像特征块序列经过层规范化后的第i列,LayerNorm(U)j,*表示图像特征块序列经过层规范化后的第j行。
3.4 MLP模块
UM-Net中每个MLP模块都包含2个全连接层和1个非线性激活函数GELU(Gaussian Error Linear Unit),如图3所示。对于MLP模块的输入ϖ,作用过程如式(11)所示:
σ=W2(Φ(W1(ϖ)))
(11)
其中,Φ(·)表示作用于输入元素的非线性激活函数,W1和W2表示MLP模块中的全连接层。

Figure 3 MLP module图3 MLP模块
4 实验与结果分析
4.1 数据集
MPIIFaceGaze数据集[16]:MPIIFaceGaze数据集与MPIIGaze数据集使用的是同一批数据,只是增加了全脸图像,如图4所示。MPIIFaceGaze数据集是基于表观的三维视线估计方法中常用的数据集。MPIIFaceGaze数据集包含15个文件夹,分别对应15位外貌差异明显的受试者。每个文件夹包含一个受试者的3 000组数据(包含人脸图像、左眼图像、右眼图像)。受试者图像收集历时几个月,因此图像具有不同的光照条件和头部姿态。

Figure 4 Face images of 15 subjects in MPIIFaceGaze dataset图4 MPIIFaceGaze数据集中的15名受试者全脸图像
EyeDiap数据集[22]:与MPIIFaceGaze数据集不同,EyeDiap数据集是在实验室环境中收集的,包含16位外貌差异明显的受试者,如图5所示。利用深度摄像头标注RGB视频中的眼睛中心点位置和乒乓球位置。把这2个位置映射到深度摄像头记录的三维点云中,从而得到对应的三维位置坐标。这2个三维位置坐标相减后即得到三维视线方向。

Figure 5 Face images of 16 subjects in EyeDiap dataset图5 EyeDiap数据集中的16名受试者全脸图像
采取leave-one-subject-out方式进行实验,即选取数据集中1个文件夹内容作为测试集,剩下的文件夹内容作为训练集。依次将每个文件夹选取为测试集,分别进行测试,对得到的每个测试集的三维视线角度误差取平均值作为最后的结果。
4.2 数据集预处理
本文首先对数据集进行预处理,采用与先进的视线估计方法相同的图像归一化方法[16,23]。首先对相机进行虚拟旋转和平移,使虚拟相机以固定距离面对参考点,并抵消头部的滚动角。本文将MPIIFaceGaze数据集和EyeDiap数据集中的图像参考点分别设置为面部中心和2只眼睛的中心。在对人脸图像进行归一化之后,本文从人脸图像中裁剪出眼睛图像,眼睛图像经过直方图均衡对对比度进行调整。视线角度真实值也进行归一化。
4.3 各方法比较
本节在MPIIFaceGaze数据集和EyeDiap数据集上将UM-Net与以下几种先进的视线估计方法进行对比:
(1)Gaze360[24]:一种基于视频的使用双向长期短期记忆LSTM(Long Short-Term Memory)的视线估计模型。它提供了一种对序列进行建模的方法,其中一个元素的输出取决于过去和将来的输入。在文献[24]中,利用7个帧的序列来预测中心帧的视线。
(2)RT-GENE(Real-Time Gaze Estimation in Natural Environments)[25]:基于表观的视线估计的主要挑战之一是在允许自由动作的前提下,准确地估计自然外表的受试者的视线。文献[25]提出的RT-GENE允许在自由观看条件和大镜头距离下自动标注受试者的真实视线和头部姿态标签。
(3)FullFace[16]:基于注意力机制的全脸视线估计方法。文献[16]中的注意力机制主要思想是通过一条支路学习人脸区域各位置的权重,其目标是增大眼睛区域的权重,抑制与视线无关区域的权重。
(4)CA-Net[26]:一种由粗到细的视线方向估计模型,从人脸图像中估计出基本的视线方向,并利用人眼图像中相应的残差对其进行改进。在该思想指导下,文献[26]引入二元模型来处理视线残差和基本视线方向,并引入注意力分量来自适应地获取合适的细粒度特征。
实验结果如图6所示。从图6可以看出,虽然UM-Net没有使用CNN,而是使用MLP模型,旨在提高视线估计的速度,但UM-Net的视线估计精度接近这些先进的视线估计方法的。另外,图7还展示了实验图像的三维视线可视化示例,其结果表明,对于不同角度的人脸图像,UM-Net有良好的视线估计精度。

Figure 6 Performance comparison of different methods on two datasets图6 在2个数据集上不同方法的性能对比

Figure 7 Example of 3D gaze visualization图7 三维视线可视化示例
4.4 MLP模型与CNN在视线估计中实验对比
本节在MPIIFaceGaze数据集和EyeDiap数据集上比较UM-Net与基于CNN的方法在视线估计中的精度和速度。
本文选择Dilated-Convolutions[18]和ResNet50[27]中的CNN替换MLP模型作为UM-Net中的特征提取器。Chen等[18]提出的Dilated-Net表明Dilated-Convolutions在视线估计中有着优越的性能。ResNet50作为经典的CNN结构,因其强大的性能有着广泛的应用。本文使用Dilated-Net对人脸图像和双眼图像进行特征提取,使用ResNet50模型(ResNet50-Net)代替MLP模型同样对分辨率为64×64的人脸图像、左眼图像和右眼图像分别提取32,256,256维特征。

Figure 8 Average angle error comparison on MPIIFaceGaze dataset图8 在MPIIFaceGaze数据集上的平均角度误差对比

Figure 9 Average angle error comparison on EyeDiap dataset图9 在EyeDiap数据集上的平均角度误差对比
实验结果如图8和图9所示。可以看到,使用不同受试者所在的文件夹作为测试集,得到的结果也不同。在MPIIFaceGaze数据集上,UM-Net的综合平均角度误差为4.94°,Dilated-Net的为4.51°,ResNet50-Net的为5.49°。在EyeDiap数据集上,UM-Net的为6.66°,Dilated-Net的为6.17°,ResNet50-Net的为6.21°。以上结果表明,UM-Net在MPIIFaceGaze数据集和EyeDiap数据集上的平均角度误差比肩基于CNN方法的,并且在某些受试者上的预测精度占据优势。
另外,在视线估计的效率表现上,实验结果如图10所示。在MPIIFaceGaze数据集上,UM-Net的综合平均预测时间为3.74 s,Dilated-Net的为5.23 s,ResNet50-Net的为23.69 s。UM-Net处理MPIIFaceGaze数据集中3 000组数据的时间平均为3.74 s,即平均每秒能处理800组数据,证明本文方法能够很好地满足视线估计实时性的要求。
在EyeDiap数据集上,UM-Net的综合平均预测时间为6.91 s,Dilated-Net的为11.12 s,ResNet50-Net的为47.52 s。实验结果表明,UM-Net在MPIIFaceGaze数据集和EyeDiap数据集上的预测时间都明显优于Dilated-Net的,大幅度优于ResNet50-Net的。以上结果表明,UM-Net视线估计速度快,在三维视线估计实时性较强的应用场景有良好的前景。
综上,UM-Net使用MLP模型提取图像特征,在视线估计领域中,预测精度比肩基于CNN的方法的,预测速度处于领先地位。
4.5 模型参数量对比
本文计算了UM-Net、Dilated-Net和ResNet50-Net的参数量。模型参数量是模型训练中需要训练的参数总数。本文利用THOP库(PyTorch中的第三方库)统计模型的参数量。网络参数统计结果如图11所示,UM-Net所需的参数量显著低于ResNet50-Net的。UM-Net参数量也明显低于Dilated-Net的。

Figure 11 Parameter quantities comparison图11 参数量对比
4.6 人脸支路有效性验证
为了验证人脸支路的有效性,本文去除人脸支路,保留剩下的2条眼部支路进行视线估计,实验结果如表1所示。可以看到,去除人脸支路后的平均视线角度误差为5.93°,高于UM-Net的4.94°,平均预测时间为3.13 s,与UM-Net的3.74 s差距较小。因此,加入人脸支路可以补充双眼图像以外的特征信息,对视线估计精度有较为明显的提高,但对预测时间的影响较小,验证了人脸支路的有效性。另一方面,该实验结果也表明,在追求视线估计速度的场景,可以去除UM-Net中的人脸支路。

Table 1 Experimental results comparison of methodsafter removing face branches表1 去除人脸支路的实验结果比较
5 结束语
在三维视线估计领域中,如何在保持高精度的同时,设计一个高效的模型是值得思考的问题。结构较CNN更为简单但性能相当的MLP模型带来了启发。本文方法无需CNN、使用基于MLP模型的方法(UM-Net)进行视线估计。实验结果表明,对MPIIFaceGaze数据集和EyeDiap数据集中包含的31位不同相貌的受试者图像,使用UM-Net进行视线估计,精度比肩基于CNN的方法的,并且在视线估计速度上具有明显的优势,在需要视线估计实时性的领域有很好的应用前景,如在医疗领域,渐冻症患者可以通过实时性强的眼动仪来与外界进行交流。本文探索了MLP模型在视线估计领域中的潜力,未来将继续挖掘MLP模型在视线估计中的应用前景。
