差分变异和领地搜索的平衡优化算法及其机器人路径规划
2023-11-17闵华松张新明
张 贝,闵华松,张新明
(1.武汉科技大学机器人与智能系统研究院,湖北 武汉 430081;2.河南师范大学计算机与信息工程学院,河南 新乡 453007)
1 引言
优化问题在现实生活中无处不在,如二次指派问题[1]和机器人路径规划[2]等都是典型的优化问题。
一般说来,优化问题可以分为线性、非线性、连续、离散、单目标、多目标、有约束和无约束等优化问题[3]。而解决好无约束单目标问题是解决所有其它优化问题的基础[4],故本文主要讨论此类优化问题。
解决优化问题的方法称为优化方法。优化方法一般分为确定性方法和随机性方法。传统的确定性方法不能很好地解决全局优化问题,且还需要优化问题的大量信息[4]。因此,随机性优化方法引起了人们广泛的关注。元启发式算法MA(Meta- heuristic Algorithm)属于随机性优化方法范畴。MA由于其简单性、灵活性和无需太多优化问题的信息等优点,在许多领域得到广泛的应用。因此,研究人员提出了许多MA,如差分进化算法[4]、粒子群优化PSO(Particle Swarm Optimization)算法[5]、人工蜂鸟算法AHA(Artificial Hummingbird Algorithm)[6]和堆优化算法HBO(Heap-Based Optimizer)[7]等。随着社会的快速发展,需要解决的优化问题越来越多,且越来越复杂和多样化。另外,根据无免费午餐定理[8],一个算法在一类优化问题上可能有杰出的表现,但在另一类优化问题上可能表现不佳,没有一种MA可以解决所有的优化问题。因此,新的和改进的MA不断被提出。
平衡优化算法EO(Equilibrium Optimizer)是由Faramarzi等人[9]在2020年提出的一种新型的MA,受启发于受控容器中液体的动态质量守恒模型,即在受控容器中进入、离开和产生的液体质量总和保持不变。在EO中,每种液体成分类似PSO中的粒子充当搜索个体,而这些成分的浓度类似PSO中的粒子位置。每个粒子通过5个精英粒子的引导来更新其浓度,最终达到平衡状态(最优结果)。与现有的MA相比,EO具有独特的搜索机制,在解决经典的优化问题时优势明显[9]。然而,EO提出的时间较短,还有许多地方值得深入研究。因此,国内外一些研究人员提出了一些EO的改进算法,扩展了其应用范围。例如,Gupta等人[10]提出了一种具有突变策略的EO,使种群保持足够的多样性,增强了EO的全局搜索能力;Wunnava等人[11]将一种自适应EO——AEO(Adaptive EO)应用于多阈值图像分割,扩展了EO的应用范围;Fan等人[12]基于反向学习策略和新颖的更新规则提出了一种改进的EO,该算法在最优解为零向量的问题上非常有效;罗仕杭等人[13]提出了一种多策略的EO——MEO(Multi-strategy EO),在经典的优化问题上获得更好的性能;Zhang等人[14]提出了一种强化信息使用的EO——ISEO(Information utilization Strengthened EO),提升了EO的搜索能力。虽然这些EO的改进算法在不同程度上改善了EO的优化性能或扩展了其应用范围。然而,它们仍存在搜索能力不足等缺陷。此外,它们大多都是在经典函数上验证其有效性,几乎没有关于在CEC(Congress on Ewlntionary Computation)复杂优化问题的测试集上测试EO改进版本的研究,而且目前也无EO在机器人路径规划上应用的研究。综上所述,对EO的研究非常必要且有较大实际意义。
针对EO在解决复杂优化问题时存在搜索能力不足和搜索效率低等问题,本文提出了一种改进的EO,即差分变异和领地搜索的EO——DTEO(Differential mutation and Territorial search EO)。
2 平衡优化算法
EO中粒子的浓度更新方式是依据质量守恒定律所构建的一阶常微分方程推导而成[9],如式(1)所示:
(1)
其中,Xi为第i个粒子更新后的浓度;Ci为其已有的浓度,i∈[1,N],N为种群规模;Ce是从精英池(Cpool)中随机选取的精英粒子的浓度;F为缩放因子向量;G为生成速度;λ为周转速率;V表示容器的体积,常取值为1个体积单位;⊗表示2个向量中的对应分量相乘。这些符号详述如下:
精英池(Cpool)由5个精英粒子的浓度组成,如式(2)所示:
Cpool={Cα,Cβ,Cδ,Cγ,Cφ}
(2)
其中,Cα、Cβ、Cδ和Cγ分别为当前种群中最优、次优、第3优和第4优粒子的浓度,最后一个精英的浓度Cφ通过式(3)计算获得:
Cφ=(Cα+Cβ+Cδ+Cγ)/4
(3)
缩放因子向量F的计算如式(4)和式(5)所示:
F=a1×sign(r-0.5)⊗[e-z×λ-1]
(4)
z=(1-t/T)(a2×t/T)
(5)
其中,a1和a2为调整参数;sign(·)是符号函数;r与λ都是D维随机向量,其每个分量是均匀分布在[0,1]的随机数;t为当前迭代次数;T为最大迭代次数。
生成速度G的表达式如式(6)~式(8)所示:
G=G0⊗F
(6)
G0=RG×(Ce-λ⊗Ci)
(7)
(8)
其中,RG为生成速度的控制参数,由参数生成概率PG决定;r1和r2为均匀分布在[0,1]的随机数。
从式(6)~式(8)可以看出,当r2小于PG时,G为零向量,故式(1)可以改写为式(9):
(9)
根据式(1)~式(8)可知,式(1)右侧的第1项是随机选择精英粒子的浓度,第2项和第3项包含了这个精英粒子和第i个粒子浓度之间的差值。EO的伪代码如算法1所示。
算法1EO算法
输入:参数V,a1,a2和PG等的值。
输出:最优解Cα。
1.随机初始化种群中每个粒子的浓度;
2.计算粒子适应度值,确定Cα、Cβ、Cδ、Cγ和Cφ,构建精英池;
3.FORt=1 TOTDO
4.FORi=1 TONDO
5. 依据式(9)更新粒子的浓度,并对更新后的浓度进行边界控制;
6.ENDFOR
7.FORi=1 TONDO
8. 计算粒子的适应度值,用贪婪算法选择更新种群和更新精英池;
9.ENDFOR
10.ENDFOR
根据以上描述可知,EO具有以下优点:(1) 具有独特的新解产生机制,如式(1)所示。(2) 具有一定的信息引导能力。从式(1)可以看出,在一定程度上精英粒子的信息可以引导其他粒子搜索。(3) 有较强的局部搜索能力。式(1)右侧的3项都包含精英粒子的浓度,这表明精英粒子会引导种群朝着良好的方向搜索。(4) 具有一定的全局搜索能力。其一,在演化早期阶段,F的各分量值较大且精英粒子与其他粒子之间的差异也较大,这有助于扩大搜索范围;其二,更新方程包含的一些随机因素也增强了种群多样性和有利于全局搜索。(5) 具有较强的灵活性和通用性,较多的可调参数可以调整算法使其适应多种优化问题。
3 改进的平衡优化算法
EO虽然在经典函数上有较好的优化性能,但在解决复杂的优化问题时仍然存在一些不足:(1) 在EO中仅使用5个精英粒子与其他粒子共享信息,这种信息共享方式不仅单一,而且共享程度较低,导致搜索能力不足;(2) 浓度更新方程的计算复杂度高,同时搜索能力不足使得EO的搜索效率较低;(3) EO有较多参数需要调整,导致EO的可操作性较差。因此,针对EO在解决复杂优化问题时存在的缺点,本文提出了4种改进策略:(1)融合领地搜索的随机差分变异策略,提升最优个体;(2)信息共享的随机差分变异策略,提高算法的搜索能力;(3)简化EO更新方程策略,提高算法的可操作性,降低计算复杂度;(4)精英与最差个体的差分变异策略,强化最差个体。
3.1 融合领地搜索的随机差分变异策略
在EO中,所有粒子浓度的更新都是由精英粒子引导的,最优个体属于精英群中一员,发挥着重要的作用。若最优个体位于局部最优点,可能会使EO陷入局部最优。所以若能强化最优个体,则通过式(9)中的精英信息引导能够提升其它个体的搜索能力,故本文采用一种新型差分变异策略来更新最优个体的浓度,以提升最优个体。差分变异策略就是将2个解的差分向量经过缩放加到第3个解向量上,对其每维的值进行变异,从而得到一个新解。差分变异有多种形式,被广泛应用于MA中[4]。本节仅讨论将2个随机选择粒子的浓度差分向量缩放后加到当前粒子的浓度上,产生新浓度,表达式如式(10)和式(11)所示:
Xi=Ci+fr×(Cs-Cl)
(10)
fr=0.5×(sin(2π×0.25×t)×(t/T)+1)
(11)
其中,Cs和Cl分别为从当前种群中随机选择的2个粒子的浓度,且s≠l≠i;fr为正弦模型的缩放因子[15]。
由文献[15]可知,正弦模型使得fr的值在0.5上下波动。在迭代前期,波动幅度不大,但周期性的波动有利于算法跳出局部最优点,准确定位全局最优点;在迭代后期,fr波动幅度较大,有时其值接近1,有时其值近似0,在算法陷于局部最优时,接近1的缩放因子值有利于算法跳出局部最优,当算法搜索到有希望的全局最优点时,接近0的缩放因子值有利于精确搜索。因此,正弦缩放因子能够很好地平衡探索与开采能力。
融合领地搜索随机差分变异策略的基本原理是:在一个随机数rand小于0.5或者Cs和Cl为零向量时,最优个体进行领地搜索,否则采用随机差分变异策略更新其浓度。在前期,各个粒子浓度之间的差异较大,Xi远离Ci,搜索范围较大,有利于全局搜索。但是,到了后期各个粒子浓度之间的差异变小,有利于局部搜索,但无差异时,Xi=Ci为无效解。为了应对这种情况,本文将领地搜索策略融入到差分变异策略中。
领地搜索思想来自人工蜂鸟算法[6],其灵感来自于蜂鸟的领地觅食行为。在蜂鸟吃完了目标花源的花蜜之后,它有可能在其附近搜索新的花源。因此,蜂鸟在它的领地里会移到当前食物源附近,搜索也许更好的食物源作为候选解。这种搜索策略在本文称为领地搜索策略,其表达式如式(12)所示:
Xi=Ci+fα×Di⊗Ci
(12)
其中,fα是领地搜索因子,服从标准的正态分布,即均值为0、方差为1的高斯分布;Di为第i个蜂鸟的飞行方向向量,模拟蜂鸟3种飞行方式(轴向飞行、对角飞行和全向飞行),即当一个均匀分布在0~1的随机数小于1/3时,蜂鸟采用对角飞行,当这个随机数大于2/3时采用全向飞行,否则采用轴向飞行。在Di中,若一个随机维的值为1,其它维的值全为0,则表示轴向飞行;若几个随机维的值为1,其它维的值为0,则表示对角飞行;若所有维的值全为1,则表示全向飞行。
从式(12)可知,Di是0-1向量,即每个分量要么是0,要么是1,故产生的新解Xi是在Ci自身的某些维或者全维变异获得。这种搜索是一种局部搜索,能够提升算法的收敛速度和解的精度。
将领地搜索融入到差分变异中的过程如算法2所示。
算法2融合领地搜索的差分变异策略
输入:当前最优粒子。
输出:更新后的最优粒子浓度。
1.随机选择2个粒子;
2.IF(随机选择的2个粒子浓度相同) or (rand<0.5);
3. 采用式(12)领地搜索更新最优粒子的浓度;
4.ELSE
5. 采用式(10)的随机差分变异策略更新最优粒子的浓度;
6.ENDIF
从算法2可以看出:(1) 领地搜索的差分变异策略替换式(9)仅用于最优粒子的浓度更新,由此最优粒子的浓度更新是得益于种群中其它粒子的信息和自身信息。(2) 在差分值为0和rand小于0.5时采用领地搜索,解决了差分变异策略尤其在迭代后期易产生无效解的问题。(3) 从式(12)可以看出,领地搜索作用于最优粒子上,更能发挥领地搜索的作用,在最优粒子的浓度周围进行精搜索更能加快算法收敛和提高解的精度。(4) 由于前期个体之间的差异较大,随机选择的2个个体的浓度相同的概率较低,这样前期采用差分变异策略的机会较大,这有利于提高算法的全局搜索能力。(5)在迭代后期,采用领地搜索的概率较大,而领地搜索是一种局部搜索,所以在整个迭代过程中算法能够从全局搜索自动转换到局部搜索。(6) 无论前期还是后期,差分变异和领地搜索随机交替执行,即全局搜索和局部搜索交替进行,有利于平衡探索与开采能力。
3.2 信息共享的随机差分变异策略
MA通过群体中的信息共享和个体与环境的适应性等来搜索整个空间,从而找到最优解或者次优解[14]。因此,为了增强EO中粒子之间的信息共享程度,除了最优粒子和最差粒子外,本文在其它粒子的浓度更新上采用一种信息共享的随机差分变异策略,其数学模型如式(10)所示。
虽然信息共享的随机差分变异策略仍然采用3.1节的式(10),但由于这种随机差分变异策略作用在多个粒子上,且Cs和Cl的随机选择满足均匀分布,随着迭代次数的增加,使得种群中所有粒子都有可能被选择。这些差分值是种群内所有粒子贡献的信息,如此增强了种群内粒子之间的信息共享。
3.3 简化EO浓度更新策略
为了更好地与信息共享的随机差分变异策略融合,增强可操作性和缩短运行时间,本文在保证EO优势的情况下,提出一种简化EO更新策略,其表达式如式(13)所示:
Xi=Ce-(Ce-Ci)⊗F+
0.5×r1×(Ce-Ci)⊗F⊗(1-F)
(13)
F=2×sign(r-0.5)×[e-η-1]
(14)
η=(1-t/T)(t/T)
(15)
从式(13)~式(15)可以看出,与原EO更新策略相比,简化更新策略有以下差异:(1) 舍弃了λ、V、a1、a2和PG等参数,只保留了F、r和r1。这3个参数不需要人工调整,大幅度提高了EO的可操作性。(2) 去掉了参数λ,式(13)~式(15)减少了许多基于维度和基于指数的运算,这些都大幅度降低了计算量。(3) 由式(13)可知,简化后的更新策略是精英粒子浓度与当前粒子浓度的差分向量,经过缩放后加到精英粒子的浓度上,这实际上也是一种差分变异策略,更加突出了精英粒子的引导作用,如此强化开采能力。
虽然简化操作保持了EO较强开采能力的优势,降低了计算复杂度,提高了可操作性,但它并没有改变EO的整体搜索模式。此外,简化策略去掉了随机参数λ并采用一种更新模式,降低了种群的多样性,在一定程度上削弱了EO的全局搜索能力。为了增强全局搜索能力,本文通过动态调整的方法将信息共享的随机差分变异策略和简化EO更新策略相结合。动态调整融合2种策略的流程图如图1所示。其中,η是融合2种更新策略的动态调整参数,如式(15)所示,随着迭代次数的增加,它从1递减到0;r2是均匀分布在[0,1]的随机数。从图1可以看出,当r2≥η时,使用简化EO更新策略对当前粒子的浓度进行更新;否则,使用信息共享的随机差分变异策略进行更新。在迭代初期,η值较大,大部分粒子采用信息共享的差分变异策略更新其浓度,少数粒子采用简化EO更新策略更新其浓度。此时粒子之间的差异也较大,种群具有较强的多样性,有助于全局搜索。在迭代后期,η值较小,大部分粒子采用开采能力强的简化EO更新策略更新,少数粒子采用信息共享策略更新。此时粒子之间的差异较小,信息共享的差分变异策略也在一定程度上有利于算法的局部搜索。因此,动态调整2种策略有效地平衡算法的探索和开采能力,在提高全局搜索能力的同时保持了原算法局部搜索能力强的优势。另外,为了防止差分变异操作产生无效解,在式(10)和式(13)中的差分向量为零向量时采用领地搜索,发挥领地搜索的优势。

Figure 1 Process of hybrid differential mutation and simplified updating strategies图1 融合差分变异策略和简化更新策略的过程
3.4 精英与最差个体的差分变异策略
强化最差个体能够提高算法的整体性能,进而提升算法的搜索效率[1]。故针对最差个体,本文提出了一种精英与最差个体的差分变异策略。如此有别于其它个体的更新方式,使最差粒子的搜索能力大幅度提高。其数学模型如式(16)所示:
(16)
其中,Xw为最差粒子更新后的浓度,Cw为最差粒子原有的浓度,r3为均匀分布在[0,1]的随机数,fr的含义如式(11)所示。
从式(16)可以看出,在最差粒子原有浓度的基础上,添加一个精英粒子与最差粒子的浓度差分值,这可以保证最差粒子在精英信息的引导下向着最优方向趋近,强化最差个体的开采能力。同时,在0.5的概率下,其差分值受到(0.5+0.5×rand)和fr缩放因子的扰动,如此缩放最差粒子的搜索范围,以此在强化最差粒子局部搜索能力的同时兼顾全局搜索能力。因此,精英与最差个体差分变异策略能够有效地增强最差个体的性能,减少最差粒子对整个种群的不利影响。同样当差分为零向量时,采用领地搜索,以避免产生无效解。
3.5 DTEO流程
DTEO的流程图如图2所示。
由图2可知,DTEO采用了4种浓度更新方式:融合领地搜索的随机差分变异策略用于更新最优粒子的浓度;精英与最差粒子的差分变异策略用于更新最差粒子的浓度;而信息共享的随机差分变异策略主要用于其它个体在迭代前期的浓度更新;简化EO更新策略主要使用在迭代后期。虽然这4种改进策略都使用了差分变异策略和领地搜索,但随机差分变异策略在搜索前期主要用于全局搜索,而领地搜索主要用于局部搜索,也为了避免差分变异策略产生无效解。所以,在DTEO中,差分变异策略与领地搜索有机结合能够提高搜索效率。总之,DTEO在保持EO优势的同时,增强了种群中的信息利用率,克服了EO的不足,较好地平衡了探索和开采性能。

Figure 2 Flow chart of DTEO图2 DTEO算法流程图
4 实验与结果分析
4.1 实验环境与评价标准
为了验证DTEO的性能,将其用于CEC2014复杂函数测试集的优化实验。CEC2014包含4类函数:单峰函数(f1~f3)、多峰函数(f4~f16)、组合函数(f17~f22)和复合函数(f23~f30),具体细节见文献[16]。主频3.4 GHz的Intel®CoreTMi7-3770 CPU和8 GB内存的PC机实验环境下,操作系统采用64位的Windows 10系统。用于统计分析的软件是IBM SPSS Statistics 24,编程语言采用MATLAB2014A。
本文采用均值(Mean)、方差(Std)、排名(Rank)、平均排名和总排名等指标来评价一个MA的优化性能好坏。对于一个极小值问题,一个MA所获得的均值越小,表示它的优化性能越好。方差越小,稳定性越强。排名规则如下:在每个函数上,算法得到的均值越小,排名靠前;若几个算法的均值相同,再比较方差,方差越小,则排名靠前;如果均值和方差相同,则排名相同。
4.2 对比算法及参数设置
为了全面评价DTEO的表现,包括优化性能、运行时间和搜索效率等,本文选择了一些最先进的代表性算法作为其对比算法。它们包括EO[9]及其改进算法AEO[11]、MEO[13]和ISEO[14],也包括其它最新的优秀算法AHA[6]、DDHBO(Differential Disturbance HBO)[7]、XPSO(eXpanded PSO)[5]和BWCOA(Best and Worst coyotes strengthened Coyote Optimization Algorithm)[1]。XPSO是具有多榜样学习的PSO变体,而PSO是经典智能优化算法的代表。AHA是人工蜂鸟算法,是最新提出的MA,它和DTEO都采用了领地搜索策略。BWCOA是强化最优和最差个体的郊狼优化算法,它和DTEO都采用了强化最优和最差个体策略。DDHBO是最新的HBO改进变体,它与DTEO都采用了差分变异策略。ISEO是强化信息使用的EO,它与DTEO的共同目的就是强化信息使用,且它和MEO都是2022年提出的算法。这些对比算法均具有极强的代表性和可比性。
为了公平比较,根据文献[16]的公共参数最佳设置建议,所有算法的公共参数设置相同:最大函数评价次数(Mnef)为D×10000,独立运行次数为51。算法的不同参数设置将导致不同的实验结果,因此对比算法的其他参数设置是根据相应参考文献中的最佳推荐进行设置的,如表1所示。

Table 1 Parameters setting of 9 comparison algorithms表1 对比算法的参数设置
4.3 与其不完全算法的性能对比
为了验证每种改进对DTEO优化性能的贡献,本节将DTEO与其不完全算法在CEC2014的30维函数上进行实验对比。不完全算法的描述如下:DTEOwd为无信息共享差分变异策略的EO,DTEOww为无精英与最差个体差分变异策略的EO,DTEOwb为无融合领地搜索差分变异策略的EO。表2给出了DTEO与其不完全算法的Wilcoxon符号秩检验结果,显著性水平值设为0.05。3种不完全算法及EO的参数设置与DTEO的保持一致。“n”表示CEC2014测试集函数的数目30,“+”表示DTEO优于对比算法,“≈”表示DTEO与对比算法的实验结果近似,“-”表示DTEO劣于对比算法。表3列出了5种算法的平均排名结果。
由表2可知,DTEO优于4种对比算法,例如DTEO优于和劣于EO的个数分别是27和3,说明本文对EO的改进是有效的。
从表3可以看出,EO、DTEOwd、DTEOww、DTEOwb和DTEO的平均排名值分别为4.27,3.23,2.6,2.57和1.93。DTEO排名第一,DTEO在5种算法中获得了最好的优化性能,EO排名最后,其性能最差。这表明本文的改进是有效的,并且每种改进缺一不可,其中信息共享的随机差分变异策略对DTEO的贡献最大,而融合领地搜索差分变异策略贡献最小。
4.4 与最先进算法的优化性能对比
为了验证DTEO的有效性,本节将其在CEC2014的30维函数上进行实验,并将结果与最先进算法的结果进行对比。对比算法包括AEO、AHA、BWCOA、XPSO、ISEO、MEO和DDHBO。表4列出了DTEO与对比算法的实验结果,其中最优结果以粗体显示。
由表4可知,在平均排名上,DTEO为2.43,总排名第一,而MEO、AEO和ISEO分别为6.47,5.57和3.57,这表明它们在解决复杂问题上搜索能力不足,而本文提出的DTEO在解决复杂优化问题上比3种已有的EO改进算法更优。在3个单峰函数上,DTEO在f1上排名第一,在f2和f3上都排名第二。这说明DTEO具有更强的局部搜索能力,这得益于EO自身开采能力强的优势、领地搜索和精英粒子对最差粒子的引导等。在多峰函数f6和f14上,DTEO获得的结果均优于其对比算法的结果,虽然在其它多峰函数上获得的结果优势不明显,但比MEO和AEO的结果要好得多。显然,信息共享的差分变异策略使得DTEO具有不错的全局搜索能力。在混合和组合函数上,DTEO在10个函数f17、f18、f20、f21、f23~f25和f27~f29上排名第一,且排名第一的次数最多。这表明DTEO较好地平衡了探索和开采能力,能更好地处理更为复杂的优化问题。DTEO的平均排名为2.43,XPSO、DDHBO、BWCOA、AHA、ISEO、MEO和AEO的平均排名分别为6.07,3.73,3.23,4.63,3.57,6.47和5.57。显然,与最先进的算法相比,DTEO获得了最好的优化性能。这再次说明本文的4种改进策略是有效的,与EO及其改进算法相比,DTEO具有更强的搜索能力。

Table 2 Statistical results of DTEO and its incomplete algorithms表2 DTEO vs不完全算法的统计结果
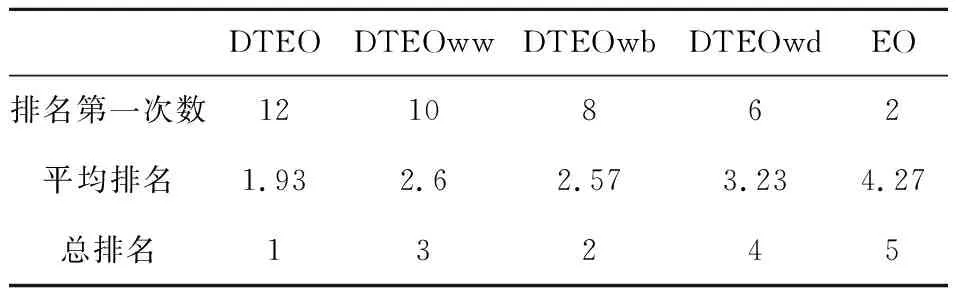
Table 3 Ranking results of DTEO and its incomplete algorithms表3 DTEO与不完全算法的排名结果
4.5 运行时间对比分析
为了讨论DTEO的运行时间,直接采用4.4节的实验,本节仅记录DTEO及其对比算法在CEC2014测试集30维函数上的运行时间。9种算法独立运行51次获得的平均运行时间如图3所示,时间单位为s。
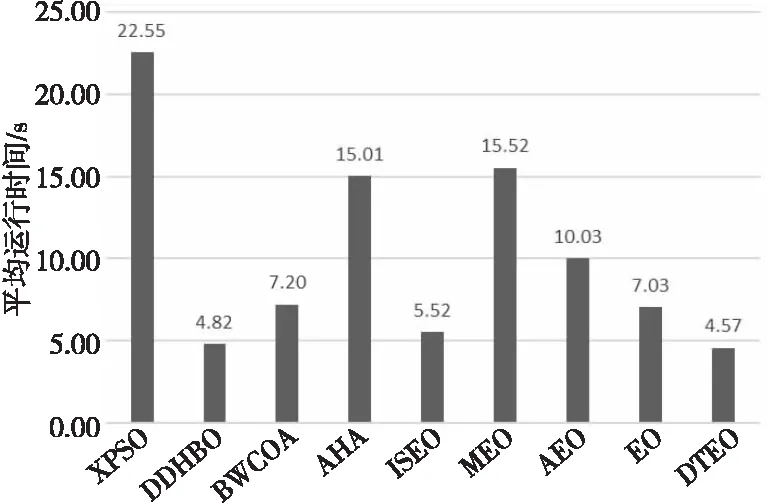
Figure 3 Comparison of average time of 9 algorithms on 30-demensional functions图3 9种算法在30维函数上的平均时间对比
从图3可以看出,DTEO的运行时间比EO、 AEO、MEO和ISEO的少,且在9种算法中,其耗时也是最少的。按耗时的升序排名,DTEO排名第一,随后是DDHBO、ISEO、EO、BWCOA、AEO、AHA、MEO和XPSO,耗时最多的是XPSO。DTEO的耗时(4.57 s)分别是EO(7.03 s)、AEO(10.03 s)、MEO(15.52 s)、ISEO(5.52 s)、DDHBO(4.82 s)、BWCOA(7.20 s)、AHA(15.01 s)和XPSO(22.55 s)的65.00%,45.56%,29.45%,82.79%,94.81%,63.47%,30.45%和20.27%。限于篇幅,本节仅简单讨论DTEO耗时少的原因。DTEO耗时少的主要原因是:(1) 本文提出的改进策略都是替代策略,不是添加策略,即用本文提出的更新策略替换原来的更新策略,没有增加额外的计算;而AEO、MEO和ISEO都添加了新操作,例如AEO为每个粒子与当前种群平均适应度值进行比较,故耗时比EO的耗时长。而ISEO添加了交叉操作,故在耗时上比DTEO的长。(2) 虽然引入了4种新的浓度更新方式,但任何更新方程都比EO的更新方程更简单。(3) 对EO更新方程的简化处理,大幅度降低了计算复杂度,节省了运行时间。而EO中包含大量的向量运算和指数运算,造成了EO的运行时间长。
4.6 Wilcoxon符号秩检验
为了测试DTEO与对比算法的显著性差异,本节进行差异性统计分析。Wilcoxon符号秩检验是一种非参数统计检验[1],它常用于检验2种算法之间差异的显著性。本节采用此方法检验DTEO与表4中对比算法之间的显著性。当DTEO的性能优于对比算法时,其秩为正;性能劣于对比算法时,其秩为负;性能与对比算法持平时,对应的秩平分。表5列出了DTEO与对比算法的Wilcoxon符号秩检验结果,显著性水平值设置为0.05。其中,p为实际显著性水平值,R+和R-分别表示正秩和负秩,“n/w/l/t”表示在n个函数上DTEO优于和劣于对比算法分别为w次和l次,相同结果为t次。如果p<0.05,则表明DTEO显著优于对比算法。相反,DTEO与对比算法无差异或更差。
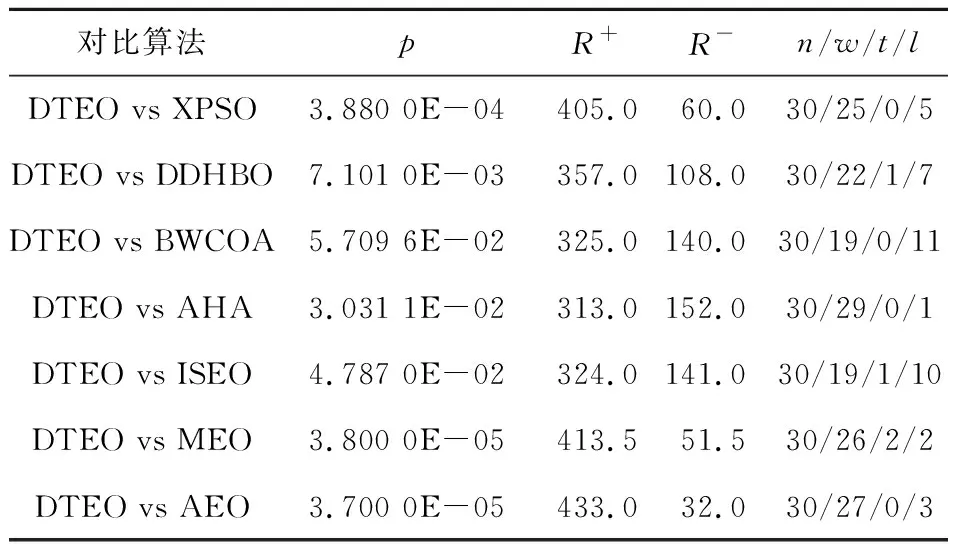
Table 5 Wilcoxon signed rank test results表5 Wilcoxon符号秩检验结果
从表5可以看出,在30个函数上DTEO优于XPSO、DDHBO、BWCOA、AHA、ISEO、MEO和AEO的函数个数分别为25,22,19,29,19,26和27。并且除了BWCOA的p值为5.709 6E-02外,DTEO与其它对比算法相比的p值均小于0.05,这表明DTEO显著优于这6种对比算法。
5 DTEO应用于机器人路径规划
随着科技的快速发展,移动机器人被广泛应用到诸多领域,替代或协助人类完成很多危险或复杂等工作。机器人路径规划RPP(Robot Path Planning)是受多种因素影响且难以求解的问题,所以在特定的环境下找到更为高效和安全的方法具有较强的实际意义。目前因MA有许多优势,已被广泛应用到路径规划中[2]。
5.1 MA运用到机器人路径规划的基本原理
机器人路径规划的主要目的是在环境地图中搜索出一条从起点到终点的距离最短的安全无碰撞路径。图4是机器人路径规划的示意图。起点和终点分别用方形和星形表示,障碍物用圆表示。在二维直角坐标系中,每个圆可以用式(17)表示:
r2=(x-a)2+(y-b)2
(17)
其中,(x,y)为点坐标,(a,b)为圆心坐标,r为半径。
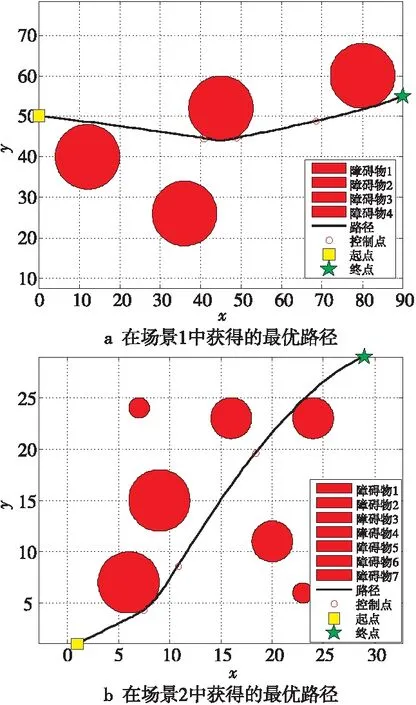
Figure 4 Best path maps of DTEO in two scenes图4 DTEO在2个场景中获得的最优路径图
RPP要求确定一条由起点(x0,y0)到终点(xn+1,yn+1)的路径{(x0,y0),(x1,y1),(x2,y2),…,(xn,yn),(xn+1,yn+1) },使决策目标最优,其中,(x1,y1),(x2,y2),…,(xn,yn)为待优化的控制点坐标。控制点的数量n决定了RPP的维度。为了降维和使路径更加精确,常引入插值方法。本文在每次迭代中,在两两控制点间采用Spline插值法插入100个点。RPP的决策目标是以带约束的线路长度作为目标函数,并在其中引入惩罚函数法构建规避障碍物约束,以便机器人避开障碍物,该数学模型如式(18)所示:
(18)
其中,v(k)为避障约束函数,r(k)为第k个障碍物的半径,(ak,bk)为第k个障碍物的圆心坐标。m为障碍物个数;ε为惩罚系数,在本文设置为100。
将一个MA运用到RPP的主要步骤如下:(1) 将式(18)作为目标函数,求此函数的最小值对应的决策变量;(2) 将起点到终点之间n个控制点的坐标,包括横坐标和纵坐标作为决策变量,在本文中n=3,则优化问题的维度为2n;(3) 确定这n个点坐标对应的上界和下界;(4) 输入以上信息到一个MA中;(5) 运行MA;(6) 输出最优解所对应的坐标。
5.2 机器人路径规划的仿真结果及分析
为了检验DTEO在路径规划中的性能,将其应用到大量较为复杂的路径规划中。为了简要说明问题,以2个场景的路径规划为示例进行描述:场景1:4个障碍物的圆心坐标分别是(12,40),(36,26),(45,52)和(80,60),其半径都为8。起点(x0,y0)=(0,50),终点(xn+1,yn+1)=(90,55)。场景2:7个障碍物的圆心坐标分别是(6,7),(20,11),(23,6),(9,15),(7,24),(16,23)和(24,23),其半径分别为3,2,1,3,1,2和2。起点(x0,y0)=(1,1),终点(xn+1,yn+1)=(29,29)。对比算法见表1。对比算法的公共参数设置相同:Mnef为10 000,独立运行次数为30。DTEO获得的最优路径如图4a和图4b所示,9种算法在2个场景中的性能分别如图5a和图5b所示。其中为了更清晰反映各个算法的性能,采用了各个算法获得的实际路径长度与它们获得最好路径长度之差(误差)的对数值。9种算法获得的均值、方差、最大值和最小值如表6所示。
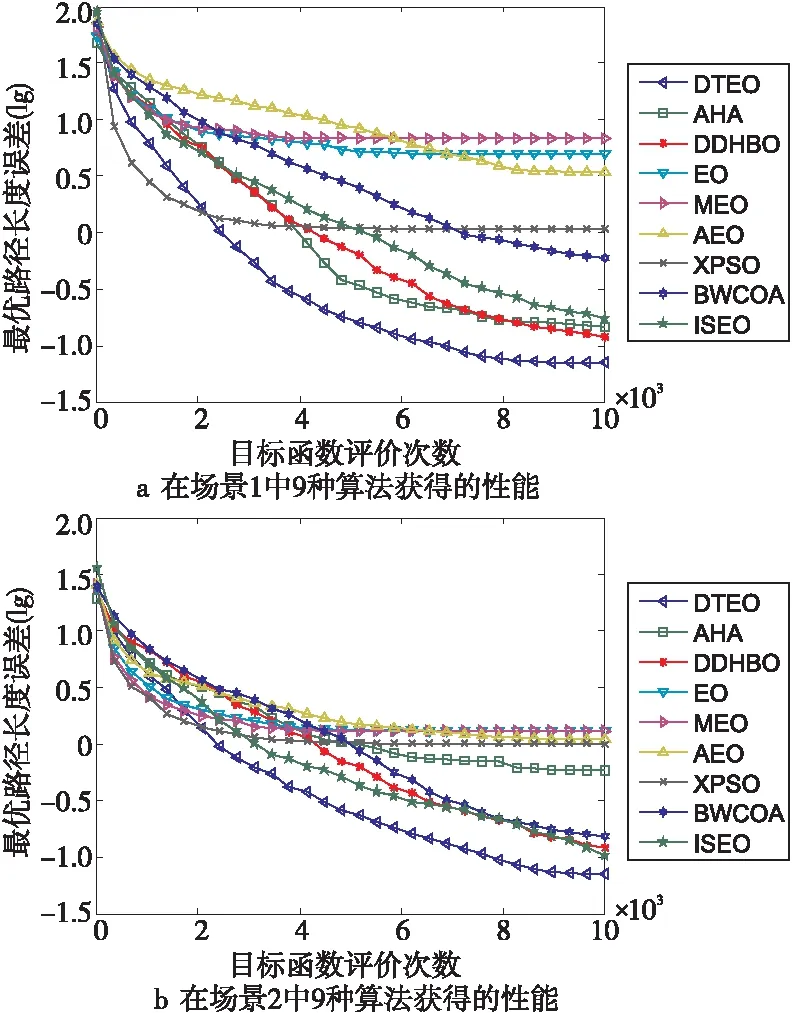
Figure 5 Performance curves of different optimization algorithms图5 不同优化算法的性能曲线
从表6可以看出,除了场景2方差排名第二外,在其它方面,DTEO都排名第一,平均排名值为1.13,总排名第一,在9种算法中获得了绝对优势。而EO的平均排名值为8.13,总排名第九,再次证明DTEO提升了EO的搜索能力,所提出的改进策略是有效的。
从图5a和图5b也可以直观看到,在9种对比算法中,无论在场景1还是在场景2中,DTEO的收敛曲线随着目标函数评价次数的增加,都是下降最快的,即收敛速度最快,获得了最好的收敛性能。
总的来说,DTEO在解决RPP时,优于对比算法。这表明DTEO能够更好地处理复杂的问题RPP,具有更强的竞争性。
6 结束语
针对EO中存在搜索能力不足、可操作性差和搜索效率低的问题,本文提出了一种改进的EO,即差分变异和领地搜索的EO。它包括4种新型浓度更新策略:(1)融合领地搜索的随机差分变异策略,提升最优个体;(2)信息共享的随机差分变异策略,提高算法的搜索能力;(3)简化EO更新方程策略,提高算法的可操作性,降低计算复杂度;(4)精英与最差个体的差分变异策略,强化最差个体。在CEC2014测试集30维函数上的实验结果表明,与EO以及一些最先进的优化算法相比,DTEO具有更好的优化性能。机器人路径规划的实验结果也表明,DTEO具有更强的竞争力,由此证明本文的改进是有效的。2类实验结果表明,DTEO采用的4种浓度更新方式是有效的,不仅增加了新解方式的多样性,也增强了种群多样性,有利于全局搜索和解决不同的优化问题。尽管DTEO的整体优化性能优于对比算法的,但其优势在CEC2014测试集多峰函数上并不明显。因为EO是最近提出的算法,许多方面还需要进一步研究,如理论研究、改进研究和应用研究。本文仅是一种改进研究的尝试。另外,在CEC系列的其它复杂函数测试集和其它实际优化问题上效果如何也是今后的研究内容。
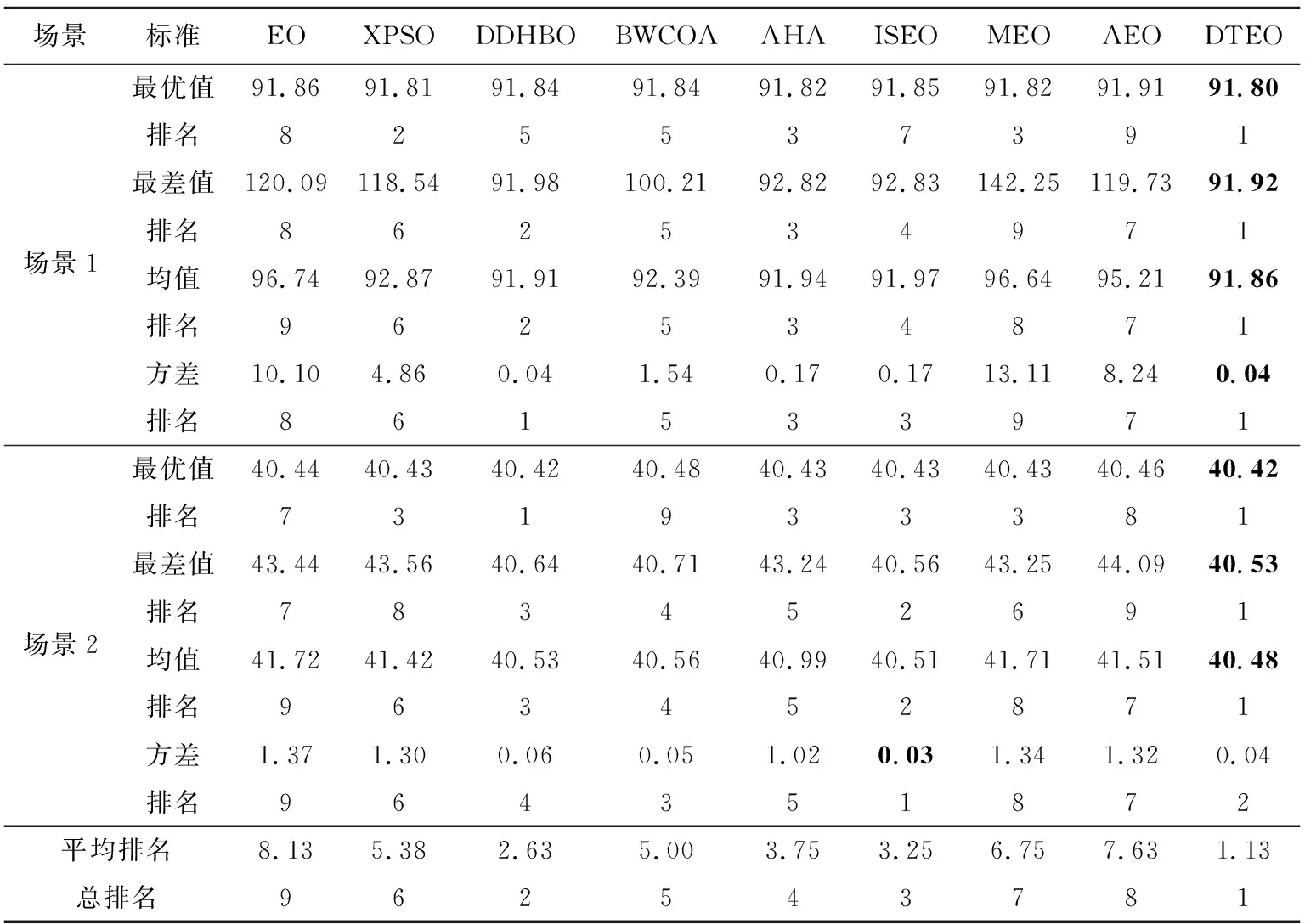
Table 6 Experimental results of DTEO and 8 comparison algorithms on RPP表6 DTEO与8种对比算法在路径规划上的实验结果
