一种基于共现关键词的TextRank文摘自动生成算法
2023-11-17阎红灿李铂初谷建涛
阎红灿,李铂初,谷建涛
(1.华北理工大学理学院,河北 唐山 063210;2.河北省数据科学与应用重点实验室,河北 唐山 063000)
1 引言
文摘自动生成[1]是自然语言处理领域中一项重要研究内容。面对如今互联网上日益增加的信息,文摘自动生成技术从海量的信息中提取有用的部分,可以提高人们获取信息的效率,节省时间。
文摘自动生成[2]方法分为抽取式和生成式2类,前者是从原始文档中提取关键句子、短语或单词来组成摘要;后者是根据对原始输入文本的理解来形成摘要。抽取式文摘自动生成方法生成的摘要通常可以保留原文中的重要信息,且保证了摘要句子语法正确,缺点是可能出现重复信息,且生成的摘要缺乏连贯性。生成式文摘自动生成方法是让模型尝试理解文本的内容后输出摘要,这种方法可能生成原文中没有的单词,具有生成高质量摘要的潜力,但需要大量的训练,并且生成的摘要可能会出现语法错误或病句。总体来说,抽取式文摘自动生成方法更适合对较长的文章进行摘要生成,生成式文摘自动生成方法更适合对短文本生成摘要。
常见的抽取式文摘自动生成方法有基于图的方法、基于特征评分的方法和基于序列标注的方法等。其中,TextRank[3]算法是一种基于图模型的算法,通过构建拓扑结构图,以句子间的相似度作为权值进行迭代来对词句进行排序,并选择排序靠前的句子作为摘要。本文提出了一种基于共现关键词的TextRank算法,通过word2vec模型、同类文章共现关键词改进了原始TextRank算法向量化表示的问题,基于关键词和句子长度对迭代后的节点进行了权重修正,使用最大边缘相关算法对摘要句子选择的不足之处进行了改进。
2 相关工作及研究
2.1 TextRank算法
TextRank算法的思想来源于网页重要性排序算法PageRank[4]。PageRank算法基于其他网页到该网页的链接数量进行排序,以页面之间的链接关系来计算每个页面的重要性。而TextRank算法将每个句子或词视为PageRank算法中的网页,并将PageRank中的有向边变为无向边,根据词之间的共现关系生成权重并构造TextRank网络图。其简要步骤如下所示:
(1)将给定的文档D分割成n个句子S1,S2,…,Sn,每个句子是由单词组成的集合,之后构造网络图G=(V,E),其中,V是文档的句子集合;E是节点之间的边的集合,形如(Vi,Vj),代表节点Vi和节点Vj之间有一条边。用式(1)计算句子之间的相似度作为边的权值:
Wij=similarity(Si,Sj)=
(1)
(2)加入权值W,形成无向有权网络图G′=(V,E,W),迭代计算其中每个节点的累加权重 ,如式(2)所示:
(2)
其中,Wij表示2个节点Vi和Vj之间的权重,即2个句子Si和Sj间的相似度;In(Vi)表示指向节点Vi的边的集合,Out(Vj)表示从节点Vj出发的边的集合,其中Vi和Vj分别为待计算节点和待分享节点,故WS(Vi)为待计算节点权重,WS(Vj)为待分享节点权重;d为阻尼系数,表示从某一节点跳转到任意节点的概率。
(3)用式(2)进行迭代计算来更新每个句子节点的权重直到收敛(即某节点前后2次计算得到的权重值之差小于给定阈值),收敛后停止迭代计算。
(4)将收敛后得到的权重值排序,选取前k个权重值的节点对应的句子作为摘要句,其中k为自定义变量。
在TextRank算法中,每个节点最终得到的累加权重由该节点的自身内容和与该节点连接的其他节点给该节点的传递权重共同构成。节点的最终权重值越高,表示该节点的内容越重要、与其他节点的关系越紧密,因此可以认为该节点代表的句子较能体现原文的主题。
国内外研究人员对TextRank算法中文本向量表示、词频权重和句子相似度计算等内容进行了深入研究。文献[5]采用word2vec模型进行文本向量表示,结合词频逆句频和词向量共同计算句子节点权重,并采用最大边缘相关MMR(Maximal Marginal Relevance)算法去除摘要中的冗余。文献[6]采用TextRank算法抽取文章中的关键词,并用BM25(Best Match 25)算法计算句子间相似度。文献[7]使用自然语言预训练模型BERT(Bidirectional Encoder Representation from Transformers)进行句向量编码,根据句子位置、标题、专有名词和总结词等特征信息调整词频权重,最后将得到的摘要进行去冗余处理。文献[8]训练了GloVe(Global Vectors)词向量并将其应用到传统的TextRank算法中。文献[9]用语料训练word2vec模型并把句子转化为向量形式,将句子中关键词的覆盖率和句子与文章标题的相似度加入句子的权值计算中。文献[10]用句子长度、句子位置、特殊句子、句子与标题相似度以及每句中的主题词是否在标题出现来调整词频权重。文献[11]将标题、段落、特殊句子、句子位置和长度等信息特征引入到TextRank网络图的构造中。Barrios等[12]将句子间相同内容、最长公共字串、余弦相似度、BM25和BM25+等计算句子相似度的方法进行了对比。曹洋[13]对比了编辑距离、WordNet语义词典和BM25等方法在TextRank算法中的效果。此外还有将TextRank算法与机器学习结合或考虑更多相似文章调整词频权重的算法。例如,文献[7]用Doc2Vec模型进行文本向量化后,采用K-means算法对相似文本进行聚类,根据句子间的位置关系以及单句与标题相似度调整句子权重,最后从每类句子中选出权重最高的句子生成摘要;文献[15]在计算句子权重时将有相同主张的句子加入权重计算。
国内外研究人员对于TextRank算法的研究有效改进了TextRank算法的几个缺点:(1)原始的TextRank算法计算2个句子间相似距离时采用比较相同词语个数的方法,没有考虑语义信息,可能会使后续的迭代准确率下降;使用word2vec、BERT等模型表示文本有效解决了这一问题。(2)TextRank算法中句子节点的累加权重取决于句子间的相似度而未考虑其它特征;使用句子长度、句子位置、句子与标题相似度、总结词等特征可以更全面地考虑句子间的关系等要素,降低了高频词对结果的影响。(3)TextRank算法提取的摘要中可能包含语义重复或相似的句子,可能导致摘要全面度下降;使用MMR算法可以有效解决该问题。已有的研究对于TextRank算法的句子表示、句子权重和去冗余方面均有改进,但对于数据预处理方面的改进较少,TextRank算法在分词、停用词选择、节点初始权值设置等数据预处理方面仍有改进空间。
2.2 TF-IDF算法
TF-IDF(Term Frequency—Inverse Document Frequency)是一种统计方法,用以评估词语在语料库中的重要程度。
词频TF计算方法有2种,分别如式(3)和式(4)所示,表示词在一篇文档中出现的频率,出现频率越高,TF值越大。
(3)
(4)
逆文档频率IDF,计算方法如式(5)所示,IDF的值与词在总的语料库中出现的频率成反比,出现频率越小,说明这个词的区分度越大,IDF值越大。
(5)
TF-IDF的计算公式如式(6)所示,其在关键词抽取中的主要思想是:某个词或短语在一篇文档中出现的频率高,而在其他文档中出现的频率低,则认为该词或短语具有很好的类别区分能力,可以作为该文档的关键词。
TF-IDF=TF×IDF
(6)
2.3 最大边缘相关MMR算法
MMR算法用于计算文本与文档之间的相似度,其公式如式(7)所示:
(7)
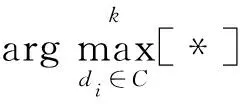
因为文章中可能会在多处用不同的语言表达文章的主要内容,这些句子相似度较高,因此抽取式文摘自动生成方法难免会产生意思重复的句子。 MMR算法多被用于去除摘要句中可能出现的冗余,使摘要的相关性和多样性相对平衡。
2.4 word2vec模型
word2vec是Google在2013年发布的一个开源词向量表征工具,可以将词表征为实数值向量。word2vec采用的模型有连续词袋CBOW(Continuous Bag Of Words)模型和Skip-Gram 2种。其中,CBOW模型能够根据输入周围n-1个词来预测这个词本身,而Skip-gram模型能够根据词本身来预测周围有哪些词。
word2vec是从大量文本语料中以无监督的方式学习语义知识的一种模型。经过训练后的word2vec模型可以把文本内容简化为K维向量空间中的向量,而向量空间上的相似度可以用来表示文本语义上的相似度。因此,某些意思相近却在传统模型中毫无联系的词通过word2vec模型可以体现出较高的相似度。
3 基于共现关键词的TextRank自动摘要生成算法
由于原始的TextRank算法只从一篇文章中提取摘要,且代表句子的节点的权重取决于该句子与其他句子的相似度,即在文中出现次数较多的词所在的句子更可能被选中,这导致某些较重要但出现频率较低的词所在的句子不被重视,且生成的摘要中会存在重复信息。针对其存在的语义无法充分表达、句中高频词对结果影响较大及摘要冗余问题,本文对TextRank算法进行改进,提出一种抽取式自动摘要技术。首先,整理出各类新闻文章常用的专有名词,在计算句子权重时,将该类文章的共现关键词加入词频权重的计算中,同时考虑句子长度和关键词等特征信息;然后,在抽取摘要后用MMR算法去除生成摘要中的冗余信息;同时,为了让算法获得更好的句向量表达,本文使用预训练好的word2vec词向量模型表示句向量。
3.1 算法流程
本文算法流程如图1所示。
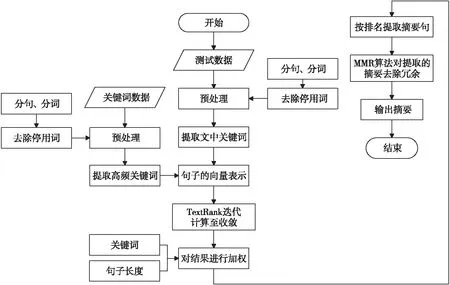
Figure 1 Flow chart of the proposed algorithm图1 本文所提算法流程图
具体步骤如下:
(1)对关键词文档的内容进行预处理。
①将关键词文档进行分词,去除停用词、标点符号以及分词后长度为1的词;
②采用TextRank算法对关键词文档中的每一条文档提取10个关键词;
③统计每一类关键词文档中的关键词,依据Gini指数(Gini Impurity)与词频相结合的方法选取词,组成该类文档的共现关键词词库。
(2)对测试文档内容进行预处理。
①计算文档中每个词的TF-IDF值,选出前5个词(若为停用词,表中的词顺延)作为关键词。
②将文档用标点符号分割为句子,生成句子集合,再对集合中的句子进行分词,去除停用词、标点以及单字词。
(3)将关键词文档与测试文档的文本转为词向量,使文本变为特征向量。
(4)构建测试文档中每个句子之间的相似度矩阵,在构建过程中加入共现关键词向量。
(5)利用相似度矩阵构建图结构,每个句子被视作一个节点,用式(8)对矩阵进行迭代计算直到收敛:
keyWS(Vi)=keywords*(1-d)+
(8)
其中,keywords表示当前输入类文档的共现关键词得到的词向量与该文本向量的余弦相似度,阻尼系数d在本文中默认取0.8。
(6)将迭代后的句子权重值进行调整,如式(9)所示:
WS′=WS*keyword*len
(9)
其中,WS表示之前计算出的句子的权值(其大小用于句子排序),keyword表示关键词权重,len表示长度权重。
①keyword计算方法:首先计算每个句子中本文关键词数量和共现关键词数量,那么每个句子的关键词权重=1+(本文关键词数量+共现关键词数量)/(所有句子本文关键词数量和+所有句子共现关键词数量和)。
②len计算方法:将长度大于最长句子长度*0.8且关键词数量少于2的句子权重置为0。将长度小于最长句子长度*0.2且关键词数量少于1的句子权重置为0。
(7)根据句子的权重值WS′选择排名靠前的s个句子作为备选摘要,其中s取值为5~8。
(8)对s句备选摘要应用MMR算法进行重新排序,MMR算法在计算权重时会减去该句子与其前面句子的相似度。
(9)输出排名靠前的3句作为最终摘要。
3.2 提取关键词
关键词抽取任务是从一段文本中自动抽出若干有意义的词语或词组。本文用TextRank和TF-IDF 2种算法提取文档中的关键词。Text- Rank算法抽取关键词时采用共现关系构造任2点之间的边,即:当2个词语在长度为K的窗口中同时出现时,代表2个词语的节点之间存在边,其中K表示每次选择词汇时的窗口大小。文献[16-18]采用TextRank算法进行关键词的提取。文献[16]考虑了词句之间的文章结构信息。文献[17]则考虑了词频、词性和词语间的语义关系等信息。文献[18]在关键词提取中加入了粗糙数据推理,分词去重后对候选关键词按照相似性划分不同的等价类,将不同等价类中2个存在关联的词及其关联值加入到关联集合中,根据关联集合构造关键词图进行迭代计算。TF-IDF算法的核心思想为:一个词在一篇文档中出现的频率越高,它对文档的贡献就越大;一个词在所有文档中出现的频率越高,它对于区分不同文档的作用就越小。因此,一个词的重要度随着它在本篇文档中出现的次数而增加,同时随着它在语料库出现的频率反比下降。该算法抽取关键词时有时更能抓住文章特有的关键词。故本文采用TextRank算法抽取共现关键词词库所需的关键词,用TF-IDF算法抽取每篇测试文档中的关键词。
3.3 共现关键词词库构建
考虑到网站对不同类型的新闻咨询进行了分类,本文选取每种类型新闻的高频关键词组成共现关键词词库。具体做法为:从同类文档的每篇文档中选取关键词,统计每个关键词在该类文档中的出现频率,选择出现频率较高的词语作为该类文档的共现关键词。共现关键词选取步骤如下:
(1)选取超高频有意义词:将关键词中出现次数大于该类新闻总篇数/50的非停用词加入关键词表。
(2)通过计算每个词在每个类中的Gini指数选取适合的中频有意义词:
①选取中频词:计算每个词出现次数/该类新闻总篇数*1000,保留大于1的词,并将结果记为频次值count。为便于第②步计算,对count进行四舍五入取整。
②计算Gini值:计算每个类中每个词的Gini值,如式(10)所示:
gini=1-(currentcount/total)2-
(othercount/total)2
(10)
其中,total表示所有类中该词总数,currentcount为本类中该词的频次值,othercount为其它类中该词的频次值。
李伟:我刚才说了,肯定还会和顺丰的市场战略配合着进行。至于具体到什么公司会被收购,我做这样的预测没有太大的意义,又不是要买股票(笑)。但我想说,2018年顺丰做得很成功,这是顺丰一个里程碑的年份,相信明年顺丰会做得更好。
③选出共现关键词:选择每类中Gini值小于0.2,且currentcount大于othercount的词。
(3)结合(1)与(2)中选出的词,得到各类的共现关键词词库。
3.4 句子长度
考虑到某些过短的句子不包含文章的主要信息,以及某些过长的句子包含的主要信息较少,本文将句子长度系数SL小于0.2且不包含关键词的句子和句子长度系数SL大于0.8且包含关键词个数较少的句子去除。句子长度系数SL的计算如式(11)所示:
(11)
其中,S表示句子的长度,SM表示句子长度中位数。
4 实验设计与结果分析
4.1 实验数据
实验使用到的数据集包括停用词表、共现关键词数据集和测试数据集。
(1)停用词表:本文对网上现存的各种停用词表(哈尔滨工业大学停用词词库、百度停用词表等)中的中文词进行整理、去重,与通用符号一起组合成本文所用停用词表。
(2)共现关键词数据集:本文提取共现关键词的数据集来自于清华大学自然语言处理实验室推出的中文文本新闻数据集,共有14类总计约80余万条新闻,从中选取娱乐、财经、体育、房产和教育类文章,从每篇文章中提取10个关键词,累加每个词出现的次数,依据3.2节的方法选取关键词组成该类文章的共现关键词词库。
(3)测试数据集:由于中文文摘自动生成没有较为通用的评估语料,因此本文测试文本数据集取自上述中文文本新闻数据集,从娱乐、财经、体育、房产和教育5类文章中,找出有标题且不存在小标题的文章,各选取20~30篇句子数超过15的长文本组成测试集。
4.2 评价方法
由于测试数据集没有参考摘要,无法用文摘生成通用评价指标ROUGE(Recall-Oriented Understudy for Gisting Evaluation)评价摘要质量。本文使用一种标题-有意义词评价方法,该方法与文献[19]中采用的评价方法的中心思想类似。由于标题往往代表着文章的中心思想,可以视为全文的简要总结,因此本文将标题去除停用词后剩下的词视为“有意义词”,并通过式(12)计算摘要效果:
(12)
其中,word表示“有意义词”个数,word′表示摘要中包含的“有意义词”个数,kw表示同时也是本文关键词的“有意义词”个数,kw′表示摘要中包含的kw词个数。通过对总数据集中抽取200条带标题的新闻进行预先评估,发现标题往往可被视作最精简的“摘要”,证明了该评价方法有较强的可靠性。同时,本文抽取acc值较高和较低的一篇摘要人工查看摘要效果。
4.3 实验设计
4.3.1 基于共现关键词的TextRank算法与其它TextRank算法对比
本节将基于共现关键词的TextRank算法与文献[9,11,20]中的算法进行对比。综合各个算法的优缺点,按照以下2个思路进行算法对比:(1)部分算法将关键词覆盖率、句子与标题相似度等引入到TextRank网络图的构造中;将特殊句子、句子位置等信息引入到权值传递中。(2)部分算法使用关键句子、与标题相似度、线索词、句子位置和特殊句子等更多要素调整句子权重,并在选择摘要时去除疑问句。需要说明的是,本文使用标题作为评判依据,并未使用其它文献中计算每个句子与文章标题相似度这一属性。
图2展示了本文所提算法、网络图改进算法和句子权重改进算法在6类新闻上的实验结果对比,可以看出,本文所提算法在大部分新闻类别上均有优势。

Figure 2 Comparison of the proposed algorithm with other TextRank algorithms图2 所提算法与其它TextRank算法对比
网络图改进算法:构造句子间的网络图时,采用式(13)代替原本的句子间相似度计算:
Wij=a×similarity(Si,Sj)+
(13)
其中,P(Sj)表示句子Sj中关键词与总词数比例,a+b=1。在网络图迭代时,文档中特殊句子(文章前两句与末句、独立成段的句子)传递权值时权值扩大1.1倍。
句子权重改进算法:得到句子权重排名后,采用式(14)重新计算权重:
NWS=WS*keyword*len*position*cueWords
(14)
其中,position表示句子位置权重,cueWords表示总结词权重,keyword和len的含义与本文所提算法的相同。
同时,再将本文所提算法与原始TextRank算法进行对比。为比较共现关键词效果,还将本文所提算法分为加入与未加入共现关键词进行对比。本文所提算法从原文中选择5句作为备选摘要,从备选摘要中选择3句作为最终摘要;TextRank算法从原文中选择3句话作为摘要,分别计算其acc值。图3显示了3种算法在各类新闻上的acc值。从图3可以发现,本文所提算法与原始TextRank算法相比,生成的摘要与标题的关联度提升明显,加入共现关键词信息后在大多类新闻中的acc值均有所提升。
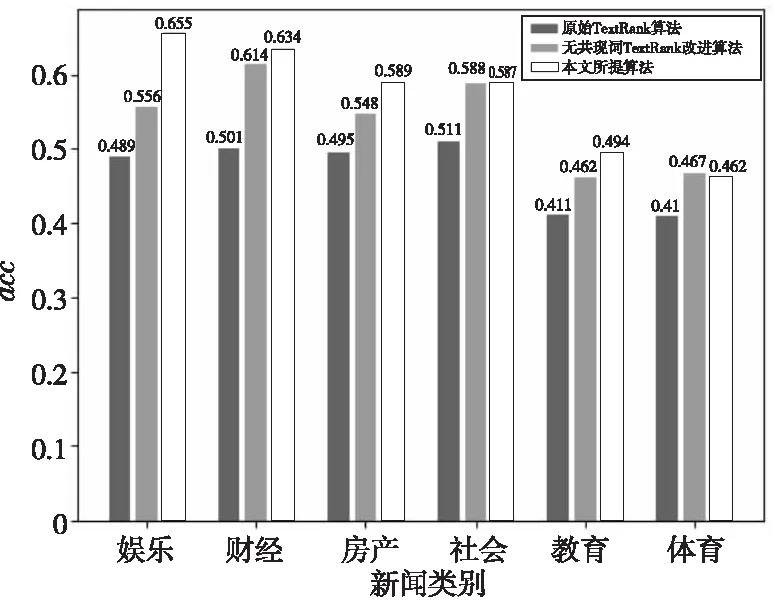
Figure 3 Experimental results comparison between the proposed algorithm and original TextRank algorithm图3 共现关键词TextRank算法 与原始TextRank算法实验结果对比
表1和表2分别给出了acc值较高和较低的摘要结果示例。从表1可以看出,评分较高的共现关键词TextRank算法生成的摘要包含了更多的标题内容,涵盖的信息也更加全面。从表2可以看出,由于原文中大部分内容与标题关联不大,因此摘要与标题关联性较低,但与无共现关键词TextRank改进算法及原始TextRank算法相比,本文所提算法生成的摘要表述更加全面,包含的信息也更多。
分析以上实验结果,体育类新闻中足球与篮球新闻较多,因此共现关键词词库中多为足球和篮球相关内容,而本文测试数据集中选择的文章分类较为平均,因此共现关键词反而影响了其他体育文章的摘要抽取。接下来,暂时排除测试数据中的体育与社会类文章,选取娱乐、财经、房产和教育4类加入共现关键词后效果提升较多的文章,研究阻尼系数d、备选摘要句数量与文中关键词数量对结果的影响。

Table 1 Abstract results with higher acc values表1 选择acc值较高的摘要结果

Table 2 Abstract results with low acc values表2 选择acc值较低的摘要结果
4.3.2 不同阻尼系数d与共现关键词的作用对句子权重的影响
本节对比了式(8)中d(共现关键词所占比重)取不同值对本文所提算法性能的影响。如图4所示,d取0.3,0.6,0.8时,无论d增大还是减小,acc值变化不大,但均高于不计算共现关键词文本时的acc值,表明共现关键词对原始TextRank算法的迭代计算权值起到了优化效果。
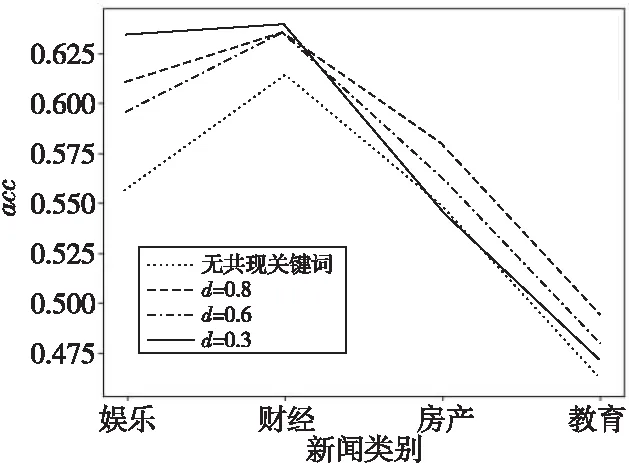
Figure 4 Influences of proportion of co-occurrence words on summary quality图4 共现词所占比重对摘要质量影响
4.3.3 MMR算法去除冗余的有效性
本节选择不同数量的句子作为备选摘要,均通过MMR算法抽取3句生成最终摘要,以测试MMR算法的有效性。从图5可以看出,备选摘要句越多,生成的最终摘要acc值越高,表明备选摘要句越多,生成的摘要内容越丰富,与标题关联度越大,实验结果表明了MMR算法可以有效去除句子中的重复部分,在信息较多时可以保证生成信息的全面性。
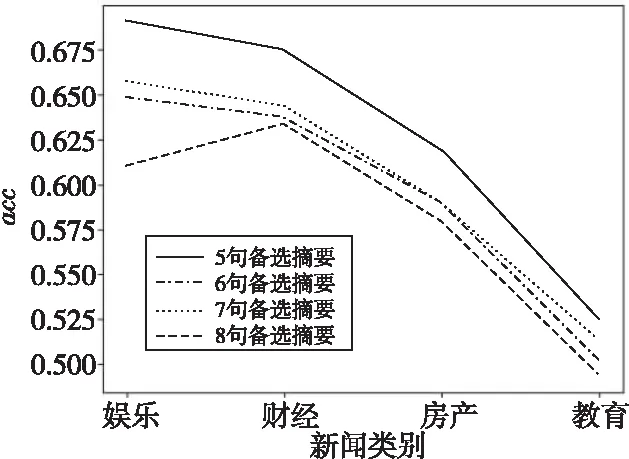
Figure 5 Influence of different number of alternative summaries on summary quality图5 不同数量备选摘要对摘要质量影响
4.3.4 测试文本中选取不同数量关键词
本文算法用文中的关键词来调整迭代收敛后的句子权重值,通过比较图6中选取不同数量关键词得到的acc值可知,更多的关键词(即更多的文中信息)可以提高生成摘要的准确性。该结论与常识中包含越多关键词的句子越重要相符。
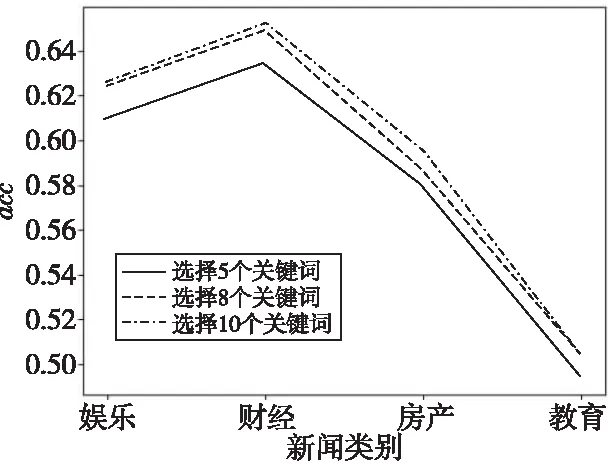
Figure 6 Influence of different number of keywords on summary quality图6 不同数量关键词对摘要质量影响
实验数据对比表明,本文所提算法中采用的加入关键词文本计算、根据句中包含的关键词数量调整权重和MMR算法均可以提升摘要质量,证明了本文所提算法的有效性。
4.3.5 测试关键词与句子长度对句子权重的修正效果
为验证关键词与句子长度对句子权重的修正效果,本节比较是否修正句子权重在各数据集上的输出结果。由图7的结果可知,在大多数类别上经过关键词与句子长度的调整后生成的摘要质量有所提升。
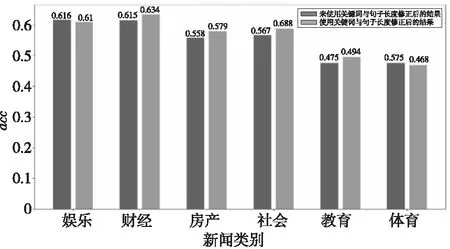
Figure 7 Influence of keywords and sentence length weight on summary quality图7 关键词与句子长度权重对摘要质量影响
具体比较是否使用关键词和句子长度修正句子权重排序的结果发现,绝大多数修正后的句子权重排序有所变化,如果将排名前5~8句的句子作为整体考虑,约有40%的结果发生变化。人工校对部分结果表明,权重修正起正面效果的占多数,与图7中的结果相吻合,表明关键词与句子长度对句子的权重能起到修正作用。
5 结束语
本文在综合对比应用TextRank算法自动生成摘要的过程中,找出其关键技术是句子的权重计算,提出了一种将该类文章共现关键词加入计算,同时考虑了文中关键词和句子长度,并加入了最大边缘相关算法去除冗余的算法。实验结果表明,生成摘要的全面性和准确性均有所提升,可以较好地反映原文主要内容。但是,本文所提算法依然有抽取式摘要自动生成方法普遍存在的句子之间通顺性较差、可能存在重复信息等问题。下一步拟与生成式摘要自动生成方法相结合,将摘要内容进一步缩短且保留其主要信息。
