基于异构信息网络的推荐研究综述
2023-11-17汪春播温继文
汪春播,温继文
(北京林业大学经济管理学院,北京 100083)
1 引言
推荐作为大数据时代的一种数据服务方式,有效解决了用户面临的信息过载问题[1],因此受到国内外研究人员的广泛关注,并在电子商务、社交媒体和科研教育等领域扮演着重要角色。推荐系统的概念最早由Resnick等[2]提出,其主要思想是依据用户的历史行为或相似性关系来给用户推荐其可能感兴趣的项目。传统的推荐方法主要有基于内容的推荐方法、基于协同过滤的推荐方法和混合推荐方法3种。基于内容的推荐方法利用推荐对象之间的特征相似度,通常需要进行复杂的对象特征建模和提取,其有效性和可扩展性有限;基于协同过滤的推荐方法则是从用户的历史行为偏好中发现规律以进行推荐,但会面临用户和物品之间行为关系数据稀疏的问题,以及面对新用户或推荐新物品时的冷启动问题;而混合推荐方法是将能够获取到的多源辅助信息融合到推荐方法中,虽然能一定程度应对数据稀疏和冷启动问题,但因为辅助信息的多模态、异构性、规模大、不均匀等特点,混合推荐方法的研究还需要攻克很多难点[3]。
异构信息网络的提出为推荐系统的进一步优化创造了可能性[4]。异构信息网络的不同类型的节点和链接代表了不同类型的对象和关系,将丰富的语义集成在了一起,通过对异构信息网络的分析能捕捉更多的重要信息[5],使推荐系统达到更好的效果。相比于传统的推荐技术,基于异构信息网络的推荐技术能够克服数据稀疏问题,能够较好应对推荐系统的冷启动问题,且具有可解释性,充分利用项目之间的语义信息,获得准确且多样的推荐结果[6]。
目前,国内外基于异构信息网络的推荐研究已积累了一定的成果。本文基于文献调研和文献题录信息统计工具SATI(Statistical Analysis Toolkit for Informatics)[7]和社会科学统计软件包SPSS(Statistical Package for the Social Sciences)Statistics的计量分析结果进行综述,将当前研究分为算法研究和应用场景2大类。异构信息网络推荐算法主要有基于聚类、随机游走、元路径、矩阵分解和网络嵌入的算法;应用场景主要有学术科研、兴趣点、Web服务和社交好友等。最后提出未来的研究展望。
2 相关概念
2.1 异构信息网络
当前大多数关于网络科学、社交和信息网络的研究,通常假设网络中的节点都是相同实体类型的对象,其中关系都是相同关联类型。然而,实际生活中的大多数网络节点或关系并不是相同类型的,因此称之为异构信息网络(Heterogeneous Information Network)。
一个有向图G=(V,E),有对象类型映射函数φ:V→A和链接类型映射函数ψ:E→R,其中,V为对象集,E为边集,A为对象类型集,R为链接类型集。每个对象v∈V具有特定的类型φ(v)且φ(v)∈A,每条边e∈E具有特定的类型ψ(e)且ψ(e)∈R。假设2个链接是相同的类型,则构成链接的起始对象和结束对象的类型都必须相同[4]。当信息网络中的对象类型满足|A|>1或者关系类型满足|R|>1时,即为异构信息网络,否则为同构信息网络。网络模式可以描述异构信息网络中不同类型的对象和链接,是网络G=(V,E)的一个元模板,形为TG=(A,R)。以文献网络为例,它包含4种类型的实体:文章(P)、刊物(V)、作者(A)和术语(T),其网络模式以及该网络的一个实例如图1所示。
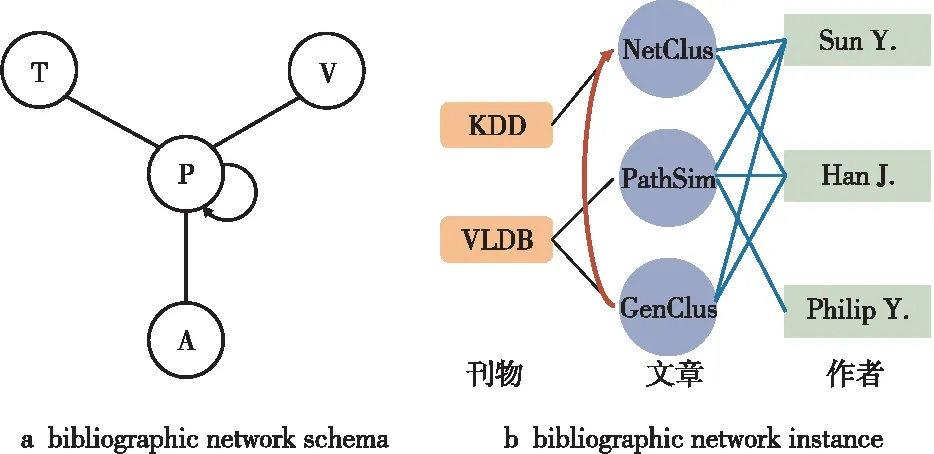
Figure 1 Bibliographic network schema and bibliographic network instance图1 文献网络模式和文献网络实例
2.2 基于异构信息网络的推荐
在常见的推荐场景下,“用户-项目”的异构信息网络包含了用户、项目以及用户和项目之间的相互连接,因此通过网络挖掘可以发现用户和项目之间的深层关系[8],从而弥补了协同过滤推荐中的用户与项目交互数据稀疏和冷启动的问题。另外,利用网络中多个链接组成的路径,可以描述用户和项目之间的不同语义关系,依据这种语义关系进行推荐使得推荐系统更具可解释性。由于基于异构信息网络的推荐系统的独特优势,使其逐渐受到学术界和商业领域的重视。
基于异构信息网络的推荐过程主要有3个环节:(1)网络建模:依据实际的推荐场景的实体与相互关系确定异构信息网络模式,将实体映射到网络中的节点,将关系映射为网络中的链接。(2)网络分析:决定使用何种算法分析网络,如实行随机游走获得节点排名[9,10]、构造元路径度量节点之间的相似度[8,11,12]、使用网络嵌入得到节点的特征表示再计算相似度[13,14]等。(3)生成推荐列表:利用节点的排名或相似度得到Top-K推荐列表,有研究人员结合用户项目的交互数据实现协同过滤推荐[15-19],或结合用户兴趣和反馈信息实现个性化推荐[20-23]。
3 研究概况分析
本文采用文献计量和可视化图谱对基于异构信息网络的相关文献进行分析。国内研究选择CNKI核心期刊和学位论文作为数据源,以“(异构信息网络+异质信息网络)*推荐”为检索项对主题进行检索;国外研究选择Web of Science核心合集作为数据源,以“主题:(heterogeneous information network) AND 主题:(recommendation)”为检索项对主题进行检索。检索时间为2021年1月30日,初步收集中文文献110篇,英文文献226篇,人工剔除与目标研究主题无关的文献,最后选取74篇中文文献和61篇英文文献作为本文的文献来源。
在文献计量分析中,利用SATI进行文献描述统计、字段抽取、矩阵生成;利用社会网络分析工具Ucinet和NetDraw绘制关键词网络知识图谱;利用SPSS Statistics进行关键词聚类分析。
3.1 文献数量统计
文献发表时间的统计结果可以直观反映出研究领域的热度变化趋势。国内外基于异构信息网络的推荐研究的文献时间分布如表1所示。从2014年至2020年,研究数量的增长态势表明这一主题的研究一直在升温,研究内容也更加深化,技术应用更加广泛。

Table 1 Annual distribution of literature quantity表1 文献数量的年度分布
3.2 关键词抽取与频次统计
关键词是文献内容的核心体现,能够很大程度反映研究的重点与热度。本文依据文献关键词出现的频次高低分别列出国内外基于异构信息网络推荐研究的前30个高频关键词,如表2和表3所示。本文采用SATI中默认的数据预处理方法,只对标点符号、大小写、单复数及词干提取的形变进行处理。

Table 2 High frequency keywords list of domestic research 表2 国内研究高频关键词列表
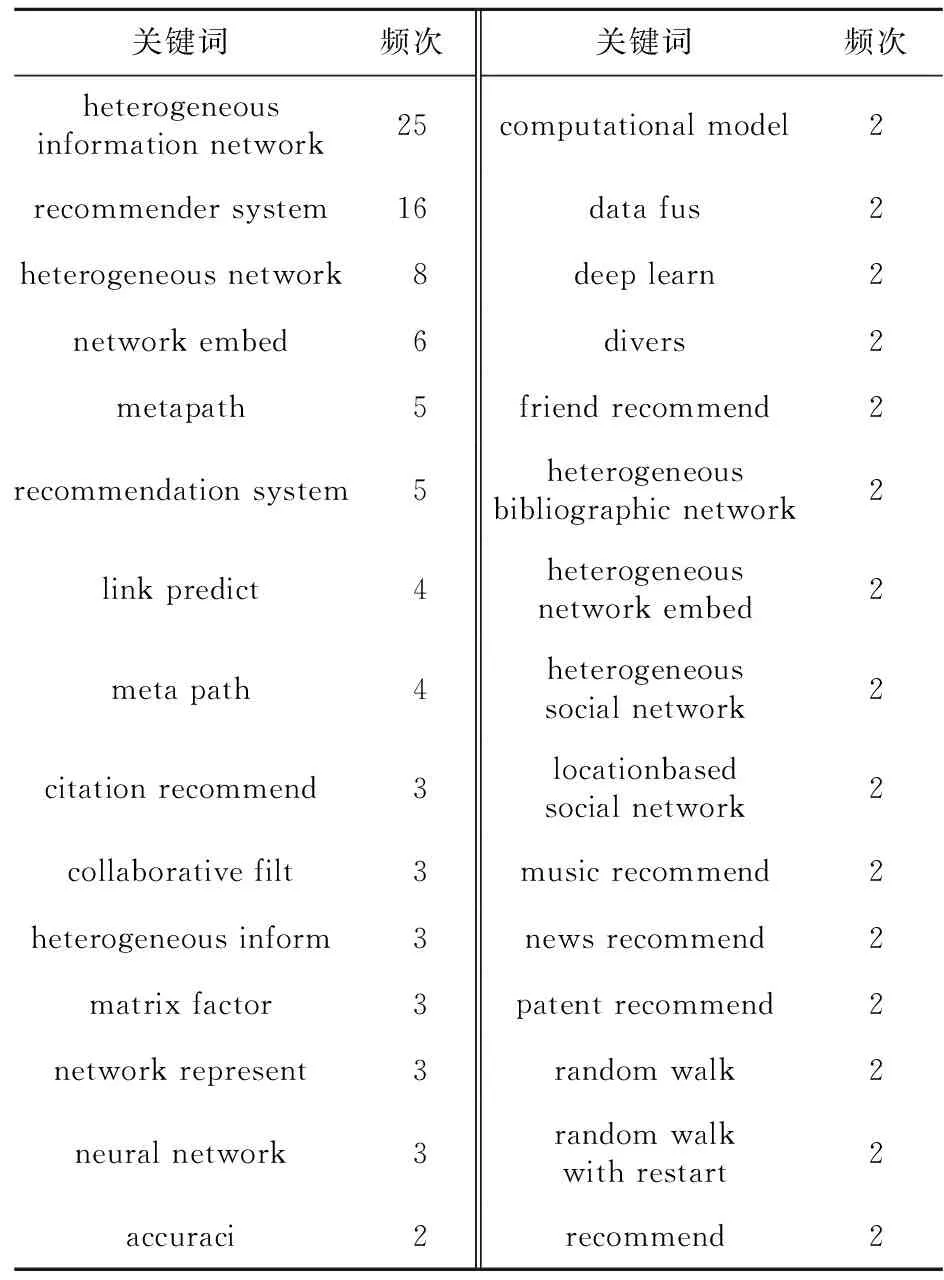
Table 3 High frequency keywords list of foreign research 表3 国外研究高频关键词列表
3.3 共现网络知识图谱
共现关键词可以形成共词网络,引入社会网络分析方法能够探究领域内研究主题的中心程度。这里使用SATI抽取30个高频关键词字段,计算得到关键词的等价共现相似矩阵(30×30),将其导入Ucinet和NetDraw中绘制网络知识图谱,生成图谱如图2所示。网络中节点代表关键词,节点位置越居中表示关键词越核心,节点大小代表中心度的高低,节点之间连线粗细代表关键词之间的紧密程度。

Figure 2 Co-occurrence network knowledge graph of high frequency keywords图2 高频关键词共现网络知识图谱
从图2a可以看出,“元路径”的位置靠近共现网络的中心,有很高的中心度,与“异构网络”和“异质信息网络”连接紧密,靠近共现网络中心的还有“矩阵分解”“协同过滤”“深度学习”。从图2b可以看出,关键词“network embed”“neural network”“citation recommend”较为靠近网络中心,并与“recommender system”和“heterogeneous information network”有较多联系。
3.4 聚类分析
聚类分析通过聚类算法将相近的主题聚集形成类团,基于文献关键词的共现聚类分析能够识别研究领域的主题结构。利用SPSS Statistics软件对等价共现相似矩阵进行系统聚类,其中聚类处理方法为组间连接,数据度量标准为计数(卡方度量)。图3为SPSS Statistics系统聚类得到的使用平均连接(组间)的树状图。
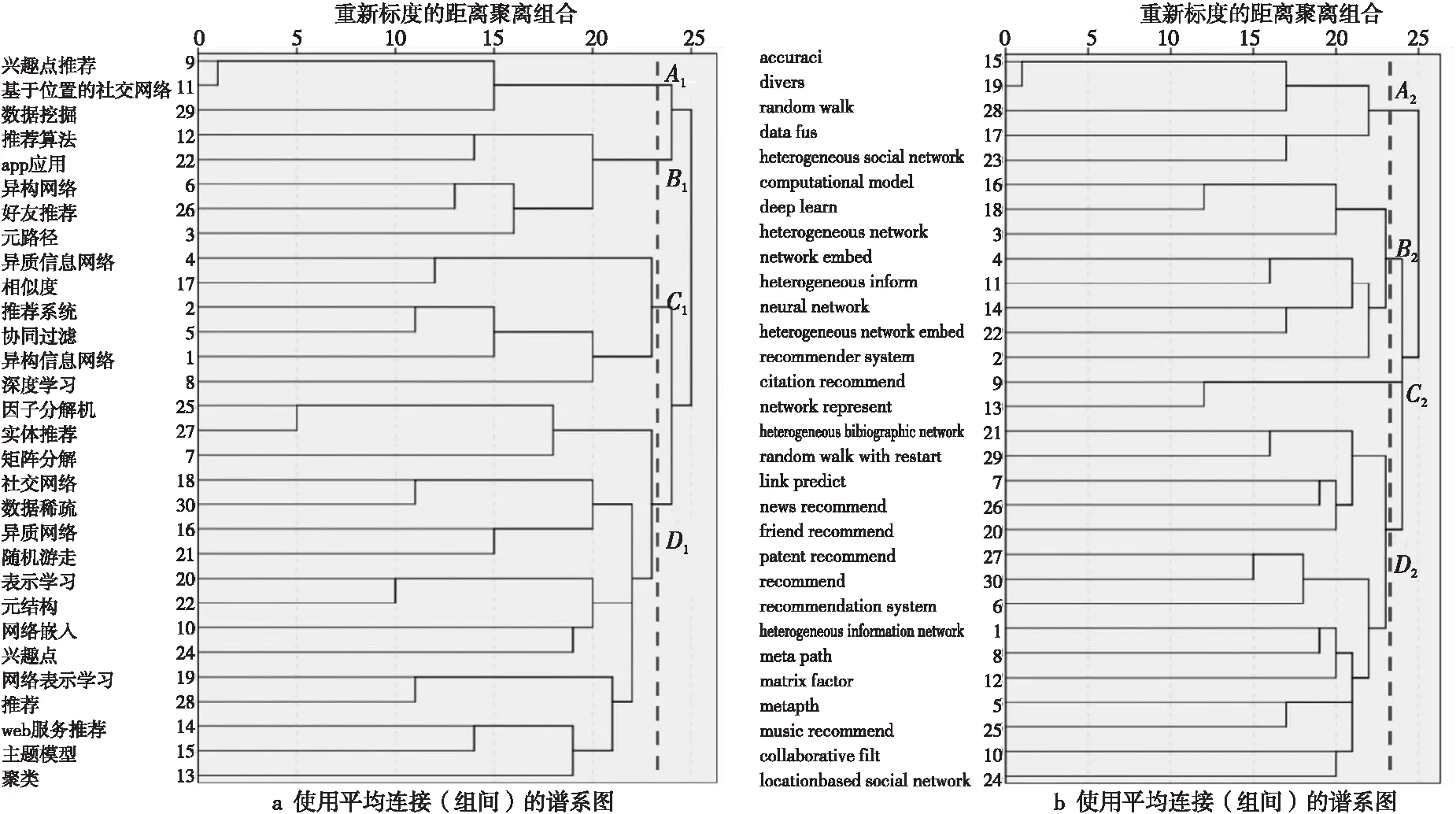
Figure 3 Cluster tree of high frequency keywords图3 高频关键词聚类树状图
依据高频关键词聚类树状图,国内和国外研究的聚类类团分别划分为A1、B1、C1、D1和A2、B2、C2、D2。依据各个类团的关键词可以将其分为2类,其中类团C1、D1和A2、B2对应的研究主题为基于异构信息网络推荐的算法研究,包含的关键词有:相似度、协同过滤、深度学习、因子分解机、矩阵分解、数据稀疏、随机游走、表示学习、元结构、网络嵌入、网络表示学习、主题模型、聚类、random walk、data fus、deep learn、network embed、neural network和heterogeneous network embed等;类团A1、B1和C2、D2对应的研究主题为基于异构信息网络推荐的应用研究,包含的关键字有:兴趣点推荐、基于位置的社交网络、app应用、好友推荐、citation recommend、heterogeneous bibliographic network、news recommend、friend recommend、patent recommend、music recommend和locationbased social network等。
4 基于异构信息网络的推荐算法研究
基于异构信息网络推荐的算法研究的关键技术包括网络聚类、在网络中实行随机游走、基于元路径度量节点相似度、矩阵分解,以及网络嵌入算法等。
4.1 基于聚类的推荐算法
Sun等[24]提出的异构信息网络聚类算法RankClus能够在双类型信息网络中实现聚类,通过排序和聚类的迭代实现排序和聚类质量的共同提升。NetClus算法[25]则拓展实现了对包含3种及以上类型对象的网络的聚类。
RankClus和NetClus的提出为异构信息网络的推荐提供了新的思路,即采用迭代的排序和聚类算法来得到推荐候选列表,如有研究人员依据NetClus算法实现了商品推荐[26]和药物推荐[27]。类似地,赵焕[28]改进NetClus后提出了MAO-NetClus算法,以应对多个同类型节点连接单个目标节点的情况,并将聚类结果结合协同过滤实现Web服务推荐。
在异构信息网络中实施聚类分析,覆盖网络范围更广,具有一定全局性,可以结合协同过滤进行推荐,同时聚类算法还需要解决大规模数据的耗时问题,另外排序函数的质量对推荐效果也至关重要,针对不同领域问题算法需重新考虑排名函数的规则。
4.2 基于随机游走的推荐算法
随机游走是从指定节点开始,以某一概率随机向相邻节点游走,持续这种游走行为就会达到一个稳定的状态,可以依据稳定状态下节点被到达的次数进行节点排名。ROUND算法[9]在异构信息网络中实行重启随机游走来表征对象节点和用户节点之间的关联强度,在“对象-用户”的双类型信息网络中实现个性化推荐,其中面临的不可靠链接使用k近邻策略来剔除。Trinity[10]在此基础上拓展到包含3种类型的“对象-用户-标签”网络。另外Zhou等[29]设定重要度量来加权网络中的链接,从而决定随机游走的重启概率。
基于异构时空图的重启随机游走RWR-HST(Random Walk with Restart on Heterogeneous Spatio-Temporal)算法[30],可以充分捕获“用户-用户”相似性和“用户-位置”相关性。赵海燕等[31]提出的时间和位置感知的个性化活动推荐TLAR(Time and Location-aware Activity Recommendation)算法,能够在包含用户、地点、时间、活动、朋友关系的异构信息网络中利用随机游走算法进行推荐,相较于流行活动推荐和基于社会关系的活动推荐优势明显。
随机游走的过程可以探索对象之间的潜在链接,度量较远对象的关联程度,且适用于大多数异构网络模型,但基于随机游走算法的缺点在于计算复杂度较高,且冷启动问题依然存在。
4.3 基于元路径的推荐算法

元路径描述了节点之间的关联性,不同的元路径包含节点间不同的语义关系,通过元路径查找相似节点为异构信息网络的推荐打开了新的突破口。Shi等[32]引入了加权异构信息网络和加权元路径的概念,设计了基于语义路径的个性化推荐SemRec(Semantic path based personalized Recommendation)算法,不仅能灵活地集成异构信息,还可以学习路径上用户偏好的优先权和个性化权重。有研究人员将注意力机制引入基于元路径的推荐算法中,使得重要的元路径语义更加突出,为推荐模型带来更好的可解释性[33-35]。人工选择元路径时,常存在路径权重优化的过度拟合问题,Liu等[36]提出通过权重优化来自动选择和组合元路径,提高了元路径语义的多样性和推荐的性能,此外三重注意力神经网络TANN(Tri-Attention Neural Network)推荐算法[37]还可以通过螺栓遗传算法自动选择元路径。
基于元路径的推荐算法通过选择或加权、组合不同的元路径来为不同的应用模型实现语义推荐,灵活度高,是近年基于异构信息网络的推荐研究工作的重要基础。但是,基于元路径的算法依赖于节点间路径的可达性,在路径稀疏或混乱的网络中的推荐结果可能并不理想。
4.4 基于矩阵分解的推荐算法
矩阵分解技术采用低维特征向量来表示用户对项目的偏好程度以及用户和项目拥有的属性特征,基于异构信息网络分析的“用户-用户”相似矩阵与“用户-项目”评分矩阵结合后得到一个拟合评分矩阵,从而预测用户对项目的评分。如张邦佐等[38]和王根生等[39]分别利用HeteSim和 PathSim计算用户间的相似度矩阵,再与评分矩阵融合进行矩阵分解,实现协同过滤推荐。Shi等[40]提出基于矩阵分解的双重正则化框架SimMF,通过采用用户和物品的相似性作为对用户和物品潜在因子的正则化,从而灵活地集成不同类型的信息。基于注意力的正则化矩阵分解ARMF(Attention-based Regularized Matrix Factorization)[41]以双线性方式将注意力机制引入到矩阵分解中构建推荐模型。不同用户评分的物品数量不同,因而用户之间的相似关系是非对称的。赵传等[42]提出在均方差相似度公式的基础上使用非对称系数,结合加权元路径衡量用户的非对称相似度。
虽然矩阵分解算法需要提升计算海量数据的效率,但矩阵分解和异构信息网络分析相结合的方法很好地解决了传统协同过滤推荐的数据稀疏和冷启动问题。
4.5 基于网络嵌入的推荐算法
随着网络规模扩张,网络中每个节点与很少的节点关联,传统网络表示方法的特征向量将是超高维且稀疏的。网络嵌入的目的在于将网络中的每个节点映射为低维空间上的特征向量,并保留了网络的结构信息,通过网络嵌入还可以继续进行网络的节点重要性、社区发现和链接预测等研究工作。同构信息网络的嵌入研究较早,代表性的算法有DeepWalk[43]、大规模信息网络嵌入LINE(Large-scale Information Network Embedding)算法[44]和node2vec[45]等。metapath2vec[46]和HIN2Vec[47]最早实现了异构信息网络的嵌入。网络嵌入技术的引入,可以更好地提取异构信息网络中节点的特征。
利用网络嵌入来生成异构信息网络的潜在特征表示,将潜在特征表示向量结合评分预测算法或相似性度量算法,从而得到推荐列表。Shi等[13]提出的推荐算法从异构信息网络中依据几组对称元路径抽取相同类型的节点,形成几个同构信息网络,对其使用DeepWalk得到对象的潜在特征,再将几组不同的潜在特征集成到矩阵分解中,实现评分推荐。异构网络嵌入推荐HetNERec(Heterogeneous Network Embedding-based Recommendation)算法[14]提取多个用户和物品的共现关系来构造共现网络,通过将多个异构网络嵌入的特征表示集成到单个特征表示的方法提高推荐性能。郑诚等[48]采用异构Skip-Gram模型,并引入神经网络算法替代矩阵分解处理加权融合后的特征向量实现评分预测。Xie等[49]的注意力元图嵌入推荐AMERec(Attentive Meta-graph Embedding Recommendation)算法,利用注意力机制学习每个元图的权重,然后通过用户和项目基于元图的上下文的低维和多维交互信息来预测评分,增加了推荐算法模型的可解释性。
基于网络嵌入的推荐算法有效克服了网络的稀疏性问题,可用于复杂网络,捕获更丰富的语义,并能集成多种辅助信息,是基于异构信息网络推荐研究的热点。基于异构信息网络的推荐算法研究总结如表4所示。另外,深度学习的发展促进了有用数据潜在特征表示的自动学习,可以降低异构信息网络中复杂任务的计算成本,已有不少研究人员将深度学习应用到推荐算法中。龙方正[50]以自动编码机作为基础提出嵌入图AAGE(Autoencoder based Attributed Graph Embedding)算法,设计了基于嵌入网络推理的ENBI(Embedding Network-Based Inference)算法并应用在二部图的推荐任务中;吕振[18]实现了将贝叶斯深度学习和节点特征学习方法相结合来进行推荐;温玉娇[51]提出的基于神经网络模型的协同过滤推荐HINCF(Collaborative Filtering based onHeterogeneous Information Network)框架,可以在面对新用户时发挥较好效果;陈星合[17]提出了基于信任网络的深度矩阵分解算法和基于路径的深度协同过滤推荐算法,前者能对用户间的信任关系进行预测,后者结合用户和物品的特征向量及其上下文信息的特征向量使用全连接层进行评分预测。
5 基于异构信息网络的推荐应用场景
基于异构信息网络推荐的应用研究,主要是在特定场景中围绕具体推荐对象,解决实际推荐问题。表5展示了异构信息网络推荐的应用场景、相关研究数量、代表研究及其关键技术。
5.1 学术科研
随着学术科研的发展,引文推荐和科研合作推荐逐渐受到了学界的关注。异构文献网络主要包含文献、研究人员、刊物、主题和所属机构等实体,主要的关系有研究人员与文献之间的著作关系、文献与文献之间的引用关系、文献与刊物之间的刊登关系、文献与主题之间的包含关系,以及研究人员和所属机构的隶属关系等。
(1)引文推荐。
日益增长的科学文献数量带来了很大的检索困难,研究人员需要快速准确地找到相关参考文献。当前的文献推荐的工作常会将异构文献网络和很多辅助信息结合,如利用文献的内容信息和研究人员的描述信息[63]以及用户的隐式反馈[64]等,基于异构网络嵌入的文献推荐PR-HNE(Paper Recommendation based on Heterogeneous Network Embedding)模型[54]还从多个信息网络中捕捉研究人员和论文的动态。在引文推荐中,新文献由于没有被引记录和浏览记录等历史信息,以往算法对其推荐的效果并不理想,文献[53]通过合并元路径的方法针对性地解决了新文献推荐的冷启动问题。当2篇文献之间没有可达路径时,基于元路径的算法无法度量其相似性,而基于引文倾向的推荐算法可以解决这一问题[52],且其性能也要优于前者[65]。

Table 4 Key technologies and typical algorithms of recommendation based on heterogeneous information network表4 基于异构信息网络推荐的关键技术和典型算法

Table 5 Application scenarios and representative researches of recommendation based on heterogeneous information network表5 基于异构信息网络推荐的应用场景和代表研究
(2)合作推荐。
当前,科研合作的最常见形式是基于文献的研究人员合作[66],也就是基于异构文献网络进行科研合作推荐。根据合作目的的不同,科研合作推荐可以分为2种:一种是推荐其研究方向相似的研究人员,以帮助其在该领域实现高水平研究成果,常见思路是在网络中度量研究人员之间的相似度,试图推荐相似的研究人员,如利用重启随机游走算法[29]、融合多种元路径[67]和采用网络表示学习[55]等技术;另一种是出于促进多学科交叉融合的目的,组建来自不同领域拥有不同技能的科研团队,如团队形成算法SkillsFirst[68]将异构信息网络转化为一个完全图,依据项目工作要求的技能来构建最小生成树去选择成员组成团队。除了基于文献的研究人员合作,Xu等[69]立足在线学术社区,进行“学术朋友”的推荐以促进科研合作。
在学术科研领域的推荐研究中,常使用的数据集有计算机科学文献库DBLP(Digital Bibliography &Library Project)和计算语言学协会年会文集网络AAN(ACL Anthology Network)。DBLP由计算机科学和相关领域的文献数据组成,目前涵盖超过500万篇文献;AAN规模较小,包含计算语言学和自然语言处理相关的23 766篇文献。
5.2 兴趣点
基于LBSN(Location-Based Social Network)的个性化兴趣点推荐是近几年的研究热点。兴趣点是指现实生活中的地点,通过兴趣点的推荐,不仅帮助用户快速了解周围环境,而且为服务提供者招揽更多客户。用户和兴趣点是LBSN中最主要的2类实体,用户在兴趣点签到,同时用户之间存在好友关系,兴趣点之间有相关关系。由于每位用户访问的兴趣点数量有限,使得签到数据非常稀疏,有研究人员使用加权异构网络模型[70]、二分网络嵌入算法[56]以及将社交关系、用户互动以及用户评论纳入推荐考虑[71],以解决数据稀疏性的问题。由于用户兴趣是动态变化的,需要将时间因素引入到推荐模型中,康来松等[72]提出使用加权元路径对地理位置、社交关系和时间周期进行建模;李全等[73]将时间信息融入到用户和兴趣点的语义关系中,进而实现动态的兴趣点推荐。兴趣点推荐研究中使用的数据集一般来自于基于位置的社交平台,用户在平台中向好友分享签到信息以及位置信息,常见的数据集有Gowalla、Foursquare、Weeplaces和Brightkite等,它们主要记录了用户在某一地区的兴趣点的签到数据。
5.3 Web服务
Web服务是应用程序开发的基本元素,是一个开放性、跨平台、低耦合和可重复使用的软件功能。随着Web服务数量的快速增长、类型的不断变化以及请求者需求的个性化,服务的推荐对基于服务的系统开发至关重要[57]。基于异构信息网络的Web服务推荐模型通常包括服务、用户、服务提供商和服务类型等多种实体。由于服务资源数量巨大且语义稀疏,有研究人员使用聚类技术来进行服务推荐[28,74]。用户兴趣也是Web服务推荐的关键点,Xie等[75]利用群组偏好来实现个性化推荐。一些公开的Web服务平台如PWeb和Mashape(已更名为 Kong Inc.)为Web服务推荐研究提供了数据基础,另外有研究使用香港中文大学开发的WS-Dream数据集,其可用于Web服务的可靠性评估和其他相关研究。
5.4 社交好友
好友推荐是社交网络平台中的重点研究内容。在当前的好友推荐研究中,主要有3个出发点:友情、兴趣和位置。基于友情的好友推荐主要考虑好友关系和社交相似度等;基于兴趣的好友推荐主要依据用户间的兴趣相似度;基于位置的好友推荐则考虑用户访问地点的相似性。杨家红等[76]考虑了用户之间的好友关系、用户与签到点的签到关系和签到点之间的相关关系来进行好友推荐;Kefalas等[30]构建了包括用户、位置和会话的三元异构时空社交网络,设计了一种基于时间维度的新颖推荐算法以捕捉用户随时间变化的偏好;朱文强等[59]提出的用户本地信任网络模型ULTNM(User Local Trust Network Model)融合了用户社交圈相似度和兴趣偏好相似度等特征。当前的社交好友推荐研究使用的公共数据集主要来自于消费者点评网站如Yelp和Epinions,以及社交平台如Gowalla和Foursquare等,这些数据集记录了用户的兴趣、评分以及好友关系等信息。
5.5 专利交易
专利推荐一定程度上解决了专利交易中的信息不对称问题,实现了供需双方的精确匹配,成为促进专利交易的重要手段。当前研究主要利用专利技术交易信息中的专利技术、专利主体和专利购买方等实体,以及技术领域、专利引文等属性来构建异构专利网络。Wang等[77]依次采用了元路径语义的推荐来满足专利购买方的不同动机;何喜军等[60]从专利主体之间的有效对接出发,以专利主体为对象进行推荐,并通过实证研究证明考虑主体间技术邻近、经济圈邻近、主体间从属关系、共申请关系以及印证关系可以使推荐结果精度更高。如何区分相同词在不同上下文中的意思,以及将表示相同意思的不同词联系起来,是专利推荐面临的一大困难。Chen等[61]利用专利主题词结构学习和词嵌入解决了这个问题。专利交易推荐研究大多使用科技创新情报平台IncoPat和美国专利商标局USPTO(United States Patent and Trademark Office)公开的数据集。
5.6 新闻
新闻推荐的特殊性在于2点:一是新闻的更新频繁使得用户与其交互数据稀疏,二是不仅要考虑用户的长期兴趣还要捕捉用户对新闻热点的短期兴趣。Hu等[62]提出使用用户、新闻和主题之间的交互行为来构建网络,将新闻主题与用户兴趣结合以减轻用户和新闻交互数据稀疏性的影响,并利用用户点击和阅读历史来确定用户的长期兴趣和短期兴趣。Symeonidis等[78]则构建了一个由用户、新闻、新闻类别、地点和会话组成的动态异构网络,从中捕捉用户会话所隐藏的短期兴趣。新闻推荐研究的实验数据基本来自于新闻平台,如Adressa数据集,由挪威科技大学和当地报纸Adressavisen合作发布。
6 结束语
由于异构信息网络蕴含了不同类型节点和关系的复杂语义,使其在推荐系统中的应用逐渐受到学界和商业领域的重视。当前异构信息网络的推荐主要基于聚类、随机游走、元路径、矩阵分解和网络嵌入的算法,一定程度克服了传统推荐算法的冷启动、数据稀疏以及可解释性的问题,另外在学术科研、兴趣点、Web服务和社交好友等推荐场景实现了广泛的应用,但在不同场景面临着不同难点。目前异构信息网络的推荐研究并未完全成熟,还有较大发展空间,未来的研究重点主要有3个方面:
(1)动态异构信息网络的推荐系统。
当前的异构信息网络推荐研究大多是立足静态的数据,在训练和测试推荐系统时也是使用提前获取的历史数据,这并不能满足实时变化的推荐需求,如兴趣点推荐、新闻推荐、商品推荐等场景的对象更新频繁,对推荐的实时性有较高要求。另外不断生成的用户反馈数据也值得利用。结合用户偏好和项目特征的动态变化构建动态异构信息网络,并利用实时的反馈数据及时优化推荐结果将是未来的研究趋势之一。
(2)融合深度网络表示学习。
在异构信息网络中使用网络表示学习算法来完成推荐的方法已被很多研究人员采用,但目前研究中的网络表示学习算法主要是以DeepWalk、Skip-Gram和matapath2vec等浅层模型为基础[79],而随着数据量不断扩增,网络中将会有更多数量且更多种类的节点和关系,网络规模不断扩大,网络结构也更加复杂,数据稀疏问题更加突出,在这种情况下引入深度神经网络来进行网络表示学习将给推荐系统带来更好的性能。
(3)拓宽应用场景。
异构信息网络推荐在学术科研、社交好友和Web服务场景有较多的应用,但是目前在电商平台、生物科学和社会标签等常见推荐场景的研究成果不多。不同推荐场景具有不同难点,未来需要突破不同场景下构建网络的特殊性和计算复杂性,拓展异构信息网络推荐的更多应用。
