融合标签信息的分层图注意力网络文本分类模型
2023-11-17杨春霞马文文
杨春霞,马文文,徐 奔,韩 煜
(1.南京信息工程大学自动化学院,江苏 南京210044;2.江苏省大数据分析技术重点实验室,江苏 南京 210044)
1 引言
作为自然语言处理文本分类核心任务之一,单标签文本分类SLTC(Single Label Text Classification)旨在准确预测文本信息的类别倾向,在情感分析、新闻检测和垃圾邮件识别等多个场景均有广泛应用。由于近年来推特、微博和博客帖子等在线内容量爆发式增长,大量未经规范的文本数据、与用户交互的数据无疑增加了分类的难度。因此,为了更高效地分析、处理这些触手可及的文本数据,需要进一步完善和提高分类技术的研究。
SLTC按照文本自身所含内容进行分类。例如,一篇新闻评论报道可归属为“娱乐”“饮食”或“军事”等主题。分类准确的关键在于有效地挖掘文本特征信息。对于文本特征信息的提取,目前越来越多的研究人员[1-3]热衷于使用图神经网络算法构建模型,提升文本分类精度。虽然目前基于图神经网络模型可以直接从文本的图结构数据中有效挖掘其局部或全局信息,获取文本主要特征信息,但是直接把文本作为长序列进行处理,不仅会降低模型性能,同时也会忽略文本层次结构中包含的信息。因此,Ding等人[4]在词和句子2个层面,利用分层图注意力网络进行文本分类,取得了不错的分类效果。然而,分层图注意力网络在训练过程中通常随机初始化一个参数向量作为所有类别的目标向量,不能较好地关注到具有明显类别的词,所以如何通过优化图注意力网络更好地对文本特征进行提取是目前亟待解决的一个问题。
除了对文本进行特征信息的提取,最近Xiao等人[5]在多标签文本分类任务中将所有文本标注的标签信息融入到文本信息中,也取得了不错的效果。但是,现有的SLTC任务大多忽略了标签信息在分类方面的作用,如何通过捕获文本与标签之间的联系以进一步凸显文本特征是现阶段需要研究的一个难点。
针对以上2个问题,本文提出融合标签信息的分层图注意力HGAT-Label (Hierarchical Graph ATtention network integrating Label)网络文本分类模型,主要工作如下:
(1)通过词级图注意力网络获取的句子向量表示是以原有随机初始化的目标向量为基础,同时利用最大池化提取句子特定的目标向量,使得获取的句子向量具有更加明显的类别特征。
(2)利用GloVe[6]模型对所有文本的标签信息进行向量化处理,然后将所有文本的标签表示与文本的特征表示进行交互,以获取具有文本特征的标签信息表示,最后将其与文本特征融合进一步凸显文本特征表示。
(3)在5个公开英文数据集上进行实验,并与HGAT-Label模型相关的其它主流基线模型作对比。实验结果表明,本文提出的HGAT-Label模型明显优于其它主流基线模型。
2 相关工作
如今大多数文本分类研究均是围绕深度学习开展的,随着深度学习技术的发展,基于图神经网络的研究方法已逐渐成为主流。

除了对文本信息进行提取,现有有关SLTC的研究很少会将所有文本标注的标签信息与文本内容信息相结合。而在多标签文本分类任务中,如覃杰[13]结合文本与标签嵌入表示的相似度计算任务,进一步提高多标签文本分类任务的实验精度。You等人[14]通过构建浅而宽的概率标签树来解决大量标签可扩展性问题,然后利用自注意力机制捕捉与标签相关联的文本特征信息,取得了不错的分类效果;肖琳等人[15]通过标签语义注意力机制捕获具有文本语义联系的标签信息表示,从而提升了文本分类的效果。在以上多标签分类任务中,均因标签信息的融入使分类效果得到明显提升,从而也进一步验证了Zhang等人[16]所提出的标签信息的融入可以有效提升模型分类性能的结论。受其启发,本文尝试在SLTC任务中将所有文本标注的标签信息与文本特征信息进行交互、融合,以提升分类的准确率。
3 HGAT-Label模型实现
本文提出的HGAT-Label模型主要由词(文本或标签)嵌入层、邻接矩阵构建层、双重图注意力层、池化层和文本特征增强层组成。模型总体框架如图1所示。
(1)词(文本或标签)嵌入层:将输入的文本、标签数据样本分别转化为词向量H∈RVmax×d和l∈RN×d,其中,Vmax表示同一批次样本中文本句子包含的最多单词数目,d表示词向量维度。
(2)邻接矩阵构建层:依据句子关键词与主题关联性构建邻接矩阵A∈RVmax×Smax,其中Smax表示同一批次样本中文本包含的最多句子数目。

(4)池化层:采用平均池化层对更新后的文本信息进行提取,以对所有特征信息进行综合判断。
(5)文本特征增强层:将池化层输出的文本特征Tq与标签矩阵l用于计算交互注意力,获取具有文本语义特征联系的标签信息表示L;然后采用融合策略将标签信息表示L与文本特征信息表示Tq相结合,从而获得文本的分类特征表示T。

Figure 1 Framework of HGAT-Label model图1 HGAT-Label模型框架
3.1 任务定义
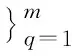
3.2 词嵌入层
本文使用GloVe模型对样本进行向量化,对于文本Cq,将其映射为向量矩阵H∈RVmax×d,即每个词被映射为一个低维稠密向量。同理,标签信息则由词嵌入矩阵l∈RN×d表示。根据GloVe的共现特性,初始化后的文本与标签表示仍具备一定的语义信息。
3.3 邻接矩阵构建层
为了捕捉文本的序列、结构与语义信息,需要对不规则的文本数据进行建模。本文首先以文本中每个句子Sj作为边,然后将句子中包含的单词(节点)按原有句法结构一一连接起来,这样就可以保留原有文本的序列信息和结构信息。为了进一步捕捉其语义信息,本文利用隐含狄利克雷分布[17]挖掘每个文本潜在的主题并将其作为边,而在每一句话中,与主题相关程度较大的词作为主题(边)连接的节点,这样既能捕获文本的序列信息和结构信息,又可以获取文本上下文语义信息。基于上述原理,定义图G=(V,E),其中,V={v1,v2,…,vi-1,vi,…,vVmax}是词节点集合,E={e1,e2,…,ej-1,ej,…,eSmax}是与词节点相连的主题边集合。因此,本文由图G的拓扑结构所构成的邻接矩阵A∈RVmax×Smax的表示如式(1)所示:
(1)
其中,Aij=0时表示句子中的词节点与主题边不相关,Aij=1时则表示两者相关联。
3.4 双重图注意力层
双重图注意力层由词级GAT和句子级GAT组成,其中GAT是将注意力机制引入到空间域的图神经网络,仅需要通过图上一阶邻居的表征信息来更新节点特征。
3.4.1 词级图注意力层
由于从句子中提取的关键词信息对分类目标的贡献程度不一样,因此在词级图注意力层,本文利用图注意力机制为句子中的关键词计算注意力得分,然后通过带有权重的关键词信息生成句子的向量表示。
首先,随机初始化一个目标向量uw,在训练的过程中通过不断学习来找出哪些关键词对于分类任务更为重要。特别地,在词级图注意力层,除了使用目标向量uw之外,本文还通过最大池化提取句子Sj的主要特征,作为其特有的目标向量u′wj。计算过程如式(2)和式(3)所示:
(2)
(3)

得到2个目标向量uw和u′wj后,紧接着通过图2所示的深度架构网络GAT分别计算关键词节点和2个目标向量的相似度并归一化,得到针对2个目标向量的注意力得分,具体计算过程如式(4)~式(6)所示:
(4)
(5)
(6)


Figure 2 GAT model图2 GAT模型
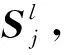
(7)
其中,θ1j和θ2j分别表示第k个关键词通过2种方式获取的注意力分数αjk与α′jk对构成句子j的最终表示的重要程度,σ(·)表示ReLU函数。
3.4.2 句子级注意力层
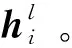
(8)
(9)
(10)

3.5 池化层
在获取新文本表示后,为了一方面考虑文本的全局信息,另一方面减少重要特征的遗漏,本文采用平均池化层对更新后的文本信息进行提取,以对所有特征信息进行综合判断。计算方法如式(1)所示:
(11)
其中,Tq表示第q个文本主要特征表示,f(·)表示平均池化函数。
3.6 标签文本交互融合层
交互注意力机制的实质是通过对2个句子关联的相似特征进行提取,从而捕获对应句子内部重要的语义信息。因此,本文将标签信息表示与文本特征表示用于计算交互注意力,获取具有文本语义特征联系的标签信息表示。
如图3所示,首先取池化层输出的文本特征Tq与标签矩阵l的点乘结果为信息交互矩阵M,其中Mqn表示第q个文本特征信息与第n个标签信息的相关性。然后分别对M的行、列进行softmax归一化处理,获取文本特征信息对标签信息和标签信息对文本特征信息的注意力分数αqn和βqn。计算过程如式(12)~式(14)所示:
M=Tq⊙l
(12)
(13)
(14)
其中,⊙表示点乘运算,αqn和βqn分别表示第q个文本特征信息对第n个标签信息的注意力权重和第n个标签信息对第q个文本特征信息的注意力权重。

Figure 3 Interactive attention model图3 交互注意力模型

(15)
(16)
L=γ⊙l
(17)
为了进一步凸显文本主要特征的表示,本文采用融合策略将标签信息L与文本特征信息Tq相结合,从而获得文本的分类特征T,如式(18)所示:
T=Tq⊕L
(18)
3.7 模型训练
模型最后通过softmax函数对T进行标签预测:
(19)

本文使用交叉熵损失函数对模型进行训练,如式(20)所示:
(20)
4 实验
4.1 实验环境
本文实验基于PyTorch深度学习框架,具体实验环境如表1所示。
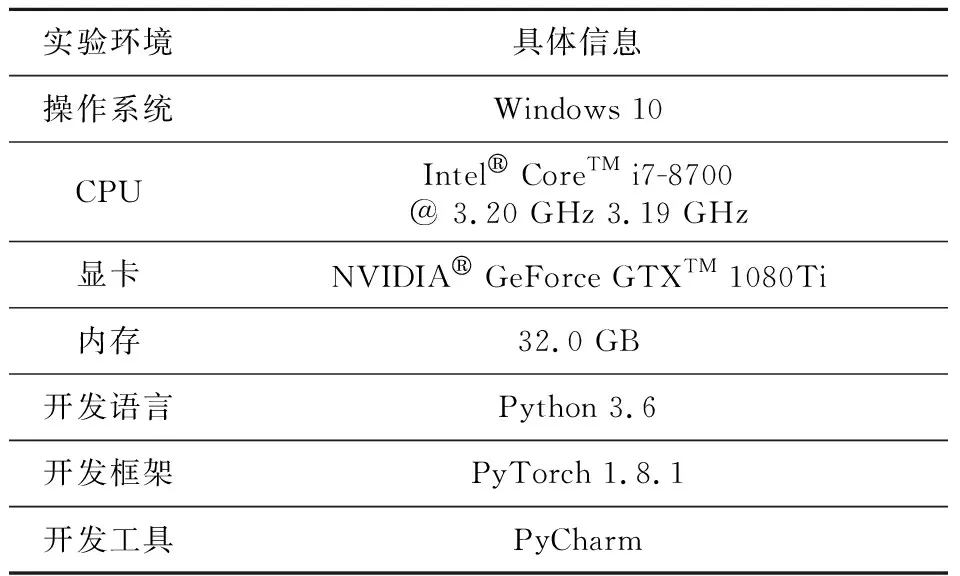
Table 1 Experimental environment表1 实验环境
4.2 实验数据
本文选用R8、R52、20NG、Ohsumed与MR 5个公开数据集进行模型性能评估,5个数据集的具体情况如表2所示。

Table 2 Information of five datasets表2 5个数据集信息
(1)R8与R52:由路透社新闻专线文件组成,分别包括8类和52类。
(2)20NG(20NewsGroups):由20个英文新闻组所组成,该数据集文本相似度高,分类难度大。
(3)Ohsumed:来源于医学文献库MEDLINE,每篇医学摘要包含23类心血管疾病中的1类或者2类。
(4)MR:由5 331个正面电影评论和5 331个负面电影评论所组成,其中每条评论仅包含1个句子[18],每个句子分别用1(正面)或0(负面)进行标注,适用于二元情感分类任务。
4.3 实验参数与评估指标
本文使用Adam优化器进行参数优化,使用2层双重GAT对文本特征进行提取,2层GAT嵌入维度分别为300和100,使用Dropout来防止过拟合。具体参数设置如表3所示。
为了验证HGAT-Label模型的优越性,本文使用准确率Acc(Accuracy)作为评估指标,计算方法如式(21)所示:
(21)

Table 3 Experimental parameters setting表3 实验参数设置
其中,TP为被正确分类的正样本数目;FP为被错误分类的负样本数目;TN为被正确分类的负样本数目;FN为被错误分类的正样本数目。通常,Acc值越大,分类效果越好。
4.4 对比模型
为验证本文模型在SLTC任务上的分类性能,在同样实验环境中将其与以下8个主流基线模型进行对比实验:
(1)SWEM(Simple Word-Embedding-based Model)[19]:采用词嵌入(Word Embedding)+池化(Pooling)的方式对文本信息进行建模分类。
(2)LEAM(Label-Embedding Attentive Model)[20]:该模型将文本与标签信息联合嵌入到同一空间,然后利用文本与标签的相关性构建文本特征表示。
(3)LSTM(Long Short-Term Memory)[21]:在多任务目标学习中,设计了3种基于LSTM信息的共享机制来提高相关文本分类任务的性能。
(4)BiLSTM(Bidirectional LSTM)[22]:利用BiLSTM具有记忆上下文语义信息和条件随机场(CRF)可以映射句子间不同标签关系的特点,将BiLSTM输出的语义特征信息直接输入到CRF层,使模型可以根据前后单词的标签信息有效预测当前词的标签信息。
(5)TextGCN(Graph Convolutional Network for Text classification)[10]:首先依据词与词和词与文档的关联性构建文本异构图,然后使用2层GCN提取其特征信息。
(6)Graph-CNN(Convolutional Neural Network on Graphs)[23]:基于谱图的CNN算法,将低维规则化数据转化成高维不规则图结构数据,并利用CNN提取其局部组成特征。
(7)Text-level GNN(Text level Graph Neural Network)[24]:改变TextGCN的构图方式,以每个输入文本为单位进行构图,然后通过图的消息传播机制将单词节点表示以及节点与节点之间的权重信息进行更新,从而提高模型在新文本数据上的分类预测能力。
(8)HyperGAT(Hierarchical Graph ATtention network)[4]:使用分层GAT对文本特征信息进行提取。
4.5 对比实验与结果分析
在5个公开数据集上,本文提出的HGAT-Label模型与8个主流基线模型的实验结果如表4所示。
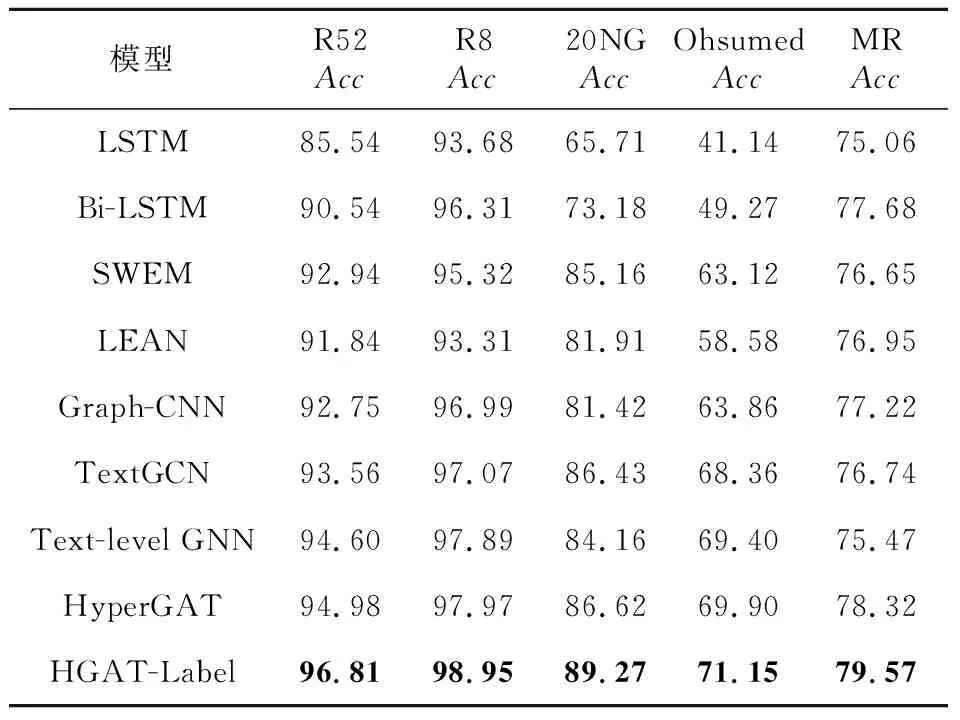
Table 4 Experimental results of different models表4 不同模型的实验结果 %
从表4可以看出,HGAT-Label模型相较最好的基线模型HyperGAT准确率分别提高了1.83%,0.98%,2.65%,1.25%和1.25%,验证了HGAT-Label模型分类性能的优越性。
在基线模型中,LSTM与BiLSTM在5个数据集上的整体效果最差,原因在于这2个模型仅对文本连续词序列信息进行提取,缺乏全局信息之间的关联性。BiLSTM是从正反2个方向对文本信息进行提取,比从单向提取信息的LSTM模型分类效果更好。与上述2个模型相比,SWEM与LEAN模型可以取得较好结果是因为二者使用的均是基于预训练词嵌入方法,预训练词嵌入方法是有利的文本表示方式,可以有效捕捉单词的语义与语法信息。此外,SWEM模型以不同池化的方式获取文本主要特征信息,而LEAN模型考虑文本特征信息的同时还利用注意力机制将文本标注的标签信息与文本信息进行交互,用以捕捉文本主题信息,所以SWEM与LEAN模型更有益于文本特征的划分。以上模型均是按时序类数据进行处理,对于非规则的文本数据而言,Graph-CNN、TextGCN、Text-level GCN和HyperGAT模型在分类任务处理中可以取得更好的效果,这是因为它们更擅长从非规则文本数据中捕捉长距离和非连续单词的关联性,实验结果可以验证这一点。但是,在MR数据集上,Graph-CNN、TextGCN和Text-level GCN模型的分类性能却没有得到很好的提升,再结合HyperGAT模型较好的分类效果,可以很容易看出,在情感分类任务上,利用图注意力机制更有利于捕捉文本的情感特征;另外,融合序列或词嵌入方法的图神经网络模型比直接在图上进行卷积操作效果会更好。
本文的HGAT-Label模型之所以优于HyperGAT模型,一方面是因为本文的词级图注意力网络结构是在原有的全局目标特征向量基础上同时利用最大池化提取句子特定的目标向量,使得获取的句子向量具有更加明显的类别特征;另一方面是因为将所有文本标注的标签信息与文本主要特征信息进行交互,用以获取具有文本特征的标签信息表示,然后将其与文本主要特征融合并进一步凸显文本特表示,从而达到最优分类效果的目的。从整体上看,文本特征的优化与标签信息的融入有着紧密的联系,有效提取文本特征信息的同时也能很好地学习标签信息的表示,当两者融合时效果最佳,所以HGAT-Label模型是优越的。
4.6 HGAT-Label模型的有效性验证
为了研究HGAT-Label模型的整体效果,本文分别去除目标向量模块和标签信息模块进行消融实验。其中w/o u表示在进行词级图注意力时,去除通过最大池化获取的目标向量u′w模块;w/o Label表示去除标签信息模块。本文以3个数据集(R52、R8和20NG)为例,研究各模型的分类性能。
由图4和图5可知,引入目标向量和融合标签信息2种方式均可使得模型效果有所改善,而将两者相结合的效果取得了进一步提升,说明本文的HGAT-Label模型在整体上是更有效的。因为标签是文本的表现形式,文本是标签的具体内容,两者相互依存有着紧密连接关系,所以将两者相结合更有利于文本特征的划分。

Figure 4 Experimental results of target vector ablation图4 目标向量消融实验结果

Figure 5 Experimental results of label information ablation图5 标签信息消融实验结果
分模块来看,融合标签信息后对文本的分类效果影响最大,准确率分别提升了1.28%,0.48%和2.03%。这是因为标签信息与文本主要特征的交互可以有效学习标签信息表示,然后通过与文本主要特征的融合降低了原有特征损失,凸显文本的主要特征信息。此外,也进一步验证了基线模型LEAN在融入标签信息后明显优于基于连续序列信息提取的LSTM与BiLSTM模型。引入目标向量后,准确率分别提高了0.66%,0.25%和1.17%。目标向量的引入,通过与原有随机初始化目标向量的自适应融合可以更加突出不同句子的类别特征,从而优化了文本特征信息的表示。对于SLTC任务来说,文本的分类效果主要取决于是否很好地学习到了关键特征信息的向量表示,所以目标向量的引入有益于文本特征的划分。以上对比与消融实验,验证了本文提出的HGAT-Label模型的优越性与有效性。
5 结束语
为了更好地对文本特征进行提取,以及如何通过文本与标签之间的联系进一步凸显文本特征,本文提出融合标签信息的分层图注意力网络模型来完成SLTC任务。本文一方面通过优化图注意力网络结构,使获取的句子向量具有更加明显的类别特征;另一方面利用GloVe模型对所有文本标注的标签信息向量化,然后将其与文本的主要特征信息进行交互、融合以减少原有特征损失,更好地表示整个文本特征信息。通过对比实验,验证了本文所提模型的优越性,同时消融实验也进一步验证了引入目标向量和融入标签信息的有效性与合理性,且两者结合效果最佳。
目前,SLTC任务已经取得较好的分类效果,但是随着文本内容日益丰富,对文本分类的要求也愈发提升。因此,下一阶段将对丰富的文本信息进行更细粒度特征划分,同时对模型算法进一步优化处理,提升训练速度。
