一种基于自适应结构感知池化图匹配的图相似度计算模型
2023-11-17李晓楠李冠宇
贾 康,李晓楠,李冠宇
(大连海事大学信息科学技术学院,辽宁 大连 116000)
1 引言
图因为其独一无二的表达能力在社交网络、知识图谱和推荐系统等领域的数据建模中受到了极大的关注。因此,很多图分析技术被开发,用于学习和提取图中有价值的数据。其中,最有挑战的问题之一是计算2个图之间的相似度。图的相似度学习已经在许多实际应用中得到了研究,如化学信息学中的分子图分类、用于疾病预测的蛋白质-蛋白质相互作用网络分析以及计算机安全中的二值函数相似度搜索等。为了解决这一问题,许多关于图相似的方法被提出,例如图编辑距离[1]、最大公共子图[2,3]和图同构[4,5]等。然而这些度量的计算都是NP-hard(Non-deterministic Polynominal-hard)问题,因此很难扩展到超过16个节点的大型图中去。此外,传统的方法没有考虑到丰富的节点特征信息,丢失了一些潜在的语义相似性。
随着深度学习技术的出现,图神经网络已经成为学习不同结构图表示的一个强大的新工具,包括节点分类[6,7]、图分类[8]和图生成[9]等。然而,利用图神经网络学习2个图之间相似度得分的研究较少。要了解2个输入图之间的相似度,一种简单而直接的方法是:首先通过图神经网络将每个图编码为图级嵌入的向量,然后将2个输入图的2个向量表示结合起来进行决策。这种方法探索了包含2个输入图重要信息的图级交互特性,可用于图相似度学习。
当前的图神经网络缺乏以分层方式聚合节点信息的能力。这种架构依赖于通过图神经网络学习到的节点表示,然后聚合节点信息来生成图表示[10-12]。但是,以分层的方式学习图表示对于捕获图中的局部子结构是很重要的。例如,在一个有机分子中,一组原子在一起可以作为一个官能团,在决定图的类别方面起着至关重要的作用。为了解决这一问题,研究人员新提出的池化架构DiffPool(Differentiable graph Pooling)[13],作为一个可微池操作符,学习将每个节点映射到一组集群的软分配矩阵,但这个分配矩阵是密集的,不容易扩展到大型图[14]。TopK[15]学习了每个节点的标量投影分数,并选择排名前k的节点。它们解决了DiffPool的稀疏性问题,但不能有效地捕获丰富的图结构。SAGPool(Self-Attention Graph Pooling)[16]提出了一种基于TopK的架构,利用自我注意力网络学习节点分数。虽然局部图结构用于评分节点,但它仍然不能有效地用于确定池化图的连通性。本文自适应结构感知池化[17]在保持稀疏性的同时能有效捕获丰富的图结构。
最近,SimGNN(Similarity computation via Graph Neural Network)[18]尝试通过直方图信息考虑低级节点-节点交互,同时使用神经张量网络NTN(Neural Tensor Network)关联了2个输入图的图级嵌入。GraphSim(Graph Similarity matrix generation)[19]通过构建节点相似矩阵,避免图级嵌入的产生。GMN(Graph Matching Networks)[20]通过合并另一个图的隐式注意邻居来改进一个图的节点嵌入。本文的结点-图匹配网络[21]通过比较一个图的上下文节点嵌入和另一个图的注意力图级嵌入,能够有效地学习更丰富的输入图对之间的跨层交互,集成输入图对之间交互的多级粒度,以端到端方式计算图的相似度。
本文的主要工作如下:
(1)利用一种自适应结构感知池化方法[17],通过学习对每一层的节点进行稀疏软集群分配,从而有效地池化子图,形成池化图。该模型利用池化图来捕获不同级别子图之间的细粒度相关性,而不是在普通图中进行节点比较。
(2)利用一种新颖的图匹配网络[21]学习图相似度。该网络有效地学习一个图的每个节点与另一整个图之间的跨层交互以提取图间相似度。
(3)在4个数据集上进行了综合实验,验证模型的有效性和优越性。实验结果表明,所提出的模型性能比所知的最先进的基线模型的更好。
2 相关工作
2.1 图神经网络
目前,研究人员已经提出了光谱法和非光谱法2种不同的GNN(Graph Neural Network)公式。光谱方法的原理是用傅里叶变换和图形拉普拉斯算子定义卷积运算,但不能直接推广到不同结构的图[22]。非光谱方法通过图中节点周围的局部邻域定义卷积,比光谱法速度快,而且易于推广到其他图形。GNN也可以被视为消息传递算法,节点通过边迭代聚合来自相邻节点的消息[23]。GCN(Graph Convolutional Network)[6]将切比雪夫多项式进一步简化为一阶,从而实现高效的逐层传播。对于空间方法,图卷积是通过聚集其空间邻域节点来表示的。例如,GraphSAGE(Graph Sample and AggreGatE)[24]是一个归纳框架,对来自其本地邻域的表示进行采样聚合;GAT(Graph ATtention networks)[25]引入注意力机制自适应聚合节点的邻域表示。
2.2 图池化
池化层克服了GNN无法按层次结构聚合节点的缺点。GNN中的图池化机制[13,26]旨在将图转换为粗化图,并捕获其层次图表示。DiffPool[13]利用图神经网络将节点软聚为一组。TopK基于一个可学习的投影向量对节点进行评分,并对得分较高的节点进行抽样。它避免了节点聚合和计算软分配矩阵,能保持图操作的稀疏性。图U-Nets[15]和SAGPool[16]保留最重要的top-K节点,并在图中进行节点采样。由于TopK和SAGPool不进行节点聚合,也不计算软边权值,因此不能有效地保留节点和边缘信息。为了解决这些局限性,本文利用了自适应结构感知池化ASAP(Adaptive Structure Aware Pooling)[17]。ASAP具有层次池的所有可取特性,同时不影响图操作的稀疏性。
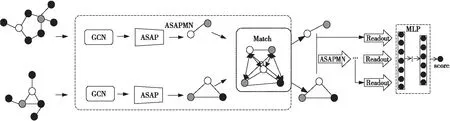
Figure 1 Overall framework of ASAPMN图1 ASAPMN的总体架构
2.3 图相似度学习
图相似度学习的目标是学习一个度量2个图对象之间相似度的函数。传统的图编辑距离GED(Graph Edit Distance)和最大公共子图MCS(Maximum Common Subgraph)通常具有指数级的时间复杂度,无法扩展到较大的图。最近,GNN被引入用于执行图相似度学习。SimGNN[18]利用直方图特征和神经张量网络[27]分别对节点级和图级交互进行建模。GraphSim[19]通过合并卷积神经网络来扩展SimGNN,以捕获复杂的节点级交互。GMN[20]提出不仅在每个图中传播节点表示,还在其他图的注意邻居之间传播节点表示。本文利用图池化结构的优势来进行池化图图匹配,而不是专注于节点间的比较。这一点在使用GNN进行图相似度学习的场景中很少被研究。
3 模型介绍
3.1 符号与公式

3.2 总体框架
图1为本文ASAPMN(Adaptive Structure Aware Pooling graph Matching Network)的总体架构。ASAPMN由3个主要部分组成:(1)图卷积。学习节点表示;(2)
图池化。利用ASAP模型有效地池化子图,形成池化图;(3)子图匹配。学习2个子图之间的跨层交互,提取图间相似度。3个部分共同组成模型ASAPMN来获得图在一个层级上的表示。本文需要保留3个层级上的表示,一个图向量需要经过3次ASAPMN模型计算才能得到最后的图级表示。然后,本文设计了一个注意力读出函数来汇总每个图在不同层级上的表示,最终的图级表示是2个图的不同层级表示的串联。最后,将级联的图级表示输入到多层感知器MLP(MultiLayer Perceptron)中,以执行图-图分类和图-图回归任务。下文将详细介绍不同组件。
3.3 图卷积网络
本文使用图卷积网络(GCN)[6]来提取特征。GCN定义如式(1)所示:
(1)

3.4 图池化
首先图中的每个节点vi视为聚类ch(vi)集合的中间体,使得每个聚类只能代表h跳固定半径内的局部邻居集合,即ch(vi)=Nh(vi)。给定一个聚类ch(vi),通过自注意力机制学习聚类分配矩阵S,通过关注集群中的相关节点来学习聚类ch(vi)的整体表示。T2T(Token2Token)[27]和S2T(Source2Token)[28]注意力机制不能利用任何集群内信息。因此,本文利用了一种新的自注意力变体M2T(Master2Token)[17]。在M2T框架中,首先创建一个主查询向量mi∈Rd代表聚类中所有节点:
mi=fm(x′j|vj∈ch(vi))
(2)
其中,x′j为节点特征向量xj通过一个单独的GCN在聚类ch(vi)捕捉到的结构信息;fm(·)是一个主函数,它结合并转换vj的特征表示x′j找到mi,mi用附加注意力关注所有组成节点vj∈ch(vi),具体定义如式(3)所示:
(3)
聚类ch(vi)中vj的权重α(i,j)计算如式(4)所示:
α(i,j)=softmax(wTσ(Wmi‖x′j))
(4)
其中,wT和W分别是可学习的向量和矩阵。
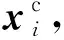
(5)

(6)
其中,W1,W2,W3为可学习的矩阵,N(vi)表示节点vi的邻居节点集合。
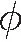
(7)

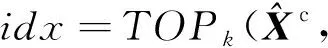
(8)
(9)
本文对聚类进行采样后,通过式(10)找到池化图Gp的新邻接矩阵Ap:
(10)
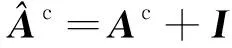
3.5 子图匹配层
这一层通过比较一个子图的每个上下文节点嵌入与另一个子图的整个图级嵌入,以及定义的多视角匹配函数,有效地学习一个图的每个节点与另一整个图之间的跨层交互,以提取图间相似度。这一层通常有2个步骤:(1)计算图的图级嵌入向量;(2)将一个图的节点嵌入与另一个完整图的相关图级嵌入向量进行比较,然后生成相似度特征向量。本文首先计算G1子图中的节点vi∈V1和G2子图中的所有节点vj∈V2之间的交叉图注意力权重αi,j。同理,计算G2子图中节点vj∈V2和G1中所有节点vi∈V1之间的交叉图注意力权重βj,i。具体来说,这2个交叉图注意力系数可以用注意力函数fs(·)独立计算,如式(11)所示:
(11)

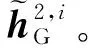
(12)

(13)
3.6 注意力聚合层和输出层
为了进一步聚合子图匹配层的交叉图交互信息,本文设计了一个注意力读出函数来生成全局图级表示。由于不同的节点通常在图中表现出不同的重要性,本文利用一个简单的注意力机制可以得出rk,如式(14)所示:
(14)
其中,σ(·)是sigmoid函数,Watt表示可训练注意力权重矩阵,hn表示节点级别向量,rk表示图级向量,k表示网络层数。
然后,将不同级别的输出连接起来,形成最终的匹配表示,如式(15)所示:
(15)

最后,将带有sigmoid激活函数的多层感知机用于执行图分类任务和图回归任务,如式(16)所示:
(16)

4 实验和结果分析
4.1 数据集
本文在4个数据集上评估模型。表1总结了数据集的统计数据,其中,#of graphs表示数据集中包含的图的数量,#of function表示数据集的函数个数,Avg #of nodes 表示数据集的平均节点数,Avg #of edges 表示数据集的平均连边数,Initial feature dimensions表示数据集的初始特征维度。FFmpeg和OpenSSL[21,29]被用于图形分类任务,这2个数据集由2个流行的开源软件FFmpeg和OpenSSL 生成。实验在不同的设置下编译源代码函数,例如不同的编译器(例如gcc或clang)和不同的优化级别可以生成多个二元函数图。因此,将从相同源代码编译的2个二进制函数视为语义相似的函数,即S(G1,G2)=+1;而不同的二进制函数对是从不同源代码编译的图,即S(G1,G2)=-1。这样,将二元函数之间的图相似度学习问题转化为图分类任务。此外,根据图对的大小范围将每个数据集分成3个子集(即[3,200],[20,200]和[50,200])来研究图大小的影响。
在图回归任务中使用AIDS700和LINUX1000这2个数据集,其中每个图分别代表一种化合物或程序函数。每个数据集包含每对图形之间的图编辑距离(GED)分数。对于AIDS700和LINUX1000,A*算法用于计算精确的GED。为了进一步将GED转换为相似度值,本文使用文献[25]中的方法将其标准化为(0,1]的数。图回归任务的目标是学习任何2个图之间的GED。

Table 1 Information of dataset 表1 数据集信息
4.2 基线模型和实验设置
4.2.1 基线模型
为了评估本文模型的有效性,本文考虑了4种最先进的基线模型进行比较,如下所示:
(1)SimGNN[18]:采用多层GCN,并采用2种策略来计算2个图之间的GED,一种使用神经张量网络来捕捉图与图之间的交互,另一种使用从2组节点嵌入中提取的直方图特征;
(2)GMN[20]:采用了消息传递神经网络的一种变体,并通过合并另一个图的关注邻域信息来改进一个图的节点嵌入;
(3)GraphSim[19]:首先将2组节点嵌入转化为相似矩阵,然后用CNN处理矩阵,扩展了SimGNN;
(4)MGMN(Multilevel Graph Matching Networks)[21]:由一个节点图匹配网络和一个孪生图神经网络组成,有效地学习一个图的每个节点与另一整个图之间的跨层交互,以及一个连体图神经网络用于学习2个输入图之间的全局级交互。
4.2.2 实验和参数设置
本文将每个数据集随机分成3个不相交的子集,分别占比80%,10%和10%,用于在图分类任务中进行训练、验证和测试。对于图回归任务,本文使用文献[18]中的拆分,即分别将60%,20%和20%的图对分别用作训练集、验证集和测试集。为了公平比较,本文使用MGMN作者发布的源代码,并在每个基线模型的验证集上调整他们的超参数。本文将所有数据的节点表示维度设置为100,提出的模型用PyTorch Geometric实现,用Adam optimizer优化模型参数。本文在{0.1,0.01,1e-3,1e-4,1e-5}范围内研究学习率和权值衰减,池化率r∈[0.1,1.0],神经网络层数L∈[1,5]。MLP由3个完全连接的层组成,每层的神经元设置为200,100和50。本文在一台具有128 GB RAM和NVIDIA®GeForce®RTXTM3090 GPU的Windows机器上完成实验。在训练过程中,本文使用早期停止标准进行模型优化,即:如果验证损失在100个连续时间段内没有减少,将停止训练。
4.2.3 评估指标
为了评估和比较 ASAPMN的性能,本文使用了以下指标评估:
(1)均方误差MSE(Mean Square Error):用于计算式(16)中定义的预测分数与真实值之间的损失。
(2)Spearman的排名相关系数(ρ)[30]和 Kendall 的排名相关系数(τ)[31]:用于衡量预测排名结果与真实排名结果的匹配程度。这2个系数越大表示预测数据和真实数据越接近,效果越好。p@10表示返回前10个结果的精确度,p@20表示返回前20个结果的精确度。
(3)AUC(Area Under the receiver operating Characteriic)[32]和ROC(Receiver Operating Characteristic):ROC曲线用来衡量当分类阈值变化时,分类器系统的判别能力。ROC曲线对样本是否平衡不敏感,适用于样本类别不均衡时对分类器性能的评价。AUC指的是ROC曲线下的面积,取值一般在 0.5到1之间。分类器的AUC是指将随机选择的正例排在随机选择的负例前面的概率。
以上5个评估指标中,均方误差MSE越小越好,相关系数(ρ和τ)、p@10、p@20和AUC越大越好。
4.3 图分类任务
对于图形分类任务,本文重复实验5次,取ROC曲线(AUC)下面积的平均值和标准差,例如0.982±0.040中0.982表示平均值,0.040表示标准差。实验结果如表2所示。

Table 2 AUC scores of graph-graph classification 表2 图-图分类任务的AUC值
首先,本文提出的ASAPMN在所有设置下在2个数据集上获得的性能都最好。与原始解决方案MGMN和经典模型SimGNN、GMN和GraphSim相比,ASAPMN在FFmpeg和OpenSSL数据集的所有6个子数据集上都明显达到了最先进的性能。这表明此前用于图相似度学习的全局图级交互不能很好地捕捉底层图的语义相似性,因此有必要对输入图对之间的细粒度低级交互进行建模。ASAPMN优于具有不同的节点级比较方法,将性能提升归因于子图匹配机制的优势。与整个图的节点匹配不同,池化操作保留了关键子图的子集,然后在整个图中进行匹配,其中子图通常包含丰富的局部子结构信息,对于图的语义相似度学习非常重要。特别是,当图的大小增加时,基线模型的性能降低。然而,与最先进的基线模型相比,本文提出的模型仍然实现了相对更好和更鲁棒的性能。
4.4 图回归任务
对于计算2个输入图之间的相似度得分GED的图-图回归任务,本文统计了MSE、ρ、τ和p@k这些指标值。图回归性能如表3所示。本文还在图回归任务中将所提ASAPMN与最先进的基线模型进行比较。从表3可以看出,尽管GraphSim在LINUX1000数据集上τ有更好的性能,MGMN在AIDS700数据集上ρ和τ有更好的性能,但ASAPMN在AIDS700和LINUX1000数据集上的大多数评估指标值都优于基线模型的。ASAPMN由于其精心设计的池化机制和池化图上的子图匹配机制,获取了更好的性能。
4.5 消融实验
4.5.1 仅考虑池化方法
本文对不使用图匹配网络的原池化机制ASAP和本文的模型做了对比,如表4所示。可以看出,仅考虑池化机制的ASAP在2个数据集上无法获得令人满意的性能,实验性能大幅下降,说明加入图匹配网络可以学习到更多有效的信息。

Table 4 Graph-graph regression results of ASAPMN and ASAP表4 ASAPMN和ASAP图回归任务结果
4.5.2 考虑不同的池化方法
为了研究不同池化方法的影响,本文选择了几种广泛使用的图池化模型进行对比实验:DiffPool[13]、TopK[15]、SAGPool[16]和AttPool[33]。如表5所示,DiffPool[13]和ASAP[17]基于节点聚类的池化机制效果好于TopK[15]、SAGPool[16]和AttPool基于节点选择的池化机制的。ASAP[17]通过节点聚类、稀疏性问题的解决以及对注意力机制的改进可以更好地捕捉到图的层级信息,与分层级的图匹配机制结合得到了更好的结果。

Table 3 Graph-graph regression results 表3 图-图回归任务结果
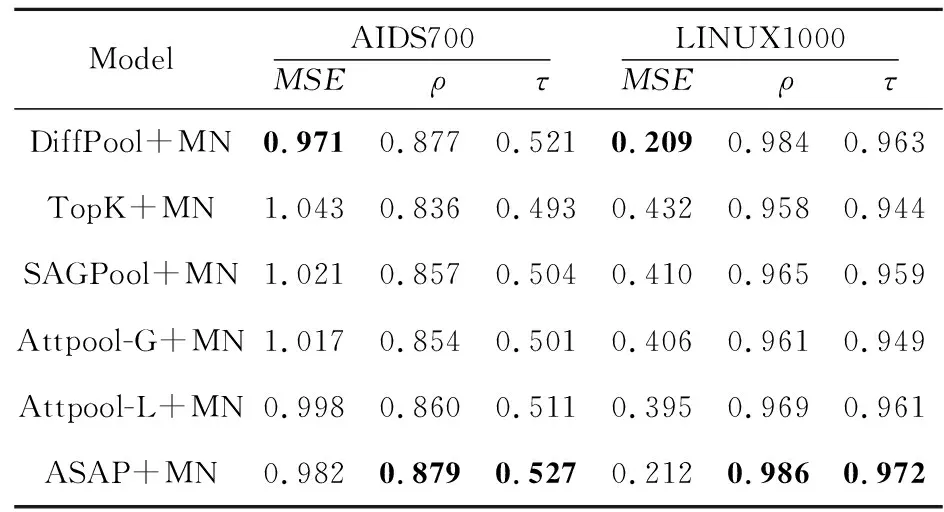
Table 5 Graph-graph regression results when using different pooling methods表5 使用不同池化方法的图回归任务结果
4.5.3 超参数分析
本节测试了2个关键的超参数对OpenSSL子集的影响。特别地,研究了图池化率r和池化层数L对图的分类结果的影响情况。如图2和图3所示,当设置r=0.8和L=3时,ASAPMN可以在所有数据集上获得最佳性能。当不使用池机制时,r=1.0时,性能也会下降。

Figure 2 Sensitivity analysis of pooling ratio r图2 图池化率r敏感性分析

Figure 3 Sensitivity analysis of number of layers L of graph convolutional neural network图3 图卷积神经网络层数L敏感性分析
5 结束语
本文研究了图分类和图回归任务中的图相似度学习问题,该问题需要模型对一对输入图进行联合推理。本文提出了一个新的框架ASAPMN,将图池化后再进行子图匹配。在ASAPMN中,先利用ASAP模型执行池化操作,再利用节点-图匹配网络有效地学习一个图的每个节点与另一整个图之间的跨层交互以提取图间相似度。通过这样一个过程,可以以端到端的方式评估任意结构图对的相似性。在4个常用数据集上的实验结果表明,与一系列最先进的基线模型相比,它是有效的。之后还将考虑如何应用 ASAPMN解决相关的图相似性挑战,例如蛋白质分子查找、程序流程图的安全性等。对于这些实际应用,图结构的相似性研究至关重要。
