基于多尺度特征融合网络的HEVC帧内编码单元快速划分研究
2023-11-17刘雨墨刘剑飞郝禄国曾文彬
刘雨墨,刘剑飞,郝禄国,曾文彬
(1.河北工业大学电子信息工程学院,天津 300131;2.河北工业大学电子与通信工程国家级实验教学示范中心,天津 300131; 3.广东工业大学信息工程学院,广东 广州 510006;4.天津大学电气自动化与信息工程学院,天津 300072)
1 引言
高效视频编码HEVC(High Efficiency Video Coding)作为一个新的视频压缩标准,首次被ITU-T (International Telegraph Union Telecommunication standardization sector)和 ISO/IE(International Organization for Standardization/ International Electro technical Commission)联合发布[1]。与上一版本H.264相比,HEVC引入了很多新的技术模块,能够在保证视频编码质量的前提下,压缩率提高40%~50%,但其复杂度也显著增加。在庞大的数字视频数据量的环境下,许多的电子设备,包括便携式设备都要传输和存储数字视频,因此对数字视频进行高压缩率处理的同时,还需要降低HEVC的编码复杂度。
在HEVC新引入的诸多技术模块当中,最核心的模块之一是基于四叉树的编码单元CU(Coding Unit)灵活划分结构。根据编码特性的不同,视频图像中包括了平缓区域和复杂区域。HEVC为了适应不同区域,将图像划分为互不重叠、大小相等的正方形块,称作编码树单元CTU(Coding Tree Units)[2]。CTU基于四叉树划分结构继续向下划分出若干个CU。编码单元划分采用递归划分方案,其中每个编码单元的节点又可以递归地细分为4个新节点,直到达到最小的CU。CU的大小一般为64×64,32×32,16×16和8×8。若HEVC采用递归方式,编码区需要扫描所有可能的CU,并通过自上而下的率失真优化RDO(Rate Distortion Optimization)成本计算以及自下而上的成本比较,来选择最优结果。这个过程包含了大量的冗余计算,且非常耗时,占据了80%以上的编码时间。
为了降低HEVC的编码复杂度,优化编码单元划分过程,研究人员提出了多种针对HEVC编码单元划分的快速方法,大致上可以分为2种:基于启发式的方法和基于机器学习的方法。基于启发式的方法是根据当前CU的中间特性以及相邻CU的空间相关性实现跳过或提前终止某些模式。Shen等[3]根据CU与内容的关联程度,跳过一些内容中很少使用的CU深度等级。文献 [4-6] 采用贝叶斯决策对所有的CU深度等级进行提前终止和裁剪。文献 [7] 引入绝对变换误差成本计算进行模式选择和双向深度搜索,来实现CU的早期终止。这类方法相较于RDO递归过程节省了大量计算,但其不能全面地考虑各类视频序列中的分割特性,导致在特定场景下RD(Rate Distortion)精确度不佳的问题尤为明显。为克服这类方法的缺点,一些研究人员采用机器学习的方法完成加速编码过程。文献 [8,9] 采用支持向量机SVM(Support Vector Machine)快速提取图像特征,根据特征对应的CU复杂程度建立分类器再进行CU深度决策。文献 [10]利用在线学习构建精确模型以跳过不必要的模式。文献 [11] 通过数据挖掘技术训练分类器实现早期CU分类。文献 [12] 利用随机森林分类器跳过或终止当前CU深度等级。在基于机器学习的方法中,分割效果相当程度上依赖输入的特征,而特征的提取和功能设计需要大量的工作和经验。诸多研究利用卷积神经网络CNN(Convolutional Neural Network)自动学习特征的特点,在帧内编码的过程中主要作用于提前预测CU划分,从而避免RDO的冗余计算,降低HEVC的编码复杂度。文献 [13,14]利用浅层CNN结构并提出了一种友好的VLSI(Very Large Scale Integration)快速决策算法,以此来预测CU块边缘的概率向量,并跳过部分分割模式,但该方法并没有完全摆脱RDO递归计算过程。文献 [15] 利用CNN模型在CU搜索过程中预测3种类型的CU划分结果,将模型作为CU分区过程的分类器。文献 [16,17]尝试跳过RDO的递归过程,将CTU分成3种尺度输入到CNN,每种尺度深度等级不同,同时得到3个分割标志,用3个CNN来判断不同深度等级是否需要进行分割,但分割标志是基于当前块决定,不考虑整个CTU的信息。
为简化穷举法的RDO计算过程,本文利用深度学习方法对帧内编码单元划分进行提前预测,即使用具有很强泛化能力的CNN有效地对视频中不同纹理复杂程度的图像进行自适应划分,以此来降低HEVC的编码复杂度。实验结果表明,本文设计的CNN网络模型能够有效泛化于不同分辨率的视频序列,同时很大程度上缩短了视频编码的时间。本文工作可总结如下:
(1)选取5种不同分辨率的38个视频序列,将视频序列和对应的编码信息构建成用于训练CNN模型的大规模数据集。
(2)根据CU划分特点和U-Net网络结构优势,设计出多尺度特征融合的UcuNet(U-shape code unit Net)网络结构,有效提取不同尺度的CTU特征并进行拼接融合,同时引入非对称卷积AC(Asymmetric Convolution)和CBAM(Convolutional Block Attention Module)注意力机制来提高网络预测能力。
(3)通过实验验证了上述设计的有效性,与HEVC官方测试模型(HM16.20)相比,该设计缩短了68.13%的编码时间,BD-BR(Bitrate- Distortion Bound Rate)的影响在可接受的2.63%范围内。
2 UcuNet算法设计
本文提出基于多尺度特征融合的网络(UcuNet)来优化HEVC结构。在编码一帧时,添加新的线程启用UcuNet,使其对输入的一整帧图像进行处理。UcuNet是由不同视频序列所构建出的数据集训练得来。
UcuNet的流程如图1所示。首先,视频的每一帧图像输入后,被裁剪成大小为64×64的互不重叠的CTU,随后进行CTU编码;然后,利用所提出的CNN网络模型预测出所有CU的深度信息;最后,利用预测的深度信息进行CU编码,得到输出的编码结果。HEVC编码过程中,原始的线程负责判断,新的线程预测是否完成,待预测完成后,直接将预测的深度信息作为CU划分深度进行编码。整个过程循环往复,直到所有编码完成。

Figure 1 Flow chart of UcuNet for fast partitioning of coding units图1 UcuNet实现编码单元快速划分的流程图
2.1 数据集构建
为了训练预测CU划分的深度学习模型,需要构建一个由图像块和对应的深度信息组成的数据集。为了产生足够多的训练样本,同时防止训练过程出现过拟合,本文剔除了常用的JCT-VC(Joint Collaborative Team on Video Coding)测试序列,构建了一个大规模的数据集。该数据集包含了5种不同分辨率的38个视频序列,分辨率分别为:352×288, 704×576, 1280×720, 1920×1080和3840×2160。将这些序列分成3个子集,其中23个用作训练集、8个用作验证集和7个用作测试集。使用不同分辨率的视频序列来制作数据集是为了保证训练数据的多样性,从而提高CTU划分的高效性。使用HEVC官方测试模型HM16.20在量化参数QP(Quantization Parameter)(4种取值:37,32,27,22)下对以上所有视频序列进行全帧内编码。将得到的每一个CTU划分结构情况和原始的64×64亮度像素值一起作为一个样本。收集并统计所有CTU划分的样本情况。由于视频图像具有时间相关性,相邻帧之间具有高度相似性,为了数据集的合理性,以及避免在训练时产生过拟合,采用随机方式抽取部分帧进行处理获取随机样本RS(Random Samples)。这样做的好处是,可以去除大部分重复数据,同时增加样本间的差异性。表1列出了不同分辨率下的视频序列个数、总帧数、获取到的原始样本总量以及随机抽取帧获得的样本总量。

Table 1 Information of the samples in the dataset表1 数据集中样本的信息
基于随机抽取帧获取的样本中,训练集、测试集和验证集的样本数量分别占样本总量的82%,8%和10%。
2.2 UcuNet网络
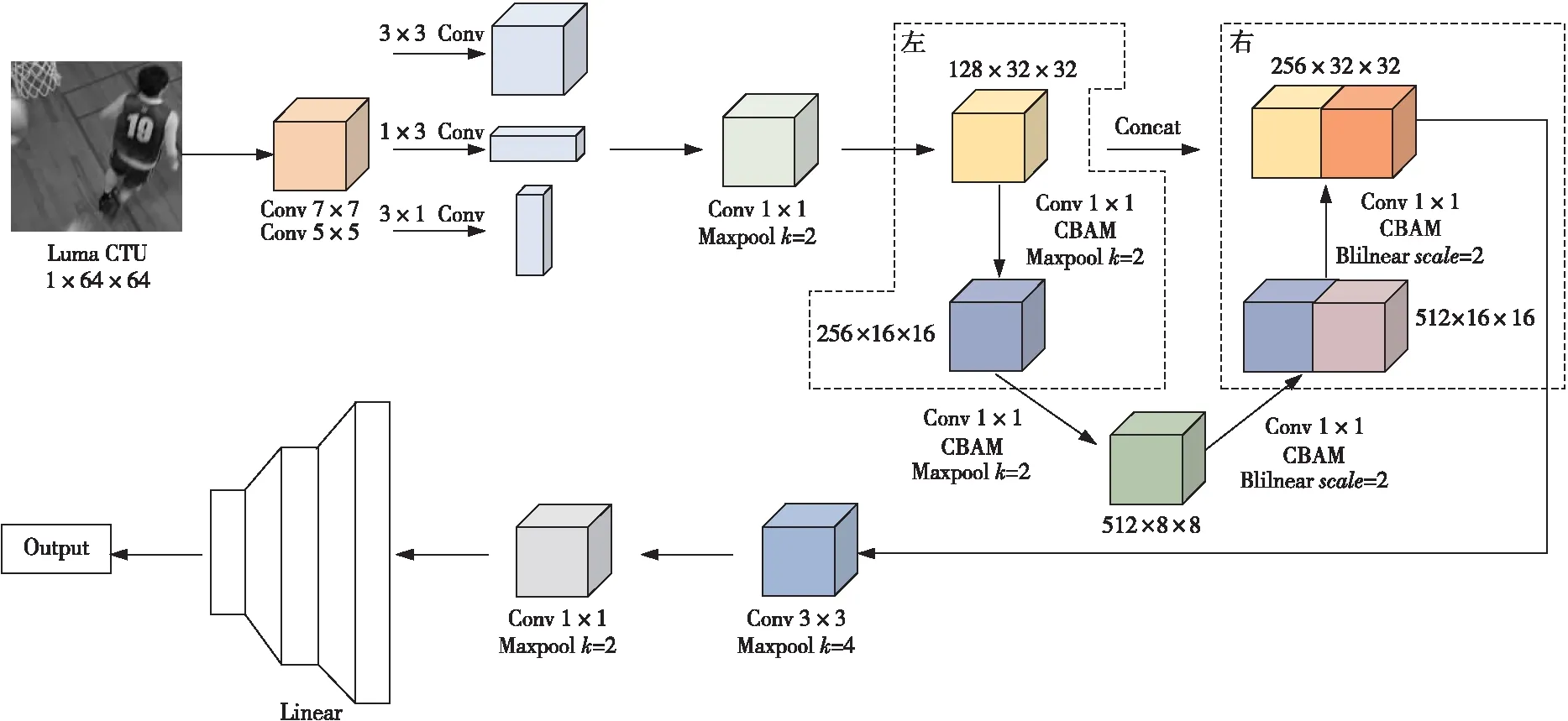
Figure 2 Structure of UcuNet图2 UcuNet结构
由于CU划分的深度很大程度上与视频图像中的纹理复杂程度相关,分析图像的特征可以预测CU深度信息。CNN已经被证实是一个能从图像内容中提取特征的强大工具,因此本文利用CNN设计了一个多尺度特征融合的网络模型UcuNet来预测CU深度。图2为UcuNet结构。整体结构除包含输入层、卷积层、池化层和全连接层外,还为了满足不同尺度的特征提取,尤其是CU特有的尺寸64×64,32×32,16×16和8×8,引入了非对称卷积、下采样和上采样的处理方法,增加了卷积核的表征能力和特征图的多样性。输入是处理原始CTU后得到的64×64 CTU亮度,即YUV(Y表示亮度,U表示色度,V表示浓度)视频中Y分量组成的亮度像素块。首先,通过7×7和5×5的卷积层获取浅层特征,然后利用非对称卷积AC模块增强特征拟合,减少参数量和计算量的同时,引入非线性激活函数来提高网络模型的表达能力,然后再利用1×1的卷积层进一步提取更深的特征并减少计算量,同时对特征通道升维。根据CU尺寸的特点,经过卷积处理后的特征进入到本文网络模型的主体部分,将其进行下采样后,对不同尺寸进行卷积层和池化层的操作,然后采用双线性插值法的上采样后,继续进行卷积层和池化层的操作,最后将得到的每个尺寸下的特征进行拼接融合,有效提升模型的特征学习能力。
接下来,通过1×1的卷积将特征通道升维后,再进行全局池化,进一步精简特征。本文采用了卷积核为4的池化层处理,将所获取的特征进行过滤,能够达到在保留主要特征的前提下减少大量冗余参数的效果。最后,通过全连接层把前面获取的特征综合起来进行权重矩阵的匹配。整个过程均采用全局归一化BatchNorm和ReLU非线性激活操作,以使训练数据更快地收敛。
本文UcuNet中的主干网络是U型对称的,其设计思路来源于U-Net[18]。U-Net在2015年的IEEE国际生物医学成像研讨会ISBI(International Symposium on Biomedical Imaging)比赛中应用于图像分割领域并获得了冠军。本文将U-Net结合CU划分的特点加以修整。图2左侧称为压缩路径,采用最大池化层进行下采样操作,其目的是提取低分辨率的特征信息。右侧是扩展路径,采用双线性插值法进行上采样操作,其目的是提取高分辨率的特征信息。通过2条不同类型的路径,使得网络能够进行端到端的训练,同时可以较为精确地获取图像中的上下文信息和精确的定位。整个过程包含了3种特征尺寸,分别为32×32,16×16和8×8,对应CU划分的深度1,2和3。每次下采样过程包含了2个1×1的卷积层,相应地,上采样过程包含了2个1×1的卷积层(卷积与双线性插值结合实现反卷积操作),并将扩展路径和压缩路径的同尺寸特征图进行基于通道的拼接处理。
最后,网络利用CTU矩阵中重复数值块最小的尺寸捕捉其纹理复杂度特征信息。其输出的标签数值所取范围均为0~3,表征每个CTU中所有CU划分的深度信息。
为了让网络充分学习不同像素类别、通道特征以及上下文特征信息,在上采样和下采样的过程中引入CBAM注意力机制[19],CBAM的结构如图3所示。在每个尺寸特征图中加入注意力机制,可以让网络对不同特征信息添加不同的权重,并且更为全面地获取特征信息。CBAM是基于卷积模块的注意力机制,相较于SENet(Squeeze-and-Excitation Networks)[20],CBAM的优势是同时结合了空间和通道的注意力机制模块,且与原输入特征图相乘实现了自适应特征修正。

Figure 3 Structure of CBAM图3 CBAM的结构
通道注意力模块结合了全局平均池化(AvgPool)和最大池化(MaxPool)的处理,随后将结果输出到多层感知器MLP(MultiLayer Perceptron)进行基于像素的相加处理,最后利用Sigmoid激活函数生成该模块的特征图F。它的数学计算公式如式(1)所示:
F=S(MLP(MaxPool(x))+
MLP(AvgPool(x)))
(1)
其中,x表示输入特征,S表示Sigmoid函数。
空间注意力模块与通道注意力模块相互补充,通道注意力模块的输出和原始的输入特征相乘后作为空间注意力模块的输入,然后利用全局平均池化和最大池化处理后拼接起来,再送入到卷积层将通道数变成1,最后利用Sigmoid函数激活后生成最终的特征F,如式(2)所示:
F=S(f7×7([MaxPool(x);AvgPool(x)]))
(2)
其中,f7×7表示卷积核为7×7大小的卷积层。
经过CBAM的注意力机制后,输出的新特征图获得通道和空间维度上的注意力权重,极大地增强了在通道和空间层面上每个特征之间的联系,提高了获取的目标特征的有效性。
3 实验与结果分析
为了评价UcuNet CU划分深度预测中的性能,本文将训练好的模型嵌入到HEVC官方测试模型HM16.20[21]中进行多次实验。本文实验的硬件环境配置为:1.6 GHz主频的Intel®CoreTMi5-8265U CPU、8 GB运行内存和64位Windows操作系统。在训练过程中,采用BP (Back Propagation)算法对CNN模型进行迭代更新,并选择Adam算法进行优化。优化器的动量衰减和重量衰减因子分别设为0.9和0.005。初始学习率设置为0.001,并且激活NVIDIA®GeFore®GTX 1080Ti GPU加速CNN模型的训练过程。CNN模型的训练和测试过程是在PyTorch架构下完成的,其中配置文件采用encoder_intra_main.cfg,原因是本文只考虑降低HEVC帧内编码过程的复杂程度。实验共计对17个测试序列进行实验比较。这些测试序列均来自标准JCT-VC测试集[22],其中包含5个类别,分别是A、B、C、D和E类。为了评估算法编码效率、复杂度和主观视频质量,分别使用指标ΔT、BD-BR和BD-PSNR对所提出的基于深度学习的帧内编码单元划分算法和官方测试模型HM16.20算法进行比较。3个指标定义如下:
(1)ΔT:表示相较于原始编码方式的编码缩短时间,同时也表示编码中计算复杂度的降低程度,计算公式如式(3)所示:
(3)
其中,Tprop表示本文提出算法对应的实际编码时间,THM16.20表示使用官方测试模型HM16.20算法对应的编码时间。编码时间越短,表示复杂度的降低程度越高。
(2)BD-BR:表示在目标视频质量相同的情况下,优化算法与对比算法相比的比特率增量,计算公式如式(4)所示:
(4)
其中,DH和DL分别为RD输出曲线的最大值和最小值,r1和r2为2个相对应的比特率。BD-BR指保证相同图像质量的前提下对应码率的相对值,该值越小代表码率越小,意味着编码效率更佳。
(3)BD-PSNR(Bitrate-Distortion Peak Signal- to-Noise Ratio):表示在相同比特率下,优化算法与对比算法相比视频质量的客观改善程度,计算公式如式(5)所示:
(5)
其中,rH和rL分别为输出码率最大值和最小值,D1(r)和D2(r)为2个相对应的RD输出曲线。BD-PSNR指在保证相同码率的前提下亮度分量对应的峰值信噪比的大小,该值越小表示图像视频质量损耗越小。
根据以上参数,使用本文算法在4种QP值(22,27,32,37)下分别对A(2560×1600)、B(1920×1080)、C(832×480)、D(416×240)、E(1280×720)5类测试序列(选取其中14个测试视频的前50帧)使用全帧内编码配置进行编码测试实验,以充分测试不同视频编码方法的效果。
表2列出了利用本文设计对测试序列进行编码实验的结果,其中包含了BD-BR、BD-PSNR以及4种QP值下的编码时间缩短量ΔT。结果表明,A和E类的编码复杂度降低最多,C类和D类的编码质量损失最小。在测试序列中最多可缩短79.49%的编码时间,最小编码质量损失BD-BR为1.19%,对应BD-PSNR为-0.1 dB。
为了评估UcuNet在CU划分预测上的表现,本文完成了4组消融实验。4组实验分别采用了不同的CNN网络结构设置,如表3所示。具体来说,采用U-Net结合CU划分尺寸特性的3层结构中UcuNet-T是网络主干,UcuNet-E1和UcuNet-E2表示不同模块的消融,UcuNet-E3表示最终提出的方案。各模型结果需要在4种不同的QP值(22,27,32,37)下对每个序列的前10帧进行测试。测试序列为随机抽取的5种不同分辨率大小的视频,具体视频序列信息如表4所示。各网络对应的BD-BR和BD-PSNR测试结果如图4所示,图中数据越偏左上方对应的预测效果越好。可以看出,对于CU划分的深度预测,网络模型中不同模块的使用都有明显效果,其中最终网络UcuNet-E3效果最佳。

Table 3 Configuration of 4 ablation experiments 表3 4组消融实验配置
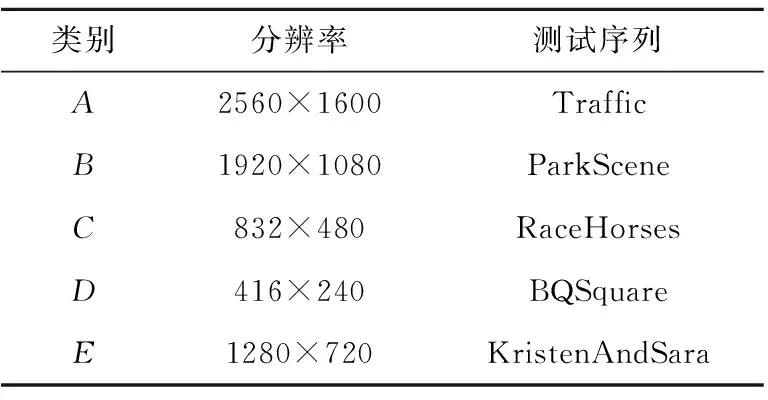
Table 4 JCT-VC test sequences used in ablation experiments表4 消融实验使用的JCT-VC测试序列

Figure 4 Performance of each model of the ablation experiments图4 消融实验各模型的性能结果
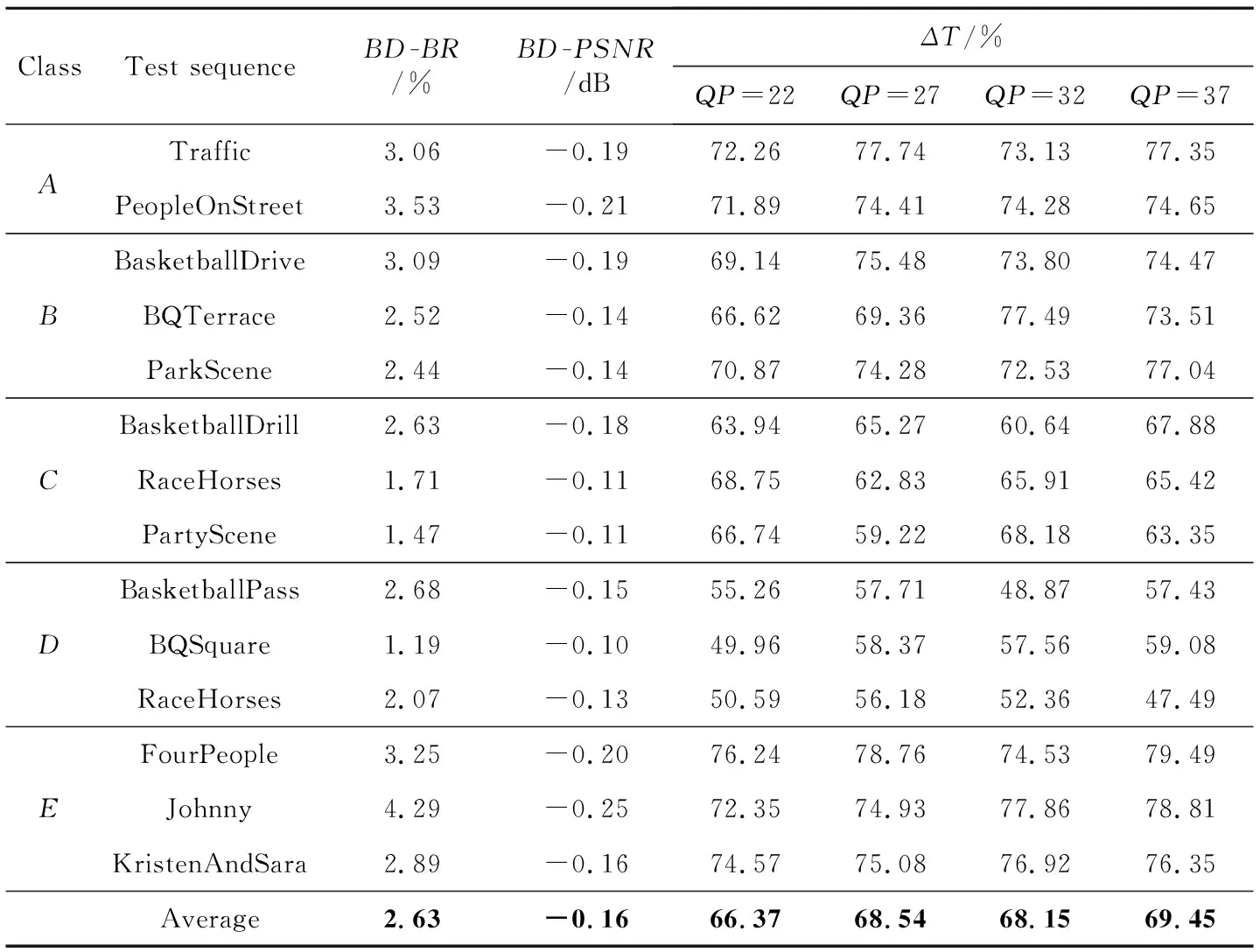
Table 2 Experimental results of UcuNet on JCT-VC testset
表5列出了本文设计和其他文献中算法关于以上性能的比较,其中ΔTAve表示4种QP值下ΔT的平均值。整体上与之前工作相比,在通用测试条件下本文设计算法性能提高较为显著,在编码复杂度的降低程度上也表现更好,同时编码质量也只有相对较小程度的降低。主要原因是UcuNet-E3可以通过CNN网络提取CTU块不同尺度的特征,从而一次性完整地预测各个类型的CU深度并进行编码,减少了CU划分过程中大量的冗余计算。由此可以看出,本文算法可以将编码损耗控制在可接受范围,更适合分辨率较高、实时传输方面的应用场景。

Table 5 Performance comparison of UcuNet and other algorithms表5 UcuNet和其他算法性能比较
4 结束语
本文提出了多尺度特征融合的UcuNet网络模型用于CU划分的高效预测,跳过了原始HEVC帧内编码中大量的冗余计算。整体结构以亮度块像素为基准,通过分层提取并拼接融合不同尺度CTU亮度块的特征,并利用了非对称卷积AC和CBAM注意力机制减少网络的参数量,同时提高了特征提取能力。模型利用了38个视频序列中的CTU和对应的编码信息作为样本进行训练。本文将此设计嵌入到HEVC官方测试模型HM16.20中进行实验。实验结果表明,本文设计用可接受范围内的编码性能损失为代价,缩短了68.13%的编码时间。目前本文设计的深度学习模型仅限于应用在帧内编码当中的CTU分区,未来的工作可以扩展到帧内和帧间编码部分中的PU(Prediction Unit)和TU(Transform Unit)分割预测,实现RD性能下降在可接受范围内,同时进一步降低HEVC的复杂度。另外,此设计还可以扩展到H.266/VCC中,但VCC中的分区过程比HEVC的更为复杂,未来需要开展更多相关的研究。
