基于改进YOLOv3的缺陷检测算法研究
2023-10-18成霄翔宋宝宇
成霄翔,宋宝宇
(鞍钢集团北京研究院有限公司,北京 102211)
近年来,随着机器视觉和深度学习技术的迅猛发展,机器代替人工的优势愈发凸显,对基于深度学习的钢铁领域缺陷检测的相关研究也愈发受到广大科技人员的重视。对于缺陷检测,不同于将其视为目标分类任务来求解,提出了一种更实用的基于目标检测的问题求解算法。目标检测任务是找出图像中所有感兴趣的目标,确定其位置、大小以及类别信息,即不仅需要输出图片中物体的类别信息,还需要得到物体所在的位置信息。此外,由于目标分类针对输入图片整体得到输出,而目标检测能够细化到图片中的物体,因而目标检测对于输入图片中含有混合缺陷的情形仍然适用。
现有的目标检测算法大致可分为两类:一是以R-CNN[1]系列为代表的两阶段算法,首先使用区域候选网络产生候选区域,然后使用检测网络对候选区域做缺陷类别分类和位置定位回归;另一类是以YOLO[2-3]为代表的一阶段算法,仅通过卷积神经网络直接预测不同目标的位置和类别,因其不需要经过区域候选阶段,相较于二阶段检测算法,速度更快,但检测精度较低。结合实际工业应用场景,在钢铁缺陷检测任务中,对检测速度的考量是衡量缺陷检测效率的一个重要指标,因此YOLO系列算法更为适用。
然而,聚焦到钢铁缺陷检测中,深度学习算法直接应用到工业环境中需要一定的策略。由于工业检测对实时性要求较高,因此适用于工业环境的算法设计必须考虑算法的高效性,这就需要研究网络结构轻量化策略来减少计算量提升效率。此外,由于钢铁领域生产线的全流程性,必须充分衡量当前产线缺陷检测的误检率和漏检率,以最大化降低缺陷产品对后续工序的影响,因此针对缺陷数据集特点提升准确率也是需要研究的方向。
综上,本文针对钢铁领域的缺陷检测任务,研究YOLOv3[3]目标检测算法从轻量化设计和提升检测精度两个维度的自适应改进,推动算法落地应用。
1 YOLOv3算法原理
1.1 网络结构
YOLOv3总体上将目标检测任务视为回归问题。其基本思路为将输入图像分成S×S大小的网格,每个单元格负责检测中心点落在该单元格中的目标。首先将输入图片经过特定的骨干网络提取特征,并结合多尺度预测策略,得到分别为原始图片1/8、1/16、1/32分辨率的特征图。之后分别在三种维度的特征图上同时预测类别概率和定位概率。
YOLOv3网络框架结构如图1所示,其中DBL由卷积层、批归一化层和非线性激活函数Leaky ReLu组成。Res_n是指包含n个残差单元的残差块,每个残差单元包含2个DBL单元和一个快捷链路。Conv是指1×1卷积操作,Concat为张量拼接操作。

图1 YOLOv3网络框架结构图Fig.1 Structure Diagram of YOLOv3 Network Framework
YOLOv3使用自定义的Darknet53网络提取图像特征,并在此过程中进行对原始图片的下采样。Darknet-53网络由3×3和1×1卷积连接而成,共有53层卷积层,并借鉴了ResNet的残差结构,使得网络层数加深时不会出现梯度消失或者爆炸的现象。此外为了降低池化操作带来的梯度负面影响,舍弃了池化操作,使用步长为2的卷积进行下采样。
YOLOv3 借鉴了特征金字塔(FPN)[4]的思想进行多尺度预测,相对于之前版本,尤其提升了对小缺陷目标的检测性能。通过将经过上采样的深层特征和浅层特征进行融合,对原始图片分别进行32、16和8倍下采样,相应得到原始图片的1/32、1/16、1/8三种不同分辨率特征图,从而实现对大、中、小目标的检测。
以将输入图片映射到1/32分辨率为例 (图2),若输入图片为416×416,则经过骨干网络提取特征后,特征图大小为13×13,这样便实现了对输入图片划分网格的操作。每一网格负责检测中心点落在该网格内的物体,并且输出三个边界框,每个网格的输出分别对应一个多维向量,包含边框坐标、边框置信度和目标类别概率。为了降低网络训练的难度,YOLOv3根据数据集,通过K-均值聚类算法生成九个锚框,分别应用于三个特征尺度,作为该尺度下预测框的先验知识。在锚框的基础上,模型对锚框进行微调,计算相对于锚框的偏移量得到预测框。

图2 网络输出结果示意图Fig.2 Schematic Diagram of Network Output Results
由于网络对同一个目标可能进行多次检测,通过非极大值抑制(NMS)算法消除重叠较大的冗余的预测框,得到最终输出。其基本思想是,如果有多个预测框都对应同一个物体,则只选出得分最高的预测框,丢弃剩余预测框。其算法流程如下:
(1)从所有候选框中选取置信度最高的预测边界框B1作为基准,将所有和B1重叠程度超过指定阈值的其他边界框移除;
(2)从所有候选框中选取第二置信度的边界框B2作为基准,将所有和B2重叠程度超过指定阈值的其他边界框移除;
(3)重复上述操作,直至所有预测框都被当成基准。
1.2 损失函数
YOLOv3将目标检测定义为回归问题,损失函数包含三部分目标定位损失 ,目标置信度损失和目标分类损失。目标定位损失衡量的是预测框和真实框之间偏移量。目标置信度损失为预测框的类别概率和预测框的置信度相乘而来,不仅表征是否含有目标,还包含预测框与真实框的接近程度。目标分类损失则用于衡量预测框的类别。
2 YOLOv3算法改进
2.1 轻量化改进
2.1.1 骨干网络轻量化改进
针对图像进行的卷积操作,标准卷积操作是将卷积核作用在所有的输入通道上,而深度可分离卷积则是将标准卷积拆分为一个深度卷积和一个逐点卷积,通过将卷积核拆分成单通道的形式,在不改变输入特征图像的深度的情况下,对每一通道进行卷积操作,这样就得到了和输入特征图通道数一致的输出特征图。逐点卷积就是1×1卷积,进一步对特征图进行升维和降维(图3展示了深度可分离卷积的构成)。因此深度可分离卷积的整体效果和一个标准卷积相差不多,但是能够大大减少模型的参数量和计算量。

图3 深度可分离卷积构成图Fig.3 Composition Diagram of In-depth Separable Convolution
原始的YOLOv3(YOLOv3-Darknet53)中采用了Darknet-53网络来提取特征,该网络为标准的卷积结构,卷积运算部分计算量大。针对上述问题,采用卷积操作为深度可分离卷积的MobileNet[5]网络作为骨干网络。
2.1.2 检测尺度改进
通常情况下,为了能够检测到不同尺度的目标框,需要进行多尺度预测,这也是原始YOLOv3通过多尺度检测能够提升对小缺陷目标检测能力的创新性所在。在进行预测框的先验计算时,K-means算法聚类得到9个锚框,按照面积大小均匀应用到三个不同尺度的特征图中。小分辨率的特征图(13×13)由于其下采样倍数大,感受野较大,因此分配大尺度的三个锚框 (16×90)、(156×198)、(373×326),用于检测大缺陷目标。中等分辨率和小分辨率的特征图(26×26,52×52)则分别用于检测中等大小的目标和小缺陷目标,如表1所示。

表1 多尺度预测中锚框的初值(图片大小为416×416×3)Table 1 Initial Value of Anchor Frame in Multi-scale Prediction (Picture Size 416×416×3)
对大多数数据任务而言,由于锚框使用从大型COCO数据集上聚类得到的三种尺度的锚框,适合检测大、中、小三尺度的缺陷,锚框参数具有代表性,因此无需进行更改。然而,对于钢铁领域的表面缺陷检测,数据集的缺陷尺度并非如此分布。缺陷大小不能天然地分出层级,小缺陷目标并不常见。
因此,为了进一步减少模型参数量和计算量,将原始网络中三个尺度预测减少为两个尺度的预测,只进行32倍和16倍下采样,去除针对小缺陷目标的检测分支,得到针对中等缺陷目标和大缺陷目标的特征图检测分支。改进后的网络结构如图4所示。
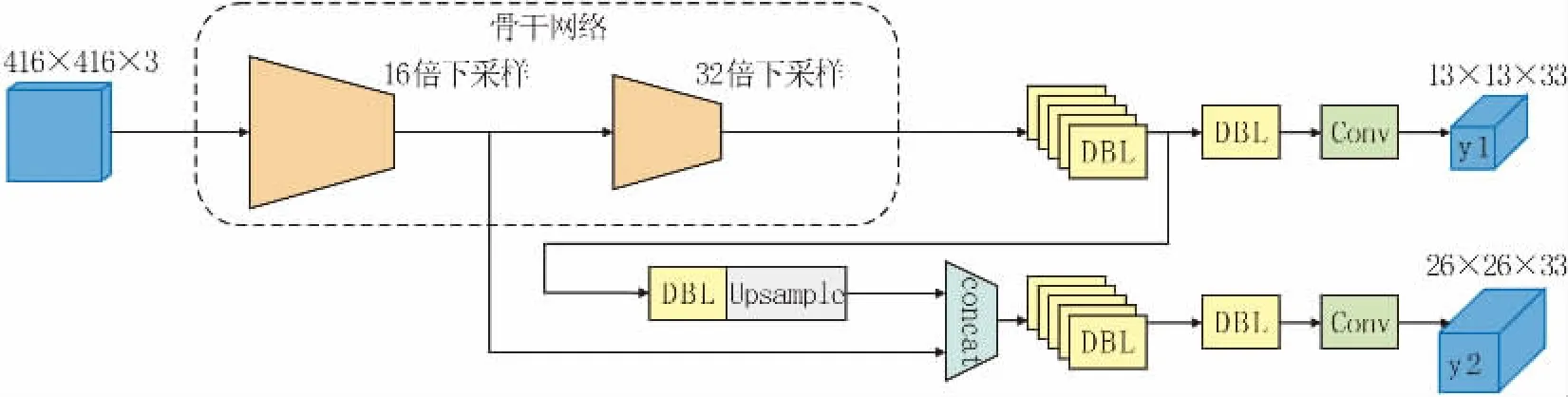
图4 改进后的网络结构图Fig.4 Network Structure Diagram after Improvement
2.2 检测效果提升
由于钢铁缺陷成因复杂且类型多样,部分缺陷类别图片呈现出背景干扰且无固定形状的特征。此外,由于部分缺陷样本类间差异较小,容易导致分类错误,为检测增加了难度。针对这种类别错检的情况,引入对分类损失函数进行类别加权的策略,通过加大对某种类别的惩罚来进一步约束模型的训练过程,进而提升检测精度,缓解模型在目标检测中出现的漏检问题。
对数据集中的缺陷类别,默认类别的重要程度均相等。在损失函数中对类别加权则是将某一类别赋予更大的权重,如果该类出错则损失函数增大更多,增加了误判成本。
具体而言,YOLOv3的目标分类损失lossclass中,默认类别权重数组为:
其中,数组长度为数据集的缺陷类别数。如果第i类缺陷的检测精度较低,且该类缺陷图像上呈现出缺陷特征不明显,与其他类别缺陷类间差异较小,则在类别权重数组中将该类缺陷的权重设为α(α>1),此时类别权重数组更新为:
之后重新开始训练网络。
3 实验及结果分析
3.1 数据集
训练和测试所采用的数据集为东北大学表面缺陷检测数据集(NEU-DET)[6]。 该数据集包含六种典型的热轧带钢表面缺陷,分别为开裂(Crazing,Cr)、夹杂(Inclusion,In)、斑块(Patches,Pa)、点蚀(Pitted Surface,PS)、氧化铁皮压入(Rolled-in Scale,RS)和划痕(Scratches,Sc)。 每种缺陷图像各有 300 张,将数据集按照8:1划分,则训练集1 600张,验证集200张。NEU-DET数据集部分图片如图5所示。

图5 NEU-DET数据集部分图片Fig.5 Some Pictures of Neu-det Data Set
3.2 实验环境
在PaddlePaddle深度学习框架上进行实验,并在 Win10系统 NVIDIA GTX 3080 GPU,11th Gen Intel(R)Core (TM)i9-11950H@2.60 GHz处理器的笔记本电脑中完成训练和测试。
3.3 结果分析
3.3.1 轻量化改进相关实验及结果分析
对于轻量化改进,轻量化网络应在保证检测精度的前提下,具有参数量少,计算量小,推理时间短的特点。其中参数量为模型所需要学习的参数总数,计算量用浮点运算数(floating point operations,FLOPs)来衡量,表征算法的复杂度。推理时间是指模型处理一张图片所需时间,根据推理时间也可得到模型的推理速度,即每秒内可以处理的图片数量。检测精度用平均精确度均值 (mean Average Precision,mAP)来衡量,其计算公式如下:
式中,TP为被正确预测的正样本;FP为被错误预测为正样本的负样本;FN为被错误预测为负样本的正样本;n为检测类别数;AP为各类的检测精度。
轻量化改进涉及到原始YOLOv3算法(YOLOv3-Darknet53),骨干网络更换后的YOLOv3算法(YOLOv3-Mobilenetv3)以及更改检测尺度的YOLOv3算法。
实验表明,将骨干网络从Darknet53更换为轻量级网络Mobilenet,模型的检测精度在千分位量级的误差上没有差异,但是后者的参数量、计算量以及推理时间均有所减小。轻量化改进模型结果对比如表2所示,可以看出改进算法对生产环境中的轻量化部署和实时检测需求更为适用。

表2 轻量化改进模型结果对比(图片大小为416×416×3)Table 2 Comparison of Results of Lightweight Improved Model(Picture Size 416×416×3)
对检测尺寸的更改是基于对数据集的分析,将原始的Pascal VOC数据集[7]和本实验所用的NEUDET数据集分别采用K-Means算法聚类出9个锚框并进行可视化,如图6所示。

图6 VOC数据集和NEU-DET数据集分布情况对比Fig.6 Comparison of Distribution between VOC Data Set and NEU-DET Data Set
Pascal VOC数据集聚类得到的锚框按照面积排列有大、中、小三个尺度,适合原始YOLOv3输出三种分辨率下特征图的多尺度检测策略。而NEUDET数据集按照面积难以区分为三个尺度,且没有过于狭小的缺陷。因此,相对于原始YOLOv3中的多尺度检测检测策略,将改进后的YOLOv3算法检测尺度调整为2。其和检测尺度为3的YOLOv3算法对比见表2。改进后的网络模型更为轻量,且减少了由于数据集中部分目标大小相近而导致的标签重写现象[8],检测精度有所提升。
3.3.2 检测精度提升相关实验及结果分析
统计各类别的检测精度,类别权重对模型检测精度的影响如表3所示。
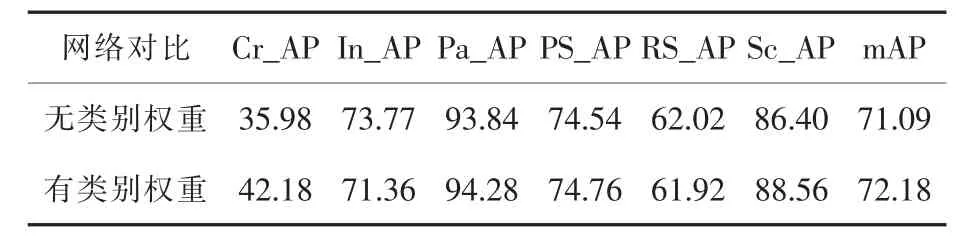
表3 类别权重对模型检测精度的影响(图片大小为 416×416×3)Table 3 Comparison of Results of Lightweight Improved Model(Picture Size 416×416×3) %
由表3可以看出,开裂(Cr)类别的检测精度是最低的。因此,将YOLOv3损失函数中的原始类别权重数组 [1.0,1.0,1.0,1.0,1.0,1.0]调整为[10.0,1.0,1.0,1.0,1.0,1.0],其中数组的第一个位置为开裂类别。实验表明,由于该类别的分类权重远高于其他类别,所以在训练过程中加大了对该类别出错的惩罚,对该类别的检测精度有所提高。
3.3.3 部分检测结果展示
使用改进的YOLOv3算法得到的部分检测结果图如图7所示。训练好的模型不仅能够检测到各类别缺陷,而且对于包含混合缺陷的图像也能得到较好的检测效果。

图7 部分检测结果图片Fig.7 Pictures of Some Test Results
由图7(c)可以看出,斑块类别样例包含斑块和夹杂缺陷,可见本文模型能很好地检测到混合缺陷,也进一步验证了相较于将缺陷检测视为图片分类而言,将其视为目标检测更能够正确检测图片中存在混合缺陷的情形。
4 结语
钢铁领域缺陷检测是保证钢铁生产质量的重要环节,通过目标检测算法来得到缺陷的类别和信息具有重要意义。以东北大学带钢表面缺陷数据集(NEU-DET)为实验对象,开展YOLOv3算法在实际生产环境中的自适应改进,进一步降低了模型的参数量和计算量,从提高单一类别的性能着手,提升了检测精度。通过实验验证了改进后的YOLOv3算法更能满足实际工业场景中轻量化部署以及快速推理的需求。
