基于BiLSTM-CRF的中文分词和词性标注联合方法
2023-10-13袁里驰
袁里驰
(江西财经大学 软件与物联网工程学院,江西 南昌,330013)
分词的目的是将一个完整的句子切分成词语级别。由于英语语句由不同的单词组成,故其分词可以依据单词间的分界符来划分,而中文语句的基本组成单位是字,无法像英语那样依据分界符来划分,因此,中文分词相比于英语分词更增加了一定的难度。中文分词是其他中文信息处理应用的基础,其结果直接影响机器翻译、信息检索、信息抽取等信息处理技术的正确率。近年来,中文分词技术发展迅速,但由于自然语言使用复杂,中文分词依然是信息处理的难点之一。
目前大多数分词方法都将中文分词作为一个序列标注问题,常用的序列标注方法有支持向量机(support vector machine, SVM)、最大熵模型(maximum entropy, ME)、隐马尔可夫模型(hidden markov model, HMM)、条件随机场(conditional random field, CRF)模型。随着深度学习方法的发展,一些神经网络模型[1-5]也被成功应用于中文分词任务。ZHENG 等[6]提出了基于神经网络的中文分词模型;CHEN 等[7]扩展了长短时记忆(long short-term memory, LSTM)神经网络模型用于中文分词,解决了传统的神经网络模型不能学习词的长距离依赖关系的问题,取得了较好的分词效果。ZHANG 等[8]提出了一种基于词向量的分词神经网络模型,将卷积神经网络和LSTM相结合,模型输入端特征向量包含字符嵌入和预训练语料库学习到的词嵌入。研究表明LSTM神经网络模型在序列标注任务中能取得不错的效果。HUANG 等[9]将双向LSTM 和CRF 结合,在序列标注任务中取得了较好的效果。双向LSTM(BiLSTM)可以对目标词同时学习上下文信息,CRF 层可以通过学习训练得到句子级的标签信息。BLSTM-CRF模型具有较好的鲁棒性,该模型对词嵌入的依赖性更小。
所谓词性标注就是根据句子上下文中的信息给句中的每个词一个正确的词性标记。词性标注是进一步进行自然语言处理的重要基础,是文本索引、文本分类、语言合成、语料库加工等应用领域的重要环节。因此,对词性标注的方法进行研究具有重要意义。现有的词性标注所采用的语言模型主要可以分为基于规则的方法和基于统计的方法[10-14]。基于规则的标注系统与系统设计者的语言能力有关,其中规则集直接体现了设计者的语言能力。然而,要对某一种语言的各种语言现象都构造规则,是一项很艰难也很耗时的任务。基于统计的方法主要有最大熵模型、隐马尔可夫模型、条件随机场模型等。隐马尔可夫模型是广泛应用于词性标注任务中效果较好的统计模型。针对隐马尔可夫词性标注模型状态输出独立同分布等与语言实际特性不够协调的假设,袁里驰[10]对隐马尔可夫模型进行改进,引入了马尔可夫族模型(markov family model, MFM)。马尔可夫族模型用条件独立性假设取代了HMM模型的独立性假设,相对条件独立性假设,独立性假设是过强假设,因而,基于马尔可夫族模型的语言模型更符合语言实际。将马尔可夫族模型成功应用于词性标注,用改进的隐马尔可夫模型进行词性标注实验,结果表明,在相同的测试条件下,马尔可夫族模型明显优于隐马尔可夫模型。
中文分词和词性标注2个阶段的处理方案是先进行分词再进行词性标注或者分词和词性标注一起进行。传统方法是分开处理这2个阶段,但分词的精度和词性标注的准确度密切相关,分词产生的错误可能会影响词性标注的准确率。近年来,人们对分词和词性标注联合模型进行了大量研究。使用联合模型可以有效地降低错误传递,并且有助于使用词性标注信息实现分词,有机地将两者结合起来,有利于消除歧义和提高分词、词性标注任务的准确率。本文提出一种基于双向长短时记忆神经网络模型、条件随机场的中文分词和词性标注联合方法,该方法将马尔可夫族模型(改进的隐马尔科夫模型) 或树形概率(tree-like probability, TLP)的计算方法应用到分词、词性标签推断CRF 层的转移概率计算中,大幅度提高了分词和词性标注的准确率。
1 基于马尔可夫族模型的词性标注
统计标注方法如隐马尔可夫模型在计算每一输入词序列的最可能词性标注序列时,既要考虑上下文,也要考虑二元或三元概率(这些参数可通过已标注用于训练的语料估计得到)。目前,许多种语言都有人工标注的训练语料,并且统计模型有很强的鲁棒性,这些优点使得统计方法成为当前主流的词性标注方法。基于隐马尔可夫模型的词性标注存在的不足有:为了达到很高的标注准确率,需要大量的训练语料;传统的基于隐马尔可夫模型的标注方法没有结合现有的语言知识。隐马尔可夫模型在用于词性标注时作了3个基本假设:1) 马尔可夫性假设;2) 不动性假设;3) 输出独立性假设,即输出(词的出现)概率仅与当前状态(词性标记)有关。但是这些假定尤其第三个假定太粗糙。本文引入一种统计模型,即马尔可夫族模型[15](树形概率是其简化),假定一个词出现的概率既与它的词性标记有关,也与前面的词有关,但该词的词性标记与该词前面的词关于该词条件独立(即在该词已知条件下是独立的)。在以上假设下,简化马尔可夫族模型,可成功用于词性标注。实验结果证明:在相同的测试条件下,基于马尔可夫族模型的词性标注方法比常规的基于隐马尔可夫模型的词性标注方法大大提高了标注准确率。
设T表示词性,W表示词,词性标注即为在已知输入词序列w1,n的条件下,寻找最大可能的词性标记序列T1,n的任务:
假设任意一个词的词性标记和该词前面的词关于该词条件独立(即在该词已知的条件下独立):
在上述假定下,可以利用马尔可夫族模型进行词性标注,为了简单,假定随机向量{wi,Ti}i≥1的成分变量{wi}i≥1、{Ti}i≥1都是2 阶马尔可夫链,即
得到词性标注模型后,要采用有效的算法求出在给定输入条件下概率最大的词性标记序列。Viterbi算法是一种动态编程的方法,能够根据模型参数有效地计算出一给定词序列w1, …,wn最可能产生的词性标记序列T1, …,Tn。计算过程如下。


2 基于BILSTM-CRF的分词和词性标注联合方法
将分词和词性标注统一在一个联合模型架构中,可以有效地降低错误传递,并且有助于使用词性标注信息实现分词,有机地将两者结合起来有利于消除歧义和提高分词、词性标注任务的准确率。
中文分词、词性标注分别通过所属标注来判断每个字符在词语中的位置、词语的词性标记。中文分词常用的标注集是{B,M,E,S},利用这四种标注获取词语的边界信息,其中B、M、E表示词语的开头、中间、结尾,S表示单字词。本文中文分词、词性标注联合方法采用的标注集是{B,M,E-T,S-T},其中T表示词性。基于BiLSTMCRF 的分词、词性标注联合模型由字符嵌入层、BiLSTM层和CRF层3部分组成。
2.1 字符嵌入层
利用神经网络模型处理中文分词、词性标注问题,首先需要将文本向量化表示,即使用一个特定维度的特征向量代表字符。字符向量可以刻画字与字在语义和语法上的相关性,并且作为字符特征成为神经网络的输入。
首先,用Word2Vec 算法[16]在中文维基百科语料库中进行训练,获得d维字符向量,形成d×N的字符矩阵,其中N表示训练语料库中有效字符个数。其次,对于句子中的每个字符xi,设置长度l=5(l的值可调)的窗口,提取xi的上下文字符序列(xi-2,xi-1,xi,xi+1,xi+2)。对于窗口中的每个字符,从字符矩阵中查找得到相应的向量。最后,为当前字符xi构建字符嵌入向量ei。
2.2 BILSTM层
循环神经网络(RNN)利用隐藏状态来保存历史信息,是解决序列标注问题的一种有效方法。然而,由于梯度消失,RNN 不能很好地学习到词的长距离依赖关系。长短期记忆网络(LSTM)[17]在RNN 的基础上引入记忆单元来记录状态信息,并通过输入门、遗忘门和输出门的门结构来更新隐藏状态和记忆单元。LSTM 网络由LSTM 单元构成,一个LSTM单元由输入门、遗忘门、输出门和细胞状态构成。输入门控制细胞状态加入新的信息量,遗忘门控制前一时刻细胞状态被丢弃的信息,输出门控制隐藏状态的输出。设t时刻的LSTM的工作流程可表示为:
式中:et表示t时刻的输入向量;ht-1表示LSTM单元t-1时刻隐藏状态的输出;ct-1表示t-1时刻的细胞状态;it、ft、ot、ct分别代表输入门、遗忘门、输出门和细胞状态;σ(∙)代表sigmoid函数;⊙表示元素间的点积;Wi、Wf、Wo、为ht-1的权重矩阵;Ui、Uf、Uo、为et的权重矩阵;bi、bf、bo、为偏置向量。
LSTM的门机制使得模型可以捕捉长距离历史信息。为了同时获取上下文信息,采用双向LSTM(BI-LSTM),如图1所示。双向LSTM[1]网络有2个不同方向的并行层:前向层和后向层。2个并行层分别从句子的前端和末端开始运行,存储了来自2个方向的句子信息,进而提高分词和词性标注性能。因此,BI-LSTM中的输出(隐藏状态)ht可表示如下:

图1 BiLSTM示意图Fig. 1 Schematic diagram of BiLSTM
2.3 基于MFM(或TLP)的标签推断CRF层
对于基于字符的中文分词和词性标注任务,需要考虑相邻标签间的依赖关系。例如,B(开始)标签后面应该跟一个M(中间)标签或者E-T(结束)标签,而一个M标签后面不能跟一个B标签或者S-T标签。因此,不是独立地使用ht来做标签决策,而是使用条件随机场来共同建模标签序列。条件随机场是一种用来计算在给定输入随机变量时,输出随机变量的条件概率的无向图模型,它结合了最大熵模型和隐马尔可夫模型的特征,具有表达长距离依赖性和交叠性特征的能力,能够较好地解决标注偏置等问题,因此,在自然语言处理领域有着广泛的应用。
给定句子X=(x1,x2,…,xn)和对应的预测标签Y=(y1,y2,…,yn),yt∊{B,M,E-T,S-T},其中,T表示词性。预测标签Y=(y1,y2,…,yn)包含分词信息和词性标注信息,可以分解为分词标签Z=(z1,z2,…,zn),zt∊{B,M,E,S}和分词条件下的词性标注标签P(T1,T2,…,Tm|w1,w2,…,wm),其中,w1,w2,…,wm为给定句子X=(x1,x2,…,xn)在分词标签序列Z=(z1,z2,…,zn)下的词序列。
假设在给定词序列条件下词性标注满足马尔可夫族模型(MFM),有下式成立:
对于给定句子X=(x1,x2,…,xn)和对应的预测标签Y=(y1,y2,…,yn),预测评估分数定义如下:
其中:Azi-1,zi为一个分词标签转换分数矩阵的元素;BTk-1,Tk为一个词性标签转换分数矩阵的元素;Qi,yi为字符xi在分词和词性联合预测标注yi上的得分。Qi定义如下:
其中:ht为BiLSTM 中t时刻输入数据xt的隐藏状态;Ws为权值矩阵;bs为偏置向量。
假设在给定词序列条件下词性标注满足树形概率(TLP),则有下式成立:
则对于给定句子X=(x1,x2,…,xn)和对应的预测标签Y=(y1,y2,…,yn),预测评估分数定义如下:
在CRF层,句子X被标记为序列Y的可能性概率计算如下:
其中:YX表示给定句子X的所有可能标签序列的集合。
深度神经网络训练时,损失函数定义如式(19)所示。
其中:Ω(θ)是为了防止神经网络的过拟合而添加的正则项。
3 基于BiLSTM-CRF 的词性标注方法
对于词性标注这种序列标注任务来说,可以把输入的文本看作是线性序列,文本中词为序列的一个元素,每个元素的标注在很大程度依赖于前面元素的信息。LSTM 隶属于循环反馈神经网络,它可以将文本中某一序列元素与某时刻模型的输入对应起来,利用隐层单元的记忆模块,保存长间隔信息,对序列元素逐一标注。将双向LSTM 和CRF 结合应用于单独的词性标注任务中,同样可取得很好的效果。
3.1 基于BiLSTM-CRF和马尔可夫族模型的词性标注方法
假设在给定词序列条件下词性标注满足马尔可夫族模型,即对给定词序列U=(w1,w2,…,wm)和对应的预测词性标签序列V=(T1,T2,…,Tm),预测评估分数定义如下:
其中:代表词wk在词性预测标注Tk上的得分。定义如下:
其中:hk为BiLSTM 中k时刻输入词wk的隐藏状态;Ws*为权值矩阵;b*s为偏置向量。
3.2 基于BiLSTM-CRF 和树形概率(tree-like probability)的词性标注方法
假设在给定词序列条件下词性标注满足树形概率,即对给定词序列U=(w1,w2,…,wm)和对应的预测词性标签序列V=(T1,T2,…,Tm),预测评估分数定义如下:
4 实验结果及分析
本文模型的主要设置如下:隐藏层节点的维度设置为256,字向量和词向量的维度都是128,增加维度并不能再提高效果。本文实验学习率取值0.001;实验采用Dropout 机制来防止神经网络过拟合,实验中Dropout设置为20%。
word2vcc 模型训练采用Skip-Gram 训练目标。本文利用新浪微博语料和中文维基百科语料库训练word2vec 字向量,利用中文维基百科语料训练词向量,最终得到各个字的字向量和各个词的词向量。
4.1 词性标注实验
词性标注实验采用的数据集为人民日报1998年上半年标注语料(约700 万个词)和CTB8.0。其中,《人民日报》标注语料是由北京大学计算语言学研究所和富士通研究开发中心有限公司共同制作的标注语料库,内容涉及政治、经济、文艺、体育、报告文学等多种题材,该标注语料对纯文本语料进行了词语切分和词性标注,使用39 种词性标记;CTB8.0是宾州大学汉语树库中的语料库,该语料库是经过分词、词性标注和句法标注的数据库,按照句子内部结构形成句子树,语料中共出现了32 种词性标记。实验中,语料库将分割为训练集、开发集和测试集3部分,各集数量比例为7:1:2。采用标注准确率(Accuracy)评估词性标注性能,标注准确率是常用的评测指标,它表示已正确标注词性的词语在所有待标注词性的全部词语中所占的百分比。
针对相同的语料库,分别采用HMM(隐马尔科夫模型)、MFM(马尔可夫族模型)、BiLSTMCRF-TLP(基于双向长短时记忆神经网络模型、条件随机场模型、树形概率)、BiLSTM-CRF-MFM(基于双向长短时记忆神经网络模型、条件随机场模型、马尔可夫族模型)进行词性标注。表1 所示为不同方法的词性标注准确率。
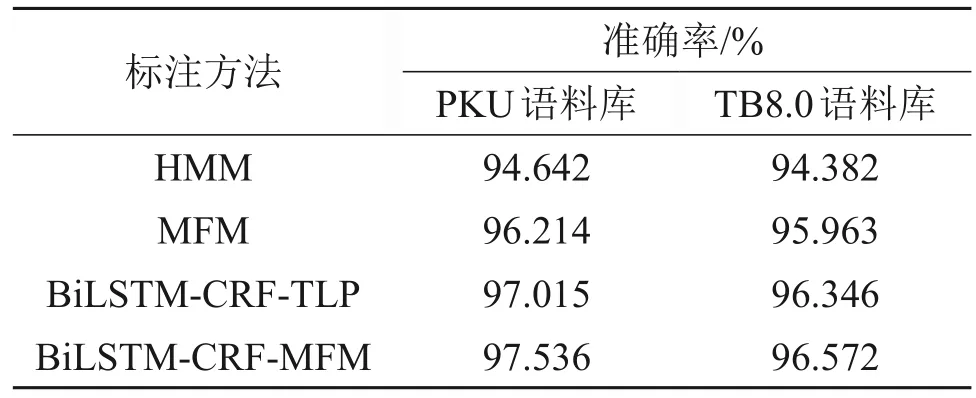
表1 不同方法的词性标注准确率Table 1 Accuracy of different part-of-speech tagging method
从表1 可以看出:由于基于隐马尔科夫模型(HMM)的词性标注方法计算过程只计算了词性到词的发射概率,而忽略了词本身到词性的发射概率,因此,会因为发射概率太小而被标错词性。在基于马尔可夫族模型或树形概率的词性标注中,当前词的词性不但与前面词的词性有关,而且与当前词本身有关,因而,在相同测试条件下,基于马尔可夫族模型或树形概率的词性标注方法比常规的基于隐马尔可夫模型的词性标注方法大大提高了标注准确率;LSTM神经网络模型解决了传统的神经网络模型不能学习词的长距离依赖关系的问题,在词性序列标注任务中能取得不错的效果,基于BiLSTM-CRF 和马尔可夫族模型(或树形概率)的词性标注方法进一步提高了标注准确率。由于CTB 的训练语料库规模小于PKU 的训练语料库规模,因而,采用相同的词性标注方法时,CTB8.0语料库的词性标注准确率明显比PKU语料库的低。
4.2 分词和词性联合标注实验
分词和词性联合标注实验使用的实验语料为PKU、MSR 和CTB8(来自Chinese Treebank 8.0)。其中,PKU和CTB8与词性标注实验的相同,MSR是微软亚洲研究院所提供的语料库,其分词特点是由大量的命名实体构成的长单词。
式(14)和(17)中的分词标签转换分数矩阵A由语料集PKU、MSR 和CTB8 联合训练得到,其他模型参数分别在语料集PKU、CTB8上单独进行训练。分词性能采用召回率和精确率的调和平均值F1来评价:
其中,精确率P为指预测正确的分词数目与预测分词数目的比值;召回率R为指预测正确的分词数目与测试集中正确的分词数目的比值。
应用马尔可夫族模型(MFM)、树形概率(TLP)进行词性标注,并结合双向长短时记忆神经网络模型(BiLSTM)和条件随机场模型(CRF)提出了中文分词和词性标注联合方法BiLSTM-CRF-MFM 和BiLSTM-CRF-TLP。表2所示为不同语料集的分词测试性能[18-19]。由表2可以看出:本文提出的分词方法在基于字的BiLSTM-CRF 中文分词模型基础上,利用词性标注信息实现分词,有机地将中文分词和词性标注结合起来明显提高了分词效果;在中文分词上,相比于BiLSTM-CRF 分词模型和Switch-LSTMs 分词模型,本文提出的BiLSTMCRF-MFM和BiLSTM-CRF-TLP方法分词效果有大幅度提高,并且基于马尔可夫族模型(MFM)、长短时记忆神经网络模型和条件随机场模型的中文分词和词性标注联合方法BiLSTM-CRF-MFM取得了最佳的效果。

表2 不同语料集的分词测试性能Table 2 Word segmentation test results of different test sets
采用语料集PKU和CTB8,将本文中文分词和词性标注联合方法与文献[20-21]中方法进行比较,结果分别如表3[20]和表4[21]所示。

表3 不同方法在CTB语料集上的实验结果对比Table 3 Comparison of experimental results of different methods on the corpus CTB

表4 不同方法在PKU语料集上的实验结果对比Table 4 Comparison of experimental results of different methods on the corpus PKU
实验结果表明,中文分词和词性标注联合方法BiLSTM-CRF-MFM能同时大幅度提高分词和词性标注效果。在基于马尔可夫族模型的词性标注中,当前词的词性不但与前面词的词性有关,也与当前词本身有关。因而,在相同测试条件下,与常规的词性标注方法相比,基于马尔可夫族模型的联合标注方法BiLSTM-CRF-MFM大大提高了词性标注准确率。
5 结论
1) 本文提出了结合BLSTM、CRF 和马尔可夫族模型(MFM)或树形概率(TLP)构建的中文分词和词性标注联合方法。本文的中文分词和词性标注联合方法相比于BiLSTM-CRF 分词模型能够大幅度提高分词的准确率。
2) 使用联合模型可以有效地降低错误传递次数,并且有助于使用词性标注信息实现分词,有机地将两者结合起来有利于消除歧义和提高分词、词性标注任务的准确率。
