基于知识图谱使用多特征语义融合的文档对匹配
2023-10-13陈毅波张祖平黄鑫向行何智强
陈毅波,张祖平,黄鑫,向行,何智强
(1. 国网湖南省电力有限公司,湖南 长沙,410004;2. 中南大学 计算机学院,湖南 长沙,410083)
识别文档对的关系是一项自然语言理解任务,也是文档查重和文档搜索工作必不可少的步骤。人工区分文档需要花费大量的人力资源成本,而早期文档识别方法主要基于术语相似度和规则。传统的基于术语如TF-IDF 向量、BM25、LDA 的匹配方法通过无监督指标评估文档对之间的语义信息[1-4],在查询文档、检索和搜索信息方面该方法取得了较大的成功,而基于规则的模型的稳定性取决于构建的知识结构。此外,基于机器学习的文档识别方法主要思想是将文档分成多个类别,然后进行分类以进行检索,在新闻报道、文献查重等领域也取得了很好的识别效果[5]。
目前,文档表示方法主要包括词袋(BOW)[6]、词频逆文档频率(TF-IDF)[1]、隐含狄利克雷分布(LDA)[3]等向量,但是这些表示方法无法捕获语义信息,通常无法获得良好的性能。为了更好地捕捉语义关系,研究人员提出了图形文档表示[4],现有的大多数图形文档表示主要有词、文本、概念和混合图4 类[4]。在单词图中,文本中的单词作为顶点,通过句法分析、共现[4]等方法构建边;在文本图中,句子、段落或文档都被视为顶点,词共现、位置[7]、文本相似性被用来构建边。
近年来,研究人员提出多种用于文本匹配的深度神经网络模型[8-9],可以通过递归或卷积神经网络来捕捉自然语言中的语义依赖(尤其是顺序依赖)关系,其中,WAN 等[8]提出了一种多语言通用的BiLSTM-CRF 模型,利用词嵌入作为特征来识别命名实体;罗凌等[9]使用了CNN 与CRF 相结合在中文电子病历上做命名实体识别研究;赵宏等[10]所提出的BiLSTM-CNNs模型在中文评论数据集上实现了92.64%的F1 值;SHEN 等[11]提出了一种基于命名实体识别的方法运用在深度主动学习上,帮助深度主动学习在医学和影像领域也取得了很大的成果[12],与深度学习方法相比,它只需要少量的训练数据即可获得相同的效果。然而,这些神经网络模型没有充分利用长文本文档固有的结构特征。BERT预训练模型[13]可以用于长文本匹配,但是模型复杂度高,难以满足实际应用中的速度要求。
然而,现有的涉及句子对匹配的深度模型主要用于释义识别、文档中的答案选择、实体或较长文档中句子之间复杂的交互[8]等文档匹配,但它并没有被充分研究。其中,长文档间的语义匹配在很大程度上是一个未开发的领域,尽管有很多用于句子匹配的数据集[9],但没有用于匹配长文档的公共标签数据集。
为了对长文档的语义匹配进行评估,本文首先构建了2个带标签的数据集,一个是已标注项目可研文档对(来自不同项目)是否属于同一个项目,另一个是已标注文档对是否属于同一个主题,将DBPEDIA 等知识库[14]中的专业术语链接到实际中的文档匹配,通过捕获文档中的专业术语以构建概念图。在此基础上,提出了一种后端匹配算法,以概念图的形式表示和匹配长文档,基于构建的概念图(concept graph,CG)和图神经网络(graph convolution network,GCN)来匹配一对文档,其思想是对于两个文档中出现的每个概念顶点,首先获得一个局部匹配,然后采用GCN 将局部匹配向量聚合为最终匹配结果,该结果基于图的整体视图通过一系列文本编码方案(包括神经编码和基于术语的编码)生成。最后,对于关键字识别,提出了一种基于概念的多特征语义融合模型(multifeature semantic fusion model,MFSFM),引入上下文多特征嵌入(contextual multi-feature embedding,CMFE)结构来优化文本表示。
1 模型构建
1.1 概念图
本文采用概念图将文档表示为无向扩展图。将文本转化为概念图的示意图如图1所示。

图1 将文本转化为概念图的示意图Fig. 1 Schematic diagram of converting texts into a concept graph
首先,将文档分解为句子的子集,每个句子与其产生的概念进行对齐。比如在文档D中,概念图GD是一个关键字或一组高度相关的关键字[4]。在概念图中,先将关键字分组为概念,然后将每个句子附加到其最相关的概念顶点[4]。例如,在图1 中,句子1 和句子2 主要讨论“变压器”和“电气设备”的关系,因此被附加在概念(变压器、电气设备)之后。总的来说,本文基于知识图谱使用一个包含关键字信息的概念图来正确地表示原始文档。每个概念图都有一个句子的子集和它们之间的拓扑关系。从文档对构建概念图并通过GCN对其进行分类的方法概览如图2所示,它诠释了概念的发现、概念与句子的对齐方式和文档概念图的构造过程。拆分文档以及合并概念图的步骤如下。
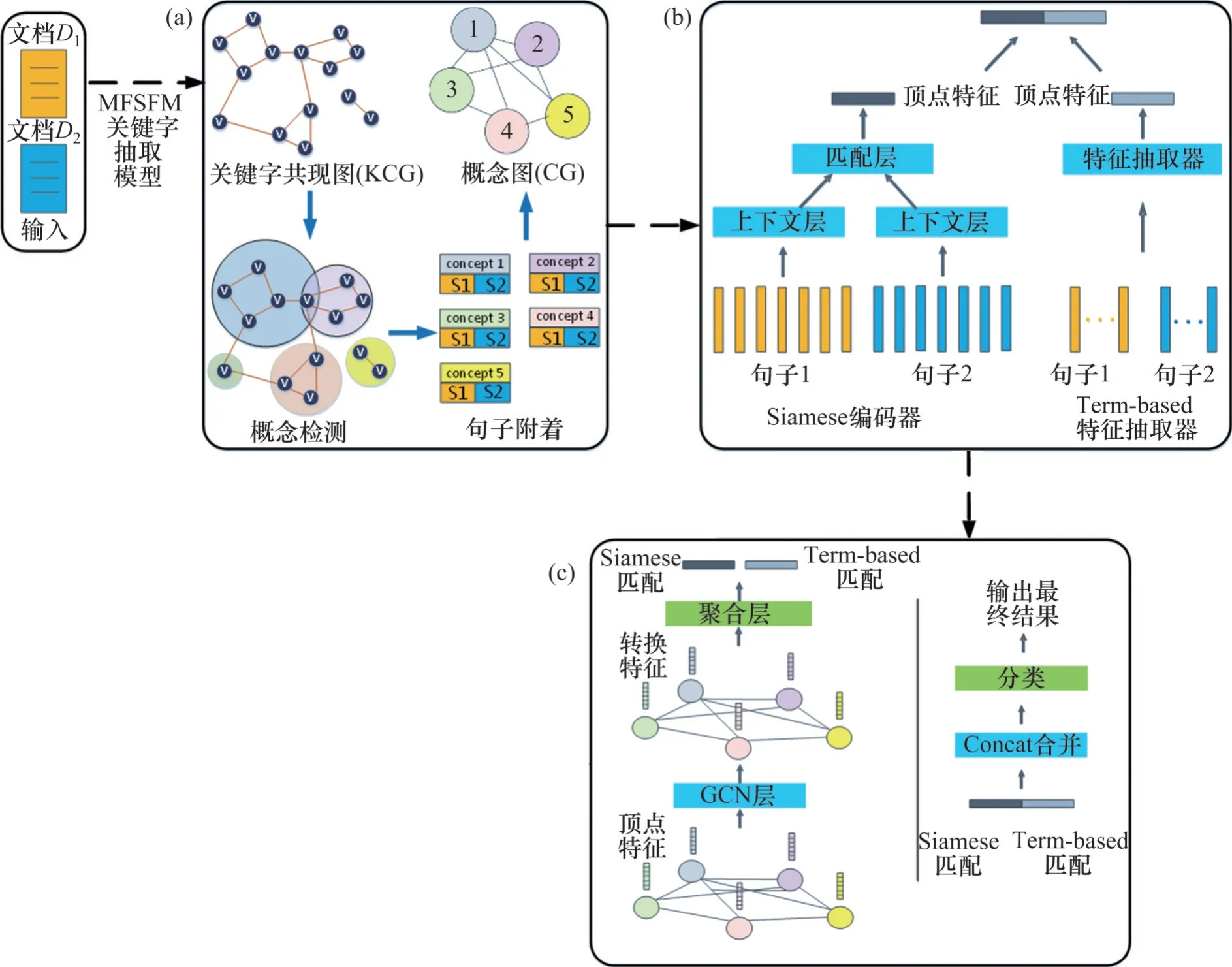
图2 从文档对构建概念图并通过GCN对其进行分类的方法概览Fig. 2 Overview of the method of constructing CG from document pairs and classifying them through GCN
步骤1) 构建关键字共现图。给定一个文档,应用命名实体识别方法提取命名实体和关键字,并且基于找到的关键字集构建一个关键字共现图(keyword co-occurrence graph,KCG),其中每个关键字代表一个顶点。如果2个关键字同时出现在同一个句子中,则构建一条边将它们连接起来。为了进一步改进模型,还可以通过共同实体分析和同义词分析来组合具有相同含义的键。
步骤2) 概念检测。KCG 的架构揭示了关键字之间的交互关系。当2 个关键字的集含高度相关时,就可以在KCG中构建一个密集连接的子图[4]。此外,使用社区检测算法可以将KCG 划分为一组社区,其中每个社区包含某个概念的关键字集合。由于每个关键字可能出现在多个概念中,且不同文档中的概念数量差异很大,本文使用一种基于介数中心性得分的算法[15]检测KCG 中的关键字社区,而且每个关键字都可直接作为一个概念来使用,因此,概念检测的优点是减少了顶点的数量,增加了匹配速度。
步骤3) 句子附着。通过捕获文档关键字来发现概念后,按概念对句子进行分组,然后计算句子和概念之间的余弦相似度,并且使用TF-IDF 向量表示[1]。不包含概念匹配的句子将被附加到虚拟顶点。虚拟顶点不包含任何关键字。
步骤4) 构建边。通过在概念之间放置边来体现概念之间的关系,对于每个顶点,将其句子集表示为与其相连的一系列句子,并使用TF-IDF 相似度计算两者之间的边权重。虽然可以使用其他方式来确定边的权重,但是通过TF-IDF 构造边更好,这样生成的概念图的连接更紧密。
1.2 文档对匹配
对于给定的2个文档DA和DB,首先匹配DA和DB中与每个概念相关的句子集;然后,分别采用Siamese 编码器和Term-based 特征抽取器匹配该文档对[4]得到局部匹配结果并通过多个图卷积层将局部匹配结果聚合成最终结果。为了克服以往算法的缺点以及在较长的文本中捕获更多的语义交互,本文从图形角度来表示文档。
图2 所示为基于MFSFM 的文档对匹配模型的整体架构,包括4个步骤:1) 通过单个合并的概念图表达文档对;2) 研究每个概念顶点的多视图匹配特征;3) 进行结构化转换,通过GCN 获得局部匹配特征;4) 对局部匹配特征进行分组得到最终结果。以上4个步骤以端到端的方式进行训练。
对于给定分组后的概念图GAB,所提出的模型首先为每个概念v(v∈GAB)学习一个固定长度的匹配向量,以表示文档DA和DB的句子集CA(v)和CB(v)之间的TF-IDF 语义相似度。这意味着将两个文档匹配转换为每个顶点的句子集对匹配。进一步地,基于术语的技术和神经网络生成局部匹配来聚合匹配向量。Siamese 网络编码器[15]被应用于每个顶点v,将{CA(v),CB(v)}的词嵌入转换为固定大小的隐藏特征向量mAB(v)。
首先,采用Siamese 编码器将CA(v)和CB(v)分别编码成上下文向量tA(v)和tB(v)。采用包含1个或多个BiLSTM 或CNN 层的神经网络来学习CA(v)和CB(v)中的上下文信息。然后,通过后续聚合层[4]来计算顶点v的mAB(v)。分别计算上下文向量tA(v)和tB(v)的逐元素乘法以及逐元素绝对差,并拼接成mAB(v),即
其中:“◦”表示Hadamard积[2]。
在采用Term-based 特征抽取器匹配文档时,综合4种计算指标(TF-IDF余弦相似度、TF余弦相似度、BM25 余弦相似度和1-gram 的Jaccard 相似度)来计算CA(v)和CB(v)之间基于术语的相似度,作为v的另一个匹配向量m′AB(v)。
一般而言,图G=(V,E)被认为是GCN 的输入,其中,V和E分别为顶点和边的集合,第i个顶点vi∈V,第i和j个顶点连成的边eij=(vi,vj) ∈E。另外,GCN 输入中包含顶点特征矩阵其中,fi是顶点vi的特征向量。那么,文档对DA和DB的概念图GAB包含了GCN 中每个顶点的连通匹配向量,因此,fi可以表示为
本文所设计的GCN 层如图2(c)所示。概念图GAB的加权邻接矩阵为A∊RN×N,矩阵A中的元素Aij为顶点i和j的TF-IDF相似度。以为元素构建对角矩阵,其中,为概念图GAB的度矩阵,为A的邻接矩阵。GCN 的输入层为H(0)=X,原始顶点特征被包含在H(0)中。记H(l)∊RN×Ml为第l层的隐藏表示矩阵,每个GCN 层将运用以下图卷积滤波器来学习隐藏表示:
在概念图GAB上,一阶局部谱滤波器的近似利用了图卷积规则[16]。在递归过程中,首先提取顶点之间的交互模式[4],然后根据获得的最后一层所有顶点的隐藏向量的平均值,在GCN 层合并该平均值为一个固定长度的向量,最后,使用诸如MLP的分类器来计算基于mAB(v)的最终匹配分数。
1.3 MFSFM模型
本文提出了MFSFM模型来改进文档的关键字表示,MFSFM 的架构如图3 所示。首先,设计了一个基于上下文的多特征语义融合(contextual multi-feature embedding,CMFE)结构来编码上下文获取的表达语义信息的词向量;其次,考虑到关键字实体边界的不确定性,构造了一个多卷积核混合残差CNN 模块来获得局部注意力和实体边界信息;第三,采用一个由BiLSTM和单向LSTM组成的LSTM模块来增强时序信息学习;最后,采用CRF模块来识别关键字实体。
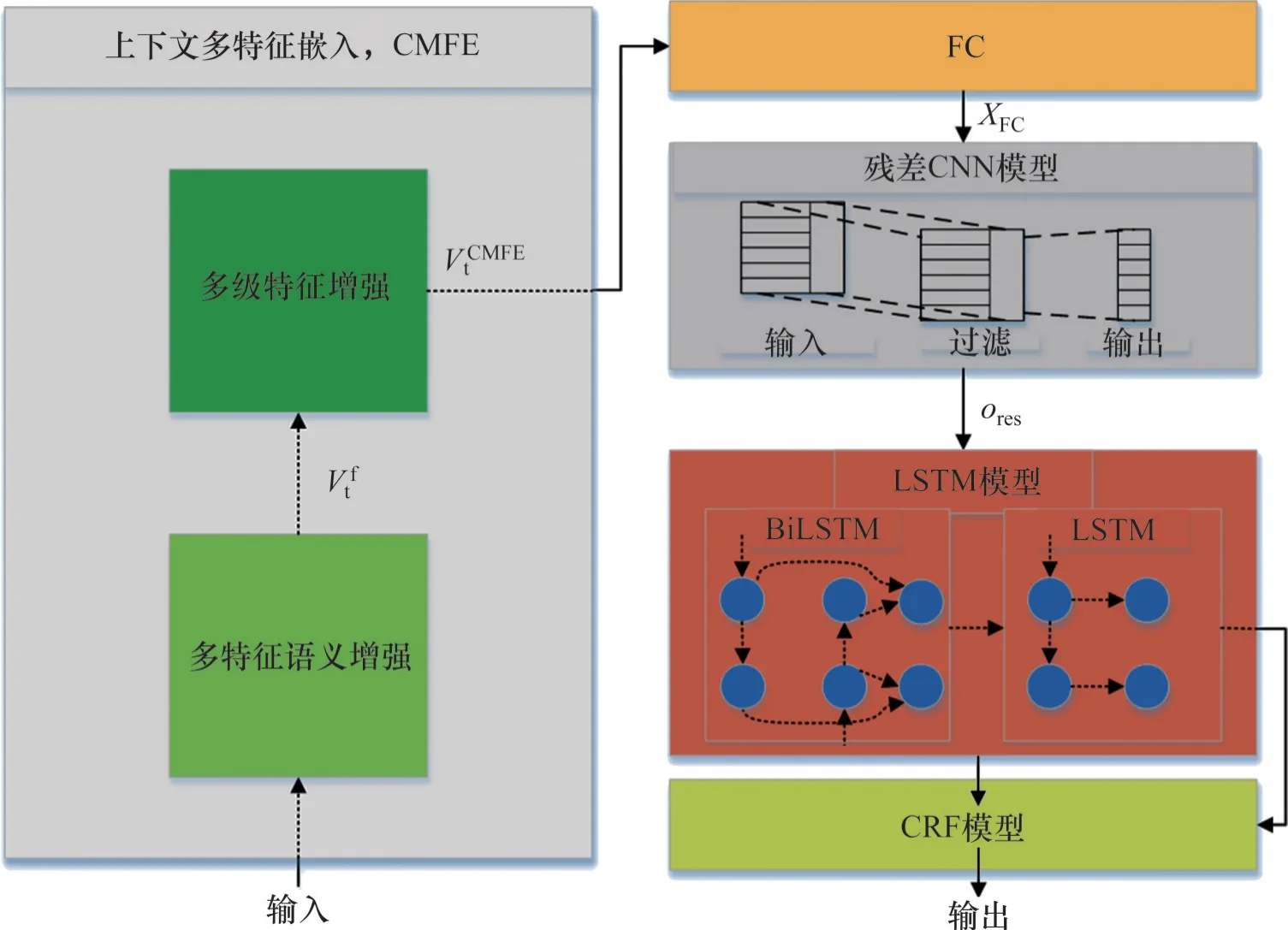
图3 多特征语义融合(MFSFM)架构示意图Fig. 3 Schematic diagram of multi-feature semantic fusion (MFSFM) architecture
利用Word2Vec 技术编码文档作为MFSFM 的输入。Word2Vec 可以将每个单词表示为一个低维向量,以便压缩数据规模,加快编码速度,使模型更容易学习。此外,所构建的文档数据集不仅具有字符(词)特征,还具有词性特征和相对位置特征,本文提出CMFE 方法来学习这两种特征。CMFE 方法主要包括多特征语义增强(multi-feature semantic enhancement)和多级特征增强(multi-level feature enhancement)两个过程,其示意图如图3所示。
多特征语义增强过程示意图如图4所示,其步骤如下。
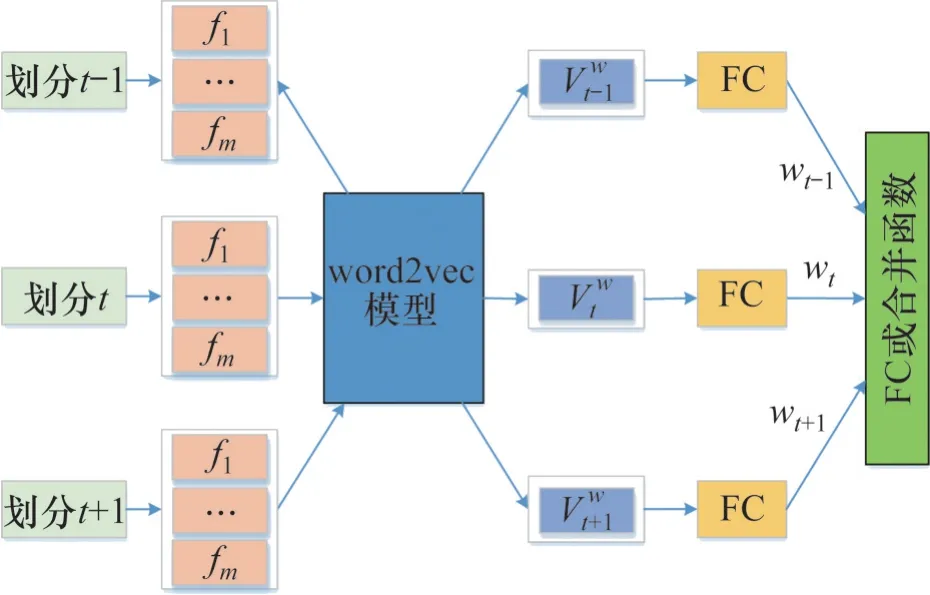
图4 多特征语义增强(以n=3为例)示意图Fig. 4 Schematic diagram of multi-feature semantic enhancement (taking n=3 as an example)
1) 使用Word2Vec 技术得到数据集中每个特征的词向量矩阵Wfi,i=1,2,…,m(m代表特征个数)。
2) 将每个划分中的特征输入到矩阵Wfi,i=1,2,…,m,并得到对应的特征向量。由于每个划分中的特征可以被训练以反映不同特征的语义信息,因此,使用全连接(full connected,FC)层进行加权求和得到加权词向量(没有偏置向量)。
令当前时隙t的每个特征向量为Vt,i(i=1,2,…,m),FC 层每个特征向量权重为wt,i,i=1,2,…,m,与当前时隙t有关的加权词向量Vtw可以由下式计算:
式中:“⊙”为逐元素乘法运算符号。
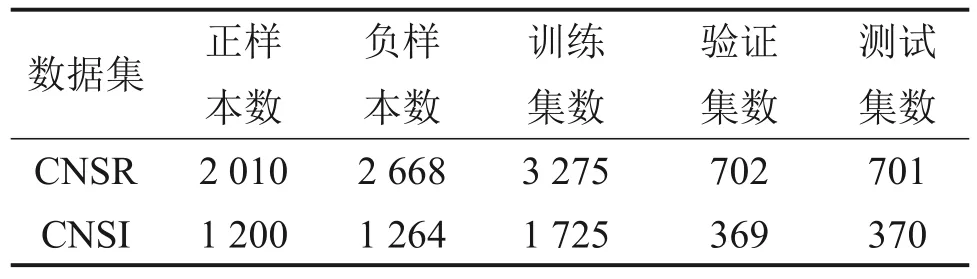
3) 采用窗口数n表征上下文的语义信息的相关度,使用FC层(无偏差向量)将n个分区加权词向量拼接起来。记最大分割数为T,当前时隙为t,则窗口数为n时,FC 层的权重为wt+k,0 因此,当使用FC 层获取词向量时,多特征语义增强向量Vtf为 当使用拼接操作获取词向量时,多特征语义增强向量Vtf为 式中:“Σ⊕”为累积串联运算。 考虑到多特征语义增强只提取浅层特征,本文并没有捕捉数据划分之间的深层特征。为了用词向量矩阵来表达数据的语义信息,本文利用CNN 网络中的卷积操作通过扩大感受野来获得数据划分的相关信息。因此,多级特征增强使用了两层CNN 网络(使用一维卷积)将两层特征向量与多特征语义增强向量进行拼接得到CMFE 向量,如图5所示。 图5 多级特征增强(以n=3为例)示意图Fig. 5 Schematic diagram of multi-level feature enhancement (taking n=3 as an example) CMFE方法的输出向量VtCMFE定义为: 其中:“⊕”为拼接操作,h(t1)和h(t2)分别为一维卷积输出的1级和2级特征向量。 CMFE方法可以得到每个划分数据的词向量表示,利用多特征强化语义信息和简单的CNN 网络强化层次信息,使得后续的学习过程更容易。 为了评估所提出的MFSFM方法的有效性,将MFSFM方法应用于项目申报中的项目查重,并与现有的模型进行对比,其中,基于DNN 模型包括ARC-I[17]、 ARC-II[17]、 DSSM[18]、 DUET[19]和Matchpyramid[20]模型;基于术语的相似性模型包括BM25[2]、LDA[3]和SimNet,以及基于大规模预训练语言模型BERT[13]。 为了更好地匹配长文本,在所提出的方法中,任何短文本信息(如短标题、图表标注、停用词等)都被遗弃,但保留关键文档信息的短文本(例如文章标题)。 对于匹配长文档任务,没有公共数据集可供使用。为此,本文构建了中文可行性研究同项目数据集(Chinese feasibility study same project data set,CNSR)和中文可行性研究同主题数据集(Chinese feasibility study same subject data set,CNSI)2 个数据集,包含从中国湖南国网电力有限公司收集的约500份长篇可行性报告文件,涵盖公司各个领域的多个主题。这些数据集均由相关领域专家进行辅助标记。其中,CNSR 数据集包含4 678 对带标记的可行性研究报告,标记了每对文档是否为同一领域的项目;CNSI数据集包含2 464对带标记的可行性研究报告,标记了每对文档是否属为同一主题。数据集中所有文档的平均单词数为9 034 个,最大值为32 461 个。在CNSR 和CNSI 数据集中,使用样本的70%作为训练集,15%作为验证集,剩下的15%作为测试集。表1所示为CNSR 和CNSI 数据集的详细分类。在这些数据集中,只标注了可行性研究报告的主要研究项目,同时需要保证不同的分割不涵盖重复数据,避免数据泄露。本文选择包含相似项目(关键字)的项目文档对,并排除TF-IDF 相似度低于某个阈值的样本,不会随机生成两个数据集中的负样本。 表1 CNSR和CNSI数据集的详细分类Table 1 CNSR ans CNSI evaluation dataset detailed classification 采用二分类的准确率以及F1-measure 值评估模型的文档对匹配性能。对于每种评估方法,进行20个epoch的训练,然后选择测试集的最优值作为最终结果。 采用文献[10]中提出的BiLSTM-CRF模型作为关键字实体识别模型,并将本文所提出的CMFE与CBOW和Skip-gram进行比较。其中,CBOW和Skip-gram 算法的参数设置如下:上下文窗口数n不同之处为5,负样本数为10,词向量大小为128。CMFE 的参数设置与CBOW 和Skip-gram 算法的设置相同,其中,一组64 维词向量用于多特征语义增强,窗口数n=3;另一组64 维词向量用于多级特征增强,卷积核大小为3。使用Stanford CoreNLP进行分词(中文文本)和命名实体识别,对于带有社区检测的概念交互图构建,将最小社区大小(概念顶点中包含的关键字数量)设置为2,最大社区大小设置为6。 本文的神经网络模型包括词嵌入层、Siamese编码器、图卷积层和分类层。在Siamese 编码器中,依次使用1维卷积和64维全连接层、ReLU和Max Pooling 操作对概念图进行编码表示。在图卷积层中,使用3 层GCN[16]对CNSS 数据集和CNSE数据集进行文档匹配,当顶点编码器有4 维特征时,GCN 层的输出大小设置为32;当顶点编码器是Siamese 编码器时,将GCN 层的输出大小设置为128。在最后的分类层中,有一个输出大小为32的线性层和一个ReLU层。使用tensorflow 2.0来实现基于MFSFM 的匹配算法。在神经网络模型中,采用正则化项L2对所有可训练变量使用权重衰减,正则化参数λ设置为2×10-6。网络损失率设置为0.005。使用最大梯度范数为5.0 的梯度裁剪,ADAM 作为优化器,其中,第一动量梯度下降因子β1=0.85,第二动量梯度下降因子β2=0.99,除零误差ε=1×10-8。在前1 500 步中,网络学习率呈指数衰减,衰减幅度设为0~0.001,然后在其余步骤中保持恒定的学习率,最大训练epoch 数设置为20。 不同识别方法在2个数据集上的识别性能如表2所示。从表2可以看出,在关键字实体识别方面,CMFE 模型的准确率和召回率明显比其他方法的高。 表2 不同识别方法的识别性能对比Table 2 Comparison of performance for different textual representations CMFE通过数据集中的多个特征进行多特征语义增强,再通过CNN网络进行多层次的特征增强。所提出的MFSFM在两个数据集上都实现了最佳识别性能,并且明显优于其他方法的识别性能。这是因为两个文档在知识图谱化后是沿着对应的语义单元对齐的,从而便于概念比较,而且所提出的MFSFM 对实体上下文周围的语义信息进行编码,并通过图卷积来聚合它们。因此,基于MFSFM的匹配算法通过图形化文档的方式解决文档匹配问题,适用于处理长文本。 不同方法在CNSR 和CNSI 数据集上的准确率和F1值比较如表3所示。从表3可见:本文所提出的模型在CNSR 和CNSI 数据集上的分类精度分别提高了13.67%和15.83%。 表3 不同方法在CNSR和CNSI数据集上的准确率和F1值比较Table 3 Comparison of accuracy and F1 value of different methods on CNSR and CNSI datasets CG-Siam 模型和MatchPyramid 模型具有相同的词向量,均使用神经网络(NN)对文本进行编码,但CG-Siam模型以逐顶点分解的方式比较了CG上的文档对,对比可知:CG-Siam模型的匹配性能优于MatchPyramid 模型的匹配性能。同样,将本文CG-Sim模型与SimNet模型进行比较,两者都应用基于术语的相似性,可见,本文的方法的匹配性能大大优于SimNet 算法。这是因为图形分解可以显着提高长文本的匹配性能,而SimNet 模型的主要是为了匹配序列而发明的,无法在项目文档对中获得有意义的语义信息。当上下文太长时,匹配文档对很难获得较好的上下文表示。对于专注于交互的NN模型,单词之间的大多数交互对于两个长文档来说是没有意义的。 分别对比CG-Siam-GCN 和CG-Siam 模型、CG-Sim-GCN和CG-Sim模型可知:通过合并GCN层,2个数据集的匹配性能均显著提高。GCN通过整合每个顶点及其相邻顶点来更新隐藏向量,将局部匹配特征聚合成最终结果。 分别对比CGc-Siam-GCN 和CG-Siam-GCN 模型、CGc-Sim-GCN 和CG-Sim-GCN 模型可知:社区检测技术会带来短暂的性能降低,这是因为直接使用关键字的概念顶点可以提供更多锚点来比较文档对。一致的关键字可以通过社区检测高度分组在一起,CG的平均大小可以从35个顶点减少到16 个,基于MFSFM 的匹配算法的总训练时间可以减少53.6%。因此,可以选择使用社区检测来降低准确性以提高算法速度。 CG-Sim&Siam-GCN模型的匹配性能明显优于CG-Sim 模型的匹配性能,这证明了连接多视图匹配向量可以捕获更多的文档关键信息,提高匹配度。从表3可见:全局特征越多的算法总是表现不佳。这是因为这些文档对的相似性和/或BERT 编码的全局特征相对于本文所提出的概念图,缺乏对文档核心语义的理解。提高匹配性能的主要因素是图的分解和卷积,模型在全局语义关系中综合了局部比较信息,而多余的全局特征会干扰模型的训练。 在实验中,没有BERT 的最大模型是CGSim&Siam-GCN-Simg,它只包含大约54 000 个参数,而BERT 中有130~340×106个参数。此外,本文在模型中对不同参数的敏感性进行了测试,可以发现含2~3 个GCN 层的模型的匹配性能最好,增加更多的GCN 层不能提高模型的匹配性能,但如果不含GCN 或只有1 层GCN,模型匹配性能最差。另外,GCN层中隐藏层向量大小在32~256之间具有最佳性能,并且更大的尺寸不会提高性能。当构建CG 时,需要为可选的社区检测步骤选择社区的大小,如果最大尺寸为8~10,最小尺寸为2~3,性能会更差。这表明所提出的基于MFSFM的匹配算法是稳定的,即对参数并不是很敏感。总而言之,本文所提出的基于概念图的模型优于其他算法。 根据实际复杂度的定义,社区检测的时间复杂度为O(q3),构建关键字图的时间复杂度为O(rp+q2),句子附着和计算权重的操作时间复杂度为O(rp+p2),其中,r表示2 个文档数据集中句子的数量,p表示句子中单词的数量,q表示句子中关键字的数量。由于本文构建的文档中关键字数量q很小,因此,整体时间复杂度很小,模型的收敛速度快。 1) 针对文档的关键字提取,提出了多特征语义融合模型MFSFM 来捕获关键字。与基于RNN的序列建模相比,MFSFM通过多特征语义增强组件更关注实体的上下文语义信息。 2) 提出一种后端匹配算法,通过构建关键字共现图,并应用社区检测算法检测概念以概念图的形式来表示文档,并利用图卷积神经网络进行文档对匹配。 3) 本文所提出的模型在CNSR 和CHSI 数据集上的分类精度分别提高了13.67%和15.83%,同时可以实现快速收敛,而且本文所提出的后端匹配算法可以很容易地实现,并应用于其他文档数据集。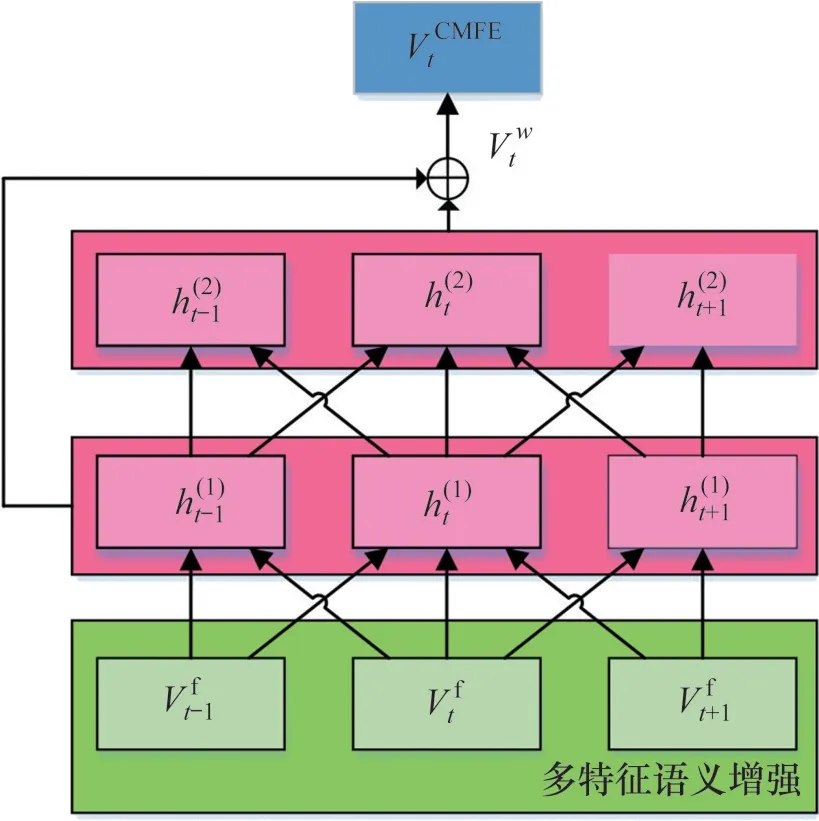
2 模型验证与分析
2.1 数据集
2.2 实验参数设置
2.3 结果与分析


4 结论
