基于改进堆叠自编码器结合LightGBM 的近红外光谱回归算法研究
2023-09-21吴继忠时艺丹厉小润
吴继忠,时艺丹,黄 慧,厉小润
(1.浙江中烟工业有限责任公司技术中心,浙江 杭州 310008;2.浙江大学 海洋学院,浙江 舟山 316000;3.浙江大学 电气工程学院,浙江 杭州 310027)
近红外光谱分析技术具有绿色、无损、快速等优点,已广泛应用于烟草、食品、石油化工等领域[1]。基于近红外光谱的回归分析常用方法多为线性回归算法,如多元线性回归[2]、偏最小二乘回归(PLSR)[3]、Lasso 回归[4]和岭回归[5]等。线性回归算法具有结构简单、速度快、可解释性强等优点,但对于现实情景中真实关系的表达能力有限。近年来,一系列表达能力更强的非线性回归算法被应用于近红外光谱分析。例如,王立琦等[6]通过分析豆粕组分含量与近红外光谱的相关关系,建立了豆粕水分、蛋白质和脂肪的广义回归神经网络预测模型。Zhu等[7]提出了一种基于残差网络和长短期记忆神经网络的烟草化学成分分析方法,可同时准确定量分析烟叶的多种化学成分。罗智勇等[8]提出了一种基于改进卷积自编码网络特征提取的烟叶烟碱与总糖定量分析方法。现有非线性回归算法可能存在结构复杂、超参数敏感、过拟合等问题,因此,探索更强预测能力与鲁棒性的近红外光谱回归算法仍具有重要意义。
LightGBM 是一种基于序列化的集成学习算法,具有强回归预测能力,适用于挖掘复杂的非线性关系[9]。但LightGBM 需要设置合适的超参数,例如叶子节点数量和树的深度。常规的调参方法包括网格搜索、随机搜索等,但通常运算时间长。相比传统方法,利用Optuna[10]框架可以实现LightGBM 超参数的快速自动优化。同时LightGBM 的训练过程易受噪声等干扰信息的影响,生长出过深的决策树,产生过拟合。堆叠自编码器(SAE)是一个由多层稀疏约束的自编码器组成的深度学习算法[11-12],具有简单、高效、对前处理不敏感等优点,可以学习到相对于线性特征更深层抽象的非线性特征,同时抑制噪声等干扰因素的负面影响。利用SAE 挖掘的深层特征可以降低LightGBM 过拟合的风险,但SAE的网络层数和各层神经元数量会显著影响SAE 的重构能力。确定网络层数和各层神经元数量的常用方法包括经验法则、交叉验证和正则化技术等,然而这些方法通常存在计算量大、效率低下、针对性弱等问题。
为解决上述方法的不足,本文提出了一种改进的SAE结合LightGBM(iSAE-LGBM)的近红外光谱回归算法,通过设计递归式策略自适应确定SAE 网络结构,利用SAE 特征表达与消除干扰的能力,降低LightGBM 过拟合的风险,并采用Optuna 框架实现了LightGBM 的超参数自动优化。该算法以包含1 911个烟草样本4 项化学指标的数据集为研究对象,并与4 种常用的近红外光谱回归分析算法进行对比分析,进行了有效性验证。
1 实验部分
1.1 仪器与材料
Futura 型8 通道连续流动化学分析仪(法国Alliance 公司);Antaris Ⅱ近红外光谱仪,配有TQ Analyst 软件(美国Thermo 公司),工作参数为:光谱采集范围12 000~4 000 cm-1,光谱分辨率8 cm-1,扫描次数64次;FED-240型干燥箱(德国Binder公司);YC-400B-03型烟草粉碎机(成都英特瑞公司)。
所用烟草样品为2014~2019 年从中国14 个省市收集的典型复烤片烟样品,共1 911 个,每个样品的信息包括近红外光谱吸光度数据、产地以及还原糖、氯、钾、总氮4种化学成分的含量。
1.2 数据采集与光谱预处理
将干燥后的烟叶样品处理为烟叶粉末,置于近红外光谱仪上进行吸收光谱信息采集。样品采集时入射光斑偏心,采集光谱范围12 000~4 000 cm-1的烟叶粉末样品近红外光谱吸光度数据。每个烟草样本还原糖、氯、钾与总氮的含量(质量分数)按照烟草行业标准测定。对于得到的烟草样本,计算每个指标的均值和标准差,将每个指标距离平均值3 个标准差以外的数据作为异常值进行剔除,处理后共得到1 911 条数据。采取多元散射校正法(MSC)对近红外光谱数据进行散射校正,用Savitzky-Golay(SG)平滑滤波法进行平滑处理[13],再将处理后的数据均值中心化、标准化,以便后续分析。
1.3 光谱波段选择
光谱波段选择的目的是从原始光谱中选择出最具代表性的波段,以提高模型的预测性能和稳定性,本文选择基于梯度提升树的变量重要性评估法[14]对原始光谱进行波段选择。作为一种基于机器学习的特征选择方法,该法的主要思想是通过训练梯度提升树模型,计算每个波段在模型中的重要性,并选择重要性较高的波段。以下是基于梯度提升树的变量重要性评估法进行波段选择的具体步骤:
(1)模型训练:将近红外光谱数据集分为训练集和测试集,使用梯度提升树模型对训练集进行训练,并对测试集进行预测。
(2)变量重要性评估:计算每个波段在模型中的重要性。在梯度提升树模型中,每个决策树都是基于某个波段进行分裂的,因此可以通过计算每个波段在所有决策树中被使用的次数,来评估该波段的重要性。
(3)波段选择:选择重要性较高的波段。根据变量重要性评估的结果,选择前N个波段作为特征集合。
1.4 算法原理
iSAE-LGBM 的算法原理如图1所示,主要包含两个模块,分别是结构自适应优化的SAE 模块和基于Optuna超参数自动优化的LightGBM 模块。SAE模块可以实现光谱矩阵强表征性特征的提取与噪声等干扰因素的抑制;LightGBM 模块可以实现复杂非线性关系的分析,LightGBM 的输入为经过SAE训练得到的隐藏层特征,抑制了部分无关的噪声和干扰,降低了LightGBM 过拟合的风险,使回归的结果和化学成分指向的特征相关性更强。模型的性能由测试集样本进行验证。

图1 基于iSAE-LightGBM 的自适应光谱回归算法Fig.1 Adaptive spectral regression algorithm based on iSAE-LightGBM
1.4.1 结构自适应优化的SAESAE 由多个加入稀疏约束的编码器与解码器组成,上一个编码器的输出被送入下一个编码器的输入,再通过解码器得到最终的重构数据。因为具有更多的隐藏层和非线性变换,相对于自编码器(AE),SAE可以学习到更复杂的特征表示,更符合现实复杂情景的模拟。SAE的结构示意图如图2所示。

图2 SAE结构示意图Fig.2 SAE structure schematic
图2 中,n表示编码器和解码器的个数,决定了SAE 网络的层数,Ni(i= 1,2,...,n)表示第i层神经元的个数。n和Ni会显著影响SAE的重构能力。本文受到二叉搜索树算法的启发[15],基于递归的思想,提出了一种适用于近红外光谱回归分析的SAE 结构参数自适应确定策略,公式如下:
式中,round(·,a)表示取整函数,a表示保留的有效数字位数,bandsize(·)表示近红外光谱数据的光谱维数,Xori表示原始近红外光谱数据,sgn(·)为符号函数,表达式为:
该策略下,下层编/解码器的神经元个数由上一层决定,层数与各层神经元个数由递归运算得到。在3层前,每层的神经元数量为上一层的一半,在递进式的压缩中,数据中的隐层特征可被充分表达。然而,为了控制网络的复杂程度,避免训练时间过长造成计算资源的浪费,3 层及以后的收敛速度提高4 倍,递归停止的条件为Ni<10 且Ni-1≥10,这样中间层维度被控制在10 × 8 = 80 以内,可以实现合理的降维。
考虑到提取更深、更隐层特征的需求,对原始SAE 的损失函数进行修改,去除稀疏约束的部分,只考虑原始数据与重构数据的相似度,使提取到的隐层特征能更完整表达原始的近红外光谱数据,改进后的损失函数为:
式中:X为预处理后的光谱数据,z(·)为解码器的映射函数,MSE 表示均方误差,X^ 为重构得到的光谱数据,训练在损失函数小于10-6时停止。重构的目的是使原始数据与重构数据尽可能相似,另外,考虑到同一品类样本近红外光谱相似度高、形状类似的特点,选择ReLU 为激活函数,避免梯度消失、模型放弃学习特征而选择重构出一条平均光谱。
1.4.2 Optuna 优化自适应确定LightGBM 超参数LightGBM 算法重要的超参数包括叶子节点数量和树的深度,在Optuna框架下设置合理的超参数寻优范围,在一定次数的迭代下得到最优参数组合,并基于该组合进行LightGBM回归模型的构建。具体步骤如下:
(1)定义待优化函数Objective Function,并指定参数/超参数的合理范围;
(2)创建一个Study对象,负责管理优化,决定优化的方式、总实验的次数、实验结果的记录等;
(3)指定循环次数,在一定的搜索空间中利用尝试的历史组合确定接下来要尝试的参数组合,根据“Tree-structured Parzen Estimator”贝叶斯优化算法进行指定次数的迭代与Objective Function的优化;
(4)达到设定的优化目标后,获得最优的超参数组合。
1.4.3 对比算法与模型评价指标选取经典的偏最小二乘(PLSR)线性算法[16]和带二次项的回归分析(D2reg)[17]、随机森林(RF)[18]和XGBoost[19]3个非线性算法,与本文提出的方法进行比较。模型的准确性、鲁棒性由6 个参数评价:训练集/测试集相关系数(RC/RP);训练集/测试集均方根误差(RMSEC/RMSEP);训练集/测试集决定系数(RC2/RP2)。较好的模型评判标准是:较小的RMSE 与接近1的R、R2值,表明其预测能力强;RMSEC 和RMSEP,RC和RP,RC2和RP2之间的差值越小,表明其泛化能力越强,模型鲁棒性强,过拟合程度低。其计算公式为:
其中X和Y表示输入光谱矩阵与化学成分含量矩阵,yi表示第i个样品的某化学成分含量真实值,y'i表示第i个样品的某化学成分含量预测值,
2 结果与讨论
2.1 光谱预处理与波段选择结果
在对光谱和化学成分指标进行标准化操作后,对标准化后的光谱进行SG平滑+MSC+中心化的预处理操作。预处理前后的烟草样本集近红外光谱对比如图3 所示,其中右上角的子图表示框选区域的细节放大。可见,经MSC 配合SG 平滑法和中心化的预处理后光谱更加平滑,有效校正了光谱的散射效应,提高了光谱的准确性和可靠性。
对预处理前后的光谱数据进行PLSR建模,测试预处理的有效性,用4种成分平均的测试集均方根误差与决定系数对其进行测试,结果如表1所示。可见,预处理后的数据建模效果更佳,进一步证明了预处理对建立化学成分回归模型的正面效果。

表1 预处理前后的建模结果对比Table 1 Comparison of modeling results before and after preprocessing
对预处理后的数据进行基于梯度提升树的变量重要性评估的波段选择,设定优选的波段数为50,得到降维后的光谱数据X。
2.2 参数优化
模型的参数优化包括改进的SAE 模块和LightGBM模块的参数优化。改进的SAE模块参数自适应确定结果如表2 所示,其中输入光谱的原始波段数bandsize(Xori)= 1 609。

表2 SAE模块参数自适应确定Table 2 Adaptive determination of SAE module parameters
D2reg 方法中主成分数的确定:利用主成分分析法(PCA)对原始光谱数据进行处理,选取包含99.99%的解释方差总和比率对应的主成分数,得到最佳主成分数为13,如图4所示。
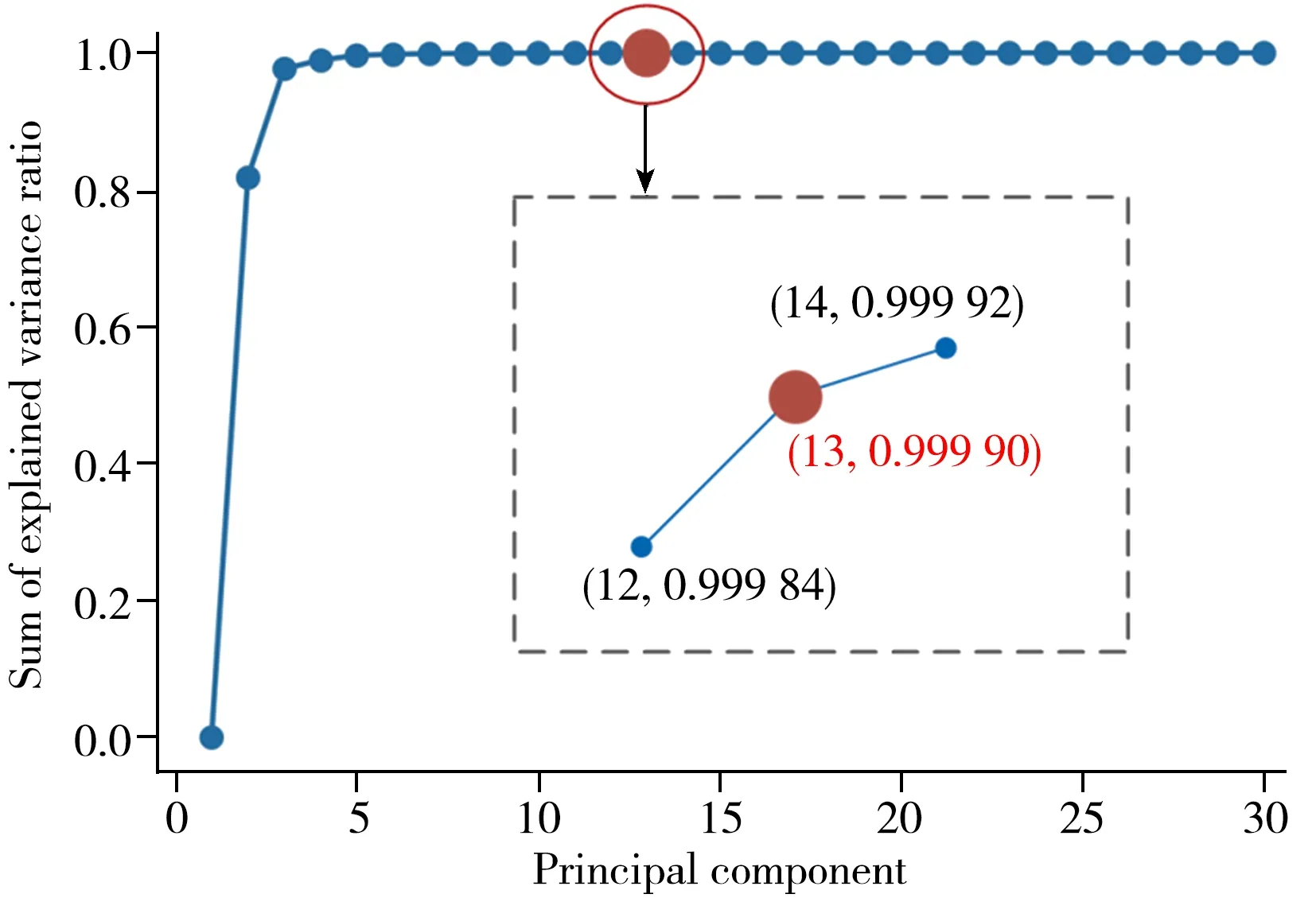
图4 解释方差率总和随主成分的变化曲线Fig.4 Variation curve of sum of explained variance ratio with principal component
在自动优化框架下,iSAE-LightGBM 与其他4种方法的最优参数组合如表3所示。

表3 最优参数组合Table 3 Optimal combination of parameters
2.3 模型构建结果
基于“2.2”得到的各算法最优参数组合,进行回归模型构建,并利用测试集样本对各模型性能进行评价,得到的模型评价参数对比如表4所示,其中加粗字体为最优项,次优项添加下划线。

表4 模型评价参数对比Table 4 Comparison of model evaluation parameters
2.3.1 从训练集角度分析5 种算法中iSAELGBM 算法的综合表现最佳,XGBoost 次之。iSAE-LGBM 算法下4 种化学成分的RC和RC2均可达到0.99以上,平均RC为0.999 2,平均RMSEC 为0.005 3,平均为0.998 3,均优于其他方法。可见iSAE-LGBM 对于烟草4 种化学成分的特征表达和回归分析能力最强。XGBoost 作为一种梯度提升树模型,与LGBM 原理相似,也能较准确地拟合训练数据。而RF算法和D2reg算法表现略差,PLSR算法的提升空间相对最大。
2.3.2 从预测集角度分析iSAE-LGBM 算法对4种成分各项指标的最优或次优项多于其他4种对比方法,4 种成分的RP分别为0.947 5、0.879 0、0.952 6、0.864 8,平均值为0.911 0,RMSEP 分别为0.072 5、0.039 9、0.055 2、0.059 6,平均值为0.056 8,RP2分别为0.867 6、0.898 6、0.904 4、0.660 5,平均值为0.832 8。而在训练集上表现同样出色的XGBoost算法在预测集上的表现则出现明显下降,平均RP比iSAE-LGBM 低约1%,而平均RP2甚至低约40%,可见XGBoost 算法出现了较明显的过拟合问题,证明iSAE-LGBM 算法的SAE 模块有效降低了过拟合的风险,提高了鲁棒性。PLSR 算法和D2reg 算法虽在预测集上的表现与训练集较为相近,过拟合问题不显著,但得到的模型预测能力有限。上述结果进一步验证了iSAE-LGBM 算法在预测能力、降低过拟合风险方面的优势。
2.3.3 从化学成分种类角度分析iSAE-LGBM算法建立的氯、钾、总氮模型相对于还原糖模型更优,还原糖模型中的PLSR算法也有不错的表现,可见氯、钾、总氮3种化学成分与近红外光谱间的相关性更倾向于非线性相关,而还原糖模型的线性相关性相对更加突出,故传统线性回归算法也能得到相对较好的结果。相比于其他4种算法,iSAE-LGBM算法在处理偏向线性或非线性的关系上均有优秀的表现。
通过上述分析可知,与4个经典算法相比,iSAE-LGBM算法无论在训练集或预测集上的表现均最优,对烟草还原糖、氯、钾、总氮4种化学成分的综合预测能力最佳,在模型预测能力、鲁棒性、通用性上更优。
为了进一步验证iSAE-LGBM 算法的有效性,图5 给出了4 种化学成分预测值与真实值的散点图,并拟合出相应的一次函数,将其与最优拟合函数y=x进行对比,点越接近y=x直线代表预测偏差越小。由图5可知,绝大部分点均匀分布在拟合直线的两侧,拟合曲线均与y=x接近,说明iSAE-LGBM算法构建的烟草4种化学成分的预测模型具有较高的预测准确率。

图5 预测值-真实值曲线Fig.5 Predicted value- measured value curves A. reducing sugar;B. chlorine;C. potassium;D. total nitrogen
3 结 论
本文将改进堆叠自编码器与LightGBM 结合应用于近红外光谱回归分析。算法由两个模块组成,其中改进的结构自适应优化的堆叠自编码器模块有效减少了噪声和干扰对模型的负面影响,可充分挖掘近红外光谱数据的非线性深层特征,同时有效降低了后续LightGBM 模块的过拟合风险;LightGBM 模块充分表达了近红外光谱数据中的深层非线性特征,超参数在Optuna框架下实现了快速自动优化。将该算法与其他4 种算法进行对比,结果显示该算法下构建的烟草化学成分回归模型在预测能力、鲁棒性和通用性方面得到有效提高。本文将堆叠自编码器与LightGBM 应用于近红外光谱的非线性回归分析,为近红外光谱数据中隐层关系的挖掘与表达提供了参考,通过烟草样本进行验证,为深度学习在化学成分检测与质量监控领域的应用提供了新的思路和依据。
