基于改进的CNN-LSTM的DGA域名检测算法
2023-09-16褚冰融付海艳
褚冰融,付海艳,刘 梦
(海南师范大学 信息科学技术学院,海南 海口 571127)
随着网络日新月异的发展,网络攻击也层出不穷。其中,僵尸网络造成了巨大的威胁,黑客通过命令与控制(Command&Control,C&C)服务器[1]对受僵尸病毒感染的主机进行控制,从而发起网络攻击。由于通过C&C服务器的IP地址可以被逆向或者列入黑名单以阻止攻击,因此攻击者为了使攻击主机不易被发现,使用域名生成算法DGA(Domain Generation Algorithms)[2]生成大量域名,以此快速变换域名对网络进行攻击。
DGA的目标是生成不存在的域名,因此DGA域名变化速率快且种类繁多。域名生成算法DGA主要分为两种,一种是基于随机字符的DGA,另一种是基于单词字典[3]的DGA。基于随机字符的DGA域名主要都是通过种子和算法进行生成的[4]。基于字典的DGA域名是通过随机字典中的合法词汇而生成的,这类域名由于与合法域名过于形似,因此加大了检测难度。一些常见类别的恶意域名见表1。由于DGA有不同的用途和类别,因此要对DGA进行多分类,由此来判别其所生成的恶意软件的类型,以便更好地应对DGA 域名所带来的危害。
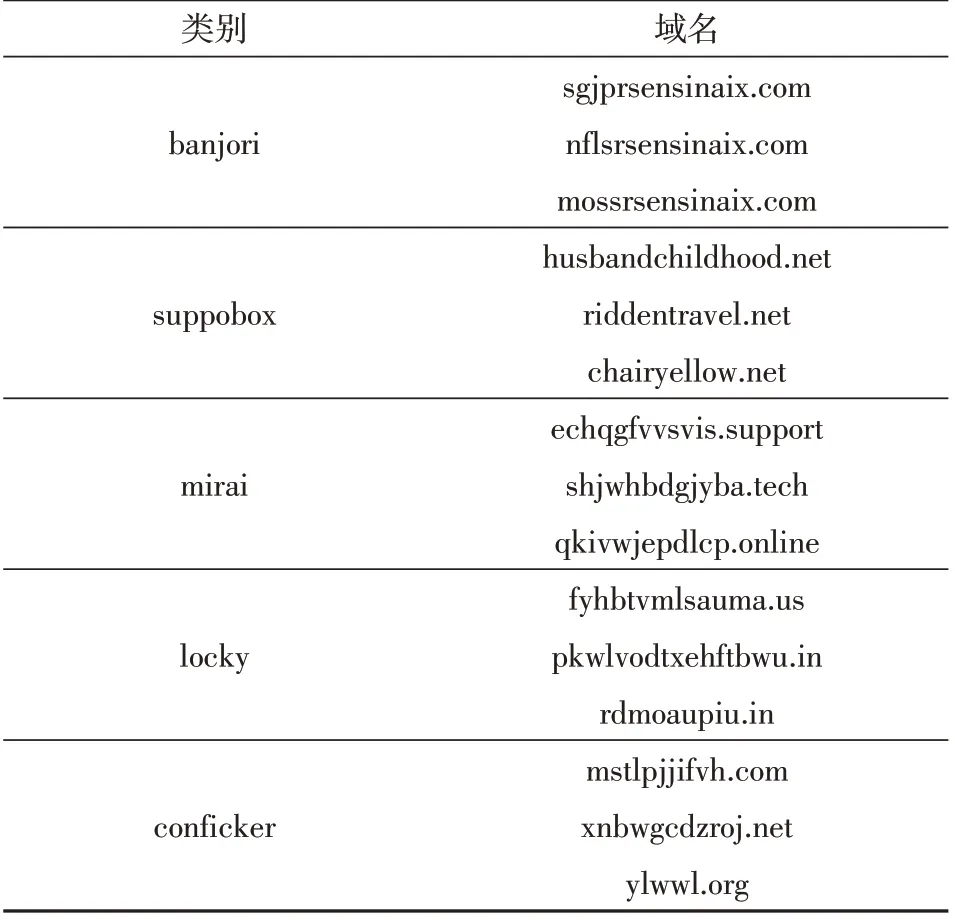
表1 常见的DGA域名Table 1 Common DGA domain names
目前针对DGA 域名的检测方法主要是基于深度学习的检测方法,以循环神经网络RNN(Recurrent Neural Netwok)和卷积神经网络CNN(Convolutional Neural Network)为主[5]。Yu 等[6]比较了堆叠CNN 和并行CNN(Parallel CNN)模型,Parallel CNN在检测DGA域名时具有更高的精确度。为了解决正负样本数据不均衡的问题,杨路辉等[7]提出了一种改进的基于卷积神经网络的恶意域名检测方法,通过引入一种聚焦损失函数提高了部分难检测域名的检测准确率。Qiao 等[8]提出了一种基于长短时记忆网络Long Short-Term Memory(LSTM)和注意力机制的DGA域名分类方法,其准确率高于单一的LSTM模型。随后,Namgung等[9]使用并行卷积神经网络(PCNN)结合基于注意力机制的双向LSTM(BiLSTM),虽然整体检测率高,但是对于locky、cryptolocker 这些基于随机字符的域名检测率依旧很低。Highnam 等[10]提出了CNN 与LSTM 并行使用的Bilbo-Hybrid模型,提高了对字典型DGA域名的检测率。Ayub等[11]使用人工神经网络ANN(Artificial Netural Network)结合Word2vec模型对域名进行检测,相比于单一的LSTM模型有更好的检测率。
由此可知,目前DGA域名检测所存在的主要问题是:(1)只对一些经典的域名种类进行检测;(2)无法同时检测出基于字典的和基于随机字符的DGA域名;(3)对于样本分布不均衡的数据集域名检测率低。因此,针对这些问题,本文构建了改进的CNN-LSTM算法,该算法结合了注意力机制、并行卷积神经网络(Parallel CNN)[12]和双向长短时记忆网络(BiLSTM),并且改进了损失函数,将focalloss 函数融入至算法中,即构建了APCNN-BiLSTM-ATT(Attention Parallel CNN-Bidirectional LSTM-Attention)检测算法进行域名检测。
1 APCNN-BiLSTM-ATT域名检测算法
该域名检测算法主要分为3个步骤,分别为数据预处理、特征提取和特征融合。经过上述3个步骤后便可以得到APCNN-BiLSTM-ATT算法模型,该模型的总体架构如图1所示。

图1 模型总体架构Figure 1 Overall structure of the model
1.1 数据预处理
数据预处理的步骤主要分为两步,第一步是将域名文本转化为数字序列,即进行字符编码和填充,第二步是将数字序列输入至嵌入层,将其进行向量化。
嵌入层的作用是将输入的序列向量化,在嵌入层中,给定输入矩阵Xn×t、权重矩阵Wt×m,该权重矩阵为模型在训练中学到的参数,通过下列公式得到嵌入矩阵Yn×m:
数据预处理的算法步骤如下:
算法1 数据预处理算法
输入:域名文本x
输出:嵌入矩阵Y
(1)将域名文本x进行字符编码,得到数字序列xi;
(2)将xi进行长度标准化(为了统一输入长度),得到数字序列x′i;
(3)将输入至嵌入层,通过式(1)得到嵌入矩阵Y。
1.2 特征提取
特征提取由添加注意力机制的并行卷积神经网络(APCNN)和添加了注意力机制的双向长短期记忆网络(BiLSTM-ATT)两部分组成,其APCNN层的作用是对特征向量进行局部特征提取,BiLSTM层的作用是对特征向量进行全局特征提取。
1.2.1 APCNN层
APCNN层是指添加了注意力机制的并行卷积神经网络层。
注意力机制(Attention 机制)最早在视觉图像领域中被提出[13],在本文算法中所使用的注意力机制均为自注意力机制,它不需要依赖次序序列计算,可以有效地减少长距离依赖,提取域名中的重要信息,减少了计算的复杂度,同时也增加了计算的并行性[14],在注意力机制中,给定3个输入:Q(查询Query)、K(键值Key)和V(内容Value)。Q、K和V都是通过输入矩阵Y和训练优化得到的矩阵WQ、Wk和Wv进行点积运算得来的。然后将Q与K的转置做点积运算,接着除以一个缩放系数,再使用softmax函数处理获得结果,最后与V做张量乘法得到注意力的输出结果Oatt,公式如下:
卷积神经网络(CNN)常用于处理图像数据,也可用来处理序列数据,它通过从序列数据中提取特征来解决分类问题,其优点是能学习局部信息,因此在本文的模型中,使用并行的卷积神经网络来学习域名中的各类特征。该卷积神经网络由卷积层、池化层和隐藏层组成。其中,卷积层是核心部分,它将多个滤波器映射到输入数据,以找到合适的特征,通过将卷积核移动k大小的窗口并在它们和整个输入数据之间执行卷积运算来提取特征,公式如下:
其中,xt属于注意力输出结果Oatt中的向量,xt*xt-1表示卷积,k是卷积核的大小,C(t,k)是指卷积操作,R是卷积操作后得到的卷积结果,K是所有卷积核的大小,在本文中,K=[5, 6, 7]。
池化层的作用是对数据进行降维,以此来提取重要特征,提高检测率。池化层分为最大池化层和平均池化层,在该模型中,使用最大池化层,池化计算的公式如下:
将每一个卷积层的池化结果拼接起来,得到
隐藏层中包括全连接层、激活层和批处理规范化(Batch Normalization)和Dropout 层,其中,全连接层的作用是将提取的局部特征进行特征融合,使用整流线性单元Re LU作为激活函数,公式如下:
其中x∈P。
而当学习率过高时,会导致神经元被置为0,使训练中断,因此激活层中使用ELU函数以弥补ReLU函数的缺点,可以让激活的平均值接近于0,使其学习更快,然后使用批处理规范化使激活函数的结果服从正态分布,使模型可以学习而不是严重依赖于初始值,最后添加Dropout函数以防止过拟合,公式如下:
其中,γ和β为待学习的参数,ε为偏置参数。
APCNN层的结构图如图2所示,算法步骤如下:

图2 APCNN结构图Figure 2 The structure diagram of APCNN
算法2 APCNN算法
输入:嵌入矩阵Y
输出:特征向量D
(1)将嵌入矩阵Y输入至注意力机制,通过式(2)得到Oatt;
(2)将Oatt输入至卷积层,通过式(4)得到R;
(3)将R输入至池化层进行降维,通过式(5)~(6)得到P;
(4)将P输入至隐藏层,通过式(7)~(10)得到特征向量D。
1.2.2 BiLSTM-ATT层
这一层是由BiLSTM(双向长短时记忆网络)和ATT(注意力机制)构成。
LSTM是一种特殊的RNN(循环神经网络)[15],可以很好地解决长时依赖问题,其结构如图3所示。
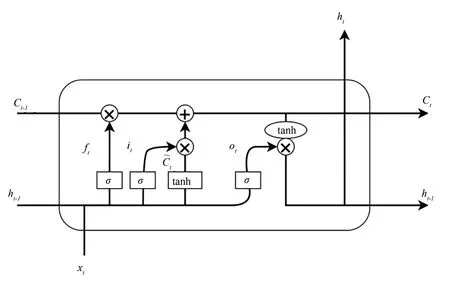
图3 LSTM结构图Figure 3 The structure diagram of LSTM
由图可知,LSTM由3个门来确定单元状态:遗忘门、输入门和输出门,具体公式如下:
其中,xt∈Y,是LSTM 网络的输入;ft是遗忘门得出的信息,决定需要丢弃的信息,然后进入sigmoid 层;it是需要更新的值,再通过tanh 函数对状态进行更新,将旧状态与ft相乘,丢弃掉确定需要丢弃的信息,接着加上it*C~t,便得到一个候选值;最后通过tanh 和sigmoid 两个激活函数得到最终的输出ht,其中Wi、Wc、Wo为权重矩阵。由模型的训练过程得出bi、bc和bo为偏置值,但LSTM 只能提取单向信息,这会降低准确率。
因此提出了BiLSTM,BiLSTM 由前向LSTM和后向LSTM组成[16],可以同时提取前向和后向信息,输出由前向输入和反向输入共同决定,相比于LSTM可以更好地捕捉双向的语义依赖,用来提取域名中的字符双向序列特征[17],结构如图4所示。
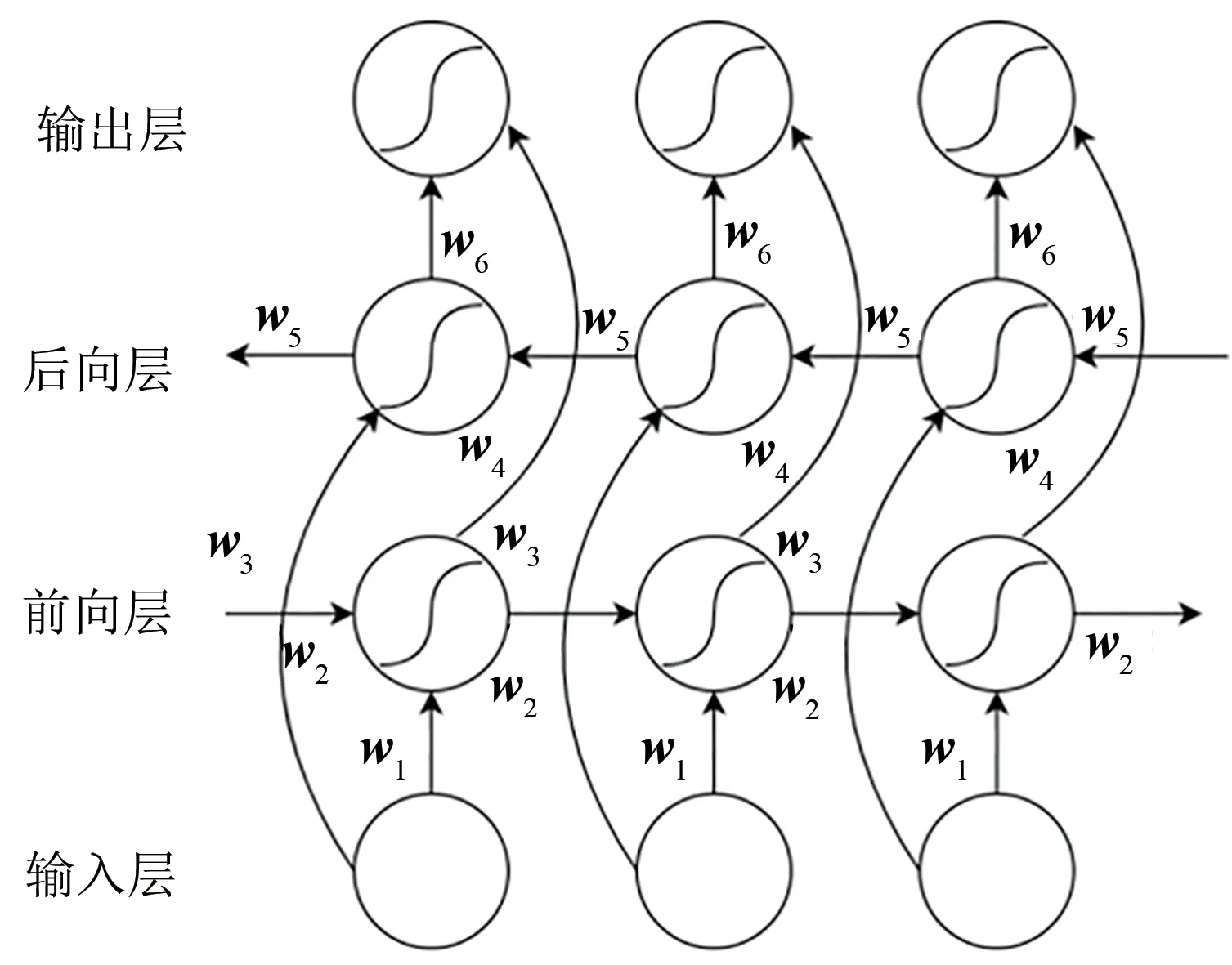
图4 BiLSTM结构图Figure 4 The structure diagram of BiLSTM
其中,w1和w2属于前向层中权重矩阵中的权重向量,w3和w5属于后向层中权重矩阵中的权重向量,w4和w6属于输出层中权重矩阵的权重向量,ht是前向的输出,是后向的输出,两者通过函数g得到BiLSTM层的输出。然后将BiLSTM 层的输出输入至注意力层,通过1.2.1 节中的注意力机制公式得到该层的输出O。
BiLSTM-ATT的结构如图5所示。

图5 BiLSTM-ATT结构图Figure 5 The structure diagram of BiLSTM-ATT
算法步骤如下:
算法3 BiLSTM-ATT算法
输入:嵌入矩阵Y
输出:特征向量O
(1)将Y输入至BiLSTM层,通过式(15)得到ot;
(2)将ot输入至注意力层,通过式(2)得到特征向量O。
1.3 特征融合
在这一步中,将经过局部特征提取后得到的结果和经过全局特征提取后得到的结果进行特征融合,即将APCNN层的输出D和BiLSTM-ATT层的输出O进行拼接,公式如下:
然后通过全连接层进行分类。全连接层的层数就是需要分类的DGA域名的种类数量,这一层的激活函数使用softmax函数,该函数将多分类结果转换为概率,公式如下:
特征融合的算法步骤如下:
算法4 特征融合算法
输入:特征向量O,特征向量D
输出:分类结果s
(1)将特征向量O和特征向量D通过concatenate函数进行拼接,通过式(20)得到C;
(2)将C输入至全连接层,使用softmax函数进行分类,通过式(21)得到s= softmax(C);
(3)输出分类结果s。
2 实验与结果分析
2.1 实验数据集
实验的数据集分为恶意域名数据集和良性域名数据集,恶意域名数据集中的数据主要是域名生成算法(DGA)自动生成的恶意域名,现有的恶意域名数据集DGArchive[18]是公开的恶意域名数据集,良性域名数据集主要来自于文献[19]。在本文中,DGA数据集中共有约85万条数据,良性数据集共有约76万条数据。在评估模型的时候,使用交叉验证法划分数据集,将训练集、验证集和测试集的样本数按照8∶1∶1的比例划分。实验数据集的数量分布如表2所示。
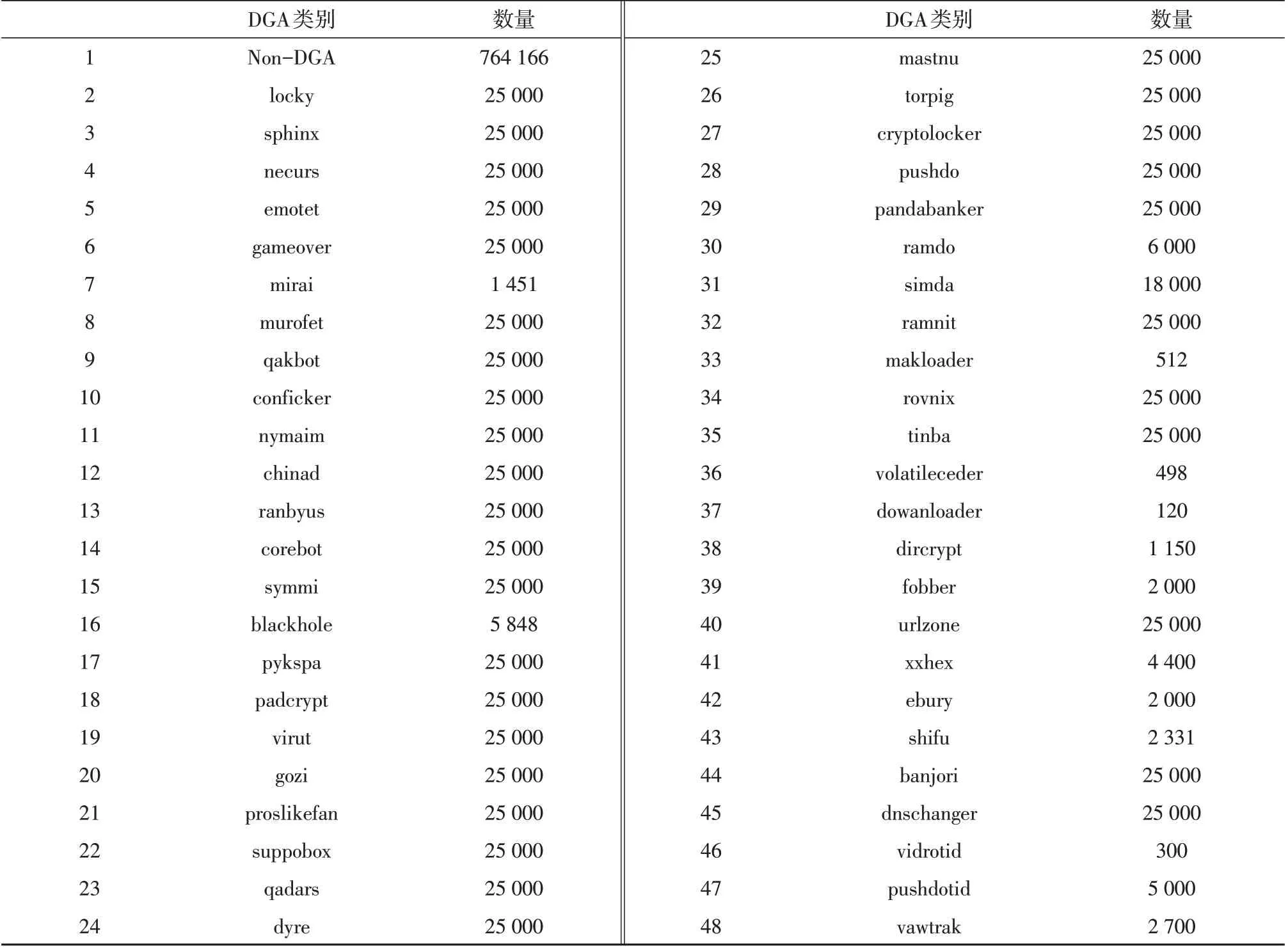
表2 数据集数量分布Table 2 Distribution of the numbers of datasets
2.2 实验环境
本文的实验环境如表3所示。

表3 实验环境Table 3 Experimental environment
2.3 APCNN-BiLSTM-ATT 域名检测算法在实验数据集上的应用
(1)数据预处理
利用pandas 统计该数据集中域名的长度,并且将其可视化,可视化得到的域名长度分布如图6所示,由此可知域名长度最长的不超过74,因此,在进行数据预处理时,对域名进行字符编码并将域名长度填充至74,然后将其输入至嵌入层进行向量化。

图6 域名长度分布图Figure 6 Distribution of domain name lengths
(2)特征提取
将经过数据预处理的域名分别输入至APCNN层进行域名的局部特征提取,再输入至BiLSTM-ATT层进行域名的全局特征提取。
(3)特征融合
将上一步经过局部特征提取后得到的结果和经过全局特征提取后得到的结果进行特征融合,然后通过全连接层进行输出。全连接层的层数就是需要分类的DGA域名的类别数,因此在进行二分类实验时,全连接层的层数为2,在进行多分类实验时,全连接层的层数便是数据集域名的类别数48。
2.4 实验参数设计
在APCNN 层中,卷积网络的卷积核数量为3,卷积核大小为5、6、7,滤波器大小为256,激活函数是ReLU。在BiLSTM-ATT 层中,BiLSTM 层的维度 是128,激活函数为ReLU,该实验的损失函数为focalloss函数,实验参数设置如表4所示。

表4 实验参数设置Table 4 Experimental parameter settings
由于实验数据集中恶意域名的数量分布不均,因此在进行多分类域名检测时导致部分数据量很低的域名检测率很低甚至为0,因此,在本算法进行域名多分类时,损失函数采用focalloss 函数[20]。focalloss 函数的公式如下:
其中,pt代表模型预测某类别的概率,α是类别权重,用来调和正负样本的权重比,γ是用来调节样本不均衡的问题,一般取γ≥1,对于易分类样本的损失进行一个幂函数的降低,因此(1 -pt)γ可以使模型更加关注于难分样本,有利于模型预测能力的提高,因此在本实验中将focalloss函数作为损失函数。
2.5 评价指标
为了验证该模型检测DGA 域名的能力,本文的评价标准有准确率(Accuracy,Acc)、精确率(Precision,Pr),召回率(Recall,Rc)和F1值(F1-score),计算公式如下:
其中,TP(True Positive)表示被正确归为DGA类别的样本数;FP(False Positive)表示被错误归为良性域名的样本数;TN(True Negative)表示被正确归为良性域名的样本数;FN(False Negative)表示被错误归为DGA 类别的样本数。F1值是精确率和召回率的一个综合评价指标,准确率(Accuracy)是最基础的评价指标,描述了整体检测结果是否正确。在该实验中使用准确率和F1值作为主要评价标准,准确率和F1值越大,说明模型性能越好。在多分类实验中,本文使用加权平均值中的评价指标来验证模型的性能。加权平均(weighted avg)是指对每个类的指标值进行加权平均求和,它考虑了每个类别样本数量在总样本中的占比,因此可以用来判断DGA域名的多分类检测能力[21]。
2.6 结果分析
在这一节中,对实验结果进行分析,由于本算法中包含卷积神经网络,因此卷积核的选择很重要。首先使用不同的卷积核进行实验,在选择好模型参数后进行二分类和多分类实验分析。
2.6.1 卷积核的选择
在选择卷积核时,选择了几种常见的卷积核组合进行对比实验,只改变卷积核的大小,其他实验参数不变。由表5可知,当卷积核大小为5、6、7时实验的准确率最高,且这个组合卷积核的数量少,可以减少计算时间,卷积核的滤波器的大小都是256。

表5 卷积核大小对比实验Table 5 Comparison of convolution kernel sizes
2.6.2 分类结果分析
在这一节中,本文使用并行CNN(Parallel CNN)、LSTM-ATT、Bilbo-Hybrid模型和本文提出的模型进行二分类和多分类对比实验,通过比对它们的准确率和F1值验证DGA域名的检测能力。二分类是指将域名分为DGA 域名和良性域名两个类别。二分类实验结果表明,本文提出的模型在DGA 检测上准确率和F1 值(0.982 9、0.982 9)高于其他模型,计算时间也大都小于其他模型,这说明本文提出的模型对DGA域名检测能力好于其他模型,结果如表6所示。

表6 二分类实验结果Table 6 Results of binary classification
随后再进行多分类对比实验,实验的准确率如表7所示,结果表明,在进行多分类实验时,本文提出的算法检测DGA域名的准确率(0.929 2)高于其他模型,本文提出的算法在精确率、召回率和F1值这3个加权平均值的综合评价指标上均有提升(分别为0.931 0、0.929 2、0.928 2),训练时间也有所减短,这证明本文提出的模型检测DGA域名的能力高于其他模型。

表7 多分类实验结果Table 7 Results of multi-classification
2.6.3 多分类对比实验
本文主要提升了字典型DGA 域名的分类能力,如mastnu、suppobox 和gozi 等域名。图7 展示了字典型DGA域名的F1值,其中各字典型DGA域名的F1值都有所提升,大部分的字典型DGA域名的F1值几乎达到了1,这说明本模型对于字典型DGA的检测能力高于其他模型。由图7可知,本模型对mastnu这一类别的字典型域名的F1值提升最多。图8对mastnu 这一域名进行了具体分析,该类域名的准确率和F1值都有大幅度提升,本模型对于这一类别域名的召回率提升最多,由此可知,本文提出的模型对mastnu域名的检测能力高于其他模型。
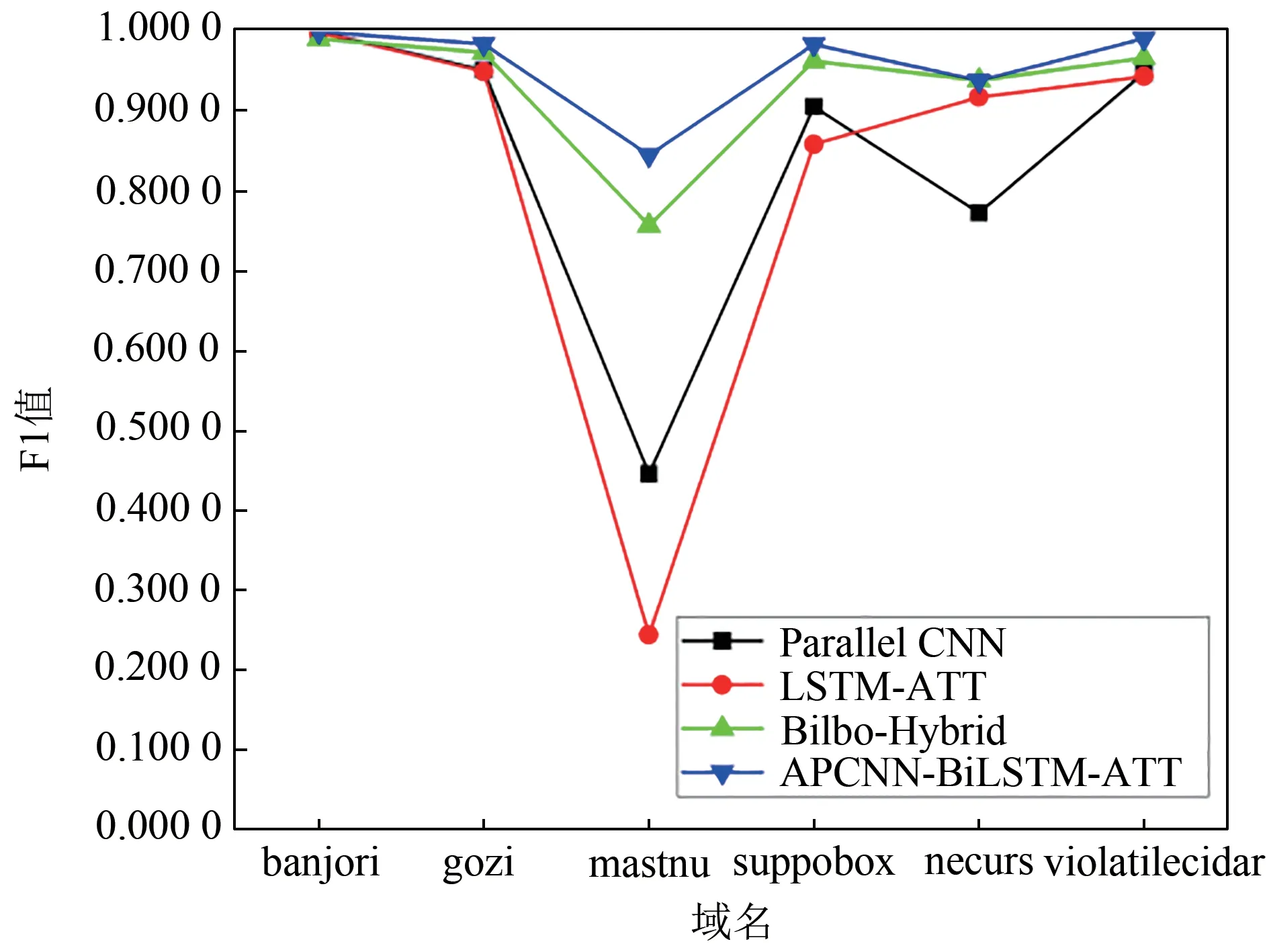
图7 字典型DGA域名F1值Figure 7 F1-scores of dictionary-based DGA domain names
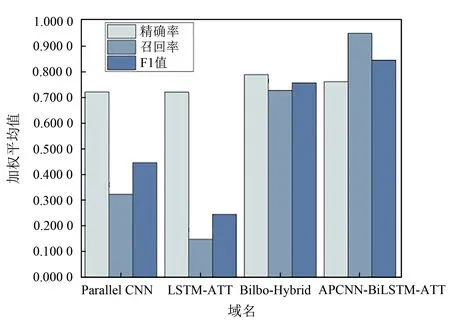
图8 mastnu DGA域名精确率、召回率和F1值结果对比Figure 8 The precision, recall and F1-score comparison of mastnu DGA domain names
本文同时也提升了基于字符的DGA域名的F1值,但由于其他模型对于基于字符型的DGA域名的检测率本身就不低,因此本模型对于该类型域名检测率的提升幅度并不大,字符型的DGA域名的F1值对比如图9 所示。由于focalloss 函数的加入,因此本文提升了一些数据量很低的域名的检测率。由表2 可知,mirai、dowanloader、makloader和vidrotid等域名的数据量很少,由图10对这些类别的DGA域名F1值进行的统计分析可知,这些数据量很少的域名的F1值高于其他模型的F1值,但是对于dircypt这一类域名,本文模型的F1值提升不高。总体来说,本文提出的模型对DGA的检测效果好于其他模型。

图9 字符型DGA域名F1值Figure 9 F1-scores of character-based DGA domain names

图10 数据量少的DGA域名F1值Figure 10 F1-scores of DGA domain names with less number
APCNN-BiLSTM-ATT 检测模型的多分类混淆矩阵如图11所示,该矩阵的每一行对应着预测属于该类的所有样本,其对角线表示预测正确的样本个数,由此可知,本文提出的模型取得了比较有效的分类结果,但同时也有一些域名会被误判,比如conficker和nymaim域名被误判为pykspa域名等等,但被误判的域名类型不多。总体而言本文所提出的模型在DGA类别的多分类检测上是有效的。

图11 APCNN-BiLSTM-ATT检测模型的多分类混淆矩阵Figure 11 Nomalized confusion matrix for APCNN-BiLSTM-ATT detection model
3 结论
本文提出了APCNN-BiLSTM-ATT域名检测算法以检测DGA域名,描述了该域名检测算法的算法流程,并且使用了大量类别的DGA域名进行了二分类和多分类实验,通过与其他模型进行比较,可知本文提出的模型对DGA域名的检测分类效果高于其他模型,尤其提高了基于字典和一些数据量很小的DGA域名的分类准确率。
不过仍然存在少许域名检测率很低的问题,虽然提高了一些数据量少的DGA域名的检测率,但提升幅度不高,针对此类问题,后续会继续改进算法以解决此问题。此外,还有少许基于字符的DGA 域名检测率低,其原因是本文提出的模型没有准确地提取其特征,导致这类域名与良性域名相混淆,针对这一类问题,在后续的研究中可以通过在嵌入层中使用词嵌入的方法以提取域名特征,从而提高域名的检测率。
