融入历史信息的多轮对话意图识别
2023-07-13孟佳娜孙世昶姜笑君刘玉宁马腾飞
孟佳娜,单 明,孙世昶,姜笑君,刘玉宁,马腾飞
(大连民族大学 a.计算机科学与工程学院;b.文法学院,辽宁 大连 116650)
近年来社交网络发展迅速,海量数据推动着人机对话系统不断的发展,促进了数据驱动的开放领域对话系统的研究[1]。如今,任务型人机对话系统[2]已经在生活中被广泛的应用。但是在任务型人机对话系统研究历程中,大多数的研究都是针对单轮对话开展的,并且意图分类和语义槽填充单独处理语句,传统任务型对话面临新的挑战。
Sarikaya等[3]提出基于卷积神经网络的联合模型用于意图识别和语义槽填充两个任务。Tur等[4]使用了一种联合模型,通过递归神经网络将离散的语法结构和连续空间的单词和短语表示合并到一个强大的合成模型中,用于执行人机对话系统中的NLU任务。Zhang等[5]提出了基于胶囊的神经网络模型,通过动态路由协议模式进行联合建模,从而使用推断的意图表示进一步协同插槽填充提高模型性能。通常训练词向量的方法都是使用 Word2Vec,但是Word2Vec主要是从词义的分布式假设出发,最终得到相应的向量,其弊端就是它是静态的,无法联系上下文并且该技术不能从根本上解决一词多义的问题。
针对上述问题,本文从联合建模、引入历史信息和预训练模型微调三个方面对自然语言理解任务进行研究。实验结果表明,通过使用提出的基于多任务学习的联合模型和微调预训练模型的方式,可以提升意图识别和语义槽填充任务的效果。
1 相关工作
1.1 预训练模型
BERT是用来处理词向量的工具,2018年谷歌公司发布了全新的预训练模型BERT,在各大自然语言处理的比赛中脱颖而出。在BERT[6](Bidirectional Encoder Representations from Transformers)诞生之前,通常都是使用Word2Vec训练词向量,但是Word2Vec所具有的泛化能力使其包含了某一个词的全部含义,因此分布式的表示方法只能够把两种含义编码成一种向量,无法很好地解决一词多义的问题,这也是词向量目前存在的问题。
而BERT的提出恰好解决了这一问题,通过寻找词与词之间的特征更好地表达句子的完整语义。BERT采用无监督学习的方式使用Transformer模型的Encoder部分,同时也沿用了Transformer模型的多头注意力机制,使得BERT能够在训练的过程中能够联系上下文,解决一词多义的问题。BERT模型图如图1。
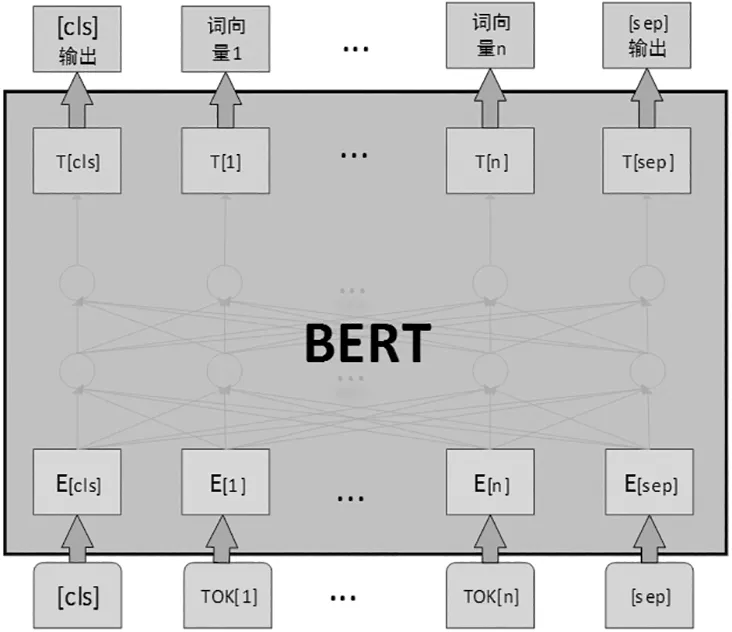
图1 BERT模型图
1.2 融入多轮对话
为了使得模型能够联系上下文,循环神经网络(Recurrent Neural Network, RNN)[7]应运而生。同时RNN的出现也很好的解决了全连接神经网络的弊端。但是在处理长句子时RNN容易丢失记忆信息,导致模型性能表现不佳。长短期记忆网络(Long Short-Term Memory, LSTM)[8]的提出很好的解决了这些问题,LSTM实际上是RNN的一种变体,其实质是将RNN的隐藏层变换成了一个长短期记忆的模块,能有效解决长距离的依赖问题。Chuang等[9]通过比较了不同类型的RNN,在音乐建模和语音信号建模的任务上评估这些循环单元,证明了长短期记忆网络比传统的循环单元效果要好。
2 本文方法
本文提出基于多任务学习的多轮对话语言理解联合模型,该联合模型的两个任务分别是意图识别和语义槽填充。代表当前轮次的对话预测,历史轮次的对话用到表示。同时模型的设计中添加LSTM模块来引入历史信息,其中LSTM1代表第一轮输入的句子训练时使用的历史信息编码器,LSTMt代表当前轮次LSTM的历史编码器模块,此时的LSTM已经融入了1到t-1轮次的对话历史信息。
2.1 基于预训练模型的语义编码器
本文分别使用BERT和RoBERTa作为多轮对话的语义编码器,以使用BERT模型作为语义编码器为例,对于多轮对话任务一共有T轮次的对话,输入每轮对话的文本M=(m1,m2,...,mn)首先送进BERT训练其语义表示,计算之后合成ut,ut代表输入文本中[CLS]位置,最后完成对输入文本的分类,计算过程如下公式。
Xt=BERT(mt,1,mt,2,…mt,n)=(ut,xt,1,xt,2,…xt,n)。
(1)
式中:ut代表第t轮对话BERT输出的[CLS]隐状态向量;xt,n表示第t轮次对话的第n个词所对应的向量表示。
2.2 进一步预训练
在多任务联合模型基础上,将预训练模型进行进一步训练,使得预训练模型更适应此任务型人机对话任务,提升模型的性能。通过采用三阶段模式进行进一步预训练,选用预训练好的BERT和RoBERTa,然后用相关的小数据进一步训练,保留训练后的权重,再对模型进行微调得到更好的性能如图2。

图2 预训练模型进一步预训练的方法图
2.3 引入历史信息的编码器
2.3.1 LSTM模型
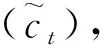
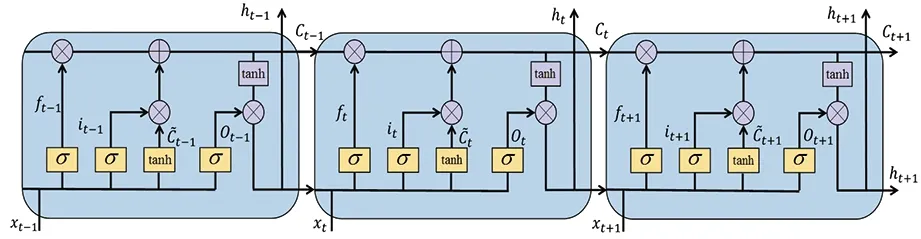
图3 LSTM模型
计算过程如下公式:
输入门:it=σ(wi·[ht-1,ut]+bi),
(2)
遗忘门:ft=σ(wf·[ht-1,ut]+bf),
(3)

(4)
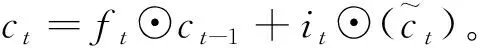
(5)
最后根据细胞的状态得到输出门输出当前值ht,如式:
ht=ot⊙tanh(ct)。
(6)
2.3.2 意图识别和语义槽填充解码器
通过全连接层映射标签,最后通过softmax得到意图标签yI如式。
ytI=softmax(WIht+bI)(t∈1,2,…T)。
(7)
由于本文任务是多轮对话,其中模型中的第n次slot输出状态就是指当前轮次的输出状态。因此直接将除CLS和SEP的当前轮次的输出状态通过全连接层将其映射到标签集合,然后通过softmax层对每个词处理后,得到每个维度的数值就是这个词的标签概率,从而得出每个词相应的标签所属的类别。将每一轮次的文本的长度设置为n,WS是语义槽任务的权重矩阵,bS是语义槽填充部分的偏置项,xt,i是经过BERT处理后代表当前轮次的第i个文本向量输入到softmax层。公式如下:
(8)
2.4 基于多任务学习联合训练
本模型采用多任务学习的方法,联合训练意图识别和语义槽填充任务,通过使用交叉熵函数作为损失函数,其中Number代表样本的数量,类别的数量为ClassNumber,pik代表对样本i预测为k的概率,yik代表当k和样本i是相同的种类时,其值是1,其他的均为0。
(9)
由于意图识别和语义槽填充这两个任务有很明显的联系,在实际的训练当中LossI,LossS分别代表意图识别和语义槽填充的损失,LossJ代表整个联合模型的整体损失。
(10)
联合模型最终训练目标损失函数如下所式:
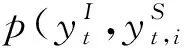
(11)
2.5 微调联合模型
2.5.1 Lookhead优化器
想要在神经网络中获得更好的性能,往往需要代价高昂的超参数调节。使用Lookahead[10]可以改进内部优化器的收敛性,并经常提高泛化性能,同时对超参数变化鲁棒性很好,实验证明,Lookahead对内循环优化器的变化,快速权值更新的次数和慢的权重学习速率具有很强的鲁棒性,因此本文选用Lookahead提升模型的性能。
2.5.2 自蒸馏微调策略
为了提升BERT的自适应能力,提出了自蒸馏微调策略[11],进一步对BERT的微调进行了改进。自蒸馏主要是采用了监督学习的方式去进行知识蒸馏。自蒸馏主要是采用了监督学习的方式去进行知识蒸馏。本文选用了SDA (Self-Distillation-Averaged)[12]的方法如图4。先计算出过去K个time step参数的平均值作为教师模型,进一步提升了模型的性能。
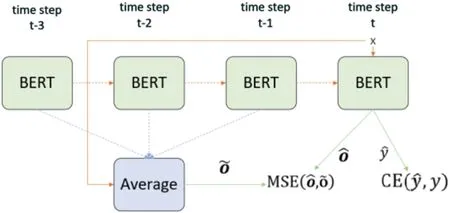
图4 SDA微调的策略图
2.5.3 对抗训练
对抗训练(adversarial training)是增强神经网络鲁棒性一种的重要方式[13]。在自然语言处理领域中,在语言模型中使用对抗训练,既提高了鲁棒性同时也提高了泛化能力。对抗训练的一般性原理其公式可以概括为如下的最大最小化公式:
(12)
实际上,对抗训练的研究基本上就是在寻找合适的扰动,使得模型具有更强的鲁棒性。FGM(Fast Gradient Method)[14]采用了L2归一化的方法。其核心思想就是通过利用梯度的每个维度的值除以梯度的L2范数,保留梯度的方向可以使训练后模型的效果更好。FGM的公式如下:
(13)
式中,g代表损失函数L输入x的梯度,公式如下:
g=▽xL(θ,x,y)。
(14)
3 实验结果与分析
3.1 数据集
本文选用三个数据量依次递增的数据集,分别是KVRETA[15]、MultiWOZ[16]、DSTC8[17]。KVRET数据集是斯坦福自然语言处理小组收集的。斯坦福自然语言处理小组发布的这个数据集里面包含了3031段任务型多轮对话的数据,主要里面包含了导航类,日程安排类和天气搜索类。MultiWOZ采用的2.2版本的数据集,MultiWOZ一个大型多领域用于特定任务对话模型的人机对话实验数据集。该语料库由Attraction、Hospital、Police、Hotel、Restaurant、Taxi、Bus和Train这8个领域组成。DSTC8是2019年第八届对话系统挑战赛发布的数据集,对话系统挑战赛DSTC由微软、卡内基梅隆大学的科学家于2013年发起。实验所使用的数据集的具体描述见表1。
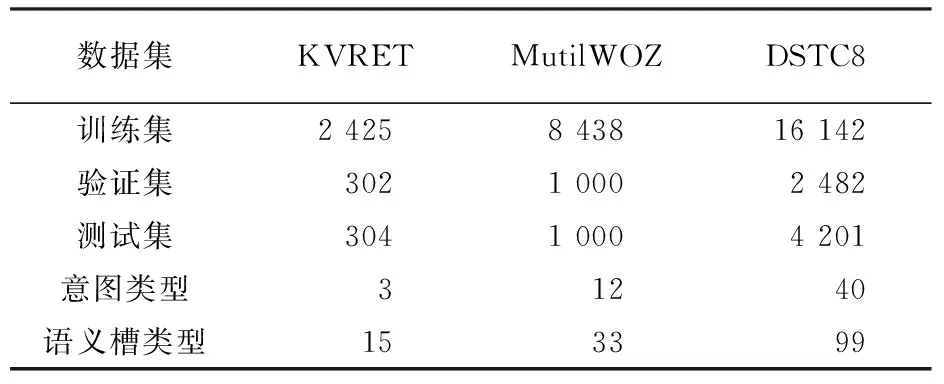
表1 KVRET、MultiWOZ和DSTC8数据集统计
3.2 实验结果与分析
3.2.1 基线模型
SDEN[18]:模型通过使用记忆网络的方法,把记忆后的编码存储,通过顺序对话编码网络,允许按时间顺序从对话历史中编码上下文,在多域对话数据集上的实验表明,该结构降低了语义帧错误率。
MNMDLJ[19]: 提出了一种新的对话逻辑推理(DLI)任务,该任务在多任务框架下与SLU共同巩固上下文记忆, 采用联合学习的方法进行训练。
CDS[20]:提出了模型采用基于方法的语义组合机制。
Joint BERT:基线模型,采用基于BERT意图分类和语义槽填充的联合学习模型。
Joint RoBERTa:将基线模型中的BERT模型换为RoBERTa意图分类和语义槽填充的联合学习模型。
Joint BERT+LSTM:本文提出的实验模型。
Joint RoBERTa+LSTM:在本文Joint BERT-LSTM模型基础上,将BERT换成RoBERTa模型。
本文模型基于Joint BERT再加入LSTM后,引入历史信息之后意图分类的准确率达到99.9%,本文的模型捕捉词语中的隐藏依赖关系,提升意图识别的表现,意图识别表现的提升意味着模型对于意图识别的困惑度降低,使该部分的训练的效率更高,同时由于本文的模型是联合建模,BERT的训练效率的提高也就提升了槽填充的表现。在KVRET数据集上的实验的结果见表2。

表2 KVRET数据集中的实验结果 %
3.2.2 实验结果分析
在实验的训练过程中,以KVRET数据集和MultiWOZ数据集为例,对比Joint BERT+LSTM、Joint RoBERTa+LSTM、Joint BERT和Joint RoBERTa这四种模型的变化过程。KVRET数据集中Joint RoBERTa+LSTM模型收敛的更快,虽然意图分类的准确率略低于Joint BERT+LSTM模型,但是语义槽填充的F1值更高,整体来看Joint RoBERTa+LSTM模型在KVRET数据集上的效果更好。在KVRET数据集当中,其loss下降的变化图如图5,意图准确率和语义槽填充的F1值如图6。
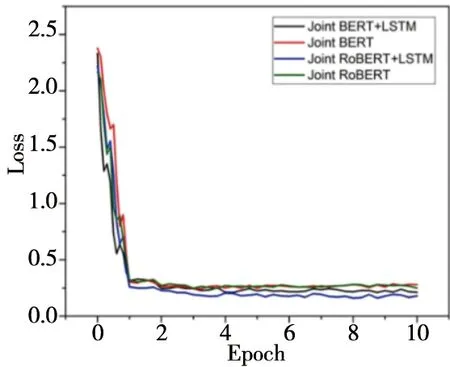
图5 KVRET数据集loss变化图
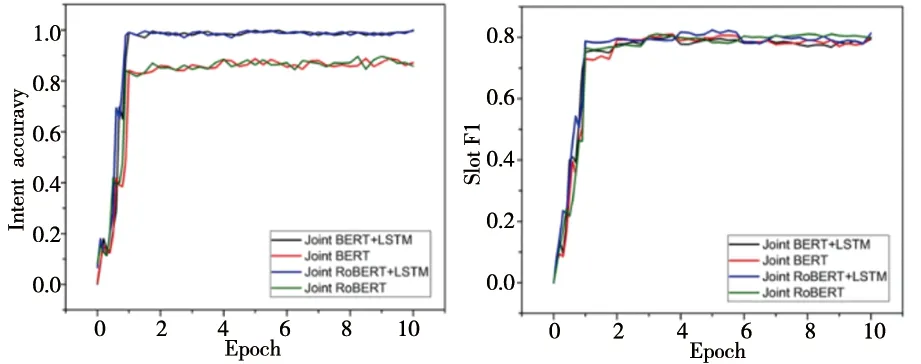
a)Intent准确率变化图 b)Slot F1值变化图图6 KVRET数据集意图准确率和语义槽填充变化图
在MultiWOZ数据集当中,其loss下降的变化图如图7。意图准确率和语义槽填充的F1值分别如图8。Joint BERT+LSTM模型收敛的更快,并且意图分类的准确率和语义槽填充的F1值最高,因此Joint BERT+LSTM模型在MultiWOZ数据集上效果更好。
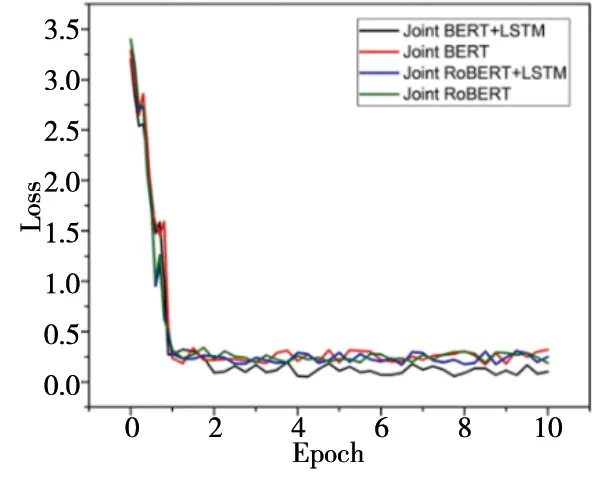
图7 MultiWOZ数据集的loss变化图

a)Intent准确率变化图 b)Slot F1值变化图图8 MultiWOZ数据集意图准确率和语义槽填充变化图
综合以上两个数据集的训练变化图中可知,在模型引入LSTM之后,模型的在训练时收敛的更快,模型的性能也有了大幅的提升。
在这两个数据集上实验的结果见表3,由于KVRET多轮对话中的数据较少,为了证明模型应用在其他任务上仍然有效果,本文也选用了数据量较大的数据集,分别是超10 000段对话的跨越8个域的带注释对话数据集MultiWOZ和超16 000段对话覆盖16个领域的数据集DSTC8。可以看出使用相同预训练模型加入LSTM融入历史信息之后,意图识别的准确率都大幅提高,语义槽的F1值也有略微提升。
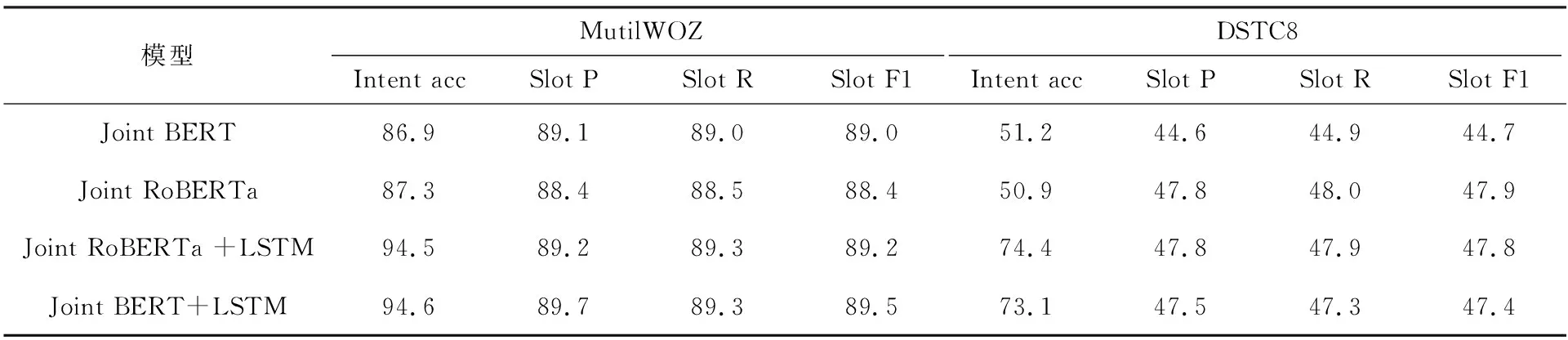
表3 MultiWOZ和DSTC8中的实验结果 %
综上所述,在引入了LSTM对多轮对话的历史信息进行建模,并对意图分类和语义槽填充任务进行联合建模后,无论是使用BERT和RoBERTa其模型性能都有所提升,同时也证明了引入历史信息的预训练联合模型具有较强泛化能力。
4 结 论
提出了一种基于预训练模型的多轮对话自然语言理解联合建模的方法,将BERT和RoBERTa作为语义编码器对意图分类和语义槽填充进行联合建模,通过多任务学习共享特征的特性,联合建模可以提升两个任务的效果。同时本文加入BERT到多轮对话上,引入LSTM用历史信息进行多轮对话语言理解任务的联合建模,辅助意图识别任务,在大幅度提高意图识别准确率的同时,提高了槽填充任务的准确率。
