基于ICEEMDAN和松鼠算法优化极限学习机的滚动轴承故障诊断
2023-07-13赵凤强史书杰
周 阳,赵凤强,乔 浩,王 波,史书杰
(大连民族大学 机电工程学院,辽宁 大连 116650)
滚动轴承作为旋转机械的核心组成部分,起着承受载荷、传递动力的重要作用,其稳定性和可靠性是整个设备健康工作的关键。根据统计,滚动轴承故障造成的旋转机械设备故障占所有机械故障的30%[1]。当滚动轴承发生故障时,通常会有异常的振动噪声和异常的温升,振动噪声会影响机械设备的正常运转,并且严重时会造成重大事故;而温升过高会导致轴承过早损坏或降低轴承寿命,所以精准识别与判断轴承故障是保持机械设备长久运营的关键。工作时,轴承有无故障都会产生一定的振动信号,经过多年的技术发展,提取振动信号中的有效特征信号和分析轴承故障原因的方法也逐渐多样化、高效化。
在处理非平稳,非线性的振动信号时,经验模态分解(EMD)是强有力的工具[2],复杂的信号集可以通过该方法自适应分解为若干分量和残差,即固有模态函数(IMF)。EMD有很好的自适应能力和信噪比[3],能够从瞬时频率中提取重要信息,鲍怀谦[4]为增强传统轴承强噪声背景下故障诊断精度和稳定度,用EMD处理振动信号,有效地提取到前期的微弱信号,更好地识别轴承故障特征。然而,经验模态分解也存在着一些缺陷,当采集到的信号存在强噪音干扰,脉冲干扰等异常事件或者信号分量频率和幅值之间相互作用,就会发生模态混叠,从而影响了IMF的信号特征。同时,在由极值点确定包络线的过程中,存在端点被当做极值点的情况,从而产生较大的计算误差,引发端点效应问题,导致产生虚假分量和失真现象。为此,集合经验模态分解(EEMD)[5]、互补经验模态分解(CEEMD)[6]、完整集合经验模态分解(CEEMDAN)[7]等EMD的改进算法依次被提出。Jinde Zheng[8]也提出了均值优化模式分解(MOMD)方法,以提高原始EMD在均值曲线构建中的性能,结果表明,MOMD方法比原始EMD方法获得了更准确的IMF分量和故障诊断效果。改进的自适应噪声完备集合经验模态分解(ICEEMDAN)是2014年由Colominas[9]提出的,在重构信号时,它能消除噪声影响从而避免信号被污染,同时能够有效克服模态混叠和端点效应问题[10]。
在模式识别方面,常用的方法有随机森林[11]、支持向量机(SVM)[12]、人工神经网络(ANN)[13]、极限学习机(ELM)[14]等,相对于其他方法,极限学习机具有学习效率高、参数设定简单、泛化性好等优点。董治麟[15]将多尺度排列熵与ELM结合,应用于对滚动轴承故障类型和程度进行识别,相对于其他方法具有更高的识别率。同时,ELM是一种单层前馈神经网络,算法参数少,训练时间快,但其输入权值和隐含层阈值对分类精度有较大的影响。本文为提高ELM的识别准确率和泛化能力,选择适合的网络参数,提出松鼠搜索算法优化极限学习机SSA-ELM的模式识别方法。
1 特征提取方法
1.1 ICEEMDAN原理
在 ICEEMDAN算法中,分解过程的每个阶段,把白噪声一步步地加入,与此同时,在 EMD分解白噪声所得的模态中,选出特殊的模态信号,并将其添加到残差信号中,从而得到信号的每一模态分量,实现对原始信号的完全分解[16]。
ICEEMDAN有以下算子Ek(·)、M(·)、〈·〉,Ek(·)表示经过EMD分解得到的第k个模态分量,M(·)是生成局部平均值运算符,〈·〉表示求平均值,具体实现步骤如下:
(1)对原始信号x加入经过EMD分解的具有零均值和单位方差的高斯白噪声分量,根据xi=x+β0E1(ωi)得到分解序列的局部均值信号为M(x+β0E1(ωi)),其中,β0为第一个噪声振幅,ωi表示被添加的第i个白噪声。
第一个残差:
r1=〈M(xi)〉 (i=1,2....S)。
(1)
第一个分量:
IMF1=x-r1。
(2)
对第一个残差r1加入白噪声作为第二次局部平均值M(r1+β1E2(ωi))可以得到第二个分量:
IMF2=r1-r2=r1-〈M(r1+β1E2(ωi)) 〉。
(3)
以此类推,直到不能分解为止,得到第K个分量:
IMFK=rK-1-rK=rK-1-〈M(rK-1+βK-1EK(ωi)) 〉。
(4)
式中,噪声振幅βk由以下公式确定:
(5)
式中,εk为第k次加噪信号与分析信号间的期望信噪比倒数,std为标准差。
可以看出,ICEEMDAN算法的核心依然是经验模态分解,与CEEMDAN向信号分解的每一个阶段都加入高斯白噪声不同,它先利用EMD将自适应高斯白噪声分解,获取其中特定第K个IMF分量作为辅助噪声,接着对IMF分量计算信号和噪声的局部均值并把残差减去局部均值,最后得到K阶差值,计算过程中,噪声信号和伪分量也大大减少。因此ICEEMDAN能有效地避免重构误差、模态混叠等问题,其流程图如图1。
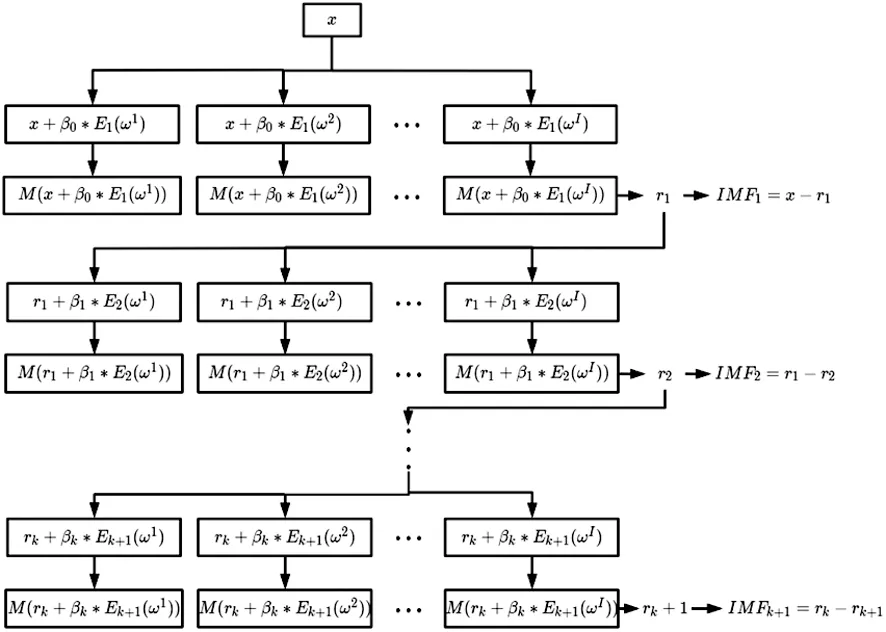
图1 分解流程图
1.2 相关系数
由于原始信号中含有大量虚假的分量,相关性较差,不能有效反应原始信号特征,所以在将它分解后可与原始信号的互相关系数作为区分虚假分量的评定指标,并将互相关系数较小的IMF分量剔除。
在时域中,对于容量为n的样本,两个信号xi和yi的互相关系数r表示为
(6)
1.3 奇异值分解(Singular Value Decomposition,SVD)
SVD[17]是一种矩阵分解方法,在机器学习、信号处理、统计分析等方面有着广泛应用。奇异值分解能够有效获取矩阵中所代表的重要信息,本文将利用这个特点提取筛选出的IMF分量的特征值。在线性相关的矩阵左右分别乘以一个正交矩阵进行变换,可将原始矩阵转换为线性独立的矩阵。例如对于矩阵Bm×n,秩为r,则存在两个标准正交矩阵U和W及对角矩阵D,满足
B=UDWT。
(7)
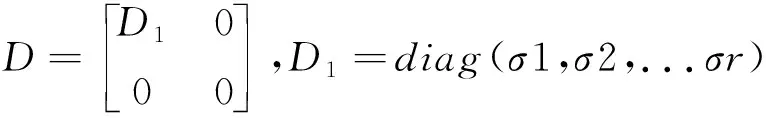
2 故障分类方法
2.1 松鼠搜索算法(Squirrel Search Algorithm,SSA)
在松鼠搜索算法中[18],松鼠的位置分为三种:山核桃树、橡子树、普通树,分别表示最优解,次优解和一般解。松鼠们通过移动位置寻找更好的食物源。具体流程如下:
初始森林中的n只松鼠可以用下面的矩阵表示:
(8)
式中,d为待优化变量的维度,FSi,j表示第几只松鼠在第j维上的值,由式(9)所确定。
FSi,j=FSiL+U(0,1)×(FSi,u-FSi,L)。
(9)
式中,U(0,1)是0和1之间的随机值,FSi,u和FSi,L是第j维的上下界。
所有松鼠的适应度函数表示为
(10)
计算排序所有松鼠的适应度值,最佳适应度值的松鼠停留在山核桃树上,次佳适应度值的三只松鼠停留在橡子树上,其他的松鼠则停留在普通树上。接下来根据天敌出现的概率Pdp以及松鼠们所在位置决定对应的三种移动策略。当没有天敌出现,松鼠可以通过滑行来更好的获取食物,寻找山核桃树和橡树;而存在天敌时,松鼠们会谨慎前行,随机转移到一个新的地方。
(1)第一种移动策略是由橡树去往山核桃树。
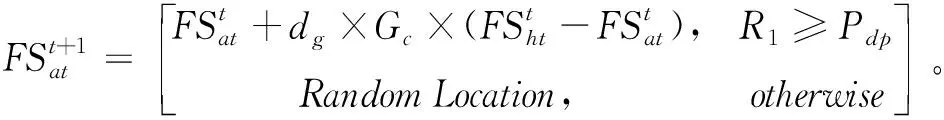
(11)
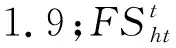
(2)第二种移动策略是由普通树去往橡树。
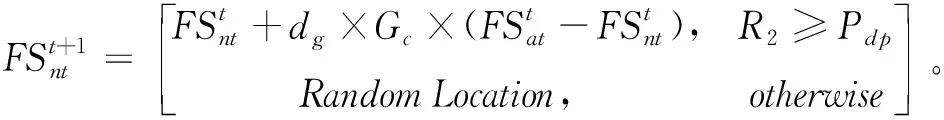
(12)
式中,R2为0和1之间的随机数。
(3)第三种移动策略是部分已经有过食物的松鼠会由普通树去往山核桃树。
(13)
式中,R3为0和1之间的随机数。
为了防止陷入局部最优,松鼠优化算法中引入了季节变化机制,通过季节检测常量Sc检测季节的变化。
(14)
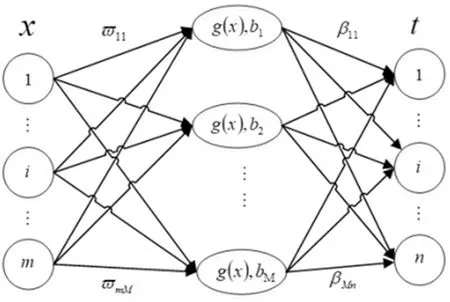
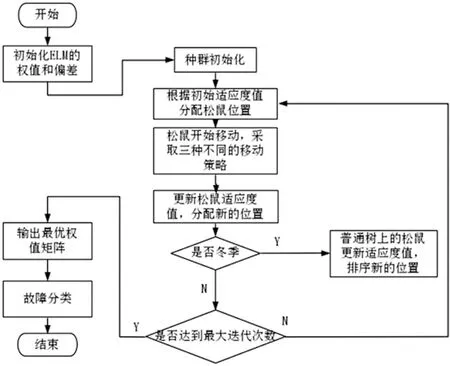
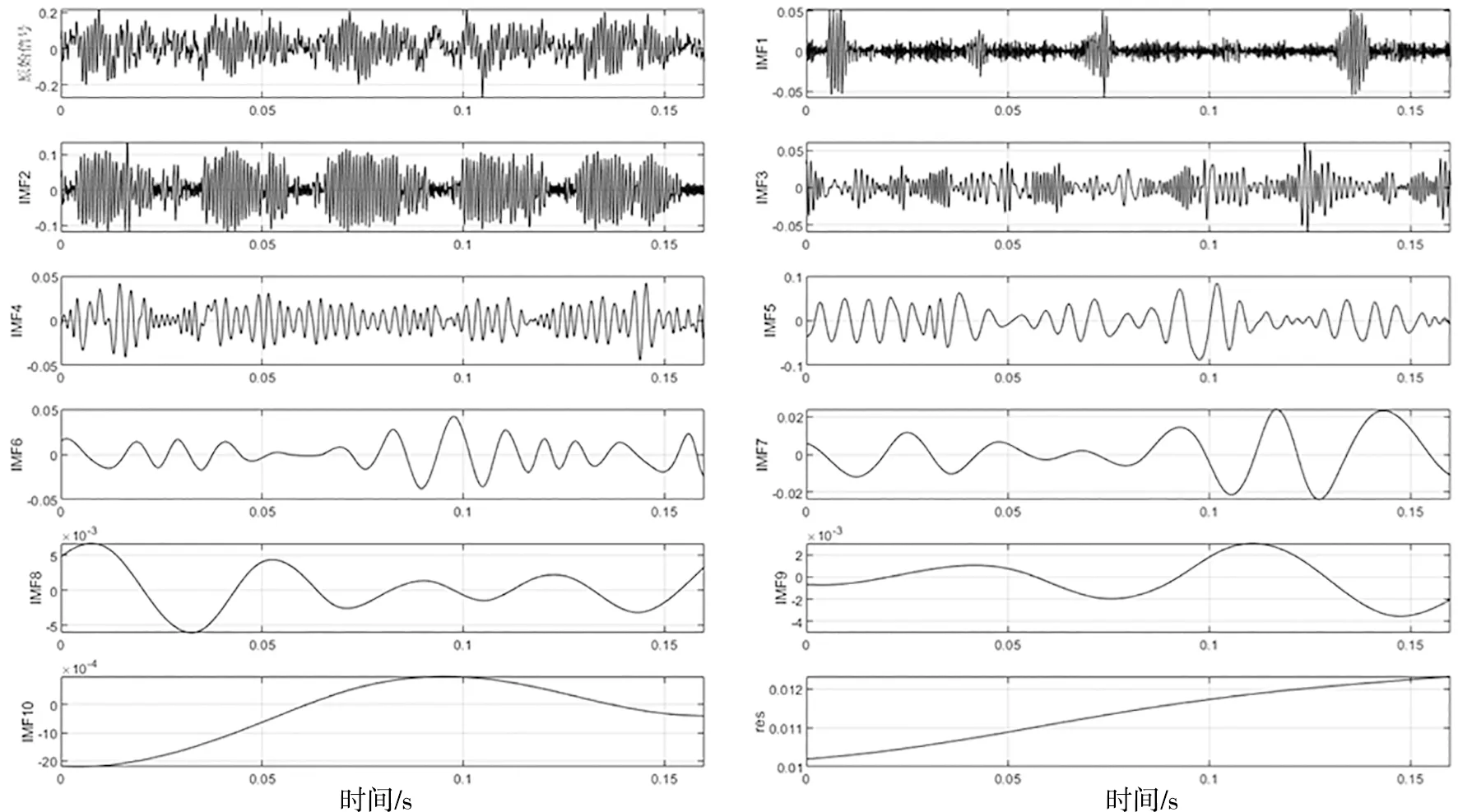
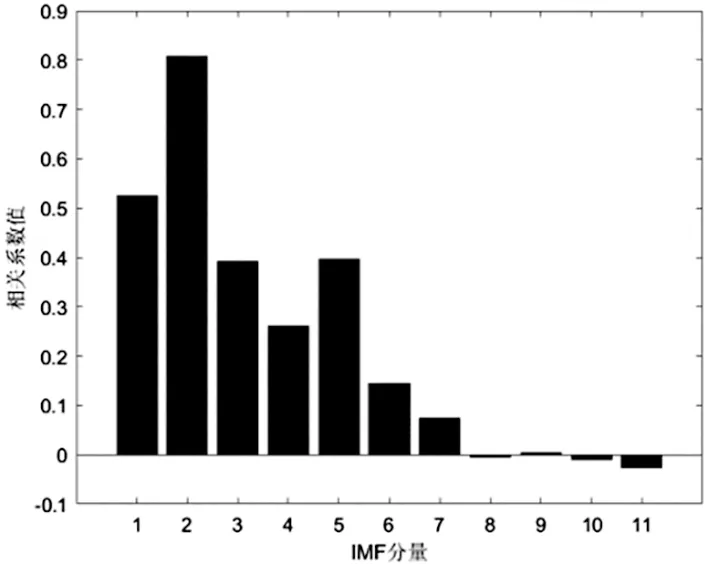
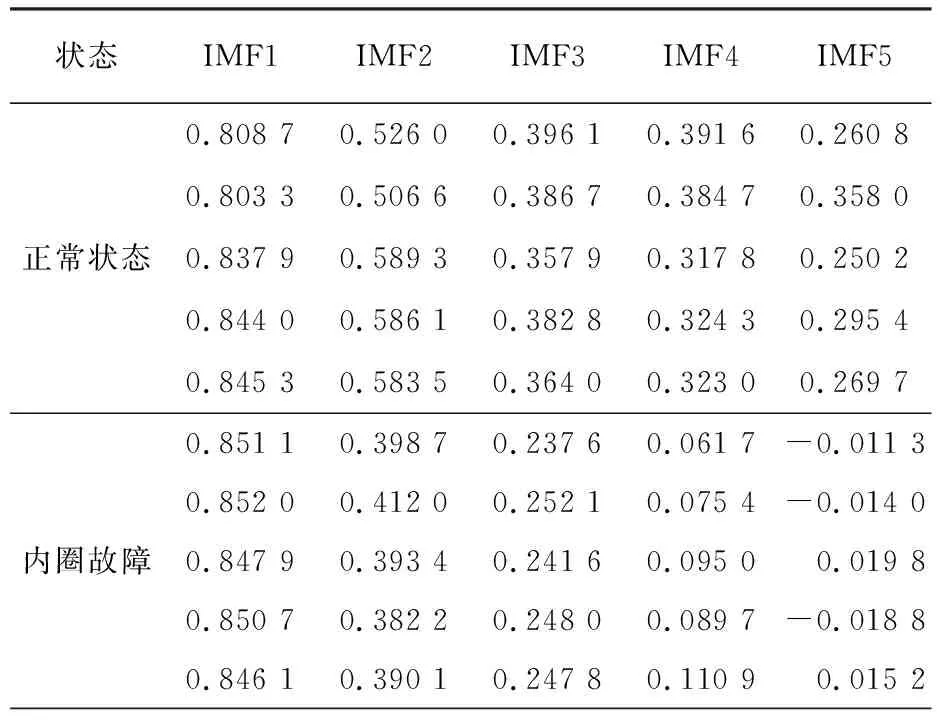
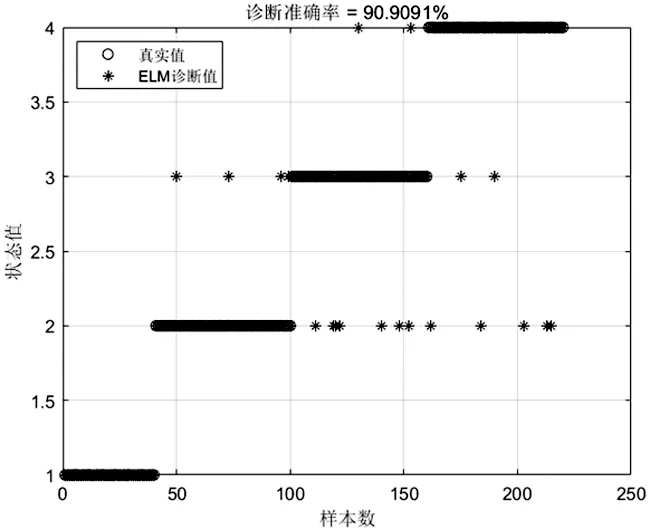
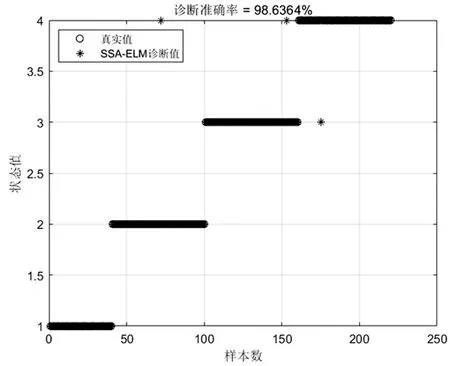
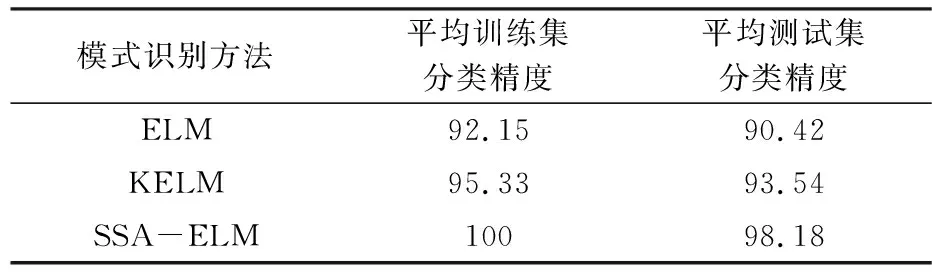
当季节变化条件Sct (15) 式中,Smin主要用于平衡全局和局部搜索能力,t和tm分别为当前迭代和最大迭代值。 当满足季节变化条件(冬季结束),普通树上的松鼠就会按照式(16)移动。 (16) 式中,Levy表示列维分布中的步长,列维分布通过随机改变步长能够提高全局搜索能力。 (17) 式中,ra和rb是[0,1]间的正态分布随机数,β为常数,一般取1.5,σ取值如式(18)。 (18) 式中,τ(x)=(x-1)!。 极限学习机(Extreme Learning Machine,ELM)是由Huang[19]等人在2014年提出,它的输入权值矩阵与隐含层阈值均为随机生成,只需选择合适的隐含层神经元个数,与传统的基于梯度下降的学习算法如反向传播算法相比,具有训练参数少、学习速度快、泛化能力强等优势。目前已被广泛应用于分类、回归以及预测问题。 设m、M、n分别为ELM网络输入层、隐含层和输出层的节点数,g是隐层神经元的激活函数,bi为阈值。 设有N个任意数据样本(xi,ti),1≤i≤N,其中: xi=[xi1,xi2,…,xim]T∈Rm; (19) ti=[ti1,ti2,…,tin]T∈Rn。 (20) ELM模型如图2。 图2 极限学习机的网络训练模型图 数学表达式为 (21) 式中:βi=[βi1,βi2…,βin]T为第i个隐层节点与输出权值向量;ωi=[ω1i,ω2i,…ωmi]T为输入层节点与第i个隐层节点的输入权值向量;oi=[oi1,oi2,…,oin]T为最终输出值。 ELM算法用于故障分类时,有两个决定模型训练性能和最终分类准确率的关键因素,便是初始输入权值ωi和隐藏层阈值bi。为了减小这两个参数给诊断精度带来性能和精度的影响,本文采用SSA算法对ELM两个参数进行迭代寻优,进而建立SSA-ELM分类模型。 SSA优化ELM流程图如图3。以训练集错误率作为适应度函数,即当错误率最小时,所对应的ωi和bi,作为该模型的最优参数。具体优化步骤如下[20]: 图3 优化模型流程图 步骤1:设置初始化参数,包括迭代次数、升力系数、天敌出现概率、种群大小等; 步骤2:按初始适应度值划分食物等级,适应度值最佳的为山核桃树,其次接下来三个为橡树,其他为普通树; 步骤3:根据是否出现天敌,橡树上的松鼠利用式(11)开始移动,更新位置; 步骤4:普通树上未有食物的松鼠利用式(12)开始移动,更新位置; 步骤5:普通树上已有食物的松鼠利用式(13)开始移动,更新位置; 步骤6:将此时所有松鼠得到的最佳适应度值与上一次做对比,更新最佳适应度值并将它们分配到山核桃树、橡树和普通树上; 步骤7:判断季节变化,如果满足就改变普通树上松鼠的位置; 步骤8:根据公式(15)更新Smin值; 步骤9:排序新的适应度值,根据排序结果再次分配松鼠位置; 步骤10:判断是否达到迭代次数,达到就退出循环并输出最佳值,否则返回步骤2继续运行。 本文实验数据采用凯斯西储大学轴承数据集部分数据[21],实验平台如图4。该平台拥有一个2马力的电机(左)、一个扭矩传感器(中)、一个功率测试计(右)以及相应的电控设备。被测试轴承厂商为SKF轴承和等效的NTN轴承。其中,SKF轴承会被电火花加工技术在轴承的内圈、外圈、滚动体位置制造出0.007英寸、0.014英寸、0.021英寸的单点故障;TNT轴承则被制造出0.028 英寸和0.040英寸的单点故障。测试中采用的加速度传感器通过16通道的记录器记录振动信号,分别放置于驱动端和风扇端采集,采样频率为12 kHz和48 kHz两种。 图4 西储大学轴承实验平台 本文选用采样频率为12 kHz、负载为0、转速为1 797 r·min-1的驱动端数据,其中包含了正常状态和内圈故障、外圈故障、滚动体故障三种故障状态,以及故障状态下直径为0.007、0.014、0.021英寸的三种故障尺寸。将上述的9种故障状态与正常状态共计10种类型作为实验样本数据,实验样本每个序列长度为2 048,正常状态分为100组数据(数字1作为其状态值),故障状态分为450组数据,每种故障有150组(数字2作为内圈故障状态值、数字3作为外圈故障值、数字4作为滚动体故障值),每个故障状态都囊括三种尺寸并打乱顺序,以3:2的比例分为训练集和测试集,具体数据见表1。 表1 实验样本表 使用ICEEMDAN对样本集信号进行分解,得到的正常状态及其IMF分量时域图如图5。 图5 正常状态信号分解图 经过ICEEMDAN,原信号被分解出为若干IMF分量,这其中包括一些虚假分量,不利于信号分析。根据相关系数法,选取相关程度较高、能够明显反映信号特征的分量。轴承正常状态下的11个IMF分量与原始信号的相关系数如图6。经过多次测试发现,系数最高的前5个分量能够较好地表示原信号特征。 图6 正常状态分量的相关系数图 对选出的IMF分量进行奇异值求解,每种状态可由5个奇异值(即特征值)表示,每种故障状态都包含三种尺寸故障,把状态值与特征值列表归类,部分数值见表2。 表2 轴承工作下四种状态的部分特征值 本文将分别使用极限学习机、核极限学习机(KELM)和松鼠有算法优化的ELM对训练集中各状态的特征值进行训练,其中,极限学习机的参数设置:隐含层个数为20,传递函数为Sigmoid函数;核极限学习机的参数设置:核函数为径向基函数(RBF);松鼠算法的参数设置:种群数量为30,最大迭代次数为100,天敌出现概率0.1,滑动系数为1.9,以训练集错误率为适应度值。 利用这三种方法对测试集分类,单次诊断结果如图7~ 9。 图7 极限学习机单次诊断图 图7中可以看出仅用极限学习机方法分类识别,准确率只有90.909 1%,轴承的外圈故障,内圈故障,滚动体故障识别精度均有较大的误差。图8中可以看出核极限学习机分类准确率为93.181 8%,比ELM提高了大约2.272 7%,误差主要集中在轴承内圈故障和滚动体故障的识别分类上,外圈故障仅有2组诊断失败。图9看出经过松鼠算法优化后的极限学习机分类准确率98.636 4%,比ELM提高了7.727 3%,失败样本仅外圈故障、内圈故障和滚动体故障各一例。 图8 核极限学习机单次诊断图 图9 松鼠算法优化后极限学习机单次诊断图 为了进一步验证实验准确性和鲁棒性,对比了ELM、KELM、SSA-ELM三种方法重复20次实验得到的训练集和测试集的平均精度,具体数据见表3。 表3 实验结果对比 % 由表3可知,SSA-ELM的平均训练精度为100%,平均测试精度为98.18%,相比较于ELM和KELM具有更高的诊断精度。 本文对滚动轴承故障诊断方法进行了研究,通过ICEEMDAN和奇异值方法完成对轴承故障振动信号的特征提取,并将提取到的奇异值特征输入到本文提出的SSA-ELM模型中,完成了对西储大学轴承数据集的10类故障状态的识别。结果证明,基于SSA-ELM的滚动轴承故障诊断模型准确率可达98.18%,相比于传统的ELM、KELM模型而言,诊断准确率分别提高了7.76%和4.64%,该方法有较高的识别精准和识别能力。2.2 极限学习机
2.3 SSA-ELM模型
3 实验分析
3.1 数据准备

3.2 信号分析和特征提取
3.3 故障诊断

4 结 语
