基于数据集元特征的超参数优化方法
2023-06-16焦博扬郭浩浩杨中国
焦博扬,王 菁,∗,朱 峰,郭浩浩,杨中国
(1.北方工业大学 大规模流数据集成与分析技术北京市重点实验室,北京 100144;2.北京国电通网络技术有限公司,北京 100070)
0 引言
超参数优化被认为是获得机器学习算法有效性能的重要部分[1]。初始超参数的配置很大程度上决定了算法的性能,而超参数调整旨在通过使用初始超参数搜索空间重复训练机器学习模型来确定模型超参数的最佳配置。目前,超参数优化问题仍然是机器学习算法应用的难点之一。
起初,调整超参数主要是依赖专家的经验反复试验获得超参数的最佳的配置。但是手动调参非常耗费时间且需要专家指导。因此,自动化机器学习(Automated Machine Learning, AutoML)近几年得到了快速发展,其中,自动超参数优化是AutoML 的首要任务之一,它以自动化的方式代替手动调整超参数,旨在通过探寻性能最佳的超参数配置[2-3]。即使不了解机器学习领域的知识,也可以使用自动超参数优化方法找到最优的超参数配置。此方法能够更快更准确地得到结果,提高机器学习的性能。自动超参数优化作为AutoML领域的热门话题,研究者们已经提出了很多超参数优化方法。但是AutoML 的超参数优化方法仍然存在耗时长、性能低的问题。
为了解决超参数优化方法存在的问题,本文考虑到将数据集元特征的历史经验作用于初始超参数配置区间来缩小搜索空间,从而加快找到最优超参数配置,提高算法的性能,进一步优化AutoML 的性能。OpenML[4]平台上有很多来自不同领域的数据集,本文选择一定约束条件的分类数据集进行实验。实验结果表明:与同类别工具相比,该方法在预测超参数最优区间的精度达到87%,且耗时缩短将近一半,从而使效率得到了进一步的提升。
1 相关工作
作为机器学习领域的热门话题,超参数优化的研究可以追溯到1990年代[5]之后,许多超参数优化方法相继出现。主要的实现方法有:网格搜索(Grid Search,GS)、随机搜索(Random Search,RS)、遗传算法(Genetic Algorithm,GA)、贝叶斯优化(Bayesian Optimization,BO)、元学习等。
GS 通过遍历整个超参数搜索空间来解决问题,它的初始超参数搜索空间由软件包提供默认值或者用户手动设置[6]。它是一种较简单的方法,其计算复杂度会随着待优化超参数的规模呈指数级增长,适用于小规模任务。RS 是通过在超参数搜索空间内随机采样来搜索最优配置[7],相比较于GS,它的搜索效率更高一点。Schaer 等人[8]和 Bhat 等人[9]的一些研究表明,RS 在高维空间中的效率远高于GS,但是也无法保证能够找到最优超参数配置。上述算法搜索需要花费大量的时间和空间才能找到答案,因此一些研究在有限的搜索空间内,通过减少搜索超参数配置的数量来提高算法性能。如经典的启发式算法——GA[10],它是进化算法之一,具有良好的全局搜索能力,可以很快地找到全局近似最优解。贝叶斯优化通过先获取几组超参数配置的算法性能建立概率模型,再进行采样且每一次采样的结果用于更新模型,最后通过概率模型得到最优超参数配置。Gustafson 等人[11]提出了Bayesian Tuning and Bandits(BTB),它是一种用于处理机器学习参数的开源AutoML 库。Takuya Akiba 等人[12]提出了Optuna,它有方便的目标函数定义、多样化的采样算法,可以动态地构建超参数搜索空间,是一个特别为机器学习设计的自动超参数优化框架。上述的超参数优化算法,仍然存在效率低的问题,没有将先前任务中学到的知识应用于当前任务,导致了重复计算。最近,元学习[13]技术被广泛应用,Liu Xiyuan 等人[14]提出了一种基于上下文的元强化学习方法来解决超参数优化的效率低的问题。Reif 等人[15]提出利用各种数据集的历史信息构建元数据,然后建立模型对算法的超参数进行预测。元学习能够通过从大量任务中提取元知识来更快地学习到新任务的方法。值得注意的是现有的元学习方法显式地定义了元知识的表示和学习过程,导致对新任务泛化能力差。
上述的超参数优化方法适用于不同的情况,且具有各自的优点。超参数优化方法都是在每一次尝试超参数配置时优化选择更有可能的超参数,没有对初始超参数配置形成的搜索空间进行优化。超参数搜索空间依旧巨大,导致机器学习算法的性能没有得到进一步提升。模型的精度、参数本质上是由数据集本身的特征决定。本文借鉴文献[15-16]的思想通过将元学习与贝叶斯优化方法结合对超参数进行优化。首先利用已有数据集的先验知识,对数据集的特征进行提取,通过预测算法预测特定算法的超参数区间范围;然后将该范围用于AutoML 系统超参数优化的初始超参数配置区间范围先缩小搜索空间;最后再利用现有的贝叶斯优化方法进行超参数优化,从而提高算法的性能,使得AutoML 系统的耗时大大降低,性能有效提升。综上所述,本文从数据集元特征入手,将历史经验知识与贝叶斯优化结合共同指导超参数优化。
2 基于数据集元特征的超参数优化
2.1 方法原理
本节将介绍如何利用元学习与超参数优化(如贝叶斯优化)相结合的方式有效解决超参数优化问题。通过特定预测算法找到最优超参数对应区间,将此区间作为超参数优化的初始超参数配置区间,然后再使用超参数优化方法对超参数进行有效优化。原理如图1 所示,主要阶段可以分为:历史知识提取、预测模型构建、预测最优超参数对应区间、AutoML 超参数优化。
本文提出方法的具体步骤如下:
历史知识提取:利用OpenML 平台的数据集进行特征向量的提取,然后利用AutoML 系统获取当前数据集在特定算法下对应的最优超参数区间。
预测模型构建:将上述历史知识下的特征向量与最优超参数区间建立对应关系作为模型训练的输入,建立预测模型。
预测最优超参数区间:首先提取新数据集的特征向量,然后利用上述构建的预测模型预测当前数据集的最优超参数区间。
AutoML 超参数优化:将预测出来的最优超参数区间作为AutoML 系统特定算法下(如决策树)初始超参数配置区间,接着利用AutoML 系统的超参数优化方法进行超参数优化,获取到当前性能最优的pipeline。
2.2 基于元特征的历史经验挖掘
从历史数据集的特征中获取经验被认为是元学习问题,本文研究的目标是基于元特征为特定算法选择最优超参数区间。我们使用元学习算法将数据集特征整合到预测的过程中,并使用机器学习算法(分类模型)作为推荐数据的元学习器。元学习可以定义为将学习算法的性能与学习问题的特征(例如数据集的元特征)相关联以获得知识的自动化过程[16]。元学习有多种方法,这里使用的是基于数据集元特征的数据挖掘。
2.2.1 元特征
元特征是由学习问题中数据的一般特征形成的。算法的精度以及最优超参数值高度依赖于数据集的元特征[16-17]。元特征是刻画数据集的一种方式,主要包括简单特征、统计特征和信息论的特征等。简单特征一般描述的是数据集的一些统计信息,如实例数和属性。统计特征描述的是数据的统计属性,如典型相关分析。信息论特征描述的是数据集中属性的分布信息,如信息熵。本文参考的是OpenML 平台上数据集的属性,表1 是部分元特征描述。
表1 数据集元特征Tab.1 Meta-features of the dataset
对于数据集统计元特征,描述如下:
偏度:描述数据分布形态的统计量。数据左端有较多的极端值,数据均值左侧的离散程度强,偏度大于零,叫做正偏态。同理,数据右端有较多的极端值,数据均值右侧的离散程度强,偏度小于零,叫做负偏态。利用文献[18]中提供的公式计算连续属性的平均偏度:
其中,x是数据集的数字属性,μ是x的平均值,σ是x的标准差。
峰度:描述数据总体中所有取值分布形态陡峭程度的统计量。当峰度大于0 时表示低峰态;峰度小于0 时表示尖峰态;峰度等于0 时表示正态分布的峰度。利用文献[18]中提供的公式计算连续属性的平均峰度:
其中,x是数据集的数字属性,μ是x的平均值,σ是x的标准差。
典型相关分析是常用的挖掘数据关联关系的算法之一,主要是研究两组变量之间的相关关系。在数理统计中,假设有两组一维的数据集X和Y,则相关系数ρ的定义为
其中,cov(X,Y)是X和Y的协方差,而D(X),D(Y)分别是X和Y的方差,相关系数ρ的取值为[-1,1],ρ的绝对值越接近于1,则X和Y相关性越高,ρ越接近于0,则相关性越低。
信息论元特征有很多,主要有标准化类别信息熵、标注化类别平均信息熵、联合信息熵、互信息、信噪比、信息熵度量下的等同特征数目。
2.2.2 基于递归特征消除的特征选择算法
对于数据集的元特征,本文参考OpenML 平台上数据集的元特征,将这些元特征转化为特征向量作为研究对象。对于特定学习任务,有些元特征对任务结果的影响很小,甚至没有,因此去除这些不相关的元特征可以降低学习任务的难度,且可以使模型防止过拟合,提高学习算法的预测精度、鲁棒性和可解释性。特征选择即使用某种评价准则从原始特征空间中选择特征子集。特征选择有很多分类方式,依据特征选择和学习器的不同结合方式,特征选择主要分为过滤式、封装式、嵌入式和集成式[19]。
过滤式的特征选择算法效率较高,但是它和学习算法互不相干,所选的特征子集在准确率方面通常较低。集成式特征选择的特征子集稳定性较好,但是大都对数据分布敏感,且效率较低。嵌入式特征选择算法嵌入到学习器训练过程中,增加了模型的训练负担,且易过拟合。封装式特征选择是直接针对学习器进行优化,将最终要使用的学习器的性能作为特征子集的评价标准,选择的特征子集用于模型的性能更好。递归特征消除(Recursive Feature Elimination,RFE)[20]是封装式算法的代表。算法的起始训练集是特征全集,对数据训练后仅带有权重特征的模型精度为衡量指标,随后每次循环迭代消除权重最小即不相关特征。基于上述评价标准,根据特征权重的大小进行排序,产生特征子集S,最后根据特征子集对应的训练模型精度来选取最优子集D。这里采用此方法对于决策树的四个可调超参数(max_features、max_depth、min_samples_split、min_samples_leaf)进行特征选择,具体的算法过程见算法1,其中Y表示为上述四个可调超参数集合。
算法1 基于递归特征消除的特征选择算法


2.3 基于XGBoost 的超参数区间预测
超参数区间预测是采用机器学习模型作为元学习器来预测最优超参数值,本文利用数据集提取的元特征与最优超参数范围的对应关系,使用机器学习模型预测最优超参数区间范围。XGBoost 模型在预测问题应用中的效果很好,且数据集特征的区间预测变化趋势无明显规律呈非线性,因此本文采用XGBoost 算法对超参数区间进行预测。
在齿圈淬火处理时根据供应形式的不同,可以通过淬火机床程序设定相应工艺参数完成自回火处理,还可以利用淬火余热实现齿圈与飞轮件的热装,减少整机厂齿圈热装工序二次加热带来的能源浪费,实现经济效益最大化;同时减小齿圈二次(重复)加热导致硬度降低退火的风险。
2.3.1 XGBoost 算法
XGBoost 是Chen 等[21]提出的一种基于梯度提升算法的集成学习模型框架。它在总结了梯度提升算法工作基础之上进行了改进,提升了算法的准确性和运行速度。
假设样本数据集D={(xi,yi)},xi为第i个样本的特征数据,yi为结果输出值,模型的输出表示为k个弱学习器输出的累加:
其中,fz∈F,F是回归树的空间,定义如下:
其中,q表示树的结构,ω表示叶子权重,T表示树上叶子的数目,fz表示q和ω相应树的函数。
为了优化集成树并减小误差,XGBoost 的目标函数最终优化为
其中,l(·)是用来表示测量值和预测值差异的损失函数,是预测值,yi是测量值,t是最小化误差的迭代次数,Ω(·)是模型复杂度的惩罚值,
2.3.2 超参数区间预测
历史数据集中挖掘出各个数据集元特征与最优超参数的对应关系,将此作为训练模型的数据即元特征数据集。这里的最优超参数定义为:将初始超参数区间均分为n等份,使用自动超参数系统的特定算法获取成绩最好的超参数配置,此超参数配置对应的区间被认为是当前特定算法下的最优超参数区间。
预测模型XGBoost 流程图如图2 表示,首先将元特征数据集进行预处理,然后对处理的数据做RFE 特征选择形成新的数据集合D。对新数据集建立XGBoost 预测模型Premodel,调整部分参数优化预测模型。最后对超参数区间进行预测,预测出最优的超参数区间集合Interval。算法如下。

图2 基于XGBoost 的超参数区间预测流程图Fig.2 Flow chart of hyperparameter interval prediction based on XGBoost
算法2 超参数区间预测算法

2.4 基于数据集元特征的贝叶斯优化
贝叶斯优化是AutoML 领域里经典的超参数优化方法,是一种十分有效的全局优化方法。首先生成一个初始候选解集合,然后根据这些点获取信息,评估寻找下一个最有可能是极值的点,将该点加入集合中,重复这一步骤,直至迭代终止,最后从这些点中找出函数值最大的点作为最优解。
本文提出的基于数据集元特征的超参数优化方法(Hyperparameter Optimization Based on Dataset Meta-Features,HODMF)是在进行超参数优化之前限制超参数的取值范围,这里的超参数优化可以使用网格搜索、贝叶斯优化等超参数优化方法,现以贝叶斯优化为例。利用之前XGBoost 算法预测的每个超参数区间作为贝叶斯超参数优化的各个超参数初始区间,然后再利用贝叶斯优化方法进行优化,使得贝叶斯优化选择的点为最有可能的极值点且搜索的效率更高,最终生成性能最优的pipeline。
算法3 基于数据集元特征的超参数优化算法

3 实验
3.1 数据集
实验所使用的数据集来自OpenML 平台,从中挑选了活跃度较高的120 个分类数据集,这些数据集涉及不同的领域,包括计算机工程、生命科学、物理科学、社会生活、电子商务等领域。且数据集的实例最多有20 000 个,属性的个数分布为3 到100 个不等,类别的个数都是两个。数据集的特征足够多样,使得本文提出的超参数优化方法有一定的普遍性和适用性。
3.2 数据集评价指标
本实验对AutoML 系统中的决策树分类器进行实验验证,通过超参数优化得到的pipeline 对应的精度来评价超参数优化算法的性能。本文参考文献[22]采用MAE(Magnitude of Absolute Error)、MRE(Magnitude of Relative Error)和PRED(·)三个指标。
对于基于数据集元特征的超参数优化方法,最终生成最优的pipeline,评估pipeline 采用F1值指标评价当前pipeline 下的分类精度。
1) MAE:表示预测值与对应的最优对应的超参数区间值的绝对误差,即MAE=(最优精度-预测精度)×100%。
2) MRE:表示预测值与对应的最优超参数区间值的相对误差,即MRE=(最优精度-预测精度)÷最优精度×100%。对于MAE 和MRE,它们的值越小表示预测精度越高。
3) PRED(·):是一个常用的评价指标。PRED(m)表示MAE(MRE)小于m%的预测个数占总预测个数的百分比,即PRED(m)= (n0÷n)×100%。其中n0表示MAE≤m%(MRE≤m%)的数据集的个数,n表示全部数据集的个数,在本文中n为120。PRED(·)的值越大表明预测效果越好的数据集占比越大。本实验m取5,PRED(5)筛选出精度误差小于等于5%的数据集的占比。
4)F1值:表示特定pipeline 在AutoML 系统的性能评价指标。它通过P(精确率)和R(召回率)计算得出。
3.3 实验方法
本文实验的物理环境为:操作系统:Ubuntu 16.04; 内存 16G; CPU: Intel Core i5-1135G7 2.40 GHz。
本实验对AutoML 系统中的一种分类器(决策树)的超参数区间进行预测,且只对可调超参数(max_features、max_depth、min_samples_split、min_samples_leaf)进行区间预测。为了证明本文优化算法的性能,采用穷举法求出每个数据集上的最优pipeline 对应的超参数区间,并将此pipeline 的分类精度作为参照,这样可以清晰地展现此优化方法的有效性。实验对比对象为贝叶斯优化(BO)方法和Optuna 超参数优化框架,其中Optuna超参数优化框架分别采用不同的采样策略(GS,RS,TPE)进行实验。通过本文方法预测得到的最优超参数区间作为超参数方法的初始超参数区间( HODMF-BO, HODMF-Optuna-GS, HODMFOptuna-RS,HODMF-Optuna-TPE)与原BO 方法和Optuna 超参数优化框架进行对比分析。为保证实验公平,采用的数据和实验方法完全相同,对耗时和精度两方面进行对比分析。
3.4 实验结果分析
本文采用最优超参数区间预测算法对120 个数据集进行实验,将预测得到的最优超参数区间作为AutoML 系统中决策树超参数的初始配置区间,以此优化方法进行分类,从而得到各个数据集上的预测精度。本文分别计算了预测最优超参数区间算法的精度在各个数据集上的MAE 和MRE,表2 展示了部分数据集。
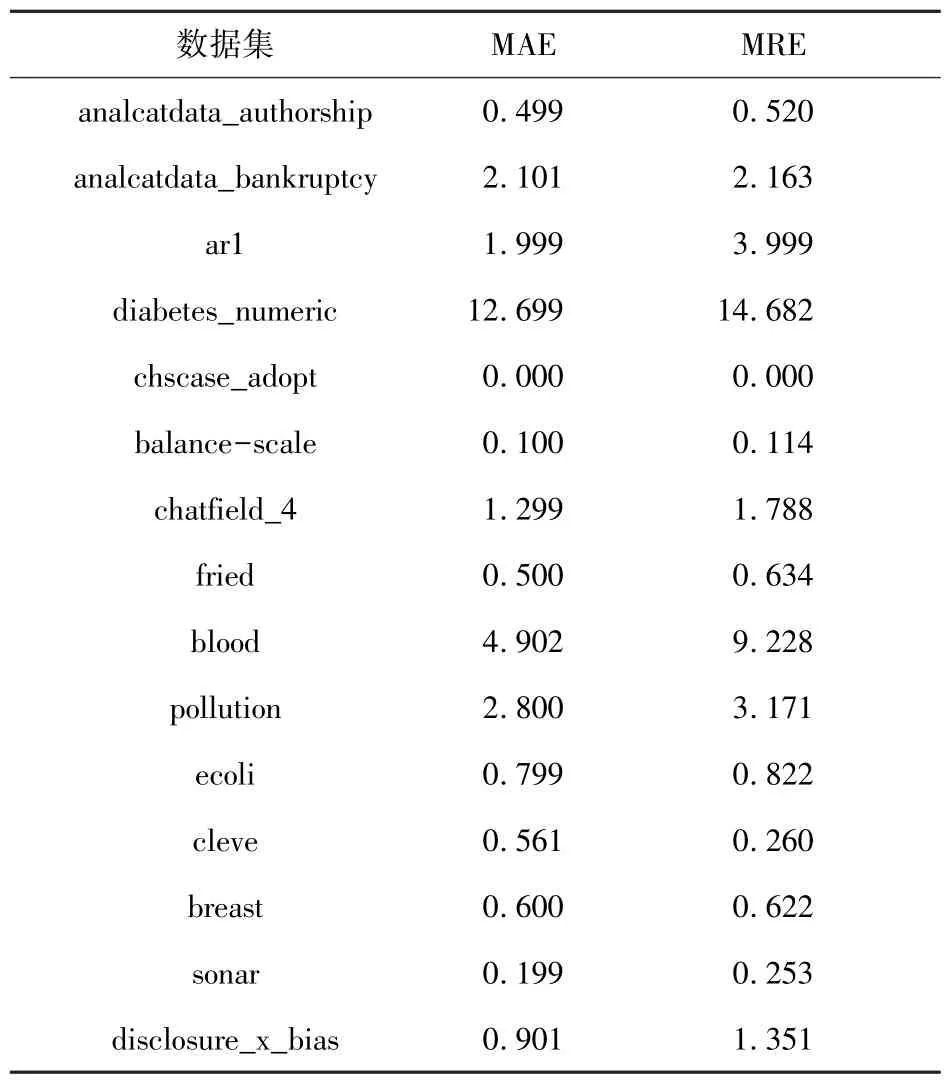
表2 预测区间与最优区间的绝对误差MAE和相对误差MRETab.2 Absolute error MAE and relative error MRE between prediction interval and optimal interval%
从表2 可以看出除了diabetes_numeric 数据集外,其他的数据集用预测算法得到的MAE 均小于5%。这也意味着大部分数据集都得到了较高的精度。然而,为了直观地看出预测最优超参数区间算法的效果,本文分别计算了120 个数据集上MAE 和MRE 的最小值(min)、最大值(max)、中位数(median)、众数(mode)、平均值(mean)和标准差(std.),并给出了PRED(5)的值,如表3。

表3 整体测试数据集在MAE 和MRE 的统计结果Tab.3 Statistical results of the overall test dataset in MAE and MRE%
从表3 中可以看到,MAE 和MRE 的最小值为0,说明预测最优超参数区间的算法能够成功找到最优区间,且均值和方差都较小,证明了此算法在大多数据集上的有效性。即使MAE 和MRE 的最大值较大,但是这仅仅是在较少数据集上的结果。MAE 在PRED(5)上说明有87.1%的数据集的预测超参数区间的精度的绝对偏差在5%范围内。综上,此算法在整体取得了较好的效果。
图3 描述的是使用上述最优超参数区间预测算法预测的超参数区间作为贝叶斯优化的初始超参数配置,用此方法(HODMF-BO)得到性能最优pipeline,将此pipeline 和使用原超参数配置的BO方法得到的pipeline 进行耗时对比。图中展示的是从测试集中随机选择的6 个数据集在两个方法上的对比结果。

图3 基于BO 的最优pipeline 耗时对比Fig.3 Comparison of optimal pipeline time-consuming based on Bayesian optimization
从图3 中可以看出在运行同一个数据集的情况下,使用HODMF 方法生成最优pipeline 的耗时大多都比未使用 HODMF 方法的耗时少将近50%。
图4 表示采用HODMF-BO 和BO 方法生成的pipeline 的性能对比。从图中可以看出采用这两种超参数优化方法生成的最优pipeline 的F1相差不大。除chscase_adopt 和sonar 这两个数据集外,其它数据集采用HODMF-BO 方法比BO 方法生成的最优pipeline 性能好。

图4 基于BO 的最优pipeline 性能对比Fig.4 Comparison of optimal pipeline performance based on Bayesian optimization
为进一步的证明实验的有效性,下面将HODMF 方法预测的最优超参数区间作为Optuna超参数优化框架中不同采样策略的超参数优化方法的初始超参数区间,与不采用HODMF 方法生成的pipeline 进行对比分析。
图5~图7 分别表示采用Optuna 超参数优化框架中的GS、RS 和TPE 策略的超参数优化方法与本文提出的HODMF 方法结合生成的pipeline的耗时对比。从图中可以看出采用HODMF 方法之后,Optuna 框架的超参数优化方法的耗时基本都减少了50%以上。

图5 基于Optuna-GS 的最优pipeline 耗时对比Fig.5 Comparison of optimal pipeline time-consuming based on Optuna-GS

图6 基于Optuna-RS 的最优pipeline 耗时对比Fig.6 Comparison of optimal pipeline time-consuming based on Optuna-RS
图8~图10 分别表示采用Optuna 超参数优化框架中的GS、RS 和TPE 策略的超参数优化方法与本文提出的HODMF 方法结合生成的pipeline的性能对比。从图中可以看出除了HODMFOptuna-RS 的breast 数据集外,采用HODMF 方法的超参数优化方法生成的pipeline 的F1大都比不采用此方法的性能好,也进一步验证了HODMF 方法的有效性。因此,可以说明本文提出的HODMF方法用于经典的超参数优化方法BO 和Optuna 超参数优化框架上,与原来相比,达到了良好的优化效果。
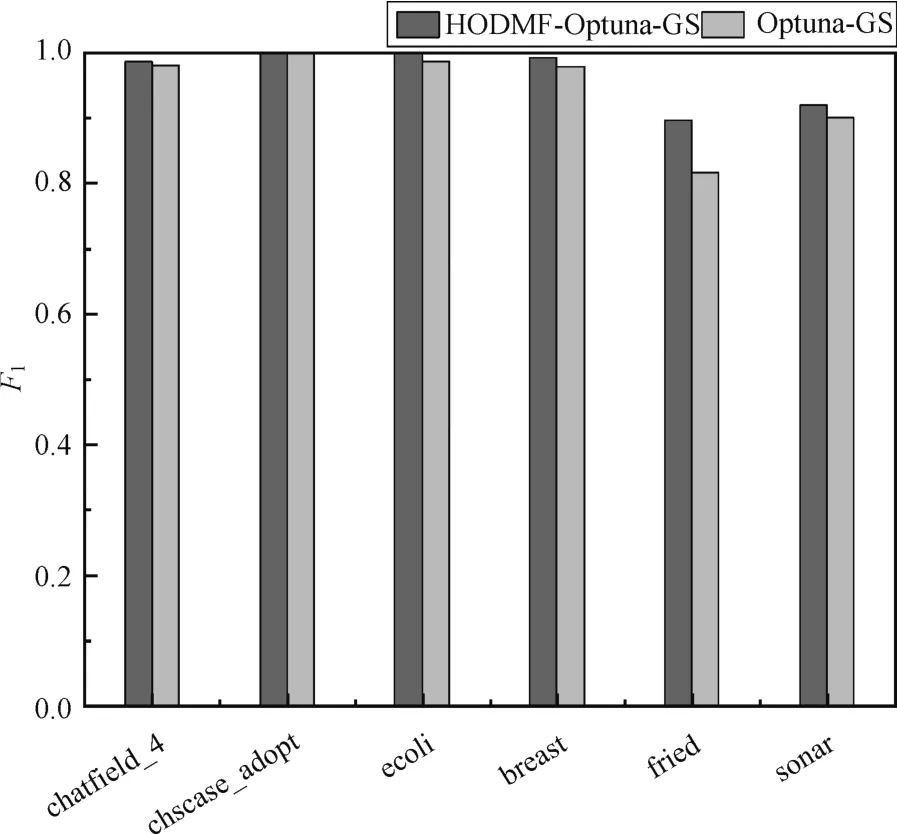
图8 基于Optuna-GS 的最优pipeline 性能对比Fig.8 Comparison of optimal pipeline performance based on Optuna-GS

图9 基于Optuna-RS 的最优pipeline 性能对比Fig.9 Comparison of optimal pipeline performance based on Optuna-RS

图10 基于Optuna-TPE 的最优pipeline 性能对比Fig.10 Comparison of optimal pipeline performance based on Optuna-TPE
分析实验结果,采用HODMF 方法的耗时明显减少的原因是由于缩小了初始超参数的区间范围,在超参数优化过程中,可以减少搜索的量级,使得可以更快速地找到下一个可能性能较优的超参数,相较于原来的超参数优化时间明显减少。另外,采用HODMF 生成的最优pipeline 的性能也达到了较好的水平,主要原因是利用挖掘历史数据集的元特征和其最优超参数区间的对应关系,建立预测模型预测数据集的最优超参数区间,同时在采用相同的优化方法下,缩小了超参数的搜索空间,从耗时情况可以证明这一点,并且采用HODMF 方法生成最优pipeline 的性能方面与未使用其方法相比,性能有一定程度地提升。本文是针对120 个数据集做实验,对于相似元特征的数据集,预测的最优超参数区间的准确度较高,因此采用HODMF 方法的耗时和性能相应也较好。本文选取的数据集是随机的,且来自于各个领域,所以实验具有一定的普遍性。综合上述分析:该方法在确保性能良好的情况下,耗时方面得到了极大的优化。
4 结论
本文提出了一种基于元特征的超参数优化方法。通过挖掘元特征与最优超参数区间的历史知识,预测新数据集在特定算法下的最优超参数区间。实验结果表明:该方法预测的最优超参数区间的精度达到87%。同时,把此预测区间作为AutoML 系统的搜索范围,大大优化了AutoML 系统的耗时问题。未来计划将此方法扩展到更多的数据集和其他任务工作中,提高此方法的应用范围,进一步优化此超参数优化方法。
