基于Hadoop的港口物流大数据应用研究
2023-06-16王妍妍王艳宁刘佳新任家东
王妍妍,王艳宁,刘佳新,任家东
(1.燕山大学 经济管理学院,河北 秦皇岛 066004;2.燕山大学 理学院,河北 秦皇岛 066004;3.燕山大学 信息科学与工程学院,河北 秦皇岛 066004)
0 引言
港口作为现代综合物流服务中心,对横纵物流链产生巨大的辐射作用。依托大数据技术,有效地收集、整理和挖掘海量数据对港口物流具有重要的意义。
大数据在物流领域的应用十分广泛。WANG等[1]将大数据分析用于物流和供应链管理中,建立框架完成大数据的收集、传播、分析和使用,同时还将大数据作为战略资产用于业务分析。BORGI 等[2]综述了运输和物流大数据,面对日益增长的数据,利用新的管理方法实时分析数据,为企业创造新的商业价值。GOVINDAN 等[3]改进大数据分析技术应用到物流和供应链管理中,通过跟踪策略、绩效关系等驱动供应链,解决了大数据的实施问题。GUAN[4]针对跨境电子商务特点,基于大数据技术提出智能物流结构模型,为智慧物流建设提供思路。王智泓[5]基于大数据研究云物流模式,通过对比传统物流模式和云物流模式,剖析了云物流发展的困境和制约因素,给出了云物流发展的策略。程琳等[6]将大数据与共享相结合,提出物流信息的共享平台,实现多系统的无缝衔接和调用。姚源果等[7]分析实时路况大数据信息,以影响冷链物流配送的各项成本为基础建立配送路径优化模型,降低了冷链配送的成本,同时提高客户的满意度。孙炯宁等[8]设计舰船物流配送的路径选择流程和方法,减少了物流配送的时间和成本,有效提高配送的性能。王亚辉等[9]分析双向通航港口的船舶调度大数据,引入自适应蚁群调度优化算法,建立调度能力模型,以快速完成船只的调度。张人龙等[10]基于多粒度理论,提出大数据环境下的云物流资源配置模式,通过提高资源配置的效率和水平达到减少资源消耗的目标。赵龙飞等[11]挖掘分析AIS 大数据,通过构建大数据分析平台对电子围栏、航行事件、航次等进行分析,准确、精细地统计了海运数据。叶斌等[12]提出GA-BP 神经网络算法预测货运延迟,完善物流决策系统。
综上所述,大数据技术能够提高物流企业的数据管理水平和能力。然而,港口物流大数据类型丰富、数据量大、实时性强,对大数据管理提出了较高的要求,大数据的应用难度较大。聚类可以将大数据划分成相似度较高的多个簇,通过缩小大数据分析范围降低应用难度,便于大数据的准确描述和应用。DBSCAN 聚类算法具有速度快、效率高,能发现不规则形状簇等特点,但在用于大数据挖掘时搜索时间增长很快,聚类效率下降明显。本文基于Hadoop 平台的Map 和Reduce两个阶段,改进DBSCAN 密度聚类算法,分别设计快速DBSCAN 算法和聚类融合算法。在Map 阶段实现各数据块的聚类,在Reduce 阶段实现聚类结果的融合,以此来提高大数据聚类的效率。为进行港口物流大数据深度分析做准备,更好地发挥大数据的作用。
1 基于Hadoop 的密度聚类算法
港口物流大数据的来源主要有企业生产运作和管理的各类信息系统,这些数据具有独立存储和异构等特点。除此之外,大数据还包括操作日志、交易记录、音频、视频和地理位置等非结构化和半结构化数据。在港口快速增长的各类数据中,非结构化数据占比已达80%以上。港口物流大数据不仅来源广泛,而且结构类型复杂、缺乏自动处理能力。为此,应用港口物流大数据要以大数据技术为基础,对数据进行全面有效的分析。
Hadoop 是目前大数据处理的基础平台之一。由Common 模块、HDFS 模块、MapReduce 数据处理编程模块和Yarn 编程框架组成。HDFS 模块完成数据的存储、调取、管理和使用,MapReduce 模块完成计算功能。采用Hadoop 可以实现港口物流大数据的采集、存储、分析及应用。其中,大数据分析是最核心的功能。为了降低数据分析的范围和复杂度,基于Hadoop 改进DBSCAN 密度聚类算法。采用DBSCAN 算法聚类大数据时,随机选取核心点后,搜索核心点的密度可达点扩展聚类,再合并扩展聚类形成最终结果。随着初始聚类数量增多,合并时间也随之增长,合理选择核心点是提高DBSCAN 算法效率的途径之一。结合Hadoop 分布式处理的优势,改进的DBSCAN 算法将大数据分块,再对每个数据块分别进行快速密度聚类,在融合阶段对Map 阶段所有的聚类结果进行合并。
基于Hadoop 的密度聚类算法的思路为:首先,采用HDFS 分布式文件系统将数据分块。然后,定义熵值指导核心点选择,以此减少邻域搜索的数量,并将每个数据块分别在Map 上执行快速DBSCAN 密度聚类任务。最后,将结果发送至Reduce 融合,形成最终聚类结果写回HDFS。本算法要解决的重点问题主要包括核心点的选择、快速DBSCAN 密度聚类和Map 阶段聚类结果的融合。
1.1 核心点的选择
DBSCAN 算法根据ε和MinPts准则确定核心点,如果该点ε-邻域中包含的数据量大于等于MinPts,则为核心点。假设一个数据点分布在密度较大的区域,那么该点更有可能成为核心点。因此,选择核心点时可以考虑数据的密度分布情况,优先选择并判断密度较大区域的点是否为核心点。熵是描述系统混乱程度的概率值,熵值大小能够衡量数据分布的稀疏程度。数据xi的熵定义为
其中,dij为数据xi与数据xj之间的欧氏距离,i≠j,1≤i,j≤n。
由式(1)可知,密集区域数据的熵值较小,稀疏区域数据的熵值较大。如果选择熵值小的数据xi作为核心点,以该点形成ε-邻域所包含的数据点可能更多,得到待合并的邻域数量较少。同时,在合并ε-邻域扩展类时,任意两个邻域不同检查区域内的重复部分较少,形成初始聚类的速度较快。以熵值大小指导核心点选择的顺序,可以有效提高聚类的效率。
1.2 快速DBSCAN 密度聚类
在Map 阶段完成各数据块的快速DBSCAN 密度聚类,生成初始聚类结果。首先,在HDFS 中读取一个数据块,分别计算每个数据的熵。然后,依次选择熵值最小的数据xi,以其ε-邻域扩展聚类,直到不存在核心点为止。最后,基于密度可达准则,合并形成该数据块的初始聚类结果,将未分类的点暂时记为离群点。重复上述过程,直到所有数据块完成初始聚类为止。
在数据库D中,给定半径ε和最小数量阈值MinPts。数据xi的ε-邻域Nε(xi)定义为
其中,d(xi,xj)为xi和xj的欧式距离。
快速DBSCAN 密度聚类算法由核心点的ε-邻域扩展类簇,结合密度可达准则合并类簇。利用熵值衡量数据集在空间中的分布情况,优先选择熵值较大的核心点形成类簇,以减少邻域查询的数量来提高算法的效率。同时,结合DBSCAN 算法的基本思想对数据进行聚类。该算法具体步骤如下:
步骤1:读取HDFS 中的一个数据块,计算数据之间的欧式距离及每个数据的熵,并将数据按照熵值从小到大的顺序排列。
步骤2:选择当前熵值最小的数据xi作为候选点,计算xi的ε-邻域,若邻域内数据量大于或等于MinPts,则以xi和其ε-邻域形成一个类簇。在数据块中删除该类簇的数据,并将该数据xi存入Hadoop 缓存文件中。再重新选择下一个熵值最小的数据,重复上述过程,直到数据块中没有核心点剩余为止。
步骤3:由密度可达准则合并各类簇。如果两个类簇相交,但其交集中没有核心点,或者两个类簇不相交,则二者相互独立,否则合并这两个类簇。直到所有类簇合并完成为止,最终形成初始聚类。
步骤4:对于没有归入任何一个类簇的数据暂时记为离群点。
步骤5:重复步骤1 到步骤4,直到完成所有数据块的初始聚类为止。
快速DBSCAN 密度聚类算法描述如下:
算法1:快速DBSCAN 密度聚类算法
输入:数据集Di,邻域半径ε,最小阈值MinPts。
输出:初始聚类结果。
Begin
(1) HDFS 中的第i个数据块
(2) 计算其数据之间的欧式距离;
(3) 计算每一个数据xj的熵entropyxj;
(4) 按照熵值从小到大的顺序重新排列各数据;
(5) 选择熵值最小的数据xi,计算ε-邻域D′;
(6) 如果|D′|≥MinPts,则创建类簇将数据xi及其ε-邻域内所有数据归入其中;
(7) 否则重复步骤(5)和(6),继续创建类簇;
(8) 直到没有核心点为止;
(9) 合并由核心点形成的类簇;
(10) 如果类簇Cji和类簇Cqi彼此相交,并且交集中至少存在一个核心点;
(11) 那么合并这两个类簇;
(12) 重复步骤(10)和(11),直到没有类簇合并为止;
(13) 没有类簇标识的数据暂时归入离群点集合Oi;
(14) 重复步骤(1)到(13),直到所有数据块完成聚类为止;
(15) 输出初始聚类结果。
End.
1.3 聚类融合
Reduce 阶段实现Map 阶段形成初始聚类融合,是合并各个数据块初始聚类结果形成最终聚类的过程。聚类融合基于核心数据点的扩展类实现。在Reduce 模块完成聚类融合后,最终聚类将再写回HDFS。
假设数据集中某数据点xi为关于ε和MinPts的核心点,则该核心点xi的扩展类C(xi)定义为
其中,coreε(xi)为点xi的ε-邻域中核心点集合,o为邻域中某一个核心点。
算法2:聚类融合算法
输入:初始聚类集合C,离群点集合O,邻域半径ε,最小阈值MinPts。
输出:融合后的聚类结果。
Begin
(1) 任取C中的两个聚类和;
(2) 在Hadoop 缓存文件中获取两个簇和中所有核心点;
(3) 选取和中最近的两个核心点Pi和Pj;
(4) 计算扩展类C(Pi)和C(Pj);
(5) 如果C(Pi)和C(Pj)彼此相交,并且在交集中至少存在一个核心点,则合并C(Pi)和C(Pj)。
(6)更新待融合的聚类集合C;
(7) 重复步骤(1)到(6),直到没有初始聚类合并为止;
(8) 由ε和MinPts,计算O中所有的核心点;
(9) 以核心点的ε-邻域形成类簇;
(10) 根据密度可达准则合并形成最终聚类{C1,C2,…,Cs};
(11) 没有归入任何一个聚类的数据点则为离群点;
(12) 更新聚类结果,并输出最终聚类;
End.
2 实验与分析
为了验证改进密度聚类算法的效率和聚类结果的精度,基于Hadoop 平台的MapReduce api 实现快速DBSCAN 算法。数据集为美国zillow 房地产评估2017年房产数据,选取其中的经纬度信息进行聚类操作。数据经过预处理转换为txt 文档格式,并将程序打包为dbscan_rapid.jar 和dbscan.jar 文件后在腾讯云的轻量服务器上运行。
2.1 聚类效率分析
分别验证最小领域元素和距离阈值取不同值时,快速DBSCAN 算法的运行时间,数据集大小为10 000。首先,设置最小领域元素为30,不同距离阈值下DBSCAN 算法和本算法的运行时间如图1所示。

图1 不同距离阈值运行时间对比Fig.1 Comparison of running time with different distance thresholds
然后,设置距离阈值为20 000,不同最小领域元素下DBSCAN 算法和本算法的运行时间如图2所示。
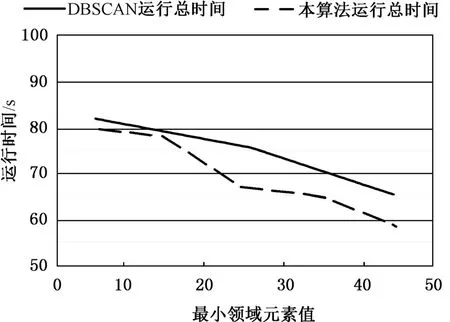
图2 不同最小领域元素运行时间对比Fig.2 Comparison of running time with different minimum domain elements
由此可见,两种算法的运行时间与距离阈值成正相关。同时,随着最小领域元素的增加先成负相关后成正相关。快速DBSCAN 算法在效率上有所提升。
2.2 聚类精度分析
首先,设置最小领域元素为30,验证快速DBSCAN 在不同距离阈值时聚类的个数。然后,设置距离阈值为20 000,验证该算法在不同最小领域元素取值时聚类的个数。数据集大小仍为10 000。运行结果如表1 所示。

表1 不同距离阈值和最小领域元素值聚类个数对比Tab.1 Comparison of the number of result clusters of different distance thresholds and minimum domain element values
由此可见,当最小领域元素固定时,快速DBSCAN 算法的聚类精度随着距离阈值的增加,呈现出先成正相关后成负相关。当距离阈值固定时,快速DBSCAN 算法的聚类精度随着最小领域元素的增加先成正相关后成负相关。
3 结论
应用大数据技术可以提升港口企业的数据管理水平,驱动港口业务的转型升级,辅助企业的决策制定。实施港口大数据聚类,能够提高大数据应用的有效性。本文基于Hadoop 平台提出快速DBSCAN 密度聚类算法,在Map 阶段以数据分布情况指导形成初始聚类,在Reduce 阶段以核心点扩展类融合最终聚类结果,该算法提高了聚类的效率,为快速、高效地分析港口物流大数据奠定了基础。
同时,现代港口企业进行大数据应用时,还需要建立健全大数据应用制度,保障大数据的高效使用。建立数据运营中心、数据分析中心和数据共享中心,让港口数据在企业内部、外部充分流通和共享,保障大数据应用的平稳运行。明确大数据管理部门和监管部门的职责分工,支持港口大数据应用的高质量发展。
