基于改进K-均值聚类算法的汽车用户行为分析方法研究
2023-06-16毋丽丽裴春琴郝耀军刘文远
王 健,毋丽丽,裴春琴,郝耀军,刘文远
(1.忻州师范学院 计算机系,山西 忻州 034000;2.燕山大学 信息科学与工程学院,河北 秦皇岛 066004)
0 引言
互联网和大数据的出现,可以有效提高各类数据的获取能力[1]。汽车作为现代家庭中必备的第二生活空间,同样记录了大量的数据,通过对车联网数据的分析,可以总结出汽车用户的驾驶习惯、出行日常、线路选择等[2]。根据车辆数据反映出来的车辆状态和用户的操作状态,可以提前感知危险因素,及时对相关问题进行对症处理,保障用户生命财产安全[3]。
汽车用户的行为和操作习惯等对于道路交通安全具有重要的意义,大量的转弯、加速、变道等行为均会对车辆状态造成影响,也会使得车辆驾驶风险大大提高[4]。利用算法分析车联网数据,对于车辆驾驶行为的辨识具有重要研究意义,国内外研究人员在相关方面也做了大量的研究工作。Mohamad 等[5]对车辆异常驾驶行为等进行了分析,利用GPS 数据构建异常行为检测系统,根据车辆的车速和位置状态的变化对异常驾驶行为进行辨识,取得了不错的效果,但是该方法对于驾驶人员的状态分析不够全面。Zoran 等[6]通过聚类分析的方法,对驾驶员风险倾向性进行了分类研究,采用主成分分析结合聚类研究的手段,对车辆的GPS 数据进行分析,利用模型对驾驶风险识别,该方法的主要问题在于模型的分类效率较低。朱冰等[7]同样通过聚类分析的研究方法,对车辆安全性展开研究,通过对不同逻辑场景的驾驶行为进行特征分析,对其安全性展开评价,并进行了实验验证。该方法以自动驾驶汽车作为研究对象,缺乏对于用户行为以及样本不平衡问题的考虑。
基于上述问题,本文对汽车用户的行为进行分析,利用聚类分析的方法,构建驾驶行为、数据和风险的关系理论,对用户行为的驾驶风险进行有效辨识。利用改进K-均值聚类算法实现驾驶风险的聚类分级,结合极端梯度提升(eXtreme Gradient Boosting,XGBoost)算法快速实现对风险等级的辨识,然后通过与其他算法对比,证明本文算法的有效性和优越性。准确辨识用户驾驶风险等级,对于优化用户的驾驶行为,提高车辆行驶安全性,具有重要的意义。
1 行为数据分析
1.1 K-均值聚类算法
聚类分析方法是数据挖掘的一种方式,通过无监督的数据学习,将研究的内容和对象进行分类、分组统计,从而将具有相同特征的数据归为一类,形成多个聚类类型,进而根据数据行为进行划分,得到归类的结果[8]。最典型的聚类分析方法为K-均值聚类分析方法。
K-均值聚类算法主要步骤为:
1) 假设整个样本集的数据量为n,随机选择数据初始聚类中心个数为K个;
2) 对各个样本计算其与初始聚类中心之间的欧式距离;
3) 计算误差平方和函数Jc;
4) 计算Jc在两次迭代的距离是否小于设定阈值,若小于则算法结束,否则继续迭代,对聚类中心进行计算,得到新的K个聚类中心;
5) 返回步骤(2),直至误差平方和函数Jc为最小,或符合中止条件。
1.2 SOM 神经网络
自组织映射(Self-organizing map, SOM)网络是一种神经网络算法,通过对输入到空间中数据的自学,将高维数据映射到低维空间,属于一种数据降维的算法[9]。SOM 神经网络属于一种无监督的人工神经网络,主要包括输入层和竞争层,其竞争层内的神经元存在侧向连接,通过不断的训练和权值优化实现聚类分析,并通过近邻函数关系来维持整个网络的拓扑结构[10]。该算法可以用于模式识别领域内数据样本的自动聚类,从而有效识别事物的内部关联。
SOM 神经网络竞争层的权重调整规则主要为胜者为王规则,具体步骤为:
1) 归一化。对输入到网络中的样本数据经过数据筛选后进行归一化,同时对其权值向量构成的矩阵进行归一化。
2) 判断获胜节点。当有样本输入到网络中时,将输入样本与竞争层节点的权值向量进行对比,选择相似性最大的权重向量为获胜方。
3) 权值调整和网络输出。获胜节点对权值进行优化,获胜方的神经元输出为1,表达式为
1.3 基于SOM 神经网络改进的K-均值聚类算法
考虑到SOM 神经网络在迭代过程中会出现钟摆效应,需要对算法进行适当优化,通过遗忘第二名的规则,可以有效改善相关问题。
算法权值优化的过程为:
设算法输入向量为X,SOM 神经网络竞争层中存在有k个输出神经元,则其中第j个输出神经元的权值向量可以表示为
输入向量的最佳匹配节点为与X具有最高相似度的竞争层节点,用w∗表示,则存在
式中,S表示欧氏距离,p为输入向量的维数。
引入遗忘第二名的调整规则,则系数μj可以表示为
式中,c为代表最佳匹配的获胜节点,r为第二名匹配节点。
算法的处理需要引入样本密度d(xi),其定义式为
当算法的学习率a远大于遗忘率b时,神经网络在迭代过程中,权值可以通过下式对获胜节点c和匹配节点r进行处理:
通过遗忘第二名的处理方式,可以有效提高获胜神经元的竞争优势,有效降低SOM 神经网络算法的迭代钟摆效应,在汽车用户样本区别较小的情况下,能够有效进行差异化处理,充分反映样本的分布特征。
结合SOM 神经网络算法的改进K-均值聚类算法的具体流程图如图1 所示。
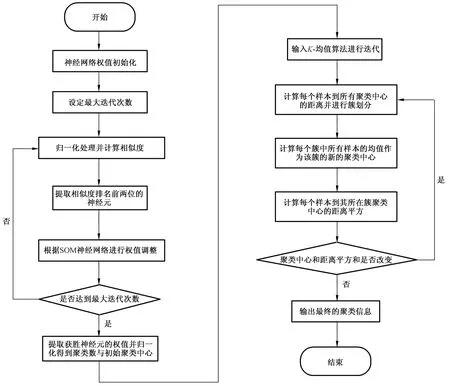
图1 改进K-均值聚类算法的流程图Fig.1 Flow chart of improved K-means clustering algorithm
在图1 表示的算法中,SOM 神经网络算法的时间复杂度可表示为O(l×m×(p×k+k2+k×n)),其中p为输入向量的维数,k为竞争层的节点数,n为输出向量的维数,m为样本数,l为迭代次数。K-均值聚类算法的时间复杂度可表示为O(t×m×n),其中t表示K-均值聚类算法的迭代次数。因此,图1 中的算法复杂度可综合表示为O(l×m×k2)。
1.4 基于XGBoost 算法的驾驶行为风险辨识模型
对于汽车用户来说,其驾驶行为各不相同,对于驾驶的操作习惯、激进程度等均存在较大的不平衡,XGBoost 算法[11]能够对驾驶员在车辆行驶过程中的驾驶行为和驾驶风险作出及时判断。
设原始数据集为D= {(xi,yi):xi∊Rm,yi∊R},数据集中包含驾驶行程n个,驾驶风险行为特征m个,xi为第i个行程样本,对应的驾驶风险等级为yi。
假设算法中集成的决策树为k棵,则其预测结果可以表示为
式中,fk(xi)为对应第k棵决策树和第i个行程样本的预测分数,F为集成分类器,fk∈F。则XGBoost 算法的损失函数可以表示为
式中,s为算法的误差函数,Z为对应正则化项。
算法经过t次迭代之后,设对应第i个样本的预测结果为,算法增量函数用ft来表示,则有
将式(9)通过二阶泰勒函数展开,忽略其中常数项,进而优化损失函数,得到第j片叶子的最优权重和目标函数的最优值:
利用网格搜索的方法实现模型的参数优化,有利于获得算法最优解,并通过采用十折交叉验证的方法来保证能够获得全局最优的参数组合,实现用户驾驶风险行为的辨识[12]。
在XGBoost 算法中,假定td表示树的最大深度,tn表示树的总个数,‖x‖0表示特征列非缺失项数之和,m表示样本数,XGBoost 算法的时间复杂度可表示为O(tn×td×‖x‖0×logm)。
2 实验结果
2.1 实验数据处理
实验所采用的数据为国外某公司的70 名驾驶员的车联网数据,在每位测试人员的车辆上搭载了设备终端,用于检测车辆及驾驶员的数据和信息。监测时间共计1 个月,获取到的数据信息600 多万条。
收集到的信息包括车辆行驶状态信息、用户的驾驶习惯、车辆变加速行为等多方面的信息,考虑到本研究是关于用户驾驶安全行为的分析角度,对数据进行精简和清洗处理,最终选择的数据内容包括[13]:
1) 行驶信息
相关的数据信息主要包括:车辆行驶里程、整车怠速时长、车辆夜间驾驶时长以及发动机高负荷比例等行驶状态信息。
2) 车速信息
车速信息中关于驾驶安全行为的数据主要包括:车辆超速的平均速度、超速平均里程、最大超速速度和车速标准差等反映车速波动的数据信息。
3) 行驶加速度
加速度中可以有效反映用户安全行为的信息主要包括:平均加速度及其标准差、平均负加速度及其标准差、急加速频率、急加速的里程和时间、急刹车频率等。
4) 不良驾驶习惯
在不良驾驶习惯方面的相关数据主要包括:车辆最大油门次数、车辆急转弯次数、单位里程空挡滑行情况、低档高速里程等影响安全性的数据。
2.2 聚类分析结果
利用改进K-均值聚类算法进行汽车用户行为的聚类分析,其聚类分析的结果与K值具有重要的关系,K值的设定受人为干预过多,因此需要综合考虑不同K值情况下的聚类效果[14]。分别考虑将样本数据分成2 类(高风险、低风险)、3 类(高风险、中风险、低风险)和4 类(高风险、中风险、较低风险、低风险)等多种情况下的效果,最终得到不同K值下的聚类结果如表1 所示(以行驶里程数据为例)。

表1 不同K 值的行驶里程聚类结果Tab.1 Clustering results of mileage with different K values %
由表1 的结果可知,对于不同的K值,聚类后的结果存在明显的差异,数据分类的界限也发生明显变化。对于K值为2 的情况,由于行驶里程的数量发生较大变化,划分的界限并不明显,产生较多的数据误判情况;当K值为3 时,数据的划分更为清晰,行驶里程的差距也逐渐缩小;当K值为4 的时候,行驶里程的差距进一步缩小,但是交界处的联结增多,界限反而变得模糊不清。于是可知K为3 时,聚类效果更好。
利用轮廓系数来衡量聚类的效果,综合考虑内聚度和分离度两种影响因素,样本i的轮廓系数S可以用公式表示为
式中,i∈ [-1,1],α和β分别为样本点i与组内其他样本点的平均距离和与其他组外样本点的平均距离。轮廓系数S越接近1 越好,得到结果如表2所示。

表2 不同K 值情况下的轮廓系数STab.2 Silhouette coefficient S under different K values
由表2 的结果可知,K值为3 时,距离分析的效果更明显,界限更清楚。
为了验证优化后的SOM 算法效果,比较遗忘第二名算法的效果,对经典SOM 算法和改进后遗忘第二名算法的收敛速度进行对比,选择3 组行驶里程数据进行对比。对比结果如表3 所示。

表3 收敛的迭代次数Tab.3 The number of iterations to converge次
从表3 的结果可以看到,本研究采用的遗忘第二名的算法策略,能够有效提高模型收敛速度,有效克服经典SOM 算法在迭代过程中的钟摆效应,提高算法的计算效率。
2.3 XGBoost 算法风险辨识
根据聚类分析结果和前文收集的风险驾驶行为特征数据,建立XGBoost 算法的汽车用户行为模型如图2 所示。
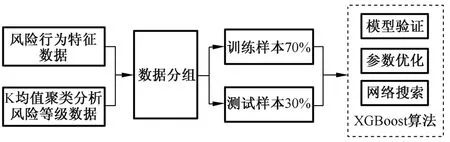
图2 XGBoost 算法模型Fig.2 XGBoost algorithm model
初始样本数据主要包括综合风险驾驶行为和上一节得到的驾驶风险等级标签,其中驾驶风险等级对应于聚类分析结果中数据所在的类。共获得样本数量为6 430 个,其中4 711 个样本用于训练,占总比例的70%,其他30%作为测试样本,用于后续测试。
XGBoost 算法的参数配置主要包括:弱分类器选择gbtree,弱分类器数量N为118 个,采样比例为0.35,学习率0.30,最大深度为2,最小损失函数1.3,随机种子数量为420。
根据风险辨识模型,将用户风险行为作为数据特征输入模型,数据标签作为驾驶风险等级,分别在训练集和测试集上进行十折交叉验证对比实验。每次实验将数据集分成10 份,轮流取9 份作训练集,剩下1 份作测试集,取10 次结果的平均值,估计算法的精度,从而有效降低模型的偶然误差,避免出现模型过拟合,提高模型可靠度。
改变弱分类器的数量N,比较模型在不同样本集中的表现,结果如图3 所示。

图3 弱分类器的数量N 对计算精度的影响Fig.3 The influence of the number N of weak classifiers on the computational accuracy
图3 表明,随着弱分类器的数量N的增大,模型的计算精度迅速上升,当N的值约为50 时,模型达到收敛,精度达到最高,之后精度基本保持平稳。且该结果在训练集、测试集以及十折交叉验证数据集中的效果完全一致,训练集上的精度更高,证明该模型对于用户行为的辨识方面具有不错的效果。将本研究模型与其他传统集成模型进行对比,利用sklearn 库函数对各个算法进行分析,比较本文算法与决策树算法、随机森林算法和K近邻算法的学习曲线。具体结果如图4 所示。

图4 不同算法的学习曲线情况Fig.4 Learning curves of different algorithms
从图4 的学习曲线结果可以看到,在拟合效果方面,各算法之间具有较大的差异。但是模型的收敛性均随着样本的增加而趋于稳定。数据结果得分方面,本文的XGBoost 算法和随机森林算法的效果更好,在训练集的学习表现和测试集的性能表现方面差距较小,表现稳定。在样本数量超过3 500 后,两种算法均取得良好的拟合效果,测试集的性能也更能稳定。而决策树算法在测试集和样本集的表现差距明显,缺乏稳定的表现。K近邻算法则是精度上表现较差的模型。综合考虑学习表现和预测精度方面,本文的XGBoost 算法更胜一筹。
为了可以量化对比4 种模型在辨识性能上的表现,通过一系列评价指标来对这些模型的性能进行量化评价,查准率(p)、召回率(r)、F1 值(F1)分别为[15]
其中,nTP为正样本被正确识别的数量,nFP为误报的负样本数量,nTN为负样本被正确识别的数量,nFN为漏报的正样本数量。
kappa 系数(ε)的表示式为
式中,p0为模型观测一致率,pe为对应模型预测一致率。
利用前文4 种算法对样本数据进行测试,比较其对于车辆驾驶人员的风险行为等级辨识结果如表4 所示。
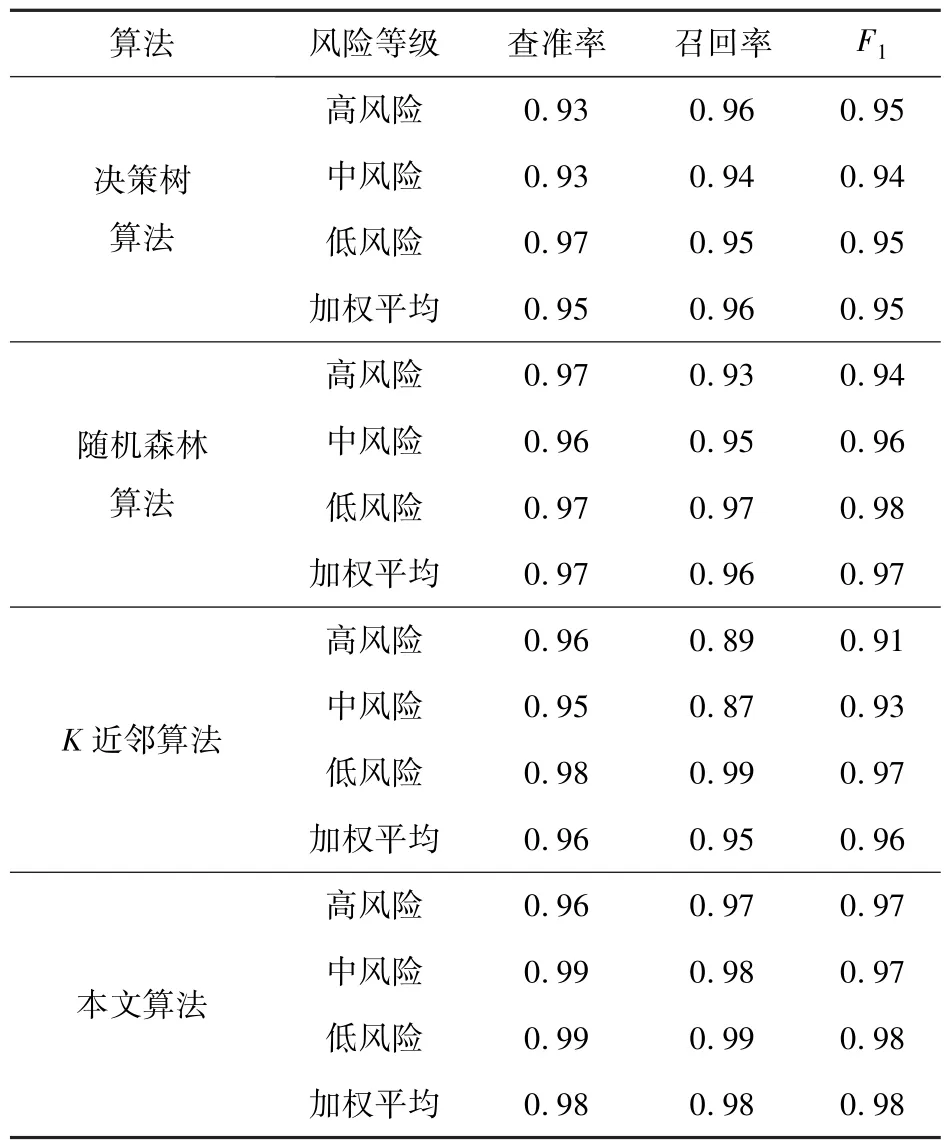
表4 不同算法的评分对比Tab.4 Score comparison of different algorithms
从表4 的结果中可以看到,4 种算法在查准率方面的表现良好,均超过95%,但本文模型的查准率更高,达到98%。召回率方面,本文算法同样达到98%,也超过其他3 种模型算法。F1 值方面同样最高,证明本文算法在模型辨识方面的有效性和精确性。在kappa 系数方面,决策树算法为0.91,随机森林算法为0.94,K近邻算法为0.92,而本文模型为0.97,比其他几个模型更接近于1,证明该模型的辨识精度更高,适合用于用户驾驶行为的辨识。
3 结论
本文提出了一种基于遗忘第二名的SOM 神经网络改进的K-均值聚类算法及XGBoost 风险辨识模型,对汽车用户的驾驶行为分析,主要是对其存在驾驶风险情况进行辨识。有效地解决了K-均值算法在对用户行为进行分析时,需要提前设定聚类数目、聚类精确度低、收敛速度慢的缺陷。综合考虑驾驶人员的状态,通过处理后的实验数据,对XGBoost 风险辨识模型进行验证,表明该模型的辨识精度更高,适合用于用户驾驶行为的辨识。该模型在驾驶用户的行驶安全、车辆监控方面具有重要的参考价值。
