结合预训练和自训练的法律信息抽取增强式方法
2023-06-16周裕林陈艳平黄瑞章秦永彬
周裕林,陈艳平,黄瑞章,秦永彬,∗,林 川
(1.公共大数据国家重点实验室,贵州 贵阳 550025;2.贵州大学 计算机科学与技术学院,贵州 贵阳 550025)
0 引言
随着“智慧法院”的建设,法律人工智能辅助任务受到日益的关注,其中法律信息抽取作为法律人工智能的第一步,直接用于支撑下游任务,如知识图谱构建、相似案例推荐、自动量刑建议等。法律信息抽取结果的不同,将会对下游任务产生不同的影响,直接影响下游任务的性能。深度学习作为法律人工智能任务中主流的方法,其训练法律人工智能任务模型往往需要标签数据,而法律文本数据人工标注成本较高。因此,在法律人工智能任务里,只有少量学习样本会导致模型学习性能较差。
为了解决标注数据样本少和数据标注成本高的问题,在图像处理[1]领域最先有学者提出自训练(Self-training,ST)[2]的方法。自训练是一种半监督学习方法,它利用有标签数据训练出一个教师模型,让教师模型对无标签数据生成伪标签,来达到数据增强的效果。其中,伪标签是指利用自训练模型对无标签数据进行预测得到的非真实标签。由于法律文本的特殊性,选择不同案由的法律文本作为无标签数据进行自训练,所带来的差异性将会对法律信息抽取产生影响,使得模型对法律文本特征理解上产生差异,从而影响法律文本信息识别性能。尽管在如何选择无标签数据文本上提出了各种解决方案,如计算文本相似度、聚类等,但由于法律文本的特殊性,在选择无标签法律文本上仍存在不足。通过分析发现,主流的信息抽取技术存在少样本学习困难、数据增强技术中无标签数据选择不恰当的问题,使得模型在少样本法律文本信息抽取上性能较差。
因而,面向信息抽取技术存在少样本学习困难、数据增强技术中无标签数据选择不恰当的特点,本文提出了结合预训练和自训练的法律信息抽取增强式模型,在2021 法研杯提供的法律信息抽取数据集上进行验证。实验表明了本文提出方法的有效性。本文的主要贡献如下:
1) 本文结合预训练和自训练的方法,通过利用无标签法律文本生成伪标签数据,增强了模型在少样本学习上的能力,实现法律信息的更好抽取。
2) 在充分分析法律文本特点的基础上,改进文本相似度函数以选择出更符合训练集的无标签法律文本数据,以提高模型特征学习能力。
3) 本文结合预训练和自训练方法首次应用于法律人工智能任务,为法律人工智能任务少样本学习提供了一种新思路。
1 相关工作
目前,信息抽取主流的方法是基于深度神经网络的有监督学习模型。然而,有监督学习模型需要大量的标签数据,而法律文本通过人工标注成本较高,存在法律人工智能标签数据较少的问题。
Yao 等[3]提出基于先验知识的图少样本学习。Zhang 等[4]提出基于图卷积神经网络的清洁web图片和原始训练图片的少样本学习方法。Bao等[5]探索了对于少样本下文本分类的原学习的应用。Tseng 等[6]利用Affine Transform 去增强图片特征。Peng 等[7]提出基于预训练-预训练-微调的方法应用于人物对话系统。
随着大规模预训练模型BERT[8]的诞生,出现了许多BERT 预训练模型的改进版,并且在小样本学习上也取得了不错的成绩。Liu 等[9]通过对BERT 进行优化,将原本静态遮蔽改为动态遮蔽,丢弃了下一句预测任务,使用了更大的批量和替换了文本的编码方式,提出了一个新的预训练模型RoBERT。Sun 等[10]通过知识整合增强表示来优化BERT 的遮蔽过程。Yang 等[11]认为现有的BERT 预训练模型会遭受微调阶段所带来的差异性,因此对原有的预训练模型进行修改,得到一个新的预训练模型XLNet。Lan 等[12]提出一个改进的预训练模型ALBERT 来解决内存消耗高和训练速度慢的问题。Clark 等[13]通过采用类似于生成对抗式网络中的生成器与判别器,在微调阶段仅使用判别器的方法推出预训练模型ELECTRA。Cui 等[14]利用以前的预训练模型,在遮蔽层进行修改,得到MacBERT。Cui 等[15]在BERT 基础上提出基于全词遮罩的BERT-wwm。Cui 等[16]提出一种基于乱序的预训练模型PERT,将掩码标记去除的情况下学习文本语义信息。
尽管大规模预训练模型在小样本上取得了不错得效果,但还存在以下不足:大规模预训练模型使用的是各个领域数据,在对法律人工智能任务中使用小样本进行微调时,由于学习样本较少,所获得的微调效果较差,导致下游任务性能不佳。因此,自训练方法被广泛应用于小样本任务上。Zoph 等[17]在图像处理领域重新探讨了自训练和预训练的作用。Niu 等[18]将自训练方法应用于机器阅读理解任务的软证据抽取,以解决成本昂贵问题。Xie 等[19]通过使用自训练为学生模型加入噪声以提高图像分类的性能。Meng 等[20]通过将远程监督和自训练方法结合起来用于命名实体识别任务以提高模型的泛化能力。
2 法律信息抽取模型
2.1 BERT 预训练模型
BERT 预训练模型区别与传统的word2vec 模型,它在Transformer[21]的基础上,用Transformer 去捕获文本特征,并利用大量数据进行一个先学习,然后再代入到某个任务微调即可。随着硬件的不断发展,Transformer 的层数从12 层到24 层,导致模型的参数越来越大,其学习特征的能力也越来越强,成就了现在的大规模预训练模型。研究证明,其文本提取特征能力远超于卷积神经网络和循环神经网络等模型。
Transformer 完全依赖于自注意力机制。自注意力从每个输入的词向量与训练后的矩阵Wq、Wk和Wv相乘所得Query、Key 和Value 向量,并将个矩阵向量分别合成矩阵,得到注意力公式如下:
式中:Q、K、V分别为Query、Key 和Value 组成的矩阵;d为Query 向量的维度,在式中除以可以使得模型在训练过程中的梯度下降的更平稳。最后,利用softmax 函数进行归一化得到每个单词的得分,使得编码器对不同得分的单词有不同的关注度。
在Transformer 的基础上,BERT 预训练模型使用了遮蔽层语言模型,采用随机遮蔽一定比例的单词,通过预测被遮蔽的单词进行训练。并且BERT 输入的Embedding 由三个Embedding 拼接而成,分别为Token Embedding、 Segment Embedding 和Position Embedding,融合了字符信息、句子信息和位置信息,最终将拼接而成的Embedding 输入到BERT 编码器中获得输出隐藏层特征。由于预训练模型并不是本文的重点,所以在这不作过多阐述。
2.2 自训练模型
自训练模型的结构图如图1 所示。本文将自训练模型分为4 个步骤。首先,利用标签数据集结合预训练BERT 模型训练出一个教师模型,此教师模型用于后续的伪标签预测;接着,利用改进的文本相似度函数从法律文书库中寻找与训练集相似的无标签法律文书数据;然后,无标签数据集送入教师模型中生成伪标签,并从伪标签数据集中选择前K个样本与标签数据集混合;最后,将混合的数据集重新训练得到一个学生模型用于下游任务。
本文自训练的方法依赖于大规模无标签的法律文书库。由于法律文书包含许多案由,而不同案由之间内容差异较大,例如,民事案件和刑事案件在法律文书中书写及内容差异较大,利用不同的文本相似度搜寻与原本训练集中相似的法律文本存在困难。因此,如何从各种案由的法律文书库中搜寻到与训练集相似的法律文书成为本文研究的重点。本文考虑了欧氏距离和余弦距离来计算相似案由的文本:
式中,x和y分别两个文本向量。使用不同的文本相似度函数计算会得到不同的结果。例如:欧氏距离更能体现个体数值特征间的绝对差异;余弦距离更多的是从方向上区分差异。由于法律案情错综复杂,使用普通的文本相似度函数在不同案由上有较大的差异性。而欧式距离和余弦距离因为其特点,分别在不同法律案由上存在着优势与劣势。因此,我们在结合欧氏距离和余弦距离的基础上,引入一个共现因子α:
式中,w1和w2是两个文本分词结果列表。α∈[0,1]表示为两个文本间的共现因子。
通过对文本相似度函数引入共现因子能够更好地捕捉两个文本间的共现度,从而提高在搜寻最相似于训练集的无标签数据的能力,增强模型在自训练过程中数据特征的学习能力。最后,通过合并公式(2)~(4),获得一个改进的文本相似度函数:
将法律文书库中无标签数据与训练集数据计算文本相似度取平均:
3 实验
3.1 数据集
实验所用数据均来自中国最高人民法院举办的第四届“中国法研杯”司法人工智能挑战赛(CAIL 2021)。数据样本详细信息如表1 所示。标签类别分为10 类,包括犯罪嫌疑人(NHCS)、受害人(NHVI)、 作案工具(NATS)、 被盗物品(NASI)、被盗货币(NCSM)、物品价值(NCGV)、盗窃获利(NCSP)、时间(NT)、地点(NS)、组织机构(NO)。

表1 数据集样本数量和标签数量统计信息Tab.1 Statistical information on the number of samples and the number of labels in the data set
3.2 评测指标
实验指标均采用精准率P、召回率R和F1值。公式如下:
式中,NTP为把正类预测为正类的数量,NFP为把负类预测为正类的数量,NFN为把正类预测为负类的数量。
3.3 参数设置
模型超参数设置的不同对实验结果会产生较大的影响。超参数设置如表2 所示。

表2 超参数设置Tab.2 Hyperparameter settings
3.4 实验结果及分析
为验证结合预训练和自训练模型的法律信息抽取增强式方法的有效性,本文利用基线模型BERT 与BERT+ST 的方法作实验对比,如表3所示。
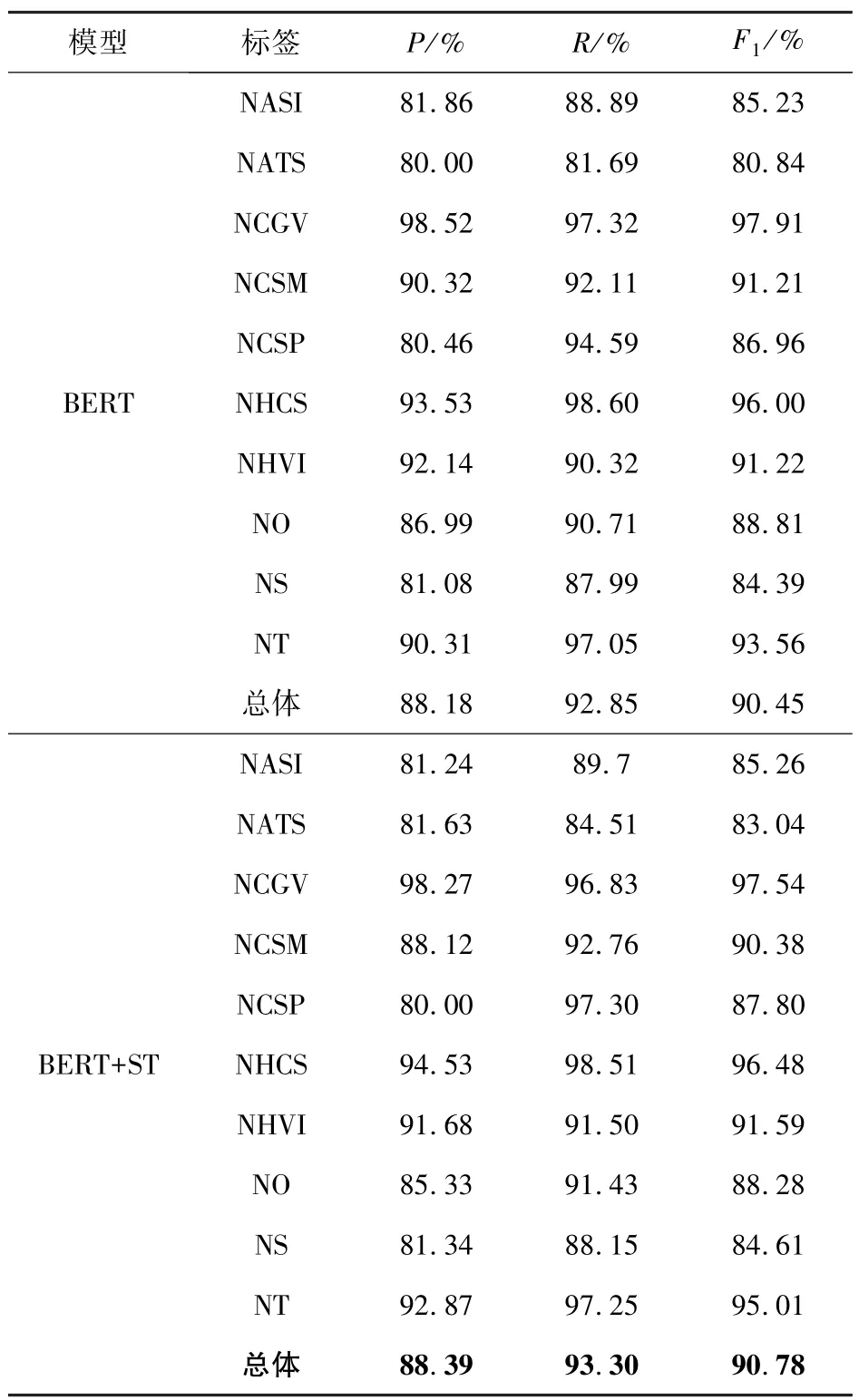
表3 结合预训练和自训练模型与基线模型的实验结果Tab.3 Experimental results of combining pre-trained and self-trained models with baseline models
从表3 可以看出,在BERT 预训练模型的基础上,结合自训练方法,可以有效地提高法律人工智能任务标签数据较少情况下的性能。具体为,训练集里标签数据最少的NATS 和NCSP 结合自训练方法后,F1值分别提高了2.2%和0.84%;总体上提高了0.33%。其原因在于:1)法律数据标签少的情况下,模型对标签数据特征识别不充分,导致对个别数量较少的标签识别性能较差。2)结合自训练方法后,通过半监督的方式来扩展标签数量,增强模型识别少样本标签数据的特征。
由于自训练的方法为数据集中较少的标签类别,通过半监督的方式进行数据扩充,增强了模型学习标签类别特征的能力。通过实验分析发现,本文所提方法也加速了模型损失函数收敛的速度,如图2 所示。原因在于:扩充的实体类别的同时增强了模型对实体类别数量较少的数据特征的学习能力,学习特征能力的增强导致模型损失函数收敛速度加快。

图2 损失函数迭代收敛变化图Fig.2 Loss iteration convergence diagram
在实验分析过程中发现,不同的预训练模型与自训练方法结合起来会有差异性。为验证不同预训练模型和自训练方法结合带来的差异性,本文选取了BERT、 BERT-wwm、 Roberta、 Macbert、PERT 预训练模型作实验对比,如表4 所示。
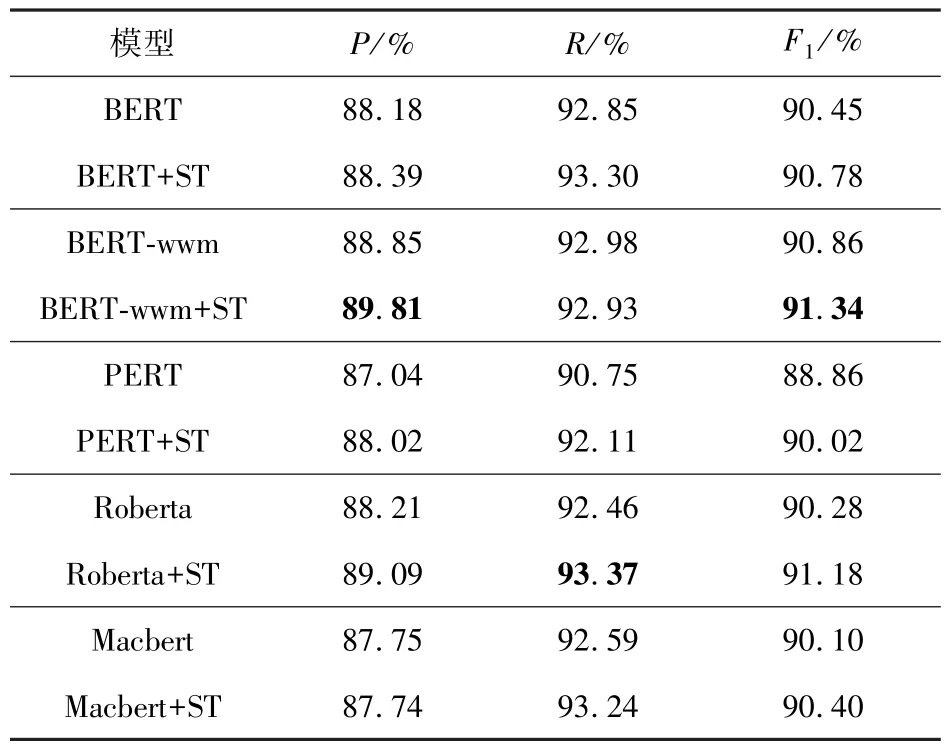
表4 不同预训练模型实验对比Tab.4 Experimental comparison of different pre-trained models
从表4 可以看出,结合自训练方法后,不同的预训练模型在法律信息抽取任务上F1值都获得了提高。BERT、 BERT-wwm、 PERT、 Roberta 和Macbert 分别提高了0.33%、0.48%、1.16%、0.9%和0.3%。在BERT-wwm 上获得最高性能,原因在于通过利用全词遮蔽(Whole Word Masking,wwm)来进一步提高了BERT 的性能;在PERT 上获得最高提升。其中,Roberta 和Macbert 等均为近年来超大规模预训练模型,在结合了自训练方法后都得到不同程度的提升,由此验证了本文方法的有效性。
由于本文的方法旨在解决法律人工智能任务中小样本问题,本文将训练集按10%、20%、40%和80%的比例划分,观察在训练集样本少的情况下,结合预训练模型和自训练方法在法律信息抽取上的变化过程,测试集保持不变。根据表4 中不同预训练模型带来的差异性,选取性能最高的BERT-wwm 作为基线模型进行对比,如表5 所示。
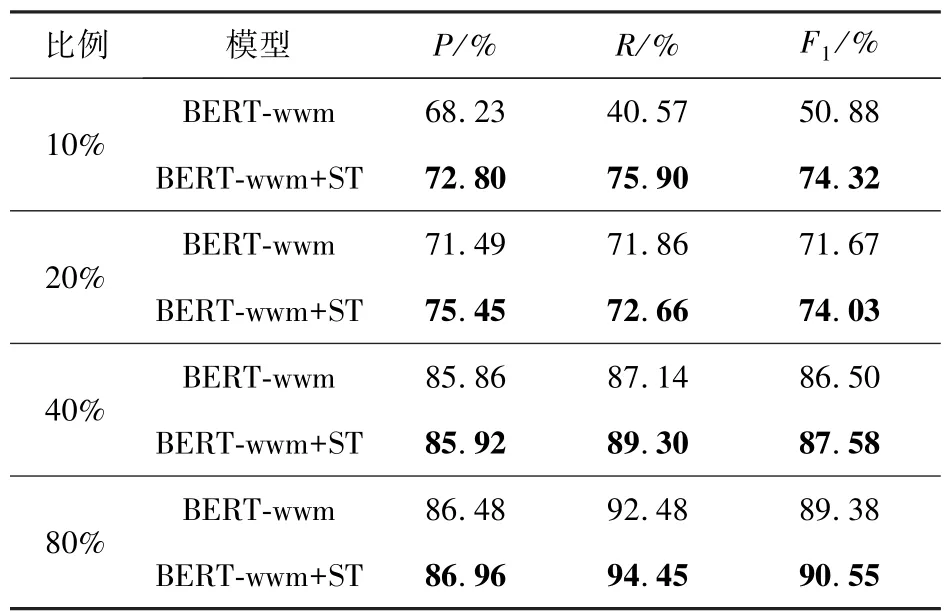
表5 结合预训练和自训练在不同比例训练集下的性能变化Tab.5 Performance variation for combining pre-training and self-training with different scaled training sets
从表5 可以看出,在训练集样本特别少的情况下,结合自训练的方法后,其性能获得了较大的提升,在训练集样本数只有10%的情况下结合自训练的方法F1值提升了23.44%。但随着数据集的增大,自训练的方法提升效果逐渐减缓。在训练集20%、40%和80%的情况下结合自训练方法F1值分别提高了2.36%、1.08%和1.17%。其原因在于:1)数据样本特别少的情况下,通过BERT预训练模型进行微调,模型不能充分学习数据特征。结合自训练方法后,尽管在生成伪标签同时增加了噪声,但更多的数据能增强模型特征的学习,并且噪声也能提高模型的鲁棒性[18]。2)BERT已经是通过海量的数据所预训练出的模型,其语言表征学习已经很强大。在数据样本较为充足的情况下,只需通过微调即可获得优异的性能,其性能并不会随着数据量的递增而递增。以上实验结果证明,在小样本情况下,结合预训练和自训练的方法会获得较大的提升。
为验证在结合自训练方法时,需要从法律文书库中挑选出合适的无标签数据而改进的文本相似度函数的有效性。本文将改进的文本相似度函数与随机选择、余弦相似度函数等作对比实验,验证本文提出改进的文本相似度函数的有效性。如表6 所示。所选用预训练模型均为BERT-wwm。

表6 无标签数据选择函数实验对比Tab.6 Experimental comparison of unlabelled data selection functions
从表6 可以看出,本文改进的文本相似度函数相比于随机选择来说提高了0.32%,比余弦距离提高了0.1%。其原因在于:1)案由的种类众多,选择不同案由的法律文书对法律信息抽取会产生一定影响。2)本文方法在普通文本相似度计算函数的基础上加入共现因子,能够更好地寻找出与训练集相似的法律文书进行自训练,同时也能减少噪声。
最后,为验证本文提出方法的通用性,本文在公共数据集MSRA 上进行实验验证,如表7 所示,实体标签有地名(LOC)、组织机构(ORG)、人名(PER)。在基线模型的基础上,本文提出的方法在MSRA 数据集上F1值提高了0.24%,由此验证了本文方法的有效性。

表7 通用性实验验证结果Tab.7 The results of universal experiment were verified
4 结论
本文的工作主要有:1)针对法律信息抽取任务中人工标注成本昂贵问题,结合预训练和自训练的方法可以增强模型在小样本数据集下的识别性能。2)改进文本相似度函数,提高从法律文书库中搜寻与训练集相似的法律文书,从而增强自训练学习的能力。实验结果表明,本文结合预训练和自训练的法律信息抽取增强式方法能够提高模型在小样本数据集上的学习。
