基于强化学习的算力资源度量方法
2023-06-16夏天豪夏长清
夏天豪,夏长清,潘 昊,许 驰,金 曦
(1.沈阳化工大学 信息工程学院,辽宁 沈阳 110142;2.中国科学院 网络化控制系统重点实验室,辽宁 沈阳 110016;3.中国科学院 沈阳自动化研究所,辽宁 沈阳 110016;4.中国科学院 机器人与智能制造创新研究院,辽宁 沈阳 110169)
0 引言
工业互联网下的生产模式呈现大规模、定制化、高精度等特征,联网设备的指数级增加以及数据的碎片化、零散化导致云为中心[1]的生产系统处理能力捉襟见肘[2]。工业边缘计算通过在系统边缘侧接入具有一定计算能力的边缘服务器实现了实时任务的就近处理,在降低网络负载的同时提高了响应速度[3],文献[4]是解决这一问题的有效途径。然而,现有工业模式中任务类型多、节点性能异构,缺乏有效的算力度量调度方法,系统难以快速、精准地为实时任务按需提供算力服务,系统性能无法保障。
1 相关工作
在大数据时代的当下,各行各业对算力的需求日益高涨,如何灵活调度分配算力资源显得格外重要,尤其在边缘计算中通过算力度量实现资源最优化已成为目前研究的热点问题[5]。为了提高系统资源利用率、解决现存工业生产模式中的问题,已有许多学者展开了对资源需求量化方法的研究,Wang 等[6]使用指数平滑的方法对到达任务进行预测,根据系统中的历史任务序列预测未来任务的到达时间、执行时间和任务大小。Frank等[7]通过结合线性回归和高斯过程,建立了关于特征参数和执行时间的模型,根据任务需求的历史资源信息,使用时间序列方法来预测接下来的任务资源需求大小。Qiu 等[8]采用深度学习算法根据虚拟机的资源使用数据信息做预测,但深度学习模型存在参数规模大的问题,导致训练模型非常耗时。Xie 等[9]提出一种基于三次指数平滑法和时间卷积网络的云资源预测模型,根据历史数据预测未来的资源需求。Wang 等[10]提出一种基于深度强化学习的联合算法,有效解决离散-连续的混合动作空间问题,该算法由基站为控制中心为每个用户分配资源,但集中式的方法不适用于柔性和实时性要求较高的工业边缘计算场景。Reig 等[11]采用传统的机器学习方法,建立在线预测系统分析任务对CPU 和内存需求进行预测,但是他们的方法是基于假设CPU 利用率和执行时间之间呈线性关系的,这就导致算法存在一定的局限性。
在面向工业的云边端协同场景中[12],工厂企业生产的大规模性会带来设备分布零散化的问题[13],单一的针对云上任务进行资源需求预测、边缘端的任务卸载或调度[14]缺少资源量化方法的依托已无法满足如今工业生产高资源利用率和低时延[15]的要求,并且上述研究很少考虑到平台与任务之间的资源量化问题[16]。
综上所述,本文提出基于多维度复杂任务细粒度分析[17]的算力度量方法,研究任务的时、空复杂度,任务计算类型与资源需求比例的关系,构建马尔科夫决策过程对任务执行时间进行预测优化,实现边缘设备的最优资源供给,结合深度Q 网络(Deep Q Network,DQN)将计算任务的资源需求量化问题转化为值函数映射问题[18]。通过实验结果表明,与Q-Learning 算法以及给出的其他两种方法相比,提出的模型结合改进的DQN 方法能够为解耦后的任务分配提供算力量化方法,成功度量任务的资源需求量,有效提高边缘设备的资源利用率,并且对任务的资源需求量化成功率可达99.37%,为工业生产提供更高效的资源分配方案。
2 系统模型和问题描述
2.1 任务模型
现有生产系统为了满足高实时性要求,采用任务-平台紧耦合的生产模式,导致系统资源利用率低、生产成本高,且不适用于个性化定制,亟需对任务进行量化分析,度量不同任务执行时需要的实际算力,实现解耦下的资源按需分配。同时,为了确保实际应用场景下控制节拍内的所有任务能够在最晚截止期之前完成,需要考虑任务之间的协同性问题,避免因资源分配不准确而导致任务执行失败。
本文将任务定义为不同传感器设备向边缘服务器发送的服务请求,假设通信范围内的所有边缘服务器的任务集合为M,任务集中的任意任务的参数集合都可以表示为mi={zi,gi,oi,λzi,gi,oi},其中,i=1,2,…,n,zi表示任务的时间复杂度大小,gi表示任务的空间复杂度大小,oi表示任务在实际处理时所归属的计算类型,λzi,gi,oi表示该项任务的所有参数类型与计算资源需求之间的权重值比例关系,用于表征边缘设备上任务占用的资源率。不同任务的实现需求也不相同,所以针对不同组合方式的参数集合可以用来表示对应的任务资源需求形式。时间复杂度可以用于评估程序执行所需的时间,可以估算出程序对处理器的使用程度,所以根据任务算法时间复杂度的大O表示法将zi表示为{O(1),O(n),O(logn)},{O(nlogn)},{O(n2),O(2n),(n!)}低中高三类范围。空间复杂度可以用于评估程序执行所需的存储空间,可以估算出程序对计算机内存的使用程度,同样地可以把gi细化为{O(1),O(n),O(logn)}。对于任务计算类型的分类主要根据实际生产需要划分为oi={GPU,GPU,NPU},本文主要考虑应用最为广泛的逻辑运算任务(CPU 类型)以及并行计算任务(GPU 类型)。综上,当给定zi,gi,oi,λzi,gi,oi时,系统可以根据最晚截止期要求为任务动态调节资源,选择合适的边缘节点进行计算。
由图1 可见,将所有计算设备的算力值虚拟化为整体的算力资源池,考虑到资源供给对任务执行时间的影响,每个任务表示为执行时间与资源分配的二元组,为满足任务可调度性及任务间的逻辑关系,需要对有限计算资源进行合理分配,即先量化后分配。例如,对所有任务量化后发现m2当前分配的资源无法使任务在最晚截止期前完成,而m4分配的资源已经超过当前任务的需求量,为了避免m3出现队列等待问题,将m4的溢出资源分配给m2,量化后m′2的计算资源增加的同时执行时间也相对减少了,并满足了整体节拍的实时性要求。

图1 控制节拍Fig.1 Tempo control
2.2 计算模型
对于边缘设备分配到的第i个任务都有实际完成时间,用于与任务预测完成时间进行对比,资源量化模型的可行性计算公式为
其中,qi表示任务实际消耗的资源大小,ei∈R+表示第i个任务所需的实际计算指令数量。给出任务的执行截止时间Di∈R+,表征任务的执行完成时间最晚不能超过该值,根据实时任务的参数类型集合可以将变化区间表示为[min(zi,gi,ei),max(zi,gi,ei)]。
根据任务属性与资源需求求解得到的权重值比例可以预测任务的执行时间,
其中,λzi,gi,oi为资源分配比例,f为预期分配的边缘节点拥有的计算资源量。由于量化方式需要对异构设备具有普适性,所以增加关于λzi,gi,oi的异构变量ξi,
其中,F为异构节点的计算资源量,根据异构节点与预期分配的节点计算能力大小比例改变ξi,令每个任务在使用最少资源的情况使预测完成时间与实际完成时间接近。
2.3 问题描述
本文的目标是最大化资源利用率,通过资源量化方法最小化预测执行时间ti,所以优化问题归纳如下:
其中,约束C1 表示资源量化的权重值比例范围要求,C2 表示任务的实际完成时间不能超过规定的最晚截止时间,δ表示误差范围率,允许超出实际执行时间的偏差值。由于大多数的云边协同模型下仅考虑任务的卸载与调度迁移问题,都未涉及在操作之前先对任务进行细化,往往会出现任务对边缘服务器资源需求不明确的问题,实际生产中任务分配到的算力溢出就会造成资源的浪费,所以本文对任务的细粒度建模能够为调度、卸载以及资源分配问题提供一个必要的前置技术参考。
2.4 马尔科夫决策过程
由于资源量化是根据任务细粒度属性分配资源比例的序列决策过程[19],所以可以把上述问题建模为马尔科夫决策过程。根据马尔科夫决策原理将单个时隙队列中的所有待量化计算任务作为状态空间,把每一个计算任务获取的资源分配比例大小作为动作空间,根据完成时间结果对比得到奖励函数R,建立三元组为[20],为了便于表述,本文在后续分别用s,a,r代表三元组中的状态、动作和奖励值。将任务集的参数集合来表示每一个时刻下任务属性发生的状态变化,对应的观测时隙为slot=1,2,…,T,系统Mslot=中的动作是每个时隙边缘节点给任务分配的资源比例大小,用表示,并对每个动作进行离散化处理∈[0,1,…,αΔw;Δw=1],其中aΔw表示动作维度为1 000,当环境结构越复杂就越需要较大的动作空间进行探索以寻找较优的结果;Δw表示步长为1;在每个时隙中,根据状态sslot选择了动作aslot得到奖励值R。
由于每一个时隙的奖励结果都是通过智能体与环境进行交互得到的,所以根据序列决策过程对奖励值进行修改,对序列进行分幕,每一幕求解任务根据状态所学到的资源比例值计算预测执行时间与实际执行时间差值之比,当成功完成一次交互则表示一幕结束,最终把马尔科夫决策过程转换为最优预测任务执行时间,即本文的优化目标minTi±Tiδ≤ti。
3 算法设计
3.1 基于强化学习的资源量化算法
强化学习通过智能体与外界环境的不断接触进行试错和学习,根据反馈信息更新自身策略的方法提高所作行为的奖励值[21],因其无需监督,只要获取环境反馈的特点而并被广泛应用于各个领域。其中Q-Learning 算法是由强化学习中的值函数迭代演变而来[22],属于时序差分学习算法,最初在某一时刻的状态下执行ε-greedy 贪心策略选择动作得到反馈收益,根据状态s与动作a构建为一张Q 表,训练过程中的每一步都会更新Q 表并把Q(s,a)存储到表格中,并在每一步更新Q 表的同时根据时隙状态选择最大Q(s,a)的动作,根据
更新迭代策略。其中,α是学习率,γ是折扣率,sslot+1为slot+1 时刻执行动作aslot后改变的状态,aslot是slot时刻通过ε-greedy 贪心策略随机生成的动作或是取使Q(sslot+1,aslot)最大的动作aslot。
算法1 Q-Learning 算法
输入:状态s,折扣率γ,学习率α
输出:资源比例分配策略集A
1.初始化Q 表
2.初始化时隙状态
3.FORi∈episodesDO
4.以ε的概率从动作集中随机选择资源分配比例策略
5.通过奖励机制得到奖励值并进入到下一个时隙状态
6.根据式(6)选择使Q(sslot+1,aslot)最大的动作更新Q 表
7.END FOR
3.2 基于DQN 的资源量化方法
强化学习和深度学习[23]都属于机器学习范畴,深度学习是一种包含有多层隐藏层的神经网络结构,通过提取样本的特征、分析数据的内在规律和表现形式来拟合高维的数据。当强化学习场景中的维度过大时,Q-Learning 学习算法很难再用Q 表对状态-动作对进行存储。然而实际资源比例分配的过程需要选择非常多的比例值进行尝试,所以当状态动作空间维度变大时容易发生维度灾难,结合Q-Learning 和深度学习两者优点的深度Q网络[24-25]解决了这一问题。图2 是基于DQN 的资源量化算法基本框架。
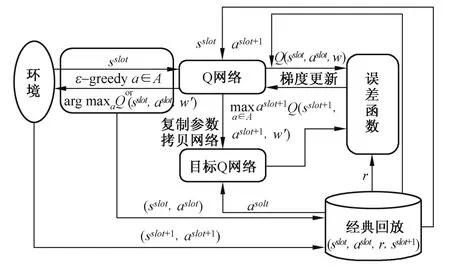
图2 DQN 算法结构Fig.2 The structure of DQN algorithm
DQN 的主要思想是在Q-Learning 的基础上将Q 表替换为Q 网络,并引入目标Q 网络与经验回放机制。本文算法针对DQN 神经网络进行修改,选择了人工神经网络,对网络层数以及神经元数量进行修改,重新定义了Q 网络中的奖励函数,将奖励值转化为对任务执行时间的预测优化问题。加入经验回放机制的原因是在强化学习的训练过程中所有观测到的数据都是有序的,而传统机器学习中监督学习的数据都是处于独立同分布的,所以需要加入一个经验池用来存储训练过程中的数据,训练时通过从经验池中抽取一部分数据用来更新网络,避免数据之间存在较强的关联性,并且当经验池存储满后每一次的新数据都会覆盖原有的旧数据。Q 网络用于接收从环境中观测到的状态s,根据所选动作得到反馈的奖励值并进入下一个状态sslot+1,aslot+1表示为状态sslot+1下获得最大奖励值的动作,并将序列(sslot,aslot,r,sslot+1)存入经验池中。目标Q 网络的结构与Q 网络完全相同,不同之处在于Q 网络每一次都会迭代更新,而目标Q 网络会每隔一段时间通过复制Q 网络的权重参数进行更新,这样做的作用是避免目标值函数频繁更新导致参数不收敛。Q 网络的动作状态估计值为
其中,w表示神经网络的权重值,目标Q 网络的动作状态值函数为Q(sslot+1,aslot+1;w′),w′表示其权重值周期性地进行更新,其目标价值函数为
为了让动作状态值函数逼近目标价值函数,即
所以将误差函数定义为
在每次迭代中通过反向传播的机制更新网络参数w,并使用Adma 优化器来优化误差函数,改善网络整体精度。
算法2 D-Quantify 算法
输入:状态s,折扣率γ,学习率α,采样长度Z,经验池|M|,目标Q 网络更新周期ts;
输出:资源比例分配策略集A
1.初始化清空经验池|M|的数据,学习率α,折扣率γ,采样长度Z
2.FORi∈episodesDO
3.WHILE TRUE
4.使用ε-greedy 随机选择动作a,否则选择令maxaQ(sslot,aslot;w)最大的动作
5.根据执行动作获得对应的奖励值并得到下一个状态sslot+1
6.将(sslot,aslot,r,sslot+1)存入经验池|M|中, 令sslot=sslot+1
7.如果经验池已满则进入下一迭代或sslot+1为完成状态则结束本幕
8.IF 采集量>经验池:
9.对经验池|M|随机均匀采样Z个数据
10.根据式(9)和式(11)得到误差函数,使用反向传播机制更新网络参数
11.使用Adma 优化器优化神经网络
12.更新Q 网络,并以ts为周期将网络参数复制给目标Q网络
13.END IF
14.如果sslot+1为满足完成状态则结束本幕
15.END FOR
4 仿真结果与分析
本节实验平台条件为Intel Core i7-10700 CPU,32 GB 内存,Python 3.8+PyTorch 1.10 作为算法的仿真语言。本实验所涉及到的部分参数参考文献[20]进行设置并如表1 所示。
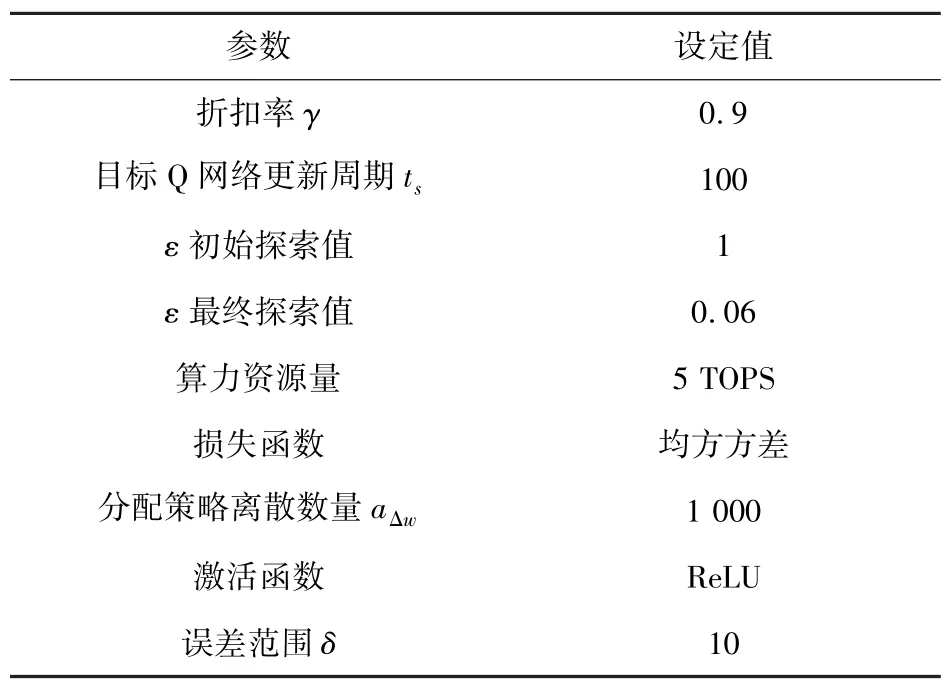
表1 仿真参数Tab.1 The simulation parameters
通过SMOTE(Synthetic Minority Over-Sampling Technique)算法[26]可以在保证数据通用性的前提下对预先测得的真实数据集进行扩充,以满足算法训练所需的样本,核心思路是对每一个采样的少类样本点以欧氏距离的标准计算到其上的距离,选择最临近的n个样本中的任意一点。
为了在实验中体现细粒度性,将各任务的属性对应任务模型把时间复杂度{O(1),O(n),O(logn)},{O(nlogn)},{O(n2),O(2n),(n!)}以{timelow,timemid,timehigh}三部分的归类方式进行组合;空间复杂度{O(1),O(n),O(logn)}以及计算类型GPU、CPU 以同样的方式分别归类为{spacelow,spacemid,spacehigh}、{compG,compC}。根据上述方法并按照不同的排列结构对已有数据集进行精确划分,例如{timelow,spacelow,compG}表示任务结构属于低时间复杂度、低空间复杂度、需要并行计算处理。上述分类方式有利于实验中按不同任务结构对数据集进行批量处理,其可扩展性有效满足在面对实际应用场景中因柔性生产而产生的任务多变性。其中,本文将误差范围设置为10%是为了避免执行时间较小的时延敏感任务获得较大的预测执行时间优化目标,ε的最终探索值设置为0.06 能够保证在实验后期仍然能进行适当地探索,避免陷入局部最优的情况,并且网络更新周期设置为100 时,网络参数能有较好地收敛结果,最终通过1 000 幕训练实现算法收敛。
首先,分析学习率、采样长度、经验池大小这3 个参数对算法性能的影响。图3 为不同的实验参数对算法的影响,纵坐标表示本文算法成功预测出任务执行时间的概率,横坐标表示算法执行的幕数。为了便于观察,本文之后的实验均为对每100 幕的数据结果进行平均化处理。由图3(a)可见,当学习率为0.001 时,虽然整体预测较为平稳,但预测准确率明显低于学习率为0.01 时,并且学习率为0.01 时准确率最高,所以本文后续实验采用学习率为0.01。如图3(b)所示,当采样长度为100 时,获取的样本数据太少导致算法学习效率较低,采样长度为300 和500 时对算法的性能影响基本一致,适当增加采样值能够加快算法收敛,所以本实验选择采样长度为1 000。由图3(c)可以看出当经验池大小为10 000 时算法性能明显优于其他3 种参数的表现情况,并且考虑到本文所设计的D-Quantify 算法动作维度较大,选择经验池大小为10 000 可以有效缓解环境探索不充分的问题。
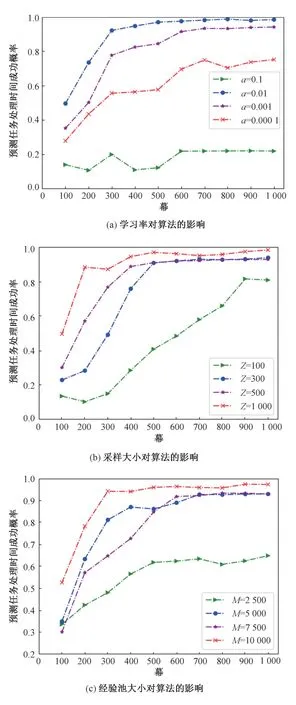
图3 各参数对算法的影响Fig.3 The influence of each parameter on the algorithm
由于目前对算力度量的细粒度研究工作较少,缺少衡量标准,所以为了说明D-Quantify 算法性能本文采用经典的贪心算法(Greedy Algorithm,GA)以及固定分配资源比例算法(Fixed allocation resource proportion algorithm, FR)进行对比,其中GA 是根据资源分配结果选择局部最优方案求解整个预测过程,FR 依据任务的计算类型按固定方式分配资源需求比例。图4 是本文所提出的DQuantify 方法与其他方法的预测误差率对比结果,图中纵坐标表示预测结果与实际执行时间的偏差率,表示为,在训练初期D-Quantify 方法和GA 方法出现差值之比较大的原因是预测的结果高于Ti较多。随着训练次数的增加,D-Quantify方法要明显优于其他3 种方法,相比Q-Learning、GA、FR 偏差率降低了约12.12%、10.44%、15.42%,并且逐渐趋于稳定且与实际执行时间相比偏差率平均只有5.14%。
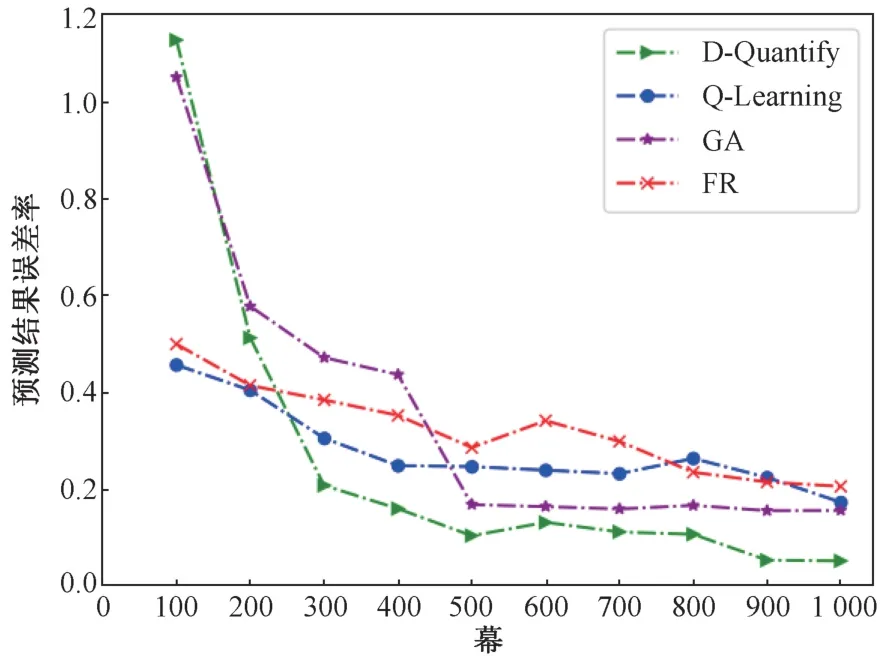
图4 各算法的预测结果偏差率对比Fig.4 Comparison of deviation rate of prediction results of each algorithm
将算力资源总量设置为5、10、15 并同时增加到达任务属性的复杂度,进行比较4 种算法在预测任务处理时间上的成功率,可以从图5 中较直观地发现本文所提方法在算力资源量变化的情况下始终能够选择正确的资源分配比例值,并且在三种情况下预测结果成功率分别能够达到99.28%、96.44%、96.17%,这表示D-Quantify 可以很好地解决任务的跨平台问题,并且较高的成功率可以更为精准地进行资源分配,提高任务跨平台卸载迁移的准确性和成功率。其中,由于GA 方法局部最优的局限性对不同的算力资源量适用性较差,无法细粒度分析任务属性导致在资源总量与任务复杂度变化的情况下不能给出更优的资源分配结果。
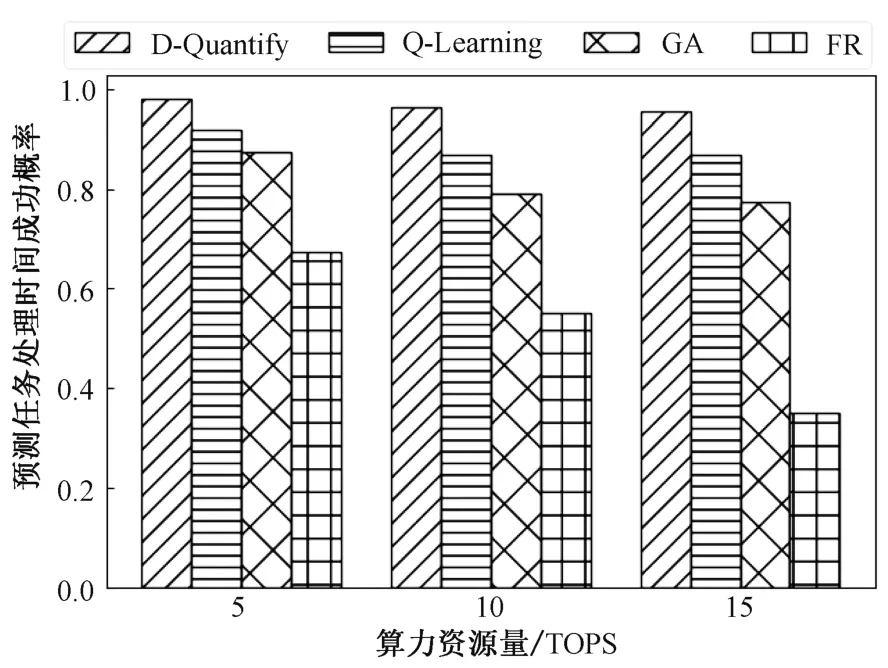
图5 算力资源量的变化对算法性能的影响Fig.5 The influence of variation of computationalpower resources on algorithm performance
由图6 所示,误差范围与各算法性能呈线性下降趋势,即当容许误差率越低时算法性能表现越显不足。从图中可以看出当误差变化范围达到5%时D-Quantify 的预测成功率仍然可以达到97.44%, 其余算法各为 86.91%、 49.33%、55.61%,且只有D-Quantify 保持稳定小幅下降状态而其他所有算法性能都大打折扣,所以即使本文算法应用于参数条件要求较高的场景下依旧可以达到很好的正确率。

图6 误差上限变化对各算法的影响Fig.6 The influence of the change of error upper limit on each algorithm
由图7 所示,在所有参数条件不变的情况下对预测任务处理时间的成功率进行比较,纵坐标表示各算法对执行时间的预测成功率,横坐标每个点表示每100 幕记录一次结果。
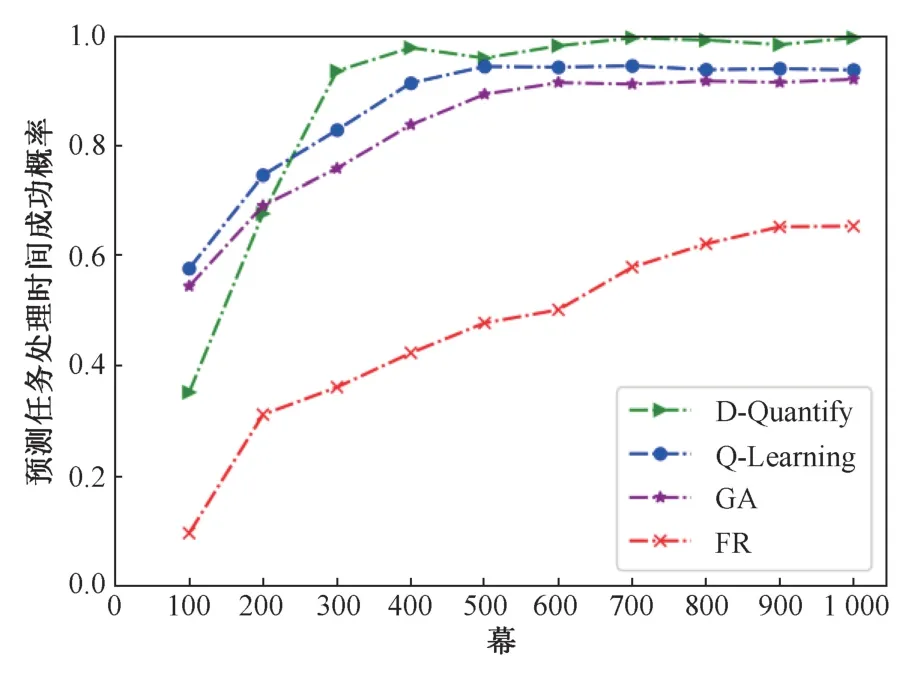
图7 各算法的预测成功率Fig.7 The success rate of prediction of each algorithm
在训练初期D-Quantify 算法预测成功率较低,这是因为经验池较大的原因导致探索到的无用情况较多,所以最开始无法找到较好的动作,但随着训练次数的增长,D-Quantify 逐渐优于其他算法,并且在300 幕左右算法开始收敛。本文改进的DQN 算法预测成功率可达99.37%,相较于QLearning、GA、FR 算法成功率要高5.84%、7.54%和34.23%,其中Q-Learning 虽然具有在线优化的能力,但在应对维度较大的场景时Q 表容易产生维度灾难,所以成功率会逐渐低于D-Quantify 并且与GA 基本相同。图7 中可以看出FR 出现了预测结果较差的情况,这是因为在预测任务执行时间的过程中如果无法对即将到达的任务做具体的资源需求分析,就会出现多分配或少分配资源,虽然在给定足够大的资源比例值时能够完成任务并且满足最晚截止期的要求,但是与实际所需的资源量相差过多,会造成资源的浪费,所以在本文的优化条件下FR 始终没有达到目标预期值。由此可以看出本文的细粒度资源量化方法能够为现有的边缘计算量化技术提供较好的前置技术参考。
5 结论
本文研究了面向工业的计算任务量化方法。针对工业场景中由节点异构性、分布零散性、与任务-平台紧耦合等导致冗余资源成本高柔性差的问题,提出基于边缘计算的算力度量方法。通过细粒度分析任务时、空复杂度,计算类型等特征,建立计算任务特征与资源需求比例之间的关系,将序列过程构建为马尔科夫决策过程,以求解最优预测时间为目的,基于深度Q 网络设计资源度量方法。仿真结果显示,所提算法预测任务执行时间成功率可达99.37%,相较于Q-Learning、GA、FR 算法分别提高了5.84%、7.54%和34.23%,有效实现了边缘侧的算力度量,为未来工业互联网下网络-计算-控制一体化提供了算力量化基础。
