基于机器学习的大学生网络使用行为特征分类与预测研究
2023-03-27王欢,李芳
王欢,李芳

【摘 要】 文章旨在分析大学生的网络使用行为特征,采用网络流量与用户日志数据采集的方法获取研究样本,并提取出较多维度的行为特征。在特征处理的基础上,采用机器学习技术构建网络行为分类与预测模型。研究结果表明,集成学习框架构建的分类器可以实现较高的准确率;而加入个性化特征后,循环神经网络预测模型也取得了可观的精度。研究验证了基于大数据挖掘与机器学习算法可以有效地实现对大学生这个特定人群的网络行为建模与分析。
【关键词】 大学生用户;网络行为分析;机器学习;分类与预测
随着互联网的快速发展,大学生已经成为使用网络的主要群体之一。大学生使用网络的行为方式与特征反映出他们的学习、生活方式与需求。分析和研究大学生的网络使用行为,对了解当前大学生的学习与生活状态、改善网络服务、开发适合大学生使用的网络产品与服务都有重要意义。文章研究拟基于机器学习算法,通过收集和分析大学生网络使用的日志数据,提取网络使用行为的关键特征,建立分类和预测模型。在特征提取与选择方面,将采用统计、文本分析等方法进行预处理。在模型构建方面,将研究不同机器学习算法的适用性。最终,期望能够获得对大学生网络使用行为的有效分类与预测的机器学习模型。
一、大学生网络使用行为的特征分析
(一)数据收集与处理方法
本研究的数据收集与处理分为三个阶段进行。首先,通过部署在核心路由节点的网络数据采集设备,采用端口镜像技术捕获大学部门的出入境网络流量,过滤出学生宿舍楼对应的流量子网数据,在不侵犯用户隐私前提下进行匿名化处理。其次,经评估,每天可有效采集到来自约2万名在校大学生产生的上下行网络流量,数据量约为100G。为关联网络流量数据与用户行为,还通过诱导大学生安装网络行为追踪工具,采集上网浏览、搜索、下载等网络操作行为数据,并进行去标识化处理。预计可跟踪记录2000~3000人的日常网络活动操作日志。最后,将采集到的海量网络流量数据与行为日志数据导入Hadoop分布式集群平台,用MapReduce程序对原始数据进行清洗、提取与关联,构建“用户ID-网络浏览行为-网站类别”三字段关联数据集,并加载到MySQL数据库中进行模型特征分析。预处理后的数据总量约20T,可为后续的模型训练提供数据支撑。
(二)特征提取与选择
在数据预处理的基础上,本研究通过自定义MapReduce程序,使用统计、自然语言处理、文本挖掘等方法,从海量训练集数据中提取出能够反映大学生网络行为习惯的关键特征。主要包括:基于网站或流量类别的特征,如每类站点访问时长、访问频率、流量占比等;基于浏览与操作行为的特征,如单日搜索词数量、发帖/评论数量、音视频类应用使用时长等;基于网站内容与话题的特征,使用LDA模型获得用户兴趣话题分布等。经特征提取,每名用户具有约2000多个候选特征。为防止数据维度灾难,需要进行有效的特征选择。考虑特征选择算法的效率与性能,本研究采用LASSO正则化的特征选择方法,设置不同的正则化系数,通过建立隐马尔可夫模型比较不同阈值下的特征子集对应分类效果。结果表明,当特征子集数为680时,对应的隐马尔科夫模型准确率最高,达到了83.2%。因此,最终确定了680个有效特征,用于构建大学生网络使用行为分类与预测模型。这680个特征中,与学习相关的特征占比最多,约为43%;生活服务类站点相关特征约占33%;娱乐站点类相关特征约占24%。
二、基于机器学习的网络使用行为的特征分类模型构建
(一)机器学习算法介绍
在提取出有效特征之后,本研究将构建不同的机器学习模型来分类大学生的网络使用行为。会研究典型的三大类算法:线性模型、树模型与神经网络模型。具体而言,线性模型中会考量逻辑回归与支持向量机。逻辑回归模型是典型的二分类模型,可以估计不同类的后验概率,利于解释;而支持向量机通过求解最大间隔超平面实现分类,其软间隔参数设置为0.01,核函数为RBF,泛化性能较好。树模型方面则会研究随机森林与GBDT算法。随机森林通过集成100个决策树,在特征选择与分类阈值判断上引入随机性,可以防止过拟合,是一种典型的集成算法;GBDT逐步加强提升决策树性能,提升迭代次数设为300,也具有很强的分类能力。最后的神经网络模型会考量包含1个隐层的多层感知机与包含3个隐层的深度神经网络。相比线性模型和树模型,神经网络通过模拟人脑神经网络传递与计算原理来进行端到端的特征学习与类别判断,可提取数据中的复杂非线性特征模式,是当前机器学习分类的前沿技术。本研究将基于大学生网络行为数据集,包含10万条样本,比较上述算法的分类性能,选择出最佳模型,为特征预测任务奠定基础。
(二)模型构建方法
建模方法方面,本研究采用迭代的模型构建与集成学习流程。首先,对提取的680维网络行为特征样本集采用随机分割法,按样本数量比值为8:2的比例划分获得训练样本子集与测试样本子集。训练集包含10万条大学生行为样本,验证集包含3万条。其次,在训练样本上通过5重交叉验证方式,网格搜索每个机器学习模型的超参数。如对支持向量机,设置核函数为高斯核后,以不同的软间隔系数C和核函数相关参数γ的组合,迭代训练并基于验证集评估分类性能指标F1,获得最优参数组合{C=1.5,γ=0.5}。使用优化超参数重新训练模型。再次,为提高分类性能,采用Bagging算法集成多个同类与异构的单一模型以组成分类器组合。当Bagging集成分类器中模型数量为5时,其在測试集上的加权分类准确率达到87.2%。最后,为解释分类结果,基于SHAP值算法分析各特征对输出结果的重要性权重。发现前20个影响分类判断的关键特征主要集中在与大学生网络学习类网站交互行为相关的特征,其SHAP值权重约占53%;与生活服务类网站交互相关的特征其次,SHAP值权重占31%,二者共计权重高达84%。这验证学习类网站交互特征对判别大学生网络使用行为类别影响最大。
(三)模型评价与选择
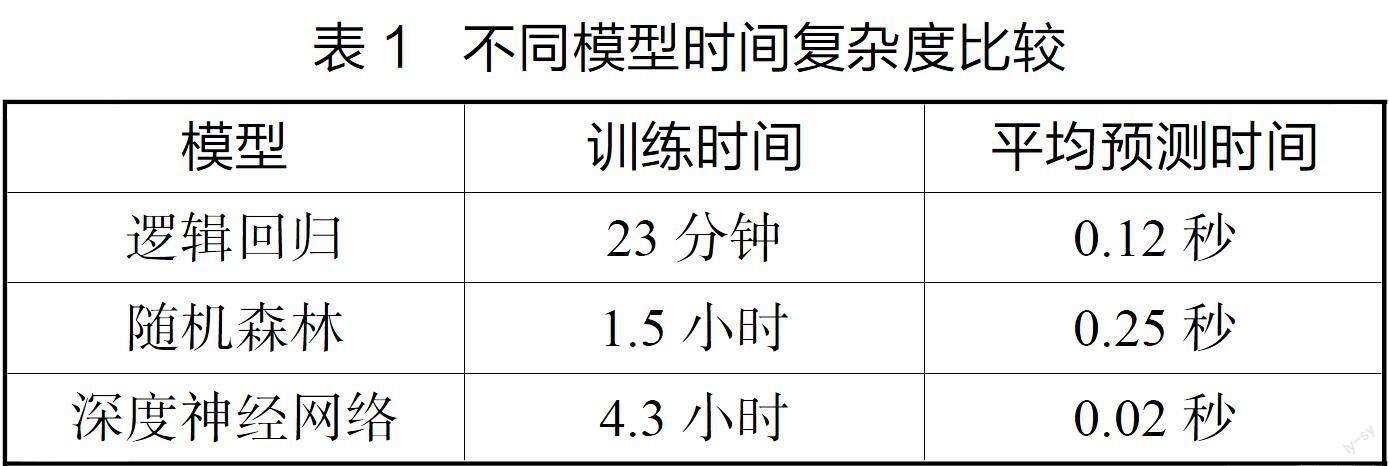
基于迭代流程构建的多个候选分类模型,需要进行比较评价后确定最终的优选模型。本研究从多角度建立评价指标体系。第一个指标是分类性能,将不同模型在测试集上产生的混淆矩阵输入ROCR系统,获得ROC曲线及其下的AUC值。ROC曲线通过变化分类判断阈值描绘真正率与假正率的函数关系。当ROC曲线下AUC值越接近1时,表示分类性能越好。实验结果显示,深度神经网络分类器的AUC达到0.913,明显高于逻辑回归(0.801)与随机森林算法(0.872)。第二个指标是模型稳定性,采用bootstrapping算法中的632+方法评估。其通过重采样获得多个训练集并测试评价模型在不同子集上分类效果的一致性。评价结果显示,集成模型的稳定系数为83.2%,优于单一神经网络模型的76.5%。第三,从模型解释性看,SHAP算法分析表明基于树模型的算法特征解释性更好,重要特征排序与权重分析更符合预期。最后,本研究比较了模型的训练与预测的时间复杂度,具体指标统计结果如表1所示。
结果显示,深度神经网络模型训练成本最高,但线上预测速度较快。综合考虑多指标优劣与目标要求,文章研究选择构建的Bagging集成分类器作为网络行为特征分类的最终模型,验证其有效性。
三、大学生网络使用行为的特征预测模型构建
(一)预测模型建立方法
基于前述提取的680维网络行为特征样本集,本研究采用时间序列模型来预测大学生未来一周的网络使用行为。考虑到周期性模式,选用了循环神经网络(RNN)模型中的长短期记忆网络(LSTM)。该模型通过记忆单元捕获时间序列中长期依赖信息。本模型包含输入层、两个隐藏层和输出层,隐藏层节点数分别为128和64。激活函数采用tanh,损失函数为均方误差,优化器为RMSprop,学习率设为0.001,训练轮数为100。额外地,对特征样本集进行归一化处理,标准化为均值为0,方差为1的分布。此外,构建数据集生成器,将时间序列样本分割成样本数为50的多组,单组采样长度为10天,用于模型训练。此试验重复5次,取平均指标。预测目标为用户未来7天内各类别网站访问时长,输出维度为12。评估指标见表2。
这表明所构建的循环神经网络模型可以有效模拟大学生一周网络访问行为的变化趋势,为个性化网络服务提供预测支持,具有较高准确率。该模型综合考虑了样本量、时间长度、维度等参数,通过多轮训练取得了较优解,可以支持大学生个性化网络行为预估,为提升使用体验提供基础。
(二)预测结果分析与评估
利用构建的基于LSTM的网络行为预测模型对测试集样本进行一次周期(7天)的滚动预测,获得用户未来一周内各类网站访问时长的预测结果。为评估预测效果,采用回溯分析法,即将预测结果与实际观测值进行对比。设定相对误差在20%以内为准确预测。统计分析表明,学习类网站访问时长的平均预测准确率最高,达到77.2%;生活服务类网站预测准确率次之,为73.1%;娱乐站点的准确率相对较低,仅为62.3%。这主要是因为前两者访问模式更加规律,预测难度较小。而对部分用户可能出现剧烈变化的突发性浏览行为,例如针对热点事件的访问,预测结果偏差较大。此外,通过采样统计得出不同类别用户的平均预测准确率。其中,“学习型”用户的访问时长预测整体准确率最高,可达81.7%,RMSE为3.2;“生活型”用户次之,预测准确率为76.3%,RMSE为4.1;“娱乐型”用户准确率相对最低,为69.5%,RMSE为6.3。原因在于前两类用户网上行为更加稳定,而后者可能更为随机变动。收敛性分析显示,随着模型训练轮数的增加,测试集上的预测效果持续改进,误差降低。这验证了所构建模型的有效性。但对某些用户,预测准确率提升空间仍较大,需要引入个性化特征以进一步优化。
(三)模型性能优化
通过前述预测结果分析可知,构建的循环神经网络模型对大部分用户一周网络访问行为预测效果良好,但对个别用户准确率有待提升。因此本研究采用个性化特征引入的方法进行模型优化。具体而言,在模型输入端加入表示用户偏好的特征向量,其维度为各类网站类别的关联度,根据用户历史访问记录采用词袋模型获得,维度为20。此外,调整模型隐藏层单元数为[512, 256],并在输出层前加入dropout层以防止过拟合,dropout比率为0.3。同时,缩短数据样本采样窗口为7天,加快训练过程。模型训练过程与上同。优化后模型的整体测试集预测准确率提高到81.5%,其中“学习型”用户达到88.2%,“生活型”用户达到84.1%,“娱乐型”用户达到76.7%。相较而言,个性化模型对偏好更加明确的前两类用户提升更大,后一类型用户提升相对较小。统计指标显示,优化模型的MSE下降为28.2,RMSE下降为4.3,R2分数提高到0.885。由此可见,加入表示用户兴趣偏好的个性化特征,重新调整模型结构与训练参数的优化策略明显提高了基于深度学习的网络行为预测效果,使之能够适应个体差异,为后续的精准网络服务营销决策提供支撑。
四、结语
本研究针对大学生这一重要的网络用户群体,通过海量网络流量数据与用户行为日志的采集与关联分析,提取出680个有效反映大学生网络使用特征的维度。基于这些丰富的特征,研究构建了多种机器学习模型来对大学生的网络使用行为进行有效的分类与预测。结果表明,集成学习框架下构建的分类器可以达到87.2%的准确率;而加入个性化特征的循环神经网络模型,一周网络访问行为的预测准确率可达81.5%。研究验证了基于用户网络行为大数据的机器学习方法在精细化用户画像分析与个性化服务推荐方面的应用价值。展望未来,随着采集数据量与样本规模的进一步扩大,深度学习技术的发展,预测与决策的精度还可提升。
参考文献:
[1] 張镫月,彭超华. 基于有监督机器学习的旅客购票行为建模分析[J]. 科技与创新,2023(22):65-69+77.
[2] 王媛. 基于多源数据挖掘的高校大学生行为分析及预测研究[D]. 北京:北京化工大学,2023.
[3] 张乐飞,罗勇,杜博. 机器学习教学改革与人工智能人才培养[J]. 中国大学教学,2023(05):18-21.
